 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Training Autoregressive Speech Recognition Models with Limited in-domain Supervision
Oct 27, 2022

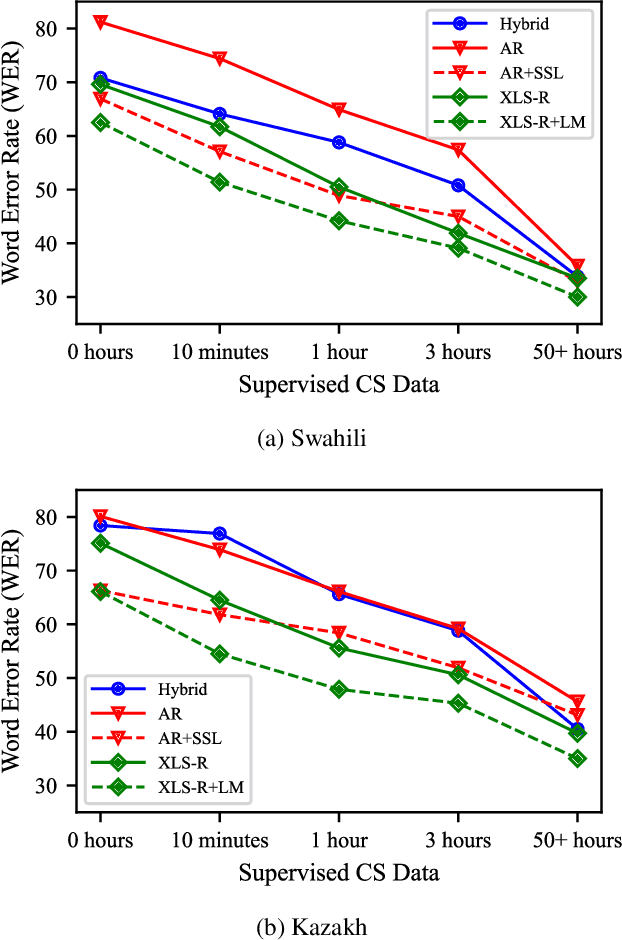

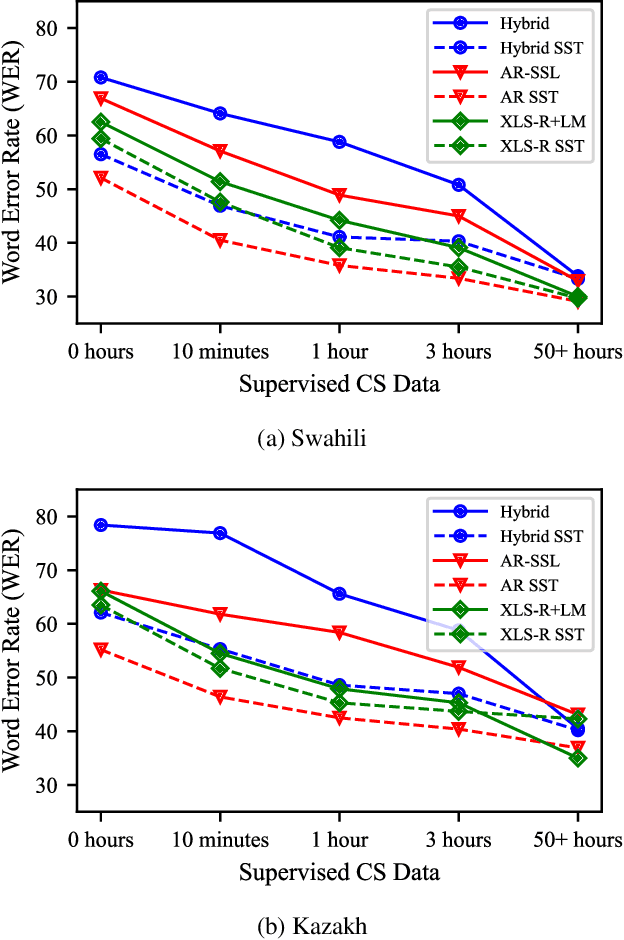
Advances in self-supervised learning have significantly reduced the amount of transcribed audio required for training. However, the majority of work in this area is focused on read speech. We explore limited supervision in the domain of conversational speech. While we assume the amount of in-domain data is limited, we augment the model with open source read speech data. The XLS-R model has been shown to perform well with limited adaptation data and serves as a strong baseline. We use untranscribed data for self-supervised learning and semi-supervised training in an autoregressive encoder-decoder model. We demonstrate that by using the XLS-R model for pseudotranscription, a much smaller autoregressive model can outperform a finetuned XLS-R model when transcribed in-domain data is limited, reducing WER by as much as 8% absolute.
