 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Critical Appraisal of Artificial Intelligence-Mediated Communication
May 15, 2023
Over the last two decades, technology use in language learning and teaching has significantly advanced and is now referred to as Computer-Assisted Language Learning (CALL). Recently, the integration of Artificial Intelligence (AI) into CALL has brought about a significant shift in the traditional approach to language education both inside and outside the classroom. In line with this book's scope, I explore the advantages and disadvantages of AI-mediated communication in language education. I begin with a brief review of AI in education. I then introduce the ICALL and give a critical appraisal of the potential of AI-powered automatic speech recognition (ASR), Machine Translation (MT), Intelligent Tutoring Systems (ITSs), AI-powered chatbots, and Extended Reality (XR). In conclusion, I argue that it is crucial for language teachers to engage in CALL teacher education and professional development to keep up with the ever-evolving technology landscape and improve their teaching effectiveness.
Assessing Phrase Break of ESL speech with Pre-trained Language Models
Oct 28, 2022

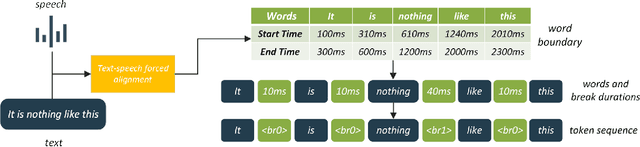
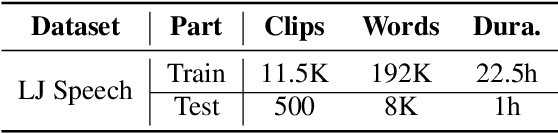
This work introduces an approach to assessing phrase break in ESL learners' speech with pre-trained language models (PLMs). Different with traditional methods, this proposal converts speech to token sequences, and then leverages the power of PLMs. There are two sub-tasks: overall assessment of phrase break for a speech clip; fine-grained assessment of every possible phrase break position. Speech input is first force-aligned with texts, then pre-processed to a token sequence, including words and associated phrase break information. The token sequence is then fed into the pre-training and fine-tuning pipeline. In pre-training, a replaced break token detection module is trained with token data where each token has a certain percentage chance to be randomly replaced. In fine-tuning, overall and fine-grained scoring are optimized with text classification and sequence labeling pipeline, respectively. With the introduction of PLMs, the dependence on labeled training data has been greatly reduced, and performance has improved.
