 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Phonemic Representation and Transcription for Speech to Text Applications for Under-resourced Indigenous African Languages: The Case of Kiswahili
Oct 29, 2022

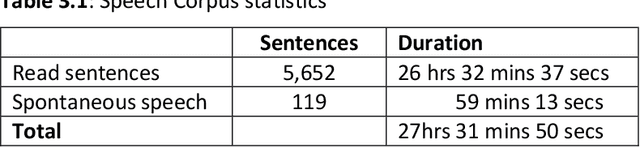
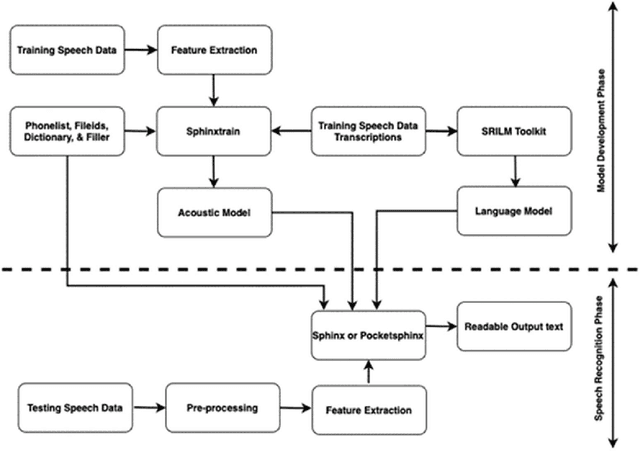
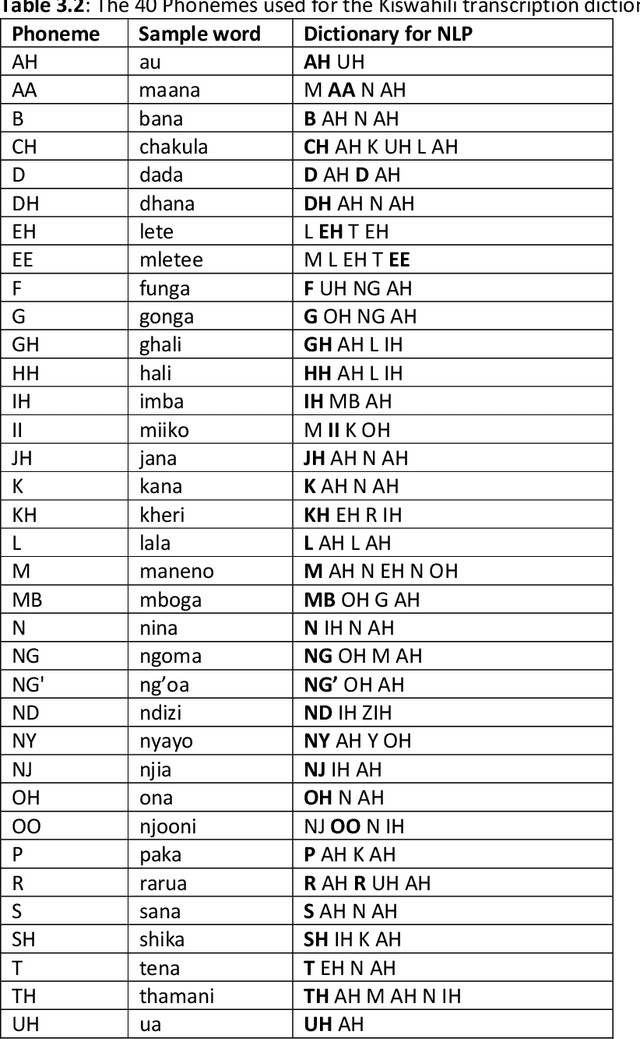
Building automatic speech recognition (ASR) systems is a challenging task, especially for under-resourced languages that need to construct corpora nearly from scratch and lack sufficient training data. It has emerged that several African indigenous languages, including Kiswahili, are technologically under-resourced. ASR systems are crucial, particularly for the hearing-impaired persons who can benefit from having transcripts in their native languages. However, the absence of transcribed speech datasets has complicated efforts to develop ASR models for these indigenous languages. This paper explores the transcription process and the development of a Kiswahili speech corpus, which includes both read-out texts and spontaneous speech data from native Kiswahili speakers. The study also discusses the vowels and consonants in Kiswahili and provides an updated Kiswahili phoneme dictionary for the ASR model that was created using the CMU Sphinx speech recognition toolbox, an open-source speech recognition toolkit. The ASR model was trained using an extended phonetic set that yielded a WER and SER of 18.87% and 49.5%, respectively, an improved performance than previous similar research for under-resourced languages.
