 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Decoding speech from non-invasive brain recordings
Aug 25, 2022
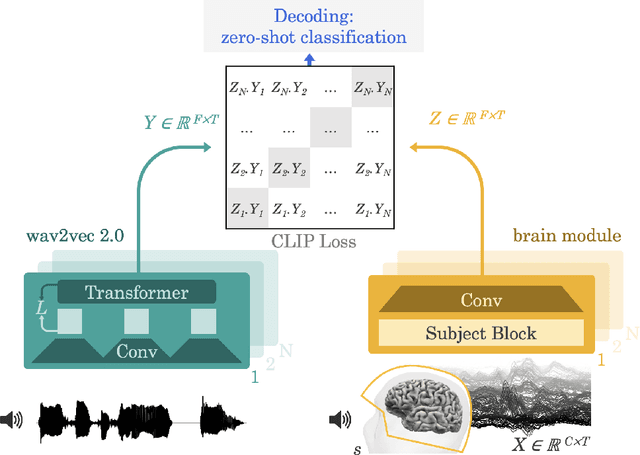

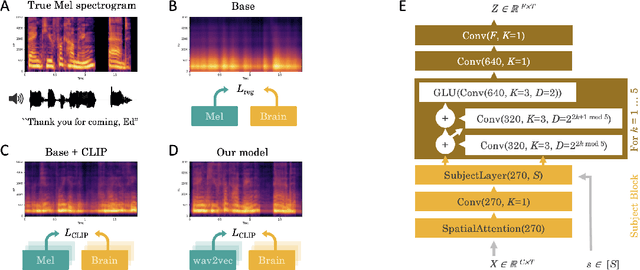

Decoding language from brain activity is a long-awaited goal in both healthcare and neuroscience. Major milestones have recently been reached thanks to intracranial devices: subject-specific pipelines trained on invasive brain responses to basic language tasks now start to efficiently decode interpretable features (e.g. letters, words, spectrograms). However, scaling this approach to natural speech and non-invasive brain recordings remains a major challenge. Here, we propose a single end-to-end architecture trained with contrastive learning across a large cohort of individuals to predict self-supervised representations of natural speech. We evaluate our model on four public datasets, encompassing 169 volunteers recorded with magneto- or electro-encephalography (M/EEG), while they listened to natural speech. The results show that our model can identify, from 3s of MEG signals, the corresponding speech segment with up to 72.5% top-10 accuracy out of 1,594 distinct segments (and 44% top-1 accuracy), and up to 19.1% out of 2,604 segments for EEG recordings -- hence allowing the decoding of phrases absent from the training set. Model comparison and ablation analyses show that these performances directly benefit from our original design choices, namely the use of (i) a contrastive objective, (ii) pretrained representations of speech and (iii) a common convolutional architecture simultaneously trained across several participants. Together, these results delineate a promising path to decode natural language processing in real time from non-invasive recordings of brain activity.
