 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
MIMO-DBnet: Multi-channel Input and Multiple Outputs DOA-aware Beamforming Network for Speech Separation
Dec 07, 2022

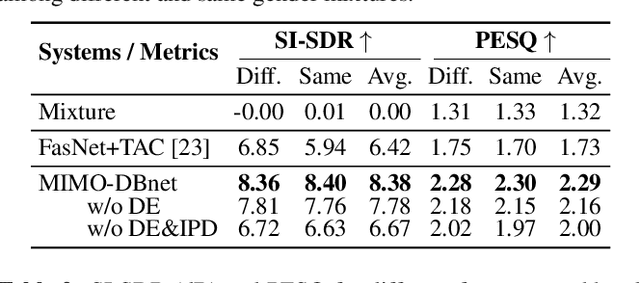
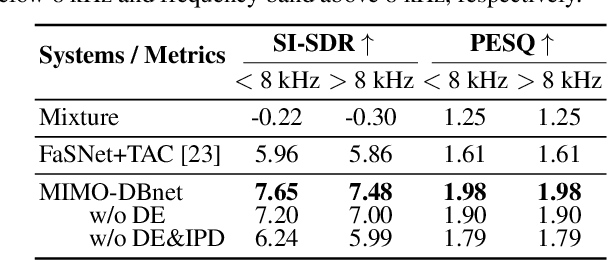
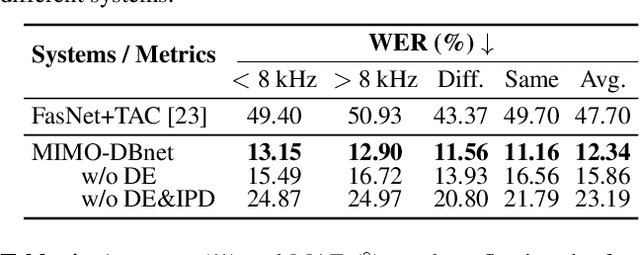
Recently, many deep learning based beamformers have been proposed for multi-channel speech separation. Nevertheless, most of them rely on extra cues known in advance, such as speaker feature, face image or directional information. In this paper, we propose an end-to-end beamforming network for direction guided speech separation given merely the mixture signal, namely MIMO-DBnet. Specifically, we design a multi-channel input and multiple outputs architecture to predict the direction-of-arrival based embeddings and beamforming weights for each source. The precisely estimated directional embedding provides quite effective spatial discrimination guidance for the neural beamformer to offset the effect of phase wrapping, thus allowing more accurate reconstruction of two sources' speech signals. Experiments show that our proposed MIMO-DBnet not only achieves a comprehensive decent improvement compared to baseline systems, but also maintain the performance on high frequency bands when phase wrapping occurs.
THLNet: two-stage heterogeneous lightweight network for monaural speech enhancement
Jan 19, 2023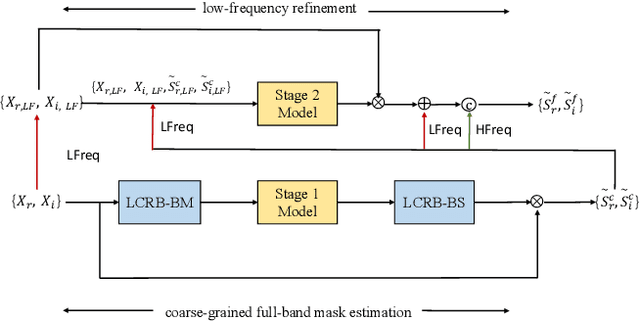
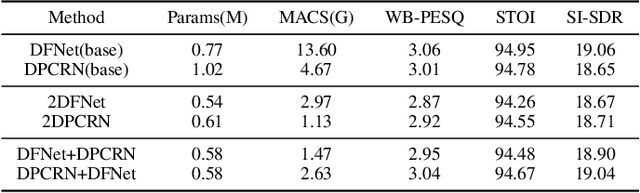
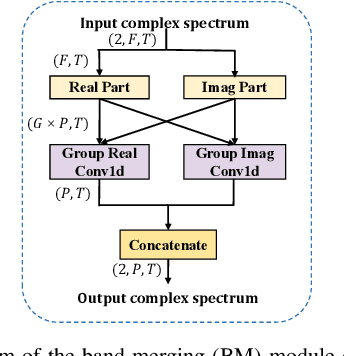
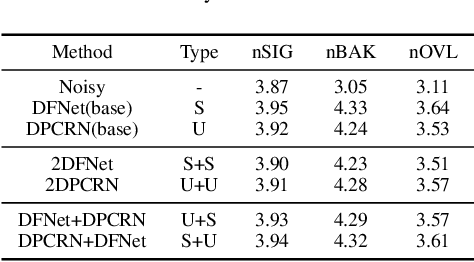
In this paper, we propose a two-stage heterogeneous lightweight network for monaural speech enhancement. Specifically, we design a novel two-stage framework consisting of a coarse-grained full-band mask estimation stage and a fine-grained low-frequency refinement stage. Instead of using a