 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Multilingual Zero Resource Speech Recognition Base on Self-Supervise Pre-Trained Acoustic Models
Oct 13, 2022
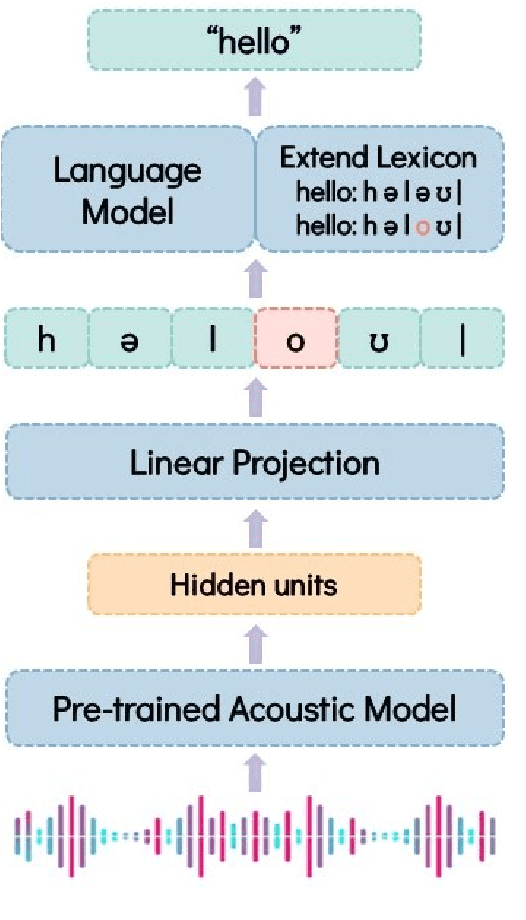
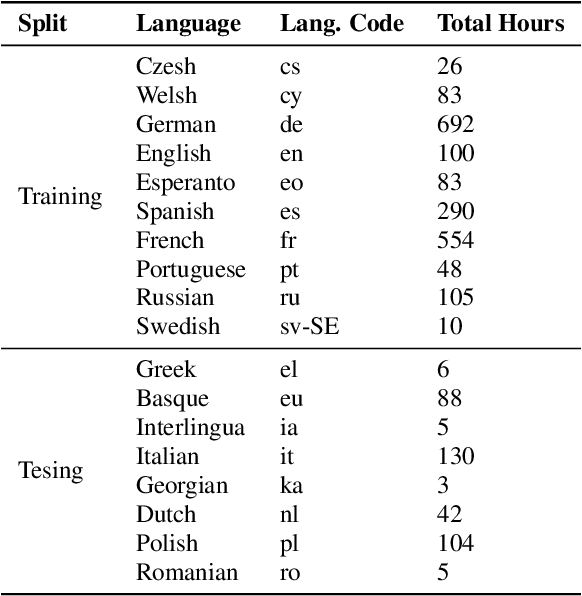
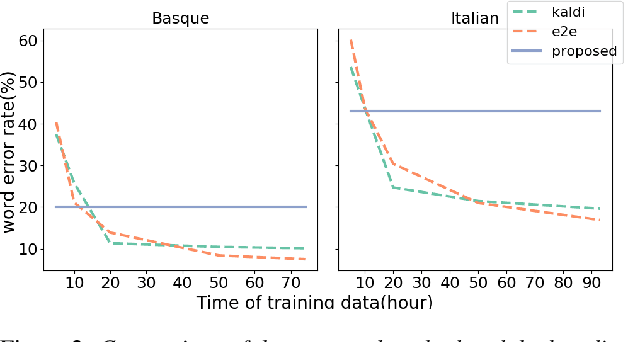
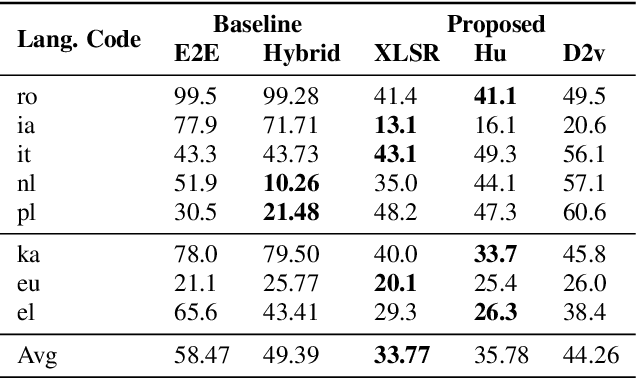
Labeled audio data is insufficient to build satisfying speech recognition systems for most of the languages in the world. There have been some zero-resource methods trying to perform phoneme or word-level speech recognition without labeled audio data of the target language, but the error rate of these methods is usually too high to be applied in real-world scenarios. Recently, the representation ability of self-supervise pre-trained models has been found to be extremely beneficial in zero-resource phoneme recognition. As far as we are concerned, this paper is the first attempt to extend the use of pre-trained models into word-level zero-resource speech recognition. This is done by fine-tuning the pre-trained models on IPA phoneme transcriptions and decoding with a language model trained on extra texts. Experiments on Wav2vec 2.0 and HuBERT models show that this method can achieve less than 20% word error rate on some languages, and the average error rate on 8 languages is 33.77%.
