 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Automated detection of pronunciation errors in non-native English speech employing deep learning
Sep 13, 2022
Despite significant advances in recent years, the existing Computer-Assisted Pronunciation Training (CAPT) methods detect pronunciation errors with a relatively low accuracy (precision of 60% at 40%-80% recall). This Ph.D. work proposes novel deep learning methods for detecting pronunciation errors in non-native (L2) English speech, outperforming the state-of-the-art method in AUC metric (Area under the Curve) by 41%, i.e., from 0.528 to 0.749. One of the problems with existing CAPT methods is the low availability of annotated mispronounced speech needed for reliable training of pronunciation error detection models. Therefore, the detection of pronunciation errors is reformulated to the task of generating synthetic mispronounced speech. Intuitively, if we could mimic mispronounced speech and produce any amount of training data, detecting pronunciation errors would be more effective. Furthermore, to eliminate the need to align canonical and recognized phonemes, a novel end-to-end multi-task technique to directly detect pronunciation errors was proposed. The pronunciation error detection models have been used at Amazon to automatically detect pronunciation errors in synthetic speech to accelerate the research into new speech synthesis methods. It was demonstrated that the proposed deep learning methods are applicable in the tasks of detecting and reconstructing dysarthric speech.
Multi-View Attention Transfer for Efficient Speech Enhancement
Aug 22, 2022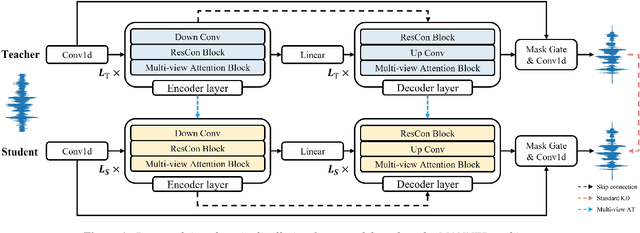
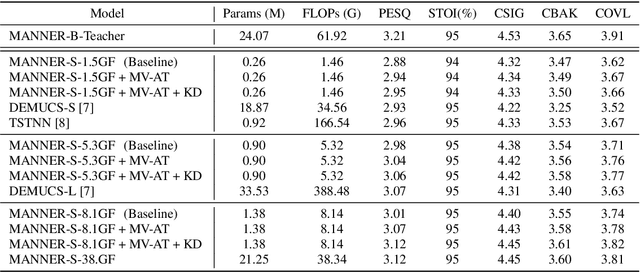
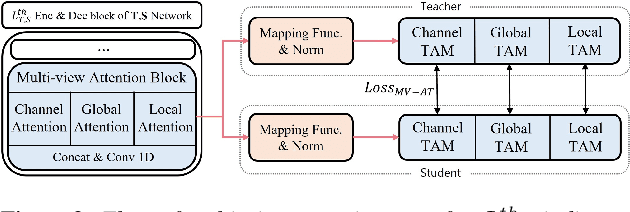
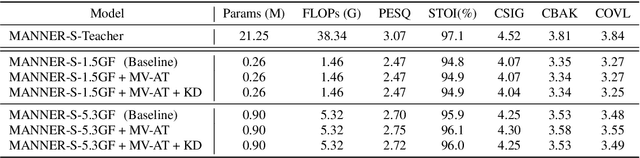
Recent deep learning models have achieved high performance in speech enhancement; however, it is still challenging to obtain a fast and low-complexity model without significant performance degradation. Previous knowledge distillation studies on speech enhancement could not solve this problem because their output distillation methods do not fit the speech enhancement task in some aspects. In this study, we propose multi-view attention transfer (MV-AT), a feature-based distillation, to obtain efficient speech enhancement models in the time domain. Based on the multi-view features extraction model, MV-AT transfers multi-view knowledge of the teacher network to the student network without additional parameters. The experimental results show that the proposed method consistently improved the performance of student models of various sizes on the Valentini and deep noise suppression (DNS) datasets. MANNER-S-8.1GF with our proposed method, a lightweight model for efficient deployment, achieved 15.4x and 4.71x fewer parameters and floating-point operations (FLOPs), respectively, compared to the baseline model with similar performance.
