 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Subspace Hybrid Beamforming for Head-worn Microphone Arrays
Mar 15, 2023
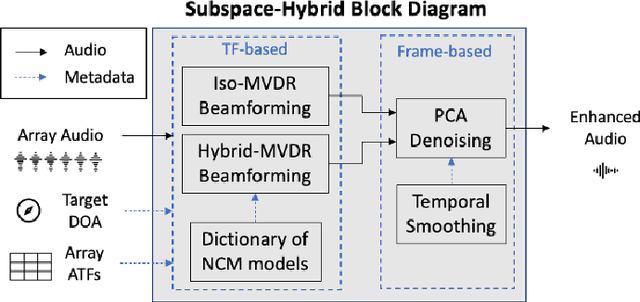
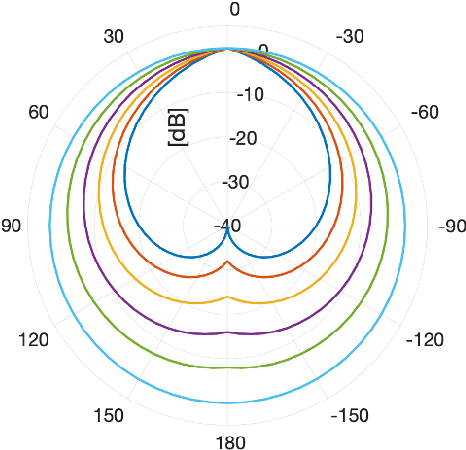
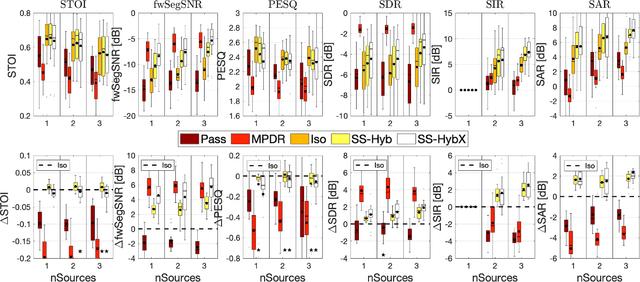
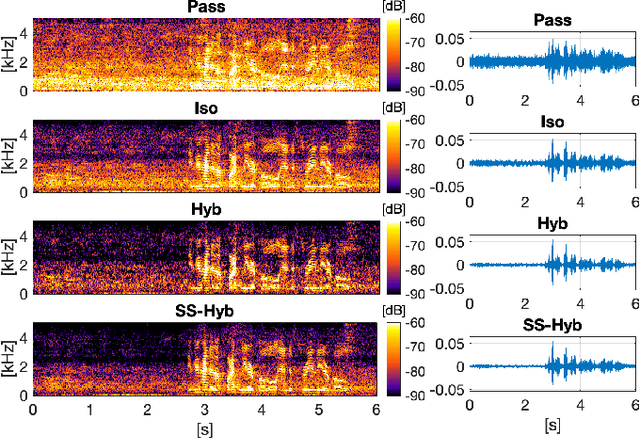
A two-stage multi-channel speech enhancement method is proposed which consists of a novel adaptive beamformer, Hybrid Minimum Variance Distortionless Response (MVDR), Isotropic-MVDR (Iso), and a novel multi-channel spectral Principal Components Analysis (PCA) denoising. In the first stage, the Hybrid-MVDR performs multiple MVDRs using a dictionary of pre-defined noise field models and picks the minimum-power outcome, which benefits from the robustness of signal-independent beamforming and the performance of adaptive beamforming. In the second stage, the outcomes of Hybrid and Iso are jointly used in a two-channel PCA-based denoising to remove the 'musical noise' produced by Hybrid beamformer. On a dataset of real 'cocktail-party' recordings with head-worn array, the proposed method outperforms the baseline superdirective beamformer in noise suppression (fwSegSNR, SDR, SIR, SAR) and speech intelligibility (STOI) with similar speech quality (PESQ) improvement.