Disentangled Speech Representation Learning for One-Shot Cross-lingual Voice Conversion Using $β$-VAE
Oct 25, 2022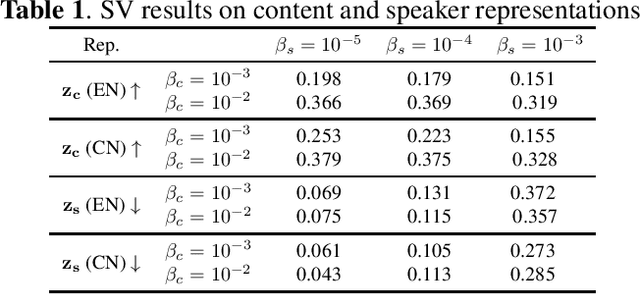
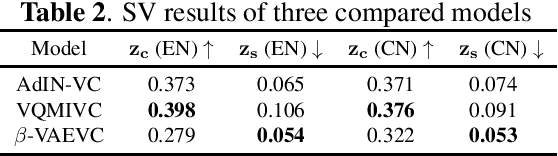
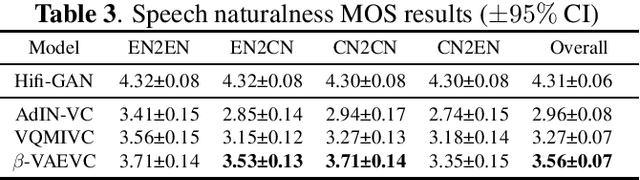
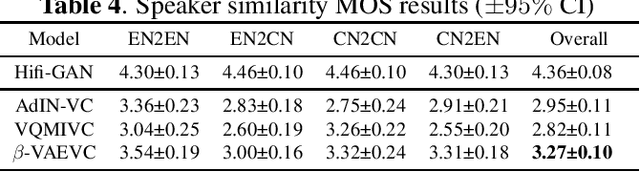
We propose an unsupervised learning method to disentangle speech into content representation and speaker identity representation. We apply this method to the challenging one-shot cross-lingual voice conversion task to demonstrate the effectiveness of the disentanglement. Inspired by $\beta$-VAE, we introduce a learning objective that balances between the information captured by the content and speaker representations. In addition, the inductive biases from the architectural design and the training dataset further encourage the desired disentanglement. Both objective and subjective evaluations show the effectiveness of the proposed method in speech disentanglement and in one-shot cross-lingual voice conversion.
