 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Advancing Stuttering Detection via Data Augmentation, Class-Balanced Loss and Multi-Contextual Deep Learning
Feb 21, 2023
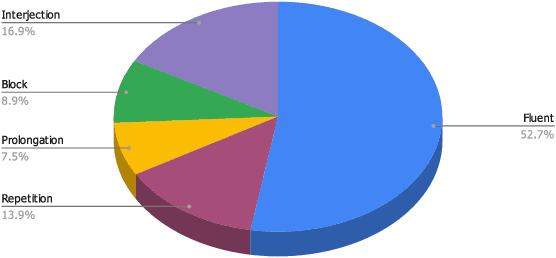
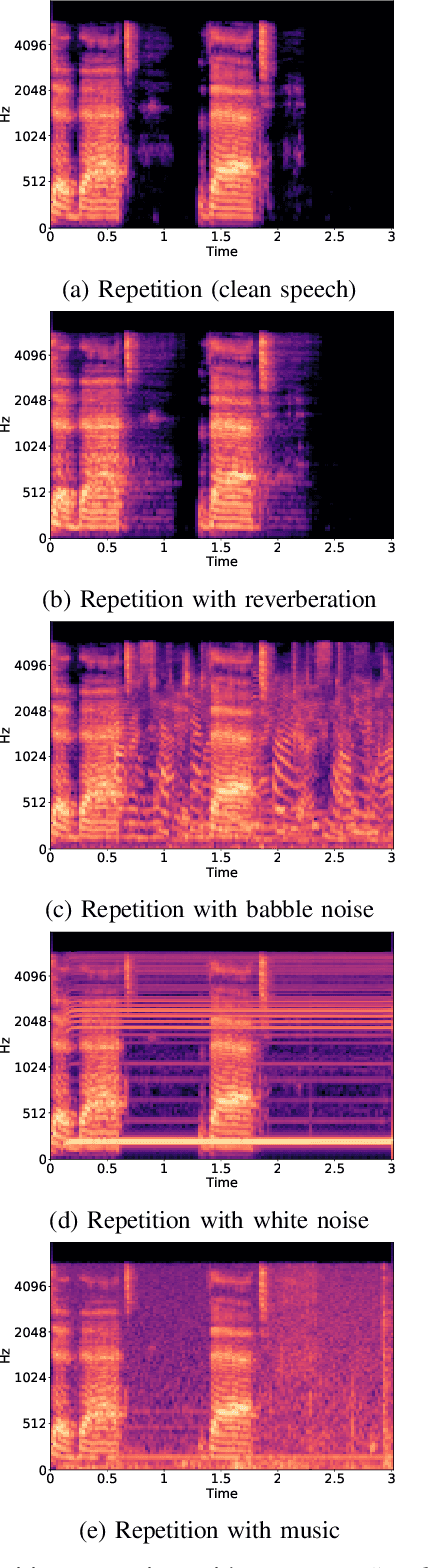
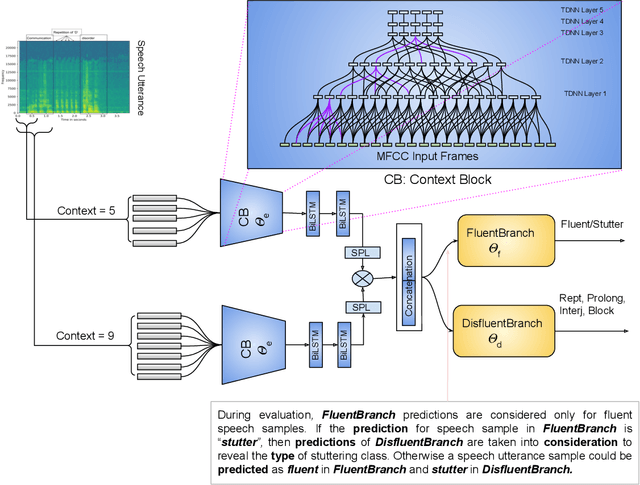
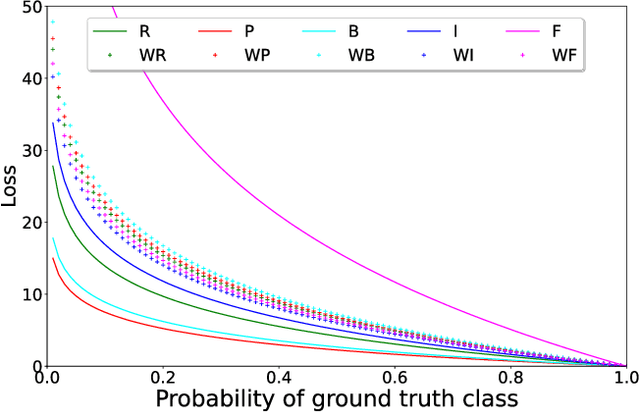
Stuttering is a neuro-developmental speech impairment characterized by uncontrolled utterances (interjections) and core behaviors (blocks, repetitions, and prolongations), and is caused by the failure of speech sensorimotors. Due to its complex nature, stuttering detection (SD) is a difficult task. If detected at an early stage, it could facilitate speech therapists to observe and rectify the speech patterns of persons who stutter (PWS). The stuttered speech of PWS is usually available in limited amounts and is highly imbalanced. To this end, we address the class imbalance problem in the SD domain via a multibranching (MB) scheme and by weighting the contribution of classes in the overall loss function, resulting in a huge improvement in stuttering classes on the SEP-28k dataset over the baseline (StutterNet). To tackle data scarcity, we investigate the effectiveness of data augmentation on top of a multi-branched training scheme. The augmented training outperforms the MB StutterNet (clean) by a relative margin of 4.18% in macro F1-score (F1). In addition, we propose a multi-contextual (MC) StutterNet, which exploits different contexts of the stuttered speech, resulting in an overall improvement of 4.48% in F 1 over the single context based MB StutterNet. Finally, we have shown that applying data augmentation in the cross-corpora scenario can improve the overall SD performance by a relative margin of 13.23% in F1 over the clean training.