An ASR-free Fluency Scoring Approach with Self-Supervised Learning
Mar 13, 2023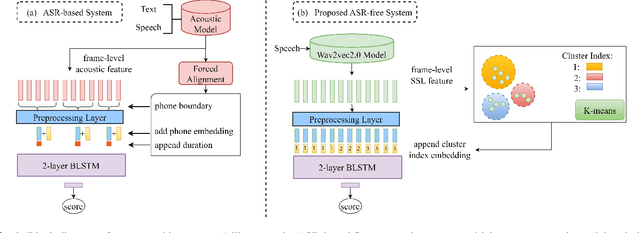
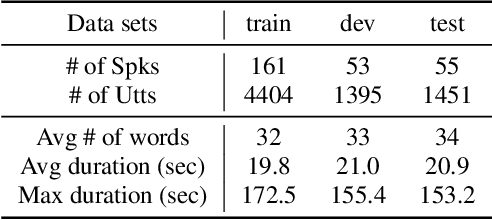
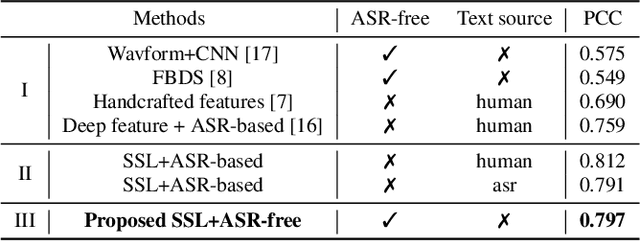
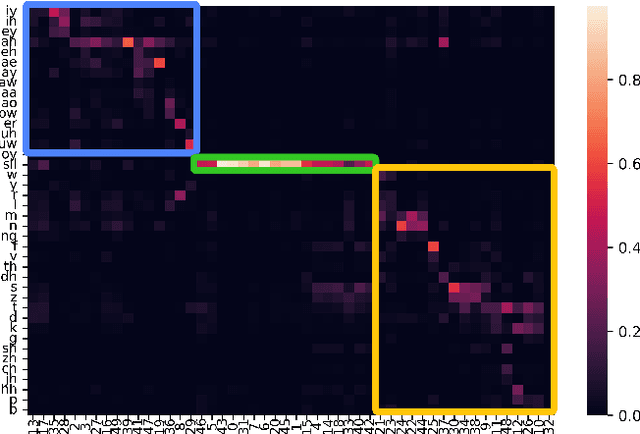
A typical fluency scoring system generally relies on an automatic speech recognition (ASR) system to obtain time stamps in input speech for either the subsequent calculation of fluency-related features or directly modeling speech fluency with an end-to-end approach. This paper describes a novel ASR-free approach for automatic fluency assessment using self-supervised learning (SSL). Specifically, wav2vec2.0 is used to extract frame-level speech features, followed by K-means clustering to assign a pseudo label (cluster index) to each frame. A BLSTM-based model is trained to predict an utterance-level fluency score from frame-level SSL features and the corresponding cluster indexes. Neither speech transcription nor time stamp information is required in the proposed system. It is ASR-free and can potentially avoid the ASR errors effect in practice. Experimental results carried out on non-native English databases show that the proposed approach significantly improves the performance in the "open response" scenario as compared to previous methods and matches the recently reported performance in the "read aloud" scenario.
Token-level Speaker Change Detection Using Speaker Difference and Speech Content via Continuous Integrate-and-fire
Nov 17, 2022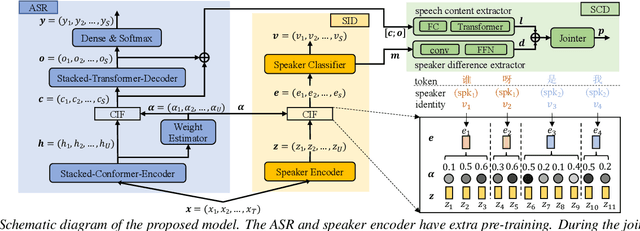
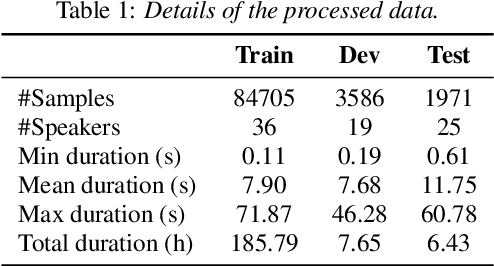
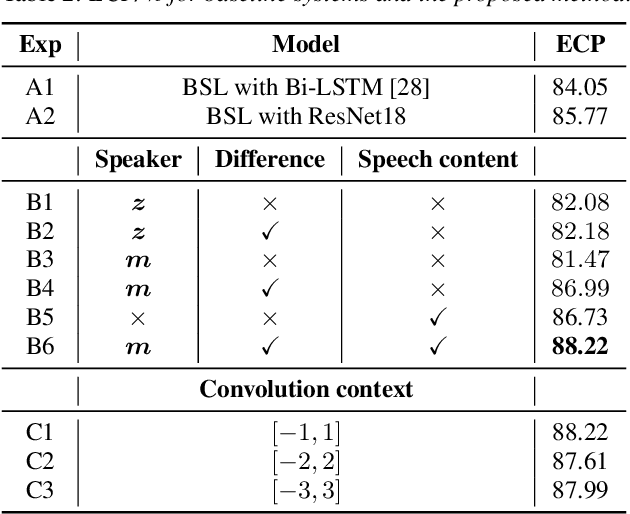
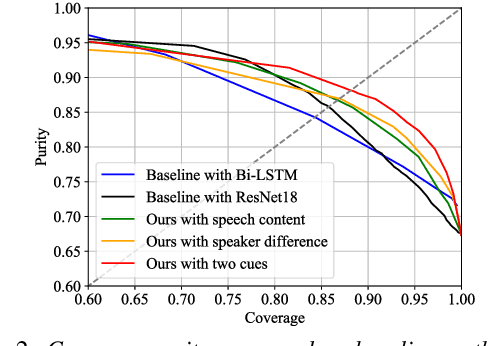