Joint Speech Activity and Overlap Detection with Multi-Exit Architecture
Sep 24, 2022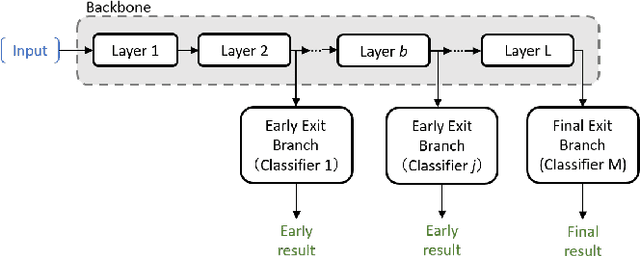
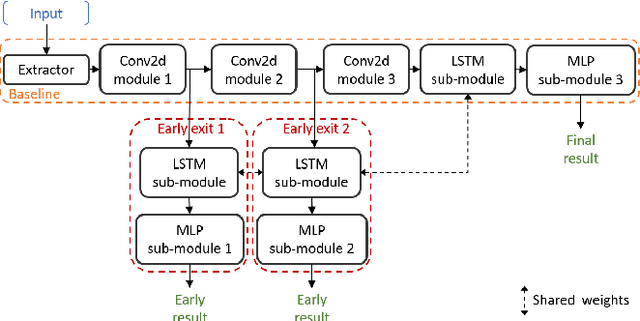
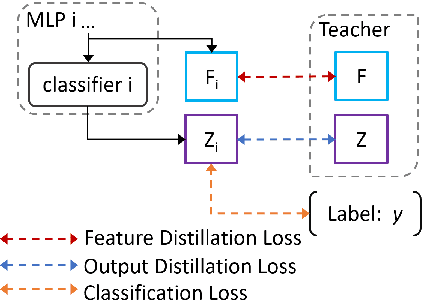
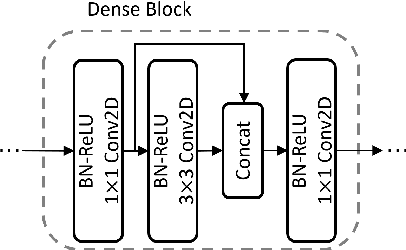
Overlapped speech detection (OSD) is critical for speech applications in scenario of multi-party conversion. Despite numerous research efforts and progresses, comparing with speech activity detection (VAD), OSD remains an open challenge and its overall performance is far from satisfactory. The majority of prior research typically formulates the OSD problem as a standard classification problem, to identify speech with binary (OSD) or three-class label (joint VAD and OSD) at frame level. In contrast to the mainstream, this study investigates the joint VAD and OSD task from a new perspective. In particular, we propose to extend traditional classification network with multi-exit architecture. Such an architecture empowers our system with unique capability to identify class using either low-level features from early exits or high-level features from last exit. In addition, two training schemes, knowledge distillation and dense connection, are adopted to further boost our system performance. Experimental results on benchmark datasets (AMI and DIHARD-III) validated the effectiveness and generality of our proposed system. Our ablations further reveal the complementary contribution of proposed schemes. With $F_1$ score of 0.792 on AMI and 0.625 on DIHARD-III, our proposed system outperforms several top performing models on these datasets, but also surpasses the current state-of-the-art by large margins across both datasets. Besides the performance benefit, our proposed system offers another appealing potential for quality-complexity trade-offs, which is highly preferred for efficient OSD deployment.
A Review of Challenges in Machine Learning based Automated Hate Speech Detection
Sep 12, 2022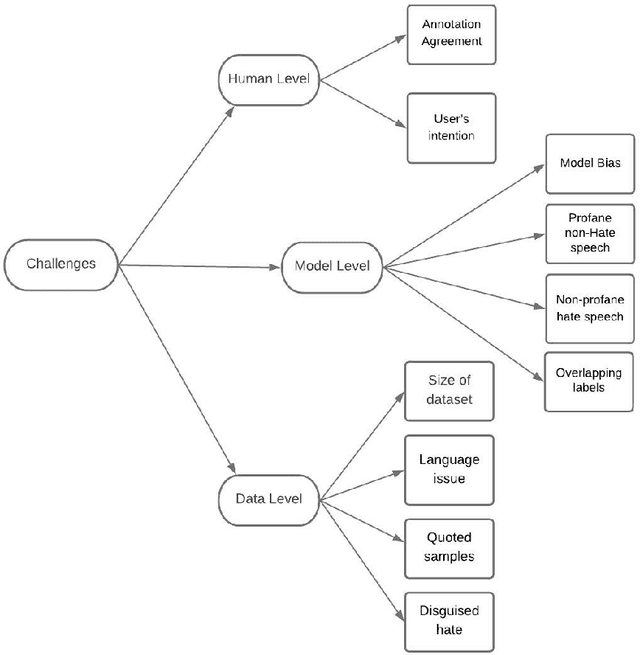
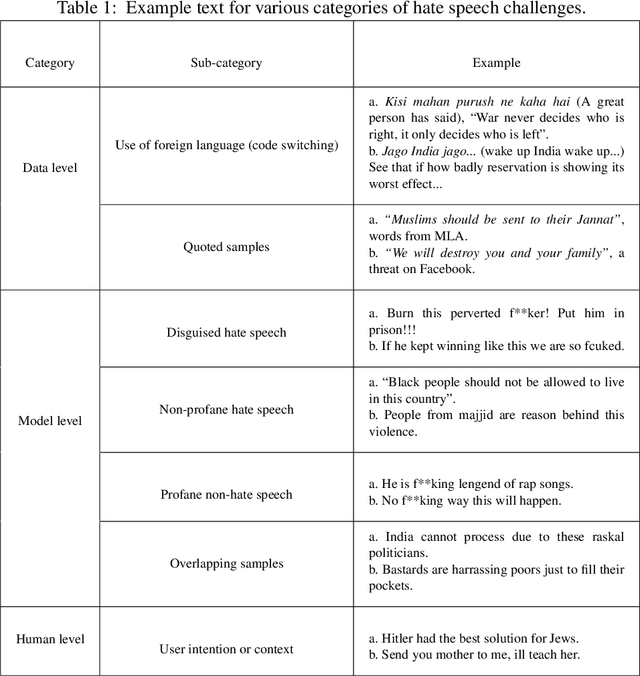