OLISIA: a Cascade System for Spoken Dialogue State Tracking
Apr 20, 2023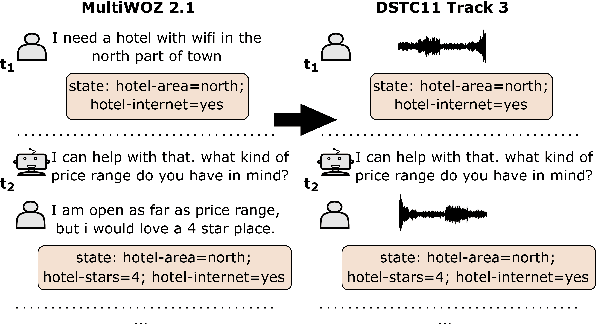
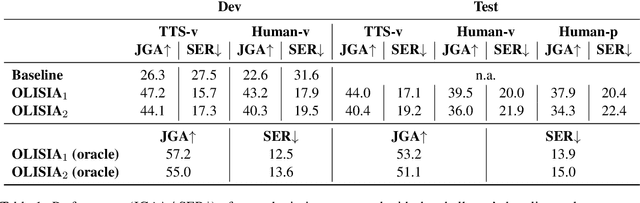
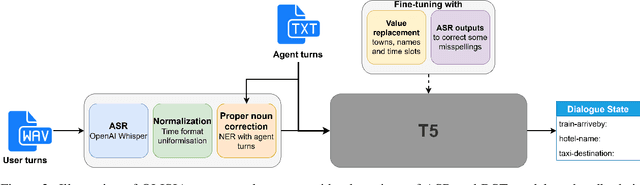
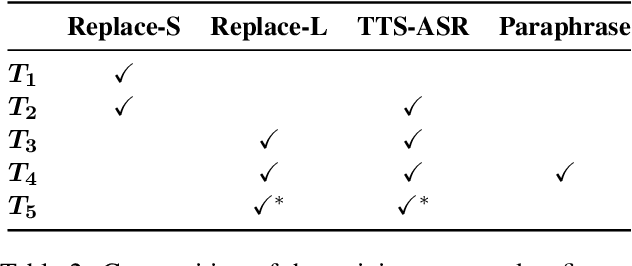
Though Dialogue State Tracking (DST) is a core component of spoken dialogue systems, recent work on this task mostly deals with chat corpora, disregarding the discrepancies between spoken and written language.In this paper, we propose OLISIA, a cascade system which integrates an Automatic Speech Recognition (ASR) model and a DST model. We introduce several adaptations in the ASR and DST modules to improve integration and robustness to spoken conversations.With these adaptations, our system ranked first in DSTC11 Track 3, a benchmark to evaluate spoken DST. We conduct an in-depth analysis of the results and find that normalizing the ASR outputs and adapting the DST inputs through data augmentation, along with increasing the pre-trained models size all play an important role in reducing the performance discrepancy between written and spoken conversations.
Extracting speaker and emotion information from self-supervised speech models via channel-wise correlations
Oct 15, 2022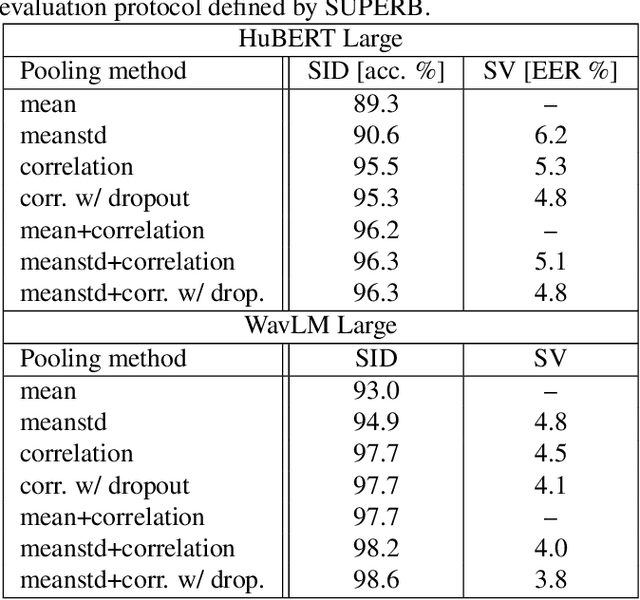
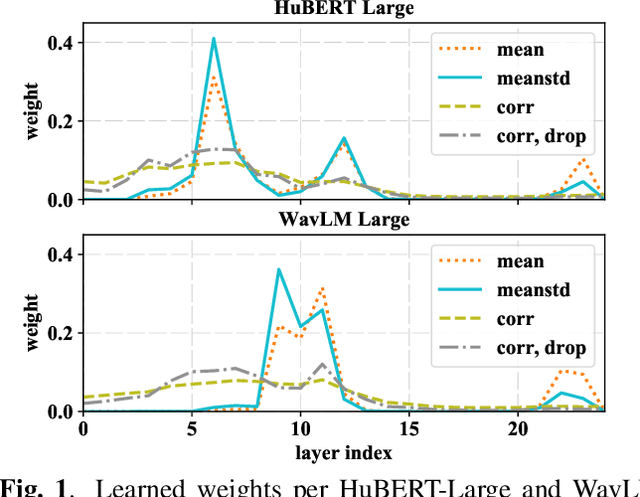
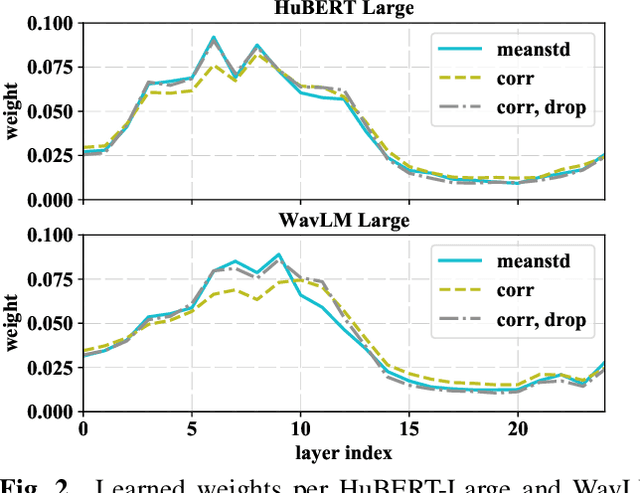
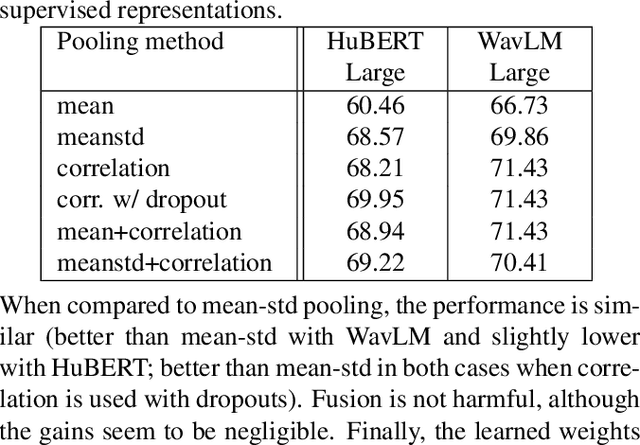
Self-supervised learning of speech representations from large amounts of unlabeled data has enabled state-of-the-art results in several speech processing tasks. Aggregating these speech representations across time is typically approached by using descriptive statistics, and in particular, using the first- and second-order statistics of representation coefficients. In this paper, we examine an alternative way of extracting speaker and emotion information from