 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Visual Information Matters for ASR Error Correction
Mar 16, 2023
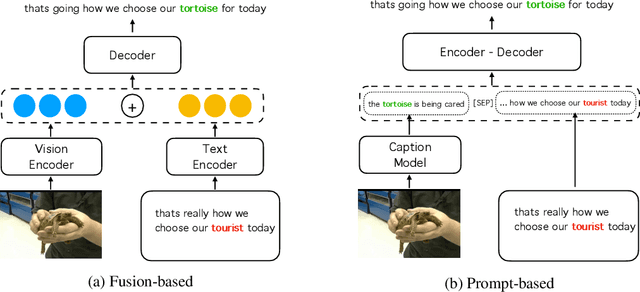
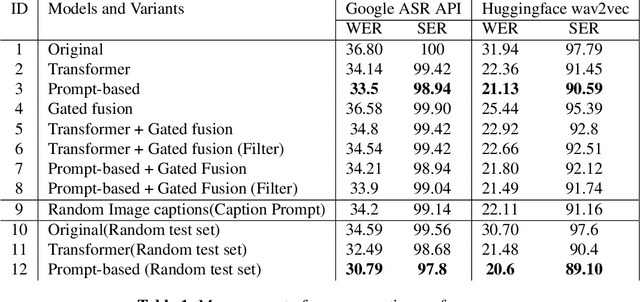


Aiming to improve the Automatic Speech Recognition (ASR) outputs with a post-processing step, ASR error correction (EC) techniques have been widely developed due to their efficiency in using parallel text data. Previous works mainly focus on using text or/ and speech data, which hinders the performance gain when not only text and speech information, but other modalities, such as visual information are critical for EC. The challenges are mainly two folds: one is that previous work fails to emphasize visual information, thus rare exploration has been studied. The other is that the community lacks a high-quality benchmark where visual information matters for the EC models. Therefore, this paper provides 1) simple yet effective methods, namely gated fusion and image captions as prompts to incorporate visual information to help EC; 2) large-scale benchmark datasets, namely Visual-ASR-EC, where each item in the training data consists of visual, speech, and text information, and the test data are carefully selected by human annotators to ensure that even humans could make mistakes when visual information is missing. Experimental results show that using captions as prompts could effectively use the visual information and surpass state-of-the-art methods by upto 1.2% in Word Error Rate(WER), which also indicates that visual information is critical in our proposed Visual-ASR-EC dataset
Adaptive Speech Quality Aware Complex Neural Network for Acoustic Echo Cancellation with Supervised Contrastive Learning
Nov 09, 2022
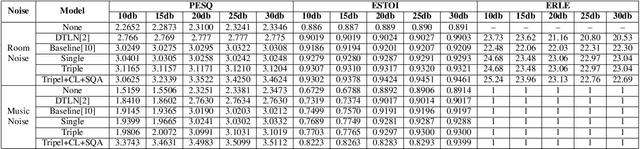
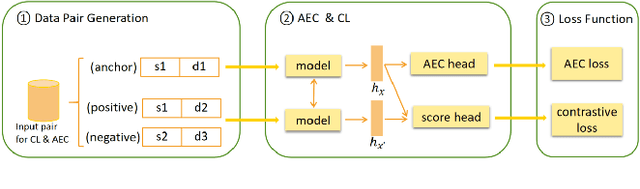
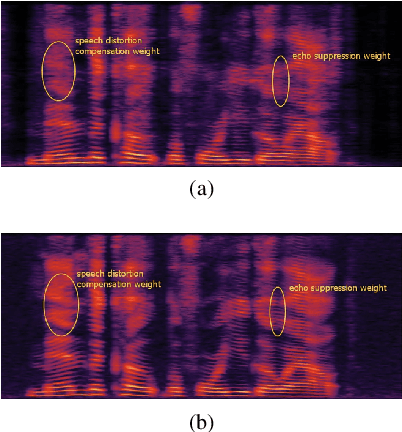
Acoustic echo cancellation (AEC) is designed to remove echoes, reverberation, and unwanted added sounds from the microphone signal while maintaining the quality of the near-end speaker's speech. This paper proposes adaptive speech quality complex neural networks to focus on specific tasks for real-time acoustic echo cancellation. In specific, we propose a complex modularize neural network with different stages to focus on feature extraction, acoustic separation, and mask optimization receptively. Furthermore, we adopt the contrastive learning framework and novel speech quality aware loss functions to further improve the performance. The model is trained with 72 hours for pre-training and then 72 hours for fine-tuning. The proposed model outperforms the state-of-the-art performance.