Hey ASR System! Why Aren't You More Inclusive? Automatic Speech Recognition Systems' Bias and Proposed Bias Mitigation Techniques. A Literature Review
Nov 17, 2022Speech is the fundamental means of communication between humans. The advent of AI and sophisticated speech technologies have led to the rapid proliferation of human-to-computer-based interactions, fueled primarily by Automatic Speech Recognition (ASR) systems. ASR systems normally take human speech in the form of audio and convert it into words, but for some users, it cannot decode the speech, and any output text is filled with errors that are incomprehensible to the human reader. These systems do not work equally for everyone and actually hinder the productivity of some users. In this paper, we present research that addresses ASR biases against gender, race, and the sick and disabled, while exploring studies that propose ASR debiasing techniques for mitigating these discriminations. We also discuss techniques for designing a more accessible and inclusive ASR technology. For each approach surveyed, we also provide a summary of the investigation and methods applied, the ASR systems and corpora used, and the research findings, and highlight their strengths and/or weaknesses. Finally, we propose future opportunities for Natural Language Processing researchers to explore in the next level creation of ASR technologies.
Rhythmic Gesticulator: Rhythm-Aware Co-Speech Gesture Synthesis with Hierarchical Neural Embeddings
Oct 05, 2022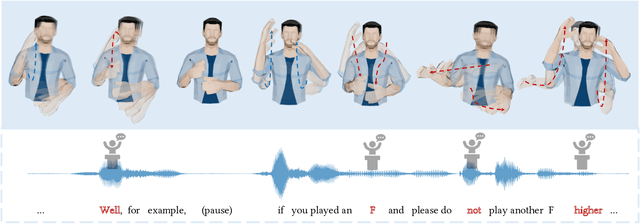
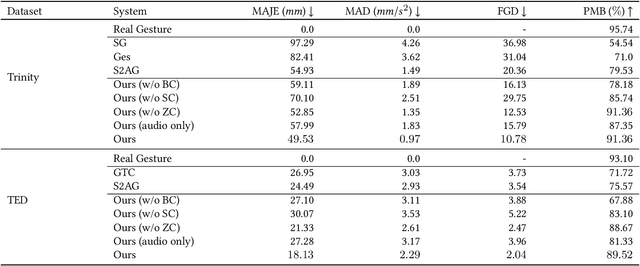
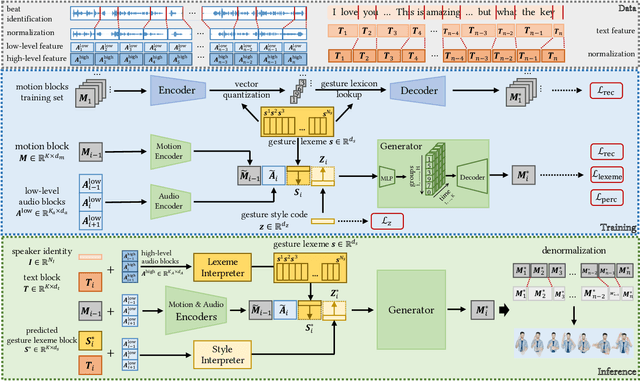
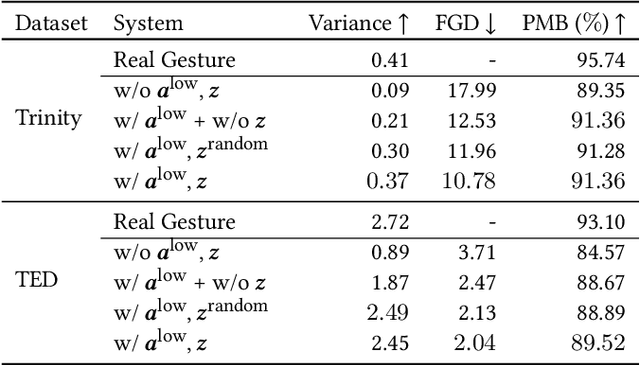
Automatic synthesis of realistic co-speech gestures is an increasingly important yet challenging task in artificial embodied agent creation. Previous systems mainly focus on generating gestures in an end-to-end manner, which leads to difficulties in mining the clear rhythm and semantics due to the complex yet subtle harmony between speech and gestures. We present a novel co-speech gesture synthesis method that achieves convincing results both on the rhythm and semantics. For the rhythm, our system contains a