 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
SpokeN-100: A Cross-Lingual Benchmarking Dataset for The Classification of Spoken Numbers in Different Languages
Mar 14, 2024
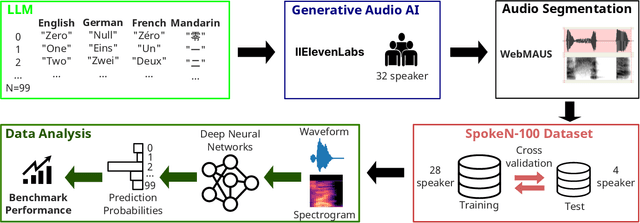
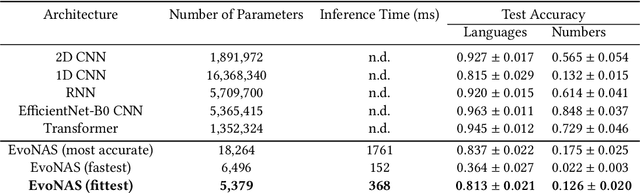
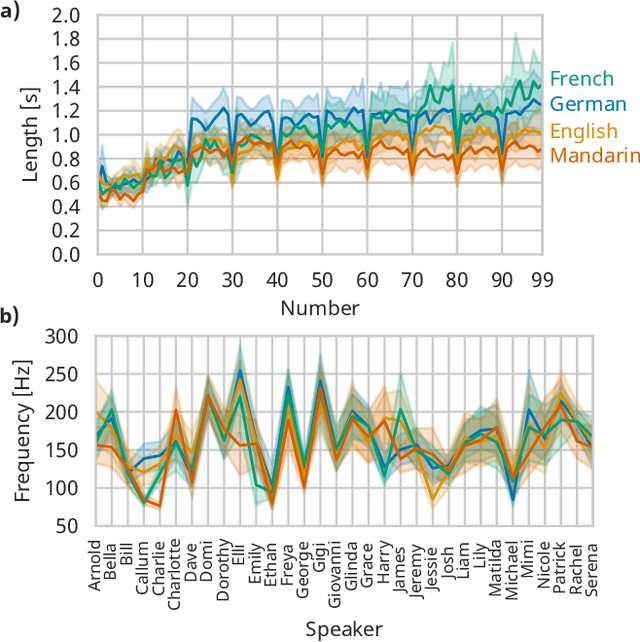
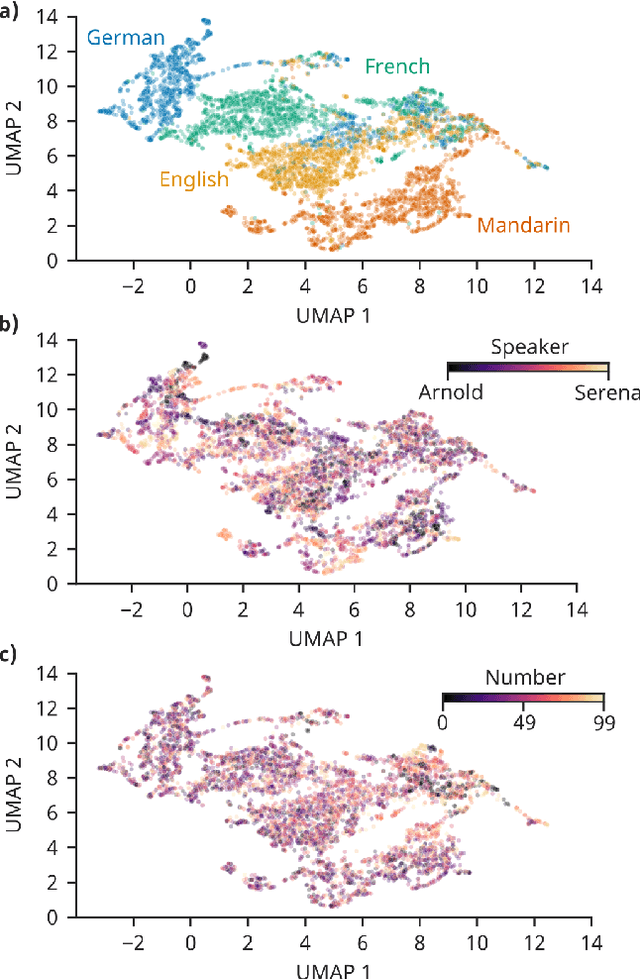
Benchmarking plays a pivotal role in assessing and enhancing the performance of compact deep learning models designed for execution on resource-constrained devices, such as microcontrollers. Our study introduces a novel, entirely artificially generated benchmarking dataset tailored for speech recognition, representing a core challenge in the field of tiny deep learning. SpokeN-100 consists of spoken numbers from 0 to 99 spoken by 32 different speakers in four different languages, namely English, Mandarin, German and French, resulting in 12,800 audio samples. We determine auditory features and use UMAP (Uniform Manifold Approximation and Projection for Dimension Reduction) as a dimensionality reduction method to show the diversity and richness of the dataset. To highlight the use case of the dataset, we introduce two benchmark tasks: given an audio sample, classify (i) the used language and/or (ii) the spoken number. We optimized state-of-the-art deep neural networks and performed an evolutionary neural architecture search to find tiny architectures optimized for the 32-bit ARM Cortex-M4 nRF52840 microcontroller. Our results represent the first benchmark data achieved for SpokeN-100.
On-Device Domain Learning for Keyword Spotting on Low-Power Extreme Edge Embedded Systems
Mar 12, 2024
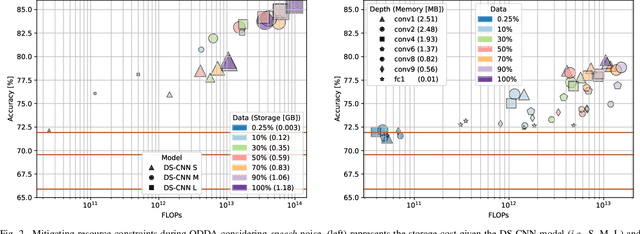

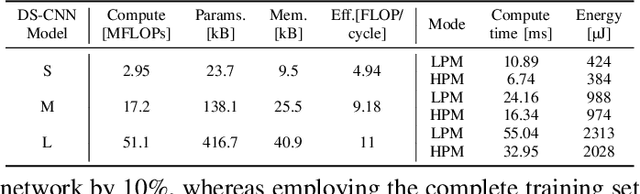
Keyword spotting accuracy degrades when neural networks are exposed to noisy environments. On-site adaptation to previously unseen noise is crucial to recovering accuracy loss, and on-device learning is required to ensure that the adaptation process happens entirely on the edge device. In this work, we propose a fully on-device domain adaptation system achieving up to 14% accuracy gains over already-robust keyword spotting models. We enable on-device learning with less than 10 kB of memory, using only 100 labeled utterances to recover 5% accuracy after adapting to the complex speech noise. We demonstrate that domain adaptation can be achieved on ultra-low-power microcontrollers with as little as 806 mJ in only 14 s on always-on, battery-operated devices.