hand-designed real-valued filter, we use a novel learnable complex-valued rectangular bandwidth (LCRB) filter bank as an extractor of compact features. Furthermore, considering the respective characteristics of the proposed two-stage task, we used a heterogeneous structure, i.e., a U-shaped subnetwork as the backbone of CoarseNet and a single-scale subnetwork as the backbone of FineNet. We conducted experiments on the VoiceBank + DEMAND and DNS datasets to evaluate the proposed approach. The experimental results show that the proposed method outperforms the current state-of-the-art methods, while maintaining relatively small model size and low computational complexity.
Automatic Tuning of Loss Trade-offs without Hyper-parameter Search in End-to-End Zero-Shot Speech Synthesis
May 26, 2023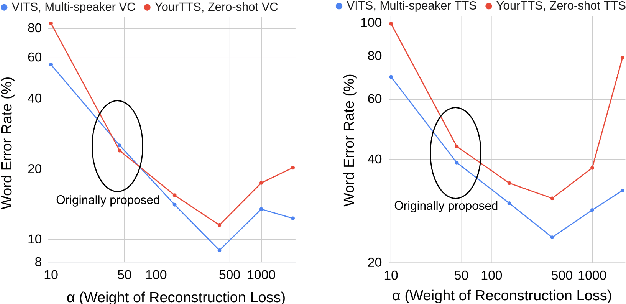


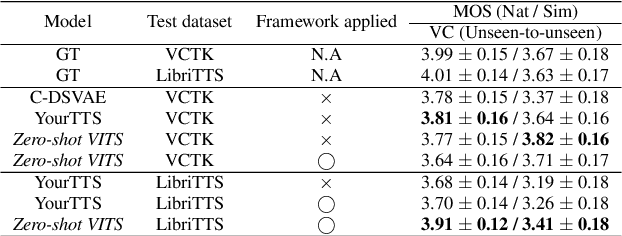
Recently, zero-shot TTS and VC methods have gained attention due to their practicality of being able to generate voices even unseen during training. Among these methods, zero-shot modifications of the VITS model have shown superior performance, while having useful properties inherited from VITS. However, the performance of VITS and VITS-based zero-shot models vary dramatically depending on how the losses are balanced. This can be problematic, as it requires a burdensome procedure of tuning loss balance hyper-parameters to find the optimal balance. In this work, we propose a novel framework that finds this optimum without search, by inducing the decoder of VITS-based models to its full reconstruction ability. With our framework, we show superior performance compared to baselines in zero-shot TTS and VC, achieving state-of-the-art performance. Furthermore, we show the robustness of our framework in various settings. We provide an explanation for the results in the discussion.
