 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Source Free Domain Adaptation of a DNN for SSVEP-based Brain-Computer Interfaces
May 27, 2023
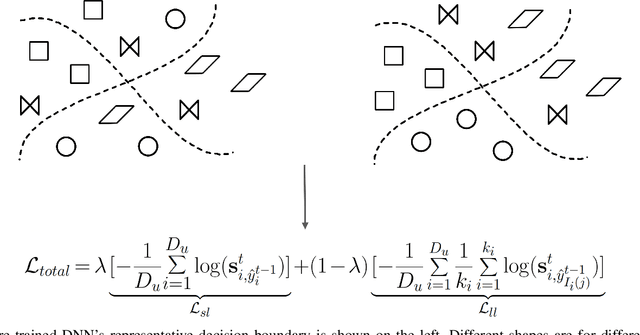
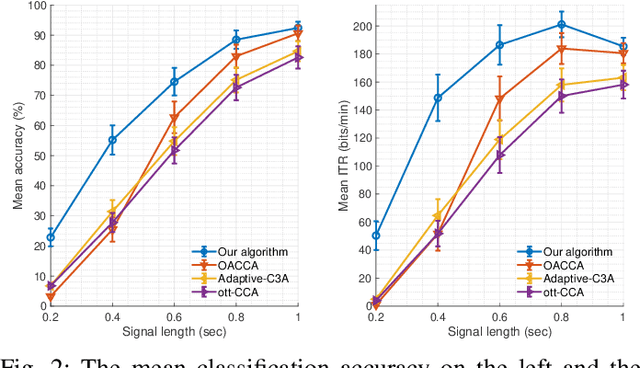
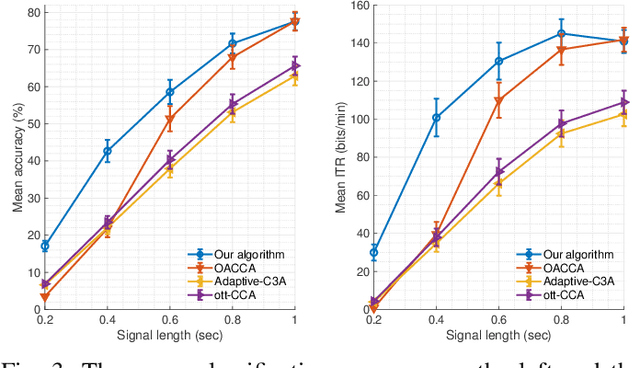
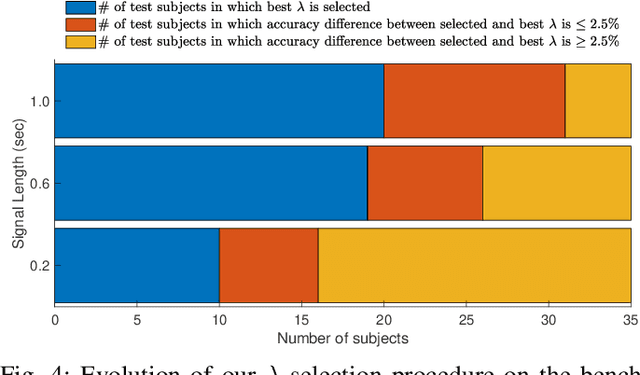
This paper presents a source free domain adaptation method for steady-state visually evoked potential (SSVEP) based brain-computer interface (BCI) spellers. SSVEP-based BCI spellers help individuals experiencing speech difficulties, enabling them to communicate at a fast rate. However, achieving a high information transfer rate (ITR) in the current methods requires an extensive calibration period before using the system, leading to discomfort for new users. We address this issue by proposing a method that adapts the deep neural network (DNN) pre-trained on data from source domains (participants of previous experiments conducted for labeled data collection), using only the unlabeled data of the new user (target domain). This adaptation is achieved by minimizing our proposed custom loss function composed of self-adaptation and local-regularity loss terms. The self-adaptation term uses the pseudo-label strategy, while the novel local-regularity term exploits the data structure and forces the DNN to assign the same labels to adjacent instances. Our method achieves striking 201.15 bits/min and 145.02 bits/min ITRs on the benchmark and BETA datasets, respectively, and outperforms the state-of-the-art alternative techniques. Our approach alleviates user discomfort and shows excellent identification performance, so it would potentially contribute to the broader application of SSVEP-based BCI systems in everyday life.
