 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Predictive Neural Speech Coding
Jul 18, 2022
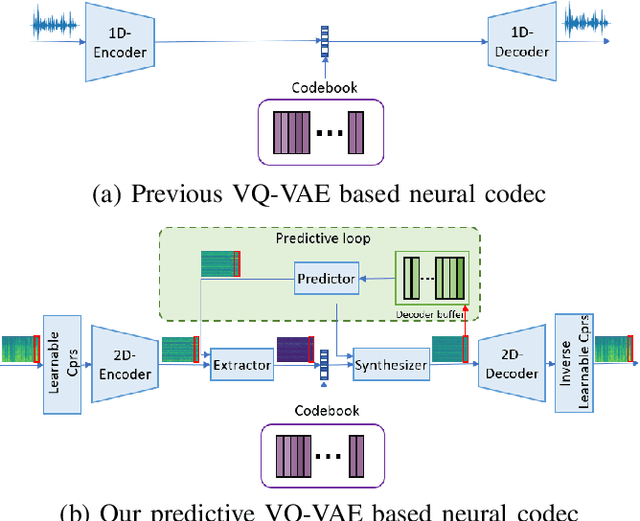
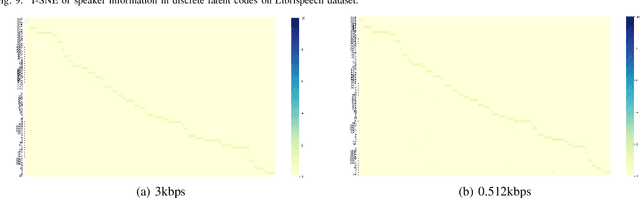
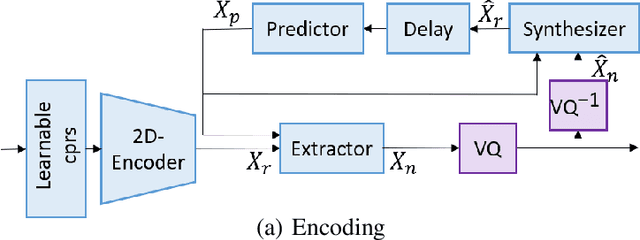
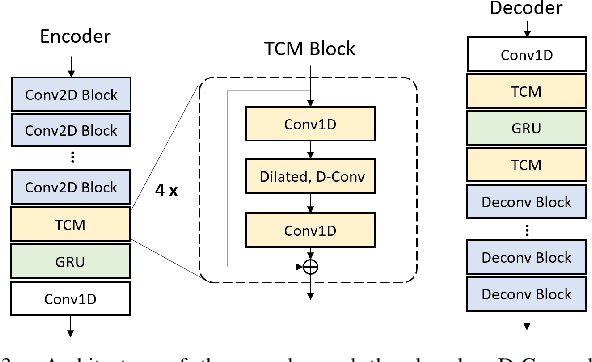
Neural audio/speech coding has shown its capability to deliver a high quality at much lower bitrates than traditional methods recently. However, existing neural audio/speech codecs employ either acoustic features or learned blind features with a convolutional neural network for encoding, by which there are still temporal redundancies inside encoded features. This paper introduces latent-domain predictive coding into the VQ-VAE framework to fully remove such redundancies and proposes the TF-Codec for low-latency neural speech coding in an end-to-end way. Specifically, the extracted features are encoded conditioned on a prediction from past quantized latent frames so that temporal correlations are further removed. What's more, we introduce a learnable compression on the time-frequency input to adaptively adjust the attention paid on main frequencies and details at different bitrates. A differentiable vector quantization scheme based on distance-to-soft mapping and Gumbel-Softmax is proposed to better model the latent distributions with rate constraint. Subjective results on multilingual speech datasets show that with a latency of 40ms, the proposed TF-Codec at 1kbps can achieve a much better quality than Opus 9kbps and TF-Codec at 3kbps outperforms both EVS 9.6kbps and Opus 12kbps. Numerous studies are conducted to show the effectiveness of these techniques.
