 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
How "open" are the conversations with open-domain chatbots? A proposal for Speech Event based evaluation
Nov 24, 2022
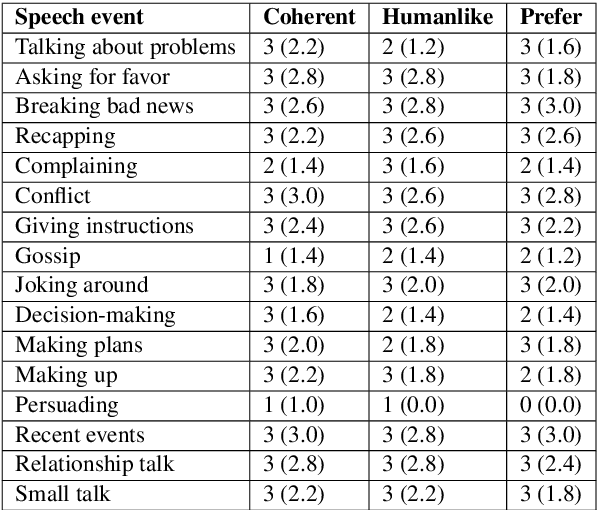
Open-domain chatbots are supposed to converse freely with humans without being restricted to a topic, task or domain. However, the boundaries and/or contents of open-domain conversations are not clear. To clarify the boundaries of "openness", we conduct two studies: First, we classify the types of "speech events" encountered in a chatbot evaluation data set (i.e., Meena by Google) and find that these conversations mainly cover the "small talk" category and exclude the other speech event categories encountered in real life human-human communication. Second, we conduct a small-scale pilot study to generate online conversations covering a wider range of speech event categories between two humans vs. a human and a state-of-the-art chatbot (i.e., Blender by Facebook). A human evaluation of these generated conversations indicates a preference for human-human conversations, since the human-chatbot conversations lack coherence in most speech event categories. Based on these results, we suggest (a) using the term "small talk" instead of "open-domain" for the current chatbots which are not that "open" in terms of conversational abilities yet, and (b) revising the evaluation methods to test the chatbot conversations against other speech events.
Cross-Modal Mutual Learning for Cued Speech Recognition
Dec 02, 2022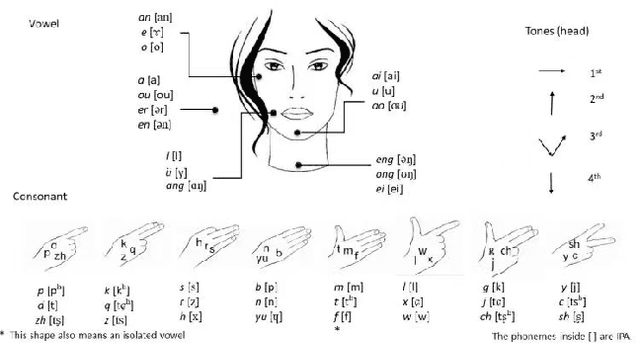
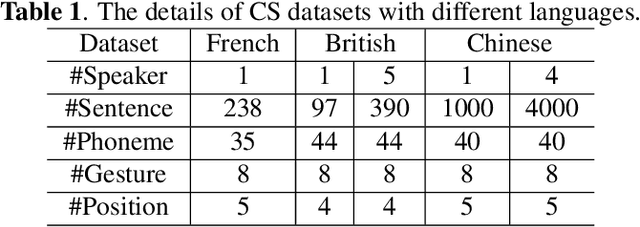
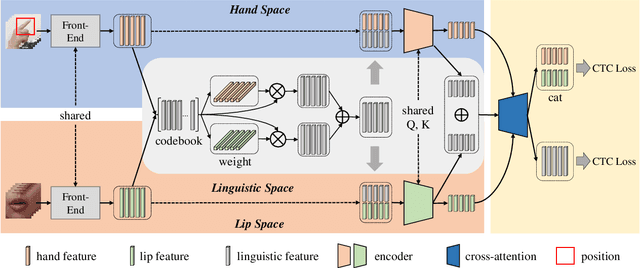
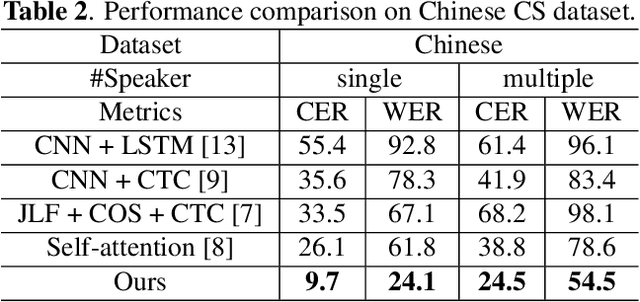