The spread of hate speech on social media space is currently a serious issue. The undemanding access to the enormous amount of information being generated on these platforms has led people to post and react with toxic content that originates violence. Though efforts have been made toward detecting and restraining such content online, it is still challenging to identify it accurately. Deep learning based solutions have been at the forefront of identifying hateful content. However, the factors such as the context-dependent nature of hate speech, the intention of the user, undesired biases, etc. make this process overcritical. In this work, we deeply explore a wide range of challenges in automatic hate speech detection by presenting a hierarchical organization of these problems. We focus on challenges faced by machine learning or deep learning based solutions to hate speech identification. At the top level, we distinguish between data level, model level, and human level challenges. We further provide an exhaustive analysis of each level of the hierarchy with examples. This survey will help researchers to design their solutions more efficiently in the domain of hate speech detection.
Speech Segmentation Optimization using Segmented Bilingual Speech Corpus for End-to-end Speech Translation
Mar 29, 2022
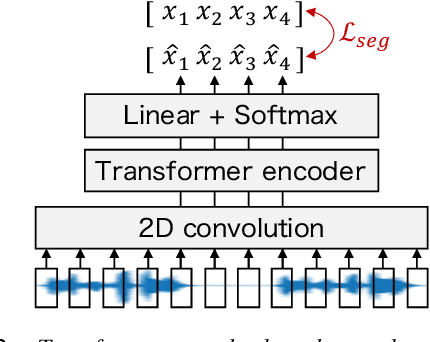
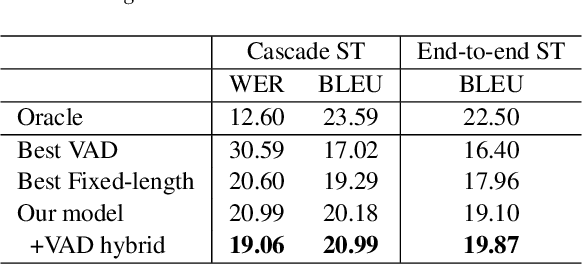
Speech segmentation, which splits long speech into short segments, is essential for speech translation (ST). Popular VAD tools like WebRTC VAD have generally relied on pause-based segmentation. Unfortunately, pauses in speech do not necessarily match sentence boundaries, and sentences can be connected by a very short pause that is difficult to detect by VAD. In this study, we propose a speech segmentation method using a binary classification model trained using a segmented bilingual speech corpus. We also propose a hybrid method that combines VAD and the above speech segmentation method. Experimental results revealed that the proposed method is more suitable for cascade and end-to-end ST systems than conventional segmentation methods. The hybrid approach further improved the translation performance.