Cross-lingual Alzheimer's Disease detection based on paralinguistic and pre-trained features
Mar 14, 2023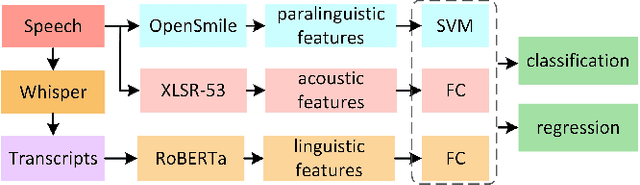
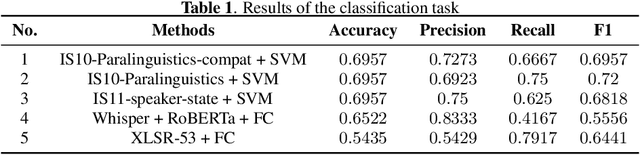
We present our submission to the ICASSP-SPGC-2023 ADReSS-M Challenge Task, which aims to investigate which acoustic features can be generalized and transferred across languages for Alzheimer's Disease (AD) prediction. The challenge consists of two tasks: one is to classify the speech of AD patients and healthy individuals, and the other is to infer Mini Mental State Examination (MMSE) score based on speech only. The difficulty is mainly embodied in the mismatch of the dataset, in which the training set is in English while the test set is in Greek. We extract paralinguistic features using openSmile toolkit and acoustic features using XLSR-53. In addition, we extract linguistic features after transcribing the speech into text. These features are used as indicators for AD detection in our method. Our method achieves an accuracy of 69.6% on the classification task and a root mean squared error (RMSE) of 4.788 on the regression task. The results show that our proposed method is expected to achieve automatic multilingual Alzheimer's Disease detection through spontaneous speech.
A Two-Stage Deep Representation Learning-Based Speech Enhancement Method Using Variational Autoencoder and Adversarial Training
Nov 16, 2022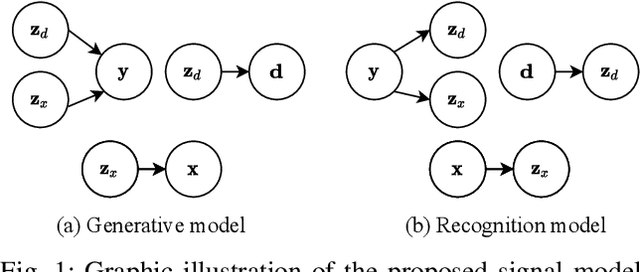
