 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
How "open" are the conversations with open-domain chatbots? A proposal for Speech Event based evaluation
Nov 24, 2022
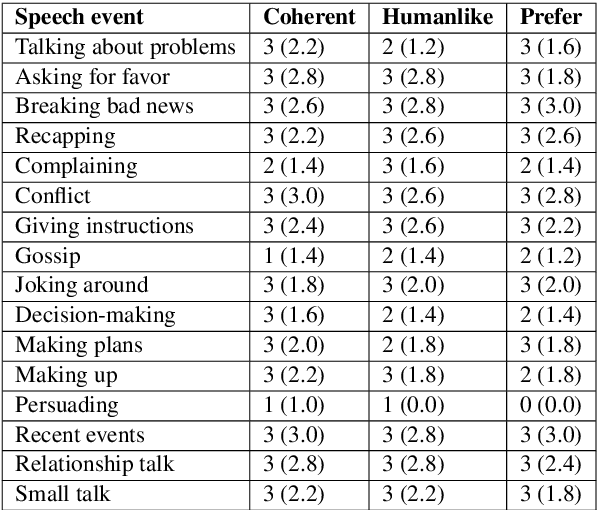
Open-domain chatbots are supposed to converse freely with humans without being restricted to a topic, task or domain. However, the boundaries and/or contents of open-domain conversations are not clear. To clarify the boundaries of "openness", we conduct two studies: First, we classify the types of "speech events" encountered in a chatbot evaluation data set (i.e., Meena by Google) and find that these conversations mainly cover the "small talk" category and exclude the other speech event categories encountered in real life human-human communication. Second, we conduct a small-scale pilot study to generate online conversations covering a wider range of speech event categories between two humans vs. a human and a state-of-the-art chatbot (i.e., Blender by Facebook). A human evaluation of these generated conversations indicates a preference for human-human conversations, since the human-chatbot conversations lack coherence in most speech event categories. Based on these results, we suggest (a) using the term "small talk" instead of "open-domain" for the current chatbots which are not that "open" in terms of conversational abilities yet, and (b) revising the evaluation methods to test the chatbot conversations against other speech events.
Cross-Modal Mutual Learning for Cued Speech Recognition
Dec 02, 2022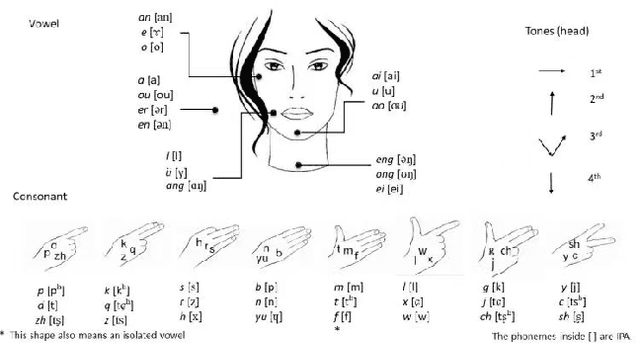
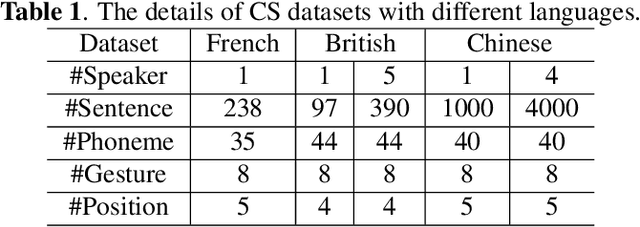
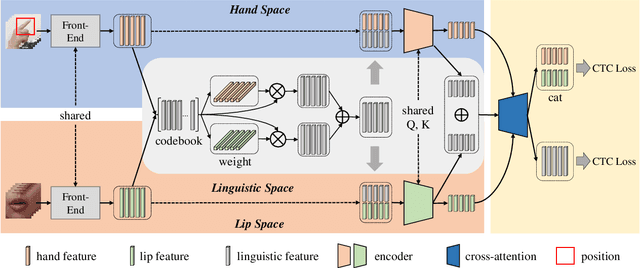
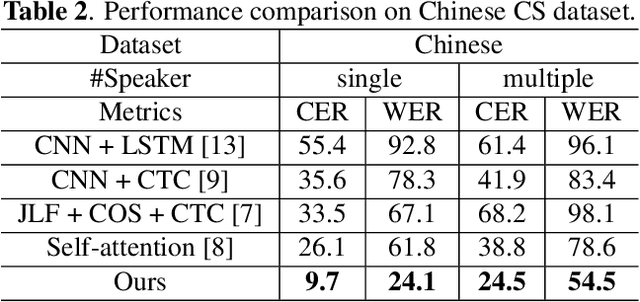
Automatic Cued Speech Recognition (ACSR) provides an intelligent human-machine interface for visual communications, where the Cued Speech (CS) system utilizes lip movements and hand gestures to code spoken language for hearing-impaired people. Previous ACSR approaches often utilize direct feature concatenation as the main fusion paradigm. However, the asynchronous modalities (\textit{i.e.