A Planning-Based Explainable Collaborative Dialogue System
Mar 02, 2023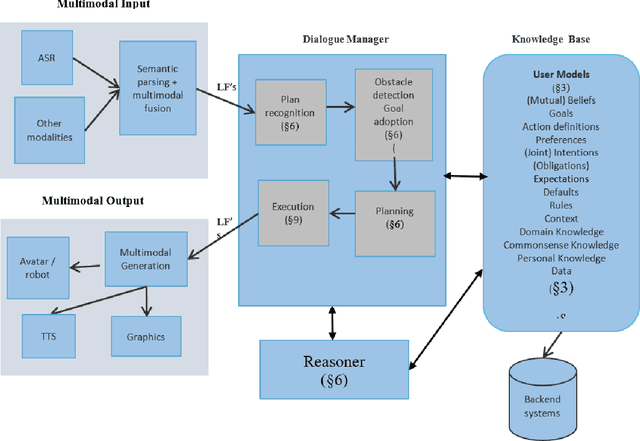
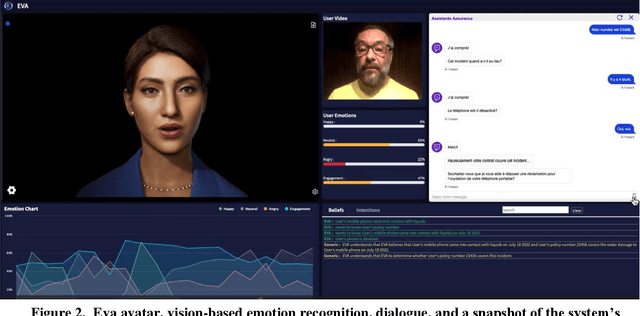

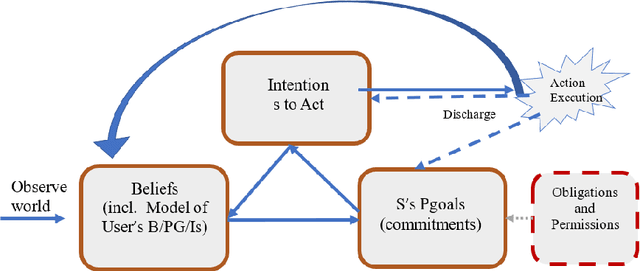
Eva is a multimodal conversational system that helps users to accomplish their domain goals through collaborative dialogue. The system does this by inferring users' intentions and plans to achieve those goals, detects whether obstacles are present, finds plans to overcome them or to achieve higher-level goals, and plans its actions, including speech acts,to help users accomplish those goals. In doing so, the system maintains and reasons with its own beliefs, goals and intentions, and explicitly reasons about those of its user. Belief reasoning is accomplished with a modal Horn-clause meta-interpreter. The planning and reasoning subsystems obey the principles of persistent goals and intentions, including the formation and decomposition of intentions to perform complex actions, as well as the conditions under which they can be given up. In virtue of its planning process, the system treats its speech acts just like its other actions -- physical acts affect physical states, digital acts affect digital states, and speech acts affect mental and social states. This general approach enables Eva to plan a variety of speech acts including requests, informs, questions, confirmations, recommendations, offers, acceptances, greetings, and emotive expressions. Each of these has a formally specified semantics which is used during the planning and reasoning processes. Because it can keep track of different users' mental states, it can engage in multi-party dialogues. Importantly, Eva can explain its utterances because it has created a plan standing behind each of them. Finally, Eva employs multimodal input and output, driving an avatar that can perceive and employ facial and head movements along with emotive speech acts.