In multi-talker scenarios such as meetings and conversations, speech processing systems are usually required to segment the audio and then transcribe each segmentation. These two stages are addressed separately by speaker change detection (SCD) and automatic speech recognition (ASR). Most previous SCD systems rely solely on speaker information and ignore the importance of speech content. In this paper, we propose a novel SCD system that considers both cues of speaker difference and speech content. These two cues are converted into token-level representations by the continuous integrate-and-fire (CIF) mechanism and then combined for detecting speaker changes on the token acoustic boundaries. We evaluate the performance of our approach on a public real-recorded meeting dataset, AISHELL-4. The experiment results show that our method outperforms a competitive frame-level baseline system by 2.45% equal coverage-purity (ECP). In addition, we demonstrate the importance of speech content and speaker difference to the SCD task, and the advantages of conducting SCD on the token acoustic boundaries compared with conducting SCD frame by frame.
Masked Audio Text Encoders are Effective Multi-Modal Rescorers
May 11, 2023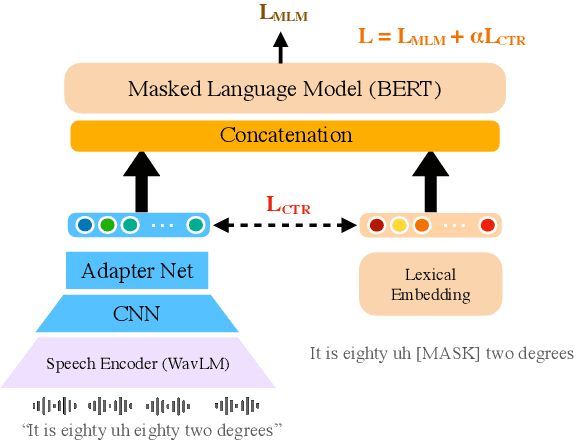
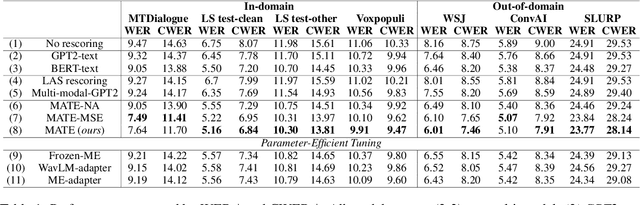
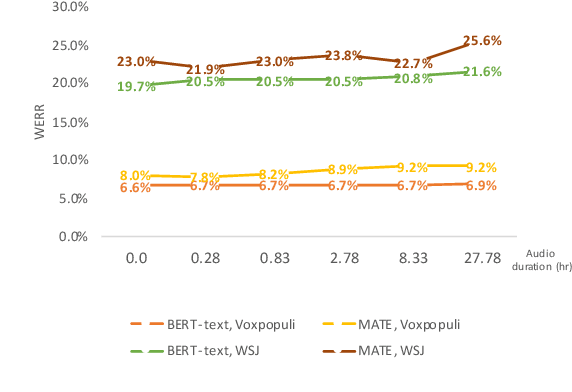
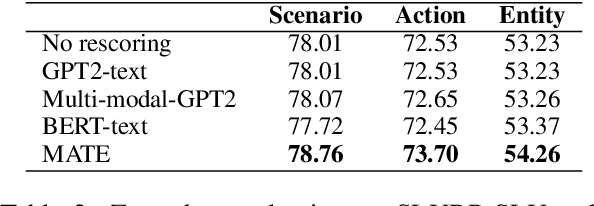
Masked Language Models (MLMs) have proven to be effective for second-pass rescoring in Automatic Speech Recognition (ASR) systems. In this work, we propose Masked Audio Text Encoder (MATE), a multi-modal masked language model rescorer which incorporates acoustic representations into the input space of MLM. We adopt contrastive learning for effectively aligning the modalities by learning shared representations. We show that using a multi-modal rescorer is beneficial for domain generalization of the ASR system when target domain data is unavailable. MATE reduces word error rate (WER) by 4%-16% on in-domain, and 3%-7% on out-of-domain datasets, over the text-only baseline. Additionally, with very limited amount of training data (0.8 hours), MATE achieves a WER reduction of 8%-23% over the first-pass baseline.