SPACEx: Speech-driven Portrait Animation with Controllable Expression
Nov 17, 2022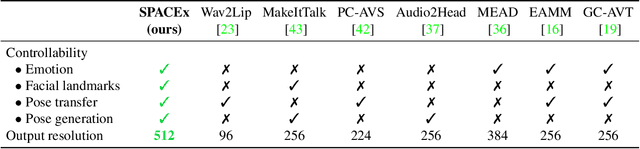
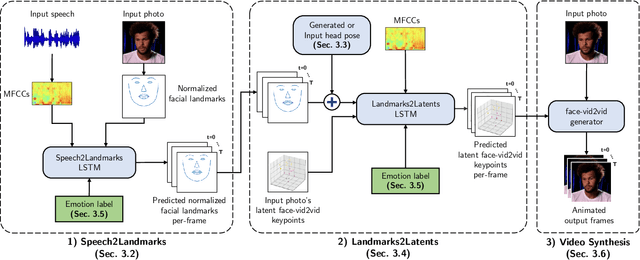
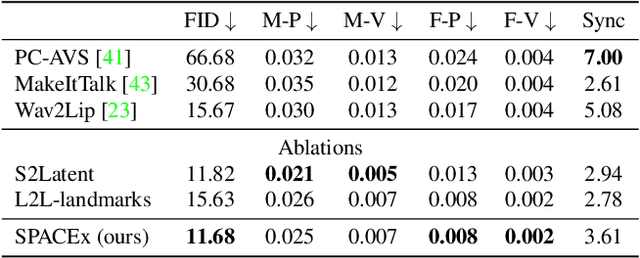
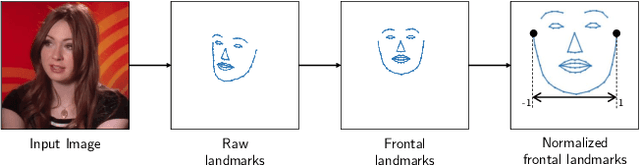
Animating portraits using speech has received growing attention in recent years, with various creative and practical use cases. An ideal generated video should have good lip sync with the audio, natural facial expressions and head motions, and high frame quality. In this work, we present SPACEx, which uses speech and a single image to generate high-resolution, and expressive videos with realistic head pose, without requiring a driving video. It uses a multi-stage approach, combining the controllability of facial landmarks with the high-quality synthesis power of a pretrained face generator. SPACEx also allows for the control of emotions and their intensities. Our method outperforms prior methods in objective metrics for image quality and facial motions and is strongly preferred by users in pair-wise comparisons. The project website is available at https://deepimagination.cc/SPACEx/
A Virtual Simulation-Pilot Agent for Training of Air Traffic Controllers
Apr 16, 2023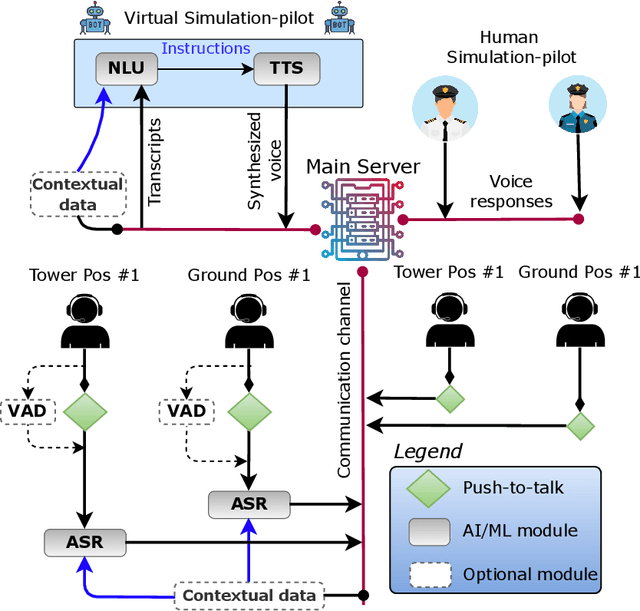
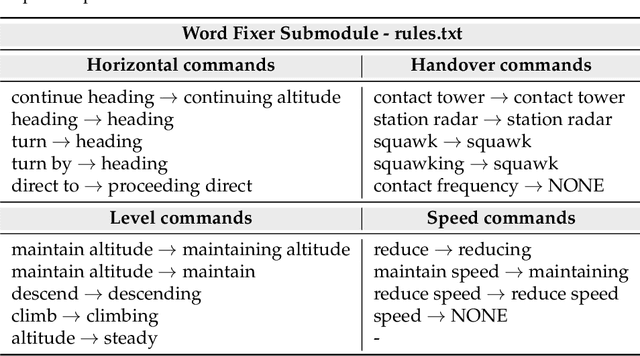
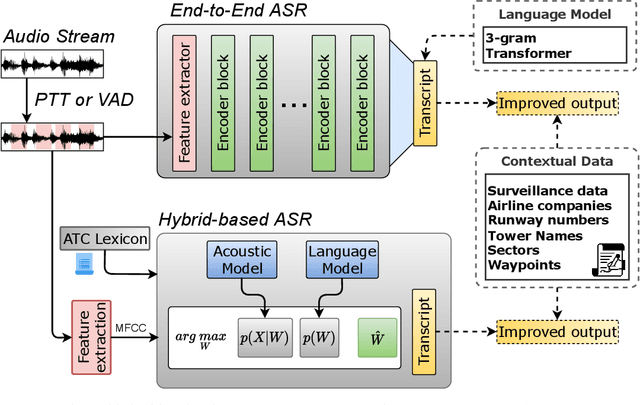
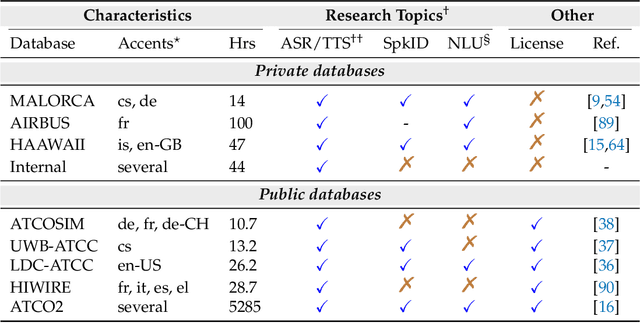
In this paper we propose a novel virtual simulation-pilot engine for speeding up air traffic controller (ATCo) training by integrating different state-of-the-art artificial intelligence (AI) based tools. The virtual simulation-pilot engine receives spoken communications from ATCo trainees, and it performs automatic speech recognition and understanding. Thus, it goes beyond only transcribing the communication and can also understand its meaning. The output is subsequently sent to a response generator system, which resembles the spoken read back that pilots give to the ATCo trainees. The overall pipeline is composed of the following submodules: (i) automatic speech recognition (ASR) system that transforms audio into a sequence of words; (ii) high-level air traffic control (ATC) related entity parser that understands the transcribed voice communication; and (iii) a text-to-speech