The Importance of Speech Stimuli for Pathologic Speech Classification
Oct 28, 2022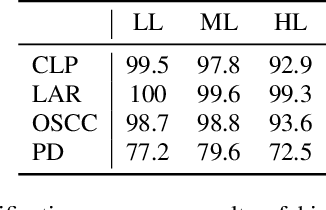

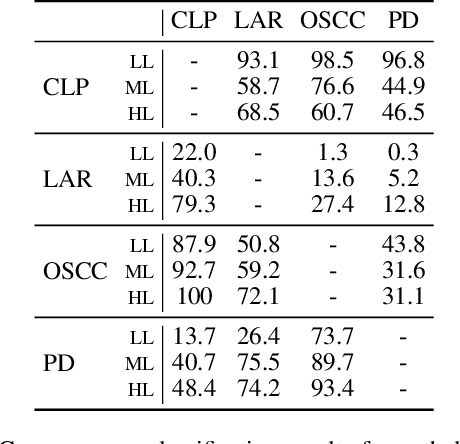
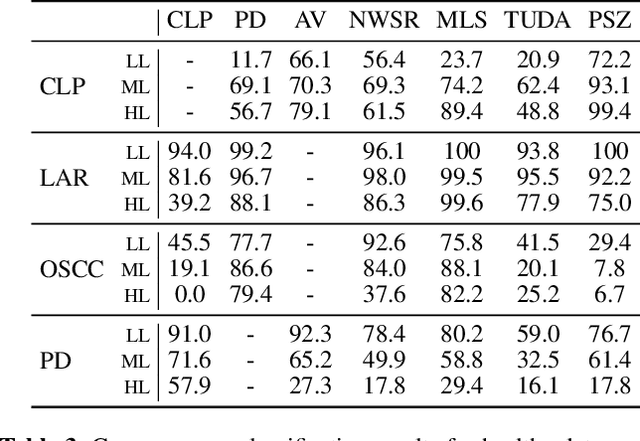
Current findings show that pre-trained wav2vec 2.0 models can be successfully used as feature extractors to discriminate on speaker-based tasks. We demonstrate that latent representations extracted at different layers of a pre-trained wav2vec 2.0 system can be effectively used for binary classification of various types of pathologic speech. We examine the pathologies laryngectomy, oral squamous cell carcinoma, parkinson's disease and cleft lip and palate for this purpose. The results show that a distinction between pathological and healthy voices, especially with latent representations from the lower layers, performs well with the lowest accuracy from 77.2% for parkinson's disease to 100% for laryngectomy classification. However, cross-pathology and cross-healthy tests show that the trained classifiers seem to be biased. The recognition rates vary considerably if there is a mismatch between training and out-of-domain test data, e.g., in age, spoken content or acoustic conditions.