Application of Knowledge Distillation to Multi-task Speech Representation Learning
Oct 29, 2022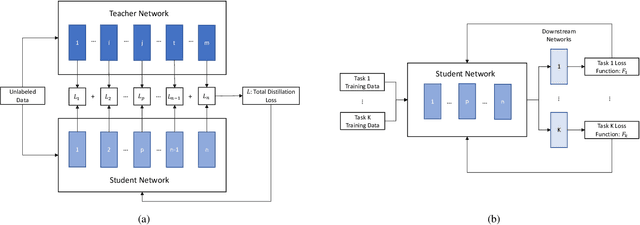
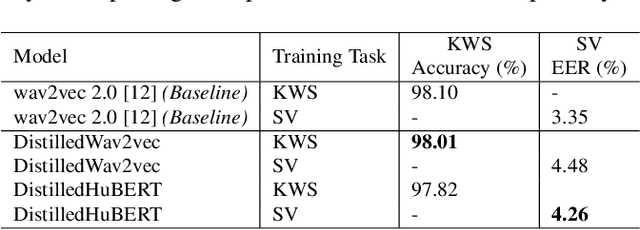
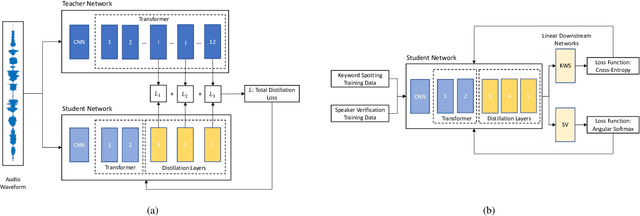
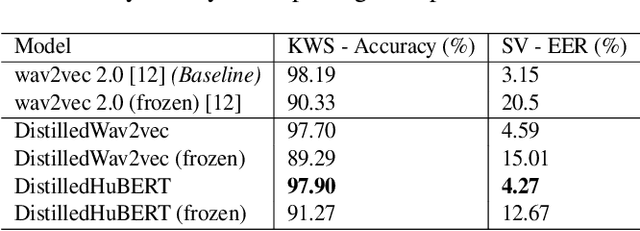
Model architectures such as wav2vec 2.0 and HuBERT have been proposed to learn speech representations from audio waveforms in a self-supervised manner. When these models are combined with downstream tasks such as speech recognition, they have been shown to provide state-of-the-art performance. However, these models use a large number of parameters, the smallest version of which has about 95 million parameters. This constitutes a challenge for edge AI device deployments. In this paper, we use knowledge distillation to reduce the original model size by about 75% while maintaining similar performance levels. Moreover, we use wav2vec 2.0 and HuBERT models for distillation and present a comprehensive performance analysis through our experiments where we fine-tune the distilled models on single task and multi-task frameworks separately. In particular, our experiments show that fine-tuning the distilled models on keyword spotting and speaker verification tasks result in only 0.1% accuracy and 0.9% equal error rate degradations, respectively.