}, lip, hand shape and hand position) in CS may cause interference for feature concatenation. To address this challenge, we propose a transformer based cross-modal mutual learning framework to prompt multi-modal interaction. Compared with the vanilla self-attention, our model forces modality-specific information of different modalities to pass through a modality-invariant codebook, collating linguistic representations for tokens of each modality. Then the shared linguistic knowledge is used to re-synchronize multi-modal sequences. Moreover, we establish a novel large-scale multi-speaker CS dataset for Mandarin Chinese. To our knowledge, this is the first work on ACSR for Mandarin Chinese. Extensive experiments are conducted for different languages (\textit{i.e.}, Chinese, French, and British English). Results demonstrate that our model exhibits superior recognition performance to the state-of-the-art by a large margin.
Neural Speech Phase Prediction based on Parallel Estimation Architecture and Anti-Wrapping Losses
Nov 29, 2022

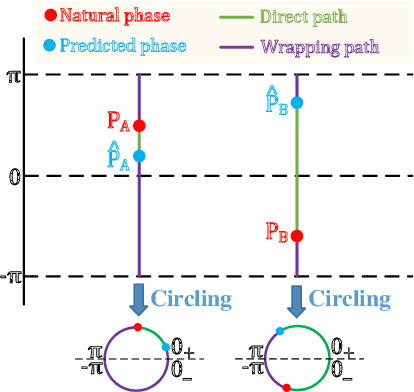
This paper presents a novel speech phase prediction model which predicts wrapped phase spectra directly from amplitude spectra by neural networks. The proposed model is a cascade of a residual convolutional network and a parallel estimation architecture. The parallel estimation architecture is composed of two parallel linear convolutional layers and a phase calculation formula, imitating the process of calculating the phase spectra from the real and imaginary parts of complex spectra and strictly restricting the predicted phase values to the principal value interval. To avoid the error expansion issue caused by phase wrapping, we design anti-wrapping training losses defined between the predicted wrapped phase spectra and natural ones by activating the instantaneous phase error, group delay error and instantaneous angular frequency error using an anti-wrapping function. Experimental results show that our proposed neural speech phase prediction model outperforms the iterative Griffin-Lim algorithm and other neural network-based method, in terms of both reconstructed speech quality and generation speed.
An ASR-free Fluency Scoring Approach with Self-Supervised Learning
Mar 13, 2023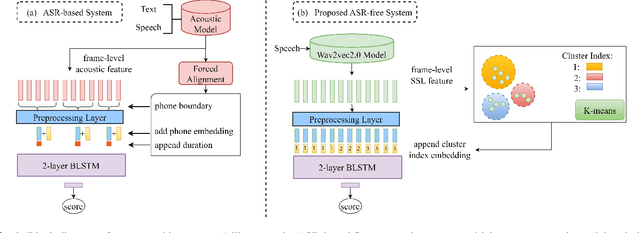
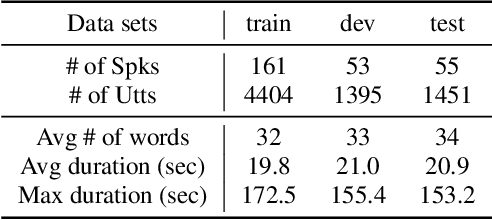
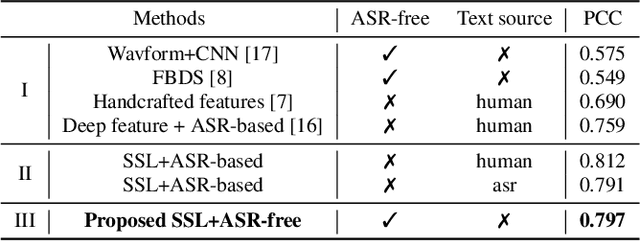
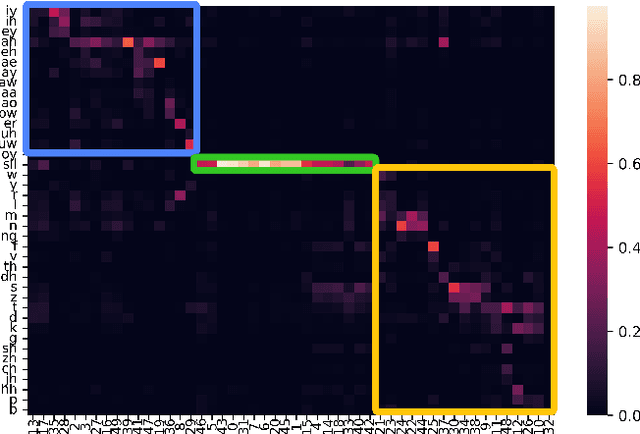