Investigating Content-Aware Neural Text-To-Speech MOS Prediction Using Prosodic and Linguistic Features
Nov 01, 2022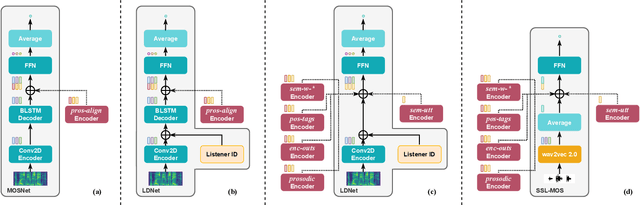
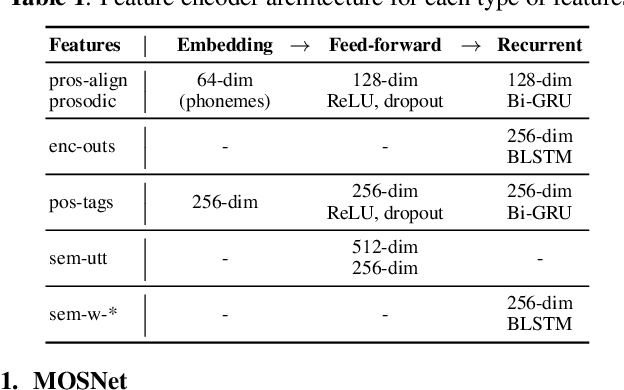
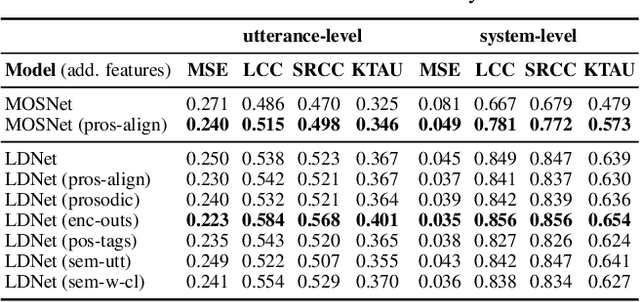
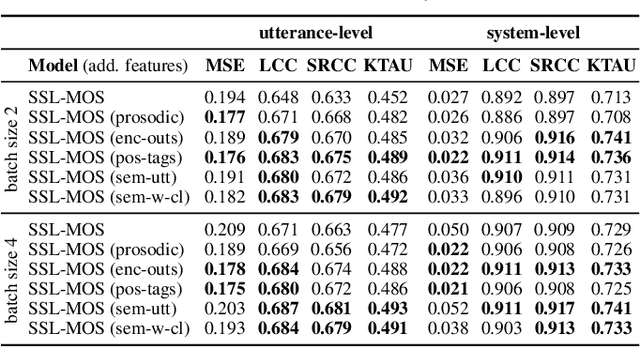
Current state-of-the-art methods for automatic synthetic speech evaluation are based on MOS prediction neural models. Such MOS prediction models include MOSNet and LDNet that use spectral features as input, and SSL-MOS that relies on a pretrained self-supervised learning model that directly uses the speech signal as input. In modern high-quality neural TTS systems, prosodic appropriateness with regard to the spoken content is a decisive factor for speech naturalness. For this reason, we propose to include prosodic and linguistic features as additional inputs in MOS prediction systems, and evaluate their impact on the prediction outcome. We consider phoneme level F0 and duration features as prosodic inputs, as well as Tacotron encoder outputs, POS tags and BERT embeddings as higher-level linguistic inputs. All MOS prediction systems are trained on SOMOS, a neural TTS-only dataset with crowdsourced naturalness MOS evaluations. Results show that the proposed additional features are beneficial in the MOS prediction task, by improving the predicted MOS scores' correlation with the ground truths, both at utterance-level and system-level predictions.