robust rhythm-based segmentation pipeline to ensure the temporal coherence between the vocalization and gestures explicitly. For the gesture semantics, we devise a mechanism to effectively disentangle both low- and high-level neural embeddings of speech and motion based on linguistic theory. The high-level embedding corresponds to semantics, while the low-level embedding relates to subtle variations. Lastly, we build correspondence between the hierarchical embeddings of the speech and the motion, resulting in rhythm- and semantics-aware gesture synthesis. Evaluations with existing objective metrics, a newly proposed rhythmic metric, and human feedback show that our method outperforms state-of-the-art systems by a clear margin.
Multi-Scale Feature Fusion Transformer Network for End-to-End Single Channel Speech Separation
Dec 14, 2022
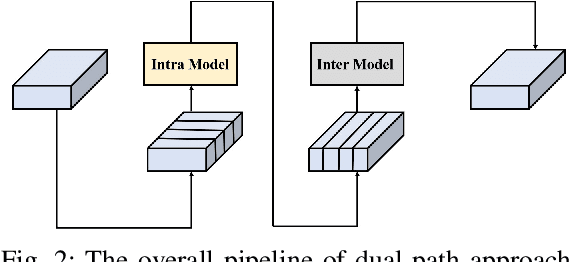
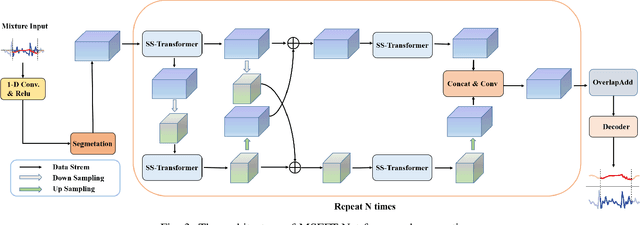
Recently studies on time-domain audio separation networks (TasNets) have made a great stride in speech separation. One of the most representative TasNets is a network with a dual-path segmentation approach. However, the original model called DPRNN used a fixed feature dimension and unchanged segment size throughout all layers of the network. In this paper, we propose a multi-scale feature fusion transformer network (MSFFT-Net) based on the conventional dual-path structure for single-channel speech separation. Unlike the conventional dual-path structure where only one processing path exists, adopting several iterative blocks with alternative intra-chunk and inter-chunk operations to capture local and global context information, the proposed MSFFT-Net has multiple parallel processing paths where the feature information can be exchanged between multiple parallel processing paths. Experiments show that our proposed networks based on multi-scale feature fusion structure have achieved better results than the original dual-path model on the benchmark dataset-WSJ0-2mix, where the SI-SNRi score of MSFFT-3P is 20.7dB (1.47% improvement), and MSFFT-2P is 21.0dB (3.45% improvement), which achieves SOTA on WSJ0-2mix without any data augmentation method.