A typical fluency scoring system generally relies on an automatic speech recognition (ASR) system to obtain time stamps in input speech for either the subsequent calculation of fluency-related features or directly modeling speech fluency with an end-to-end approach. This paper describes a novel ASR-free approach for automatic fluency assessment using self-supervised learning (SSL). Specifically, wav2vec2.0 is used to extract frame-level speech features, followed by K-means clustering to assign a pseudo label (cluster index) to each frame. A BLSTM-based model is trained to predict an utterance-level fluency score from frame-level SSL features and the corresponding cluster indexes. Neither speech transcription nor time stamp information is required in the proposed system. It is ASR-free and can potentially avoid the ASR errors effect in practice. Experimental results carried out on non-native English databases show that the proposed approach significantly improves the performance in the "open response" scenario as compared to previous methods and matches the recently reported performance in the "read aloud" scenario.
Confidence Score Based Speaker Adaptation of Conformer Speech Recognition Systems
Feb 15, 2023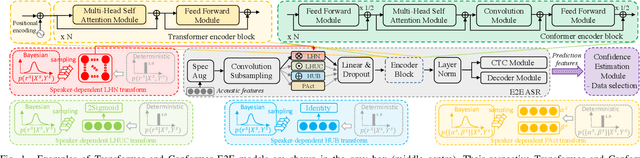
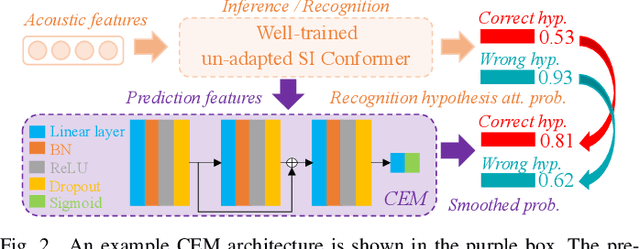
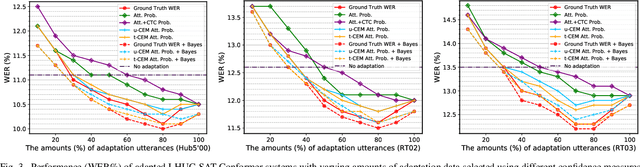
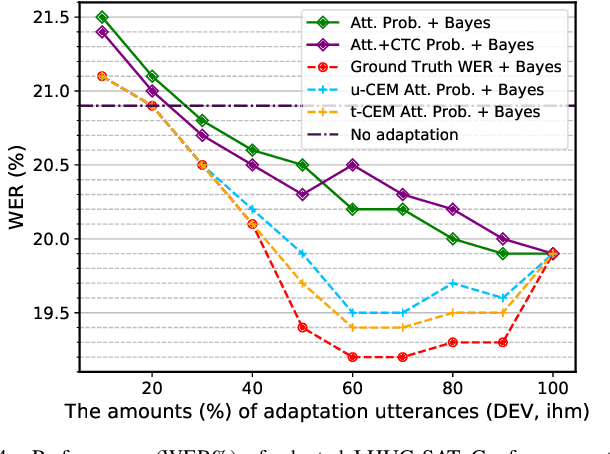
Speaker adaptation techniques provide a powerful solution to customise automatic speech recognition (ASR) systems for individual users. Practical application of unsupervised model-based speaker adaptation techniques to data intensive end-to-end ASR systems is hindered by the scarcity of speaker-level data and performance sensitivity to transcription errors. To address these issues, a set of compact and data efficient speaker-dependent (SD) parameter representations are used to facilitate both speaker adaptive training and test-time unsupervised speaker adaptation of state-of-the-art Conformer ASR systems. The sensitivity to supervision quality is reduced using a confidence score-based selection of the less erroneous subset of speaker-level adaptation data. Two lightweight confidence score estimation modules are proposed to produce more reliable confidence scores. The data sparsity issue, which is exacerbated by data selection, is addressed by modelling the SD parameter uncertainty using Bayesian learning. Experiments