A new Speech Feature Fusion method with cross gate parallel CNN for Speaker Recognition
Nov 24, 2022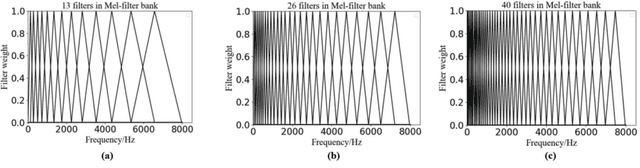
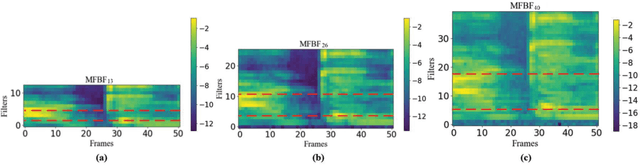
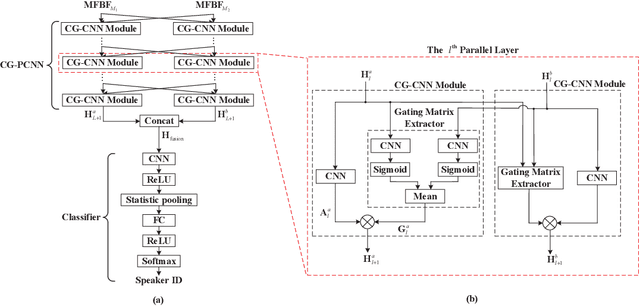
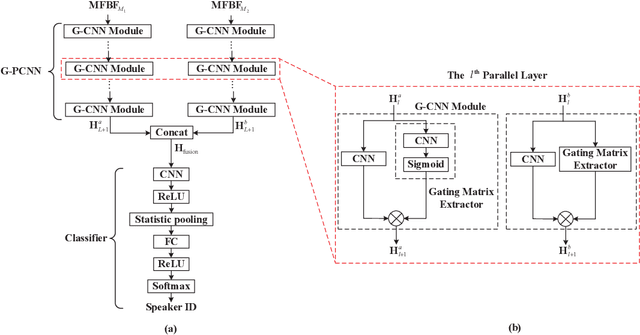
In this paper, a new speech feature fusion method is proposed for speaker recognition on the basis of the cross gate parallel convolutional neural network (CG-PCNN). The Mel filter bank features (MFBFs) of different frequency resolutions can be extracted from each speech frame of a speaker's speech by several Mel filter banks, where the numbers of the triangular filters in the Mel filter banks are different. Due to the frequency resolutions of these MFBFs are different, there are some complementaries for these MFBFs. The CG-PCNN is utilized to extract the deep features from these MFBFs, which applies a cross gate mechanism to capture the complementaries for improving the performance of the speaker recognition system. Then, the fusion feature can be obtained by concatenating these deep features for speaker recognition. The experimental results show that the speaker recognition system with the proposed speech feature fusion method is effective, and marginally outperforms the existing state-of-the-art systems.