Refining Knowledge Transfer on Audio-Image Temporal Agreement for Audio-Text Cross Retrieval
Mar 16, 2024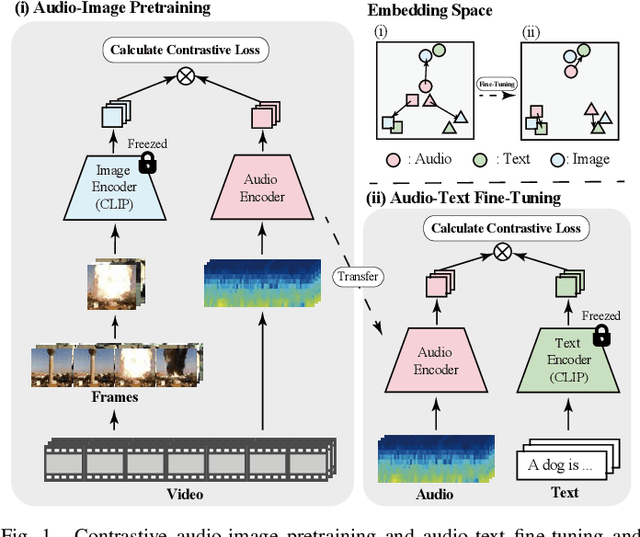
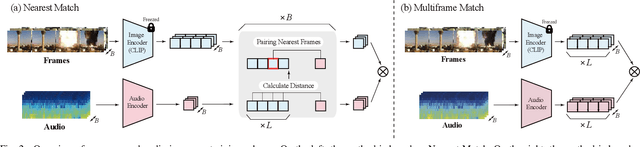
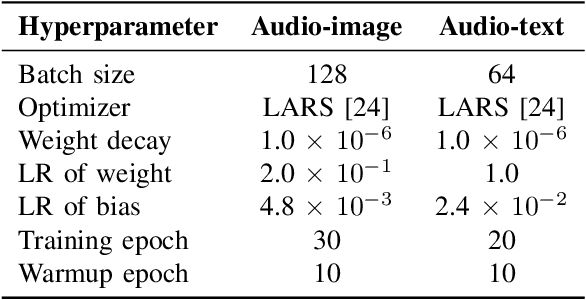
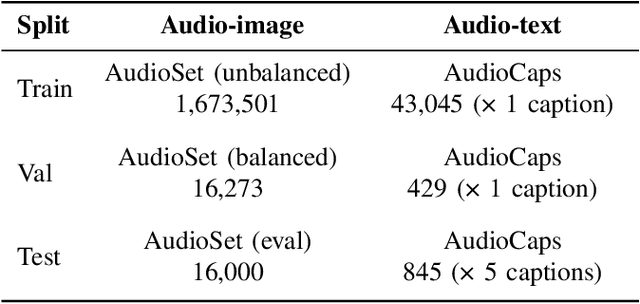
The aim of this research is to refine knowledge transfer on audio-image temporal agreement for audio-text cross retrieval. To address the limited availability of paired non-speech audio-text data, learning methods for transferring the knowledge acquired from a large amount of paired audio-image data to shared audio-text representation have been investigated, suggesting the importance of how audio-image co-occurrence is learned. Conventional approaches in audio-image learning assign a single image randomly selected from the corresponding video stream to the entire audio clip, assuming their co-occurrence. However, this method may not accurately capture the temporal agreement between the target audio and image because a single image can only represent a snapshot of a scene, though the target audio changes from moment to moment. To address this problem, we propose two methods for audio and image matching that effectively capture the temporal information: (i) Nearest Match wherein an image is selected from multiple time frames based on similarity with audio, and (ii) Multiframe Match wherein audio and image pairs of multiple time frames are used. Experimental results show that method (i) improves the audio-text retrieval performance by selecting the nearest image that aligns with the audio information and transferring the learned knowledge. Conversely, method (ii) improves the performance of audio-image retrieval while not showing significant improvements in audio-text retrieval performance. These results indicate that refining audio-image temporal agreement may contribute to better knowledge transfer to audio-text retrieval.
Concurrent Speaker Detection: A multi-microphone Transformer-Based Approach
Mar 11, 2024
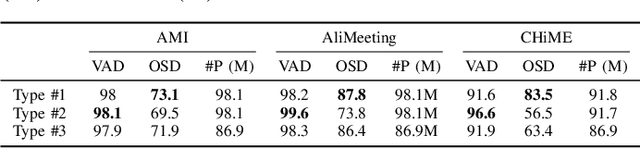

We present a deep-learning approach for the task of Concurrent Speaker Detection (CSD) using a modified transformer model. Our model is designed to handle multi-microphone data but can also work in the single-microphone case. The method can classify audio segments into one of three classes: 1) no speech activity (noise only), 2) only a single speaker is active, and 3) more than one speaker is active. We incorporate a Cost-Sensitive (CS) loss and a confidence calibration to the training procedure. The approach is evaluated using three real-world databases: AMI, AliMeeting, and CHiME 5, demonstrating an improvement over existing approaches.