Automatic Cued Speech Recognition (ACSR) provides an intelligent human-machine interface for visual communications, where the Cued Speech (CS) system utilizes lip movements and hand gestures to code spoken language for hearing-impaired people. Previous ACSR approaches often utilize direct feature concatenation as the main fusion paradigm. However, the asynchronous modalities (\textit{i.e.}, lip, hand shape and hand position) in CS may cause interference for feature concatenation. To address this challenge, we propose a transformer based cross-modal mutual learning framework to prompt multi-modal interaction. Compared with the vanilla self-attention, our model forces modality-specific information of different modalities to pass through a modality-invariant codebook, collating linguistic representations for tokens of each modality. Then the shared linguistic knowledge is used to re-synchronize multi-modal sequences. Moreover, we establish a novel large-scale multi-speaker CS dataset for Mandarin Chinese. To our knowledge, this is the first work on ACSR for Mandarin Chinese. Extensive experiments are conducted for different languages (\textit{i.e.}, Chinese, French, and British English). Results demonstrate that our model exhibits superior recognition performance to the state-of-the-art by a large margin.
Neural Speech Phase Prediction based on Parallel Estimation Architecture and Anti-Wrapping Losses
Nov 29, 2022

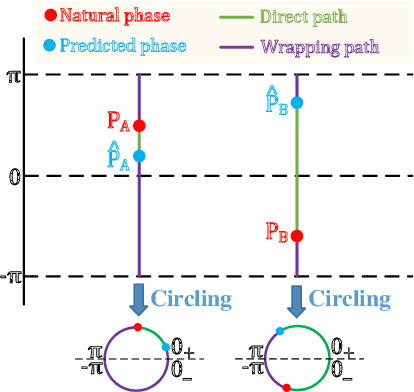
This paper presents a novel speech phase prediction model which predicts wrapped phase spectra directly from amplitude spectra by neural networks. The proposed model is a cascade of a residual convolutional network and a parallel estimation architecture. The parallel estimation architecture is composed of two parallel linear convolutional layers and a phase calculation formula, imitating the process of calculating the phase spectra from the real and imaginary parts of complex spectra and strictly restricting the predicted phase values to the principal value interval. To avoid the error expansion issue caused by phase wrapping, we design anti-wrapping training losses defined between the predicted wrapped phase spectra