 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
CB-Conformer: Contextual biasing Conformer for biased word recognition
Apr 19, 2023
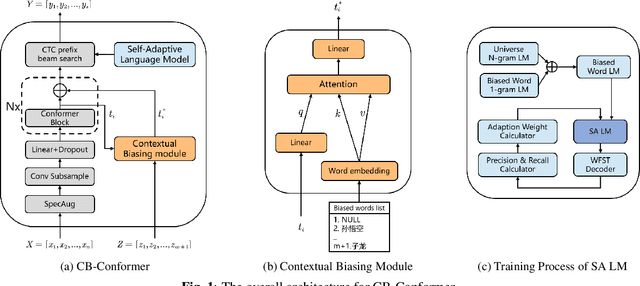
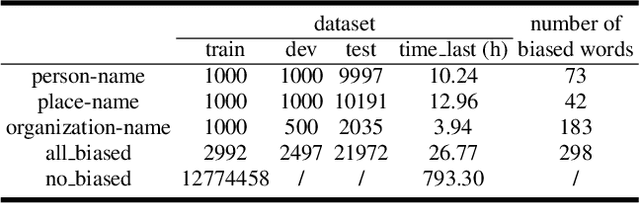
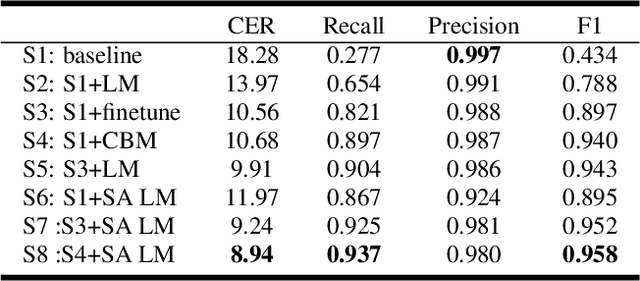
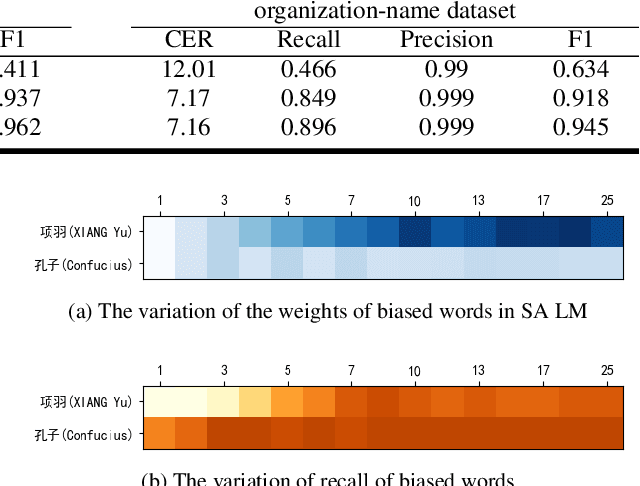
Due to the mismatch between the source and target domains, how to better utilize the biased word information to improve the performance of the automatic speech recognition model in the target domain becomes a hot research topic. Previous approaches either decode with a fixed external language model or introduce a sizeable biasing module, which leads to poor adaptability and slow inference. In this work, we propose CB-Conformer to improve biased word recognition by introducing the Contextual Biasing Module and the Self-Adaptive Language Model to vanilla Conformer. The Contextual Biasing Module combines audio fragments and contextual information, with only 0.2% model parameters of the original Conformer. The Self-Adaptive Language Model modifies the internal weights of biased words based on their recall and precision, resulting in a greater focus on biased words and more successful integration with the automatic speech recognition model than the standard fixed language model. In addition, we construct and release an open-source Mandarin biased-word dataset based on WenetSpeech. Experiments indicate that our proposed method brings a 15.34% character error rate reduction, a 14.13% biased word recall increase, and a 6.80% biased word F1-score increase compared with the base Conformer.