Channel-Aware Pretraining of Joint Encoder-Decoder Self-Supervised Model for Telephonic-Speech ASR
Nov 03, 2022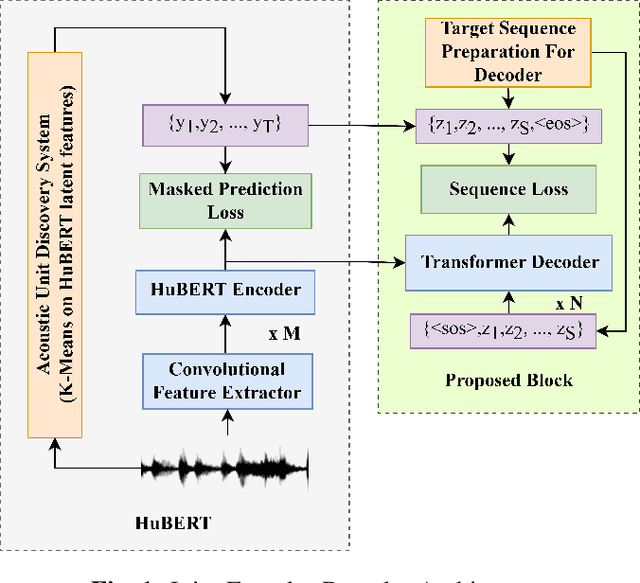
This paper proposes a novel technique to obtain better downstream ASR performance from a joint encoder-decoder self-supervised model when trained with speech pooled from two different channels (narrow and wide band). The joint encoder-decoder self-supervised model extends the HuBERT model with a Transformer decoder. HuBERT performs clustering of features and predicts the class of every input frame. In simple pooling, which is our baseline, there is no way to identify the channel information. To incorporate channel information, we have proposed non-overlapping cluster IDs for speech from different channels. Our method gives a relative improvement of ~ 5% over the joint encoder-decoder self-supervised model built with simple pooling of data, which serves as our baseline.
Mispronunciation Detection of Basic Quranic Recitation Rules using Deep Learning
May 10, 2023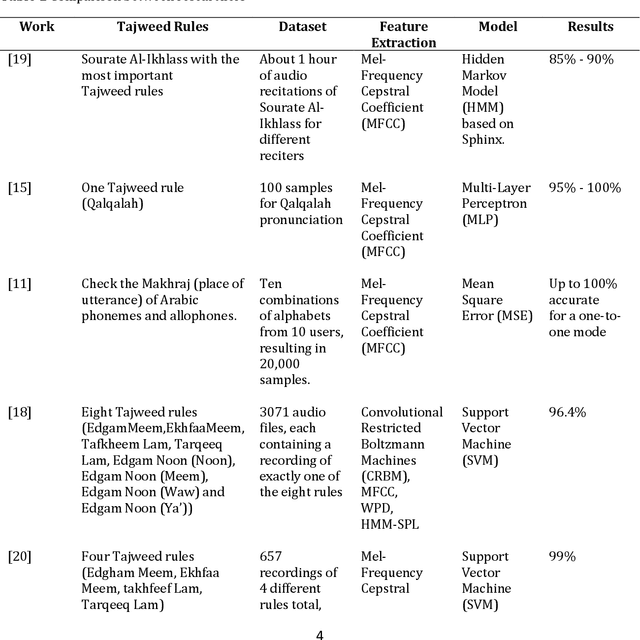
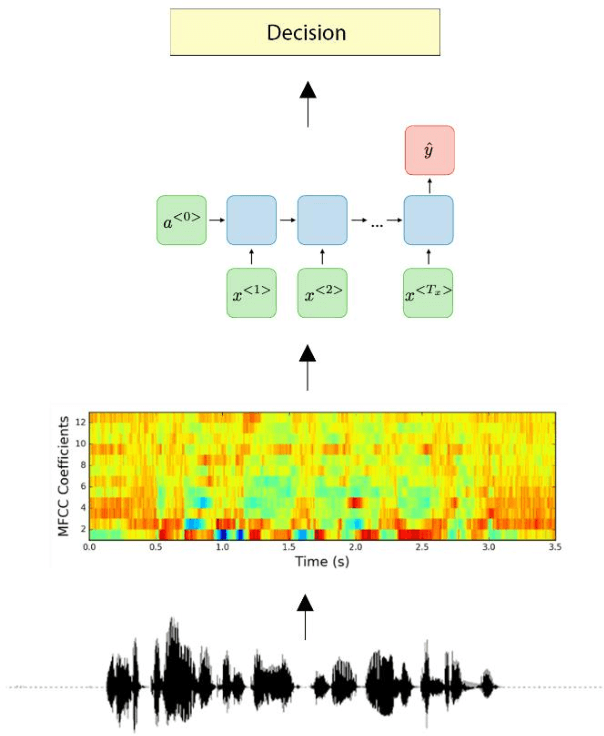

In Islam, readers must apply a set of pronunciation rules called Tajweed rules to recite the Quran in the same way that the angel Jibrael taught the Prophet, Muhammad. The traditional process of learning the correct application of these rules requires a human who must have a license and great experience to detect mispronunciation. Due to the increasing number of Muslims around the world, the number of Tajweed teachers is not enough nowadays for daily recitation practice for every Muslim. Therefore, lots of work has been done for automatic Tajweed rules' mispronunciation detection to help readers recite Quran correctly in an easier way and shorter time than traditional learning ways. All previous works have three common problems. First, most of them focused on machine learning algorithms only. Second, they used private datasets with no benchmark to compare with. Third, they did not take into consideration the sequence of input data optimally, although the speech signal is time series. To overcome these problems, we proposed a solution that consists of Mel-Frequency Cepstral Coefficient (MFCC) features with Long Short-Term Memory (LSTM) neural networks which use the time series, to