and natural ones by activating the instantaneous phase error, group delay error and instantaneous angular frequency error using an anti-wrapping function. Experimental results show that our proposed neural speech phase prediction model outperforms the iterative Griffin-Lim algorithm and other neural network-based method, in terms of both reconstructed speech quality and generation speed.
Toxic comments reduce the activity of volunteer editors on Wikipedia
Apr 26, 2023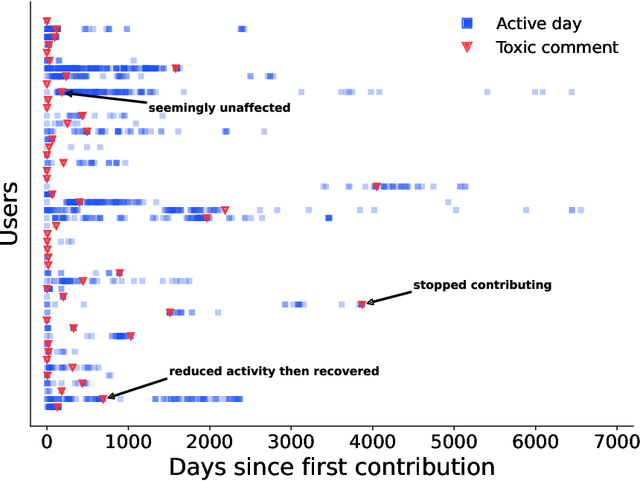
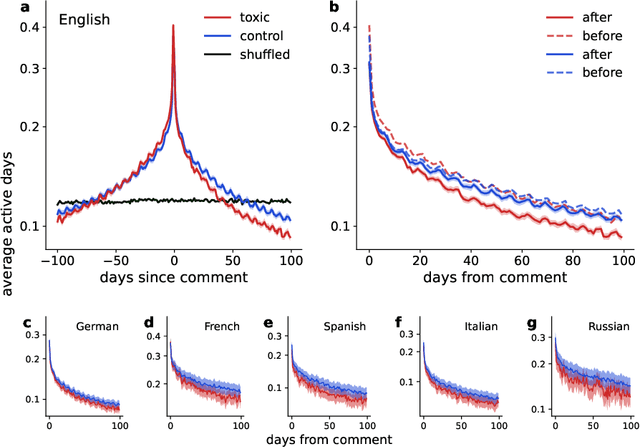
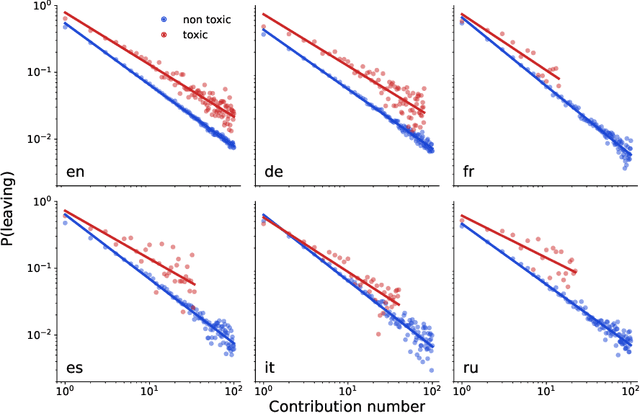
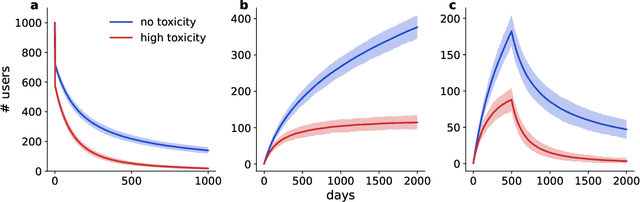
Wikipedia is one of the most successful collaborative projects in history. It is the largest encyclopedia ever created, with millions of users worldwide relying on it as the first source of information as well as for fact-checking and in-depth research. As Wikipedia relies solely on the efforts of its volunteer-editors, its success might be particularly affected by toxic speech. In this paper, we analyze all 57 million comments made on user talk pages of 8.5 million editors across the six most active language editions of Wikipedia to study the potential impact of toxicity on editors' behaviour. We find that toxic comments consistently reduce the activity of editors, leading to an estimated loss of 0.5-2 active days per user in the short term. This amounts to multiple human-years of lost productivity when considering the number of active contributors to Wikipedia. The effects of toxic comments are even greater in the long term, as they significantly increase the risk of editors leaving the project altogether. Using an agent-based model, we demonstrate that toxicity attacks on Wikipedia have the potential to impede the progress of the entire project. Our results underscore the importance of mitigating toxic speech on collaborative platforms such as Wikipedia to ensure their continued success.