Cosine Scoring with Uncertainty for Neural Speaker Embedding
Mar 11, 2024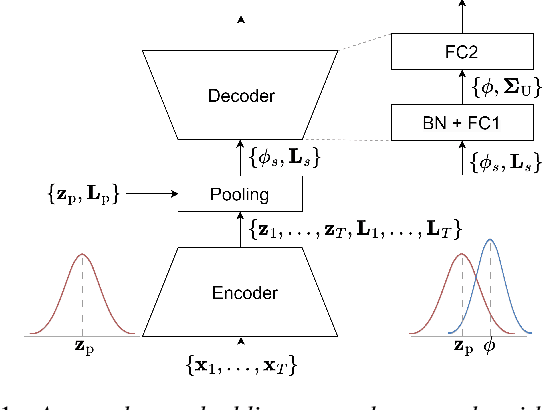
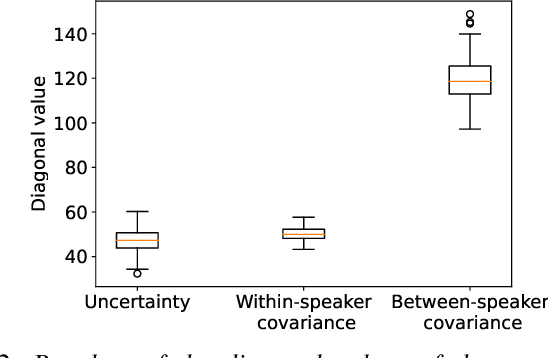
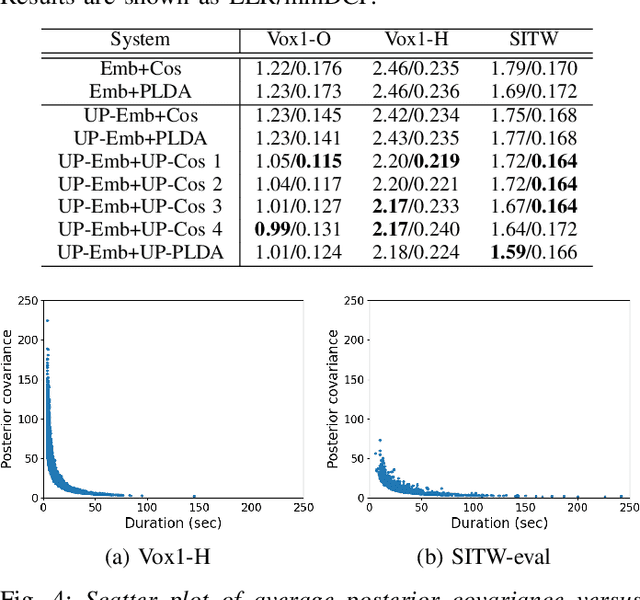
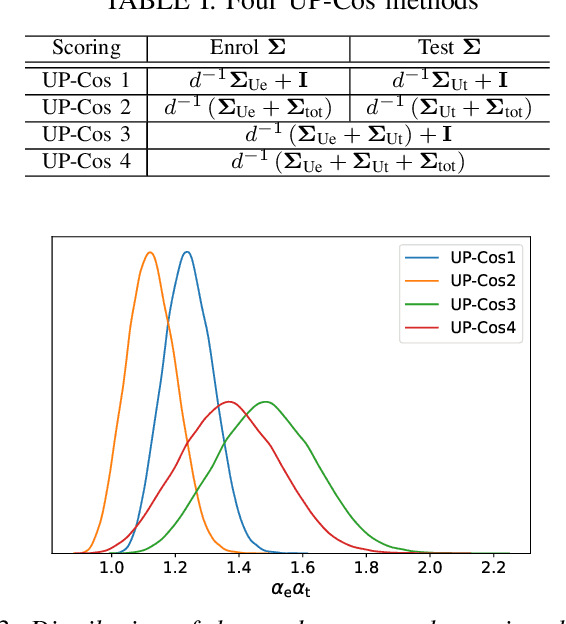
Uncertainty modeling in speaker representation aims to learn the variability present in speech utterances. While the conventional cosine-scoring is computationally efficient and prevalent in speaker recognition, it lacks the capability to handle uncertainty. To address this challenge, this paper proposes an approach for estimating uncertainty at the speaker embedding front-end and propagating it to the cosine scoring back-end. Experiments conducted on the VoxCeleb and SITW datasets confirmed the efficacy of the proposed method in handling uncertainty arising from embedding estimation. It achieved improvement with 8.5% and 9.8% average reductions in EER and minDCF compared to the conventional cosine similarity. It is also computationally efficient in practice.
