 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Anonymizing Speech with Generative Adversarial Networks to Preserve Speaker Privacy
Oct 20, 2022
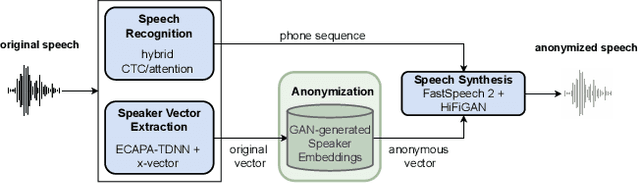
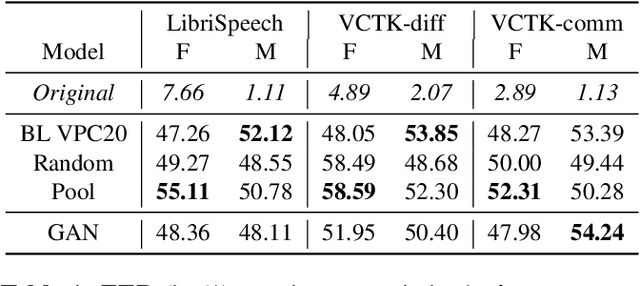
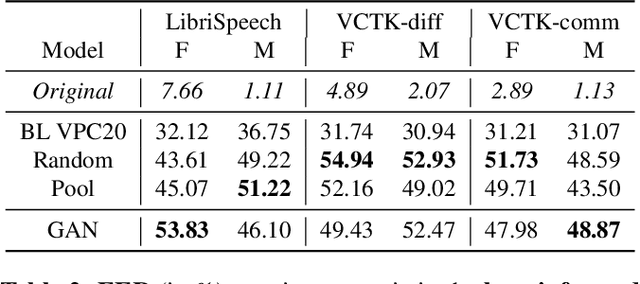
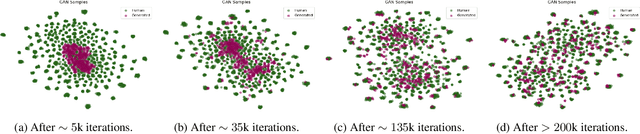
In order to protect the privacy of speech data, speaker anonymization aims for hiding the identity of a speaker by changing the voice in speech recordings. This typically comes with a privacy-utility trade-off between protection of individuals and usability of the data for downstream applications. One of the challenges in this context is to create non-existent voices that sound as natural as possible. In this work, we propose to tackle this issue by generating speaker embeddings using a generative adversarial network with Wasserstein distance as cost function. By incorporating these artificial embeddings into a speech-to-text-to-speech pipeline, we outperform previous approaches in terms of privacy and utility. According to standard objective metrics and human evaluation, our approach generates intelligible and content-preserving yet privacy-protecting versions of the original recordings.
An Adapter based Multi-label Pre-training for Speech Separation and Enhancement
Nov 11, 2022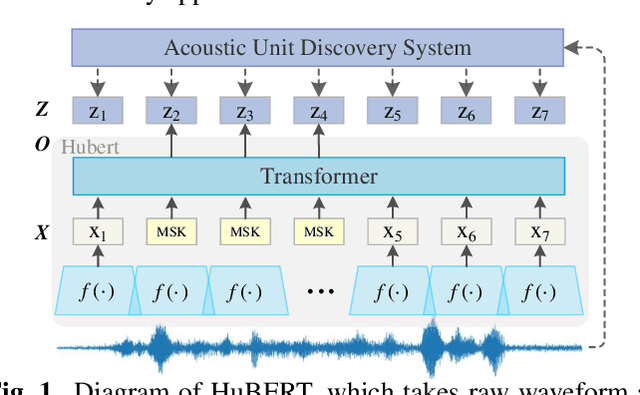
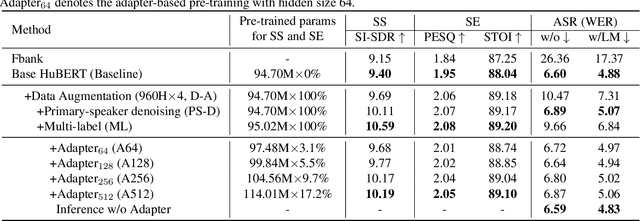
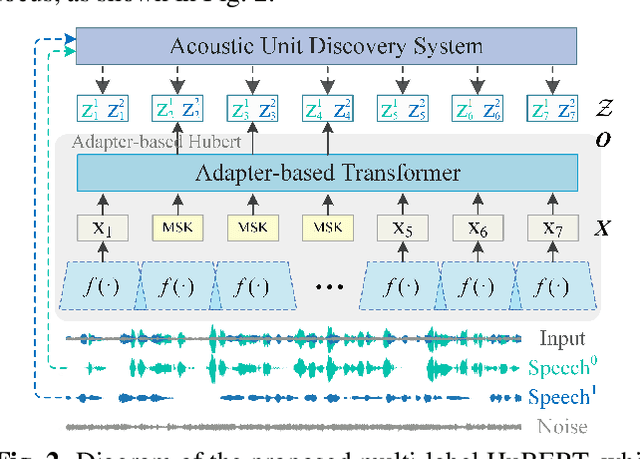
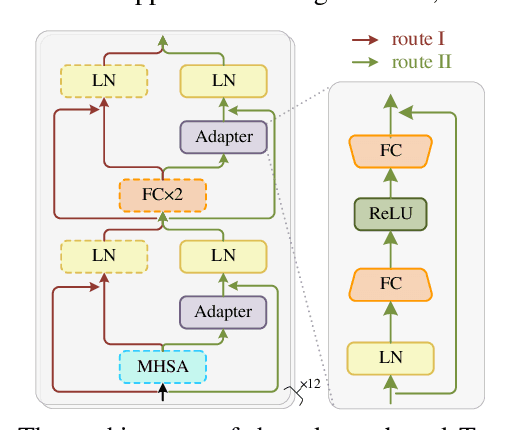
In recent years, self-supervised learning (SSL) has achieved tremendous success in various speech tasks due to its power to extract representations from massive unlabeled data. However, compared with tasks such as speech recognition (ASR), the improvements from SSL representation in speech separation (SS) and enhancement (SE) are considerably smaller. Based on HuBERT, this work investigates improving the SSL model for SS and SE. We first update HuBERT's masked speech prediction (MSP) objective by integrating the separation and denoising terms, resulting in a multiple pseudo label pre-training scheme, which significantly improves HuBERT's performance on SS and SE but degrades the performance on ASR. To maintain its performance