An Adapter based Multi-label Pre-training for Speech Separation and Enhancement
Nov 11, 2022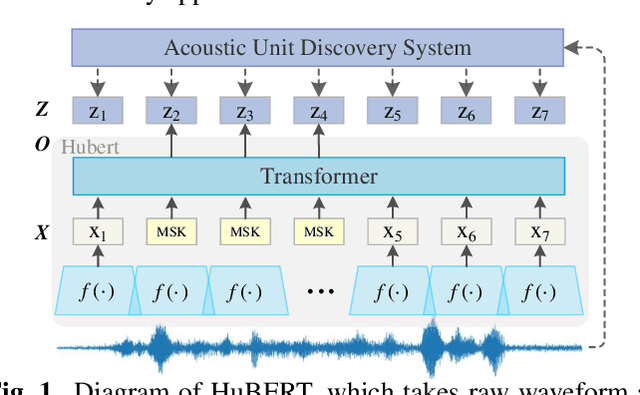
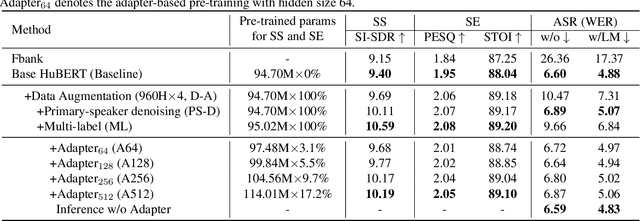
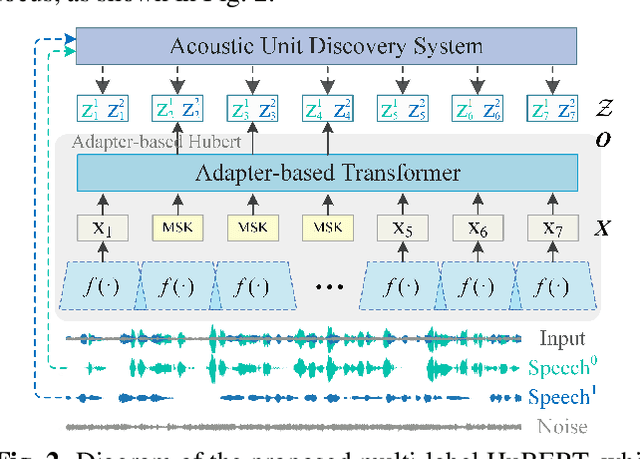
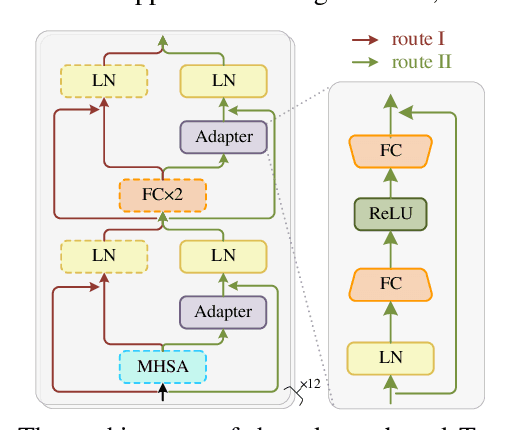
In recent years, self-supervised learning (SSL) has achieved tremendous success in various speech tasks due to its power to extract representations from massive unlabeled data. However, compared with tasks such as speech recognition (ASR), the improvements from SSL representation in speech separation (SS) and enhancement (SE) are considerably smaller. Based on HuBERT, this work investigates improving the SSL model for SS and SE. We first update HuBERT's masked speech prediction (MSP) objective by integrating the separation and denoising terms, resulting in a multiple pseudo label pre-training scheme, which significantly improves HuBERT's performance on SS and SE but degrades the performance on ASR. To maintain its performance gain on ASR, we further propose an adapter-based architecture for HuBERT's Transformer encoder, where only a few parameters of each layer are adjusted to the multiple pseudo label MSP while other parameters remain frozen as default HuBERT. Experimental results show that our proposed adapter-based multiple pseudo label HuBERT yield consistent and significant performance improvements on SE, SS, and ASR tasks, with a faster pre-training speed, at only marginal parameters increase.
Anonymizing Speech with Generative Adversarial Networks to Preserve Speaker Privacy
Oct 20, 2022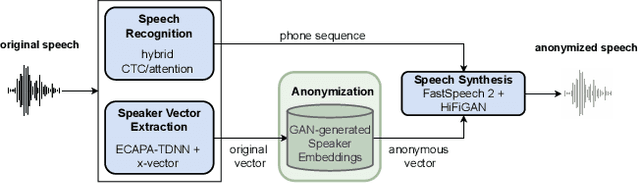
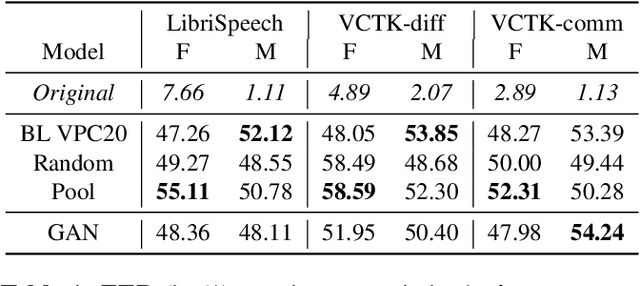
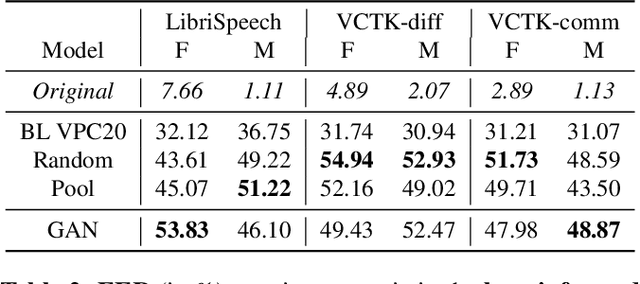
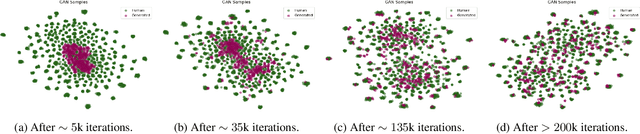