detect mispronunciation in Tajweed rules. In addition, our experiments were performed on a public dataset, the QDAT dataset, which contains more than 1500 voices of the correct and incorrect recitation of three Tajweed rules (Separate stretching , Tight Noon , and Hide ). To the best of our knowledge, the QDAT dataset has not been used by any research paper yet. We compared the performance of the proposed LSTM model with traditional machine learning algorithms used in SoTA. The LSTM model with time series showed clear superiority over traditional machine learning. The accuracy achieved by LSTM on the QDAT dataset was 96%, 95%, and 96% for the three rules (Separate stretching, Tight Noon, and Hide), respectively.
GestureDiffuCLIP: Gesture Diffusion Model with CLIP Latents
Mar 26, 2023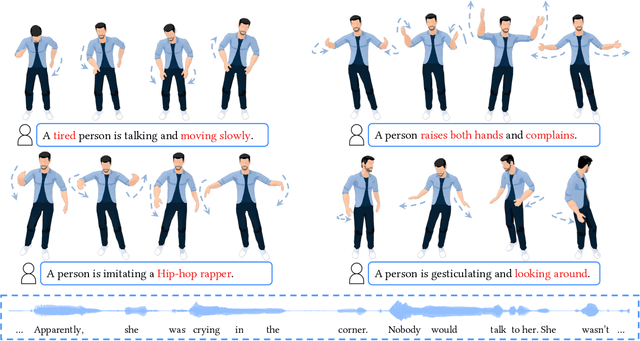
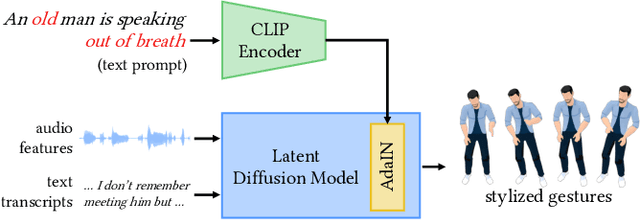


The automatic generation of stylized co-speech gestures has recently received increasing attention. Previous systems typically allow style control via predefined text labels or example motion clips, which are often not flexible enough to convey user intent accurately. In this work, we present GestureDiffuCLIP, a neural network framework for synthesizing realistic, stylized co-speech gestures with flexible style control. We leverage the power of the large-scale Contrastive-Language-Image-Pre-training (CLIP) model and present a novel CLIP-guided mechanism that extracts efficient style representations from multiple input modalities, such as a piece of text, an example motion clip, or a video. Our system learns a latent diffusion model to generate high-quality gestures and infuses the CLIP representations of style into the generator via an adaptive instance normalization (AdaIN) layer. We further devise a gesture-transcript alignment mechanism that ensures a semantically correct gesture generation based on contrastive learning. Our system can also be extended to allow fine-grained style control of individual body parts. We demonstrate an extensive set of examples showing the flexibility and generalizability of our model to a variety of style descriptions. In a user study, we show that our system outperforms the state-of-the-art approaches regarding human likeness, appropriateness, and style correctness.
