 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Neural inhibition during speech planning contributes to contrastive hyperarticulation
Sep 25, 2022
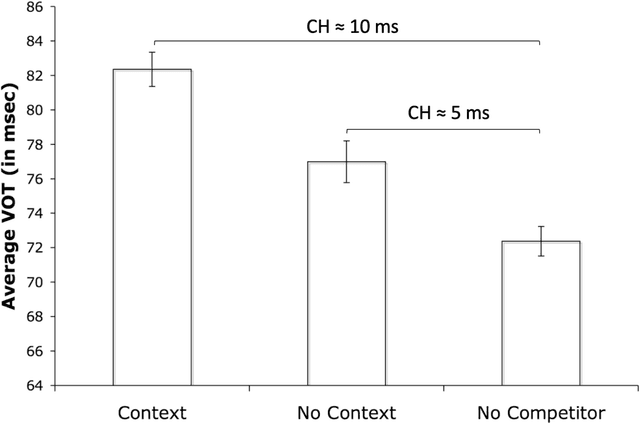
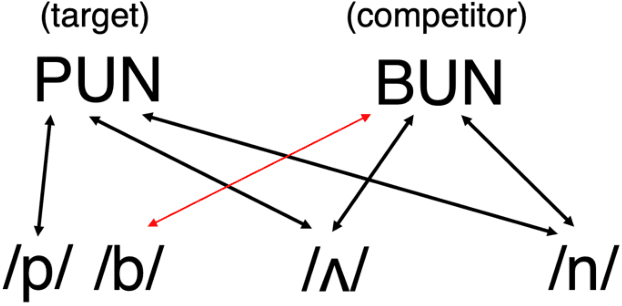
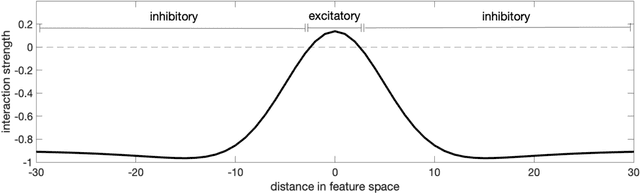
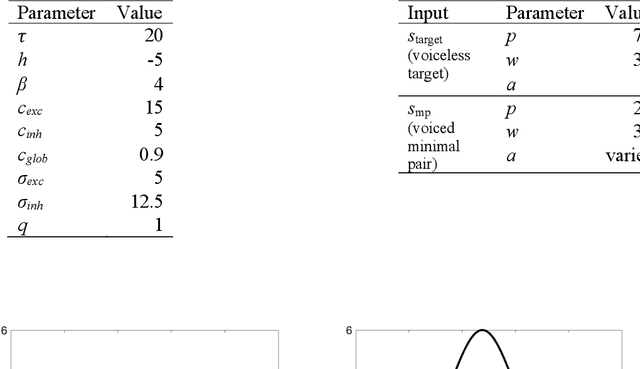
Previous work has demonstrated that words are hyperarticulated on dimensions of speech that differentiate them from a minimal pair competitor. This phenomenon has been termed contrastive hyperarticulation (CH). We present a dynamic neural field (DNF) model of voice onset time (VOT) planning that derives CH from an inhibitory influence of the minimal pair competitor during planning. We test some predictions of the model with a novel experiment investigating CH of voiceless stop consonant VOT in pseudowords. The results demonstrate a CH effect in pseudowords, consistent with a basis for the effect in the real-time planning and production of speech. The scope and magnitude of CH in pseudowords was reduced compared to CH in real words, consistent with a role for interactive activation between lexical and phonological levels of planning. We discuss the potential of our model to unify an apparently disparate set of phenomena, from CH to phonological neighborhood effects to phonetic trace effects in speech errors.