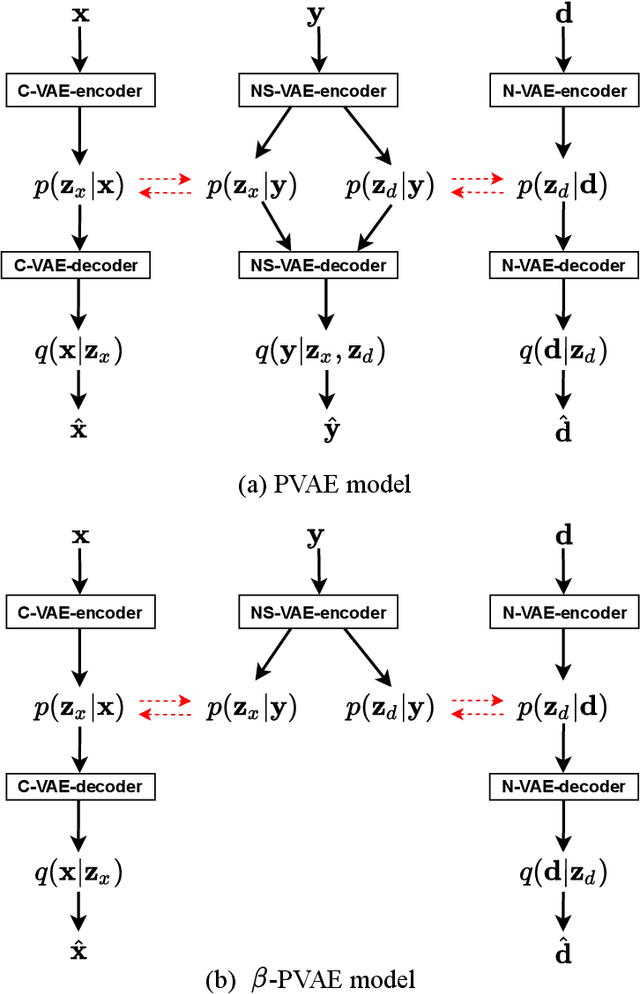
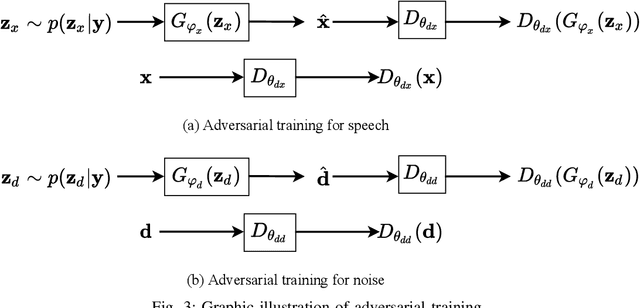
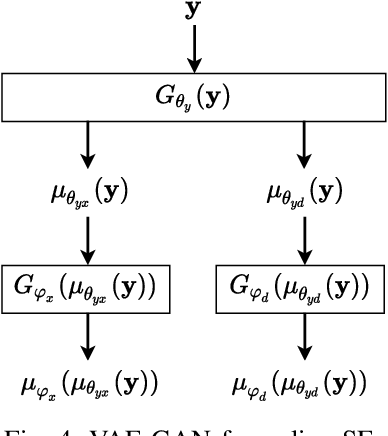
This paper focuses on leveraging deep representation learning (DRL) for speech enhancement (SE). In general, the performance of the deep neural network (DNN) is heavily dependent on the learning of data representation. However, the DRL's importance is often ignored in many DNN-based SE algorithms. To obtain a higher quality enhanced speech, we propose a two-stage DRL-based SE method through adversarial training. In the first stage, we disentangle different latent variables because disentangled representations can help DNN generate a better enhanced speech. Specifically, we use the $\beta$-variational autoencoder (VAE) algorithm to obtain the speech and noise posterior estimations and related representations from the observed signal. However, since the posteriors and representations are intractable and we can only apply a conditional assumption to estimate them, it is difficult to ensure that these estimations are always pretty accurate, which may potentially degrade the final accuracy of the signal estimation. To further improve the quality of enhanced speech, in the second stage, we introduce adversarial training to reduce the effect of the inaccurate posterior towards signal reconstruction and improve the signal estimation accuracy, making our algorithm more robust for the potentially inaccurate