submodule that generates a spoken utterance that resembles a pilot based on the situation of the dialogue. Our system employs state-of-the-art AI-based tools such as Wav2Vec 2.0, Conformer, BERT and Tacotron models. To the best of our knowledge, this is the first work fully based on open-source ATC resources and AI tools. In addition, we have developed a robust and modular system with optional submodules that can enhance the system's performance by incorporating real-time surveillance data, metadata related to exercises (such as sectors or runways), or even introducing a deliberate read-back error to train ATCo trainees to identify them. Our ASR system can reach as low as 5.5% and 15.9% word error rates (WER) on high and low-quality ATC audio. We also demonstrate that adding surveillance data into the ASR can yield callsign detection accuracy of more than 96%.
How "open" are the conversations with open-domain chatbots? A proposal for Speech Event based evaluation
Nov 24, 2022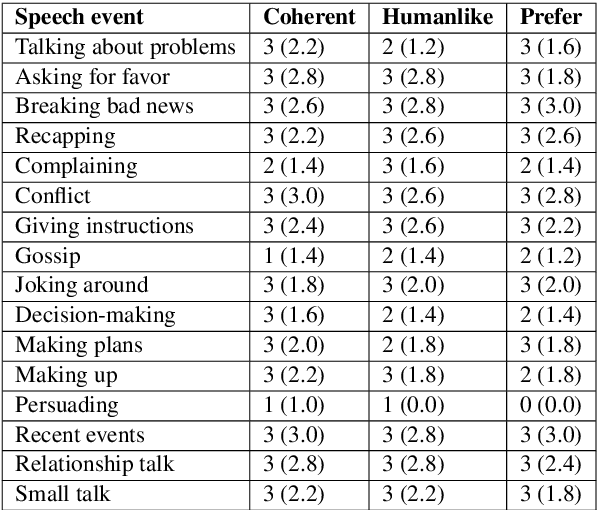
Open-domain chatbots are supposed to converse freely with humans without being restricted to a topic, task or domain. However, the boundaries and/or contents of open-domain conversations are not clear. To clarify the boundaries of "openness", we conduct two studies: First, we classify the types of "speech events" encountered in a chatbot evaluation data set (i.e., Meena by Google) and find that these conversations mainly cover the "small talk" category and exclude the other speech event categories encountered in real life human-human communication. Second, we conduct a small-scale pilot study to generate online conversations covering a wider range of speech event categories between two humans vs. a human and a state-of-the-art chatbot (i.e., Blender by Facebook). A human evaluation of these generated conversations indicates a preference for human-human conversations, since the human-chatbot conversations lack coherence in most speech event categories. Based on these results, we suggest (a) using the term "small talk" instead of "open-domain" for the current chatbots which are not that "open" in terms of conversational abilities yet, and (b) revising the evaluation methods to test the chatbot conversations against other speech events.