Using LLM-assisted Annotation for Corpus Linguistics: A Case Study of Local Grammar Analysis
May 25, 2023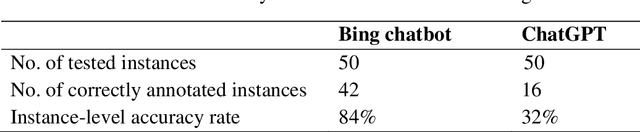

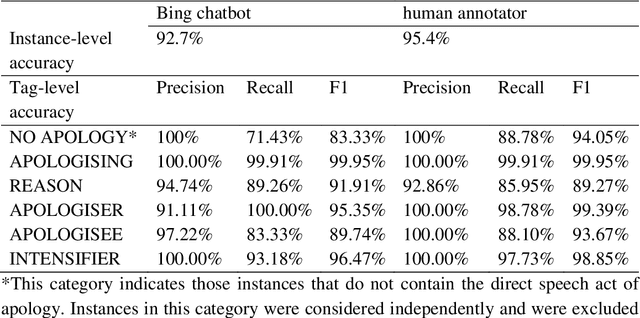
Chatbots based on Large Language Models (LLMs) have shown strong capabilities in language understanding. In this study, we explore the potential of LLMs in assisting corpus-based linguistic studies through automatic annotation of texts with specific categories of linguistic information. Specifically, we examined to what extent LLMs understand the functional elements constituting the speech act of apology from a local grammar perspective, by comparing the performance of ChatGPT (powered by GPT-3.5), the Bing chatbot (powered by GPT-4), and a human coder in the annotation task. The results demonstrate that the Bing chatbot significantly outperformed ChatGPT in the task. Compared to human annotator, the overall performance of the Bing chatbot was slightly less satisfactory. However, it already achieved high F1 scores: 99.95% for the tag of APOLOGISING, 91.91% for REASON, 95.35% for APOLOGISER, 89.74% for APOLOGISEE, and 96.47% for INTENSIFIER. This suggests that it is feasible to use LLM-assisted annotation for local grammar analysis, together with human intervention on tags that are less accurately recognized by machine. We strongly advocate conducting future studies to evaluate the performance of LLMs in annotating other linguistic phenomena. These studies have the potential to offer valuable insights into the advancement of theories developed in corpus linguistics, as well into the linguistic capabilities of LLMs..