gain on ASR, we further propose an adapter-based architecture for HuBERT's Transformer encoder, where only a few parameters of each layer are adjusted to the multiple pseudo label MSP while other parameters remain frozen as default HuBERT. Experimental results show that our proposed adapter-based multiple pseudo label HuBERT yield consistent and significant performance improvements on SE, SS, and ASR tasks, with a faster pre-training speed, at only marginal parameters increase.
Cross-Modal Mutual Learning for Cued Speech Recognition
Dec 02, 2022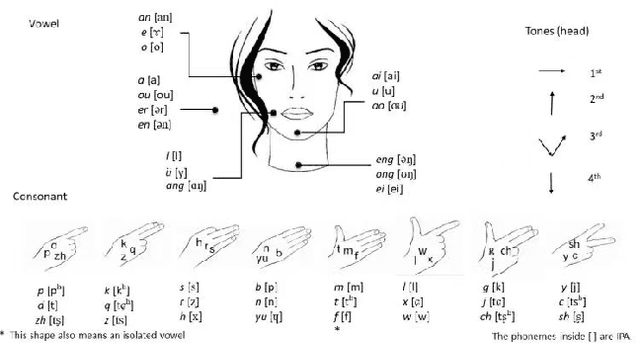
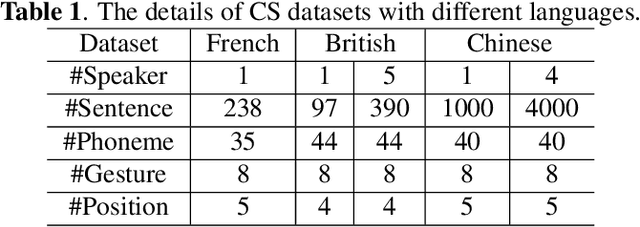
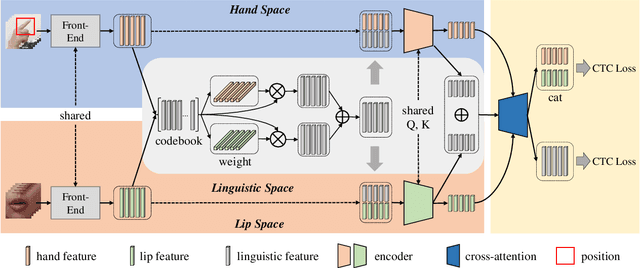
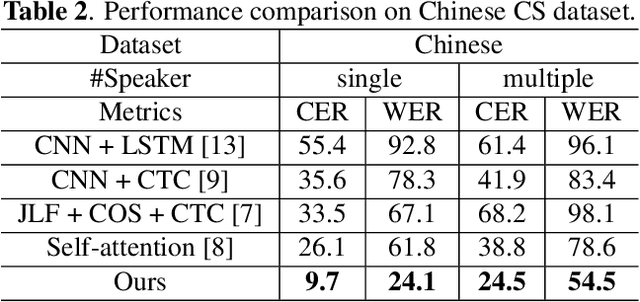
Automatic Cued Speech Recognition (ACSR) provides an intelligent human-machine interface for visual communications, where the Cued Speech (CS) system utilizes lip movements and hand gestures to code spoken language for hearing-impaired people. Previous ACSR approaches often utilize direct feature concatenation as the main fusion paradigm. However, the asynchronous modalities (\textit{i.e.}, lip, hand shape and hand position) in CS may cause interference for feature concatenation. To address this challenge, we propose a transformer based cross-modal mutual learning framework to prompt multi-modal interaction. Compared with the vanilla self-attention, our model forces modality-specific information of different modalities to pass through a modality-invariant codebook, collating linguistic representations for tokens of each modality. Then the shared linguistic knowledge is used to re-synchronize multi-modal sequences. Moreover, we establish a novel large-scale multi-speaker CS dataset for Mandarin Chinese. To our knowledge, this is the first work on ACSR for Mandarin Chinese. Extensive experiments are conducted for different languages (\textit{i.e.}, Chinese, French, and British English). Results demonstrate that our model exhibits superior recognition performance to the state-of-the-art by a large margin.
Neural Speech Phase Prediction based on Parallel Estimation Architecture and Anti-Wrapping Losses
Nov 29, 2022

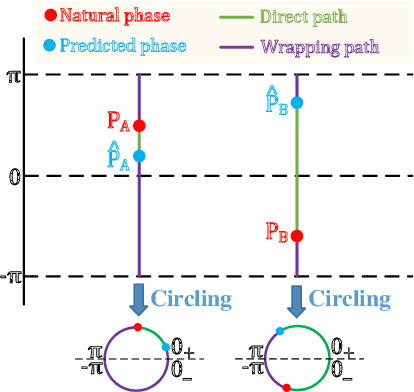
