 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Efficient Speech Representation Learning with Low-Bit Quantization
Dec 14, 2022
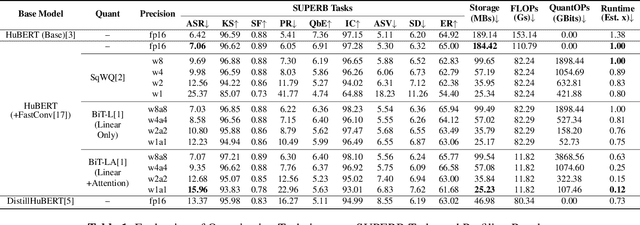

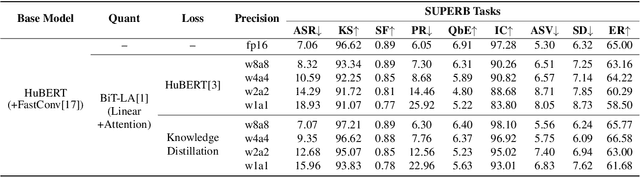
With the development of hardware for machine learning, newer models often come at the cost of both increased sizes and computational complexity. In effort to improve the efficiency for these models, we apply and investigate recent quantization techniques on speech representation learning models. The quantization techniques were evaluated on the SUPERB benchmark. On the ASR task, with aggressive quantization to 1 bit, we achieved 86.32% storage reduction (184.42 -> 25.23), 88% estimated runtime reduction (1.00 -> 0.12) with increased word error rate (7.06 -> 15.96). In comparison with DistillHuBERT which also aims for model compression, the 2-bit configuration yielded slightly smaller storage (35.84 vs. 46.98), better word error rate (12.68 vs. 13.37) and more efficient estimated runtime (0.15 vs. 0.73).
Cross-lingual Alzheimer's Disease detection based on paralinguistic and pre-trained features
Mar 14, 2023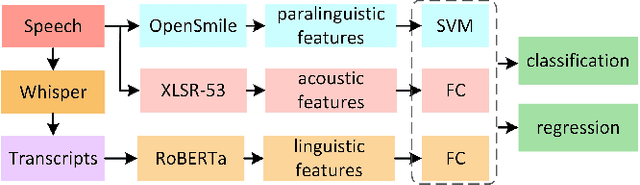
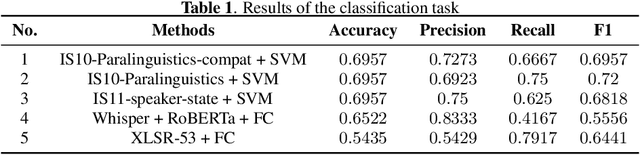
We present our submission to the ICASSP-SPGC-2023 ADReSS-M Challenge Task, which aims to investigate which acoustic features can be generalized and transferred across languages for Alzheimer's Disease (AD) prediction. The challenge consists of two tasks: one is to classify the speech of AD patients and healthy individuals, and the other is to infer Mini Mental State Examination (MMSE) score based on speech only. The difficulty is mainly embodied in the mismatch of the dataset, in which the training set is in English while the test set is in Greek. We extract paralinguistic features using openSmile toolkit and acoustic features using XLSR-53. In addition, we extract linguistic features after transcribing the speech into text. These features are used as indicators for AD detection in our method. Our method achieves an accuracy of 69.6% on the classification task and a root mean squared error (RMSE) of 4.788 on the regression task. The results show that our proposed method is expected to achieve automatic multilingual Alzheimer's Disease detection through spontaneous speech.