SpeechBlender: Speech Augmentation Framework for Mispronunciation Data Generation
Nov 02, 2022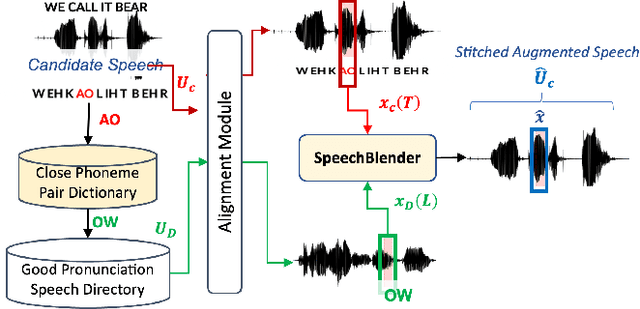

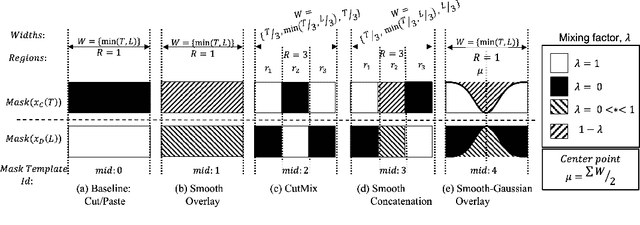
One of the biggest challenges in designing mispronunciation detection models is the unavailability of labeled L2 speech data. To overcome such data scarcity, we introduce SpeechBlender -- a fine-grained data augmentation pipeline for generating mispronunciation errors. The SpeechBlender utilizes varieties of masks to target different regions of a phonetic unit, and use the mixing factors to linearly interpolate raw speech signals while generating erroneous pronunciation instances. The masks facilitate smooth blending of the signals, thus generating more effective samples than the `Cut/Paste' method. We show the effectiveness of our augmentation technique in a phoneme-level pronunciation quality assessment task, leveraging only a good pronunciation dataset. With SpeechBlender augmentation, we observed a 3% and 2% increase in Pearson correlation coefficient (PCC) compared to no-augmentation and goodness of pronunciation augmentation scenarios respectively for Speechocean762 testset. Moreover, a 2% rise in PCC is observed when comparing our single-task phoneme-level mispronunciation detection model with a multi-task learning model using multiple-granularity information.
PITS: Variational Pitch Inference without Fundamental Frequency for End-to-End Pitch-controllable TTS
Feb 24, 2023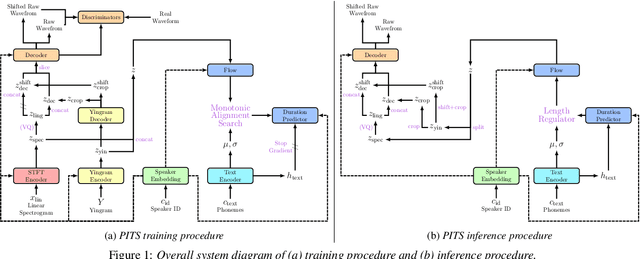
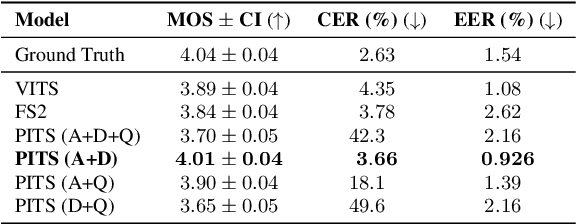
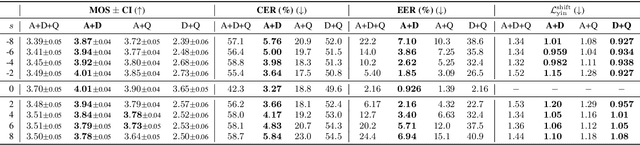
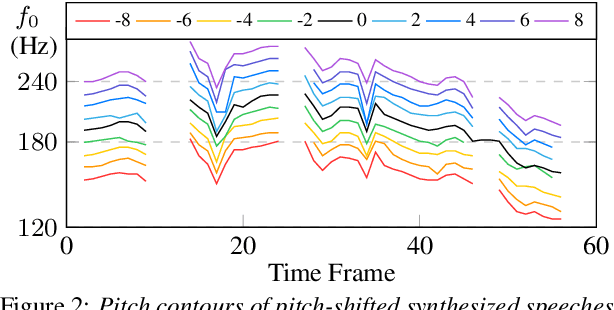
Previous pitch-controllable text-to-speech (TTS) models rely on directly modeling fundamental frequency, leading to low variance in synthesized speech. To address this issue, we propose PITS, an end-to-end pitch-controllable TTS model that utilizes variational inference to model pitch. Based on VITS, PITS incorporates the Yingram encoder, the Yingram decoder, and adversarial training of pitch-shifted synthesis to achieve pitch-controllability. Experiments demonstrate that PITS generates high-quality speech that is indistinguishable from ground truth speech and has high pitch-controllability without quality degradation. Code and audio samples will be available at https://github.com/anonymous-pits/pits.