HappyQuokka System for ICASSP 2023 Auditory EEG Challenge
May 03, 2023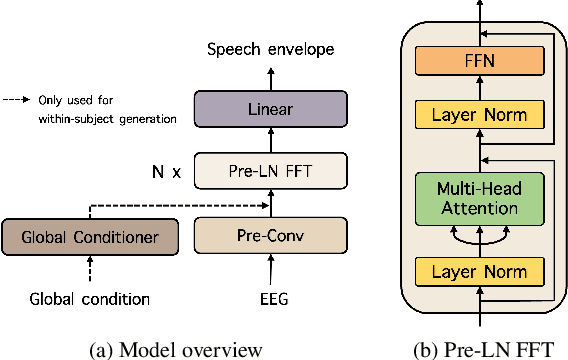
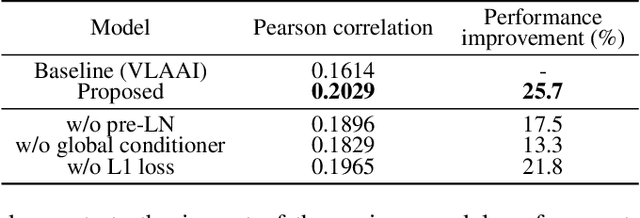
This report describes our submission to Task 2 of the Auditory EEG Decoding Challenge at ICASSP 2023 Signal Processing Grand Challenge (SPGC). Task 2 is a regression problem that focuses on reconstructing a speech envelope from an EEG signal. For the task, we propose a pre-layer normalized feed-forward transformer (FFT) architecture. For within-subjects generation, we additionally utilize an auxiliary global conditioner which provides our model with additional information about seen individuals. Experimental results show that our proposed method outperforms the VLAAI baseline and all other submitted systems. Notably, it demonstrates significant improvements on the within-subjects task, likely thanks to our use of the auxiliary global conditioner. In terms of evaluation metrics set by the challenge, we obtain Pearson correlation values of 0.1895 0.0869 for the within-subjects generation test and 0.0976 0.0444 for the heldout-subjects test. We release the training code for our model online.
What makes a good pause? Investigating the turn-holding effects of fillers
May 03, 2023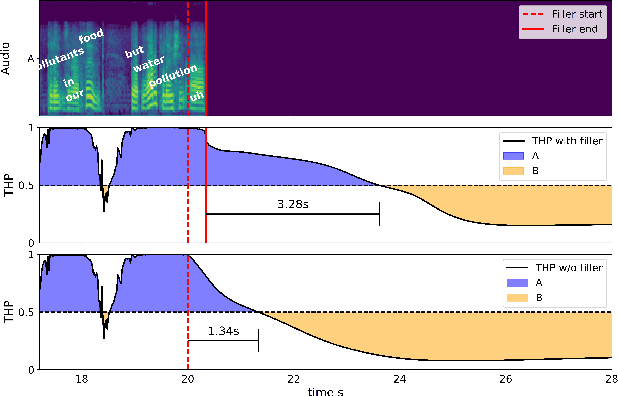
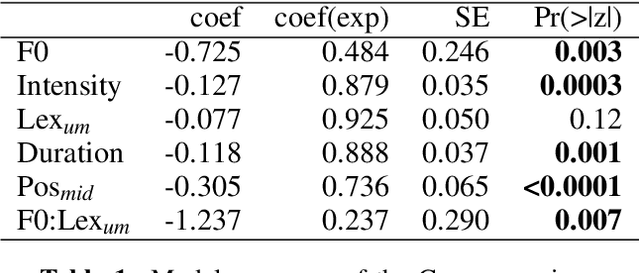

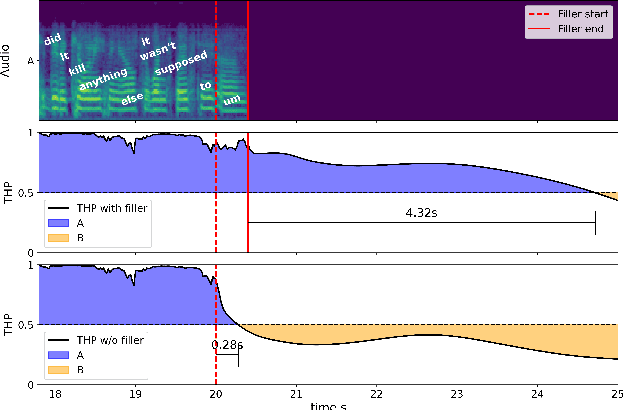
Filled pauses (or fillers), such as "uh" and "um", are frequent in spontaneous speech and can serve as a turn-holding cue for the listener, indicating that the current speaker is not done yet. In this paper, we use the recently proposed Voice Activity Projection (VAP) model, which is a deep learning model trained to predict the dynamics of conversation, to analyse the effects of filled pauses on the expected turn-hold probability. The results show that, while filled pauses do indeed have a turn-holding effect, it is perhaps not as strong as could be expected, probably due to the redundancy of other cues. We also find that the prosodic properties and position of the filler has a significant effect on the turn-hold probability. However, contrary to what has been suggested in previous work, there is no difference between "uh" and "um" in this regard.