AudioSlots: A slot-centric generative model for audio separation
May 09, 2023
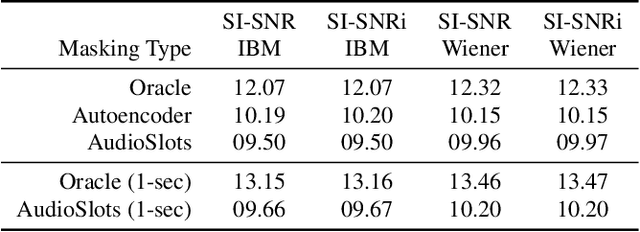
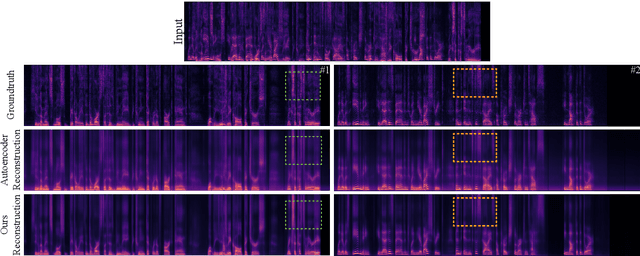
In a range of recent works, object-centric architectures have been shown to be suitable for unsupervised scene decomposition in the vision domain. Inspired by these methods we present AudioSlots, a slot-centric generative model for blind source separation in the audio domain. AudioSlots is built using permutation-equivariant encoder and decoder networks. The encoder network based on the Transformer architecture learns to map a mixed audio spectrogram to an unordered set of independent source embeddings. The spatial broadcast decoder network learns to generate the source spectrograms from the source embeddings. We train the model in an end-to-end manner using a permutation invariant loss function. Our results on Libri2Mix speech separation constitute a proof of concept that this approach shows promise. We discuss the results and limitations of our approach in detail, and further outline potential ways to overcome the limitations and directions for future work.
MVNet: Memory Assistance and Vocal Reinforcement Network for Speech Enhancement
Sep 15, 2022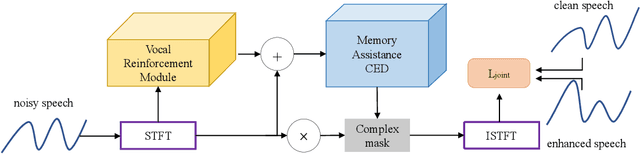
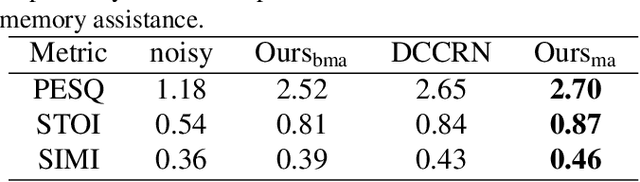
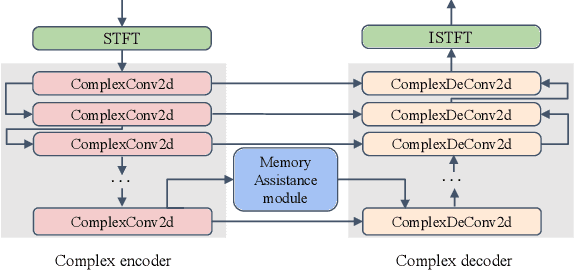
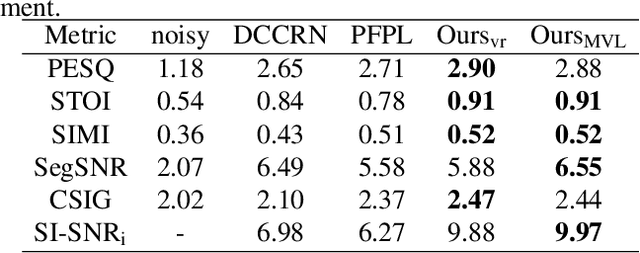
Speech enhancement improves speech quality and promotes the performance of various downstream tasks. However, most current speech enhancement work was mainly devoted to improving the performance of downstream automatic speech recognition (ASR), only a relatively small amount of work focused on the automatic speaker verification (ASV) task. In this work, we propose a MVNet consisted of a memory assistance module which improves the performance of downstream ASR and a vocal reinforcement module which boosts the performance of ASV. In addition, we design a new loss function to improve speaker vocal similarity. Experimental results on the Libri2mix dataset show that our method outperforms baseline methods in several metrics, including speech quality, intelligibility, and speaker vocal similarity et al.