* 5 pages, 4 figures
From "um" to "yeah": Producing, predicting, and regulating information flow in human conversation
Mar 13, 2024
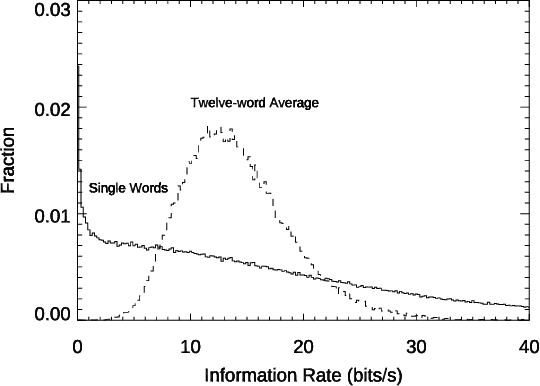
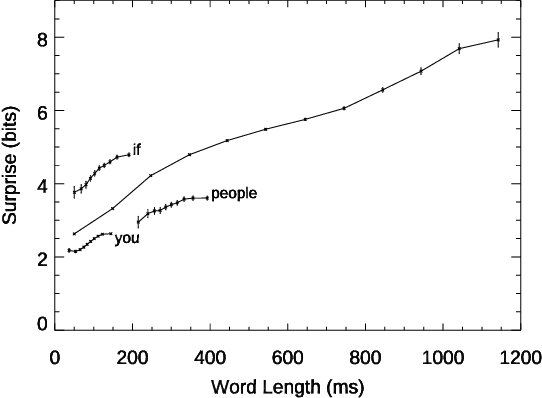
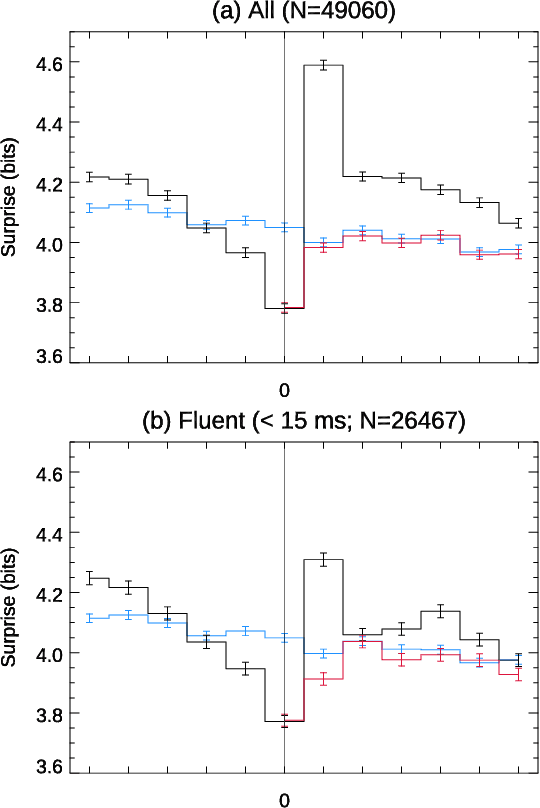
Conversation demands attention. Speakers must call words to mind, listeners must make sense of them, and both together must negotiate this flow of information, all in fractions of a second. We used large language models to study how this works in a large-scale dataset of English-language conversation, the CANDOR corpus. We provide a new estimate of the information density of unstructured conversation, of approximately 13 bits/second, and find significant effects associated with the cognitive load of both retrieving, and presenting, that information. We also reveal a role for backchannels -- the brief yeahs, uh-huhs, and mhmms that listeners provide -- in regulating the production of novelty: the lead-up to a backchannel is associated with declining information rate, while speech downstream rebounds to previous rates. Our results provide new insights into long-standing theories of how we respond to fluctuating demands on cognitive resources, and how we negotiate those demands in partnership with others.