Transferring Knowledge via Neighborhood-Aware Optimal Transport for Low-Resource Hate Speech Detection
Oct 17, 2022
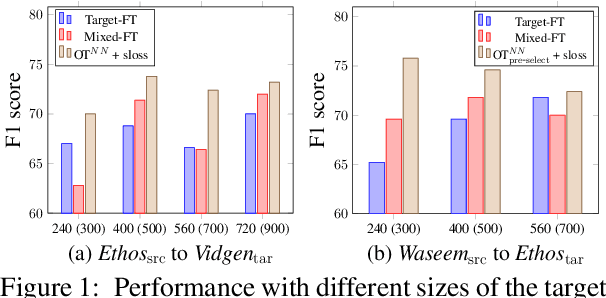

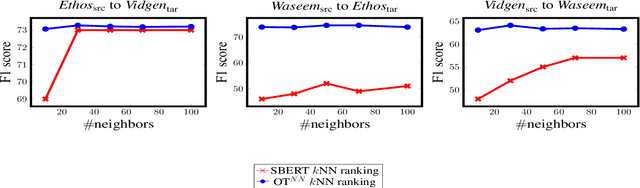
The concerning rise of hateful content on online platforms has increased the attention towards automatic hate speech detection, commonly formulated as a supervised classification task. State-of-the-art deep learning-based approaches usually require a substantial amount of labeled resources for training. However, annotating hate speech resources is expensive, time-consuming, and often harmful to the annotators. This creates a pressing need to transfer knowledge from the existing labeled resources to low-resource hate speech corpora with the goal of improving system performance. For this, neighborhood-based frameworks have been shown to be effective. However, they have limited flexibility. In our paper, we propose a novel training strategy that allows flexible modeling of the relative proximity of neighbors retrieved from a resource-rich corpus to learn the amount of transfer. In particular, we incorporate neighborhood information with Optimal Transport, which permits exploiting the geometry of the data embedding space. By aligning the joint embedding and label distributions of neighbors, we demonstrate substantial improvements over strong baselines, in low-resource scenarios, on different publicly available hate speech corpora.