This paper presents a novel speech phase prediction model which predicts wrapped phase spectra directly from amplitude spectra by neural networks. The proposed model is a cascade of a residual convolutional network and a parallel estimation architecture. The parallel estimation architecture is composed of two parallel linear convolutional layers and a phase calculation formula, imitating the process of calculating the phase spectra from the real and imaginary parts of complex spectra and strictly restricting the predicted phase values to the principal value interval. To avoid the error expansion issue caused by phase wrapping, we design anti-wrapping training losses defined between the predicted wrapped phase spectra and natural ones by activating the instantaneous phase error, group delay error and instantaneous angular frequency error using an anti-wrapping function. Experimental results show that our proposed neural speech phase prediction model outperforms the iterative Griffin-Lim algorithm and other neural network-based method, in terms of both reconstructed speech quality and generation speed.
Deep Speech Synthesis from Articulatory Representations
Sep 13, 2022

In the articulatory synthesis task, speech is synthesized from input features containing information about the physical behavior of the human vocal tract. This task provides a promising direction for speech synthesis research, as the articulatory space is compact, smooth, and interpretable. Current works have highlighted the potential for deep learning models to perform articulatory synthesis. However, it remains unclear whether these models can achieve the efficiency and fidelity of the human speech production system. To help bridge this gap, we propose a time-domain articulatory synthesis methodology and demonstrate its efficacy with both electromagnetic articulography (EMA) and synthetic articulatory feature inputs. Our model is computationally efficient and achieves a transcription word error rate (WER) of 18.5% for the EMA-to-speech task, yielding an improvement of 11.6% compared to prior work. Through interpolation experiments, we also highlight the generalizability and interpretability of our approach.