self-supervised trained models, based on the correlations between the coefficients of the representations - correlation pooling. We show improvements over mean pooling and further gains when the pooling methods are combined via fusion. The code is available at github.com/Lamomal/s3prl_correlation.
A Planning-Based Explainable Collaborative Dialogue System
Mar 02, 2023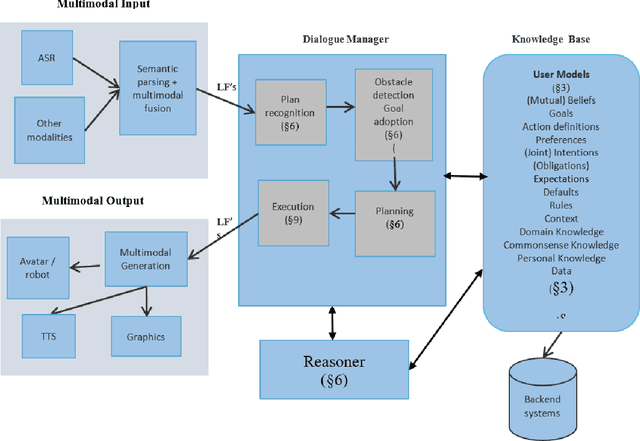
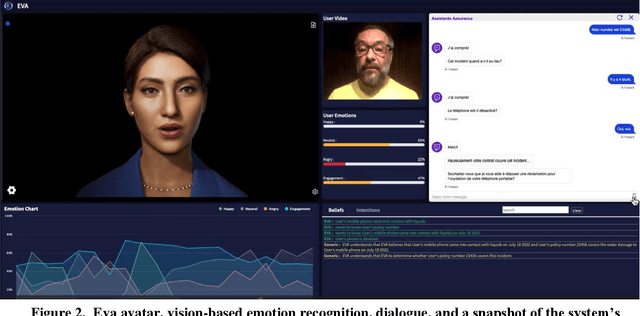

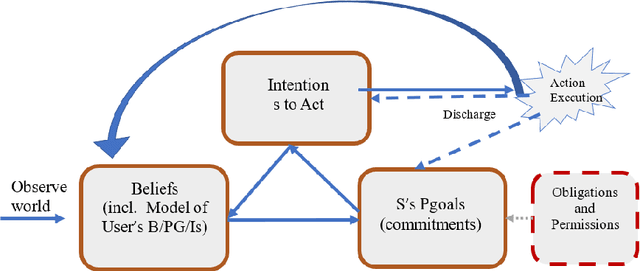
Eva is a multimodal conversational system that helps users to accomplish their domain goals through collaborative dialogue. The system does this by inferring users' intentions and plans to achieve those goals, detects whether obstacles are present, finds plans to overcome them or to achieve higher-level goals, and plans its actions, including speech acts,to help users accomplish those goals. In doing so, the system maintains and reasons with its own beliefs, goals and intentions, and explicitly reasons about those of its user. Belief reasoning is accomplished with a modal Horn-clause meta-interpreter. The planning and reasoning subsystems obey the principles of persistent goals and intentions, including the formation and decomposition of intentions to perform complex actions, as well as the conditions under which they can be given up. In virtue of its planning process, the system treats its speech acts just like its other actions -- physical acts affect physical states, digital acts affect digital states, and speech acts affect mental and social states. This general approach enables Eva to plan a variety of speech acts including requests, informs, questions, confirmations, recommendations, offers, acceptances, greetings, and emotive expressions. Each of these has a formally specified semantics which is used