In order to protect the privacy of speech data, speaker anonymization aims for hiding the identity of a speaker by changing the voice in speech recordings. This typically comes with a privacy-utility trade-off between protection of individuals and usability of the data for downstream applications. One of the challenges in this context is to create non-existent voices that sound as natural as possible. In this work, we propose to tackle this issue by generating speaker embeddings using a generative adversarial network with Wasserstein distance as cost function. By incorporating these artificial embeddings into a speech-to-text-to-speech pipeline, we outperform previous approaches in terms of privacy and utility. According to standard objective metrics and human evaluation, our approach generates intelligible and content-preserving yet privacy-protecting versions of the original recordings.
Improving End-to-End SLU performance with Prosodic Attention and Distillation
May 14, 2023
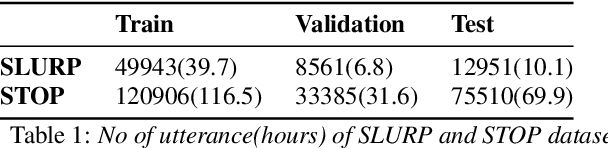
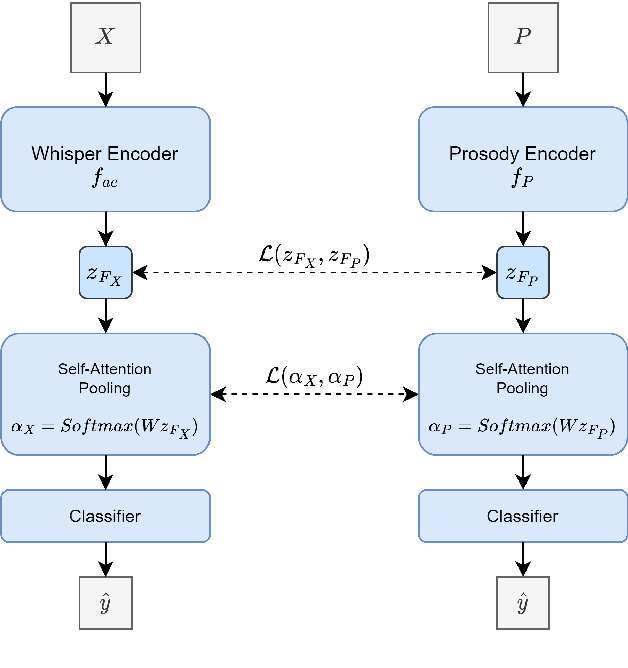
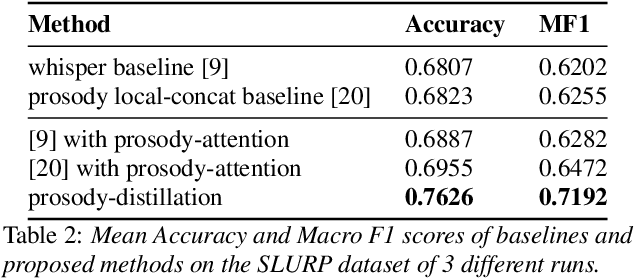
Most End-to-End SLU methods depend on the pretrained ASR or language model features for intent prediction. However, other essential information in speech, such as prosody, is often ignored. Recent research has shown improved results in classifying dialogue acts by incorporating prosodic information. The margins of improvement in these methods are minimal as the neural models ignore prosodic features. In this work, we propose prosody-attention, which uses the prosodic features differently to generate attention maps across time frames of the utterance. Then we propose prosody-distillation to explicitly learn the prosodic information in the acoustic encoder rather than concatenating the implicit prosodic features. Both the proposed methods improve the baseline results, and the prosody-distillation method gives an intent classification accuracy improvement of 8\% and 2\% on SLURP and STOP datasets over the prosody baseline.