Laugh Betrays You? Learning Robust Speaker Representation From Speech Containing Non-Verbal Fragments
Nov 07, 2022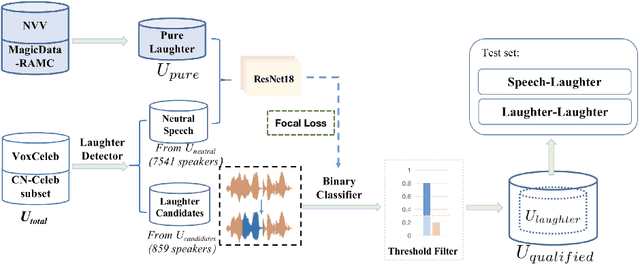
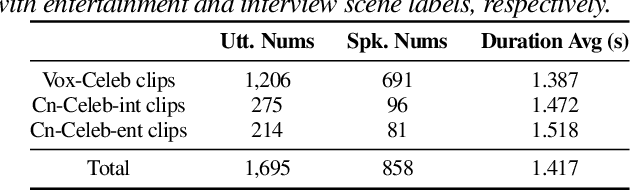

The success of automatic speaker verification shows that discriminative speaker representations can be extracted from neutral speech. However, as a kind of non-verbal voice, laughter should also carry speaker information intuitively. Thus, this paper focuses on exploring speaker verification about utterances containing non-verbal laughter segments. We collect a set of clips with laughter components by conducting a laughter detection script on VoxCeleb and part of the CN-Celeb dataset. To further filter untrusted clips, probability scores are calculated by our binary laughter detection classifier, which is pre-trained by pure laughter and neutral speech. After that, based on the clips whose scores are over the threshold, we construct trials under two different evaluation scenarios: Laughter-Laughter (LL) and Speech-Laughter (SL). Then a novel method called Laughter-Splicing based Network (LSN) is proposed, which can significantly boost performance in both scenarios and maintain the performance on the neutral speech, such as the VoxCeleb1 test set. Specifically, our system achieves relative 20% and 22% improvement on Laughter-Laughter and Speech-Laughter trials, respectively. The meta-data and sample clips have been released at https://github.com/nevermoreLin/Laugh_LSN.
Deep Speech Synthesis from Articulatory Representations
Sep 13, 2022

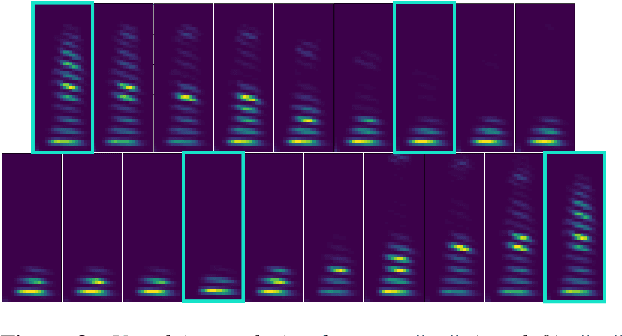
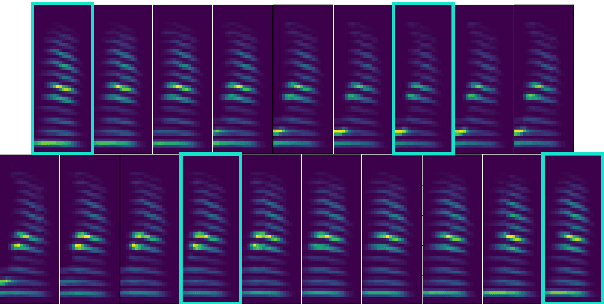
In the articulatory synthesis task, speech is synthesized from input features containing information about the physical behavior of the human vocal tract. This task provides a promising direction for speech synthesis research, as the articulatory space is compact, smooth, and interpretable. Current works have highlighted the potential for deep learning models to perform articulatory synthesis. However, it remains unclear whether these models can achieve the efficiency and fidelity of the human speech production system. To help bridge this gap, we propose a time-domain articulatory synthesis methodology and demonstrate its efficacy with both electromagnetic articulography (EMA) and synthetic articulatory feature inputs. Our model is computationally efficient and achieves a transcription word error rate (WER) of 18.5% for the EMA-to-speech task, yielding an improvement of 11.6% compared to prior work. Through interpolation experiments, we also highlight the generalizability and interpretability of our approach.