Learning utterance-level representations through token-level acoustic latents prediction for Expressive Speech Synthesis
Nov 01, 2022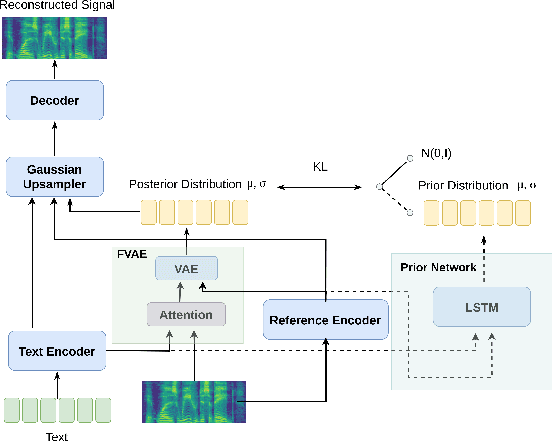
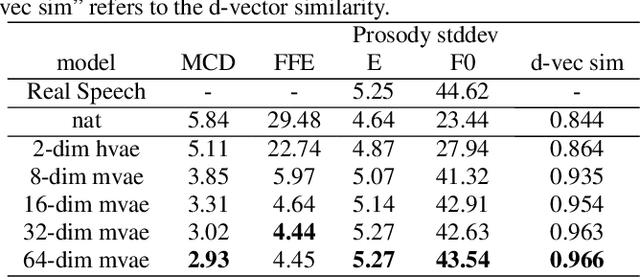
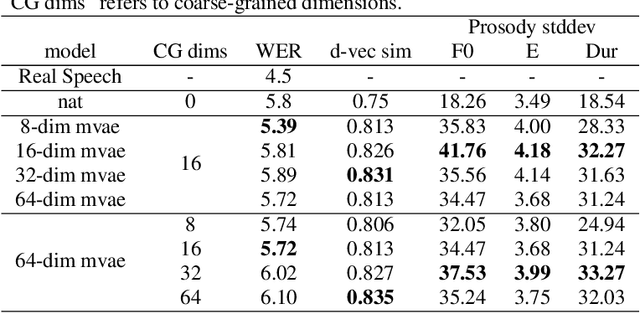
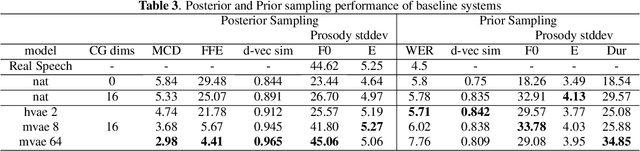
This paper proposes an Expressive Speech Synthesis model that utilizes token-level latent prosodic variables in order to capture and control utterance-level attributes, such as character acting voice and speaking style. Current works aim to explicitly factorize such fine-grained and utterance-level speech attributes into different representations extracted by modules that operate in the corresponding level. We show that the fine-grained latent space also captures coarse-grained information, which is more evident as the dimension of latent space increases in order to capture diverse prosodic representations. Therefore, a trade-off arises between the diversity of the token-level and utterance-level representations and their disentanglement. We alleviate this issue by first capturing rich speech attributes into a token-level latent space and then, separately train a prior network that given the input text, learns utterance-level representations in order to predict the phoneme-level, posterior latents extracted during the previous step. Both qualitative and quantitative evaluations are used to demonstrate the effectiveness of the proposed approach. Audio samples are available in our demo page.