Real-time Speech Interruption Analysis: From Cloud to Client Deployment
Oct 24, 2022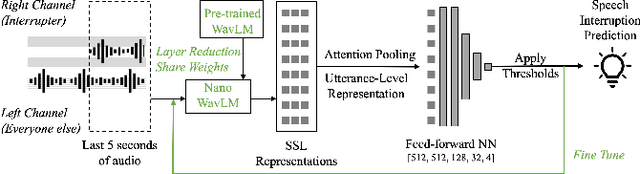
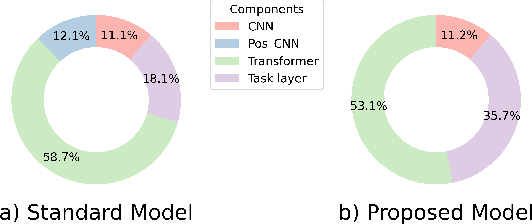
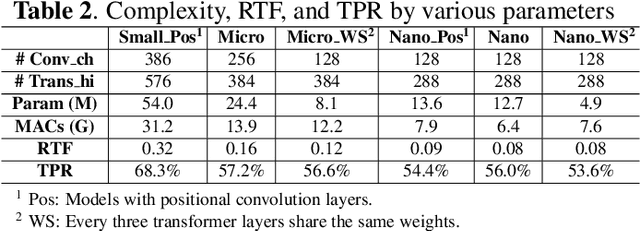
Meetings are an essential form of communication for all types of organizations, and remote collaboration systems have been much more widely used since the COVID-19 pandemic. One major issue with remote meetings is that it is challenging for remote participants to interrupt and speak. We have recently developed the first speech interruption analysis model, which detects failed speech interruptions, shows very promising performance, and is being deployed in the cloud. To deliver this feature in a more cost-efficient and environment-friendly way, we reduced the model complexity and size to ship the WavLM_SI model in client devices. In this paper, we first describe how we successfully improved the True Positive Rate (TPR) at a 1% False Positive Rate (FPR) from 50.9% to 68.3% for the failed speech interruption detection model by training on a larger dataset and fine-tuning. We then shrank the model size from 222.7 MB to 9.3 MB with an acceptable loss in accuracy and reduced the complexity from 31.2 GMACS (Giga Multiply-Accumulate Operations per Second) to 4.3 GMACS. We also estimated the environmental impact of the complexity reduction, which can be used as a general guideline for large Transformer-based models, and thus make those models more accessible with less computation overhead.
Monolingual Recognizers Fusion for Code-switching Speech Recognition
Nov 02, 2022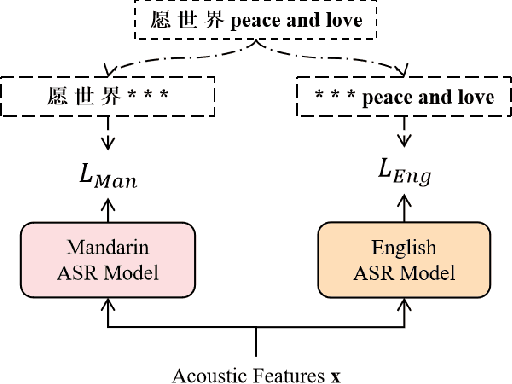
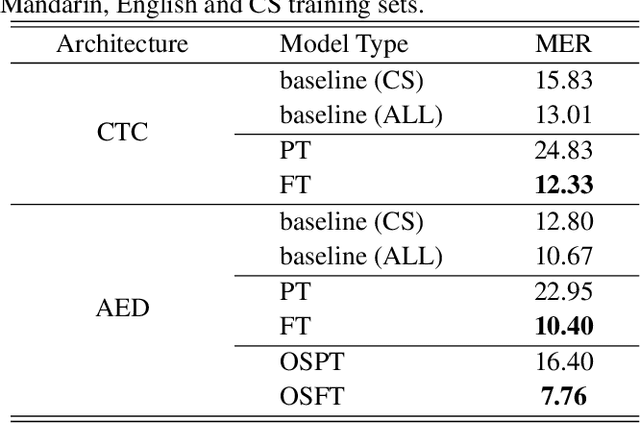
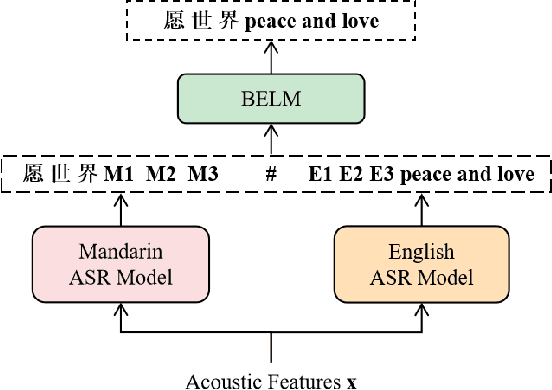
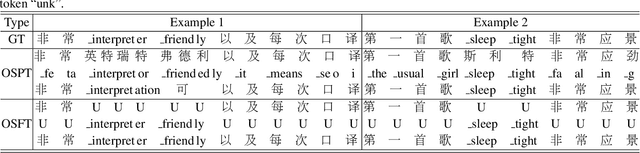
The bi-encoder structure has been intensively investigated in code-switching (CS) automatic speech recognition (ASR). However, most existing methods require the structures of two monolingual ASR models (MAMs) should be the same and only use the encoder of MAMs. This leads to the problem that pre-trained MAMs cannot be timely and fully used for CS ASR. In this paper, we propose a monolingual recognizers fusion method for CS ASR. It has two stages: the speech awareness (SA) stage and the language fusion (LF) stage. In the SA stage, acoustic features are mapped to two language-specific predictions by two independent MAMs. To keep the MAMs focused on their own language, we further extend the language-aware training strategy for the MAMs. In the LF stage, the BELM fuses two language-specific predictions to get the final prediction. Moreover, we propose a text simulation strategy to simplify the training process of the BELM and reduce reliance on CS data. Experiments on a Mandarin-English corpus show the efficiency of the proposed method. The mix error rate is significantly reduced on the test set after using open-source pre-trained MAMs.