Leveraging Pseudo-labeled Data to Improve Direct Speech-to-Speech Translation
May 18, 2022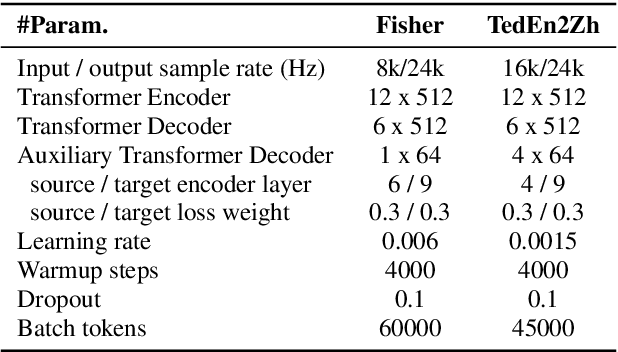
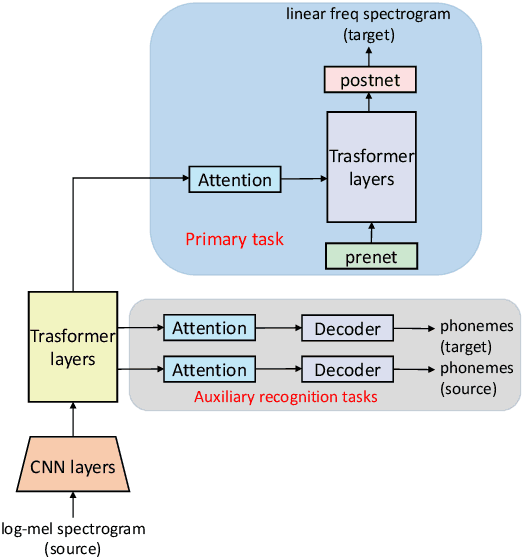
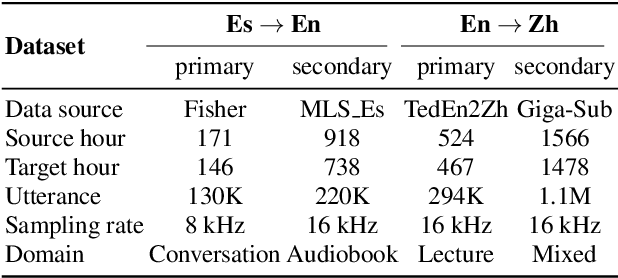
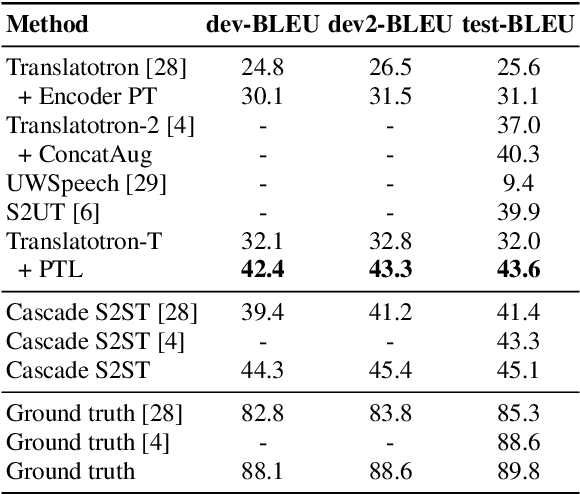
Direct Speech-to-speech translation (S2ST) has drawn more and more attention recently. The task is very challenging due to data scarcity and complex speech-to-speech mapping. In this paper, we report our recent achievements in S2ST. Firstly, we build a S2ST Transformer baseline which outperforms the original Translatotron. Secondly, we utilize the external data by pseudo-labeling and obtain a new state-of-the-art result on the Fisher English-to-Spanish test set. Indeed, we exploit the pseudo data with a combination of popular techniques which are not trivial when applied to S2ST. Moreover, we evaluate our approach on both syntactically similar (Spanish-English) and distant (English-Chinese) language pairs. Our implementation is available at https://github.com/fengpeng-yue/speech-to-speech-translation.
Adversarial Privacy Protection on Speech Enhancement
Jun 16, 2022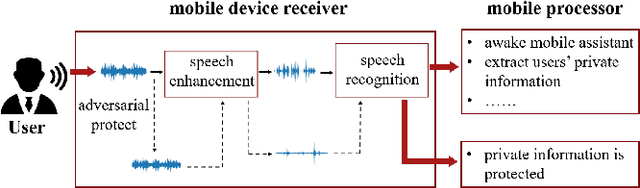

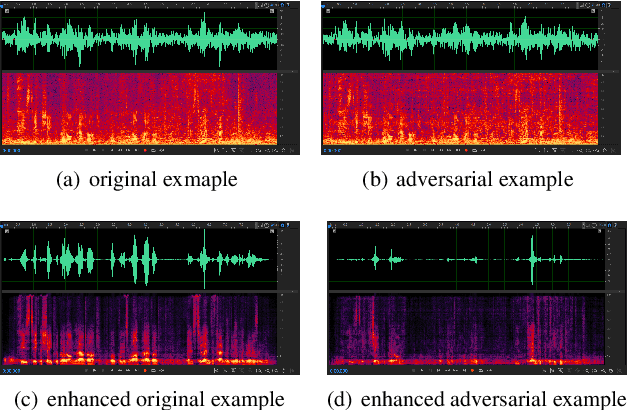

Speech is easily leaked imperceptibly, such as being recorded by mobile phones in different situations. Private content in speech may be maliciously extracted through speech enhancement technology. Speech enhancement technology has developed rapidly along with deep neural networks (DNNs), but adversarial examples can cause DNNs to fail. In this work, we propose an adversarial method to degrade speech enhancement systems. Experimental results show that generated adversarial examples can erase most content information in original examples or replace it with target speech content through speech enhancement. The word error rate (WER) between an enhanced original example and enhanced adversarial example recognition result can reach 89.0%. WER of target attack between enhanced adversarial example and target example is low to 33.75% . Adversarial perturbation can bring the rate of change to the original example to more than 1.4430. This work can prevent the malicious extraction of speech.
