 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
T5lephone: Bridging Speech and Text Self-supervised Models for Spoken Language Understanding via Phoneme level T5
Nov 01, 2022

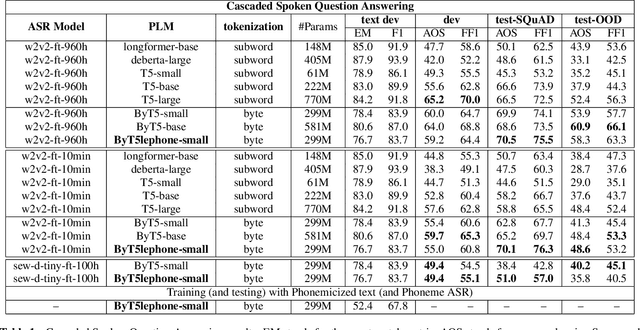
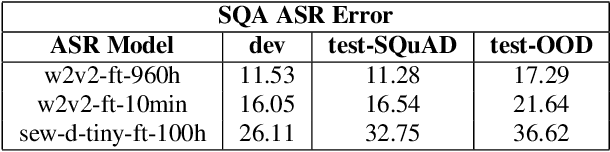

In Spoken language understanding (SLU), a natural solution is concatenating pre-trained speech models (e.g. HuBERT) and pretrained language models (PLM, e.g. T5). Most previous works use pretrained language models with subword-based tokenization. However, the granularity of input units affects the alignment of speech model outputs and language model inputs, and PLM with character-based tokenization is underexplored. In this work, we conduct extensive studies on how PLMs with different tokenization strategies affect spoken language understanding task including spoken question answering (SQA) and speech translation (ST). We further extend the idea to create T5lephone(pronounced as telephone), a variant of T5 that is pretrained using phonemicized text. We initialize T5lephone with existing PLMs to pretrain it using relatively lightweight computational resources. We reached state-of-the-art on NMSQA, and the T5lephone model exceeds T5 with other types of units on end-to-end SQA and ST.
An Automatic Speech Recognition System for Bengali Language based on Wav2Vec2 and Transfer Learning
Sep 20, 2022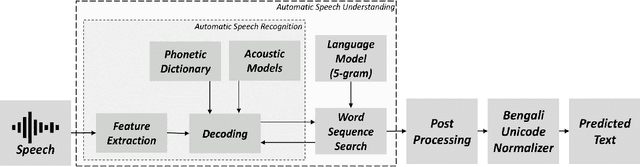
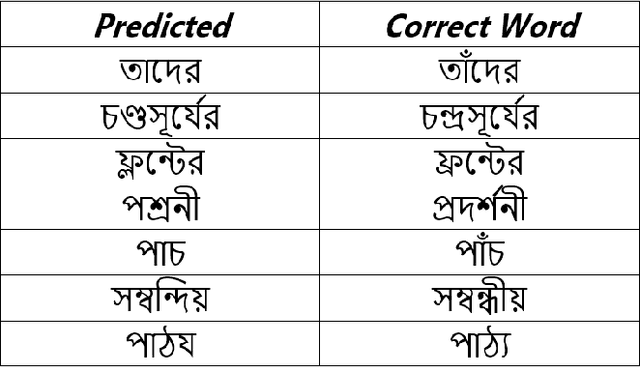
An independent, automated method of decoding and transcribing oral speech is known as automatic speech recognition (ASR). A typical ASR system extracts feature from audio recordings or streams and run one or more algorithms to map the features to corresponding texts. Numerous of research has been done in the field of speech signal processing in recent years. When given adequate resources, both conventional ASR and emerging end-to-end (E2E) speech recognition have produced promising results. However, for low-resource languages like Bengali, the current state of ASR lags behind, although the low resource state does not reflect upon the fact that this language is spoken by over 500 million people all over the world. Despite its popularity, there aren't many diverse open-source datasets available, which makes it difficult to conduct research on Bengali speech recognition systems. This paper is a part of the competition named `BUET CSE Fest DL Sprint'. The purpose of this paper is to improve the speech recognition performance of the Bengali language by adopting speech recognition technology on the E2E structure based on the transfer learning framework. The proposed method effectively models the Bengali language and achieves 3.819 score in `Levenshtein Mean Distance' on the test dataset of 7747 samples, when only 1000 samples of train dataset were used to train.