Small-footprint slimmable networks for keyword spotting
Apr 21, 2023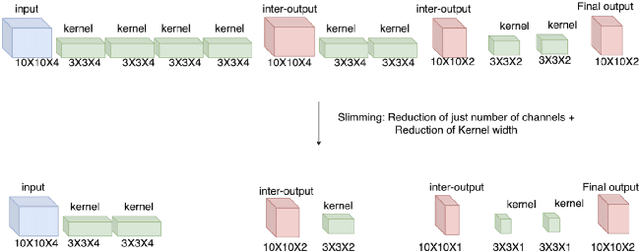
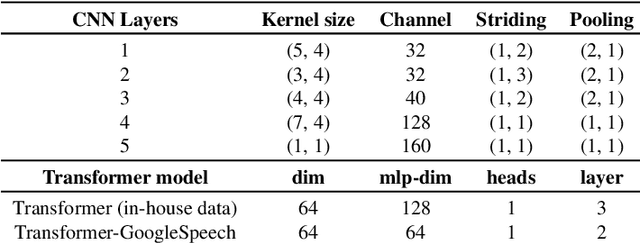
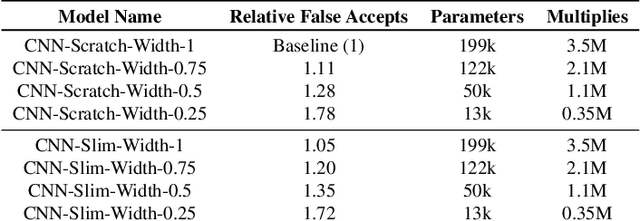
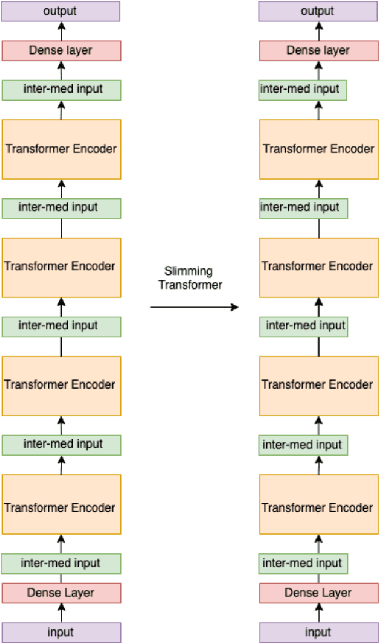
In this work, we present Slimmable Neural Networks applied to the problem of small-footprint keyword spotting. We show that slimmable neural networks allow us to create super-nets from Convolutioanl Neural Networks and Transformers, from which sub-networks of different sizes can be extracted. We demonstrate the usefulness of these models on in-house Alexa data and Google Speech Commands, and focus our efforts on models for the on-device use case, limiting ourselves to less than 250k parameters. We show that slimmable models can match (and in some cases, outperform) models trained from scratch. Slimmable neural networks are therefore a class of models particularly useful when the same functionality is to be replicated at different memory and compute budgets, with different accuracy requirements.