Cross-Modal Mutual Learning for Cued Speech Recognition
Dec 02, 2022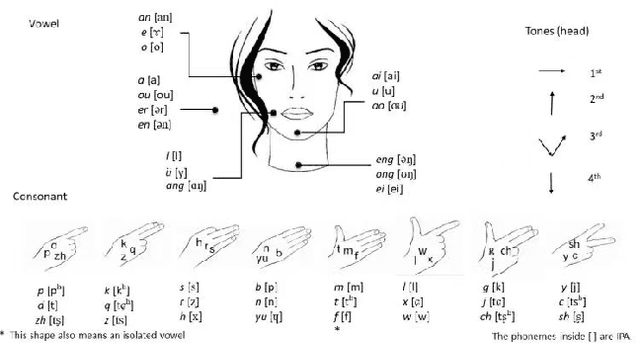
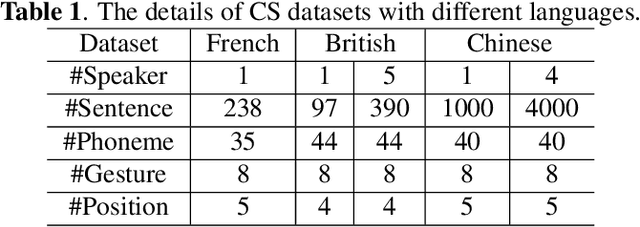
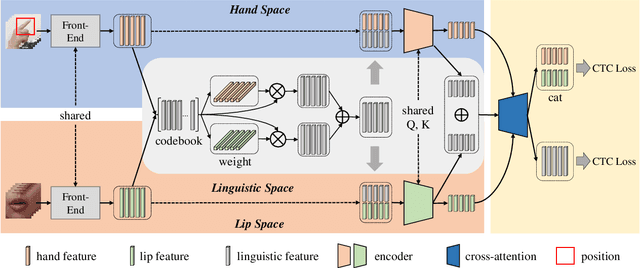
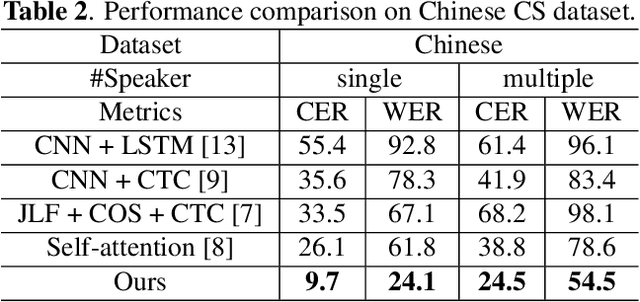
Automatic Cued Speech Recognition (ACSR) provides an intelligent human-machine interface for visual communications, where the Cued Speech (CS) system utilizes lip movements and hand gestures to code spoken language for hearing-impaired people. Previous ACSR approaches often utilize direct feature concatenation as the main fusion paradigm. However, the asynchronous modalities (\textit{i.e.}, lip, hand shape and hand position) in CS may cause interference for feature concatenation. To address this challenge, we propose a transformer based cross-modal mutual learning framework to prompt multi-modal interaction. Compared with the vanilla self-attention, our model forces modality-specific information of different modalities to pass through a modality-invariant codebook, collating linguistic representations for tokens of each modality. Then the shared linguistic knowledge is used to re-synchronize multi-modal sequences. Moreover, we establish a novel large-scale multi-speaker CS dataset for Mandarin Chinese. To our knowledge, this is the first work on ACSR for Mandarin Chinese. Extensive experiments are conducted for different languages (\textit{i.e.}, Chinese, French, and British English). Results demonstrate that our model exhibits superior recognition performance to the state-of-the-art by a large margin.