MetaSpeech: Speech Effects Switch Along with Environment for Metaverse
Oct 25, 2022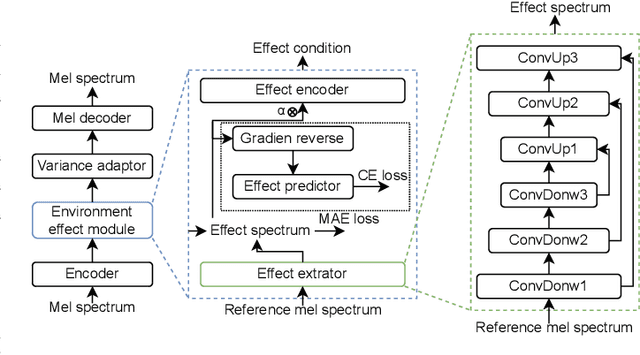
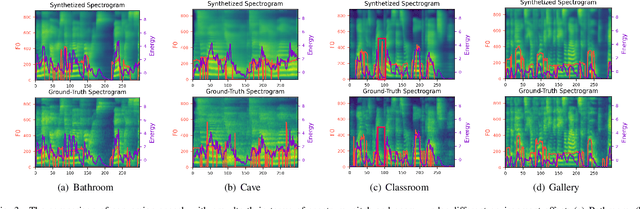
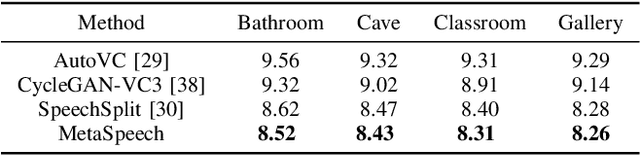
Metaverse expands the physical world to a new dimension, and the physical environment and Metaverse environment can be directly connected and entered. Voice is an indispensable communication medium in the real world and Metaverse. Fusion of the voice with environment effects is important for user immersion in Metaverse. In this paper, we proposed using the voice conversion based method for the conversion of target environment effect speech. The proposed method was named MetaSpeech, which introduces an environment effect module containing an effect extractor to extract the environment information and an effect encoder to encode the environment effect condition, in which gradient reversal layer was used for adversarial training to keep the speech content and speaker information while disentangling the environmental effects. From the experiment results on the public dataset of LJSpeech with four environment effects, the proposed model could complete the specific environment effect conversion and outperforms the baseline methods from the voice conversion task.
SQuId: Measuring Speech Naturalness in Many Languages
Oct 12, 2022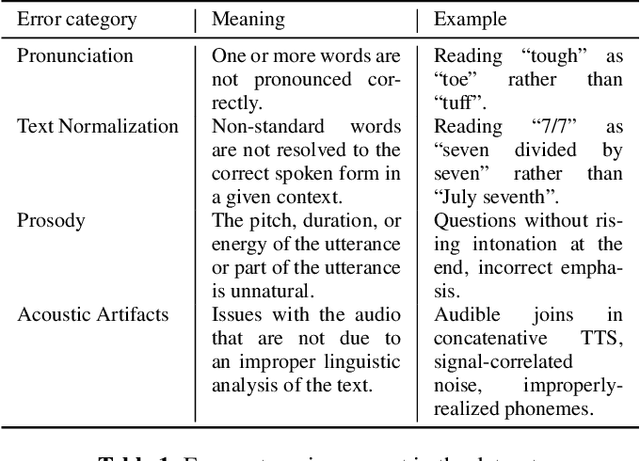
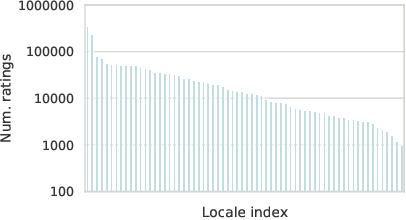

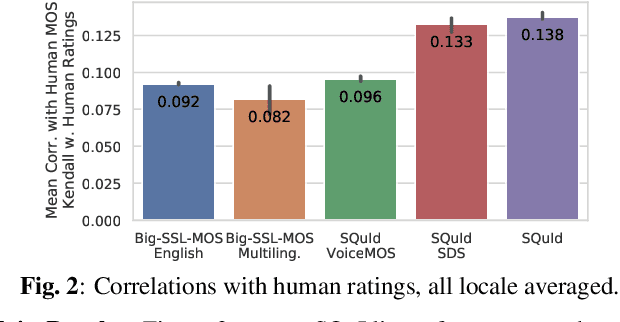
Much of text-to-speech research relies on human evaluation, which incurs heavy costs and slows down the development process. The problem is particularly acute in heavily multilingual applications, where recruiting and polling judges can take weeks. We introduce SQuId (Speech Quality Identification), a multilingual naturalness prediction model trained on over a million ratings and tested in 65 locales-the largest effort of this type to date. The main insight is that training one model on many locales consistently outperforms mono-locale baselines. We present our task, the model, and show that it outperforms a competitive baseline based on w2v-BERT and VoiceMOS by 50.0%. We then demonstrate the effectiveness of cross-locale transfer during fine-tuning and highlight its effect on zero-shot locales, i.e., locales for which there is no fine-tuning data. Through a series of analyses, we highlight the role of non-linguistic effects such as sound artifacts in cross-locale transfer. Finally, we present the effect of our design decision, e.g., model size, pre-training diversity, and language rebalancing with several ablation experiments.