End-to-End Integration of Speech Recognition, Dereverberation, Beamforming, and Self-Supervised Learning Representation
Oct 19, 2022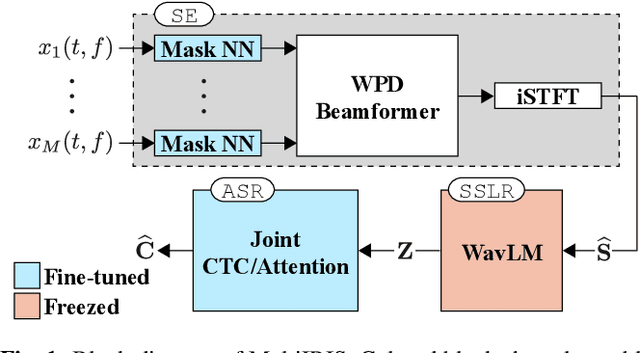
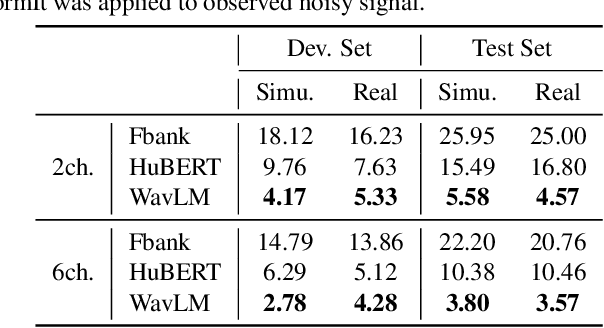
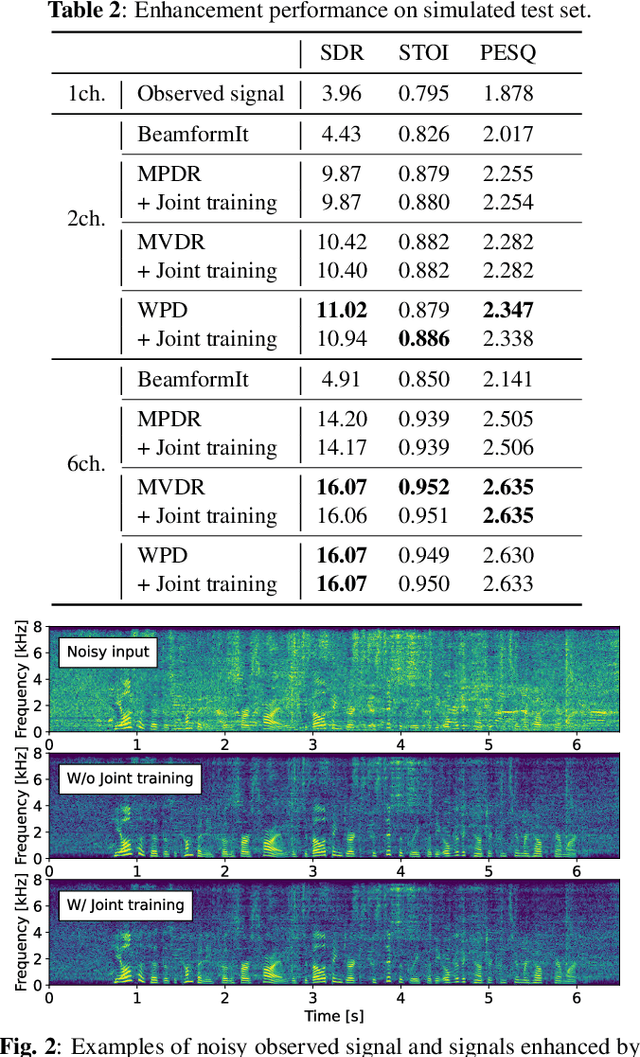
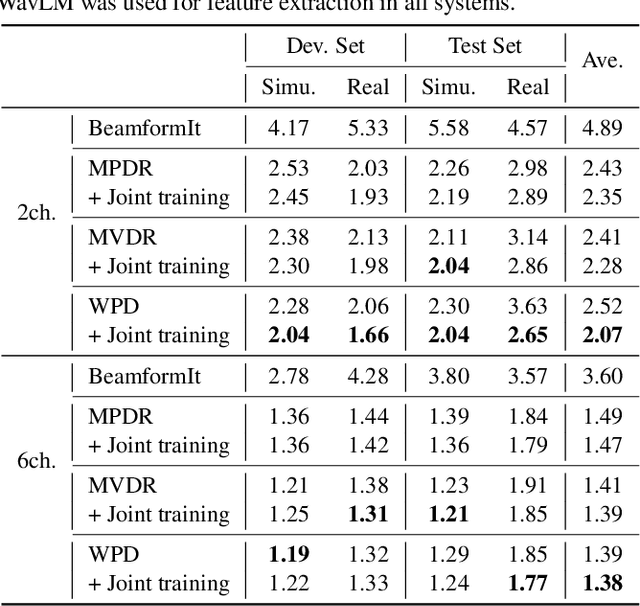
Self-supervised learning representation (SSLR) has demonstrated its significant effectiveness in automatic speech recognition (ASR), mainly with clean speech. Recent work pointed out the strength of integrating SSLR with single-channel speech enhancement for ASR in noisy environments. This paper further advances this integration by dealing with multi-channel input. We propose a novel end-to-end architecture by integrating dereverberation, beamforming, SSLR, and ASR within a single neural network. Our system achieves the best performance reported in the literature on the CHiME-4 6-channel track with a word error rate (WER) of 1.77%. While the WavLM-based strong SSLR demonstrates promising results by itself, the end-to-end integration with the weighted power minimization distortionless response beamformer, which simultaneously performs dereverberation and denoising, improves WER significantly. Its effectiveness is also validated on the REVERB dataset.
Align, Write, Re-order: Explainable End-to-End Speech Translation via Operation Sequence Generation
Nov 11, 2022
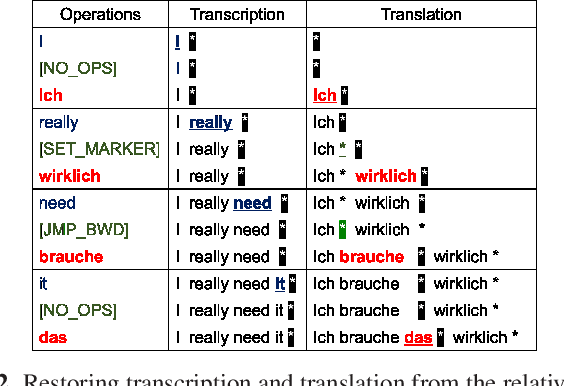
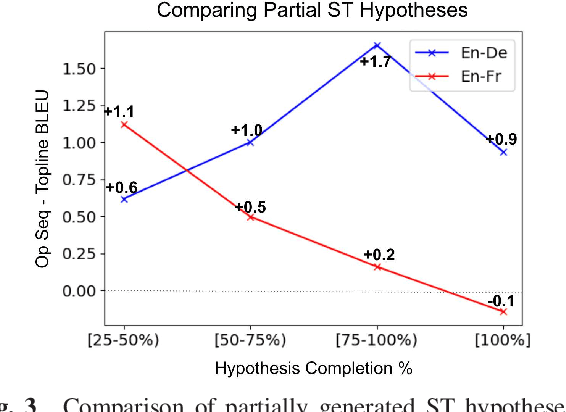
The black-box nature of end-to-end speech translation (E2E ST) systems makes it difficult to understand how source language inputs are being mapped to the target language. To solve this problem, we would like to simultaneously generate automatic speech recognition (ASR) and ST predictions such that each source language word is explicitly mapped to a target language word. A major challenge arises from the fact that translation is a non-monotonic sequence transduction task due to word ordering differences between languages -- this clashes with the monotonic nature of ASR. Therefore, we propose to generate ST tokens out-of-order while remembering how to re-order them later. We achieve this by predicting a sequence of tuples consisting of a source word, the corresponding target words, and post-editing operations dictating the correct insertion points for the target word. We examine two variants of such operation sequences which enable generation of monotonic transcriptions and non-monotonic translations from the same speech input simultaneously. We apply our approach to offline and real-time streaming models, demonstrating that we can provide explainable translations without sacrificing quality or latency. In fact, the delayed re-ordering ability of our approach improves performance during streaming. As an added benefit, our method performs ASR and ST simultaneously, making it faster than using two separate systems to perform these tasks.