Contextual-Utterance Training for Automatic Speech Recognition
Oct 27, 2022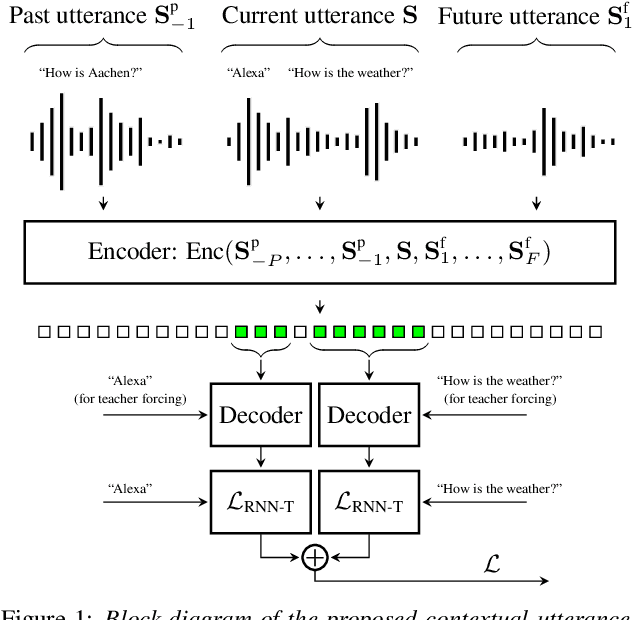
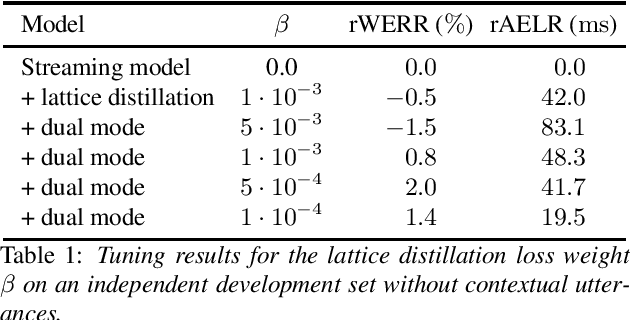
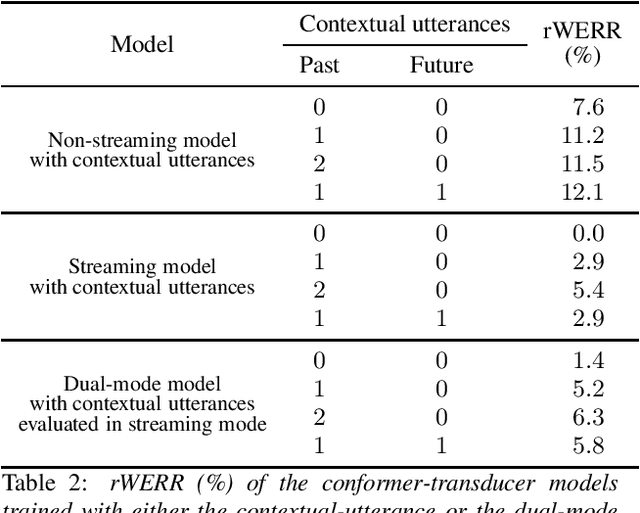

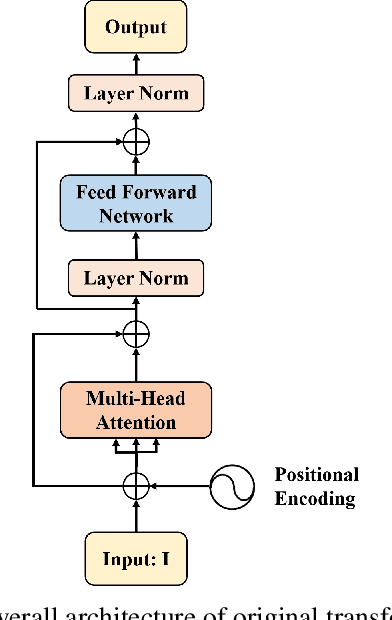
Recent studies of streaming automatic speech recognition (ASR) recurrent neural network transducer (RNN-T)-based systems have fed the encoder with past contextual information in order to improve its word error rate (WER) performance. In this paper, we first propose a contextual-utterance training technique which makes use of the previous and future contextual utterances in order to do an implicit adaptation to the speaker, topic and acoustic environment. Also, we propose a dual-mode contextual-utterance training technique for streaming automatic speech recognition (ASR) systems. This proposed approach allows to make a better use of the available acoustic context in streaming models by distilling "in-place" the knowledge of a teacher, which is able to see both past and future contextual utterances, to the student which can only see the current and past contextual utterances. The experimental results show that a conformer-transducer system trained with the proposed techniques outperforms the same system trained with the classical RNN-T loss. Specifically, the proposed technique is able to reduce both the WER and the average last token emission latency by more than 6% and 40ms relative, respectively.