Comparative Study of Pre-Trained BERT Models for Code-Mixed Hindi-English Data
May 26, 2023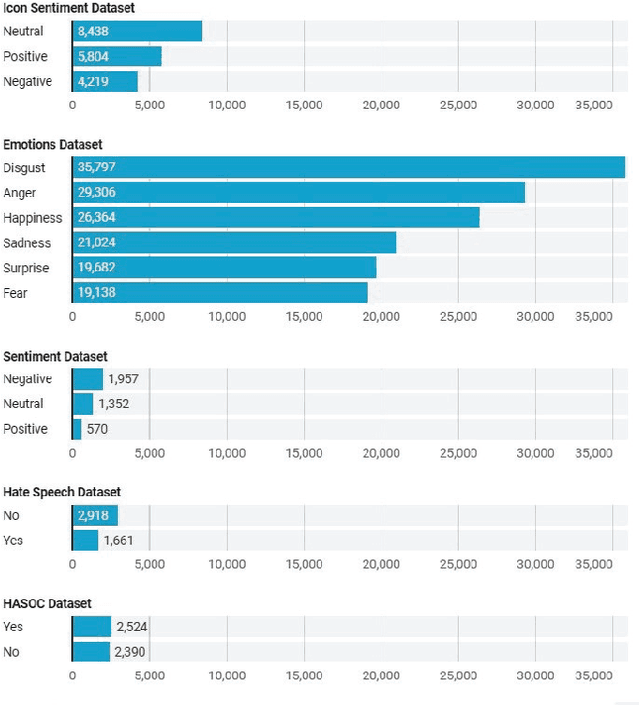
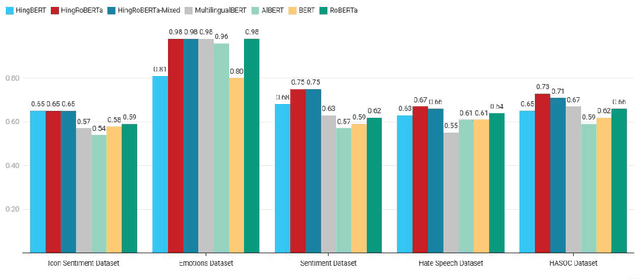
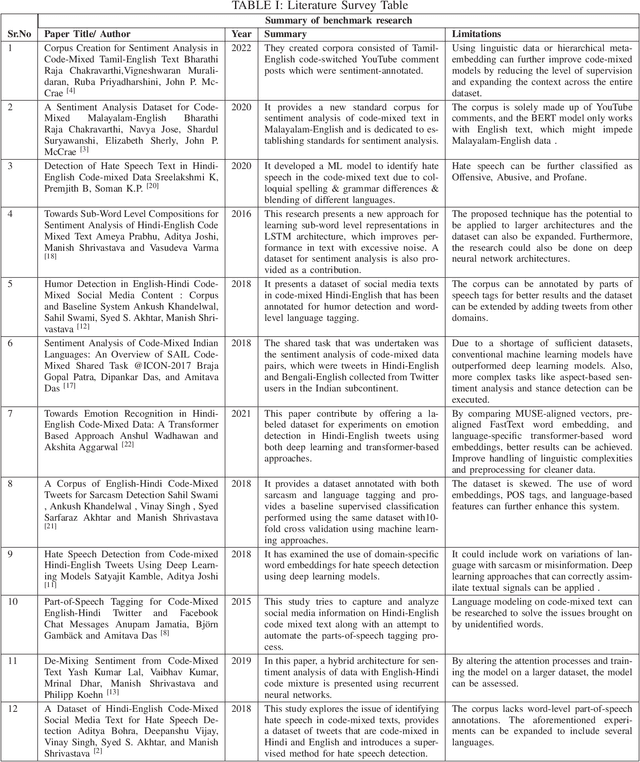
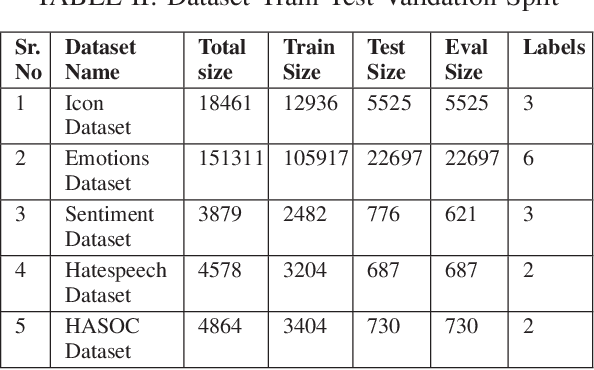
The term "Code Mixed" refers to the use of more than one language in the same text. This phenomenon is predominantly observed on social media platforms, with an increasing amount of adaptation as time goes on. It is critical to detect foreign elements in a language and process them correctly, as a considerable number of individuals are using code-mixed languages that could not be comprehended by understanding one of those languages. In this work, we focus on low-resource Hindi-English code-mixed language and enhancing the performance of different code-mixed natural language processing tasks such as sentiment analysis, emotion recognition, and hate speech identification. We perform a comparative analysis of different Transformer-based language Models pre-trained using unsupervised approaches. We have included the code-mixed models like HingBERT, HingRoBERTa, HingRoBERTa-Mixed, mBERT, and non-code-mixed models like AlBERT, BERT, and RoBERTa for comparative analysis of code-mixed Hindi-English downstream tasks. We report state-of-the-art results on respective datasets using HingBERT-based models which are specifically pre-trained on real code-mixed text. Our HingBERT-based models provide significant improvements thus highlighting the poor performance of vanilla BERT models on code-mixed text.