Unified Speech-Text Pre-training for Speech Translation and Recognition
Apr 11, 2022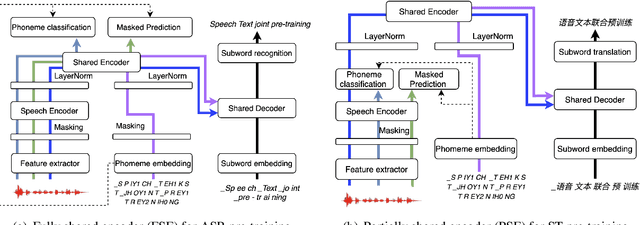

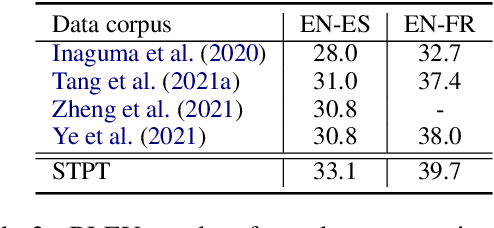
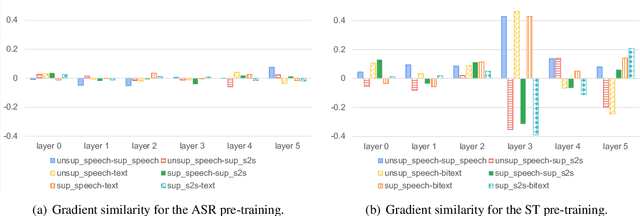
We describe a method to jointly pre-train speech and text in an encoder-decoder modeling framework for speech translation and recognition. The proposed method incorporates four self-supervised and supervised subtasks for cross modality learning. A self-supervised speech subtask leverages unlabelled speech data, and a (self-)supervised text to text subtask makes use of abundant text training data. Two auxiliary supervised speech tasks are included to unify speech and text modeling space. Our contribution lies in integrating linguistic information from the text corpus into the speech pre-training. Detailed analysis reveals learning interference among subtasks. Two pre-training configurations for speech translation and recognition, respectively, are presented to alleviate subtask interference. Our experiments show the proposed method can effectively fuse speech and text information into one model. It achieves between 1.7 and 2.3 BLEU improvement above the state of the art on the MuST-C speech translation dataset and comparable WERs to wav2vec 2.0 on the Librispeech speech recognition task.
Can Knowledge of End-to-End Text-to-Speech Models Improve Neural MIDI-to-Audio Synthesis Systems?
Nov 25, 2022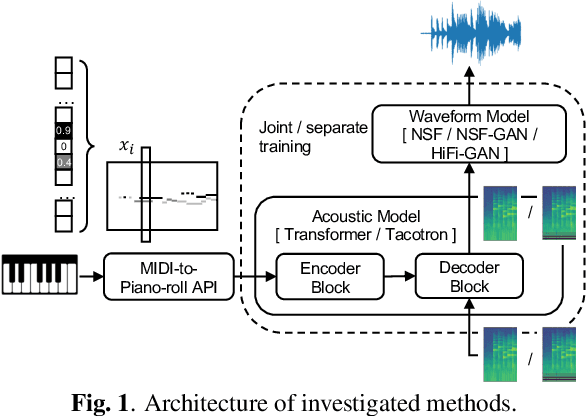
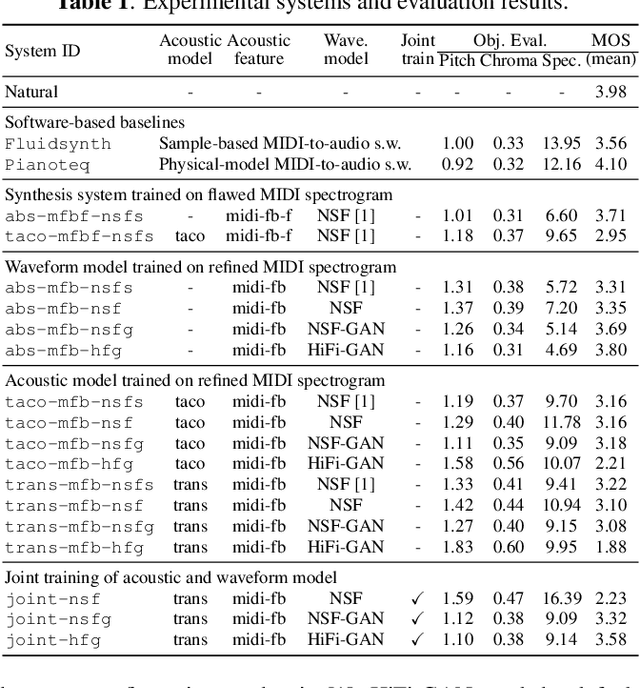
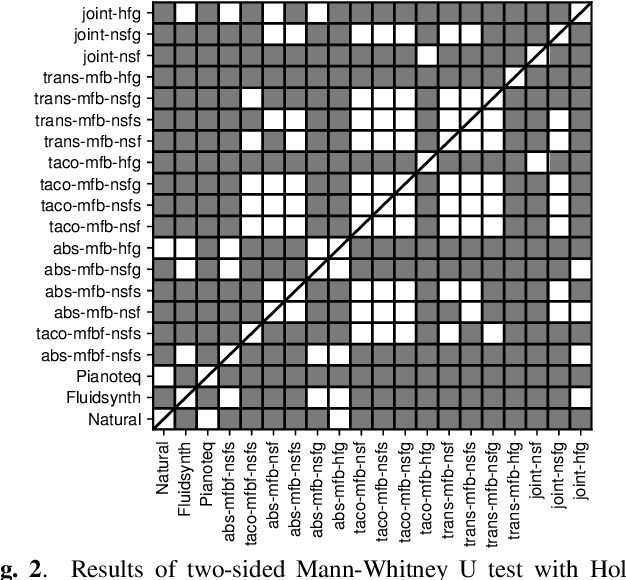
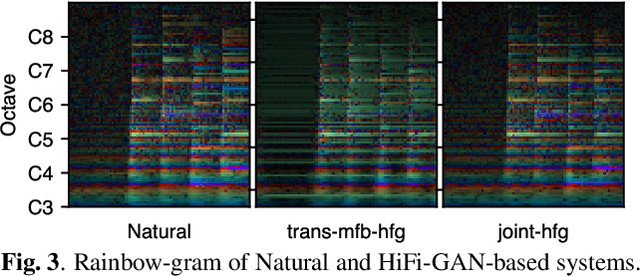