Localizing Spatial Information in Neural Spatiospectral Filters
Mar 14, 2023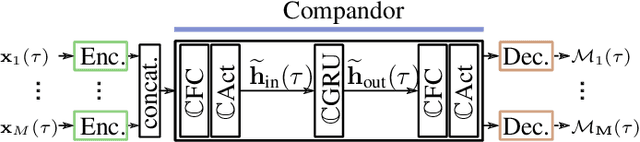
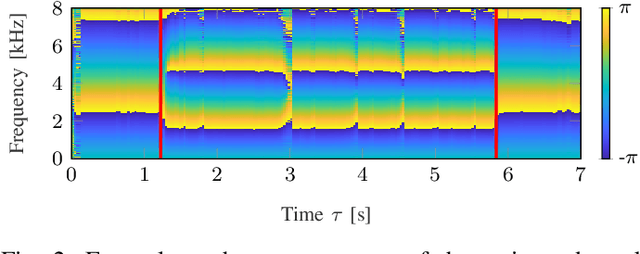
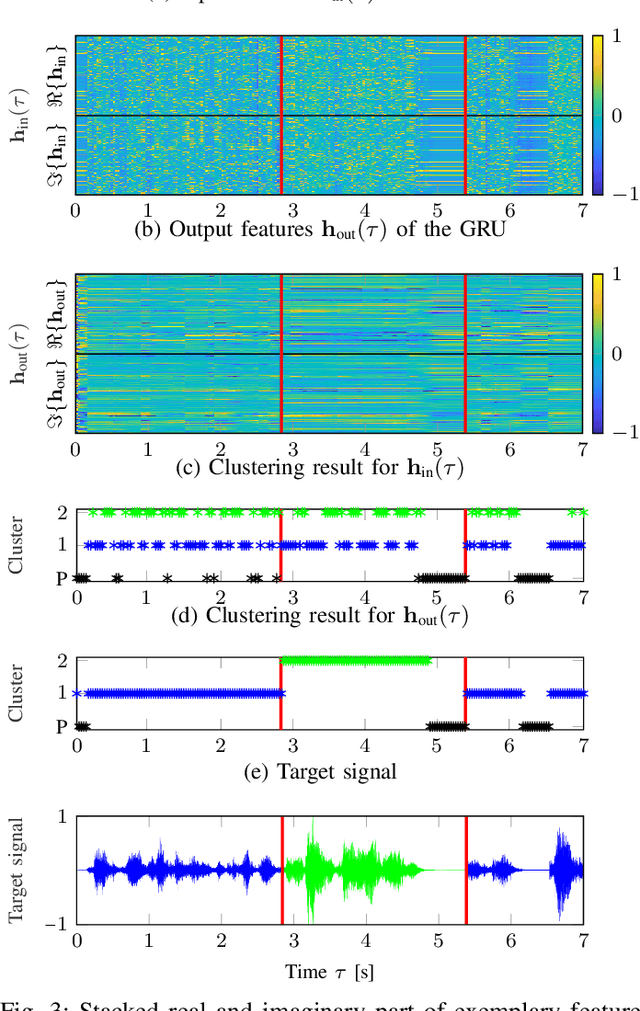
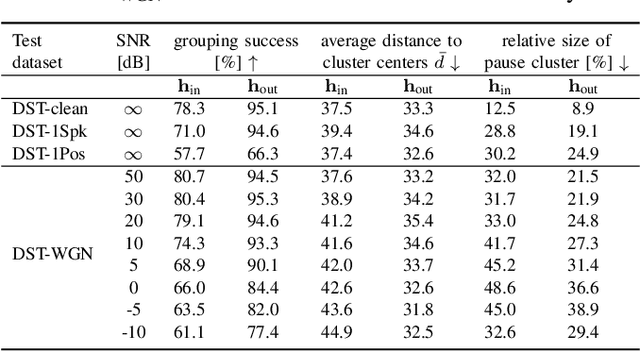
Beamforming for multichannel speech enhancement relies on the estimation of spatial characteristics of the acoustic scene. In its simplest form, the delay-and-sum beamformer (DSB) introduces a time delay to all channels to align the desired signal components for constructive superposition. Recent investigations of neural spatiospectral filtering revealed that these filters can be characterized by a beampattern similar to one of traditional beamformers, which shows that artificial neural networks can learn and explicitly represent spatial structure. Using the Complex-valued Spatial Autoencoder (COSPA) as an exemplary neural spatiospectral filter for multichannel speech enhancement, we investigate where and how such networks represent spatial information. We show via clustering that for COSPA the spatial information is represented by the features generated by a gated recurrent unit (GRU) layer that has access to all channels simultaneously and that these features are not source -- but only direction of arrival-dependent.