Temporal Modeling Matters: A Novel Temporal Emotional Modeling Approach for Speech Emotion Recognition
Nov 14, 2022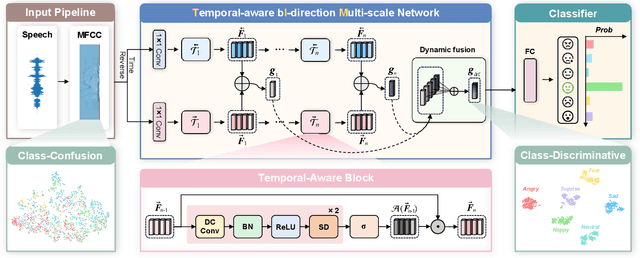
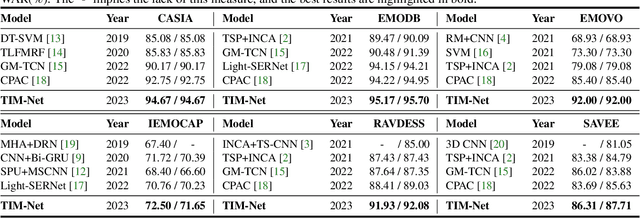


Speech emotion recognition (SER) plays a vital role in improving the interactions between humans and machines by inferring human emotion and affective states from speech signals. Whereas recent works primarily focus on mining spatiotemporal information from hand-crafted features, we explore how to model the temporal patterns of speech emotions from dynamic temporal scales. Towards that goal, we introduce a novel temporal emotional modeling approach for SER, termed Temporal-aware bI-direction Multi-scale Network (TIM-Net), which learns multi-scale contextual affective representations from various time scales. Specifically, TIM-Net first employs temporal-aware blocks to learn temporal affective representation, then integrates complementary information from the past and the future to enrich contextual representations, and finally, fuses multiple time scale features for better adaptation to the emotional variation. Extensive experimental results on six benchmark SER datasets