With the similarity between music and speech synthesis from symbolic input and the rapid development of text-to-speech (TTS) techniques, it is worthwhile to explore ways to improve the MIDI-to-audio performance by borrowing from TTS techniques. In this study, we analyze the shortcomings of a TTS-based MIDI-to-audio system and improve it in terms of feature computation, model selection, and training strategy, aiming to synthesize highly natural-sounding audio. Moreover, we conducted an extensive model evaluation through listening tests, pitch measurement, and spectrogram analysis. This work demonstrates not only synthesis of highly natural music but offers a thorough analytical approach and useful outcomes for the community. Our code and pre-trained models are open sourced at https://github.com/nii-yamagishilab/midi-to-audio.
Combating high variance in Data-Scarce Implicit Hate Speech Classification
Aug 29, 2022
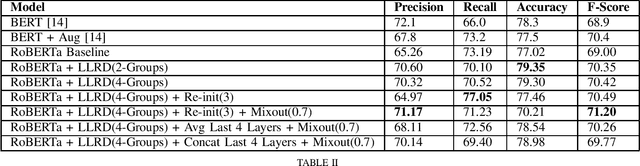
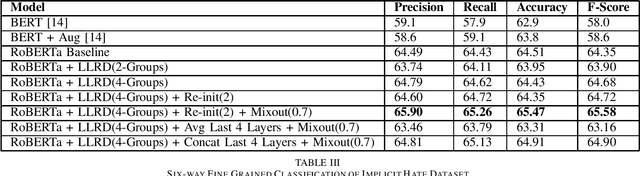
Hate speech classification has been a long-standing problem in natural language processing. However, even though there are numerous hate speech detection methods, they usually overlook a lot of hateful statements due to them being implicit in nature. Developing datasets to aid in the task of implicit hate speech classification comes with its own challenges; difficulties are nuances in language, varying definitions of what constitutes hate speech, and the labor-intensive process of annotating such data. This had led to a scarcity of data available to train and test such systems, which gives rise to high variance problems when parameter-heavy transformer-based models are used to address the problem. In this paper, we explore various optimization and regularization techniques and develop a novel RoBERTa-based model that achieves state-of-the-art performance.