FCTalker: Fine and Coarse Grained Context Modeling for Expressive Conversational Speech Synthesis
Oct 27, 2022
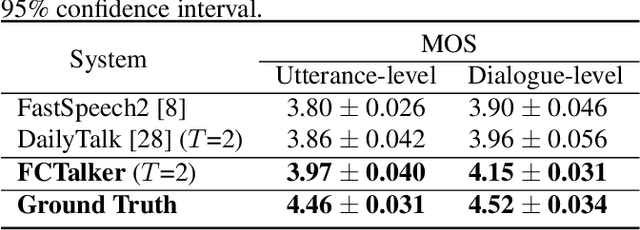
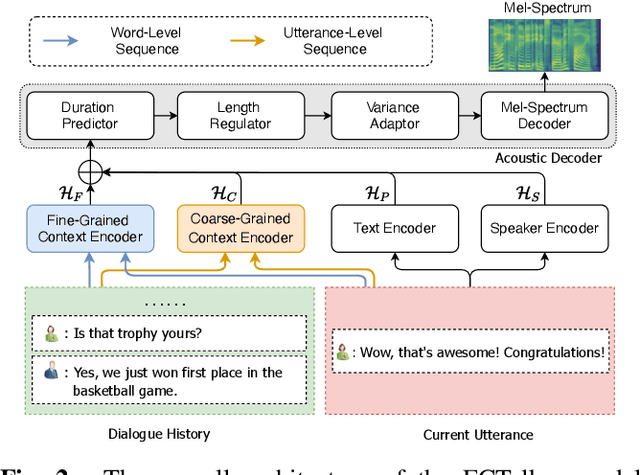
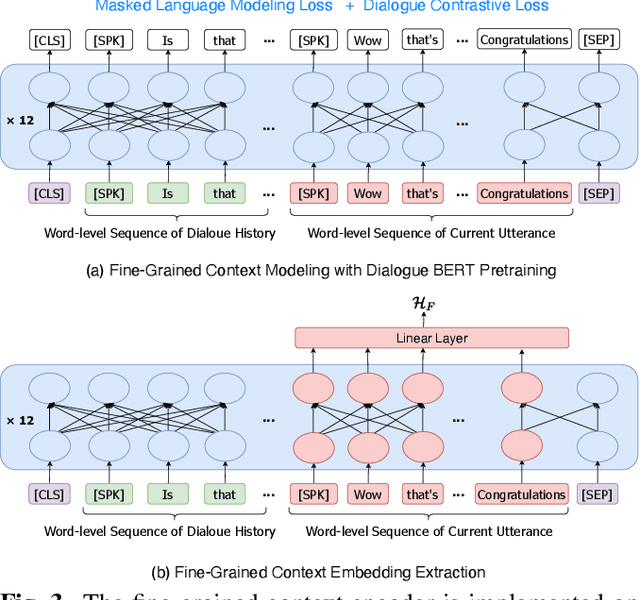
Conversational Text-to-Speech (TTS) aims to synthesis an utterance with the right linguistic and affective prosody in a conversational context. The correlation between the current utterance and the dialogue history at the utterance level was used to improve the expressiveness of synthesized speech. However, the fine-grained information in the dialogue history at the word level also has an important impact on the prosodic expression of an utterance, which has not been well studied in the prior work. Therefore, we propose a novel expressive conversational TTS model, termed as FCTalker, that learn the fine and coarse grained context dependency at the same time during speech generation. Specifically, the FCTalker includes fine and coarse grained encoders to exploit the word and utterance-level context dependency. To model the word-level dependencies between an utterance and its dialogue history, the fine-grained dialogue encoder is built on top of a dialogue BERT model. The experimental results show that the proposed method outperforms all baselines and generates more expressive speech that is contextually appropriate. We release the source code at: https://github.com/walker-hyf/FCTalker.
Text-to-speech synthesis from dark data with evaluation-in-the-loop data selection
Oct 26, 2022This paper proposes a method for selecting training data for text-to-speech (TTS) synthesis from dark data. TTS models are typically trained on high-quality speech corpora that cost much time and money for data collection, which makes it very challenging to increase speaker variation. In contrast, there is a large amount of data whose availability is unknown (a.k.a, "dark data"), such as YouTube videos. To utilize data other than TTS corpora, previous studies have selected speech data from the corpora on the basis of acoustic quality. However, considering that TTS models robust to data noise have been proposed, we should select data on the basis of its importance as training data to the given TTS model, not the quality of speech itself. Our method with a loop of training and evaluation selects training data on the basis of the automatically predicted quality of synthetic speech of a given TTS model. Results of evaluations using YouTube data reveal that our method outperforms the conventional acoustic-quality-based method.