EmoDiff: Intensity Controllable Emotional Text-to-Speech with Soft-Label Guidance
Nov 17, 2022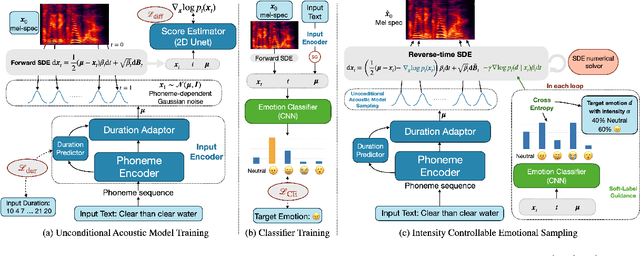
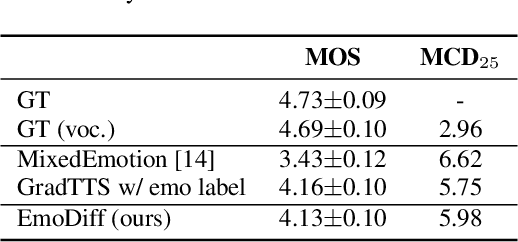

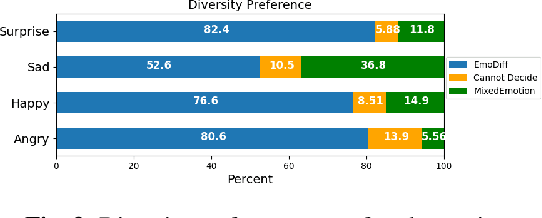
Although current neural text-to-speech (TTS) models are able to generate high-quality speech, intensity controllable emotional TTS is still a challenging task. Most existing methods need external optimizations for intensity calculation, leading to suboptimal results or degraded quality. In this paper, we propose EmoDiff, a diffusion-based TTS model where emotion intensity can be manipulated by a proposed soft-label guidance technique derived from classifier guidance. Specifically, instead of being guided with a one-hot vector for the specified emotion, EmoDiff is guided with a soft label where the value of the specified emotion and \textit{Neutral} is set to $\alpha$ and $1-\alpha$ respectively. The $\alpha$ here represents the emotion intensity and can be chosen from 0 to 1. Our experiments show that EmoDiff can precisely control the emotion intensity while maintaining high voice quality. Moreover, diverse speech with specified emotion intensity can be generated by sampling in the reverse denoising process.