Improving Scheduled Sampling for Neural Transducer-based ASR
May 25, 2023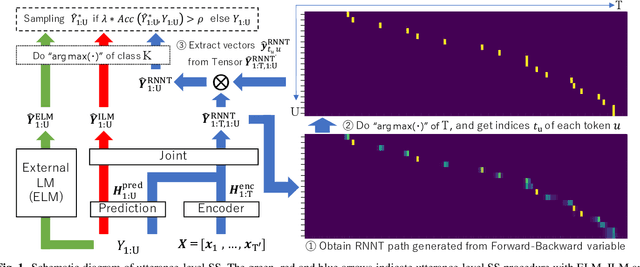
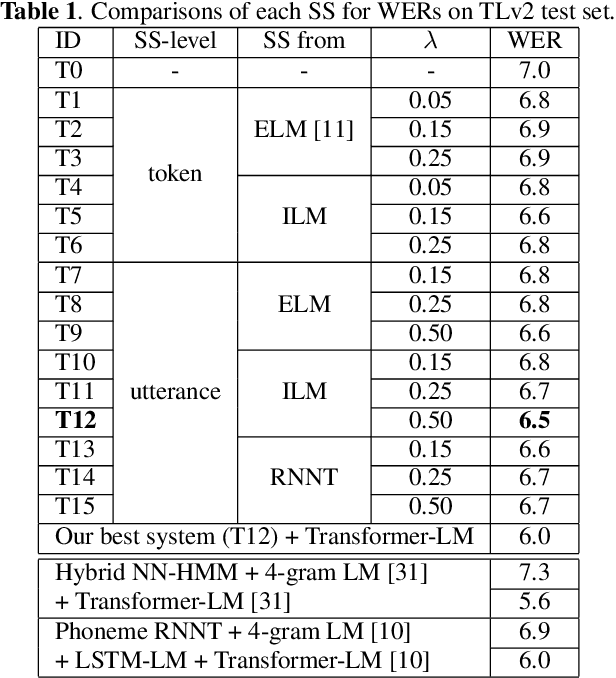
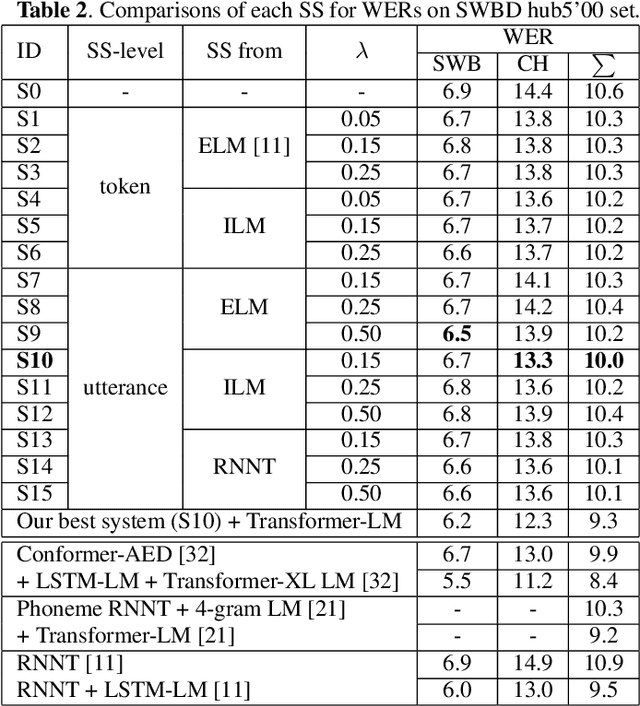
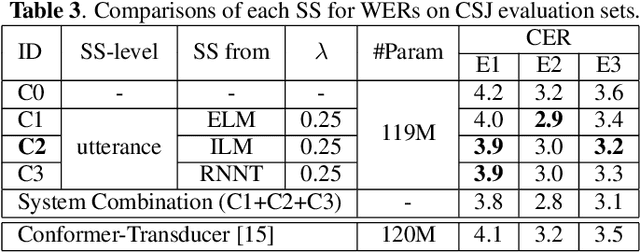
The recurrent neural network-transducer (RNNT) is a promising approach for automatic speech recognition (ASR) with the introduction of a prediction network that autoregressively considers linguistic aspects. To train the autoregressive part, the ground-truth tokens are used as substitutions for the previous output token, which leads to insufficient robustness to incorrect past tokens; a recognition error in the decoding leads to further errors. Scheduled sampling (SS) is a technique to train autoregressive model robustly to past errors by randomly replacing some ground-truth tokens with actual outputs generated from a model. SS mitigates the gaps between training and decoding steps, known as exposure bias, and it is often used for attentional encoder-decoder training. However SS has not been fully examined for RNNT because of the difficulty in applying SS to RNNT due to the complicated RNNT output form. In this paper we propose SS approaches suited for RNNT. Our SS approaches sample the tokens generated from the distiribution of RNNT itself, i.e. internal language model or RNNT outputs. Experiments in three datasets confirm that RNNT trained with our SS approach achieves the best ASR performance. In particular, on a Japanese ASR task, our best system outperforms the previous state-of-the-art alternative.