demonstrate the superior performance of TIM-Net, gaining 2.34% and 2.61% improvements of the average UAR and WAR over the second-best on each corpus. Remarkably, TIM-Net outperforms the latest domain-adaptation method on the cross-corpus SER tasks, demonstrating strong generalizability.
RedApt: An Adaptor for wav2vec 2 Encoding \\ Faster and Smaller Speech Translation without Quality Compromise
Oct 16, 2022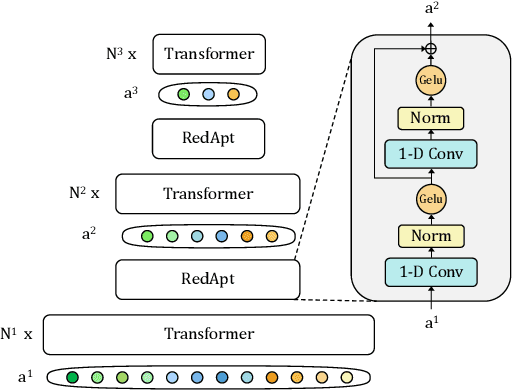
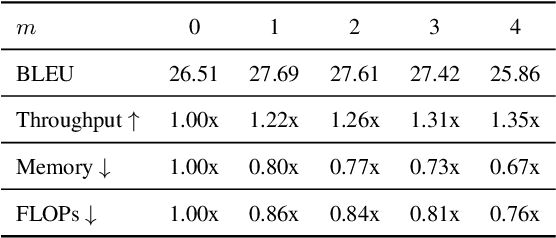
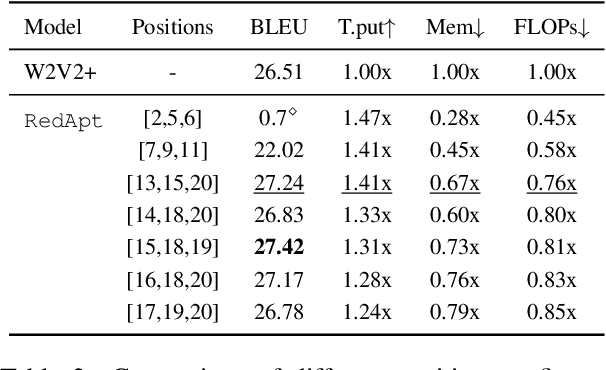
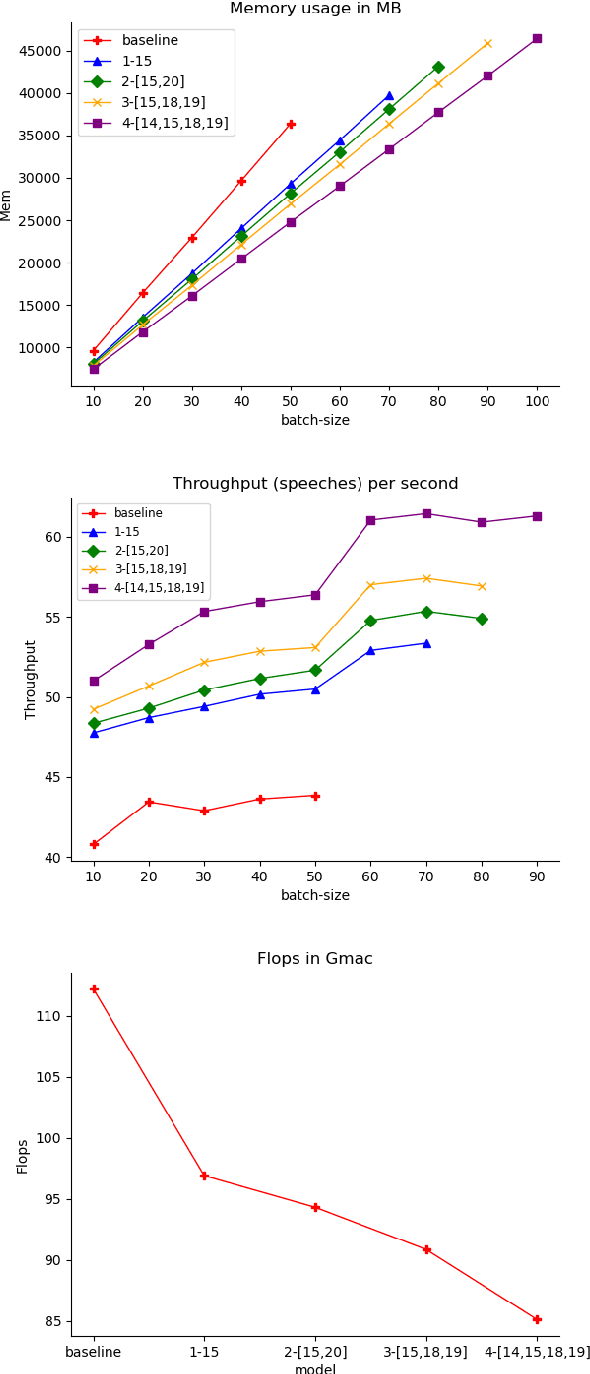
Pre-trained speech Transformers in speech translation (ST) have facilitated state-of-the-art (SotA) results; yet, using such encoders is computationally expensive. To improve this, we present a novel Reducer Adaptor block, RedApt, that could be seamlessly integrated within any Transformer-based speech encoding architecture. Integrating the pretrained wav2vec 2 speech encoder with RedAptbrings 41% speedup, 33% memory reduction with 24% fewer FLOPs at inference. To our positive surprise, our ST model with RedApt outperforms the SotA architecture by an average of 0.68 BLEU score on 8 language pairs from Must-C.