Rich Semantic Knowledge Enhanced Large Language Models for Few-shot Chinese Spell Checking
Mar 13, 2024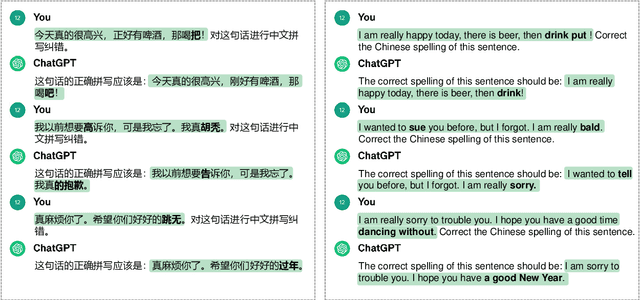
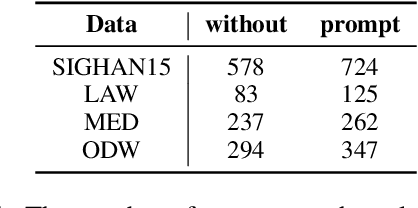
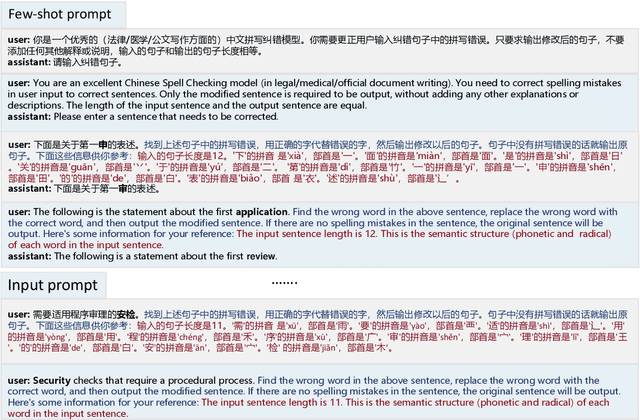
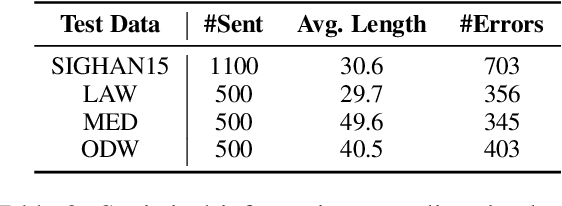
Chinese Spell Checking (CSC) is a widely used technology, which plays a vital role in speech to text (STT) and optical character recognition (OCR). Most of the existing CSC approaches relying on BERT architecture achieve excellent performance. However, limited by the scale of the foundation model, BERT-based method does not work well in few-shot scenarios, showing certain limitations in practical applications. In this paper, we explore using an in-context learning method named RS-LLM (Rich Semantic based LLMs) to introduce large language models (LLMs) as the foundation model. Besides, we study the impact of introducing various Chinese rich semantic information in our framework. We found that by introducing a small number of specific Chinese rich semantic structures, LLMs achieve better performance than the BERT-based model on few-shot CSC task. Furthermore, we conduct experiments on multiple datasets, and the experimental results verified the superiority of our proposed framework.