during the planning and reasoning processes. Because it can keep track of different users' mental states, it can engage in multi-party dialogues. Importantly, Eva can explain its utterances because it has created a plan standing behind each of them. Finally, Eva employs multimodal input and output, driving an avatar that can perceive and employ facial and head movements along with emotive speech acts.
LibriS2S: A German-English Speech-to-Speech Translation Corpus
Apr 22, 2022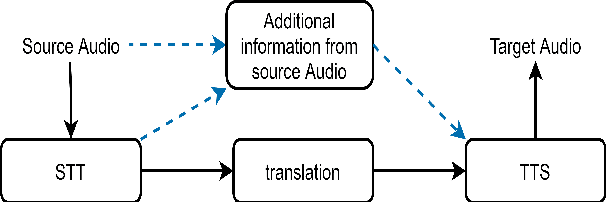
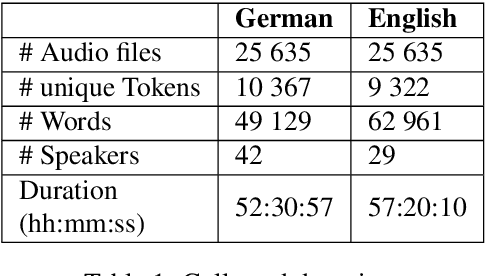
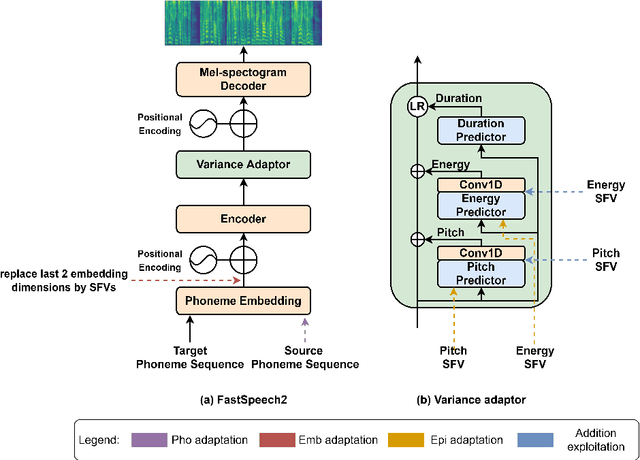
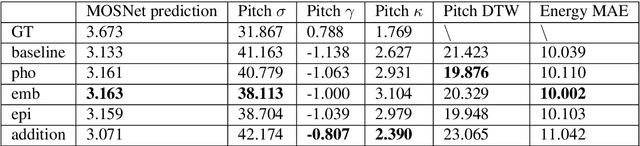
Recently, we have seen an increasing interest in the area of speech-to-text translation. This has led to astonishing improvements in this area. In contrast, the activities in the area of speech-to-speech translation is still limited, although it is essential to overcome the language barrier. We believe that one of the limiting factors is the availability of appropriate training data. We address this issue by creating LibriS2S, to our knowledge the first publicly available speech-to-speech training corpus between German and English. For this corpus, we used independently created audio for German and English leading to an unbiased pronunciation of the text in both languages. This allows the creation of a new text-to-speech and speech-to-speech translation model that directly learns to generate the speech signal based on the pronunciation of the source language. Using this created corpus, we propose Text-to-Speech models based on the example of the recently proposed FastSpeech 2 model that integrates source language information. We do this by adapting the model to take information such as the pitch, energy or transcript from the source speech as additional input.