EmoDiff: Intensity Controllable Emotional Text-to-Speech with Soft-Label Guidance
Nov 17, 2022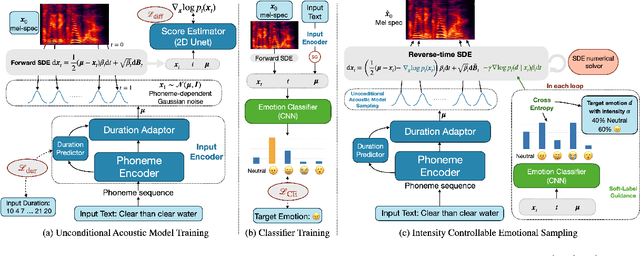
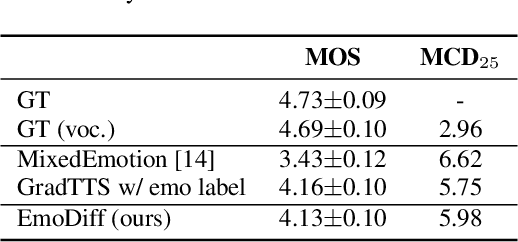

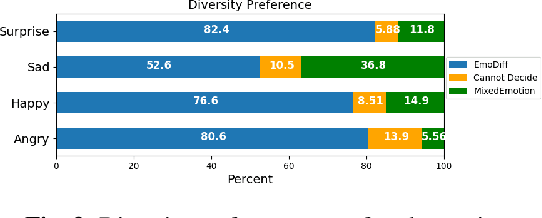
Although current neural text-to-speech (TTS) models are able to generate high-quality speech, intensity controllable emotional TTS is still a challenging task. Most existing methods need external optimizations for intensity calculation, leading to suboptimal results or degraded quality. In this paper, we propose EmoDiff, a diffusion-based TTS model where emotion intensity can be manipulated by a proposed soft-label guidance technique derived from classifier guidance. Specifically, instead of being guided with a one-hot vector for the specified emotion, EmoDiff is guided with a soft label where the value of the specified emotion and \textit{Neutral} is set to $\alpha$ and $1-\alpha$ respectively. The $\alpha$ here represents the emotion intensity and can be chosen from 0 to 1. Our experiments show that EmoDiff can precisely control the emotion intensity while maintaining high voice quality. Moreover, diverse speech with specified emotion intensity can be generated by sampling in the reverse denoising process.
Efficiently Trained Mongolian Text-to-Speech System Based On FullConv
Oct 24, 2022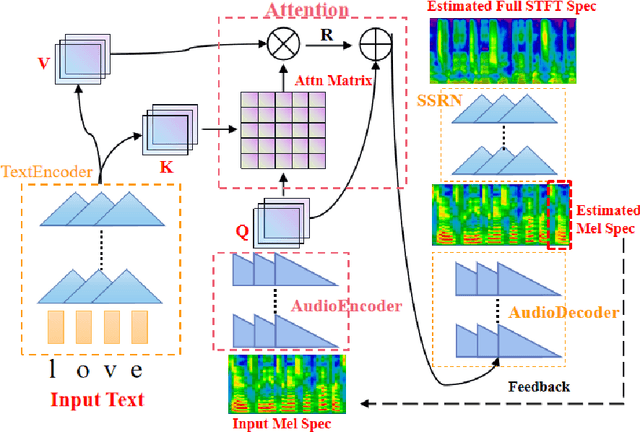
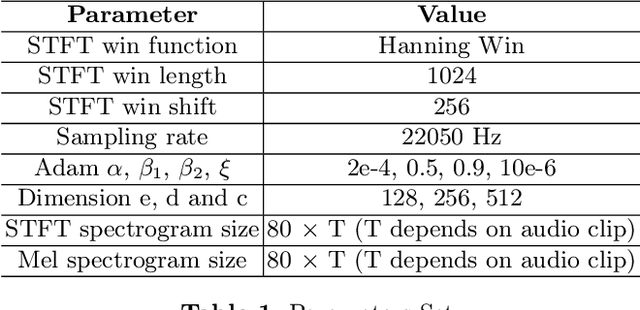
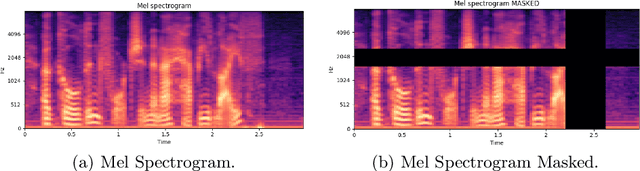
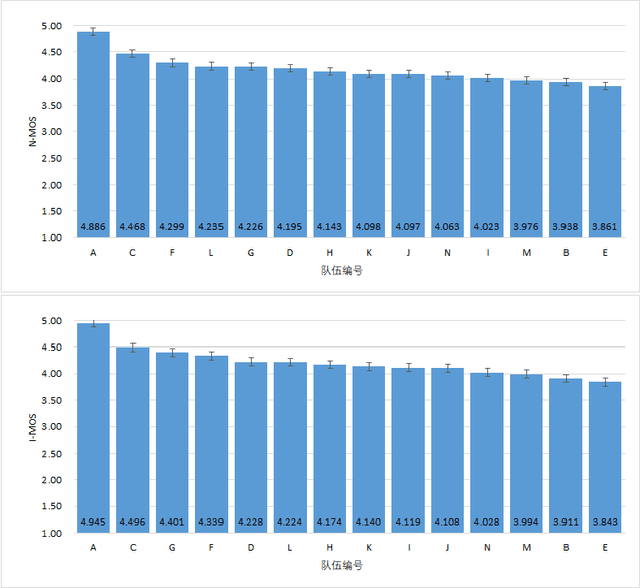
Recurrent Neural Networks (RNNs) have become the standard modeling technique for sequence data, and are used in a number of novel text-to-speech models. However, training a TTS model including RNN components has certain requirements for GPU performance and takes a long time. In contrast, studies have shown that CNN-based sequence synthesis