Text-to-speech synthesis based on latent variable conversion using diffusion probabilistic model and variational autoencoder
Dec 16, 2022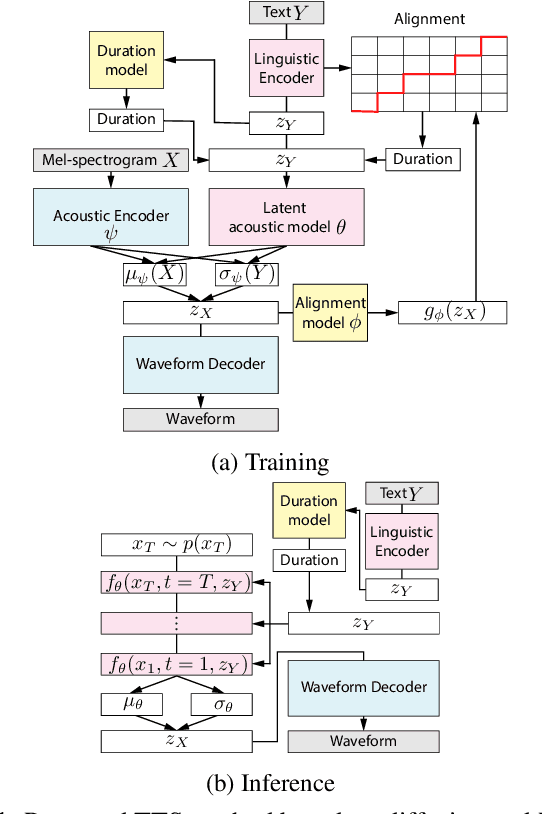
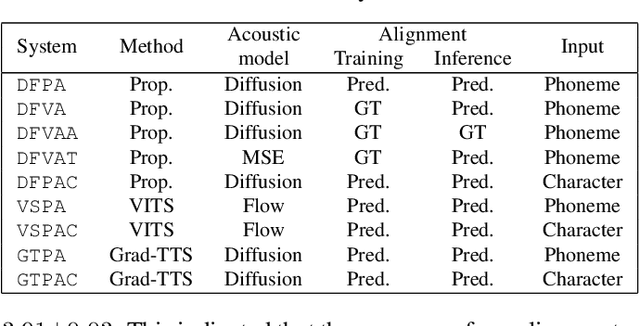
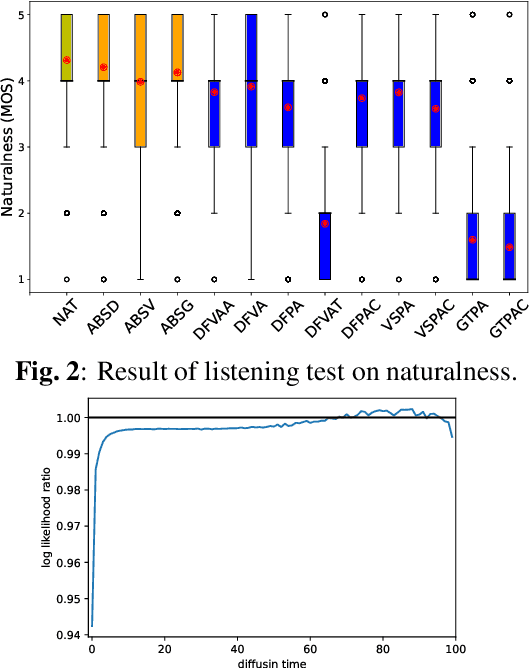
Text-to-speech synthesis (TTS) is a task to convert texts into speech. Two of the factors that have been driving TTS are the advancements of probabilistic models and latent representation learning. We propose a TTS method based on latent variable conversion using a diffusion probabilistic model and the variational autoencoder (VAE). In our TTS method, we use a waveform model based on VAE, a diffusion model that predicts the distribution of latent variables in the waveform model from texts, and an alignment model that learns alignments between the text and speech latent sequences. Our method integrates diffusion with VAE by modeling both mean and variance parameters with diffusion, where the target distribution is determined by approximation from VAE. This latent variable conversion framework potentially enables us to flexibly incorporate various latent feature extractors. Our experiments show that our method is robust to linguistic labels with poor orthography and alignment errors.