Applying wav2vec2 for Speech Recognition on Bengali Common Voices Dataset
Sep 11, 2022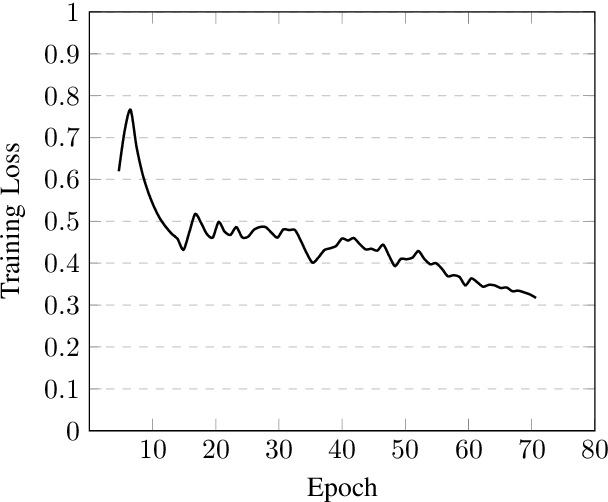
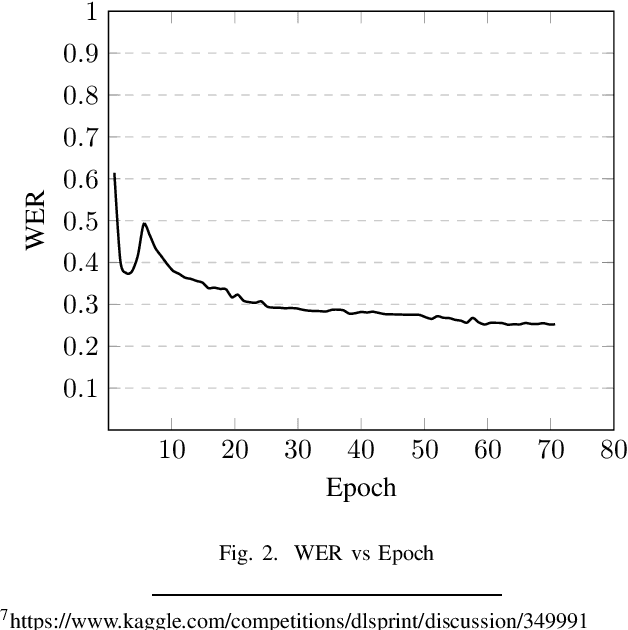

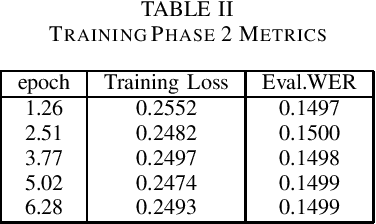
Speech is inherently continuous, where discrete words, phonemes and other units are not clearly segmented, and so speech recognition has been an active research problem for decades. In this work we have fine-tuned wav2vec 2.0 to recognize and transcribe Bengali speech -- training it on the Bengali Common Voice Speech Dataset. After training for 71 epochs, on a training set consisting of 36919 mp3 files, we achieved a training loss of 0.3172 and WER of 0.2524 on a validation set of size 7,747. Using a 5-gram language model, the Levenshtein Distance was 2.6446 on a test set of size 7,747. Then the training set and validation set were combined, shuffled and split into 85-15 ratio. Training for 7 more epochs on this combined dataset yielded an improved Levenshtein Distance of 2.60753 on the test set. Our model was the best performing one, achieving a Levenshtein Distance of 6.234 on a hidden dataset, which was 1.1049 units lower than other competing submissions.
Automated detection of pronunciation errors in non-native English speech employing deep learning
Sep 13, 2022Despite significant advances in recent years, the existing Computer-Assisted Pronunciation Training (CAPT) methods detect pronunciation errors with a relatively low accuracy (precision of 60% at 40%-80% recall). This Ph.D. work proposes novel deep learning methods for detecting pronunciation errors in non-native (L2) English speech, outperforming the state-of-the-art method in AUC metric (Area under the Curve) by 41%, i.e., from 0.528 to 0.749. One of the problems with existing CAPT methods is the low availability of annotated mispronounced speech needed for reliable training of pronunciation error detection models. Therefore, the detection of pronunciation errors is reformulated to the task of generating synthetic mispronounced speech. Intuitively, if we could mimic mispronounced speech and produce any amount of training data, detecting pronunciation errors would be more effective. Furthermore, to eliminate the need to align canonical and recognized phonemes, a novel end-to-end multi-task technique to directly detect pronunciation errors was proposed. The pronunciation error detection models have been used at Amazon to automatically detect pronunciation errors in synthetic speech to accelerate the research into new speech synthesis methods. It was demonstrated that the proposed deep learning methods are applicable in the tasks of detecting and reconstructing dysarthric speech.