Distance-based Weight Transfer for Fine-tuning from Near-field to Far-field Speaker Verification
Mar 01, 2023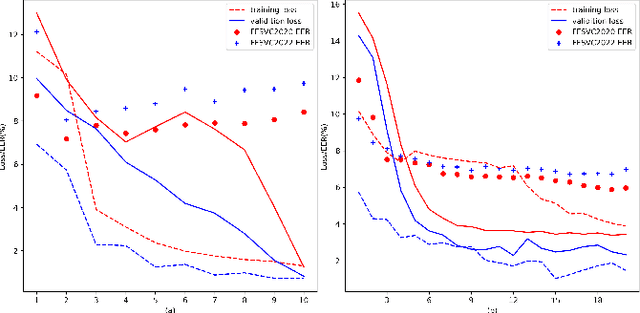
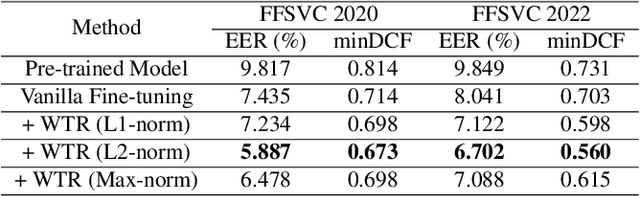
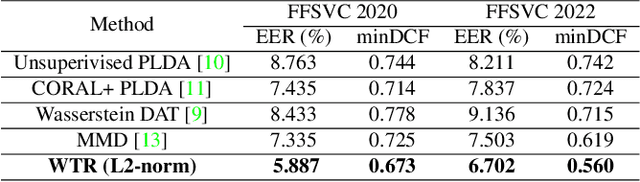
The scarcity of labeled far-field speech is a constraint for training superior far-field speaker verification systems. Fine-tuning the model pre-trained on large-scale near-field speech substantially outperforms training from scratch. However, the fine-tuning method suffers from two limitations--catastrophic forgetting and overfitting. In this paper, we propose a weight transfer regularization(WTR) loss to constrain the distance of the weights between the pre-trained model with large-scale near-field speech and the fine-tuned model through a small number of far-field speech. With the WTR loss, the fine-tuning process takes advantage of the previously acquired discriminative ability from the large-scale near-field speech without catastrophic forgetting. Meanwhile, we use the PAC-Bayes generalization theory to analyze the generalization bound of the fine-tuned model with the WTR loss. The analysis result indicates that the WTR term makes the fine-tuned model have a tighter generalization upper bound. Moreover, we explore three kinds of norm distance for weight transfer, which are L1-norm distance, L2-norm distance and Max-norm distance. Finally, we evaluate the effectiveness of the WTR loss on VoxCeleb (pre-trained dataset) and FFSVC (fine-tuned dataset) datasets.
ToxVis: Enabling Interpretability of Implicit vs. Explicit Toxicity Detection Models with Interactive Visualization
Mar 01, 2023
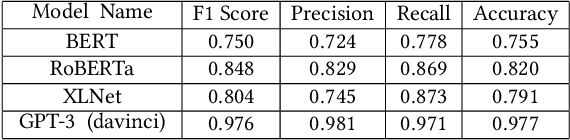
The rise of hate speech on online platforms has led to an urgent need for effective content moderation. However, the subjective and multi-faceted nature of hateful online content, including implicit hate speech, poses significant challenges to human moderators and content moderation systems. To address this issue, we developed ToxVis, a visually interactive and explainable tool for classifying hate speech into three categories: implicit, explicit, and non-hateful. We fine-tuned two transformer-based models using RoBERTa, XLNET, and GPT-3 and used deep learning interpretation techniques to provide explanations for the classification results. ToxVis enables users to input potentially hateful text and receive a classification result along with a visual explanation of which words contributed most to the decision. By making the classification process explainable, ToxVis provides a valuable tool for understanding the nuances of hateful content and supporting more effective content moderation. Our research contributes to the growing body of work aimed at mitigating the harms caused by online hate speech and demonstrates the potential for combining state-of-the-art natural language processing models with interpretable deep learning techniques to address this critical issue. Finally, ToxVis can serve as a resource for content moderators, social media platforms, and researchers working to combat the spread of hate speech online.