A Virtual Simulation-Pilot Agent for Training of Air Traffic Controllers
Apr 16, 2023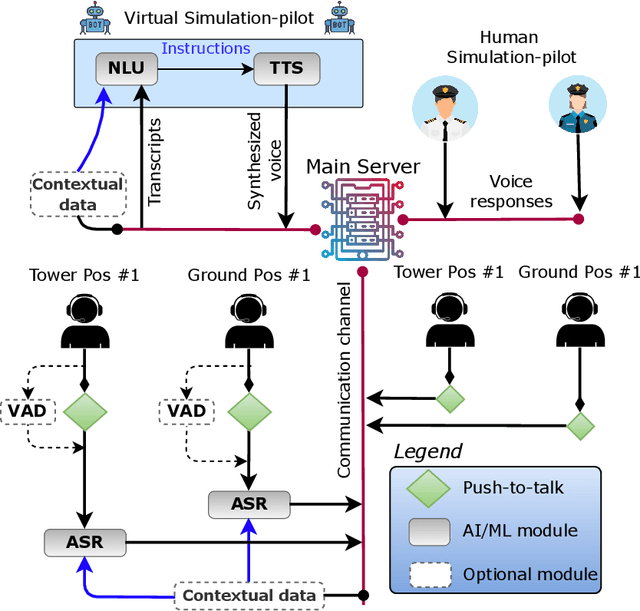
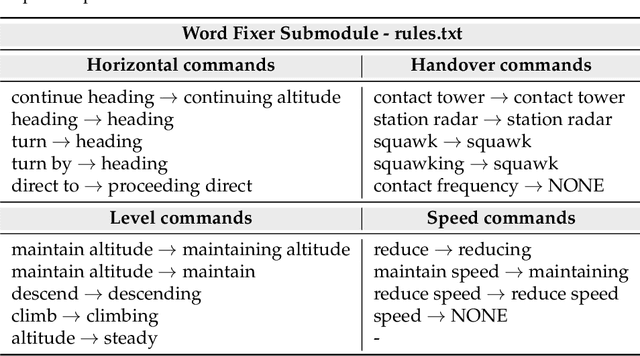
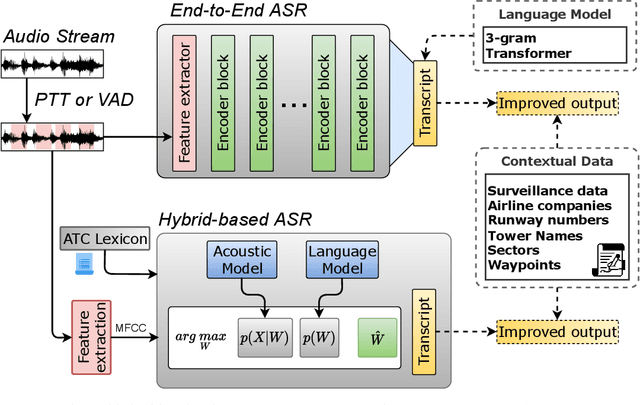
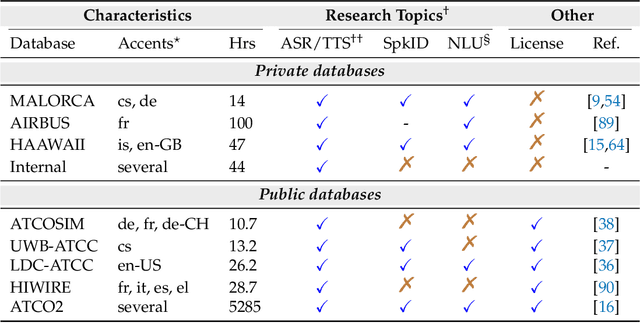
In this paper we propose a novel virtual simulation-pilot engine for speeding up air traffic controller (ATCo) training by integrating different state-of-the-art artificial intelligence (AI) based tools. The virtual simulation-pilot engine receives spoken communications from ATCo trainees, and it performs automatic speech recognition and understanding. Thus, it goes beyond only transcribing the communication and can also understand its meaning. The output is subsequently sent to a response generator system, which resembles the spoken read back that pilots give to the ATCo trainees. The overall pipeline is composed of the following submodules: (i) automatic speech recognition (ASR) system that transforms audio into a sequence of words; (ii) high-level air traffic control (ATC) related entity parser that understands the transcribed voice communication; and (iii) a text-to-speech submodule that generates a spoken utterance that resembles a pilot based on the situation of the dialogue. Our system employs state-of-the-art AI-based tools such as Wav2Vec 2.0, Conformer, BERT and Tacotron models. To the best of our knowledge, this is the first work fully based on open-source ATC resources and AI tools. In addition, we have developed a robust and modular system with optional submodules that can enhance the system's performance by incorporating real-time surveillance data, metadata related to exercises (such as sectors or runways), or even introducing a deliberate read-back error to train ATCo trainees to identify them. Our ASR system can reach as low as 5.5% and 15.9% word error rates (WER) on high and low-quality ATC audio. We also demonstrate that adding surveillance data into the ASR can yield callsign detection accuracy of more than 96%.