ZeroEGGS: Zero-shot Example-based Gesture Generation from Speech
Sep 23, 2022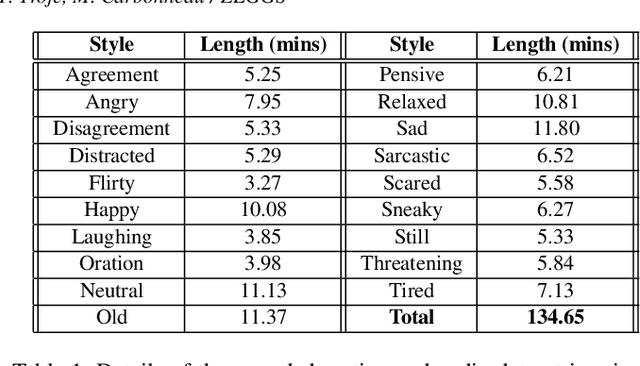
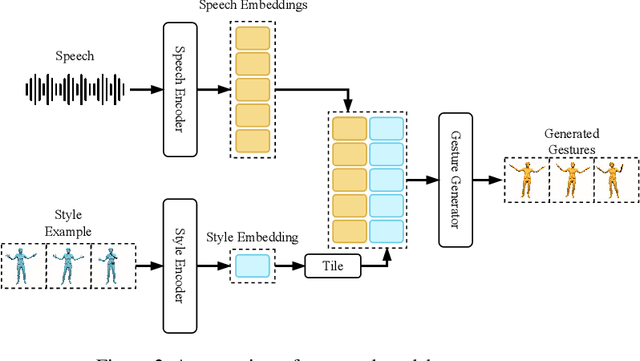

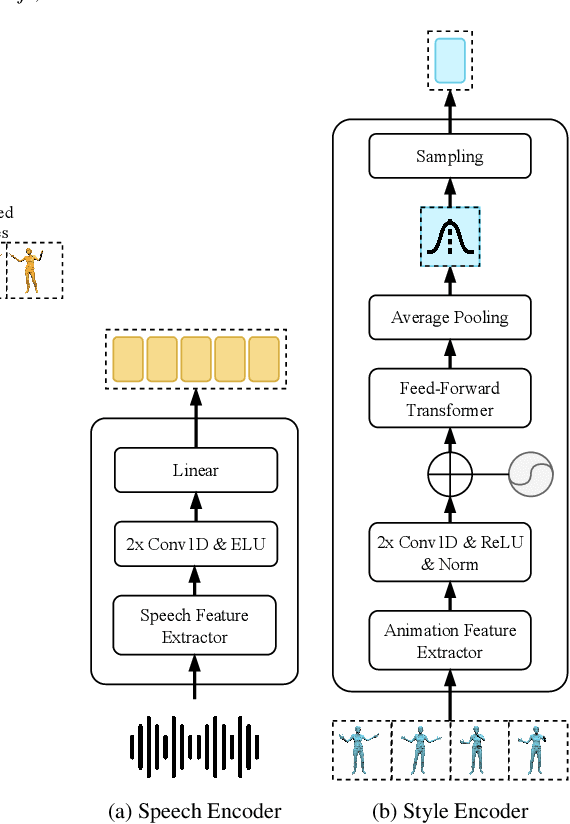
We present ZeroEGGS, a neural network framework for speech-driven gesture generation with zero-shot style control by example. This means style can be controlled via only a short example motion clip, even for motion styles unseen during training. Our model uses a Variational framework to learn a style embedding, making it easy to modify style through latent space manipulation or blending and scaling of style embeddings. The probabilistic nature of our framework further enables the generation of a variety of outputs given the same input, addressing the stochastic nature of gesture motion. In a series of experiments, we first demonstrate the flexibility and generalizability of our model to new speakers and styles. In a user study, we then show that our model outperforms previous state-of-the-art techniques in naturalness of motion, appropriateness for speech, and style portrayal. Finally, we release a high-quality dataset of full-body gesture motion including fingers, with speech, spanning across 19 different styles.