Joint unsupervised and supervised learning for context-aware language identification
Mar 29, 2023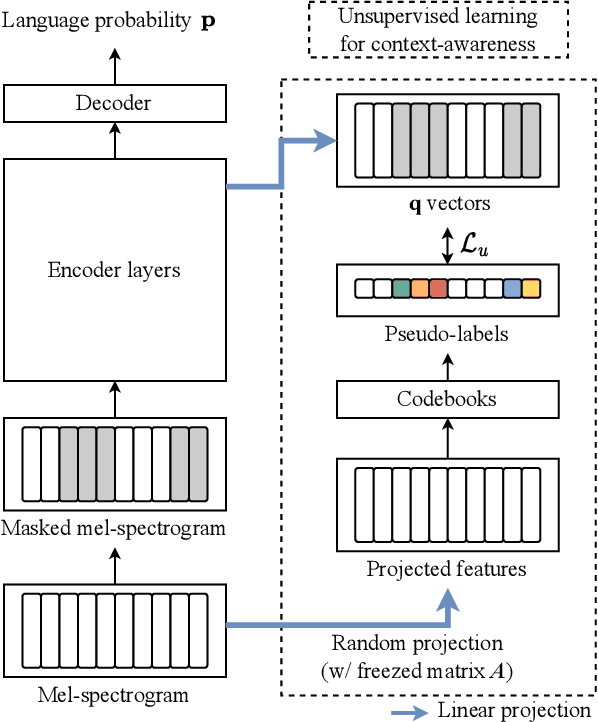
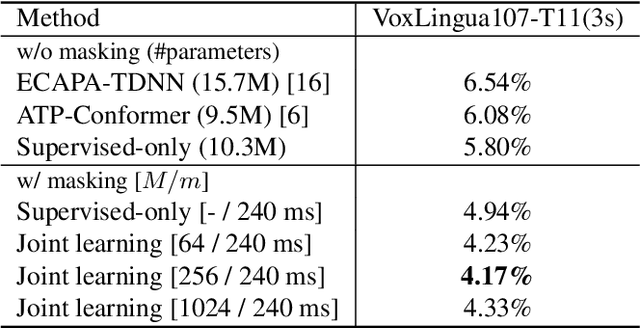
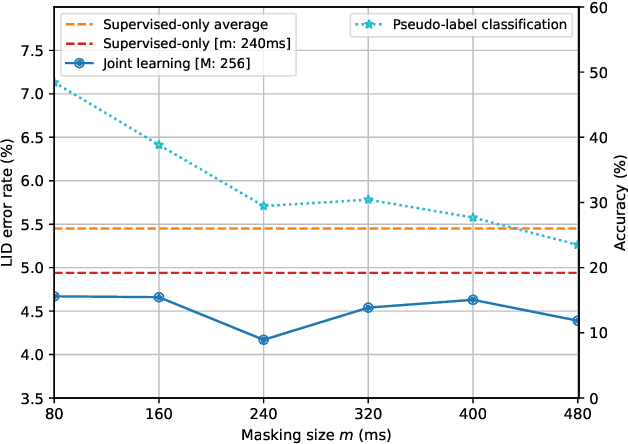
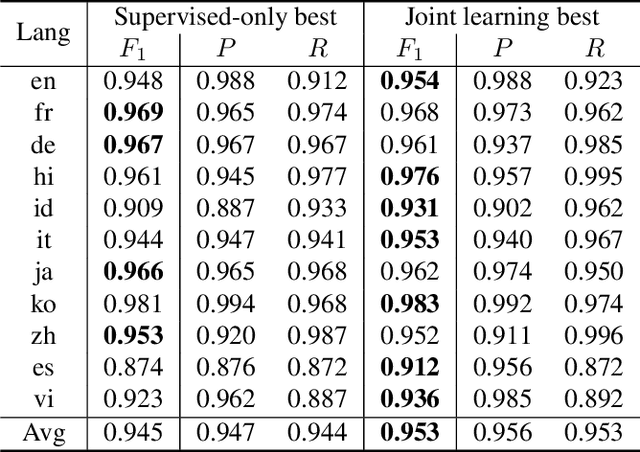
Language identification (LID) recognizes the language of a spoken utterance automatically. According to recent studies, LID models trained with an automatic speech recognition (ASR) task perform better than those trained with a LID task only. However, we need additional text labels to train the model to recognize speech, and acquiring the text labels is a cost high. In order to overcome this problem, we propose context-aware language identification using a combination of unsupervised and supervised learning without any text labels. The proposed method learns the context of speech through masked language modeling (MLM) loss and simultaneously trains to determine the language of the utterance with supervised learning loss. The proposed joint learning was found to reduce the error rate by 15.6% compared to the same structure model trained by supervised-only learning on a subset of the VoxLingua107 dataset consisting of sub-three-second utterances in 11 languages.