Coswara: A respiratory sounds and symptoms dataset for remote screening of SARS-CoV-2 infection
May 22, 2023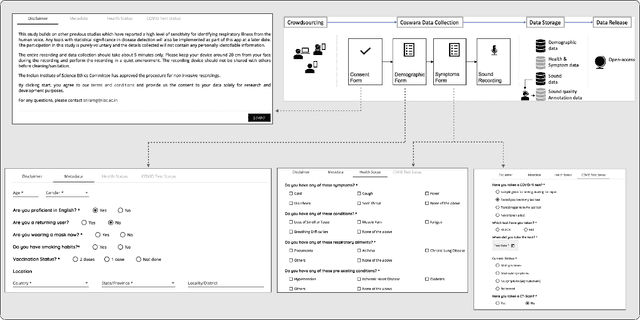
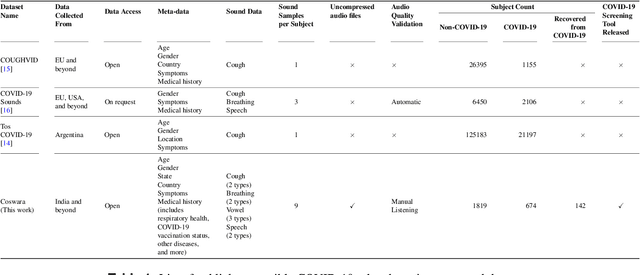
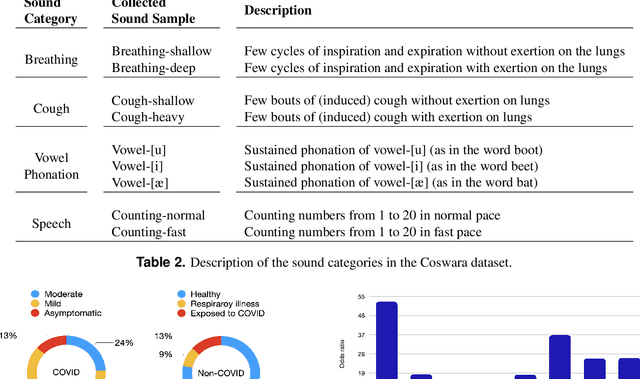
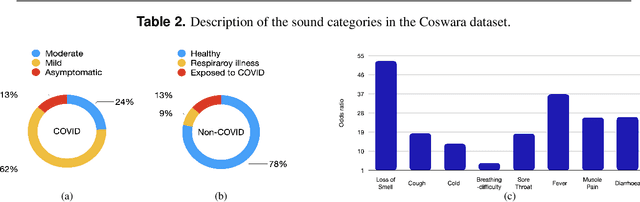
This paper presents the Coswara dataset, a dataset containing diverse set of respiratory sounds and rich meta-data, recorded between April-2020 and February-2022 from 2635 individuals (1819 SARS-CoV-2 negative, 674 positive, and 142 recovered subjects). The respiratory sounds contained nine sound categories associated with variants of breathing, cough and speech. The rich metadata contained demographic information associated with age, gender and geographic location, as well as the health information relating to the symptoms, pre-existing respiratory ailments, comorbidity and SARS-CoV-2 test status. Our study is the first of its kind to manually annotate the audio quality of the entire dataset (amounting to 65~hours) through manual listening. The paper summarizes the data collection procedure, demographic, symptoms and audio data information. A COVID-19 classifier based on bi-directional long short-term (BLSTM) architecture, is trained and evaluated on the different population sub-groups contained in the dataset to understand the bias/fairness of the model. This enabled the analysis of the impact of gender, geographic location, date of recording, and language proficiency on the COVID-19 detection performance.