Describing emotions with acoustic property prompts for speech emotion recognition
Nov 14, 2022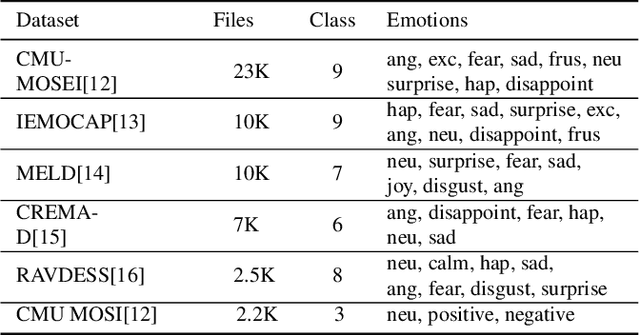
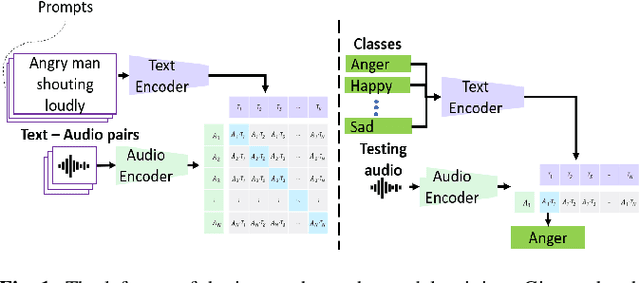
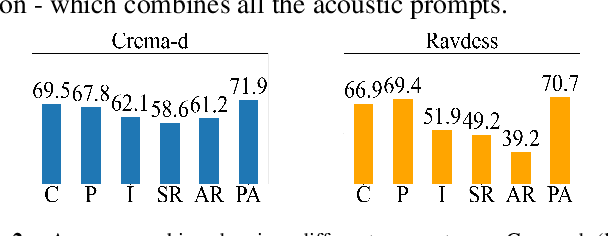
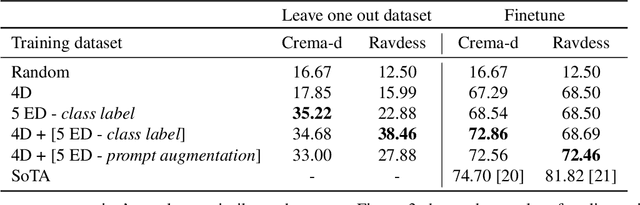
Emotions lie on a broad continuum and treating emotions as a discrete number of classes limits the ability of a model to capture the nuances in the continuum. The challenge is how to describe the nuances of emotions and how to enable a model to learn the descriptions. In this work, we devise a method to automatically create a description (or prompt) for a given audio by computing acoustic properties, such as pitch, loudness, speech rate, and articulation rate. We pair a prompt with its corresponding audio using 5 different emotion datasets. We trained a neural network model using these audio-text pairs. Then, we evaluate the model using one more dataset. We investigate how the model can learn to associate the audio with the descriptions, resulting in performance improvement of Speech Emotion Recognition and Speech Audio Retrieval. We expect our findings to motivate research describing the broad continuum of emotion
LeVoice ASR Systems for the ISCSLP 2022 Intelligent Cockpit Speech Recognition Challenge
Oct 17, 2022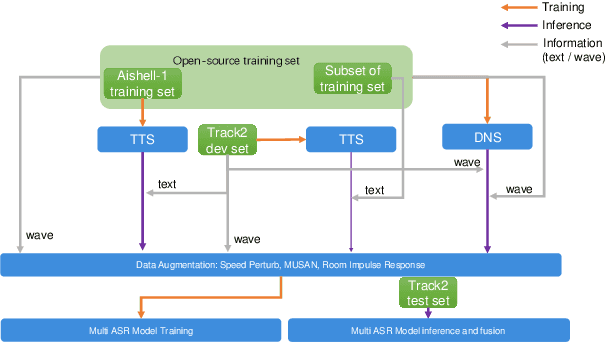
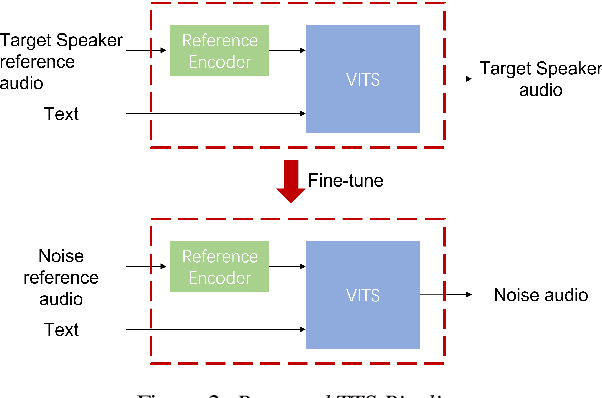
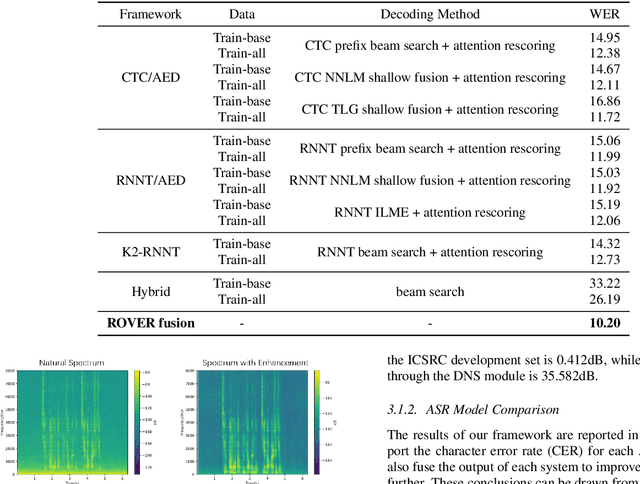
This paper describes LeVoice automatic speech recognition systems to track2 of intelligent cockpit speech recognition challenge 2022. Track2 is a speech recognition task without limits on the scope of model size. Our main points include deep learning based speech enhancement, text-to-speech