Learning to Jointly Transcribe and Subtitle for End-to-End Spontaneous Speech Recognition
Oct 14, 2022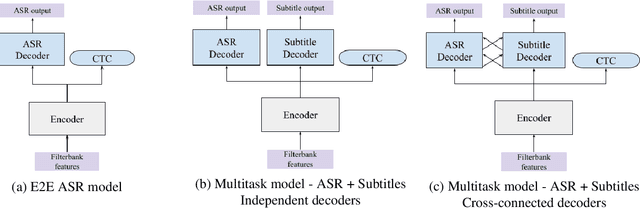
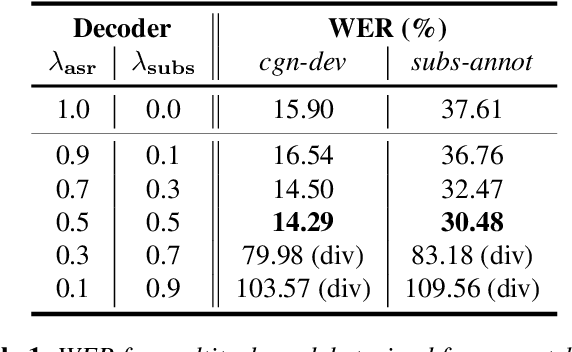

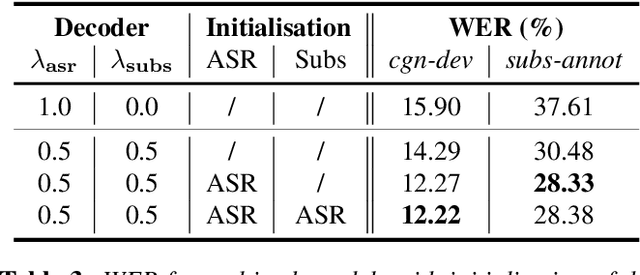
TV subtitles are a rich source of transcriptions of many types of speech, ranging from read speech in news reports to conversational and spontaneous speech in talk shows and soaps. However, subtitles are not verbatim (i.e. exact) transcriptions of speech, so they cannot be used directly to improve an Automatic Speech Recognition (ASR) model. We propose a multitask dual-decoder Transformer model that jointly performs ASR and automatic subtitling. The ASR decoder (possibly pre-trained) predicts the verbatim output and the subtitle decoder generates a subtitle, while sharing the encoder. The two decoders can be independent or connected. The model is trained to perform both tasks jointly, and is able to effectively use subtitle data. We show improvements on regular ASR and on spontaneous and conversational ASR by incorporating the additional subtitle decoder. The method does not require preprocessing (aligning, filtering, pseudo-labeling, ...) of the subtitles.
A Teacher-student Framework for Unsupervised Speech Enhancement Using Noise Remixing Training and Two-stage Inference
Oct 27, 2022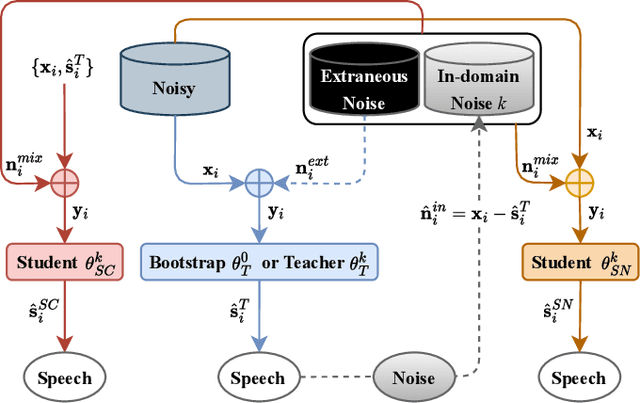

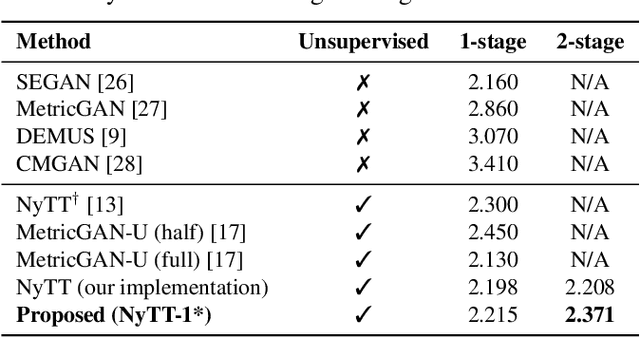
The lack of clean speech is a practical challenge to the development of speech enhancement systems, which means that the training of neural network models must be done in an unsupervised manner, and there is an inevitable mismatch between their training criterion and evaluation metric. In response to this unfavorable situation, we propose a teacher-student training strategy that does not require any subjective/objective speech quality metrics as learning reference by improving the previously proposed noisy-target training (NyTT). Because homogeneity between in-domain noise and extraneous noise is the key to the effectiveness of NyTT, we train various student models by remixing the teacher model's estimated speech and noise for clean-target training or raw noisy speech and the teacher model's estimated noise for noisy-target training. We use the NyTT model as the initial teacher model. Experimental results show that our proposed method outperforms several baselines, especially with two-stage inference, where clean speech is derived successively through the bootstrap model and the final student model.