ASR2K: Speech Recognition for Around 2000 Languages without Audio
Sep 06, 2022
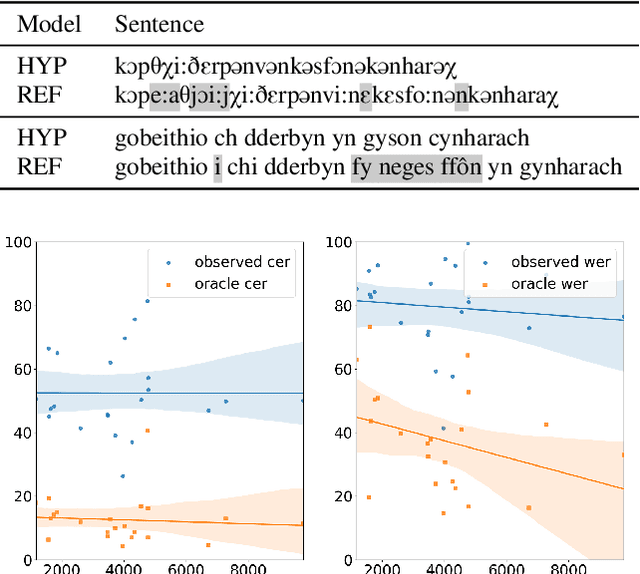
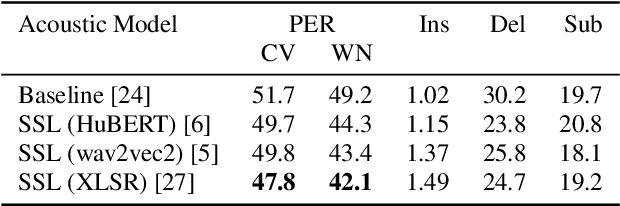
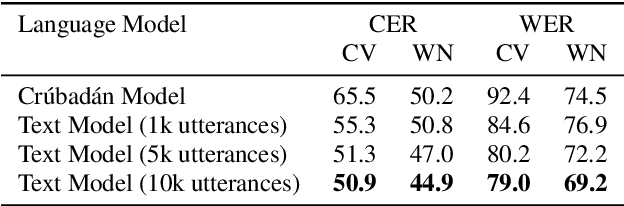
Most recent speech recognition models rely on large supervised datasets, which are unavailable for many low-resource languages. In this work, we present a speech recognition pipeline that does not require any audio for the target language. The only assumption is that we have access to raw text datasets or a set of n-gram statistics. Our speech pipeline consists of three components: acoustic, pronunciation, and language models. Unlike the standard pipeline, our acoustic and pronunciation models use multilingual models without any supervision. The language model is built using n-gram statistics or the raw text dataset. We build speech recognition for 1909 languages by combining it with Crubadan: a large endangered languages n-gram database. Furthermore, we test our approach on 129 languages across two datasets: Common Voice and CMU Wilderness dataset. We achieve 50% CER and 74% WER on the Wilderness dataset with Crubadan statistics only and improve them to 45% CER and 69% WER when using 10000 raw text utterances.