based speech generation, training data augmentation via various techniques and speech recognition model fusion. We compared and fused the hybrid architecture and two kinds of end-to-end architecture. For end-to-end modeling, we used models based on connectionist temporal classification/attention-based encoder-decoder architecture and recurrent neural network transducer/attention-based encoder-decoder architecture. The performance of these models is evaluated with an additional language model to improve word error rates. As a result, our system achieved 10.2\% character error rate on the challenge test set data and ranked third place among the submitted systems in the challenge.
Parameter-Efficient Fine-Tuning for Medical Image Analysis: The Missed Opportunity
May 24, 2023
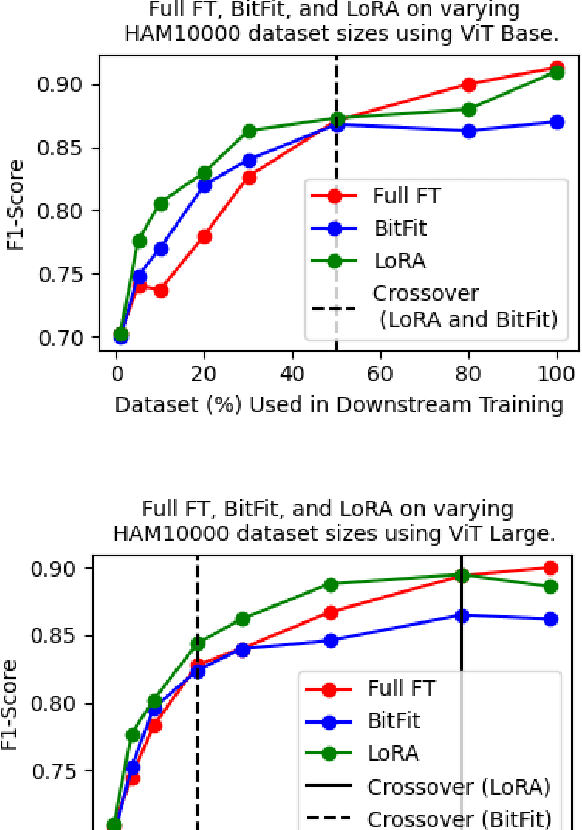
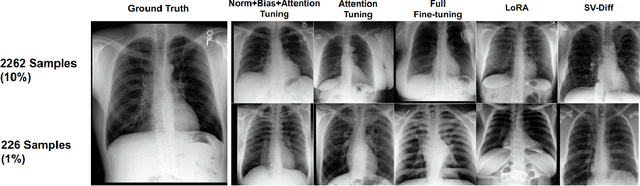
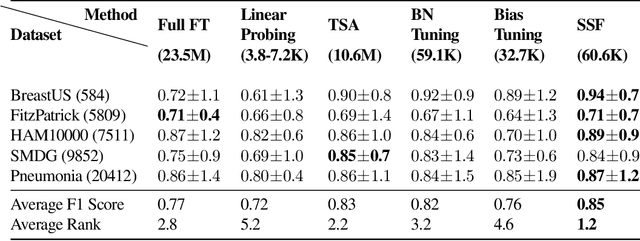
We present a comprehensive evaluation of Parameter-Efficient Fine-Tuning (PEFT) techniques for diverse medical image analysis tasks. PEFT is increasingly exploited as a valuable approach for knowledge transfer from pre-trained models in natural language processing, vision, speech, and cross-modal tasks, such as vision-language and text-to-image generation. However, its application in medical image analysis remains relatively unexplored. As foundation models are increasingly exploited in the medical domain, it is crucial to investigate and comparatively assess various strategies for knowledge transfer that can bolster a range of downstream tasks. Our study, the first of its kind (to the best of our knowledge), evaluates 16 distinct PEFT methodologies proposed for convolutional