Predictive Neural Speech Coding
Jul 18, 2022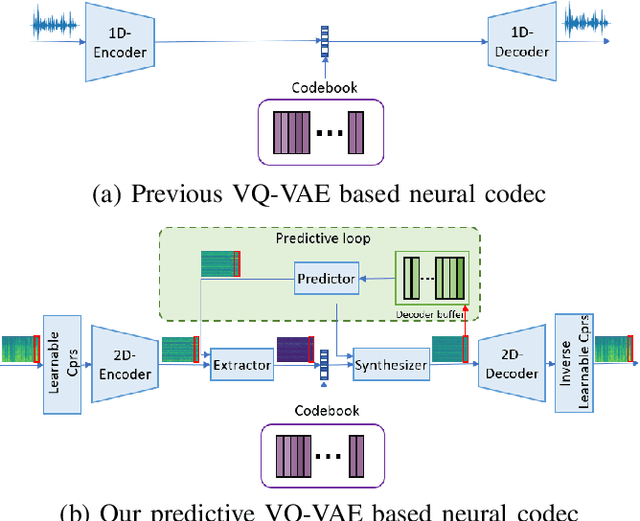
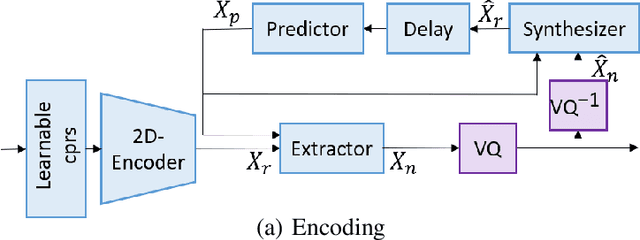
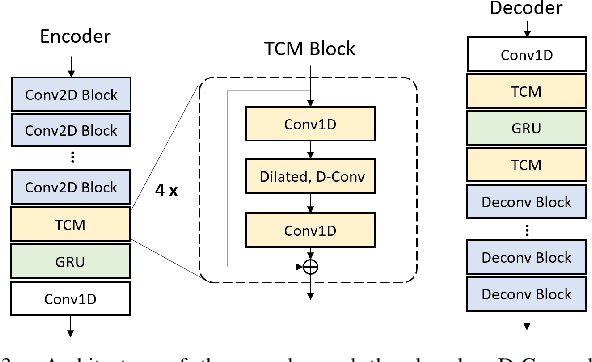
Neural audio/speech coding has shown its capability to deliver a high quality at much lower bitrates than traditional methods recently. However, existing neural audio/speech codecs employ either acoustic features or learned blind features with a convolutional neural network for encoding, by which there are still temporal redundancies inside encoded features. This paper introduces latent-domain predictive coding into the VQ-VAE framework to fully remove such redundancies and proposes the TF-Codec for low-latency neural speech coding in an end-to-end way. Specifically, the extracted features are encoded conditioned on a prediction from past quantized latent frames so that temporal correlations are further removed. What's more, we introduce a learnable compression on the time-frequency input to adaptively adjust the attention paid on main frequencies and details at different bitrates. A differentiable vector quantization scheme based on distance-to-soft mapping and Gumbel-Softmax is proposed to better model the latent distributions with rate constraint. Subjective results on multilingual speech datasets show that with a latency of 40ms, the proposed TF-Codec at 1kbps can achieve a much better quality than Opus 9kbps and TF-Codec at 3kbps outperforms both EVS 9.6kbps and Opus 12kbps. Numerous studies are conducted to show the effectiveness of these techniques.