An ASR-free Fluency Scoring Approach with Self-Supervised Learning
Feb 20, 2023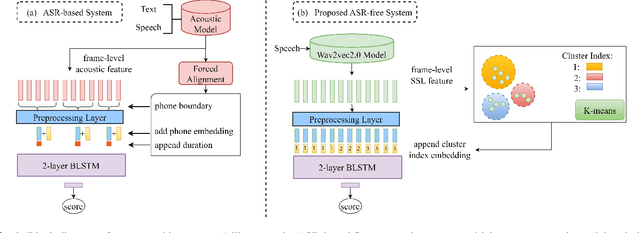
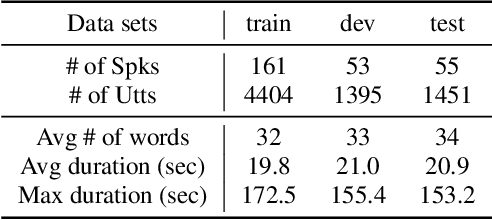
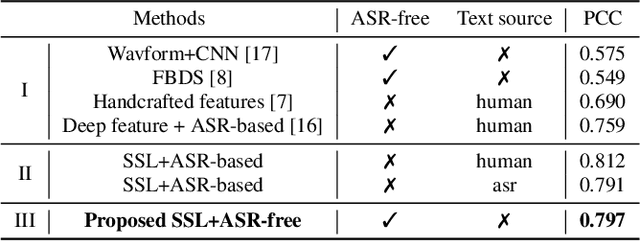
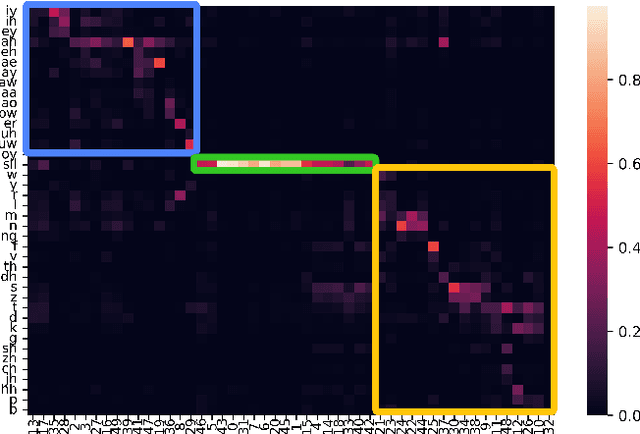
A typical fluency scoring system generally relies on an automatic speech recognition (ASR) system to obtain time stamps in input speech for either the subsequent calculation of fluency-related features or directly modeling speech fluency with an end-to-end approach. This paper describes a novel ASR-free approach for automatic fluency assessment using self-supervised learning (SSL). Specifically, wav2vec2.0 is used to extract frame-level speech features, followed by K-means clustering to assign a pseudo label (cluster index) to each frame. A BLSTM-based model is trained to predict an utterance-level fluency score from frame-level SSL features and the corresponding cluster indexes. Neither speech transcription nor time stamp information is required in the proposed system. It is ASR-free and can potentially avoid the ASR errors effect in practice. Experimental results carried out on non-native English databases show that the proposed approach significantly improves the performance in the "open response" scenario as compared to previous methods and matches the recently reported performance in the "read aloud" scenario.