Can Voice Assistants Sound Cute? Towards a Model of Kawaii Vocalics
Apr 22, 2023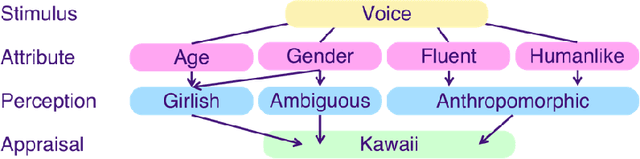
The Japanese notion of "kawaii" or expressions of cuteness, vulnerability, and/or charm is a global cultural export. Work has explored kawaii-ness as a design feature and factor of user experience in the visual appearance, nonverbal behaviour, and sound of robots and virtual characters. In this initial work, we consider whether voices can be kawaii by exploring the vocal qualities of voice assistant speech, i.e., kawaii vocalics. Drawing from an age-inclusive model of kawaii, we ran a user perceptions study on the kawaii-ness of younger- and older-sounding Japanese computer voices. We found that kawaii-ness intersected with perceptions of gender and age, i.e., gender ambiguous and girlish, as well as VA features, i.e., fluency and artificiality. We propose an initial model of kawaii vocalics to be validated through the identification and study of vocal qualities, cognitive appraisals, behavioural responses, and affective reports.
* 7 pages
"I'm" Lost in Translation: Pronoun Missteps in Crowdsourced Data Sets
Apr 22, 2023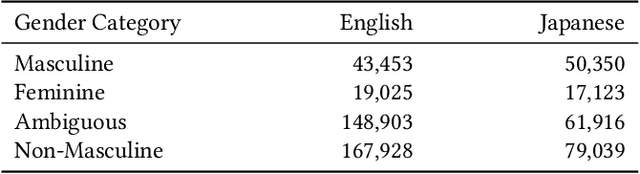

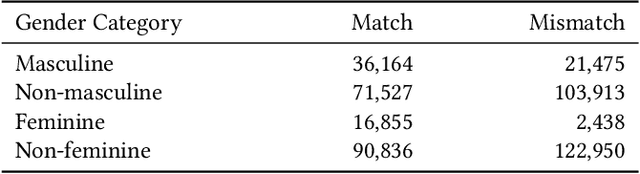
As virtual assistants continue to be taken up globally, there is an ever-greater need for these speech-based systems to communicate naturally in a variety of languages. Crowdsourcing initiatives have focused on multilingual translation of big, open data sets for use in natural language processing (NLP). Yet, language translation is often not one-to-one, and biases can trickle in. In this late-breaking work, we focus on the case of pronouns translated between English and Japanese in the crowdsourced Tatoeba database. We found that masculine pronoun biases were present overall, even though plurality in language was accounted for in other ways. Importantly, we detected biases in the translation process that reflect nuanced reactions to the presence of feminine, neutral, and/or non-binary pronouns. We raise the issue of translation bias for pronouns and offer a practical solution to embed plurality in NLP data sets.