DDKtor: Automatic Diadochokinetic Speech Analysis
Jun 29, 2022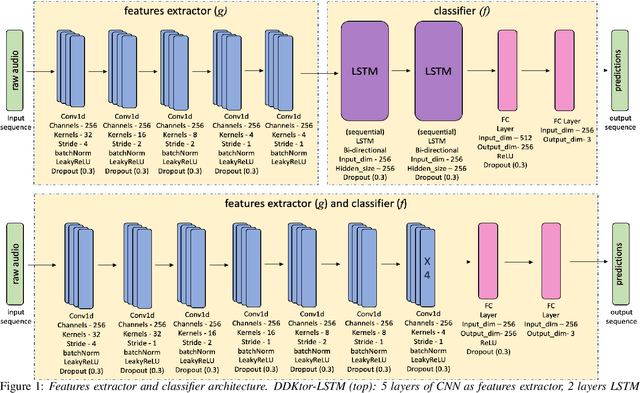
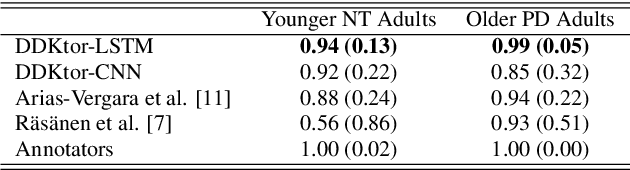
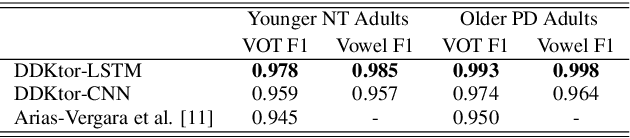
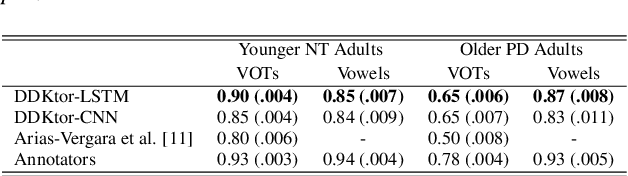
Diadochokinetic speech tasks (DDK), in which participants repeatedly produce syllables, are commonly used as part of the assessment of speech motor impairments. These studies rely on manual analyses that are time-intensive, subjective, and provide only a coarse-grained picture of speech. This paper presents two deep neural network models that automatically segment consonants and vowels from unannotated, untranscribed speech. Both models work on the raw waveform and use convolutional layers for feature extraction. The first model is based on an LSTM classifier followed by fully connected layers, while the second model adds more convolutional layers followed by fully connected layers. These segmentations predicted by the models are used to obtain measures of speech rate and sound duration. Results on a young healthy individuals dataset show that our LSTM model outperforms the current state-of-the-art systems and performs comparably to trained human annotators. Moreover, the LSTM model also presents comparable results to trained human annotators when evaluated on unseen older individuals with Parkinson's Disease dataset.