Automatic Severity Assessment of Dysarthric speech by using Self-supervised Model with Multi-task Learning
Oct 27, 2022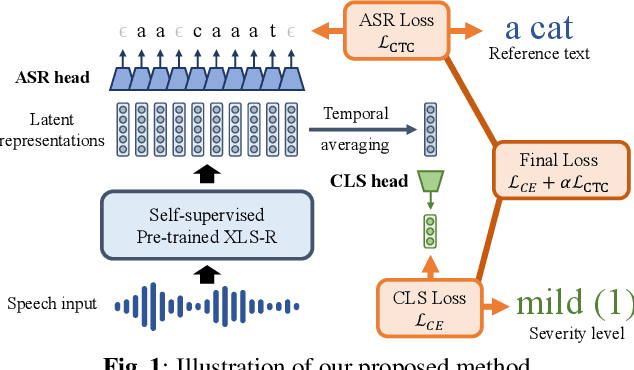

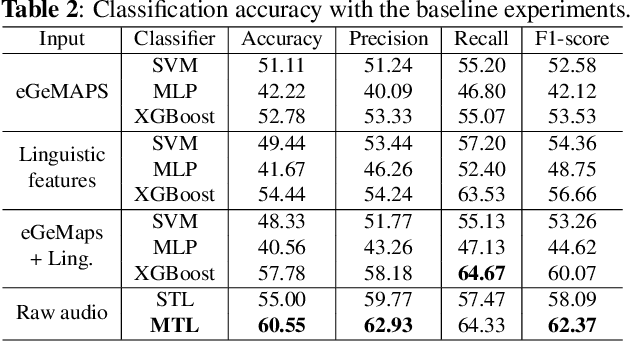
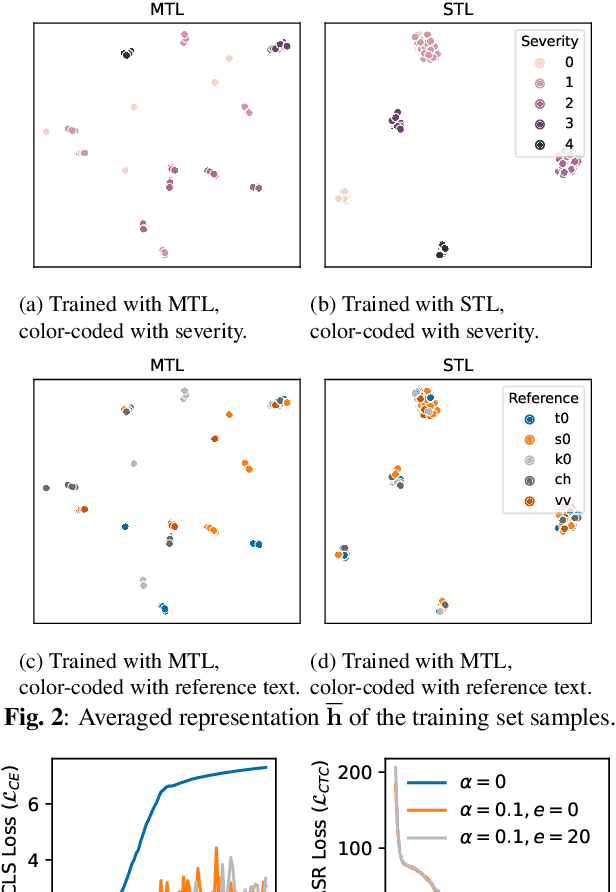
Automatic assessment of dysarthric speech is essential for sustained treatments and rehabilitation. However, obtaining atypical speech is challenging, often leading to data scarcity issues. To tackle the problem, we propose a novel automatic severity assessment method for dysarthric speech, using the self-supervised model in conjunction with multi-task learning. Wav2vec 2.0 XLS-R is jointly trained for two different tasks: severity level classification and an auxilary automatic speech recognition (ASR). For the baseline experiments, we employ hand-crafted features such as eGeMaps and linguistic features, and SVM, MLP, and XGBoost classifiers. Explored on the Korean dysarthric speech QoLT database, our model outperforms the traditional baseline methods, with a relative percentage increase of 4.79% for classification accuracy. In addition, the proposed model surpasses the model trained without ASR head, achieving 10.09% relative percentage improvements. Furthermore, we present how multi-task learning affects the severity classification performance by analyzing the latent representations and regularization effect.