posterior estimations. As a result, better SE performance can be achieved. The experimental results indicate that the proposed strategy can help similar DNN-based SE algorithms achieve higher short-time objective intelligibility (STOI), perceptual evaluation of speech quality (PESQ), and scale-invariant signal-to-distortion ratio (SI-SDR) scores. Moreover, the proposed algorithm can also outperform recent competitive SE algorithms.
Puffin: pitch-synchronous neural waveform generation for fullband speech on modest devices
Nov 25, 2022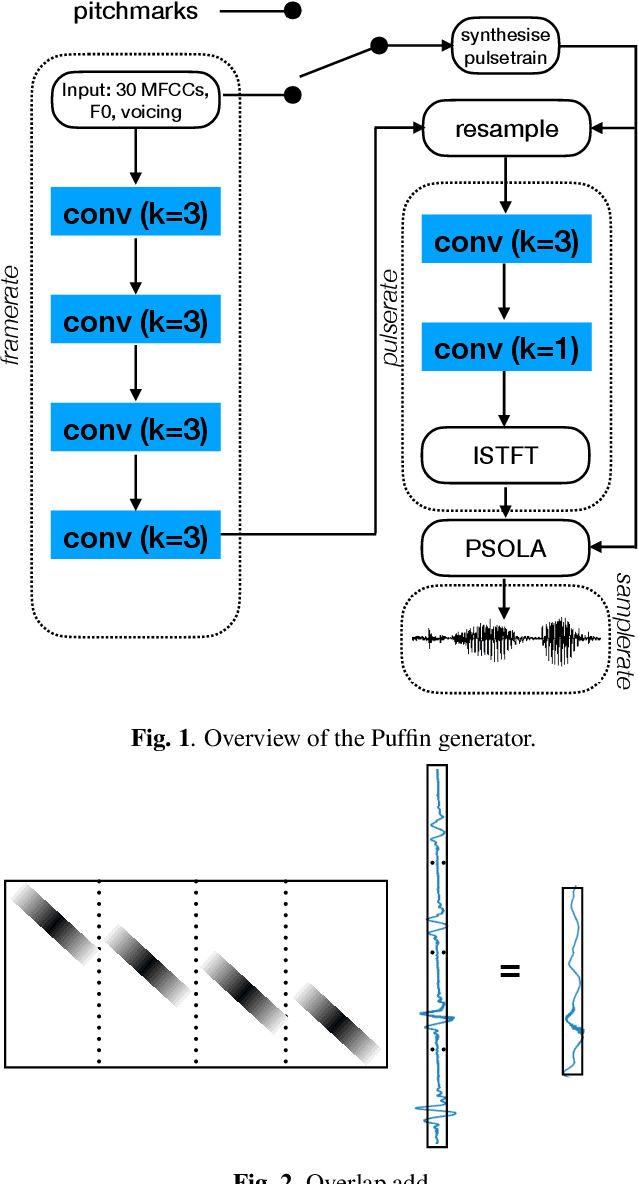
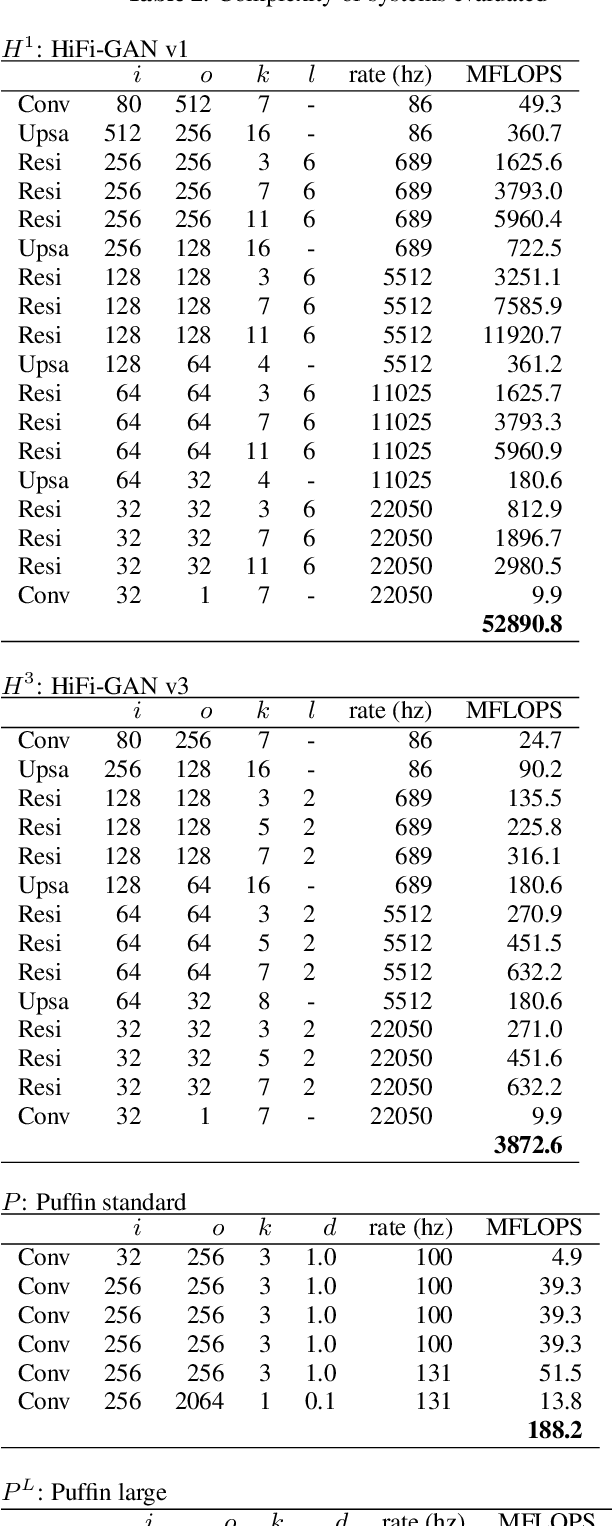
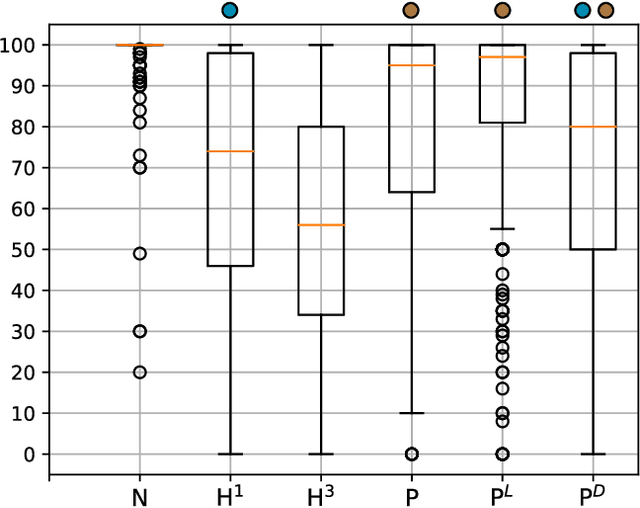
We present a neural vocoder designed with low-powered Alternative and Augmentative Communication devices in mind. By combining elements of successful modern vocoders with established ideas from an older generation of technology, our system is able to produce high quality synthetic speech at 48kHz on devices where neural vocoders are otherwise prohibitively complex. The system is trained adversarially using differentiable pitch synchronous overlap add, and reduces complexity by relying on pitch synchronous Inverse Short-Time Fourier Transform (ISTFT) to generate speech samples. Our system achieves comparable quality with a strong (HiFi-GAN) baseline while using only a fraction of the compute. We present results of a perceptual evaluation as well as an analysis of system complexity.