The 2022 NIST Language Recognition Evaluation
Feb 28, 2023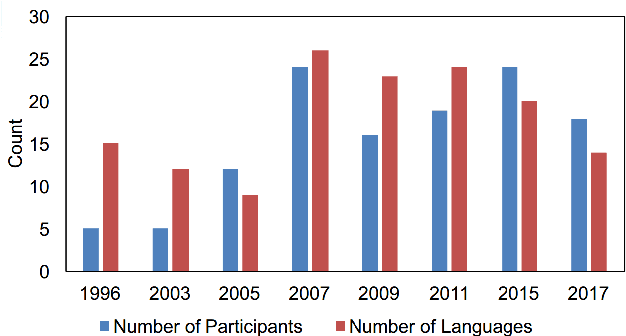
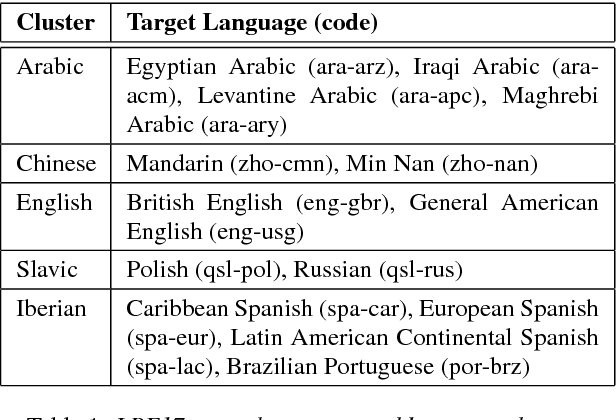
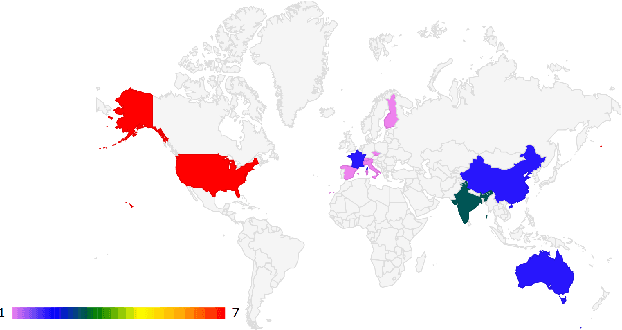
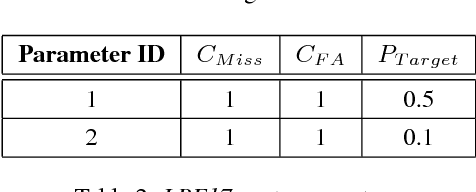
In 2022, the U.S. National Institute of Standards and Technology (NIST) conducted the latest Language Recognition Evaluation (LRE) in an ongoing series administered by NIST since 1996 to foster research in language recognition and to measure state-of-the-art technology. Similar to previous LREs, LRE22 focused on conversational telephone speech (CTS) and broadcast narrowband speech (BNBS) data. LRE22 also introduced new evaluation features, such as an emphasis on African languages, including low resource languages, and a test set consisting of segments containing between 3s and 35s of speech randomly sampled and extracted from longer recordings. A total of 21 research organizations, forming 16 teams, participated in this 3-month long evaluation and made a total of 65 valid system submissions to be evaluated. This paper presents an overview of LRE22 and an analysis of system performance over different evaluation conditions. The evaluation results suggest that Oromo and Tigrinya are easier to detect while Xhosa and Zulu are more challenging. A greater confusability is seen for some language pairs. When speech duration increased, system performance significantly increased up to a certain duration, and then a diminishing return on system performance is observed afterward.
Applying wav2vec2 for Speech Recognition on Bengali Common Voices Dataset
Sep 11, 2022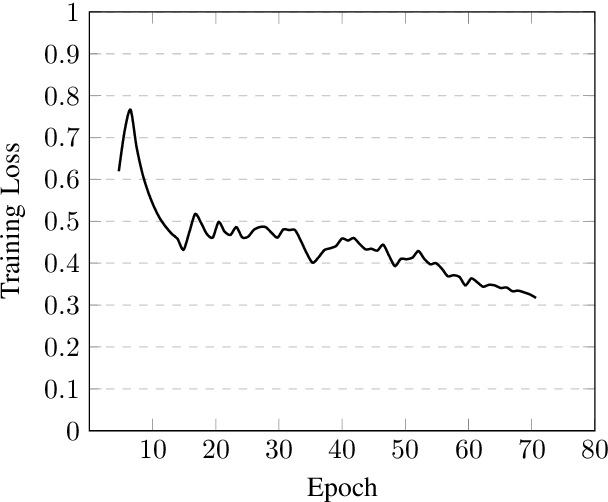
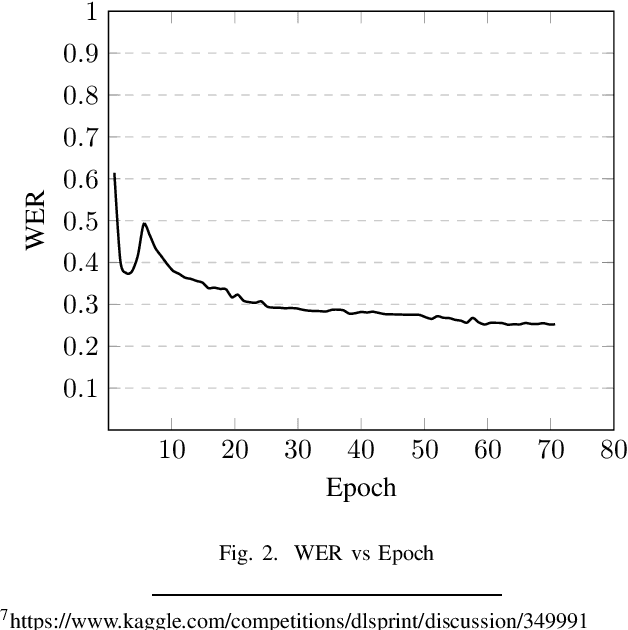

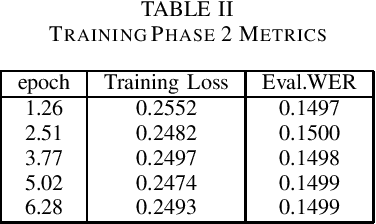