MetaSpeech: Speech Effects Switch Along with Environment for Metaverse
Oct 25, 2022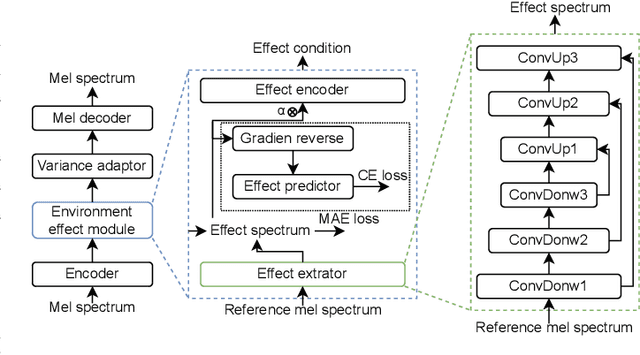
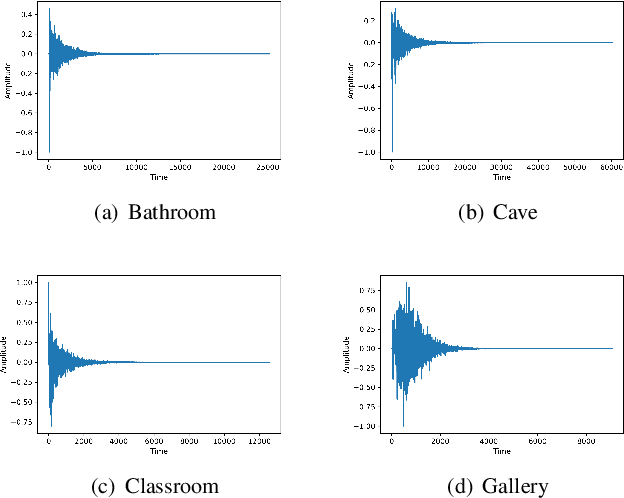
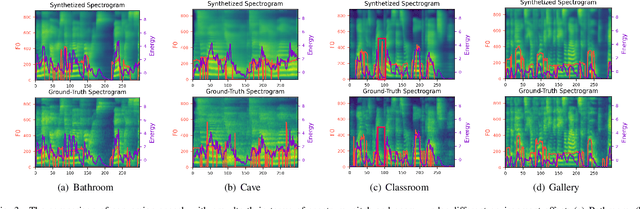
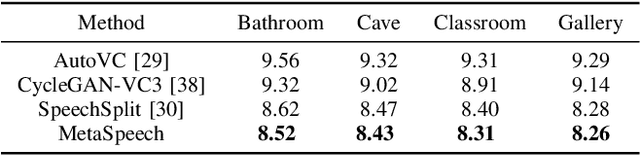
Metaverse expands the physical world to a new dimension, and the physical environment and Metaverse environment can be directly connected and entered. Voice is an indispensable communication medium in the real world and Metaverse. Fusion of the voice with environment effects is important for user immersion in Metaverse. In this paper, we proposed using the voice conversion based method for the conversion of target environment effect speech. The proposed method was named MetaSpeech, which introduces an environment effect module containing an effect extractor to extract the environment information and an effect encoder to encode the environment effect condition, in which gradient reversal layer was used for adversarial training to keep the speech content and speaker information while disentangling the environmental effects. From the experiment results on the public dataset of LJSpeech with four environment effects, the proposed model could complete the specific environment effect conversion and outperforms the baseline methods from the voice conversion task.