CMGAN: Conformer-Based Metric-GAN for Monaural Speech Enhancement
Sep 23, 2022
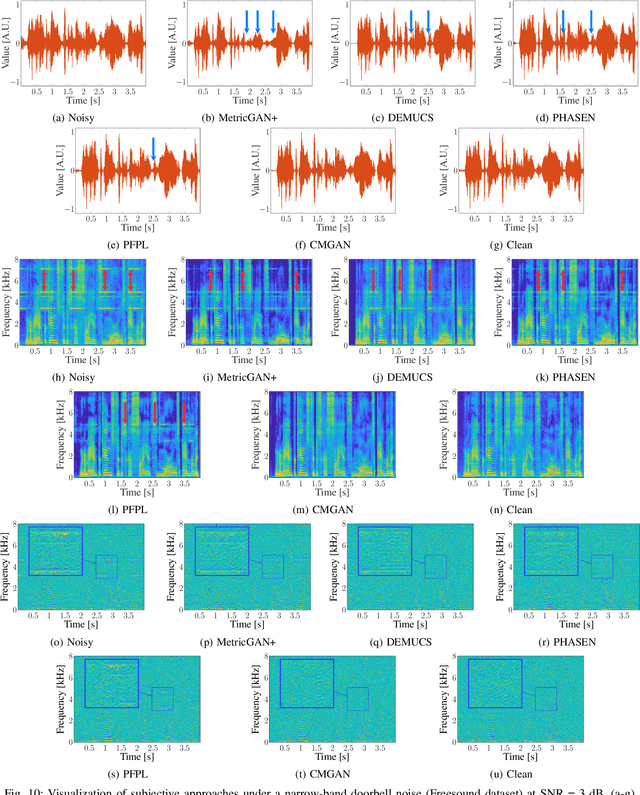
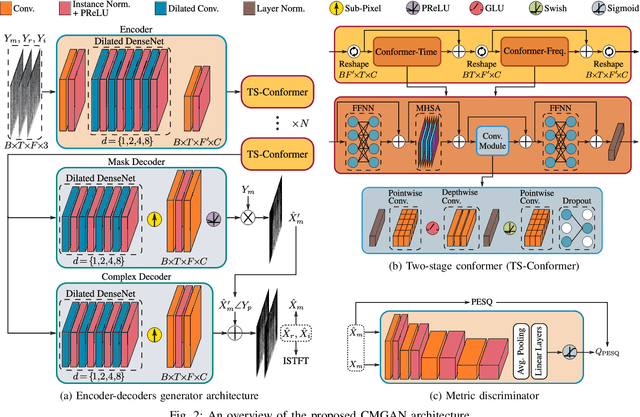
Convolution-augmented transformers (Conformers) are recently proposed in various speech-domain applications, such as automatic speech recognition (ASR) and speech separation, as they can capture both local and global dependencies. In this paper, we propose a conformer-based metric generative adversarial network (CMGAN) for speech enhancement (SE) in the time-frequency (TF) domain. The generator encodes the magnitude and complex spectrogram information using two-stage conformer blocks to model both time and frequency dependencies. The decoder then decouples the estimation into a magnitude mask decoder branch to filter out unwanted distortions and a complex refinement branch to further improve the magnitude estimation and implicitly enhance the phase information. Additionally, we include a metric discriminator to alleviate metric mismatch by optimizing the generator with respect to a corresponding evaluation score. Objective and subjective evaluations illustrate that CMGAN is able to show superior performance compared to state-of-the-art methods in three speech enhancement tasks (denoising, dereverberation and super-resolution). For instance, quantitative denoising analysis on Voice Bank+DEMAND dataset indicates that CMGAN outperforms various previous models with a margin, i.e., PESQ of 3.41 and SSNR of 11.10 dB.