Speech is inherently continuous, where discrete words, phonemes and other units are not clearly segmented, and so speech recognition has been an active research problem for decades. In this work we have fine-tuned wav2vec 2.0 to recognize and transcribe Bengali speech -- training it on the Bengali Common Voice Speech Dataset. After training for 71 epochs, on a training set consisting of 36919 mp3 files, we achieved a training loss of 0.3172 and WER of 0.2524 on a validation set of size 7,747. Using a 5-gram language model, the Levenshtein Distance was 2.6446 on a test set of size 7,747. Then the training set and validation set were combined, shuffled and split into 85-15 ratio. Training for 7 more epochs on this combined dataset yielded an improved Levenshtein Distance of 2.60753 on the test set. Our model was the best performing one, achieving a Levenshtein Distance of 6.234 on a hidden dataset, which was 1.1049 units lower than other competing submissions.
A Planning-Based Explainable Collaborative Dialogue System
Mar 02, 2023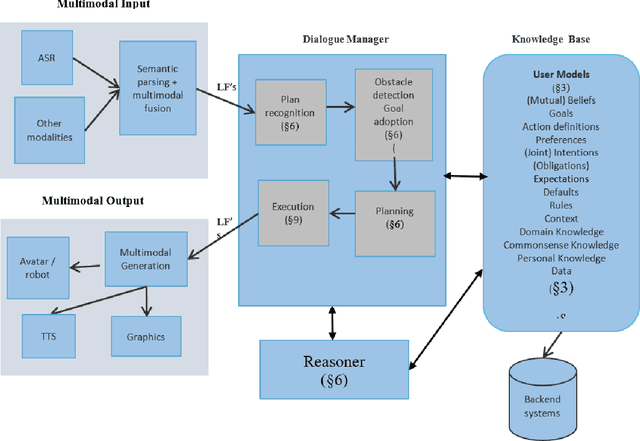
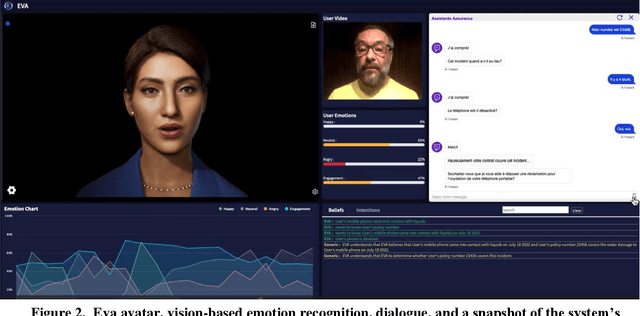

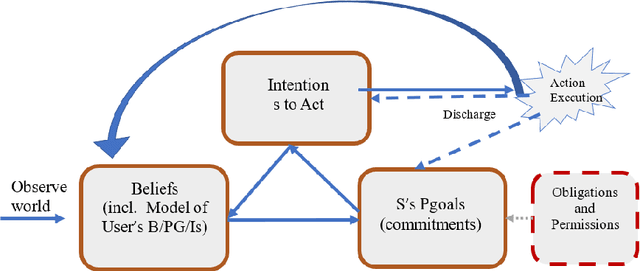
Eva is a multimodal conversational system that helps users to accomplish their domain goals through collaborative dialogue. The system does this by inferring users' intentions and plans to achieve those goals, detects whether obstacles are present, finds plans to overcome them or to achieve higher-level goals, and plans its actions, including speech acts,to help users accomplish those goals. In doing so, the system maintains and reasons with its own beliefs, goals and intentions, and explicitly reasons about those of its user. Belief reasoning is accomplished with a modal Horn-clause meta-interpreter. The planning and reasoning subsystems obey the principles of persistent goals and intentions, including the formation and decomposition of intentions to perform complex actions, as well as the conditions under which they can be given up. In virtue of its planning process, the system treats its speech acts just like its other actions -- physical acts affect physical states, digital acts affect digital states, and speech acts affect mental and social states. This general approach enables Eva to plan a variety of speech acts including