Improving generalizability of distilled self-supervised speech processing models under distorted settings
Oct 20, 2022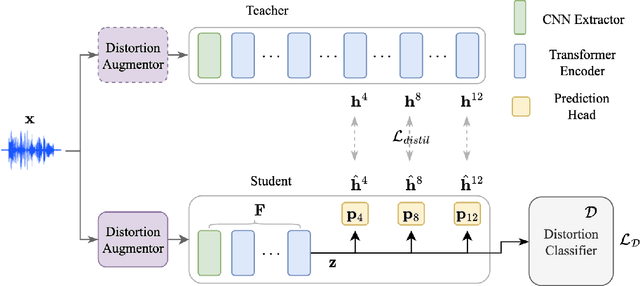
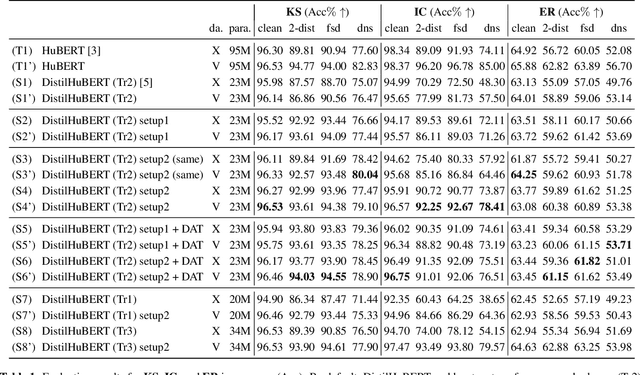
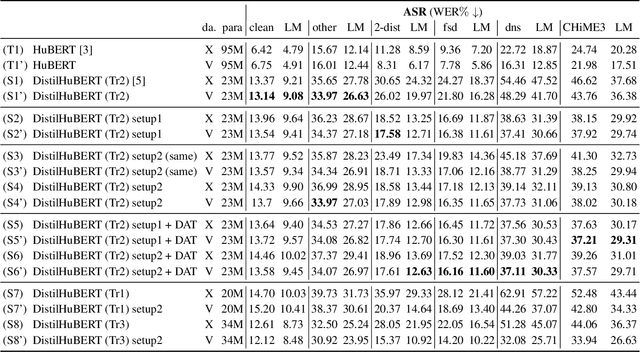
Self-supervised learned (SSL) speech pre-trained models perform well across various speech processing tasks. Distilled versions of SSL models have been developed to match the needs of on-device speech applications. Though having similar performance as original SSL models, distilled counterparts suffer from performance degradation even more than their original versions in distorted environments. This paper proposes to apply Cross-Distortion Mapping and Domain Adversarial Training to SSL models during knowledge distillation to alleviate the performance gap caused by the domain mismatch problem. Results show consistent performance improvements under both in- and out-of-domain distorted setups for different downstream tasks while keeping efficient model size.