Rate-Adaptive Coding Mechanism for Semantic Communications With Multi-Modal Data
May 18, 2023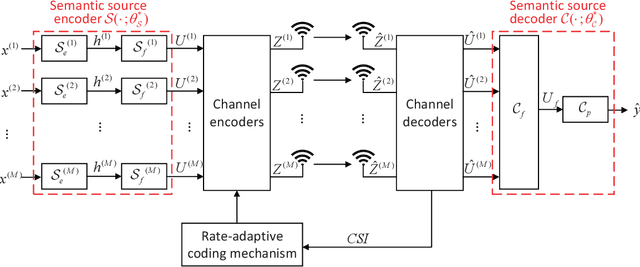
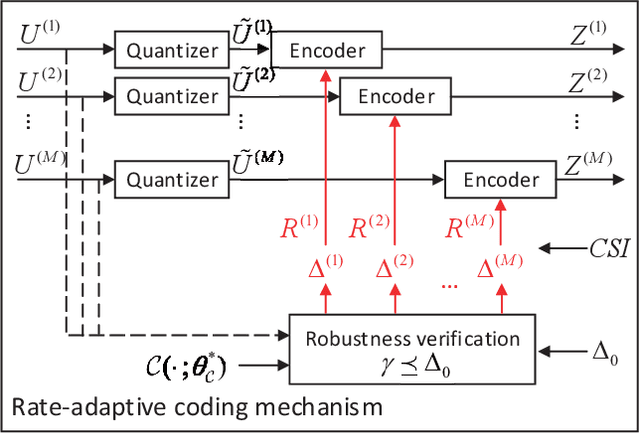
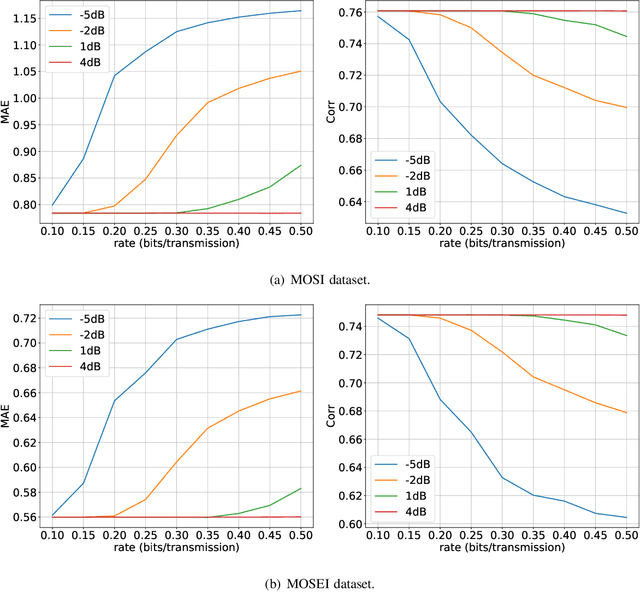
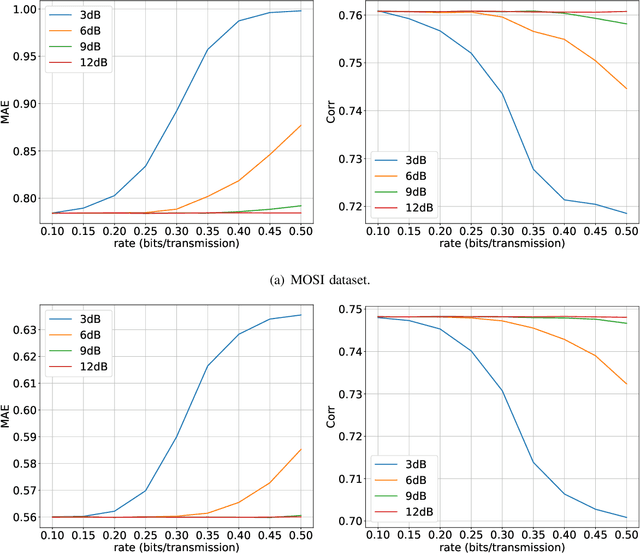
Recently, the ever-increasing demand for bandwidth in multi-modal communication systems requires a paradigm shift. Powered by deep learning, semantic communications are applied to multi-modal scenarios to boost communication efficiency and save communication resources. However, the existing end-to-end neural network (NN) based framework without the channel encoder/decoder is incompatible with modern digital communication systems. Moreover, most end-to-end designs are task-specific and require re-design and re-training for new tasks, which limits their applications. In this paper, we propose a distributed multi-modal semantic communication framework incorporating the conventional channel encoder/decoder. We adopt NN-based semantic encoder and decoder to extract correlated semantic information contained in different modalities, including speech, text, and image. Based on the proposed framework, we further establish a general rate-adaptive coding mechanism for various types of multi-modal semantic tasks. In particular, we utilize unequal error protection based on semantic importance, which is derived by evaluating the distortion bound of each modality. We further formulate and solve an optimization problem that aims at minimizing inference delay while maintaining inference accuracy for semantic tasks. Numerical results show that the proposed mechanism fares better than both conventional communication and existing semantic communication systems in terms of task performance, inference delay, and deployment complexity.