Resource-Efficient Transfer Learning From Speech Foundation Model Using Hierarchical Feature Fusion
Nov 04, 2022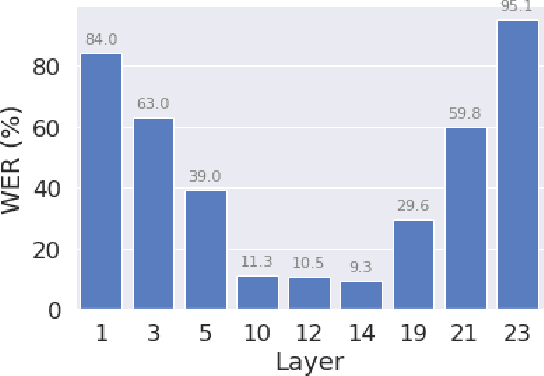
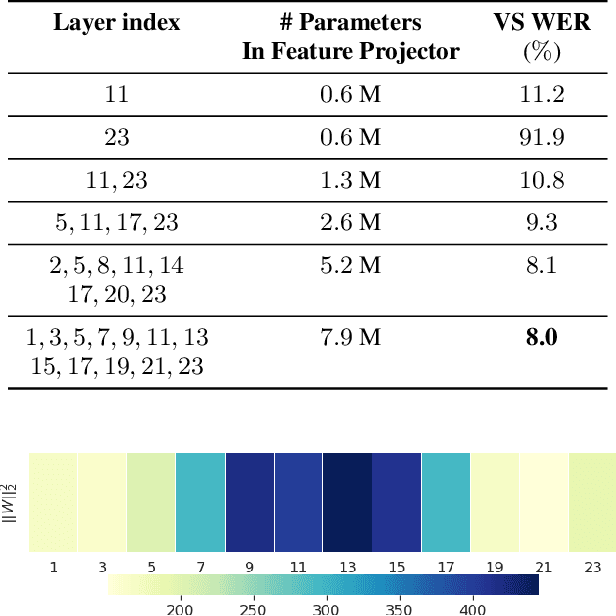
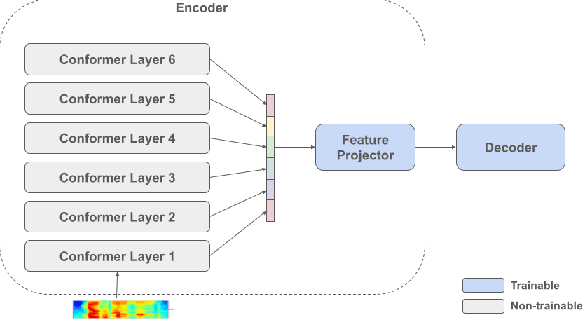
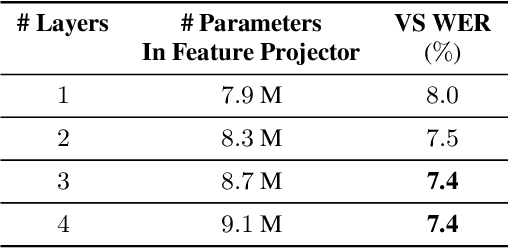
Self-supervised pre-training of a speech foundation model, followed by supervised fine-tuning, has shown impressive quality improvements on automatic speech recognition (ASR) tasks. Fine-tuning separate foundation models for many downstream tasks are expensive since the foundation model is usually very big. Parameter-efficient fine-tuning methods (e.g. adapter, sparse update methods) offer an alternative paradigm where a small set of parameters are updated to adapt the foundation model to new tasks. However, these methods still suffer from a high computational memory cost and slow training speed because they require backpropagation through the entire neural network at each step. In the paper, we analyze the performance of features at different layers of a foundation model on the speech recognition task and propose a novel hierarchical feature fusion method for resource-efficient transfer learning from speech foundation models. Experimental results show that the proposed method can achieve better performance on speech recognition task than existing algorithms with fewer number of trainable parameters, less computational memory cost and faster training speed. After combining with Adapters at all layers, the proposed method can achieve the same performance as fine-tuning the whole model with $97\%$ fewer trainable encoder parameters and $53\%$ faster training speed.