Hi,KIA: A Speech Emotion Recognition Dataset for Wake-Up Words
Nov 07, 2022
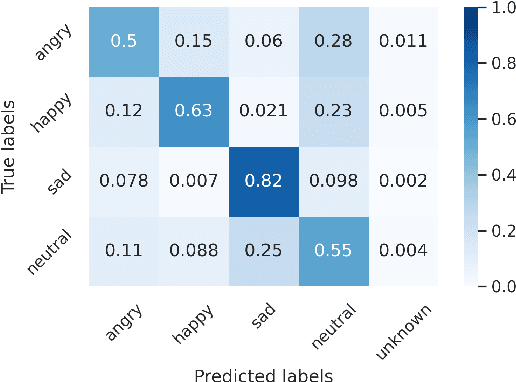
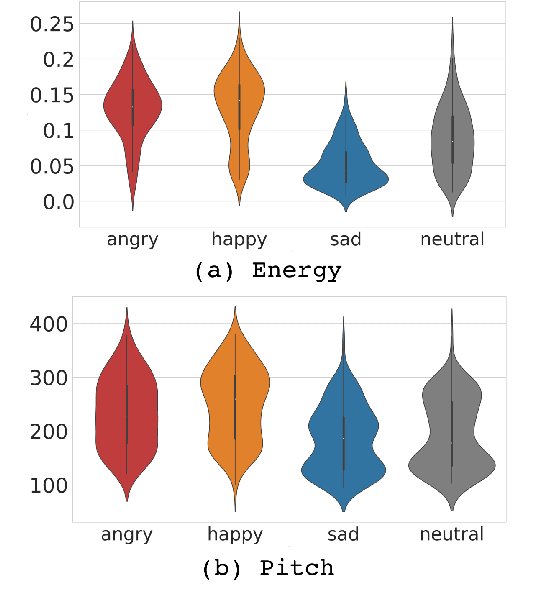
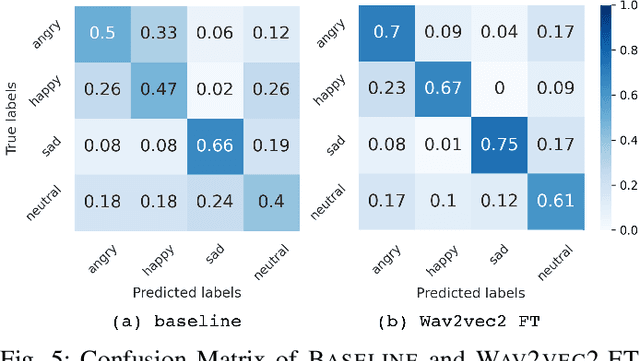
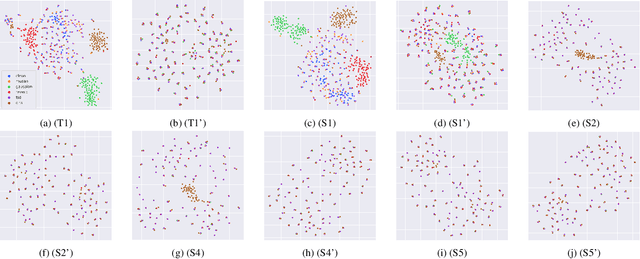
Wake-up words (WUW) is a short sentence used to activate a speech recognition system to receive the user's speech input. WUW utterances include not only the lexical information for waking up the system but also non-lexical information such as speaker identity or emotion. In particular, recognizing the user's emotional state may elaborate the voice communication. However, there is few dataset where the emotional state of the WUW utterances is labeled. In this paper, we introduce Hi, KIA, a new WUW dataset which consists of 488 Korean accent emotional utterances collected from four male and four female speakers and each of utterances is labeled with four emotional states including anger, happy, sad, or neutral. We present the step-by-step procedure to build the dataset, covering scenario selection, post-processing, and human validation for label agreement. Also, we provide two classification models for WUW speech emotion recognition using the dataset. One is based on traditional hand-craft features and the other is a transfer-learning approach using a pre-trained neural network. These classification models could be used as benchmarks in further research.