and transformer-based networks, focusing on image classification and text-to-image generation tasks across six medical datasets ranging in size, modality, and complexity. Through a battery of more than 600 controlled experiments, we demonstrate performance gains of up to 22% under certain scenarios and demonstrate the efficacy of PEFT for medical text-to-image generation. Further, we reveal the instances where PEFT methods particularly dominate over conventional fine-tuning approaches by studying their relationship with downstream data volume.
Vocal Style Factorization for Effective Speaker Recognition in Affective Scenarios
May 13, 2023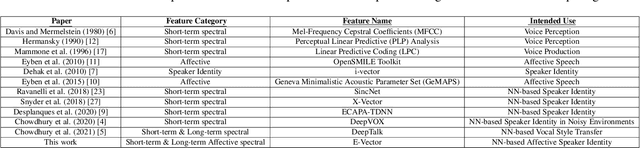
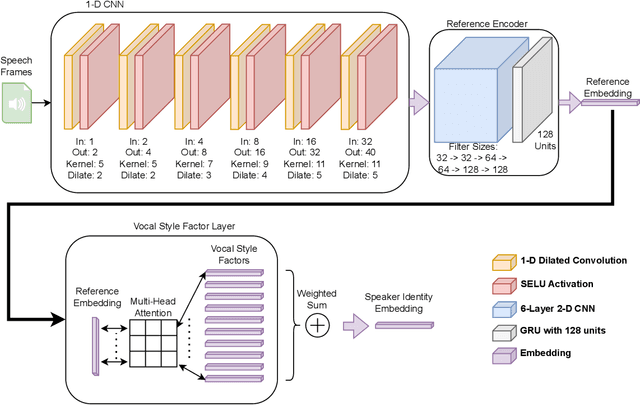
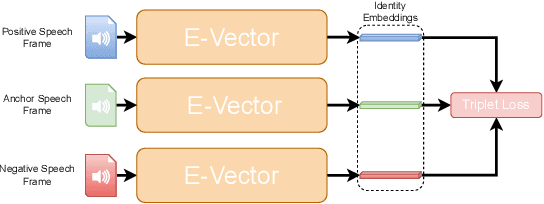
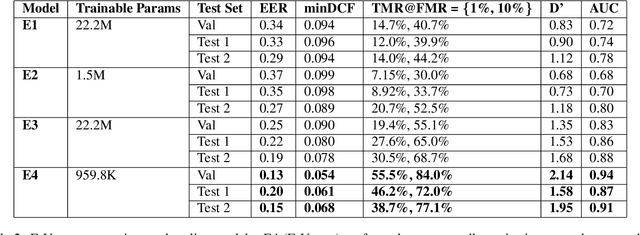
The accuracy of automated speaker recognition is negatively impacted by change in emotions in a person's speech. In this paper, we hypothesize that speaker identity is composed of various vocal style factors that may be learned from unlabeled data and re-combined using a neural network architecture to generate holistic speaker identity representations for affective scenarios. In this regard we propose the E-Vector architecture, composed of a 1-D CNN for learning speaker identity features and a vocal style factorization technique for determining vocal styles. Experiments conducted on the MSP-Podcast dataset demonstrate that the proposed architecture improves state-of-the-art speaker recognition accuracy in the affective domain over baseline ECAPA-TDNN speaker recognition models. For instance, the true match rate at a false match rate of 1% improves from 27.6% to 46.2%.