Avoid Overthinking in Self-Supervised Models for Speech Recognition
Nov 01, 2022
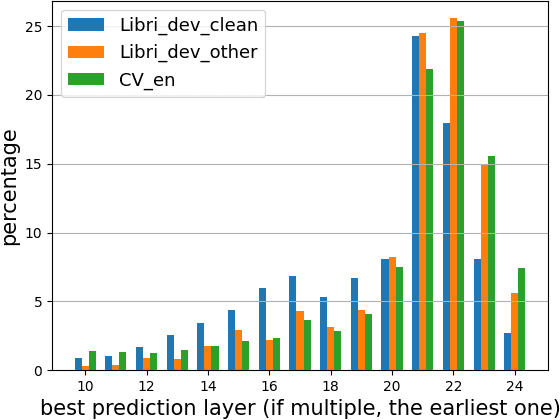
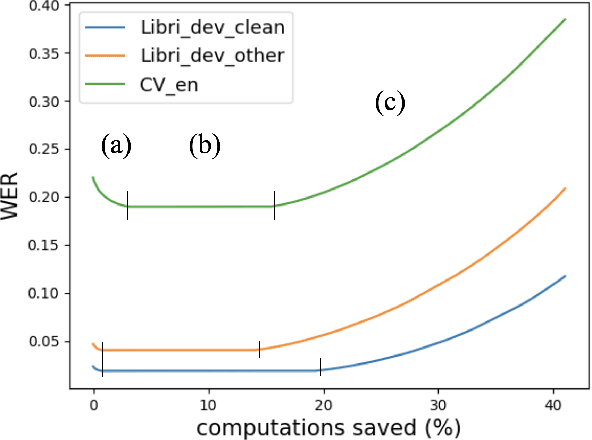

Self-supervised learning (SSL) models reshaped our approach to speech, language and vision. However their huge size and the opaque relations between their layers and tasks result in slow inference and network overthinking, where predictions made from the last layer of large models is worse than those made from intermediate layers. Early exit (EE) strategies can solve both issues by dynamically reducing computations at inference time for certain samples. Although popular for classification tasks in vision and language, EE has seen less use for sequence-to-sequence speech recognition (ASR) tasks where outputs from early layers are often degenerate. This challenge is further compounded when speech SSL models are applied on out-of-distribution (OOD) data. This paper first shows that SSL models do overthinking in ASR. We then motivate further research in EE by computing an optimal bound for performance versus speed trade-offs. To approach this bound we propose two new strategies for ASR: (1) we adapt the recently proposed patience strategy to ASR; and (2) we design a new EE strategy specific to ASR that performs better than all strategies previously introduced.
Model-based estimation of in-car-communication feedback applied to speech zone detection
Oct 07, 2022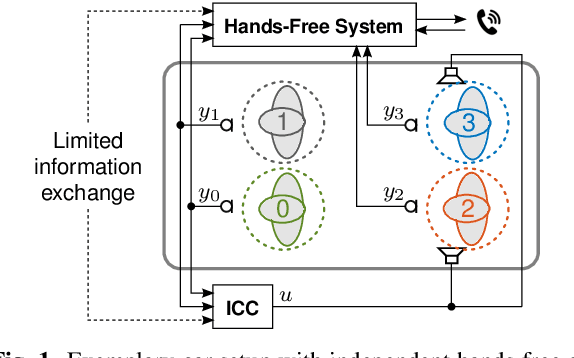
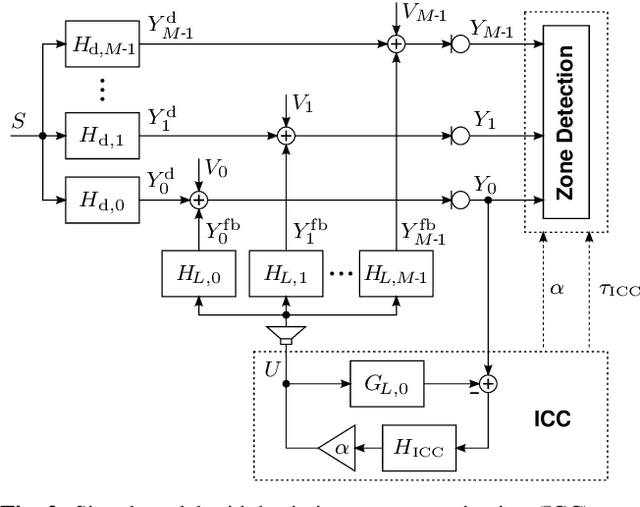

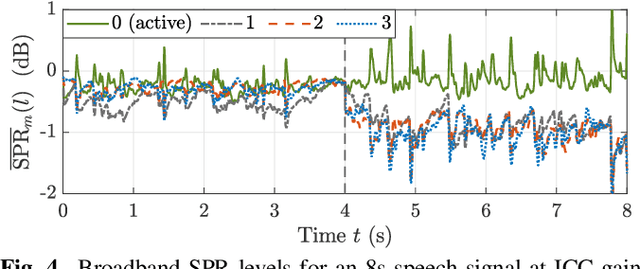
Modern cars provide versatile tools to enhance speech communication. While an in-car communication (ICC) system aims at enhancing communication between the passengers by playing back desired speech via loudspeakers in the car, these loudspeaker signals may disturb a speech enhancement system required for hands-free telephony and automatic speech recognition. In this paper, we focus on speech zone detection, i.e. detecting which passenger in the car is speaking, which is a crucial component of the speech enhancement system. We propose a model-based feedback estimation method to improve robustness of speech zone detection against ICC feedback. Specifically, since the zone detection system typically does not have access to the ICC loudspeaker signals, the proposed method estimates the feedback signal from the observed microphone signals based on a free-field propagation model between the loudspeakers and the microphones as well as the ICC gain. We propose an efficient recursive implementation in the short-time Fourier transform domain using convolutive transfer functions. A realistic simulation study indicates that the proposed method allows to increase the ICC gain by about 6dB while still achieving robust speech zone detection results.