* 6 pages
Streaming Audio-Visual Speech Recognition with Alignment Regularization
Nov 03, 2022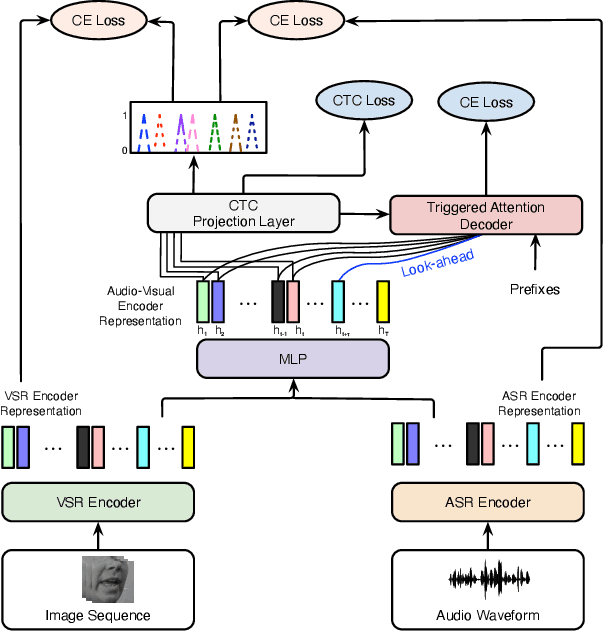
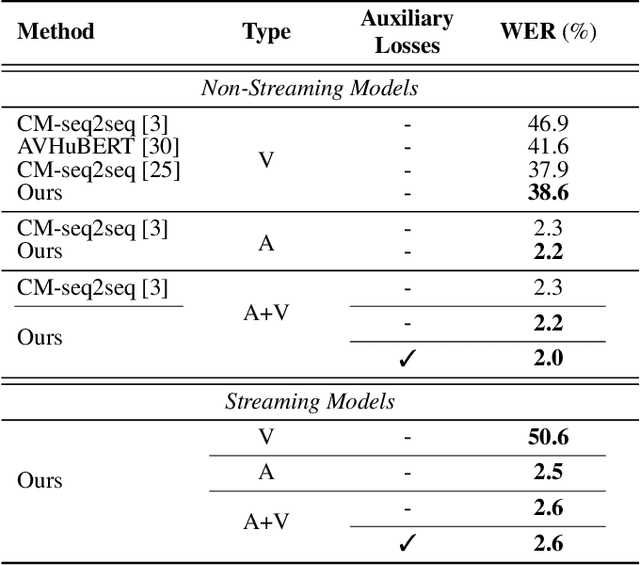
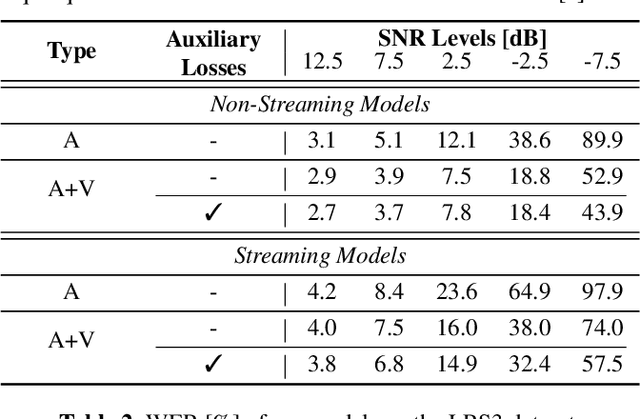
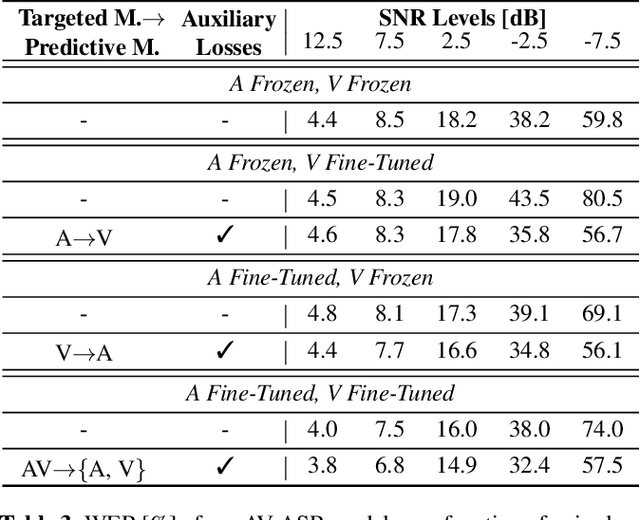
Recognizing a word shortly after it is spoken is an important requirement for automatic speech recognition (ASR) systems in real-world scenarios. As a result, a large body of work on streaming audio-only ASR models has been presented in the literature. However, streaming audio-visual automatic speech recognition (AV-ASR) has received little attention in earlier works. In this work, we propose a streaming AV-ASR system based on a hybrid connectionist temporal classification (CTC)/attention neural network architecture. The audio and the visual encoder neural networks are both based on the conformer architecture, which is made streamable using chunk-wise self-attention (CSA) and causal convolution. Streaming recognition with a decoder neural network is realized by using the triggered attention technique, which performs time-synchronous decoding with joint CTC/attention scoring. For frame-level ASR criteria, such as CTC, a synchronized response from the audio and visual encoders is critical for a joint AV decision making process. In this work, we propose a novel alignment regularization technique that promotes synchronization of the audio and visual encoder, which in turn results in better word error rates (WERs) at all SNR levels for streaming and offline AV-ASR models. The proposed AV-ASR model achieves WERs of 2.0% and 2.6% on the Lip Reading Sentences 3 (LRS3) dataset in an offline and online setup, respectively, which both present state-of-the-art results when no external training data are used.