Syllable based DNN-HMM Cantonese Speech to Text System
Feb 13, 2024This paper reports our work on building up a Cantonese Speech-to-Text (STT) system with a syllable based acoustic model. This is a part of an effort in building a STT system to aid dyslexic students who have cognitive deficiency in writing skills but have no problem expressing their ideas through speech. For Cantonese speech recognition, the basic unit of acoustic models can either be the conventional Initial-Final (IF) syllables, or the Onset-Nucleus-Coda (ONC) syllables where finals are further split into nucleus and coda to reflect the intra-syllable variations in Cantonese. By using the Kaldi toolkit, our system is trained using the stochastic gradient descent optimization model with the aid of GPUs for the hybrid Deep Neural Network and Hidden Markov Model (DNN-HMM) with and without I-vector based speaker adaptive training technique. The input features of the same Gaussian Mixture Model with speaker adaptive training (GMM-SAT) to DNN are used in all cases. Experiments show that the ONC-based syllable acoustic modeling with I-vector based DNN-HMM achieves the best performance with the word error rate (WER) of 9.66% and the real time factor (RTF) of 1.38812.
When LLMs Meets Acoustic Landmarks: An Efficient Approach to Integrate Speech into Large Language Models for Depression Detection
Feb 17, 2024Depression is a critical concern in global mental health, prompting extensive research into AI-based detection methods. Among various AI technologies, Large Language Models (LLMs) stand out for their versatility in mental healthcare applications. However, their primary limitation arises from their exclusive dependence on textual input, which constrains their overall capabilities. Furthermore, the utilization of LLMs in identifying and analyzing depressive states is still relatively untapped. In this paper, we present an innovative approach to integrating acoustic speech information into the LLMs framework for multimodal depression detection. We investigate an efficient method for depression detection by integrating speech signals into LLMs utilizing Acoustic Landmarks. By incorporating acoustic landmarks, which are specific to the pronunciation of spoken words, our method adds critical dimensions to text transcripts. This integration also provides insights into the unique speech patterns of individuals, revealing the potential mental states of individuals. Evaluations of the proposed approach on the DAIC-WOZ dataset reveal state-of-the-art results when compared with existing Audio-Text baselines. In addition, this approach is not only valuable for the detection of depression but also represents a new perspective in enhancing the ability of LLMs to comprehend and process speech signals.
CoPlay: Audio-agnostic Cognitive Scaling for Acoustic Sensing
Mar 16, 2024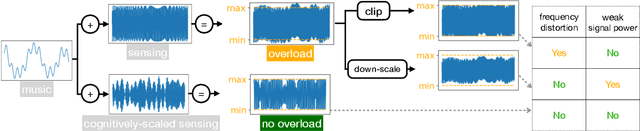

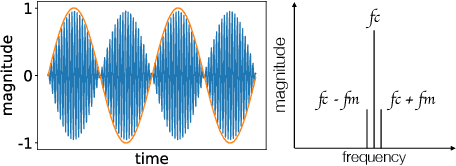

Acoustic sensing manifests great potential in various applications that encompass health monitoring, gesture interface and imaging by leveraging the speakers and microphones on smart devices. However, in ongoing research and development in acoustic sensing, one problem is often overlooked: the same speaker, when used concurrently for sensing and other traditional applications (like playing music), could cause interference in both making it impractical to use in the real world. The strong ultrasonic sensing signals mixed with music would overload the speaker's mixer. To confront this issue of overloaded signals, current solutions are clipping or down-scaling, both of which affect the music playback quality and also sensing range and accuracy. To address this challenge, we propose CoPlay, a deep learning based optimization algorithm to cognitively adapt the sensing signal. It can 1) maximize the sensing signal magnitude within the available bandwidth left by the concurrent music to optimize sensing range and accuracy and 2) minimize any consequential frequency distortion that can affect music playback. In this work, we design a deep learning model and test it on common types of sensing signals (sine wave or Frequency Modulated Continuous Wave FMCW) as inputs with various agnostic concurrent music and speech. First, we evaluated the model performance to show the quality of the generated signals. Then we conducted field studies of downstream acoustic sensing tasks in the real world. A study with 12 users proved that respiration monitoring and gesture recognition using our adapted signal achieve similar accuracy as no-concurrent-music scenarios, while clipping or down-scaling manifests worse accuracy. A qualitative study also manifests that the music play quality is not degraded, unlike traditional clipping or down-scaling methods.