requests, informs, questions, confirmations, recommendations, offers, acceptances, greetings, and emotive expressions. Each of these has a formally specified semantics which is used during the planning and reasoning processes. Because it can keep track of different users' mental states, it can engage in multi-party dialogues. Importantly, Eva can explain its utterances because it has created a plan standing behind each of them. Finally, Eva employs multimodal input and output, driving an avatar that can perceive and employ facial and head movements along with emotive speech acts.
Investigating Content-Aware Neural Text-To-Speech MOS Prediction Using Prosodic and Linguistic Features
Nov 01, 2022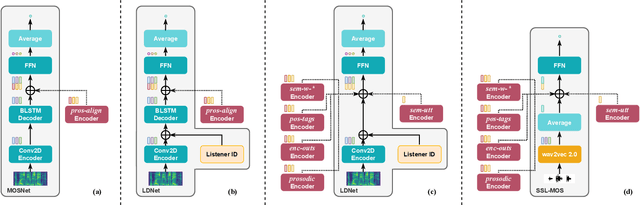
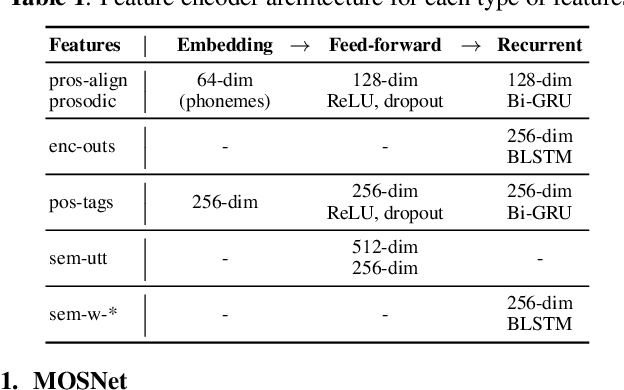
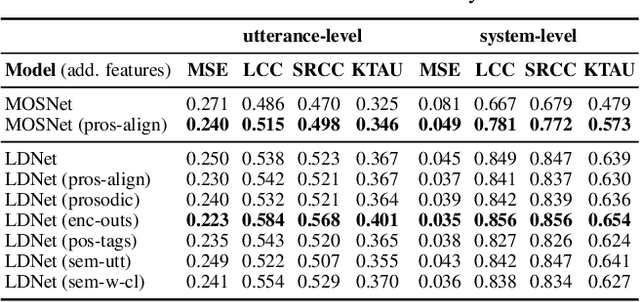
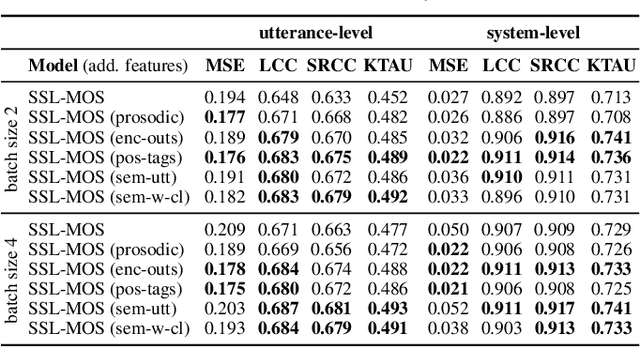
Current state-of-the-art methods for automatic synthetic speech evaluation are based on MOS prediction neural models. Such MOS prediction models include MOSNet and LDNet that use spectral features as input, and SSL-MOS that relies on a pretrained self-supervised learning model that directly uses the speech signal as input. In modern high-quality neural TTS systems, prosodic appropriateness with regard to the spoken content is a decisive factor for speech naturalness. For this reason, we propose to include prosodic and linguistic features as additional inputs in MOS prediction systems, and evaluate their impact on the prediction outcome. We consider phoneme level F0 and duration features as prosodic inputs, as well as Tacotron encoder outputs, POS tags and BERT embeddings as higher-level linguistic inputs. All MOS prediction systems are trained on SOMOS, a neural TTS-only dataset with crowdsourced naturalness MOS evaluations. Results show that the proposed additional features are beneficial in the MOS prediction task, by improving the predicted MOS scores' correlation with the ground truths, both at utterance-level and system-level predictions.