Exploring Effective Distillation of Self-Supervised Speech Models for Automatic Speech Recognition
Oct 27, 2022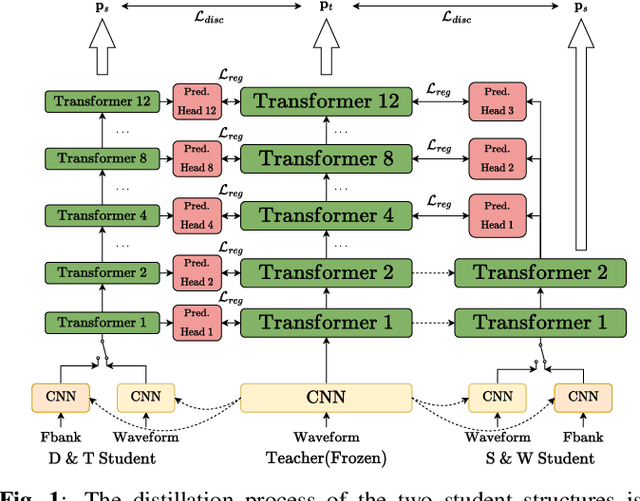
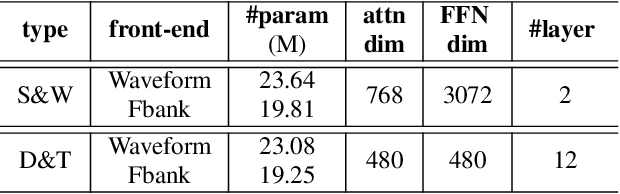
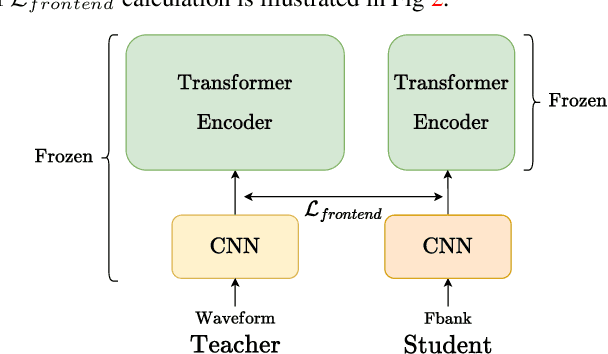
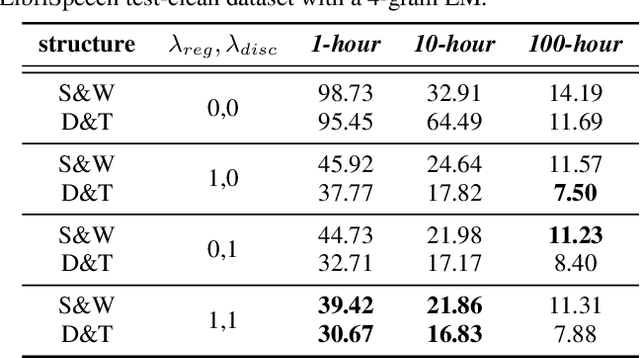
Recent years have witnessed great strides in self-supervised learning (SSL) on the speech processing. The SSL model is normally pre-trained on a great variety of unlabelled data and a large model size is preferred to increase the modeling capacity. However, this might limit its potential applications due to the expensive computation and memory costs introduced by the oversize model. Miniaturization for SSL models has become an important research direction of practical value. To this end, we explore the effective distillation of HuBERT-based SSL models for automatic speech recognition (ASR). First, in order to establish a strong baseline, a comprehensive study on different student model structures is conducted. On top of this, as a supplement to the regression loss widely adopted in previous works, a discriminative loss is introduced for HuBERT to enhance the distillation performance, especially in low-resource scenarios. In addition, we design a simple and effective algorithm to distill the front-end input from waveform to Fbank feature, resulting in 17% parameter reduction and doubling inference speed, at marginal performance degradation.