Leveraging Domain Features for Detecting Adversarial Attacks Against Deep Speech Recognition in Noise
Nov 03, 2022
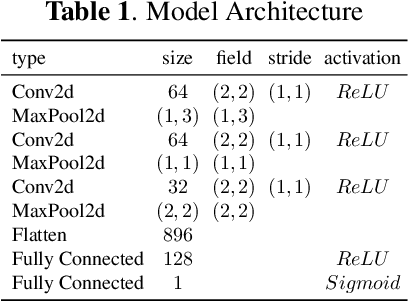
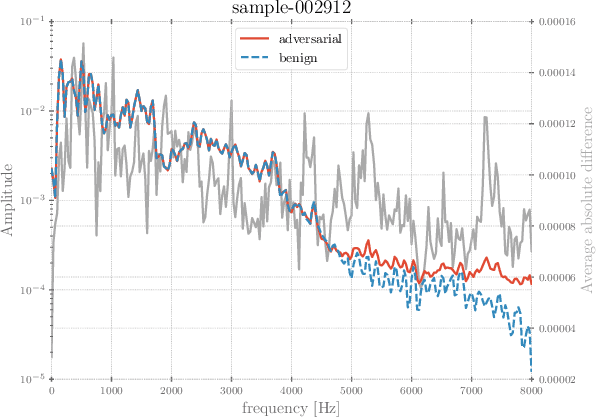
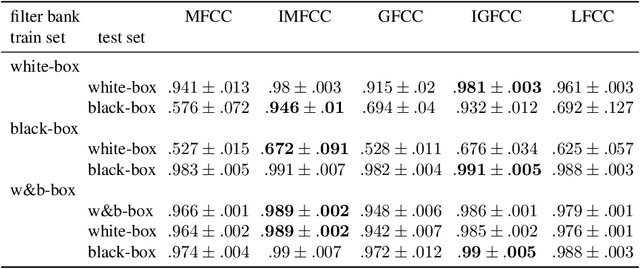
In recent years, significant progress has been made in deep model-based automatic speech recognition (ASR), leading to its widespread deployment in the real world. At the same time, adversarial attacks against deep ASR systems are highly successful. Various methods have been proposed to defend ASR systems from these attacks. However, existing classification based methods focus on the design of deep learning models while lacking exploration of domain specific features. This work leverages filter bank-based features to better capture the characteristics of attacks for improved detection. Furthermore, the paper analyses the potentials of using speech and non-speech parts separately in detecting adversarial attacks. In the end, considering adverse environments where ASR systems may be deployed, we study the impact of acoustic noise of various types and signal-to-noise ratios. Extensive experiments show that the inverse filter bank features generally perform better in both clean and noisy environments, the detection is effective using either speech or non-speech part, and the acoustic noise can largely degrade the detection performance.
Deep Learning-based Spatio Temporal Facial Feature Visual Speech Recognition
Apr 30, 2023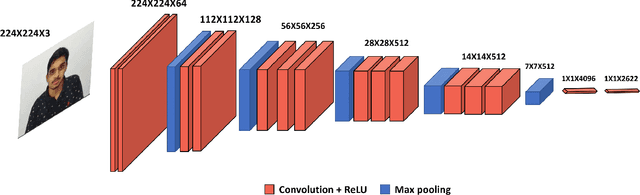
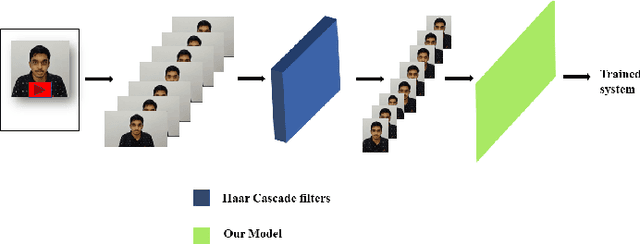

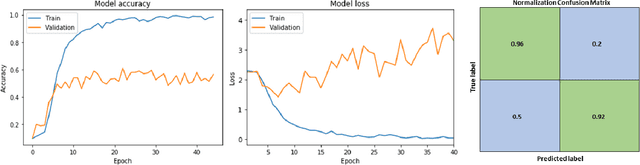
In low-resource computing contexts, such as smartphones and other tiny devices, Both deep learning and machine learning are being used in a lot of identification systems. as authentication techniques. The transparent, contactless, and non-invasive nature of these face recognition technologies driven by AI has led to their meteoric rise in popularity in recent years. While they are mostly successful, there are still methods to get inside without permission by utilising things like pictures, masks, glasses, etc. In this research, we present an alternate authentication process that makes use of both facial recognition and the individual's distinctive temporal facial feature motions while they speak a password. Because the suggested methodology allows for a password to be specified in any language, it is not limited by language. The suggested model attained an accuracy of 96.1% when tested on the industry-standard MIRACL-VC1 dataset, demonstrating its efficacy as a reliable and powerful solution. In addition to being data-efficient, the suggested technique shows promising outcomes with as little as 10 positive video examples for training the model. The effectiveness of the network's training is further proved via comparisons with other combined facial recognition and lip reading models.