Huqariq: A Multilingual Speech Corpus of Native Languages of Peru for Speech Recognition
Jul 12, 2022
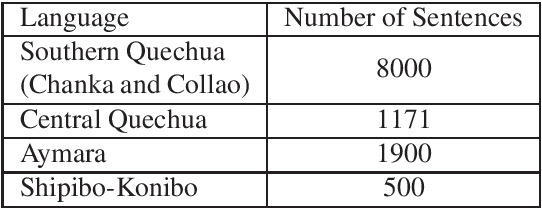
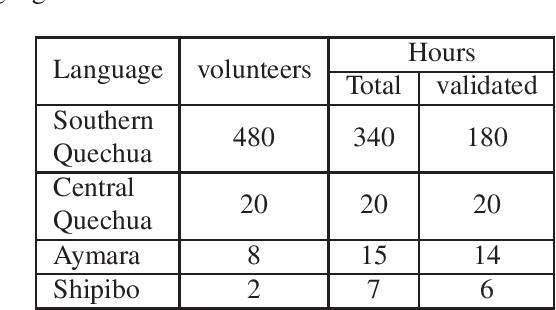
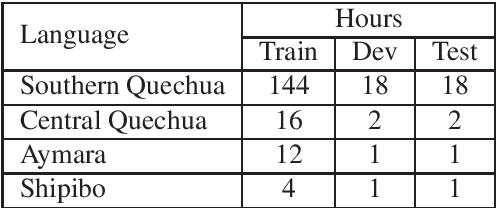
The Huqariq corpus is a multilingual collection of speech from native Peruvian languages. The transcribed corpus is intended for the research and development of speech technologies to preserve endangered languages in Peru. Huqariq is primarily designed for the development of automatic speech recognition, language identification and text-to-speech tools. In order to achieve corpus collection sustainably, we employ the crowdsourcing methodology. Huqariq includes four native languages of Peru, and it is expected that by the end of the year 2022, it can reach up to 20 native languages out of the 48 native languages in Peru. The corpus has 220 hours of transcribed audio recorded by more than 500 volunteers, making it the largest speech corpus for native languages in Peru. In order to verify the quality of the corpus, we present speech recognition experiments using 220 hours of fully transcribed audio.
Leveraging Modality-specific Representations for Audio-visual Speech Recognition via Reinforcement Learning
Dec 10, 2022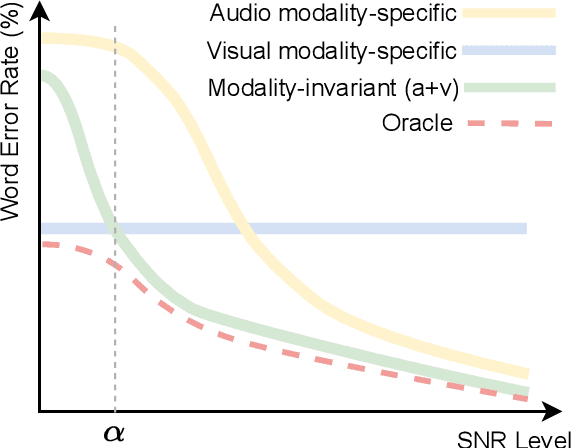

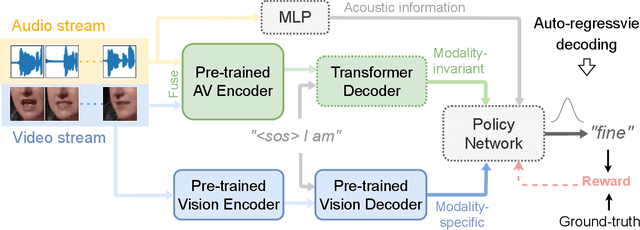
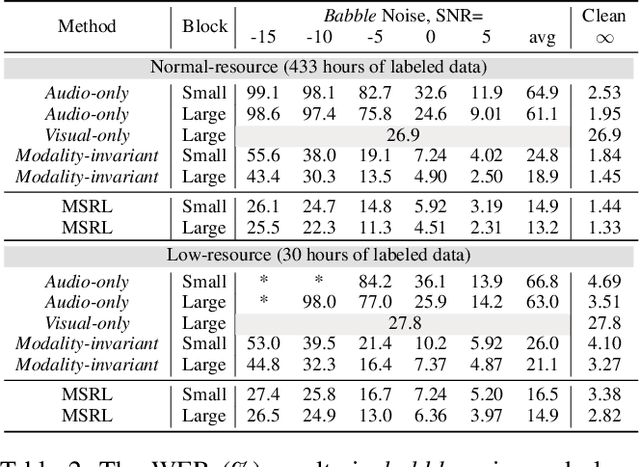
Audio-visual speech recognition (AVSR) has gained remarkable success for ameliorating the noise-robustness of speech recognition. Mainstream methods focus on fusing audio and visual inputs to obtain modality-invariant representations. However, such representations are prone to over-reliance on audio modality as it is much easier to recognize than video modality in clean conditions. As a result, the AVSR model underestimates the importance of visual stream in face of noise corruption. To this end, we leverage visual modality-specific representations to provide stable complementary information for the AVSR task. Specifically, we propose a reinforcement learning (RL) based framework called MSRL, where the agent dynamically harmonizes modality-invariant and modality-specific representations in the auto-regressive decoding process. We customize a reward function directly related to task-specific metrics (i.e., word error rate), which encourages the MSRL to effectively explore the optimal integration strategy. Experimental results on the LRS3 dataset show that the proposed method achieves state-of-the-art in both clean and various noisy conditions. Furthermore, we demonstrate the better generality of MSRL system than other baselines when test set contains unseen noises.