OLISIA: a Cascade System for Spoken Dialogue State Tracking
Apr 20, 2023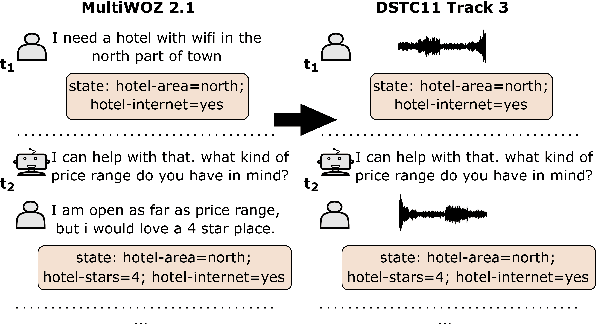
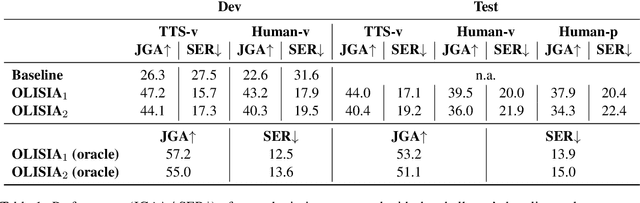
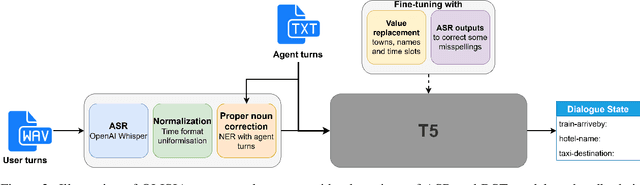
Though Dialogue State Tracking (DST) is a core component of spoken dialogue systems, recent work on this task mostly deals with chat corpora, disregarding the discrepancies between spoken and written language.In this paper, we propose OLISIA, a cascade system which integrates an Automatic Speech Recognition (ASR) model and a DST model. We introduce several adaptations in the ASR and DST modules to improve integration and robustness to spoken conversations.With these adaptations, our system ranked first in DSTC11 Track 3, a benchmark to evaluate spoken DST. We conduct an in-depth analysis of the results and find that normalizing the ASR outputs and adapting the DST inputs through data augmentation, along with increasing the pre-trained models size all play an important role in reducing the performance discrepancy between written and spoken conversations.
From Audio to Symbolic Encoding
Feb 26, 2023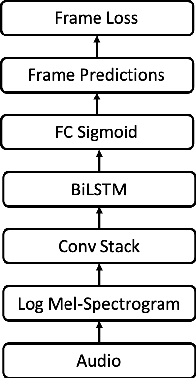
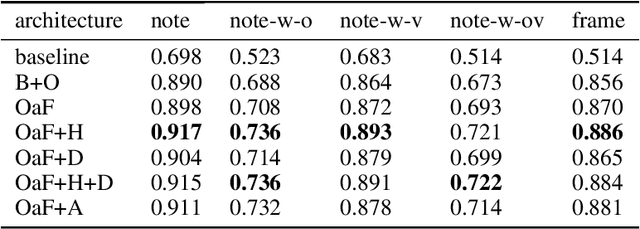
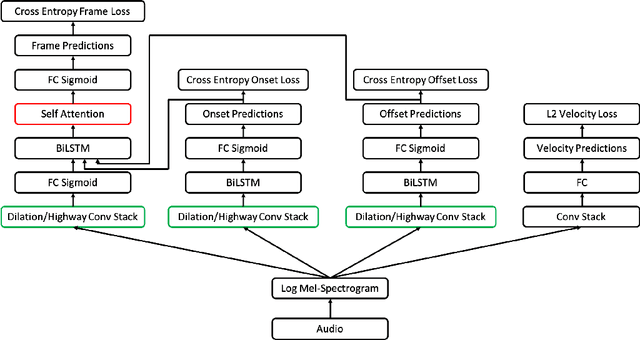
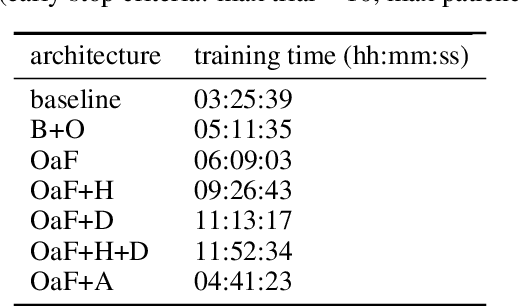
Automatic music transcription (AMT) aims to convert raw audio to symbolic music representation. As a fundamental problem of music information retrieval (MIR), AMT is considered a difficult task even for trained human experts due to overlap of multiple harmonics in the acoustic signal. On the other hand, speech recognition, as one of the most popular tasks in natural language processing, aims to translate human spoken language to texts. Based on the similar nature of AMT and speech recognition (as they both deal with tasks of translating audio signal to symbolic encoding), this paper investigated whether a generic neural network architecture could possibly work on both tasks. In this paper, we introduced our new neural network architecture built on top of the current state-of-the-art Onsets and Frames, and compared the performances of its multiple variations on AMT task. We also tested our architecture with the task of speech recognition. For AMT, our models were able to produce better results compared to the model trained using the state-of-art architecture; however, although similar architecture was able to be trained on the speech recognition task, it did not generate very ideal result compared to other task-specific models.