Distance-based Weight Transfer from Near-field to Far-field Speaker Verification
Mar 15, 2023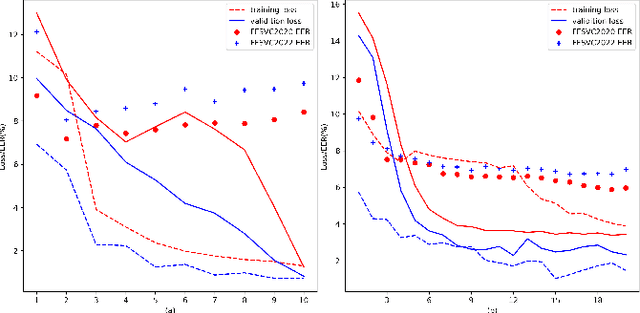
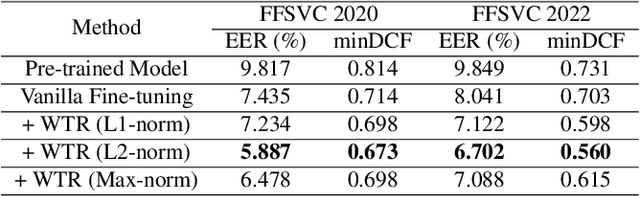
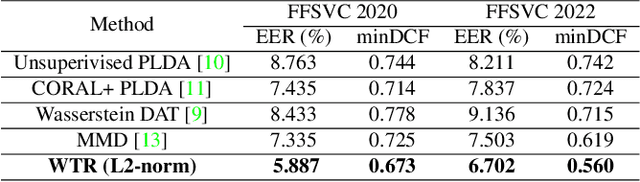
The scarcity of labeled far-field speech is a constraint for training superior far-field speaker verification systems. Fine-tuning the model pre-trained on large-scale near-field speech substantially outperforms training from scratch. However, the fine-tuning method suffers from two limitations--catastrophic forgetting and overfitting. In this paper, we propose a weight transfer regularization(WTR) loss to constrain the distance of the weights between the pre-trained model with large-scale near-field speech and the fine-tuned model through a small number of far-field speech. With the WTR loss, the fine-tuning process takes advantage of the previously acquired discriminative ability from the large-scale near-field speech without catastrophic forgetting. Meanwhile, we use the PAC-Bayes generalization theory to analyze the generalization bound of the fine-tuned model with the WTR loss. The analysis result indicates that the WTR term makes the fine-tuned model have a tighter generalization upper bound. Moreover, we explore three kinds of norm distance for weight transfer, which are L1-norm distance, L2-norm distance and Max-norm distance. Finally, we evaluate the effectiveness of the WTR loss on VoxCeleb (pre-trained dataset) and FFSVC (fine-tuned dataset) datasets.
Filler Word Detection with Hard Category Mining and Inter-Category Focal Loss
Apr 12, 2023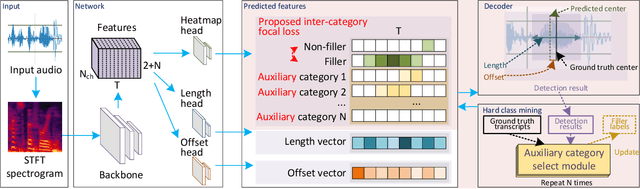
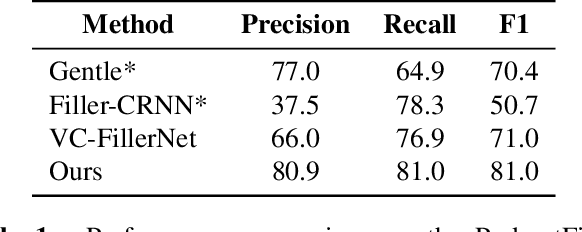
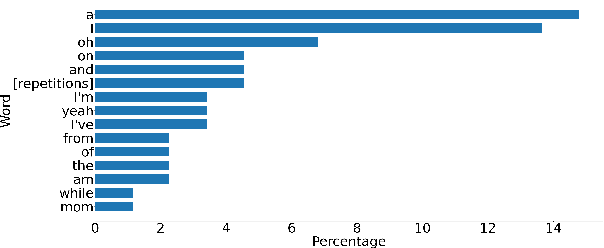
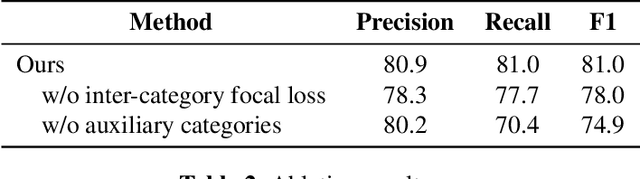
Filler words like ``um" or ``uh" are common in spontaneous speech. It is desirable to automatically detect and remove them in recordings, as they affect the fluency, confidence, and professionalism of speech. Previous studies and our preliminary experiments reveal that the biggest challenge in filler word detection is that fillers can be easily confused with other hard categories like ``a" or ``I". In this paper, we propose a novel filler word detection method that effectively addresses this challenge by adding auxiliary categories dynamically and applying an additional inter-category focal loss. The auxiliary categories force the model to explicitly model the confusing words by mining hard categories. In addition, inter-category focal loss adaptively adjusts the penalty weight between ``filler" and ``non-filler" categories to deal with other confusing words left in the ``non-filler" category. Our system achieves the best results, with a huge improvement compared to other methods on the PodcastFillers dataset.