technology can greatly reduce training time in text-to-speech models while ensuring a certain performance due to its high parallelism. We propose a new text-to-speech system based on deep convolutional neural networks that does not employ any RNN components (recurrent units). At the same time, we improve the generality and robustness of our model through a series of data augmentation methods such as Time Warping, Frequency Mask, and Time Mask. The final experimental results show that the TTS model using only the CNN component can reduce the training time compared to the classic TTS models such as Tacotron while ensuring the quality of the synthesized speech.
E2E Spoken Entity Extraction for Virtual Agents
Mar 01, 2023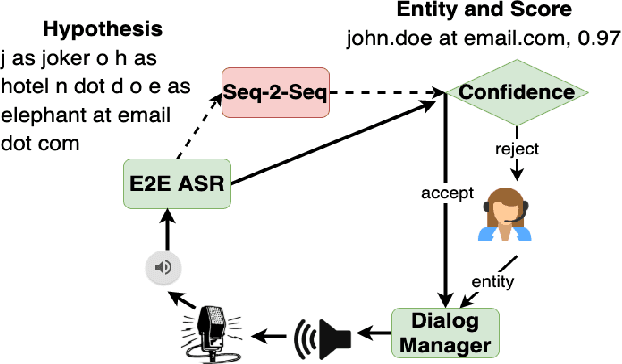
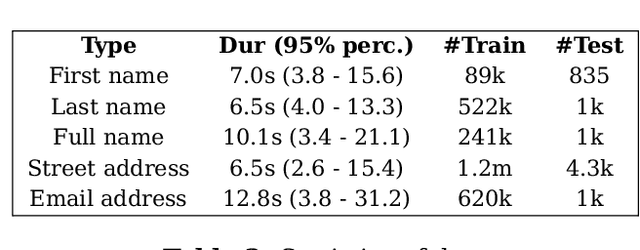
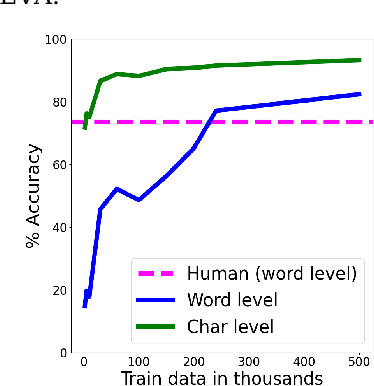

This paper reimagines some aspects of speech processing using speech encoders, specifically about extracting entities directly from speech, with no intermediate textual representation. In human-computer conversations, extracting entities such as names, postal addresses and email addresses from speech is a challenging task. In this paper, we study the impact of fine-tuning pre-trained speech encoders on extracting spoken entities in human-readable form directly from speech without the need for text transcription. We illustrate that such a direct approach optimizes the encoder to transcribe only the entity relevant portions of speech, ignoring the superfluous portions such as carrier phrases and spellings of entities. In the context of dialogs from an enterprise virtual agent, we demonstrate that the 1-step approach outperforms the typical 2-step cascade of first generating lexical transcriptions followed by text-based entity extraction for identifying spoken entities.