Deep Visual Forced Alignment: Learning to Align Transcription with Talking Face Video
Feb 27, 2023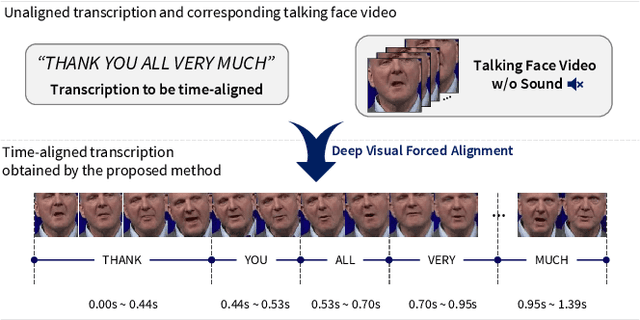
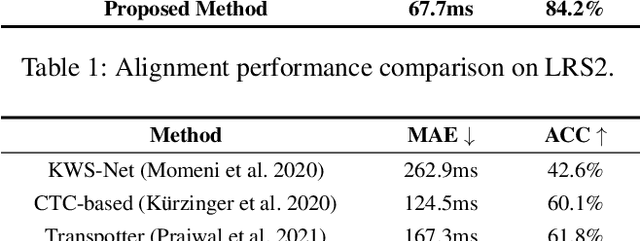
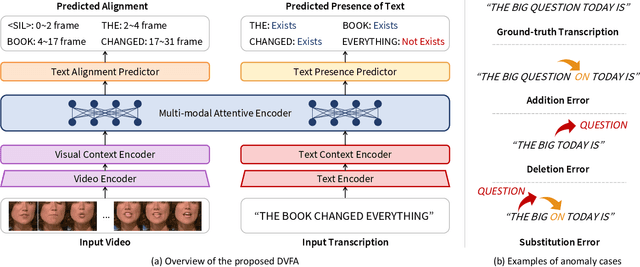
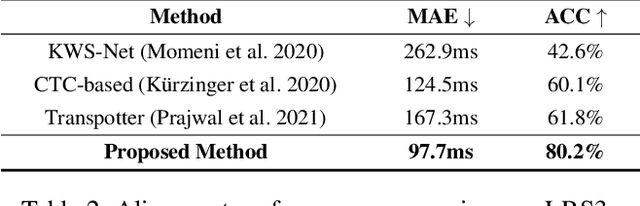
Forced alignment refers to a technology that time-aligns a given transcription with a corresponding speech. However, as the forced alignment technologies have developed using speech audio, they might fail in alignment when the input speech audio is noise-corrupted or is not accessible. We focus on that there is another component that the speech can be inferred from, the speech video (i.e., talking face video). Since the drawbacks of audio-based forced alignment can be complemented using the visual information when the audio signal is under poor condition, we try to develop a novel video-based forced alignment method. However, different from audio forced alignment, it is challenging to develop a reliable visual forced alignment technology for the following two reasons: 1) Visual Speech Recognition (VSR) has a much lower performance compared to audio-based Automatic Speech Recognition (ASR), and 2) the translation from text to video is not reliable, so the method typically used for building audio forced alignment cannot be utilized in developing visual forced alignment. In order to alleviate these challenges, in this paper, we propose a new method that is appropriate for visual forced alignment, namely Deep Visual Forced Alignment (DVFA). The proposed DVFA can align the input transcription (i.e., sentence) with the talking face video without accessing the speech audio. Moreover, by augmenting the alignment task with anomaly case detection, DVFA can detect mismatches between the input transcription and the input video while performing the alignment. Therefore, we can robustly align the text with the talking face video even if there exist error words in the text. Through extensive experiments, we show the effectiveness of the proposed DVFA not only in the alignment task but also in interpreting the outputs of VSR models.