Assessing ASR Model Quality on Disordered Speech using BERTScore
Sep 21, 2022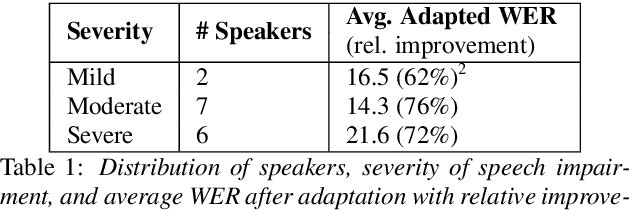
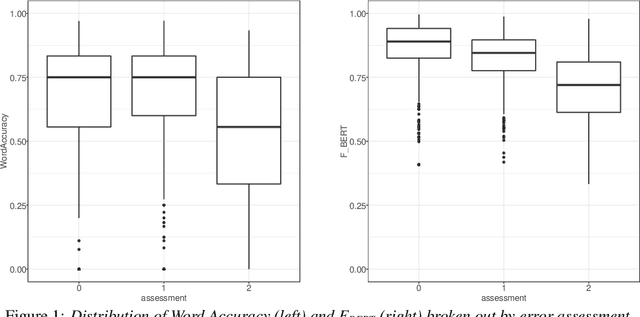
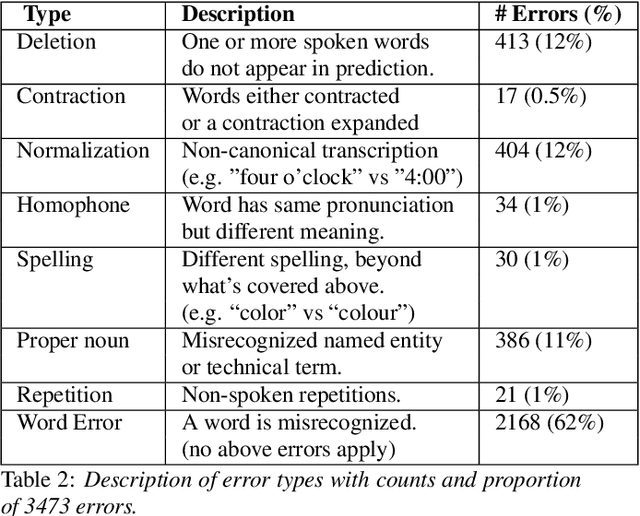
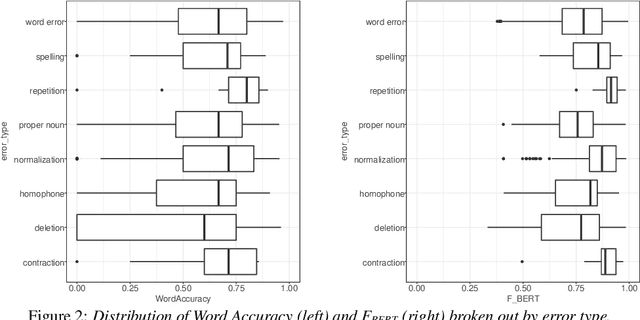
Word Error Rate (WER) is the primary metric used to assess automatic speech recognition (ASR) model quality. It has been shown that ASR models tend to have much higher WER on speakers with speech impairments than typical English speakers. It is hard to determine if models can be be useful at such high error rates. This study investigates the use of BERTScore, an evaluation metric for text generation, to provide a more informative measure of ASR model quality and usefulness. Both BERTScore and WER were compared to prediction errors manually annotated by Speech Language Pathologists for error type and assessment. BERTScore was found to be more correlated with human assessment of error type and assessment. BERTScore was specifically more robust to orthographic changes (contraction and normalization errors) where meaning was preserved. Furthermore, BERTScore was a better fit of error assessment than WER, as measured using an ordinal logistic regression and the Akaike's Information Criterion (AIC). Overall, our findings suggest that BERTScore can complement WER when assessing ASR model performance from a practical perspective, especially for accessibility applications where models are useful even at lower accuracy than for typical speech.
PhaseAug: A Differentiable Augmentation for Speech Synthesis to Simulate One-to-Many Mapping
Nov 08, 2022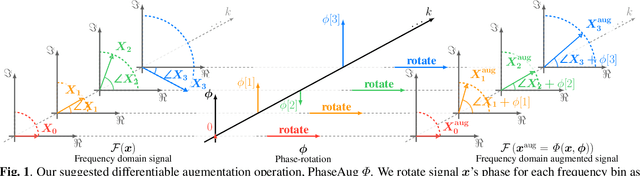
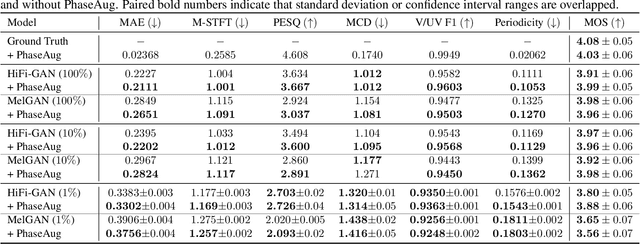
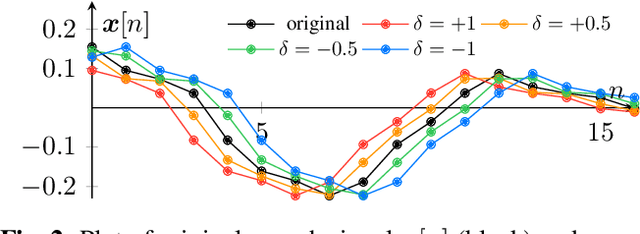
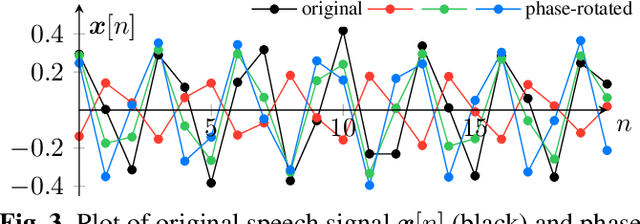
Previous generative adversarial network (GAN)-based neural vocoders are trained to reconstruct the exact ground truth waveform from the paired mel-spectrogram and do not consider the one-to-many relationship of speech synthesis. This conventional training causes overfitting for both the discriminators and the generator, leading to the periodicity artifacts in the generated audio signal. In this work, we present PhaseAug, the first differentiable augmentation for speech synthesis that rotates the phase of each frequency bin to simulate one-to-many mapping. With our proposed method, we outperform baselines without any architecture modification. Code and audio samples will be available at https://github.com/mindslab-ai/phaseaug.