Two-Stream Joint-Training for Speaker Independent Acoustic-to-Articulatory Inversion
Feb 26, 2023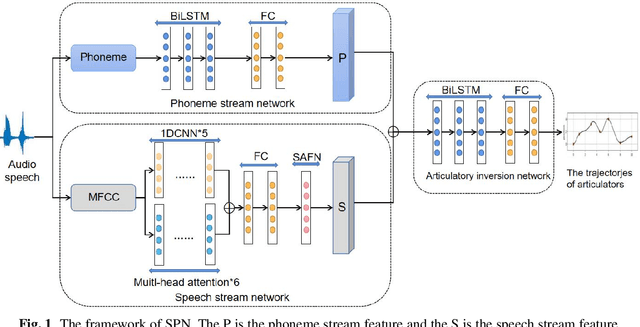
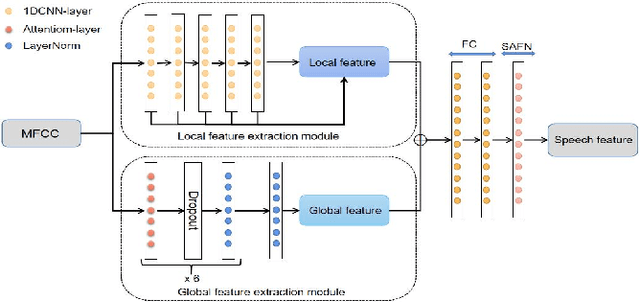
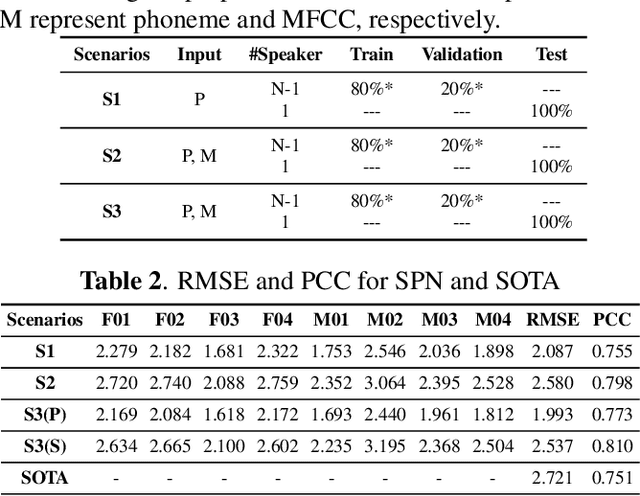
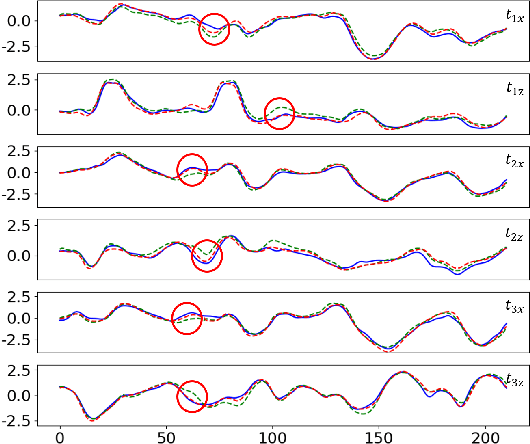
Acoustic-to-articulatory inversion (AAI) aims to estimate the parameters of articulators from speech audio. There are two common challenges in AAI, which are the limited data and the unsatisfactory performance in speaker independent scenario. Most current works focus on extracting features directly from speech and ignoring the importance of phoneme information which may limit the performance of AAI. To this end, we propose a novel network called SPN that uses two different streams to carry out the AAI task. Firstly, to improve the performance of speaker-independent experiment, we propose a new phoneme stream network to estimate the articulatory parameters as the phoneme features. To the best of our knowledge, this is the first work that extracts the speaker-independent features from phonemes to improve the performance of AAI. Secondly, in order to better represent the speech information, we train a speech stream network to combine the local features and the global features. Compared with state-of-the-art (SOTA), the proposed method reduces 0.18mm on RMSE and increases 6.0% on Pearson correlation coefficient in the speaker-independent experiment. The code has been released at https://github.com/liujinyu123/AAINetwork-SPN.