Improving Perceptual Quality, Intelligibility, and Acoustics on VoIP Platforms
Mar 16, 2023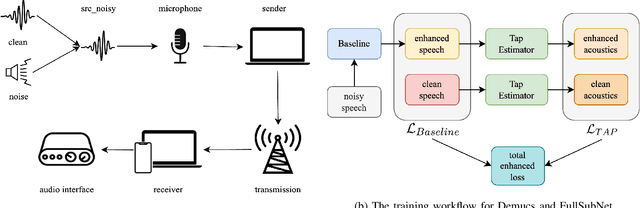
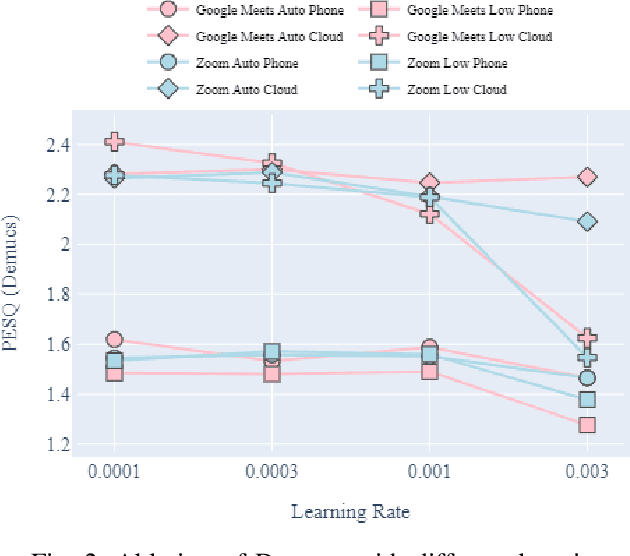
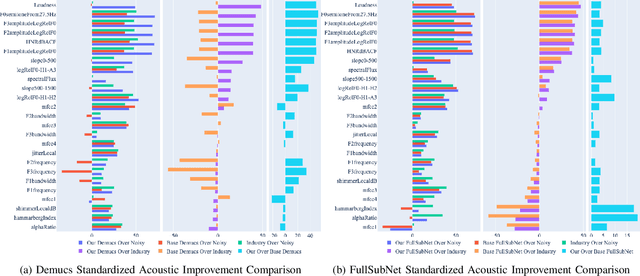

In this paper, we present a method for fine-tuning models trained on the Deep Noise Suppression (DNS) 2020 Challenge to improve their performance on Voice over Internet Protocol (VoIP) applications. Our approach involves adapting the DNS 2020 models to the specific acoustic characteristics of VoIP communications, which includes distortion and artifacts caused by compression, transmission, and platform-specific processing. To this end, we propose a multi-task learning framework for VoIP-DNS that jointly optimizes noise suppression and VoIP-specific acoustics for speech enhancement. We evaluate our approach on a diverse VoIP scenarios and show that it outperforms both industry performance and state-of-the-art methods for speech enhancement on VoIP applications. Our results demonstrate the potential of models trained on DNS-2020 to be improved and tailored to different VoIP platforms using VoIP-DNS, whose findings have important applications in areas such as speech recognition, voice assistants, and telecommunication.