Leveraging Modality-specific Representations for Audio-visual Speech Recognition via Reinforcement Learning
Dec 10, 2022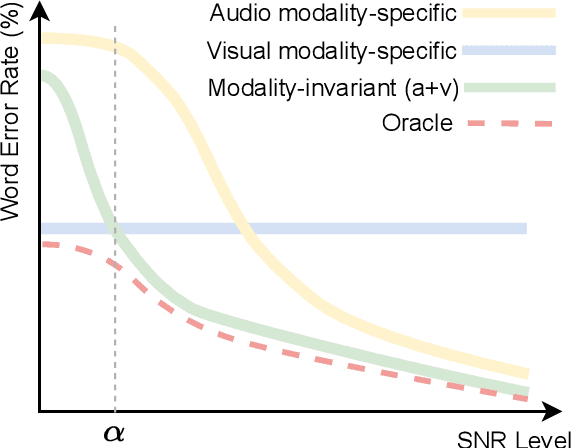

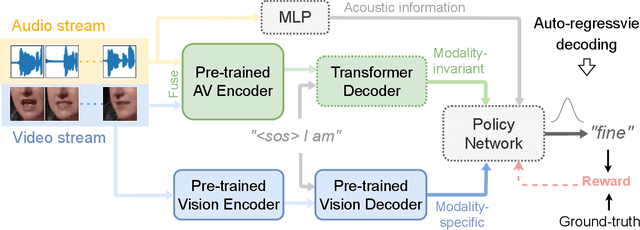
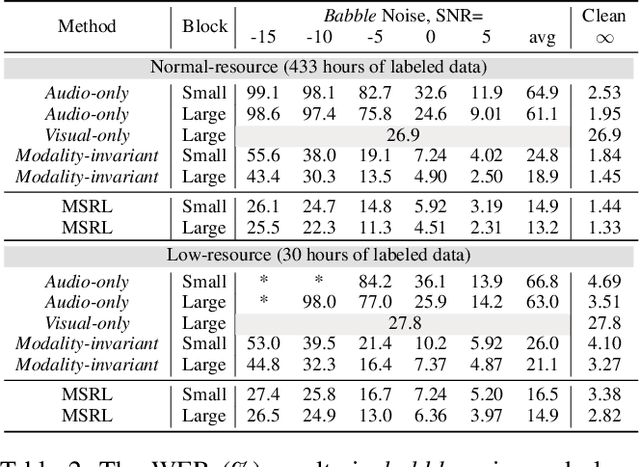
Audio-visual speech recognition (AVSR) has gained remarkable success for ameliorating the noise-robustness of speech recognition. Mainstream methods focus on fusing audio and visual inputs to obtain modality-invariant representations. However, such representations are prone to over-reliance on audio modality as it is much easier to recognize than video modality in clean conditions. As a result, the AVSR model underestimates the importance of visual stream in face of noise corruption. To this end, we leverage visual modality-specific representations to provide stable complementary information for the AVSR task. Specifically, we propose a reinforcement learning (RL) based framework called MSRL, where the agent dynamically harmonizes modality-invariant and modality-specific representations in the auto-regressive decoding process. We customize a reward function directly related to task-specific metrics (i.e., word error rate), which encourages the MSRL to effectively explore the optimal integration strategy. Experimental results on the LRS3 dataset show that the proposed method achieves state-of-the-art in both clean and various noisy conditions. Furthermore, we demonstrate the better generality of MSRL system than other baselines when test set contains unseen noises.
Partially Adaptive Multichannel Joint Reduction of Ego-noise and Environmental Noise
Mar 27, 2023
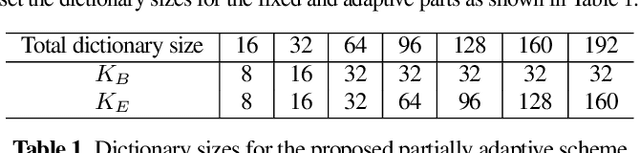
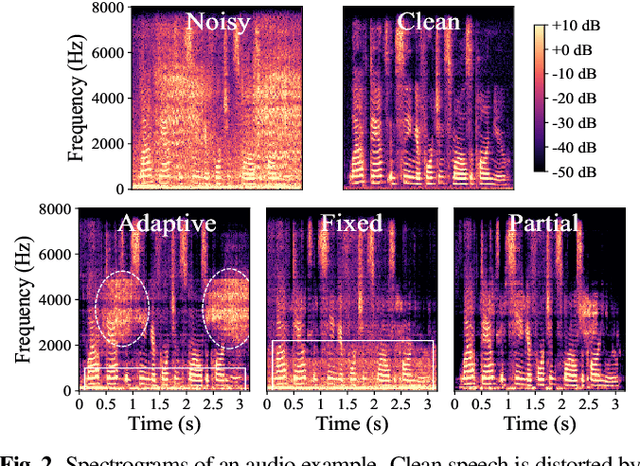
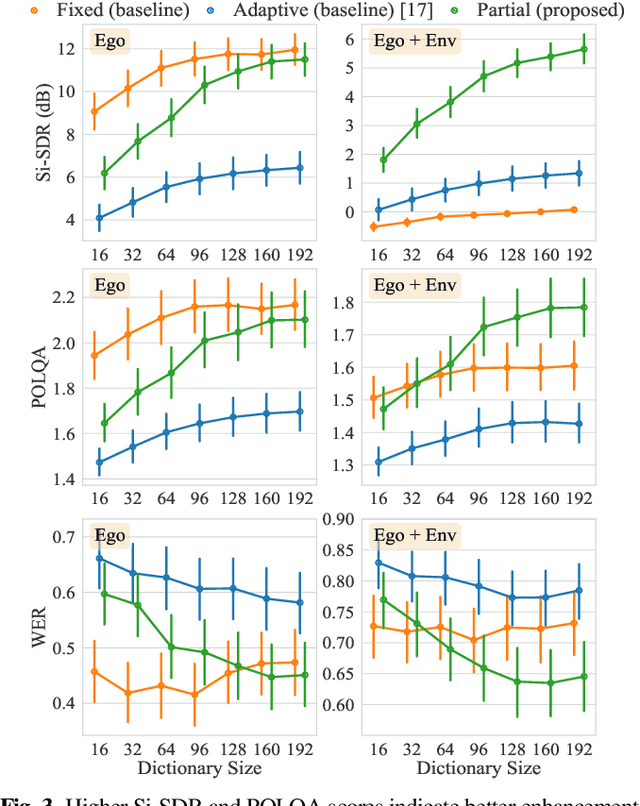
Human-robot interaction relies on a noise-robust audio processing module capable of estimating target speech from audio recordings impacted by environmental noise, as well as self-induced noise, so-called ego-noise. While external ambient noise sources vary from environment to environment, ego-noise is mainly caused by the internal motors and joints of a robot. Ego-noise and environmental noise reduction are often decoupled, i.e., ego-noise reduction is performed without considering environmental noise. Recently, a variational autoencoder (VAE)-based speech model has been combined with a fully adaptive non-negative matrix factorization (NMF) noise model to recover clean speech under different environmental noise disturbances. However, its enhancement performance is limited in adverse acoustic scenarios involving, e.g. ego-noise. In this paper, we