The Importance of Accurate Alignments in End-to-End Speech Synthesis
Oct 31, 2022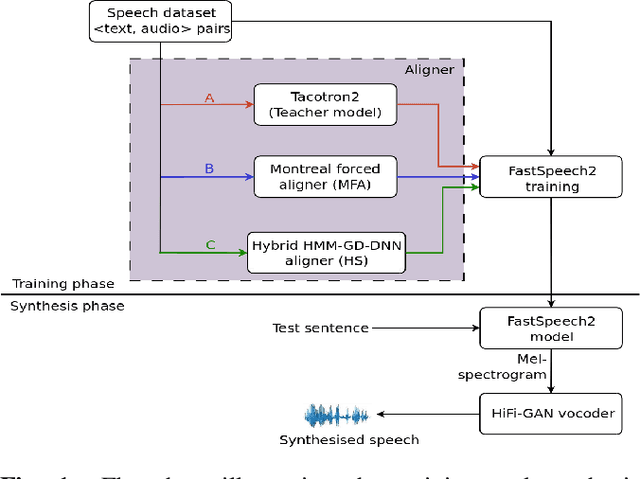

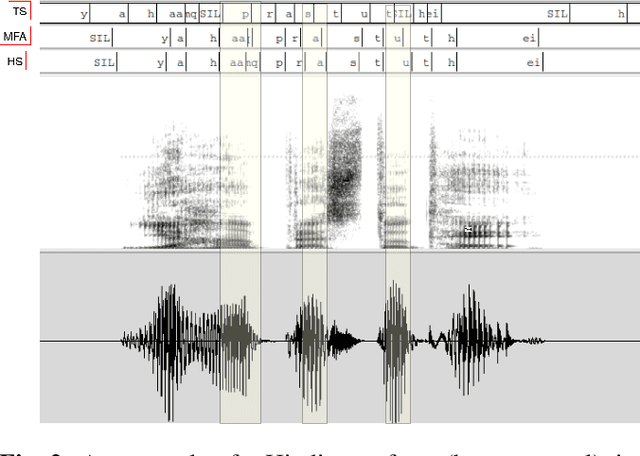

Unit selection synthesis systems required accurate segmentation and labeling of the speech signal owing to the concatenative nature. Hidden Markov model-based speech synthesis accommodates some transcription errors, but it was later shown that accurate transcriptions yield highly intelligible speech with smaller amounts of training data. With the arrival of end-to-end (E2E) systems, it was observed that very good quality speech could be synthesised with large amounts of data. As end-to-end synthesis progressed from Tacotron to FastSpeech2, it has become imminent that features that represent prosody are important for good-quality synthesis. In particular, durations of the sub-word units are important. Variants of FastSpeech use a teacher model or forced alignments to obtain good-quality synthesis. In this paper, we focus on duration prediction, using signal processing cues in tandem with forced alignment to produce accurate phone durations during training. The current work aims to highlight the importance of accurate alignments for good-quality synthesis. An attempt is made to train the E2E systems with accurately labeled data, and compare the same with approximately labeled data.