Neural Speech Phase Prediction based on Parallel Estimation Architecture and Anti-Wrapping Losses
Nov 29, 2022

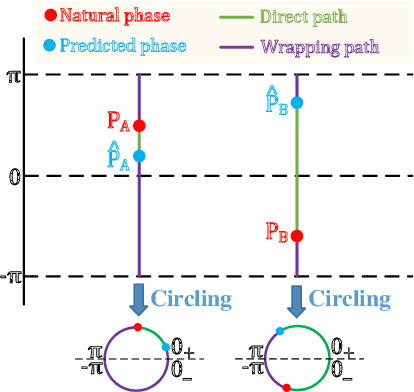
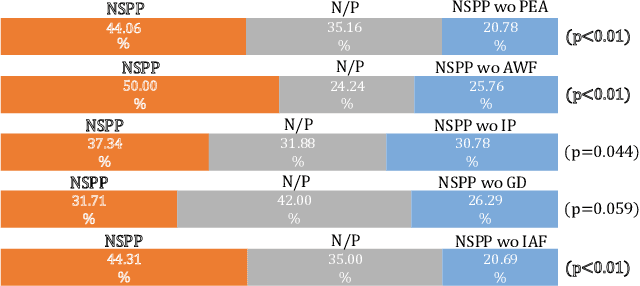
This paper presents a novel speech phase prediction model which predicts wrapped phase spectra directly from amplitude spectra by neural networks. The proposed model is a cascade of a residual convolutional network and a parallel estimation architecture. The parallel estimation architecture is composed of two parallel linear convolutional layers and a phase calculation formula, imitating the process of calculating the phase spectra from the real and imaginary parts of complex spectra and strictly restricting the predicted phase values to the principal value interval. To avoid the error expansion issue caused by phase wrapping, we design anti-wrapping training losses defined between the predicted wrapped phase spectra and natural ones by activating the instantaneous phase error, group delay error and instantaneous angular frequency error using an anti-wrapping function. Experimental results show that our proposed neural speech phase prediction model outperforms the iterative Griffin-Lim algorithm and other neural network-based method, in terms of both reconstructed speech quality and generation speed.
A Study on the Integration of Pipeline and E2E SLU systems for Spoken Semantic Parsing toward STOP Quality Challenge
May 06, 2023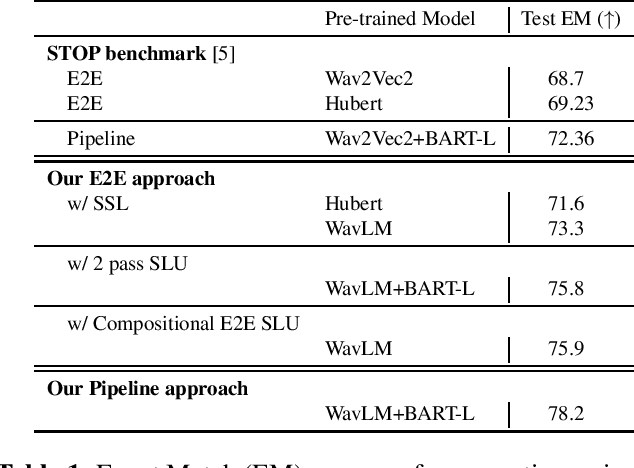

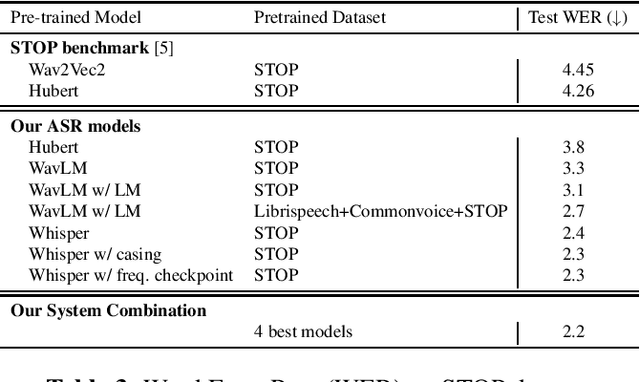
Recently there have been efforts to introduce new benchmark tasks for spoken language understanding (SLU), like semantic parsing. In this paper, we describe our proposed spoken semantic parsing system for the quality track (Track 1) in Spoken Language Understanding Grand Challenge which is part of ICASSP Signal Processing Grand Challenge 2023. We experiment with both end-to-end and pipeline systems for this task. Strong automatic speech recognition (ASR) models like Whisper and pretrained Language models (LM) like BART are utilized inside our SLU framework to boost performance. We also investigate the output level combination of various models to get an exact match accuracy of 80.8, which won the 1st place at the challenge.