Neural inhibition during speech planning contributes to contrastive hyperarticulation
Sep 25, 2022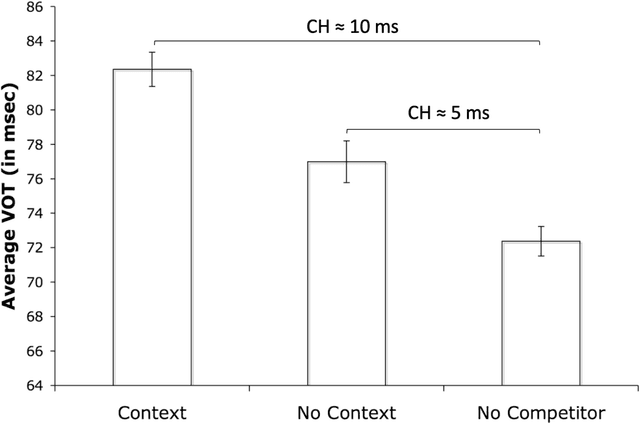
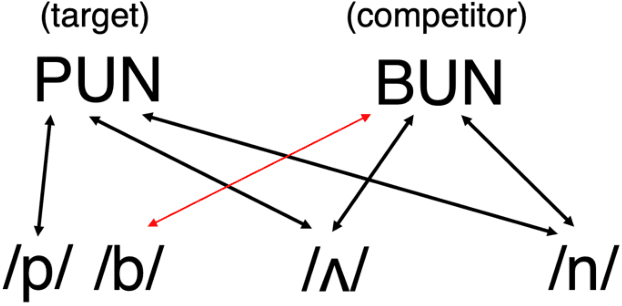
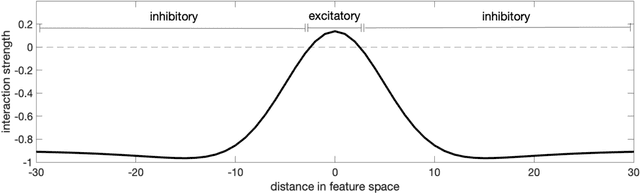
Previous work has demonstrated that words are hyperarticulated on dimensions of speech that differentiate them from a minimal pair competitor. This phenomenon has been termed contrastive hyperarticulation (CH). We present a dynamic neural field (DNF) model of voice onset time (VOT) planning that derives CH from an inhibitory influence of the minimal pair competitor during planning. We test some predictions of the model with a novel experiment investigating CH of voiceless stop consonant VOT in pseudowords. The results demonstrate a CH effect in pseudowords, consistent with a basis for the effect in the real-time planning and production of speech. The scope and magnitude of CH in pseudowords was reduced compared to CH in real words, consistent with a role for interactive activation between lexical and phonological levels of planning. We discuss the potential of our model to unify an apparently disparate set of phenomena, from CH to phonological neighborhood effects to phonetic trace effects in speech errors.
DualVoice: Speech Interaction that Discriminates between Normal and Whispered Voice Input
Aug 22, 2022
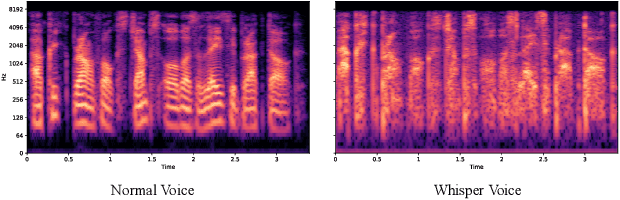
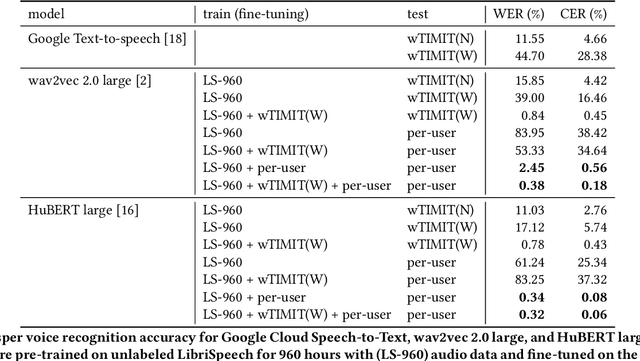
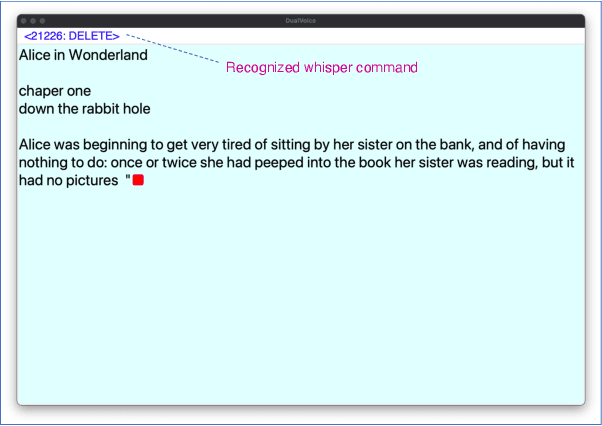
Interactions based on automatic speech recognition (ASR) have become widely used, with speech input being increasingly utilized to create documents. However, as there is no easy way to distinguish between commands being issued and text required to be input in speech, misrecognitions are difficult to identify and correct, meaning that documents need to be manually edited and corrected. The input of symbols and commands is also challenging because these may be misrecognized as text letters. To address these problems, this study proposes a speech interaction method called DualVoice, by which commands can be input in a whispered voice and letters in a normal voice. The proposed method does not require any specialized hardware other than a regular microphone, enabling a complete hands-free interaction. The method can be used in a wide range of situations where speech recognition is already available, ranging from text input to mobile/wearable computing. Two neural networks were designed in this study, one for discriminating normal speech from whispered speech, and the second for recognizing whisper speech. A prototype of a text input system was then developed to show how normal and whispered voice can be used in speech text input. Other potential applications using DualVoice are also discussed.