Evaluating gesture-generation in a large-scale open challenge: The GENEA Challenge 2022
Mar 15, 2023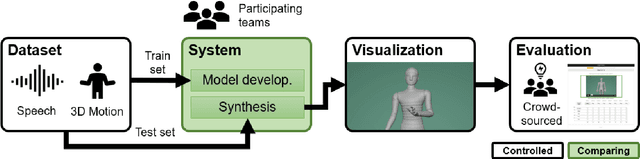
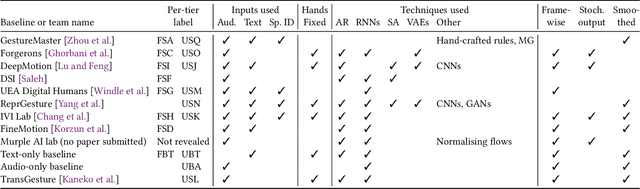
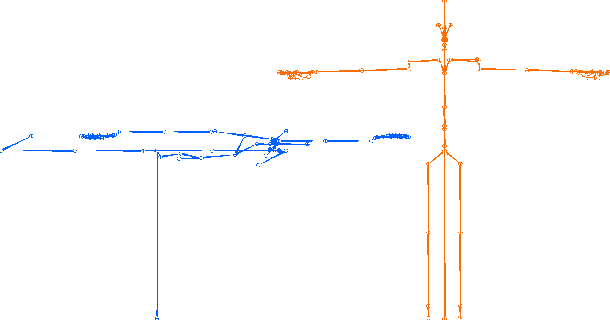
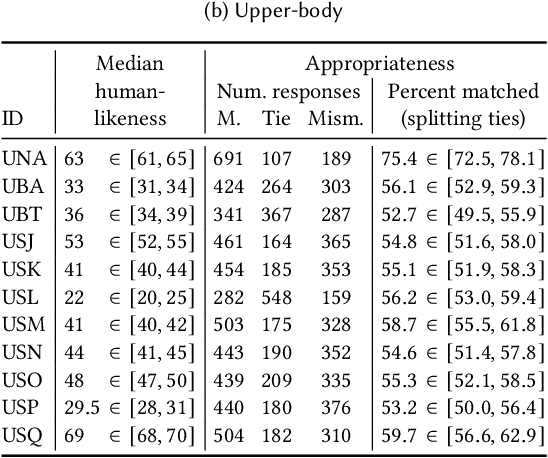
This paper reports on the second GENEA Challenge to benchmark data-driven automatic co-speech gesture generation. Participating teams used the same speech and motion dataset to build gesture-generation systems. Motion generated by all these systems was rendered to video using a standardised visualisation pipeline and evaluated in several large, crowdsourced user studies. Unlike when comparing different research papers, differences in results are here only due to differences between methods, enabling direct comparison between systems. The dataset was based on 18 hours of full-body motion capture, including fingers, of different persons engaging in a dyadic conversation. Ten teams participated in the challenge across two tiers: full-body and upper-body gesticulation. For each tier, we evaluated both the human-likeness of the gesture motion and its appropriateness for the specific speech signal. Our evaluations decouple human-likeness from gesture appropriateness, which has been a difficult problem in the field. The evaluation results are a revolution, and a revelation. Some synthetic conditions are rated as significantly more human-like than human motion capture. To the best of our knowledge, this has never been shown before on a high-fidelity avatar. On the other hand, all synthetic motion is found to be vastly less appropriate for the speech than the original motion-capture recordings. We also find that conventional objective metrics do not correlate well with subjective human-likeness ratings in this large evaluation. The one exception is the Fr\'echet gesture distance (FGD), which achieves a Kendall's tau rank correlation of around -0.5. Based on the challenge results we formulate numerous recommendations for system building and evaluation.