Brouhaha: multi-task training for voice activity detection, speech-to-noise ratio, and C50 room acoustics estimation
Oct 27, 2022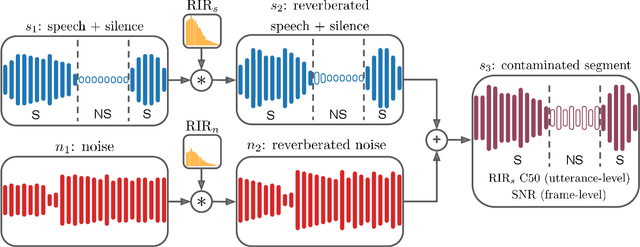
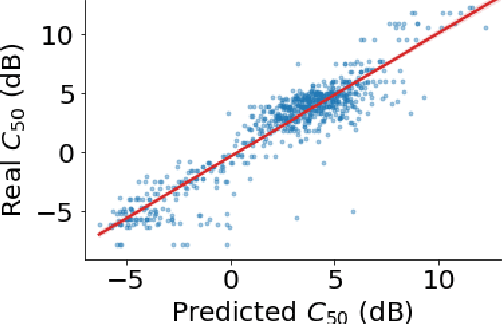
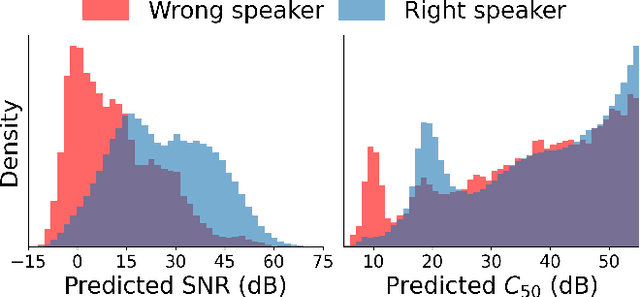
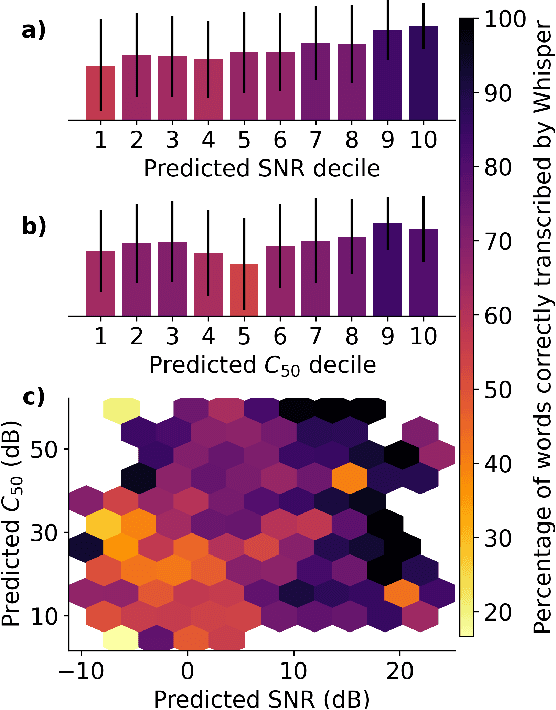
Most automatic speech processing systems are sensitive to the acoustic environment, with degraded performance when applied to noisy or reverberant speech. But how can one tell whether speech is noisy or reverberant? We propose Brouhaha, a pipeline to simulate audio segments recorded in noisy and reverberant conditions. We then use the simulated audio to jointly train the Brouhaha model for voice activity detection, signal-to-noise ratio estimation, and C50 room acoustics prediction. We show how the predicted SNR and C50 values can be used to investigate and help diagnose errors made by automatic speech processing tools (such as pyannote.audio for speaker diarization or OpenAI's Whisper for automatic speech recognition). Both our pipeline and a pretrained model are open source and shared with the speech community.