SHINE: Syntax-augmented Hierarchical Interactive Encoder for Zero-shot Cross-lingual Information Extraction
May 21, 2023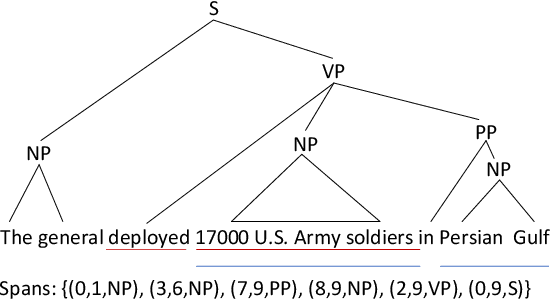
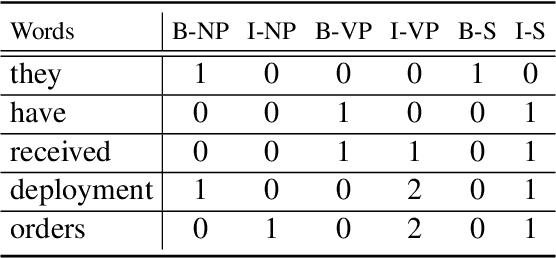
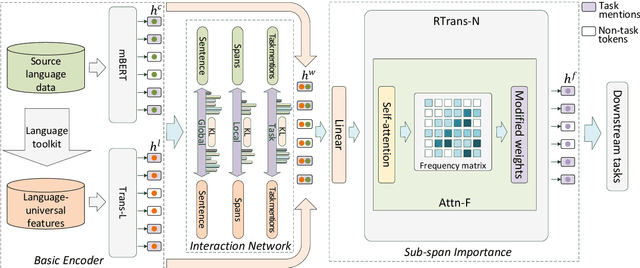
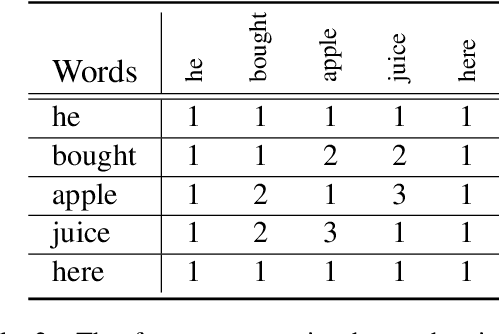
Zero-shot cross-lingual information extraction(IE) aims at constructing an IE model for some low-resource target languages, given annotations exclusively in some rich-resource languages. Recent studies based on language-universal features have shown their effectiveness and are attracting increasing attention. However, prior work has neither explored the potential of establishing interactions between language-universal features and contextual representations nor incorporated features that can effectively model constituent span attributes and relationships between multiple spans. In this study, a syntax-augmented hierarchical interactive encoder (SHINE) is proposed to transfer cross-lingual IE knowledge. The proposed encoder is capable of interactively capturing complementary information between features and contextual information, to derive language-agnostic representations for various IE tasks. Concretely, a multi-level interaction network is designed to hierarchically interact the complementary information to strengthen domain adaptability. Besides, in addition to the well-studied syntax features of part-of-speech and dependency relation, a new syntax feature of constituency structure is introduced to model the constituent span information which is crucial for IE. Experiments across seven languages on three IE tasks and four benchmarks verify the effectiveness and generalization ability of the proposed method.