Cascading and Direct Approaches to Unsupervised Constituency Parsing on Spoken Sentences
Mar 15, 2023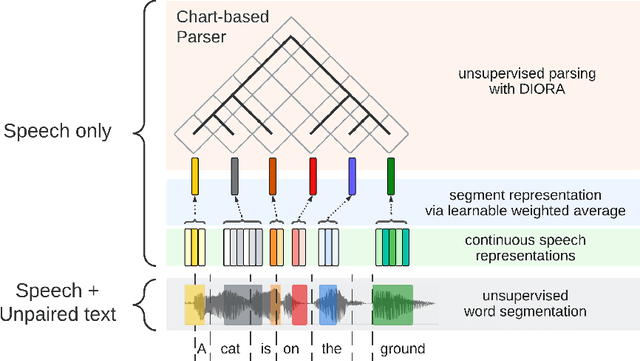
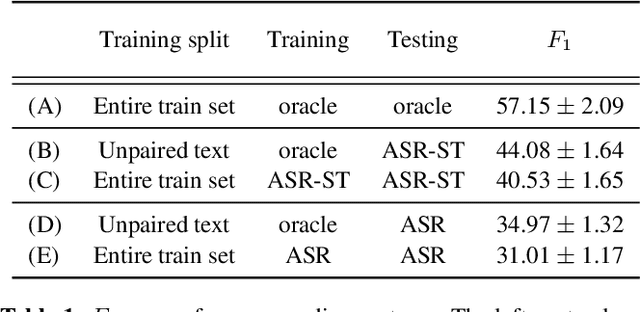
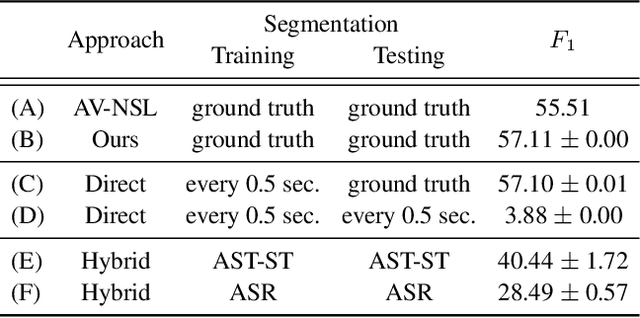
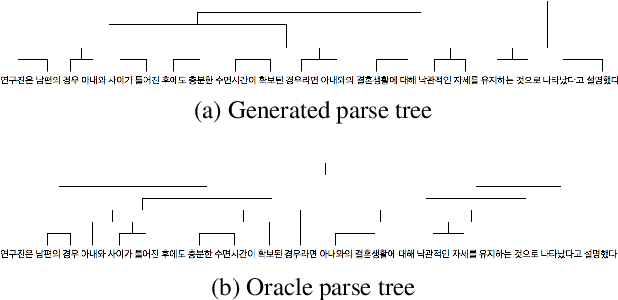
Past work on unsupervised parsing is constrained to written form. In this paper, we present the first study on unsupervised spoken constituency parsing given unlabeled spoken sentences and unpaired textual data. The goal is to determine the spoken sentences' hierarchical syntactic structure in the form of constituency parse trees, such that each node is a span of audio that corresponds to a constituent. We compare two approaches: (1) cascading an unsupervised automatic speech recognition (ASR) model and an unsupervised parser to obtain parse trees on ASR transcripts, and (2) direct training an unsupervised parser on continuous word-level speech representations. This is done by first splitting utterances into sequences of word-level segments, and aggregating self-supervised speech representations within segments to obtain segment embeddings. We find that separately training a parser on the unpaired text and directly applying it on ASR transcripts for inference produces better results for unsupervised parsing. Additionally, our results suggest that accurate segmentation alone may be sufficient to parse spoken sentences accurately. Finally, we show the direct approach may learn head-directionality correctly for both head-initial and head-final languages without any explicit inductive bias.