OLISIA: a Cascade System for Spoken Dialogue State Tracking
Apr 20, 2023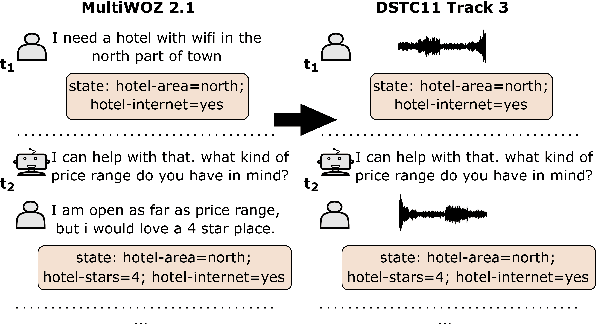
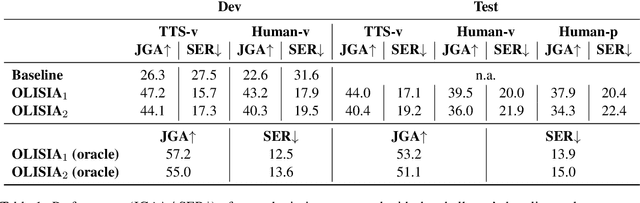
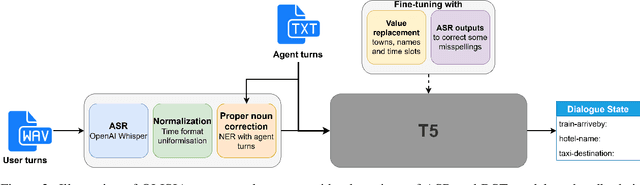
Though Dialogue State Tracking (DST) is a core component of spoken dialogue systems, recent work on this task mostly deals with chat corpora, disregarding the discrepancies between spoken and written language.In this paper, we propose OLISIA, a cascade system which integrates an Automatic Speech Recognition (ASR) model and a DST model. We introduce several adaptations in the ASR and DST modules to improve integration and robustness to spoken conversations.With these adaptations, our system ranked first in DSTC11 Track 3, a benchmark to evaluate spoken DST. We conduct an in-depth analysis of the results and find that normalizing the ASR outputs and adapting the DST inputs through data augmentation, along with increasing the pre-trained models size all play an important role in reducing the performance discrepancy between written and spoken conversations.
Application of Knowledge Distillation to Multi-task Speech Representation Learning
Oct 29, 2022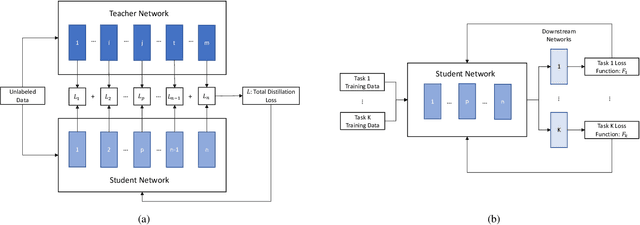
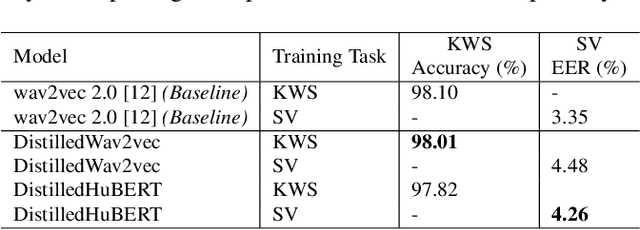
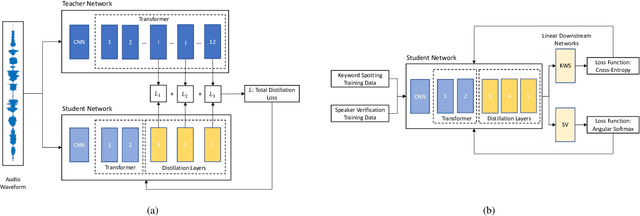
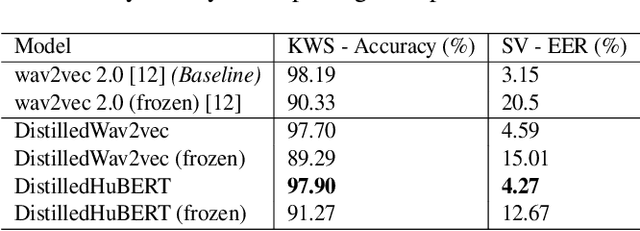
Model architectures such as wav2vec 2.0 and HuBERT have been proposed to learn speech representations from audio waveforms in a self-supervised manner. When these models are combined with downstream tasks such as speech recognition, they have been shown to provide state-of-the-art performance. However, these models use a large number of parameters, the smallest version of which has about 95 million parameters. This constitutes a challenge for edge AI device deployments. In this paper, we use knowledge distillation to reduce the original model size by about 75% while maintaining similar performance levels. Moreover, we use wav2vec 2.0 and HuBERT models for distillation and present a comprehensive performance analysis through our experiments where we fine-tune the distilled models on single task and multi-task frameworks separately. In particular, our experiments show that fine-tuning the distilled models on keyword spotting and speaker verification tasks result in only 0.1% accuracy and 0.9% equal error rate degradations, respectively.