on the benchmark 300-hour Switchboard and the 233-hour AMI datasets suggest that the proposed confidence score-based adaptation schemes consistently outperformed the baseline speaker-independent (SI) Conformer model and conventional non-Bayesian, point estimate-based adaptation using no speaker data selection. Similar consistent performance improvements were retained after external Transformer and LSTM language model rescoring. In particular, on the 300-hour Switchboard corpus, statistically significant WER reductions of 1.0%, 1.3%, and 1.4% absolute (9.5%, 10.9%, and 11.3% relative) were obtained over the baseline SI Conformer on the NIST Hub5'00, RT02, and RT03 evaluation sets respectively. Similar WER reductions of 2.7% and 3.3% absolute (8.9% and 10.2% relative) were also obtained on the AMI development and evaluation sets.
An Adapter based Multi-label Pre-training for Speech Separation and Enhancement
Nov 11, 2022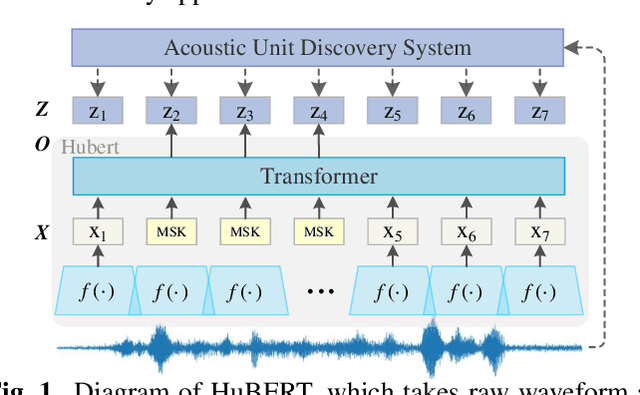
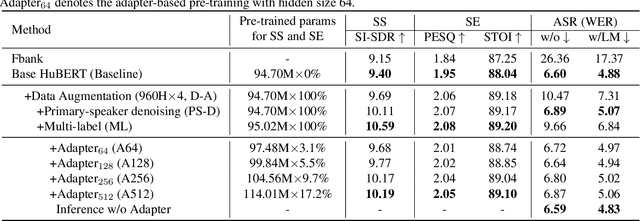
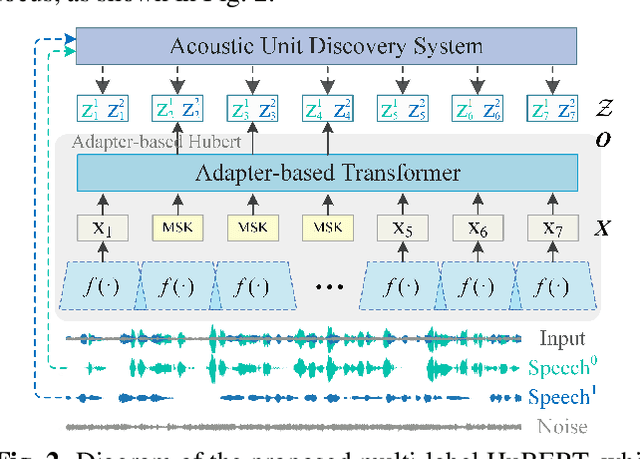
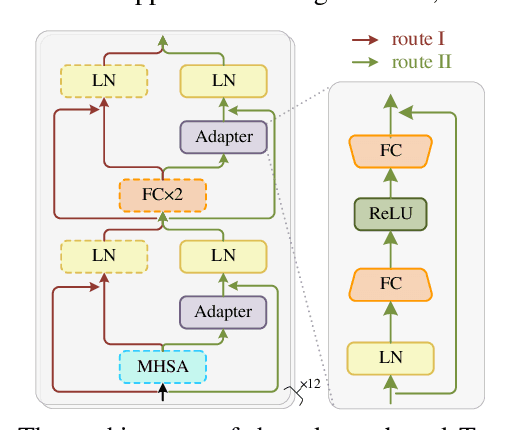
In recent years, self-supervised learning (SSL) has achieved tremendous success in various speech tasks due to its power to extract representations from massive unlabeled data. However, compared with tasks such as speech recognition (ASR), the improvements from SSL representation in speech separation (SS) and enhancement (SE) are considerably smaller. Based on HuBERT, this work investigates improving the SSL model for SS and SE. We first update HuBERT's masked speech prediction (MSP) objective by integrating the separation and denoising terms, resulting in a multiple pseudo label pre-training scheme, which significantly improves HuBERT's performance on SS and SE but degrades the performance on ASR. To maintain its performance gain on ASR, we further propose an adapter-based architecture for HuBERT's Transformer encoder, where only a few parameters of each layer are adjusted to the multiple pseudo label MSP while other parameters remain frozen as default HuBERT. Experimental results show that our proposed adapter-based multiple pseudo label HuBERT yield consistent and significant performance improvements on SE, SS, and ASR tasks, with a faster pre-training speed, at only marginal parameters increase.