DeFT-AN: Dense Frequency-Time Attentive Network for Multichannel Speech Enhancement
Dec 15, 2022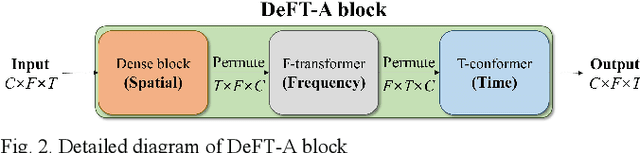
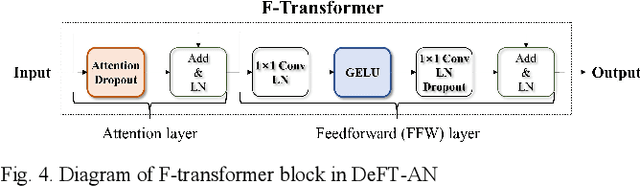
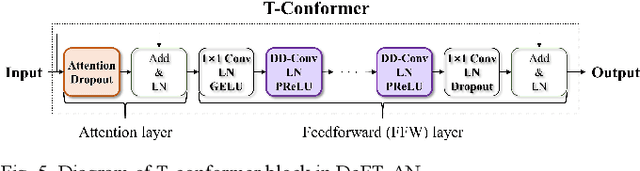
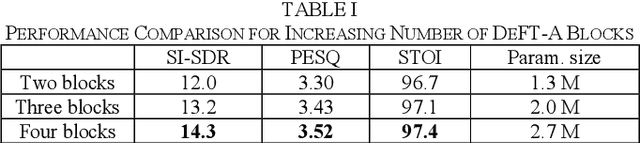
In this study, we propose a dense frequency-time attentive network (DeFT-AN) for multichannel speech enhancement. DeFT-AN is a mask estimation network that predicts a complex spectral masking pattern for suppressing the noise and reverberation embedded in the short-time Fourier transform (STFT) of an input signal. The proposed mask estimation network incorporates three different types of blocks for aggregating information in the spatial, spectral, and temporal dimensions. It utilizes a spectral transformer with a modified feed-forward network and a temporal conformer with sequential dilated convolutions. The use of dense blocks and transformers dedicated to the three different characteristics of audio signals enables more comprehensive denoising and dereverberation. The remarkable performance of DeFT-AN over state-of-the-art multichannel models is demonstrated based on two popular noisy and reverberant datasets in terms of various metrics for speech quality and intelligibility.
Difference of Submodular Minimization via DC Programming
May 18, 2023Minimizing the difference of two submodular (DS) functions is a problem that naturally occurs in various machine learning problems. Although it is well known that a DS problem can be equivalently formulated as the minimization of the difference of two convex (DC) functions, existing algorithms do not fully exploit this connection. A classical algorithm for DC problems is called the DC algorithm (DCA). We introduce variants of DCA and its complete form (CDCA) that we apply to the DC program corresponding to DS minimization. We extend existing convergence properties of DCA, and connect them to convergence properties on the DS problem. Our results on DCA match the theoretical guarantees satisfied by existing DS algorithms, while providing a more complete characterization of convergence properties. In the case of CDCA, we obtain a stronger local minimality guarantee. Our numerical results show that our proposed algorithms outperform existing baselines on two applications: speech corpus selection and feature selection.