Ultra-Low-Bitrate Speech Coding with Pretrained Transformers
Jul 05, 2022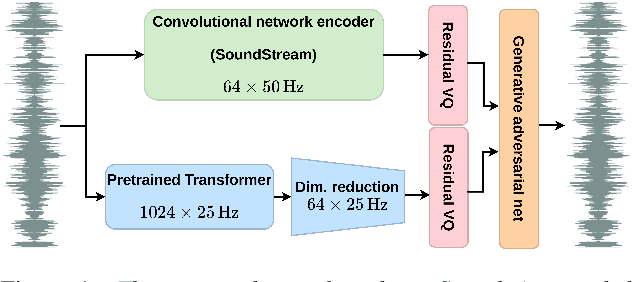
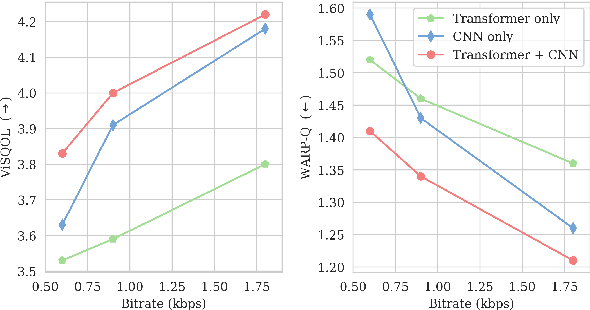
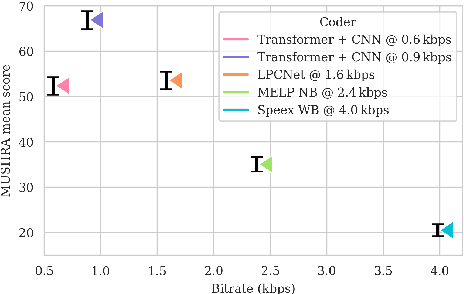
Speech coding facilitates the transmission of speech over low-bandwidth networks with minimal distortion. Neural-network based speech codecs have recently demonstrated significant improvements in quality over traditional approaches. While this new generation of codecs is capable of synthesizing high-fidelity speech, their use of recurrent or convolutional layers often restricts their effective receptive fields, which prevents them from compressing speech efficiently. We propose to further reduce the bitrate of neural speech codecs through the use of pretrained Transformers, capable of exploiting long-range dependencies in the input signal due to their inductive bias. As such, we use a pretrained Transformer in tandem with a convolutional encoder, which is trained end-to-end with a quantizer and a generative adversarial net decoder. Our numerical experiments show that supplementing the convolutional encoder of a neural speech codec with Transformer speech embeddings yields a speech codec with a bitrate of $600\,\mathrm{bps}$ that outperforms the original neural speech codec in synthesized speech quality when trained at the same bitrate. Subjective human evaluations suggest that the quality of the resulting codec is comparable or better than that of conventional codecs operating at three to four times the rate.