EmoDiff: Intensity Controllable Emotional Text-to-Speech with Soft-Label Guidance
Nov 17, 2022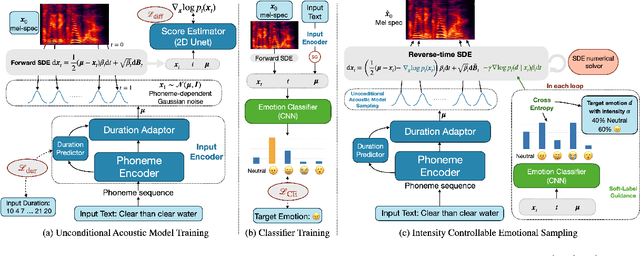
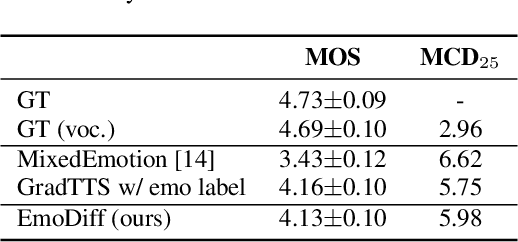

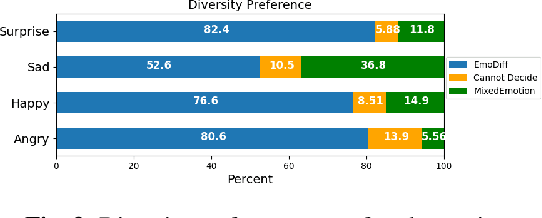
Although current neural text-to-speech (TTS) models are able to generate high-quality speech, intensity controllable emotional TTS is still a challenging task. Most existing methods need external optimizations for intensity calculation, leading to suboptimal results or degraded quality. In this paper, we propose EmoDiff, a diffusion-based TTS model where emotion intensity can be manipulated by a proposed soft-label guidance technique derived from classifier guidance. Specifically, instead of being guided with a one-hot vector for the specified emotion, EmoDiff is guided with a soft label where the value of the specified emotion and \textit{Neutral} is set to $\alpha$ and $1-\alpha$ respectively. The $\alpha$ here represents the emotion intensity and can be chosen from 0 to 1. Our experiments show that EmoDiff can precisely control the emotion intensity while maintaining high voice quality. Moreover, diverse speech with specified emotion intensity can be generated by sampling in the reverse denoising process.