SQuId: Measuring Speech Naturalness in Many Languages
Oct 12, 2022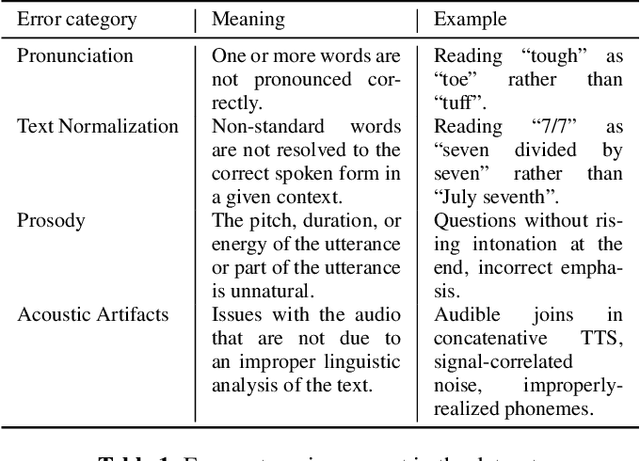
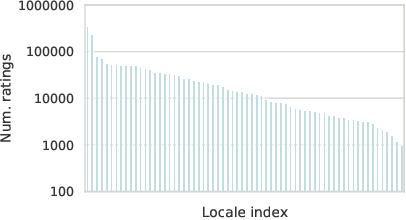

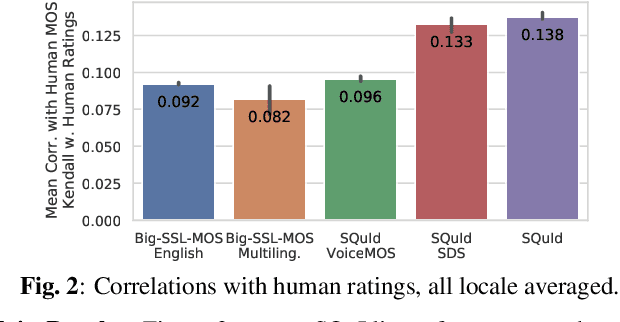
Much of text-to-speech research relies on human evaluation, which incurs heavy costs and slows down the development process. The problem is particularly acute in heavily multilingual applications, where recruiting and polling judges can take weeks. We introduce SQuId (Speech Quality Identification), a multilingual naturalness prediction model trained on over a million ratings and tested in 65 locales-the largest effort of this type to date. The main insight is that training one model on many locales consistently outperforms mono-locale baselines. We present our task, the model, and show that it outperforms a competitive baseline based on w2v-BERT and VoiceMOS by 50.0%. We then demonstrate the effectiveness of cross-locale transfer during fine-tuning and highlight its effect on zero-shot locales, i.e., locales for which there is no fine-tuning data. Through a series of analyses, we highlight the role of non-linguistic effects such as sound artifacts in cross-locale transfer. Finally, we present the effect of our design decision, e.g., model size, pre-training diversity, and language rebalancing with several ablation experiments.