Naturalistic Head Motion Generation from Speech
Oct 26, 2022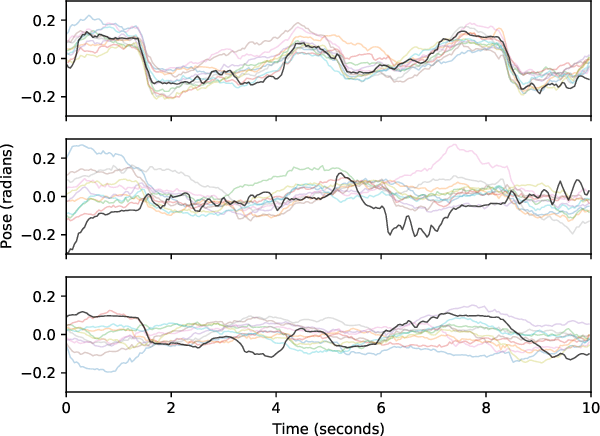
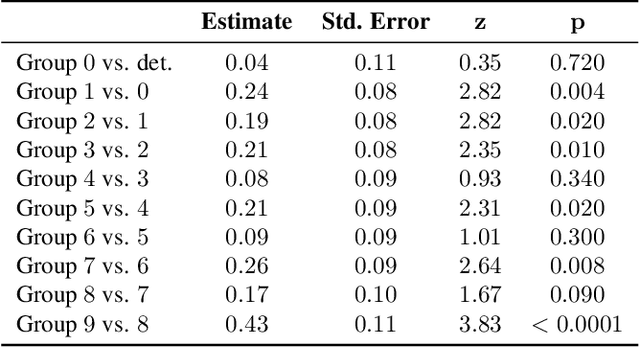
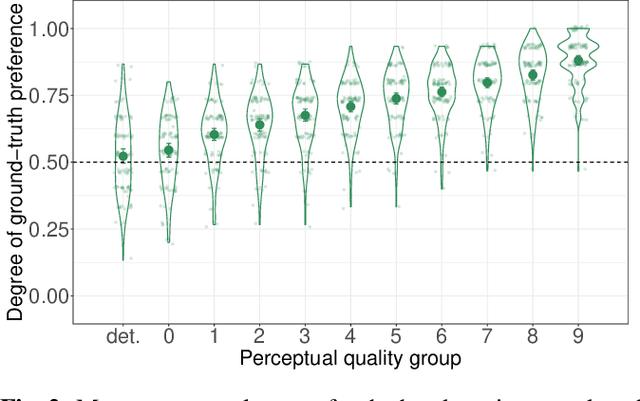
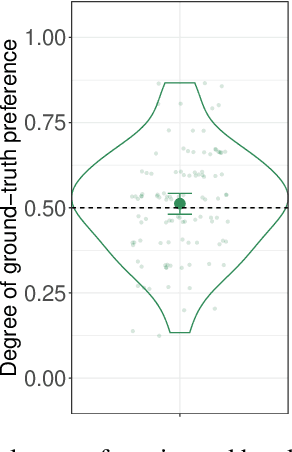
Synthesizing natural head motion to accompany speech for an embodied conversational agent is necessary for providing a rich interactive experience. Most prior works assess the quality of generated head motion by comparing them against a single ground-truth using an objective metric. Yet there are many plausible head motion sequences to accompany a speech utterance. In this work, we study the variation in the perceptual quality of head motions sampled from a generative model. We show that, despite providing more diverse head motions, the generative model produces motions with varying degrees of perceptual quality. We finally show that objective metrics commonly used in previous research do not accurately reflect the perceptual quality of generated head motions. These results open an interesting avenue for future work to investigate better objective metrics that correlate with human perception of quality.