SumREN: Summarizing Reported Speech about Events in News
Dec 02, 2022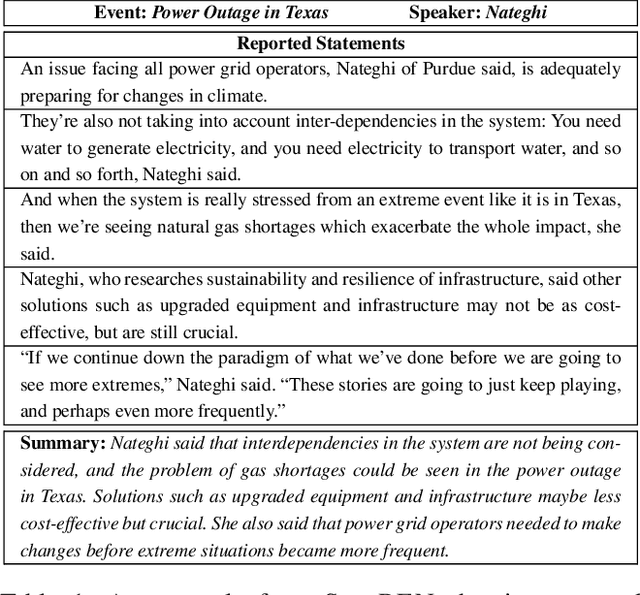
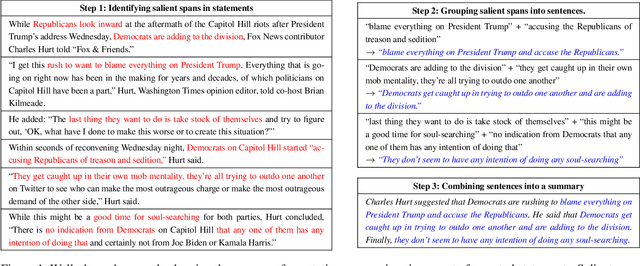
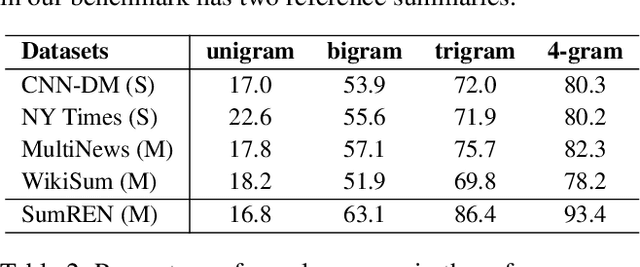

A primary objective of news articles is to establish the factual record for an event, frequently achieved by conveying both the details of the specified event (i.e., the 5 Ws; Who, What, Where, When and Why regarding the event) and how people reacted to it (i.e., reported statements). However, existing work on news summarization almost exclusively focuses on the event details. In this work, we propose the novel task of summarizing the reactions of different speakers, as expressed by their reported statements, to a given event. To this end, we create a new multi-document summarization benchmark, SUMREN, comprising 745 summaries of reported statements from various public figures obtained from 633 news articles discussing 132 events. We propose an automatic silver training data generation approach for our task, which helps smaller models like BART achieve GPT-3 level performance on this task. Finally, we introduce a pipeline-based framework for summarizing reported speech, which we empirically show to generate summaries that are more abstractive and factual than baseline query-focused summarization approaches.