Code-Switching without Switching: Language Agnostic End-to-End Speech Translation
Oct 04, 2022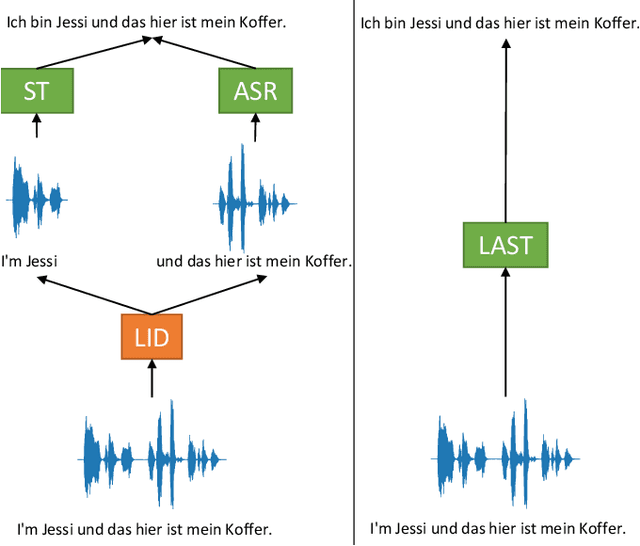
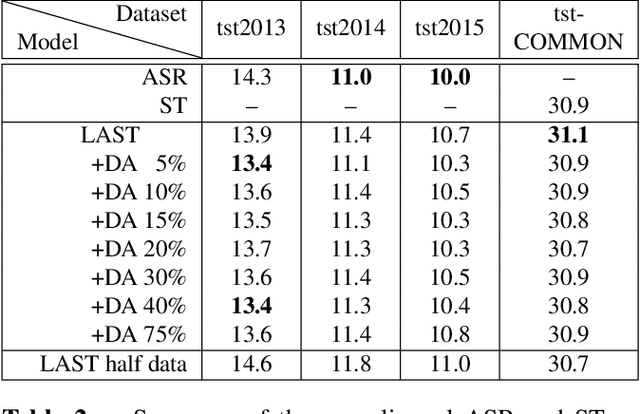
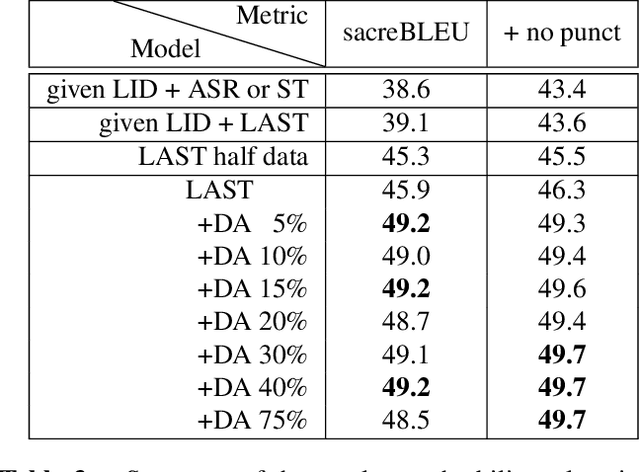
We propose a) a Language Agnostic end-to-end Speech Translation model (LAST), and b) a data augmentation strategy to increase code-switching (CS) performance. With increasing globalization, multiple languages are increasingly used interchangeably during fluent speech. Such CS complicates traditional speech recognition and translation, as we must recognize which language was spoken first and then apply a language-dependent recognizer and subsequent translation component to generate the desired target language output. Such a pipeline introduces latency and errors. In this paper, we eliminate the need for that, by treating speech recognition and translation as one unified end-to-end speech translation problem. By training LAST with both input languages, we decode speech into one target language, regardless of the input language. LAST delivers comparable recognition and speech translation accuracy in monolingual usage, while reducing latency and error rate considerably when CS is observed.