Learning utterance-level representations through token-level acoustic latents prediction for Expressive Speech Synthesis
Nov 01, 2022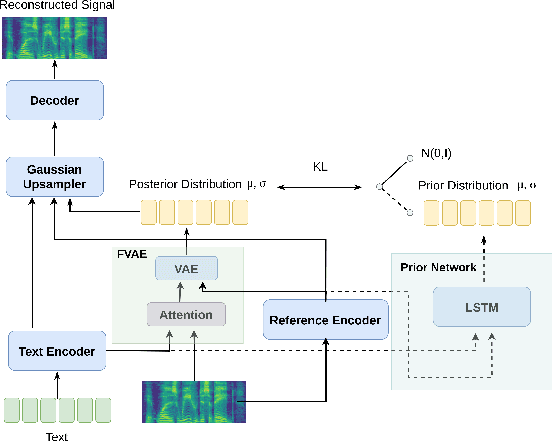
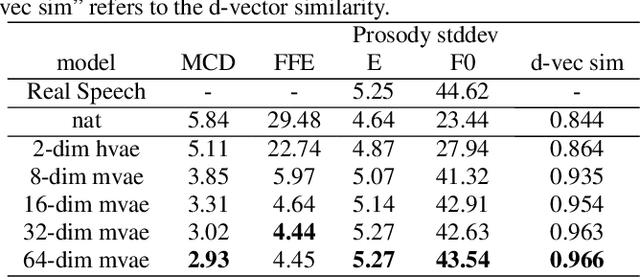
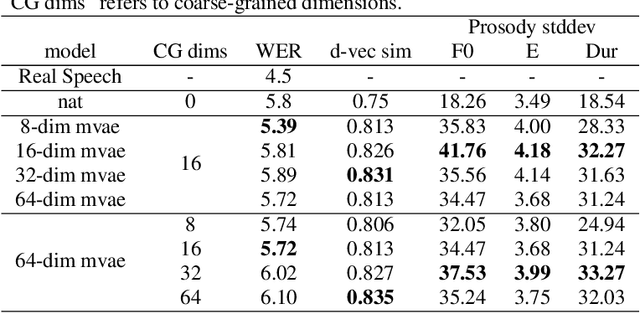
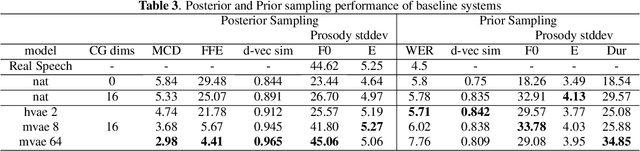
This paper proposes an Expressive Speech Synthesis model that utilizes token-level latent prosodic variables in order to capture and control utterance-level attributes, such as character acting voice and speaking style. Current works aim to explicitly factorize such fine-grained and utterance-level speech attributes into different representations extracted by modules that operate in the corresponding level. We show that the fine-grained latent space also captures coarse-grained information, which is more evident as the dimension of latent space increases in order to capture diverse prosodic representations. Therefore, a trade-off arises between the diversity of the token-level and utterance-level representations and their disentanglement. We alleviate this issue by first capturing rich speech attributes into a token-level latent space and then, separately train a prior network that given the input text, learns utterance-level representations in order to predict the phoneme-level, posterior latents extracted during the previous step. Both qualitative and quantitative evaluations are used to demonstrate the effectiveness of the proposed approach. Audio samples are available in our demo page.