Multi-View Attention Transfer for Efficient Speech Enhancement
Aug 22, 2022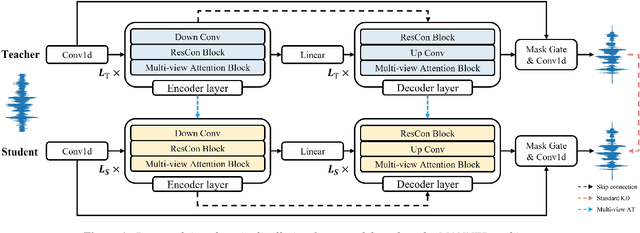
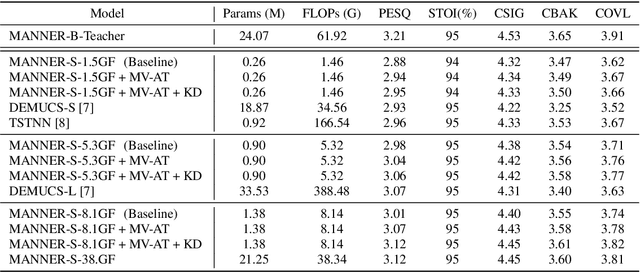
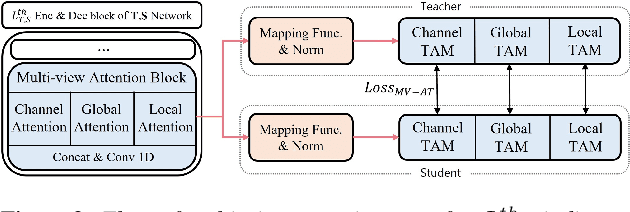
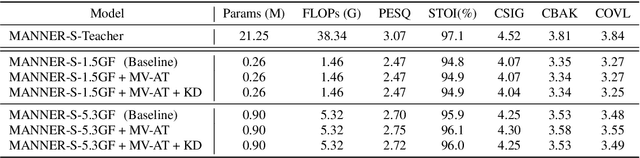
Recent deep learning models have achieved high performance in speech enhancement; however, it is still challenging to obtain a fast and low-complexity model without significant performance degradation. Previous knowledge distillation studies on speech enhancement could not solve this problem because their output distillation methods do not fit the speech enhancement task in some aspects. In this study, we propose multi-view attention transfer (MV-AT), a feature-based distillation, to obtain efficient speech enhancement models in the time domain. Based on the multi-view features extraction model, MV-AT transfers multi-view knowledge of the teacher network to the student network without additional parameters. The experimental results show that the proposed method consistently improved the performance of student models of various sizes on the Valentini and deep noise suppression (DNS) datasets. MANNER-S-8.1GF with our proposed method, a lightweight model for efficient deployment, achieved 15.4x and 4.71x fewer parameters and floating-point operations (FLOPs), respectively, compared to the baseline model with similar performance.