Token-level Speaker Change Detection Using Speaker Difference and Speech Content via Continuous Integrate-and-fire
Nov 17, 2022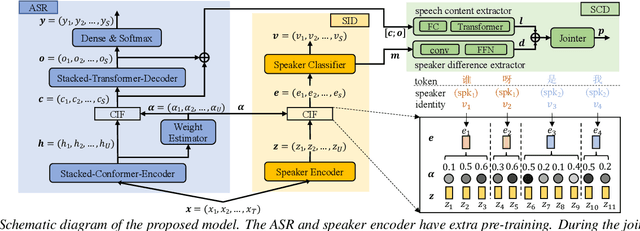
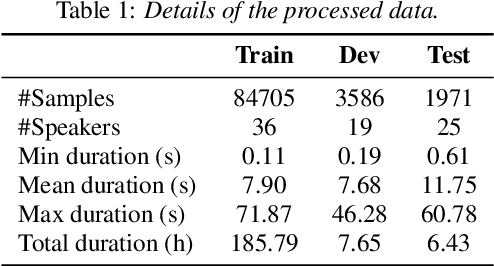
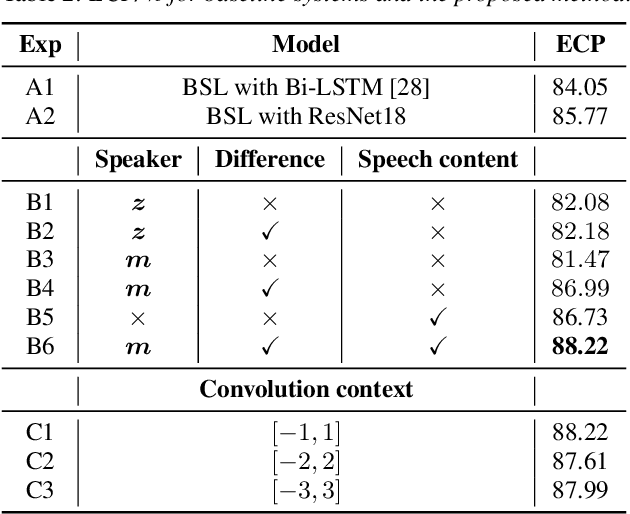
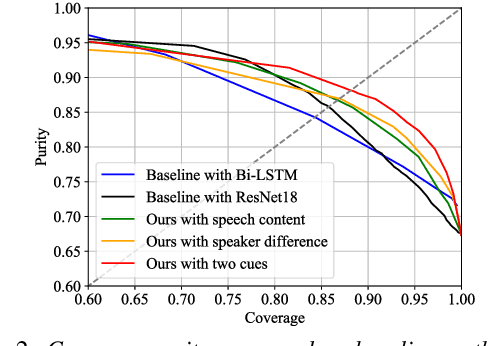
In multi-talker scenarios such as meetings and conversations, speech processing systems are usually required to segment the audio and then transcribe each segmentation. These two stages are addressed separately by speaker change detection (SCD) and automatic speech recognition (ASR). Most previous SCD systems rely solely on speaker information and ignore the importance of speech content. In this paper, we propose a novel SCD system that considers both cues of speaker difference and speech content. These two cues are converted into token-level representations by the continuous integrate-and-fire (CIF) mechanism and then combined for detecting speaker changes on the token acoustic boundaries. We evaluate the performance of our approach on a public real-recorded meeting dataset, AISHELL-4. The experiment results show that our method outperforms a competitive frame-level baseline system by 2.45% equal coverage-purity (ECP). In addition, we demonstrate the importance of speech content and speaker difference to the SCD task, and the advantages of conducting SCD on the token acoustic boundaries compared with conducting SCD frame by frame.