propose a multichannel partially adaptive scheme to jointly model ego-noise and environmental noise utilizing the VAE-NMF framework, where we take advantage of spatially and spectrally structured characteristics of ego-noise by pre-training the ego-noise model, while retaining the ability to adapt to unknown environmental noise. Experimental results show that our proposed approach outperforms the methods based on a completely fixed scheme and a fully adaptive scheme when ego-noise and environmental noise are present simultaneously.
* Accepted to the 2023 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2023)
ConceptBeam: Concept Driven Target Speech Extraction
Jul 25, 2022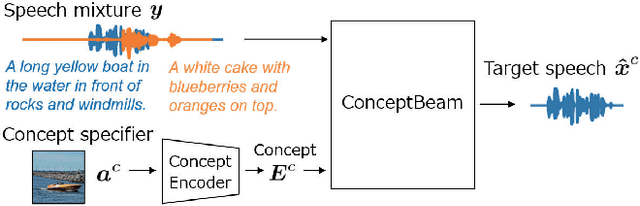

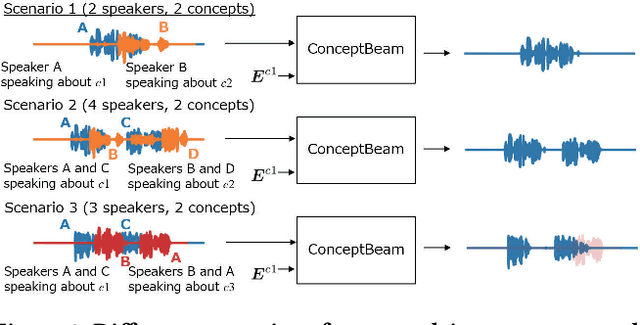

We propose a novel framework for target speech extraction based on semantic information, called ConceptBeam. Target speech extraction means extracting the speech of a target speaker in a mixture. Typical approaches have been exploiting properties of audio signals, such as harmonic structure and direction of arrival. In contrast, ConceptBeam tackles the problem with semantic clues. Specifically, we extract the speech of speakers speaking about a concept, i.e., a topic of interest, using a concept specifier such as an image or speech. Solving this novel problem would open the door to innovative applications such as listening systems that focus on a particular topic discussed in a conversation. Unlike keywords, concepts are abstract notions, making it challenging to directly represent a target concept. In our scheme, a concept is encoded as a semantic embedding by mapping the concept specifier to a shared embedding space. This modality-independent space can be built by means of deep metric learning using paired data consisting of images and their spoken captions. We use it to bridge modality-dependent information, i.e., the speech segments in the mixture, and the specified, modality-independent concept. As a proof of our scheme, we performed experiments using a set of images associated with spoken captions. That is, we generated speech mixtures from these spoken captions and used the images or speech signals as the concept specifiers. We then extracted the target speech using the acoustic characteristics of the identified segments. We compare ConceptBeam with two methods: one based on keywords obtained from recognition systems and another based on sound source separation. We show that ConceptBeam clearly outperforms the baseline methods and effectively extracts speech based on the semantic representation.