Leveraging Pseudo-labeled Data to Improve Direct Speech-to-Speech Translation
May 18, 2022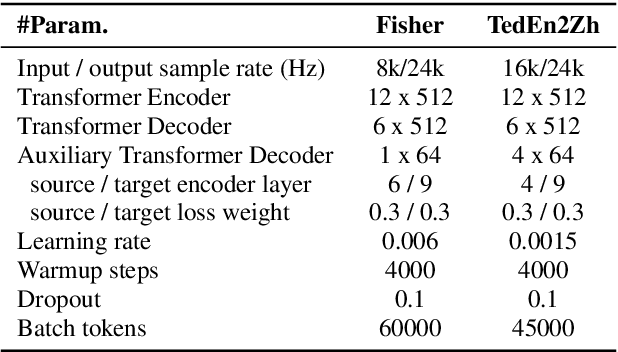
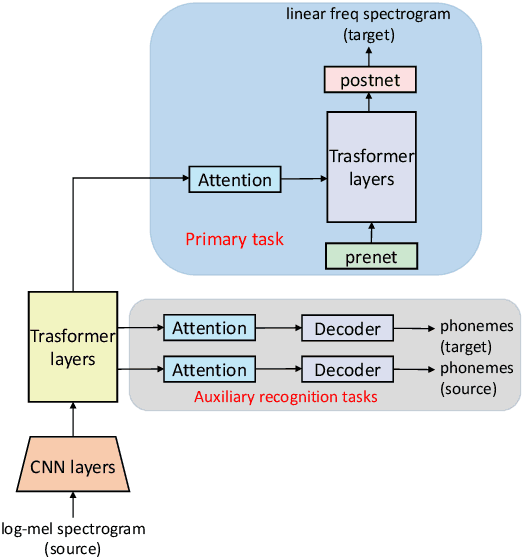
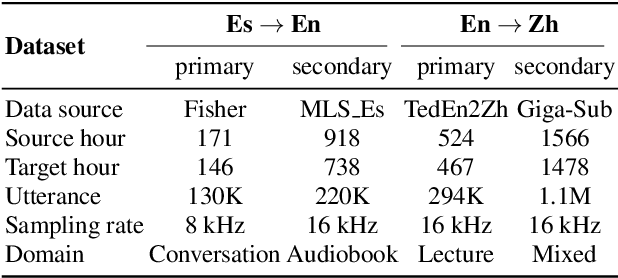
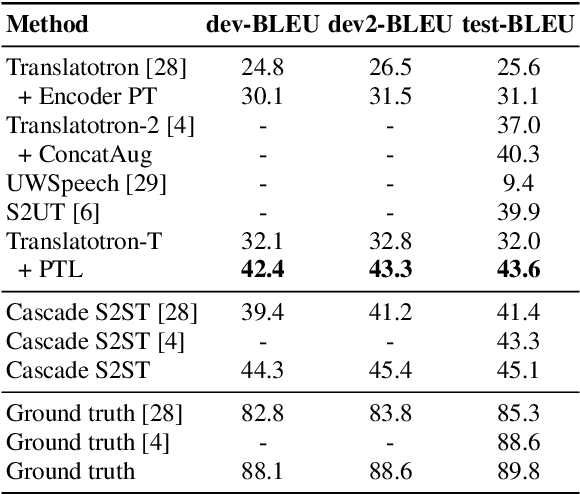
Direct Speech-to-speech translation (S2ST) has drawn more and more attention recently. The task is very challenging due to data scarcity and complex speech-to-speech mapping. In this paper, we report our recent achievements in S2ST. Firstly, we build a S2ST Transformer baseline which outperforms the original Translatotron. Secondly, we utilize the external data by pseudo-labeling and obtain a new state-of-the-art result on the Fisher English-to-Spanish test set. Indeed, we exploit the pseudo data with a combination of popular techniques which are not trivial when applied to S2ST. Moreover, we evaluate our approach on both syntactically similar (Spanish-English) and distant (English-Chinese) language pairs. Our implementation is available at https://github.com/fengpeng-yue/speech-to-speech-translation.