Towards Building Text-To-Speech Systems for the Next Billion Users
Nov 17, 2022
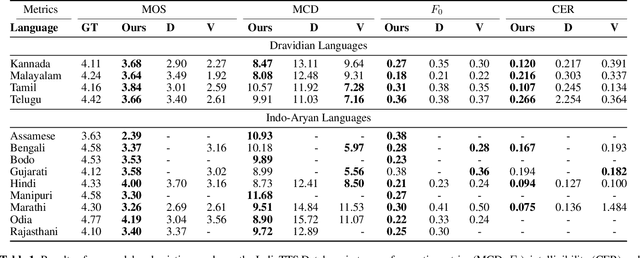
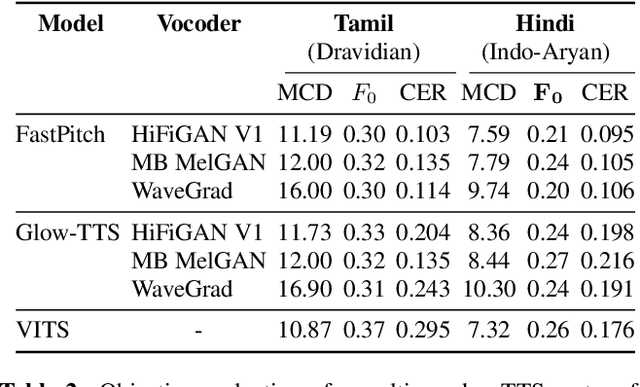
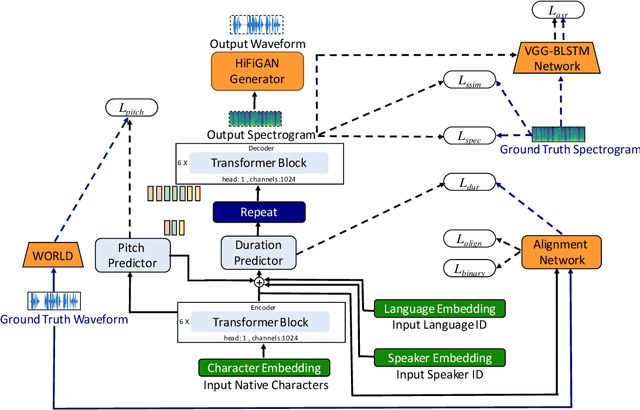
Deep learning based text-to-speech (TTS) systems have been evolving rapidly with advances in model architectures, training methodologies, and generalization across speakers and languages. However, these advances have not been thoroughly investigated for Indian language speech synthesis. Such investigation is computationally expensive given the number and diversity of Indian languages, relatively lower resource availability, and the diverse set of advances in neural TTS that remain untested. In this paper, we evaluate the choice of acoustic models, vocoders, supplementary loss functions, training schedules, and speaker and language diversity for Dravidian and Indo-Aryan languages. Based on this, we identify monolingual models with FastPitch and HiFi-GAN V1, trained jointly on male and female speakers to perform the best. With this setup, we train and evaluate TTS models for 13 languages and find our models to significantly improve upon existing models in all languages as measured by mean opinion scores. We open-source all models on the Bhashini platform.