Emotional Expression Detection in Spoken Language Employing Machine Learning Algorithms
Apr 20, 2023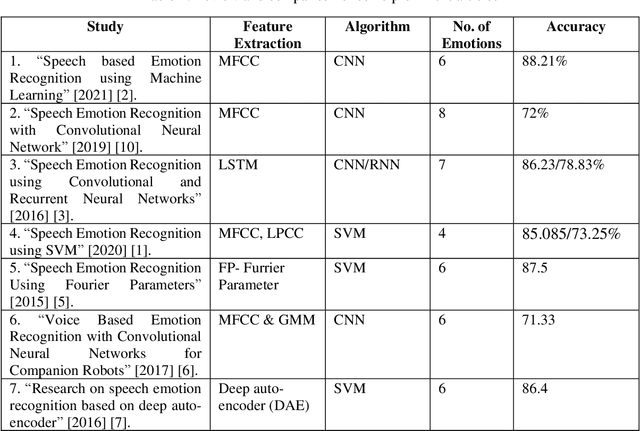
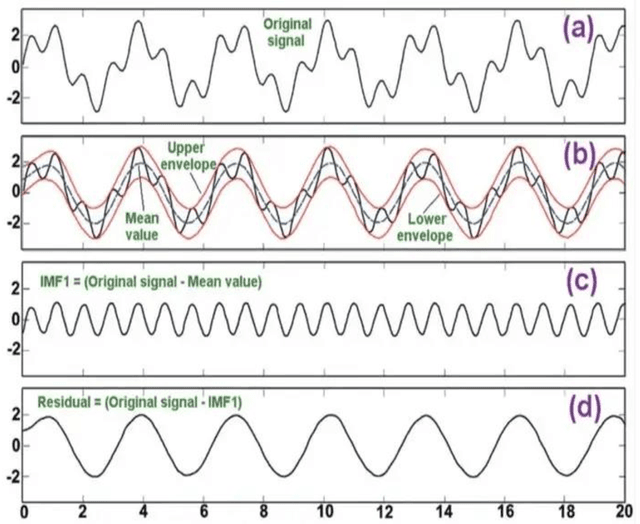
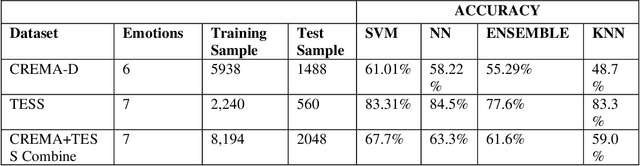
There are a variety of features of the human voice that can be classified as pitch, timbre, loudness, and vocal tone. It is observed in numerous incidents that human expresses their feelings using different vocal qualities when they are speaking. The primary objective of this research is to recognize different emotions of human beings such as anger, sadness, fear, neutrality, disgust, pleasant surprise, and happiness by using several MATLAB functions namely, spectral descriptors, periodicity, and harmonicity. To accomplish the work, we analyze the CREMA-D (Crowd-sourced Emotional Multimodal Actors Data) & TESS (Toronto Emotional Speech Set) datasets of human speech. The audio file contains data that have various characteristics (e.g., noisy, speedy, slow) thereby the efficiency of the ML (Machine Learning) models increases significantly. The EMD (Empirical Mode Decomposition) is utilized for the process of signal decomposition. Then, the features are extracted through the use of several techniques such as the MFCC, GTCC, spectral centroid, roll-off point, entropy, spread, flux, harmonic ratio, energy, skewness, flatness, and audio delta. The data is trained using some renowned ML models namely, Support Vector Machine, Neural Network, Ensemble, and KNN. The algorithms show an accuracy of 67.7%, 63.3%, 61.6%, and 59.0% respectively for the test data and 77.7%, 76.1%, 99.1%, and 61.2% for the training data. We have conducted experiments using Matlab and the result shows that our model is very prominent and flexible than existing similar works.