Combining Automatic Speaker Verification and Prosody Analysis for Synthetic Speech Detection
Oct 31, 2022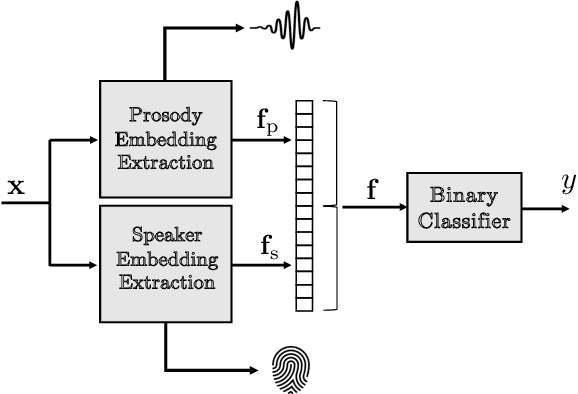
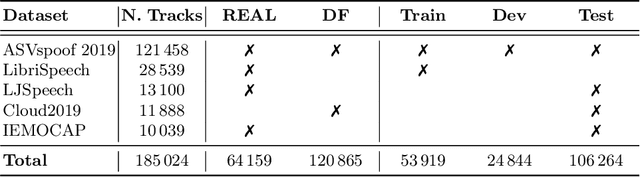
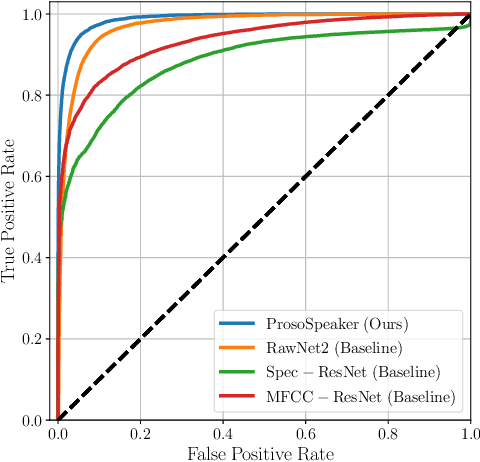
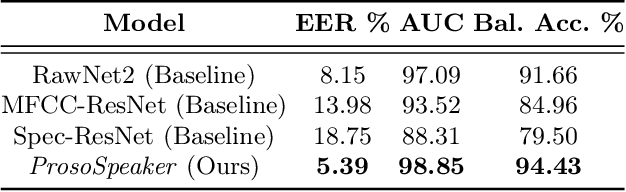
The rapid spread of media content synthesis technology and the potentially damaging impact of audio and video deepfakes on people's lives have raised the need to implement systems able to detect these forgeries automatically. In this work we present a novel approach for synthetic speech detection, exploiting the combination of two high-level semantic properties of the human voice. On one side, we focus on speaker identity cues and represent them as speaker embeddings extracted using a state-of-the-art method for the automatic speaker verification task. On the other side, voice prosody, intended as variations in rhythm, pitch or accent in speech, is extracted through a specialized encoder. We show that the combination of these two embeddings fed to a supervised binary classifier allows the detection of deepfake speech generated with both Text-to-Speech and Voice Conversion techniques. Our results show improvements over the considered baselines, good generalization properties over multiple datasets and robustness to audio compression.