Accurate and Reliable Confidence Estimation Based on Non-Autoregressive End-to-End Speech Recognition System
May 18, 2023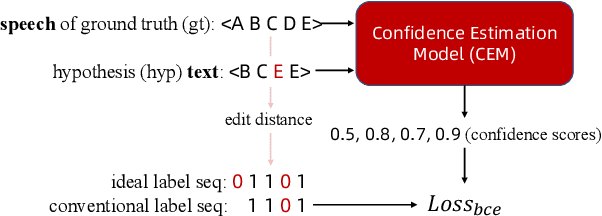
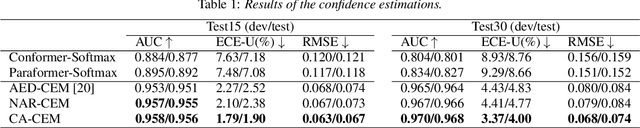
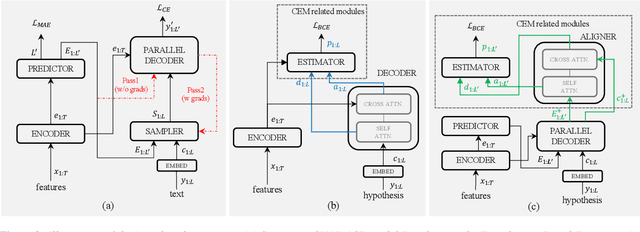
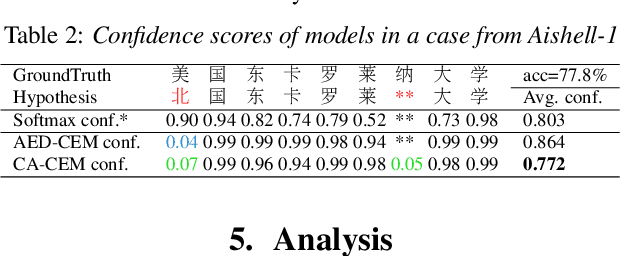
Estimating confidence scores for recognition results is a classic task in ASR field and of vital importance for kinds of downstream tasks and training strategies. Previous end-to-end~(E2E) based confidence estimation models (CEM) predict score sequences of equal length with input transcriptions, leading to unreliable estimation when deletion and insertion errors occur. In this paper we proposed CIF-Aligned confidence estimation model (CA-CEM) to achieve accurate and reliable confidence estimation based on novel non-autoregressive E2E ASR model - Paraformer. CA-CEM utilizes the modeling character of continuous integrate-and-fire (CIF) mechanism to generate token-synchronous acoustic embedding, which solves the estimation failure issue above. We measure the quality of estimation with AUC and RMSE in token level and ECE-U - a proposed metrics in utterance level. CA-CEM gains 24% and 19% relative reduction on ECE-U and also better AUC and RMSE on two test sets. Furthermore, we conduct analysis to explore the potential of CEM for different ASR related usage.
Anonymizing Speech with Generative Adversarial Networks to Preserve Speaker Privacy
Oct 20, 2022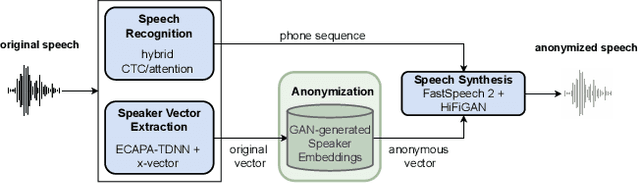
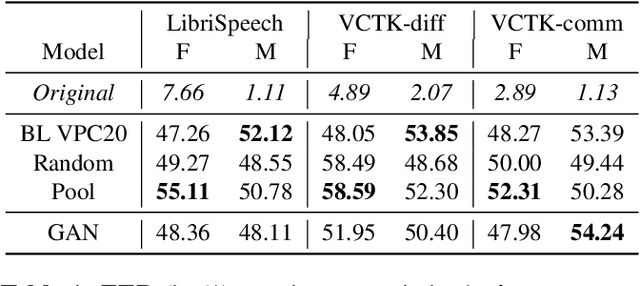
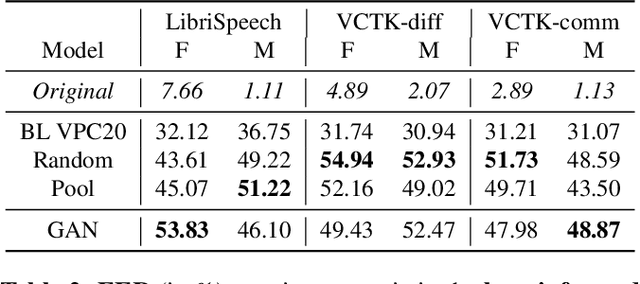
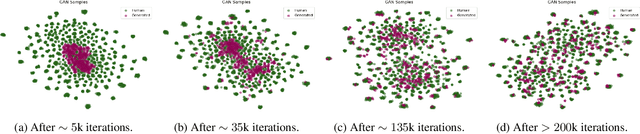
In order to protect the privacy of speech data, speaker anonymization aims for hiding the identity of a speaker by changing the voice in speech recordings. This typically comes with a privacy-utility trade-off between protection of individuals and usability of the data for downstream applications. One of the challenges in this context is to create non-existent voices that sound as natural as possible. In this work, we propose to tackle this issue by generating speaker embeddings using a generative adversarial network with Wasserstein distance as cost function. By incorporating these artificial embeddings into a speech-to-text-to-speech pipeline, we outperform previous approaches in terms of privacy and utility. According to standard objective metrics and human evaluation, our approach generates intelligible and content-preserving yet privacy-protecting versions of the original recordings.