Rudolf Christoph Eucken at SemEval-2023 Task 4: An Ensemble Approach for Identifying Human Values from Arguments
May 09, 2023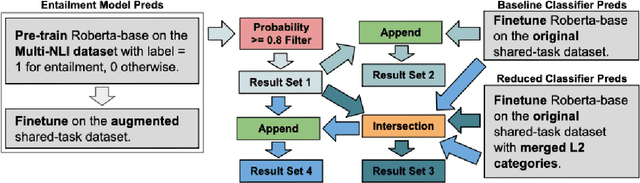
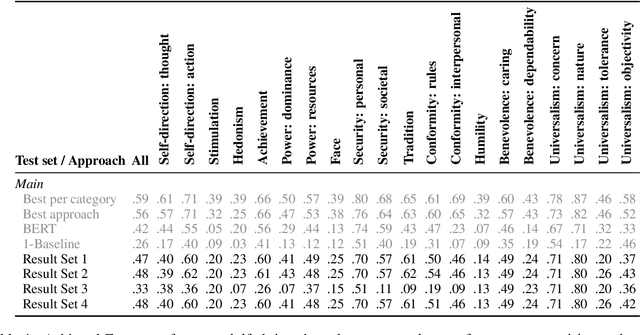
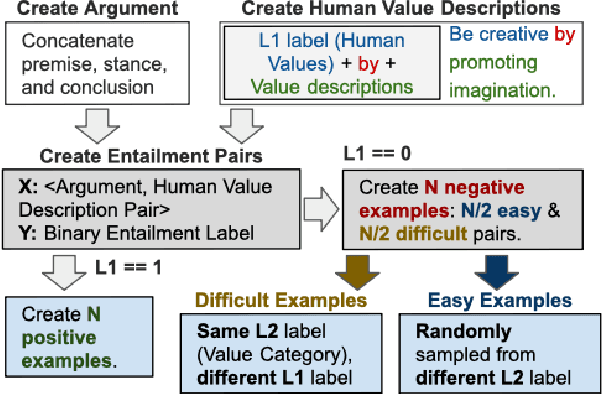
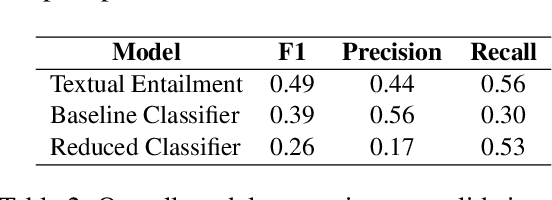
The subtle human values we acquire through life experiences govern our thoughts and gets reflected in our speech. It plays an integral part in capturing the essence of our individuality and making it imperative to identify such values in computational systems that mimic human actions. Computational argumentation is a field that deals with the argumentation capabilities of humans and can benefit from identifying such values. Motivated by that, we present an ensemble approach for detecting human values from argument text. Our ensemble comprises three models: (i) An entailment-based model for determining the human values based on their descriptions, (ii) A Roberta-based classifier that predicts the set of human values from an argument. (iii) A Roberta-based classifier to predict a reduced set of human values from an argument. We experiment with different ways of combining the models and report our results. Furthermore, our best combination achieves an overall F1 score of 0.48 on the main test set.
Towards Disentangled Speech Representations
Aug 28, 2022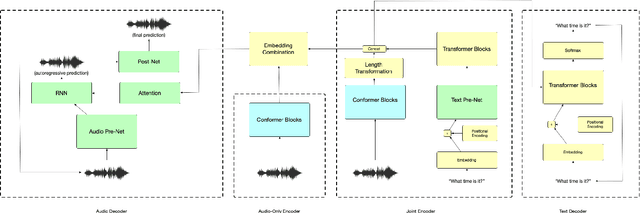
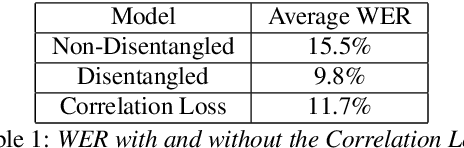

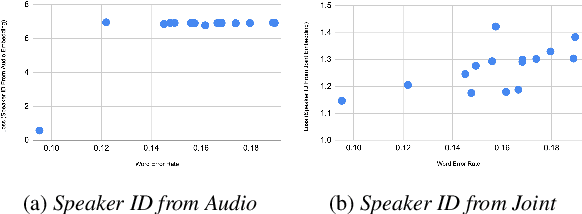
The careful construction of audio representations has become a dominant feature in the design of approaches to many speech tasks. Increasingly, such approaches have emphasized "disentanglement", where a representation contains only parts of the speech signal relevant to transcription while discarding irrelevant information. In this paper, we construct a representation learning task based on joint modeling of ASR and TTS, and seek to learn a representation of audio that disentangles that part of the speech signal that is relevant to transcription from that part which is not. We present empirical evidence that successfully finding such a representation is tied to the randomness inherent in training. We then make the observation that these desired, disentangled solutions to the optimization problem possess unique statistical properties. Finally, we show that enforcing these properties during training improves WER by 24.5% relative on average for our joint modeling task. These observations motivate a novel approach to learning effective audio representations.