Source Free Domain Adaptation of a DNN for SSVEP-based Brain-Computer Interfaces
May 27, 2023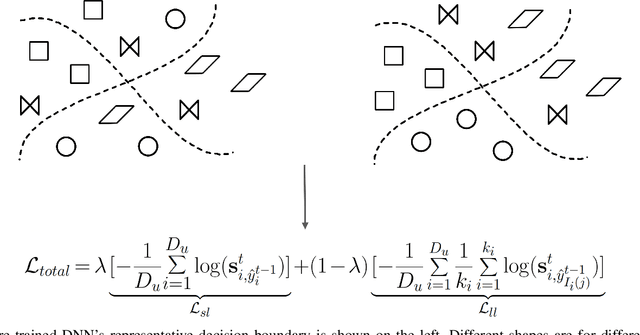
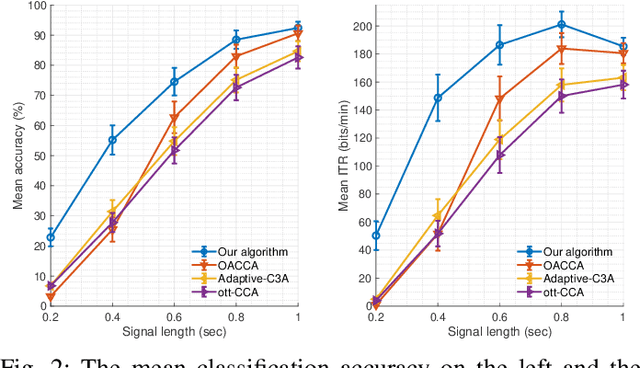
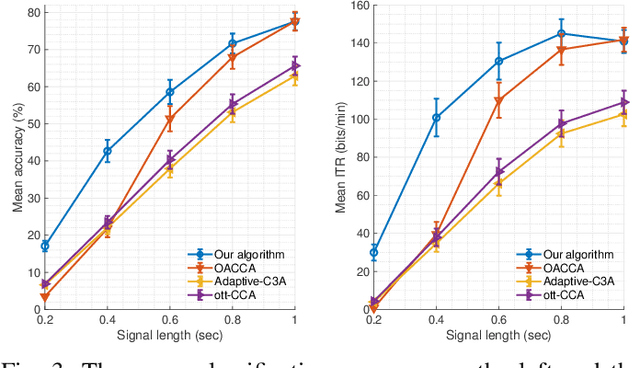
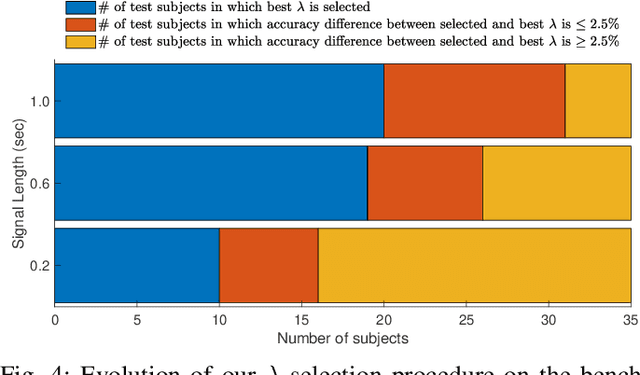
This paper presents a source free domain adaptation method for steady-state visually evoked potential (SSVEP) based brain-computer interface (BCI) spellers. SSVEP-based BCI spellers help individuals experiencing speech difficulties, enabling them to communicate at a fast rate. However, achieving a high information transfer rate (ITR) in the current methods requires an extensive calibration period before using the system, leading to discomfort for new users. We address this issue by proposing a method that adapts the deep neural network (DNN) pre-trained on data from source domains (participants of previous experiments conducted for labeled data collection), using only the unlabeled data of the new user (target domain). This adaptation is achieved by minimizing our proposed custom loss function composed of self-adaptation and local-regularity loss terms. The self-adaptation term uses the pseudo-label strategy, while the novel local-regularity term exploits the data structure and forces the DNN to assign the same labels to adjacent instances. Our method achieves striking 201.15 bits/min and 145.02 bits/min ITRs on the benchmark and BETA datasets, respectively, and outperforms the state-of-the-art alternative techniques. Our approach alleviates user discomfort and shows excellent identification performance, so it would potentially contribute to the broader application of SSVEP-based BCI systems in everyday life.