Comparative layer-wise analysis of self-supervised speech models
Nov 08, 2022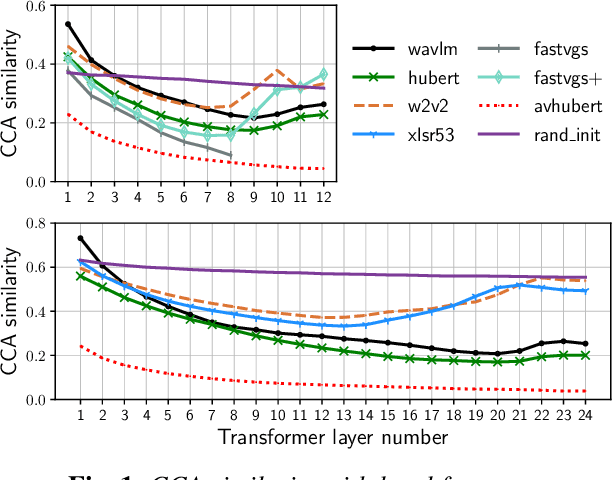
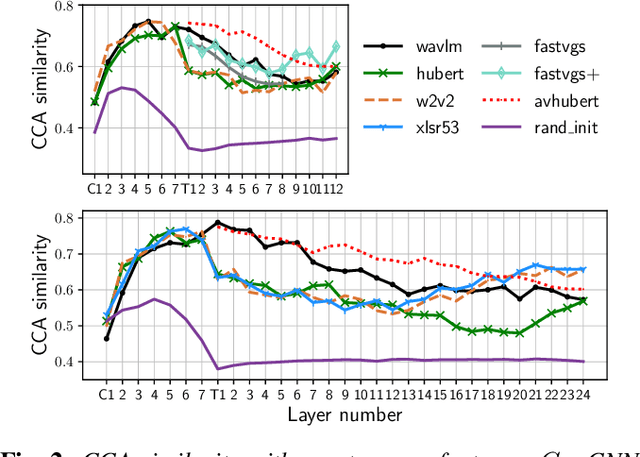
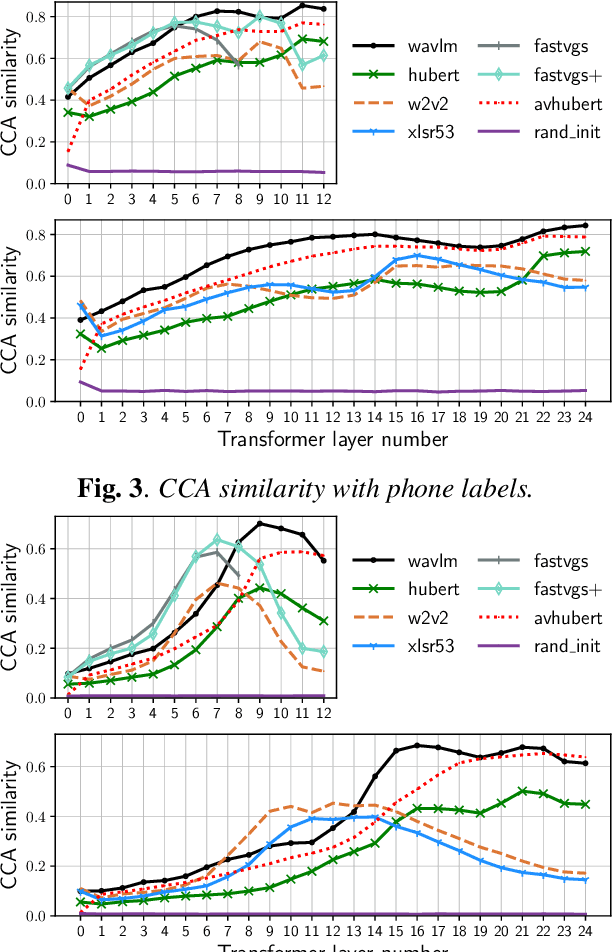
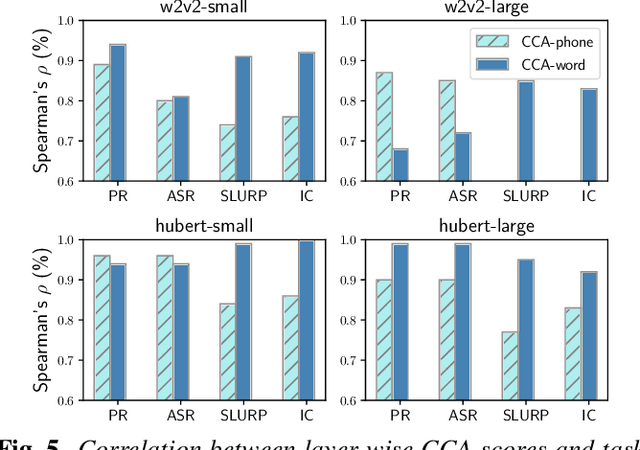
Many self-supervised speech models, varying in their pre-training objective, input modality, and pre-training data, have been proposed in the last few years. Despite impressive empirical successes on downstream tasks, we still have a limited understanding of the properties encoded by the models and the differences across models. In this work, we examine the intermediate representations for a variety of recent models. Specifically, we measure acoustic, phonetic, and word-level properties encoded in individual layers, using a lightweight analysis tool based on canonical correlation analysis (CCA). We find that these properties evolve across layers differently depending on the model, and the variations relate to the choice of pre-training objective. We further investigate the utility of our analyses for downstream tasks by comparing the property trends with performance on speech recognition and spoken language understanding tasks. We discover that CCA trends provide reliable guidance to choose layers of interest for downstream tasks and that single-layer performance often matches or improves upon using all layers, suggesting implications for more efficient use of pre-trained models.
Diverse and Vivid Sound Generation from Text Descriptions
May 03, 2023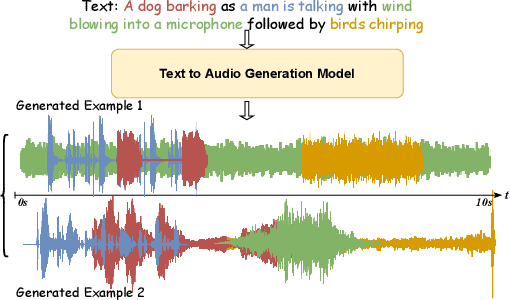
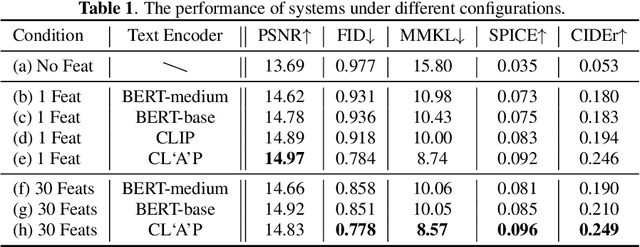
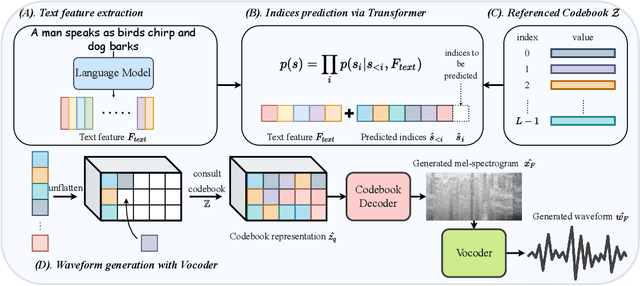

Previous audio generation mainly focuses on specified sound classes such as speech or music, whose form and content are greatly restricted. In this paper, we go beyond specific audio generation by using natural language description as a clue to generate broad sounds. Unlike visual information, a text description is concise by its nature but has rich hidden meanings beneath, which poses a higher possibility and complexity on the audio to be generated. A Variation-Quantized GAN is used to train a codebook learning discrete representations of spectrograms. For a given text description, its pre-trained embedding is fed to a Transformer to sample codebook indices to decode a spectrogram to be further transformed into waveform by a melgan vocoder. The generated waveform has high quality and fidelity while excellently corresponding to the given text. Experiments show that our proposed method is capable of generating natural, vivid audios, achieving superb quantitative and qualitative results.