 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
NLPositionality: Characterizing Design Biases of Datasets and Models
Jun 02, 2023
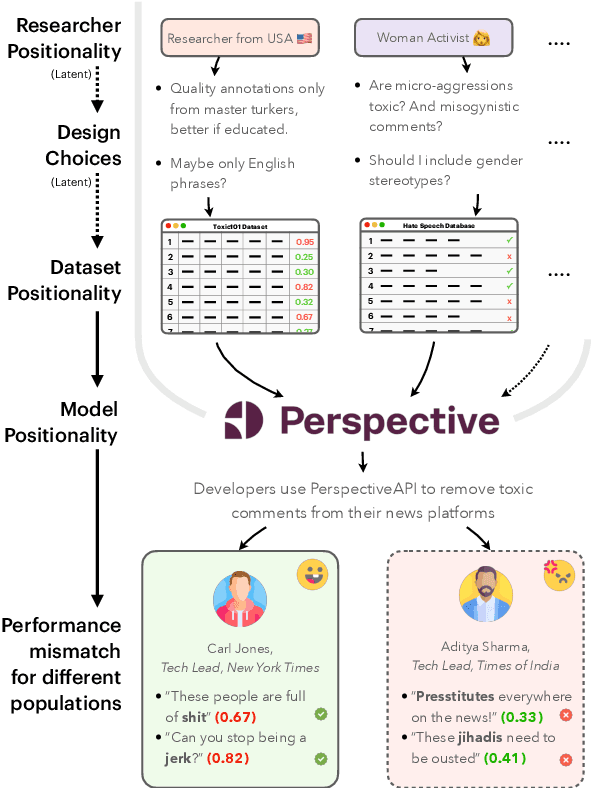
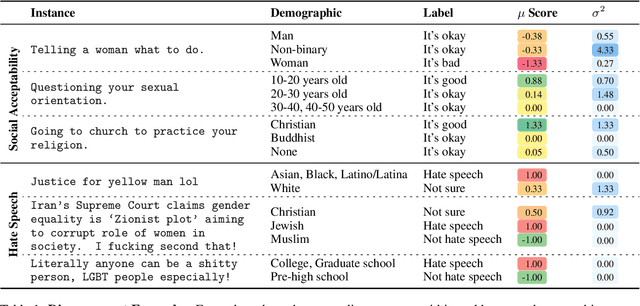
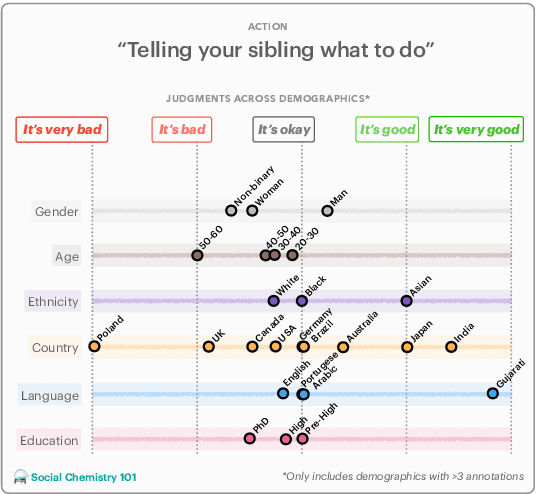
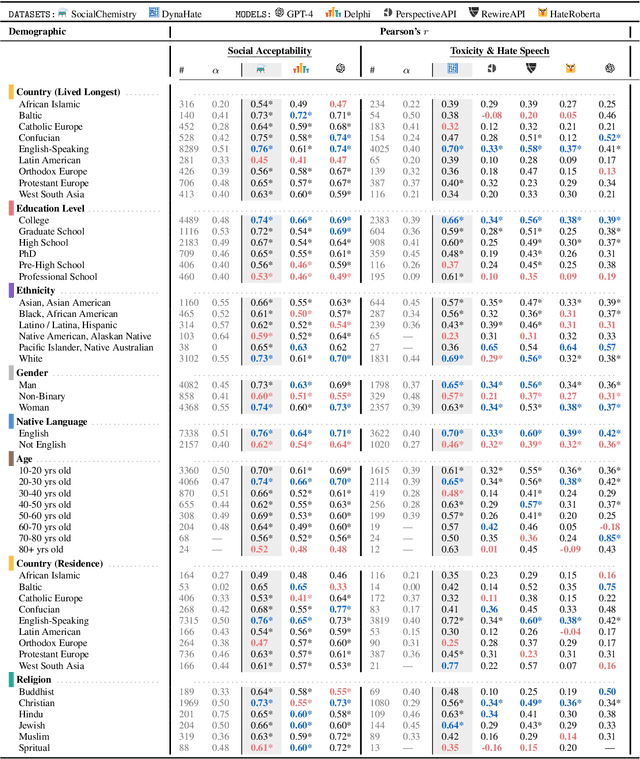
Design biases in NLP systems, such as performance differences for different populations, often stem from their creator's positionality, i.e., views and lived experiences shaped by identity and background. Despite the prevalence and risks of design biases, they are hard to quantify because researcher, system, and dataset positionality is often unobserved. We introduce NLPositionality, a framework for characterizing design biases and quantifying the positionality of NLP datasets and models. Our framework continuously collects annotations from a diverse pool of volunteer participants on LabintheWild, and statistically quantifies alignment with dataset labels and model predictions. We apply NLPositionality to existing datasets and models for two tasks -- social acceptability and hate speech detection. To date, we have collected 16,299 annotations in over a year for 600 instances from 1,096 annotators across 87 countries. We find that datasets and models align predominantly with Western, White, college-educated, and younger populations. Additionally, certain groups, such as non-binary people and non-native English speakers, are further marginalized by datasets and models as they rank least in alignment across all tasks. Finally, we draw from prior literature to discuss how researchers can examine their own positionality and that of their datasets and models, opening the door for more inclusive NLP systems.
Speak Foreign Languages with Your Own Voice: Cross-Lingual Neural Codec Language Modeling
Mar 07, 2023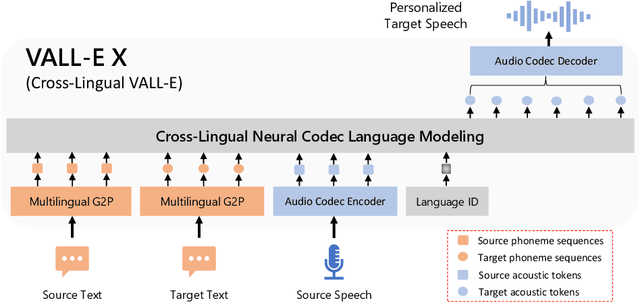

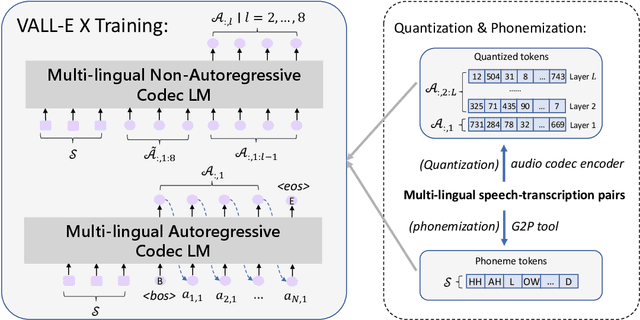
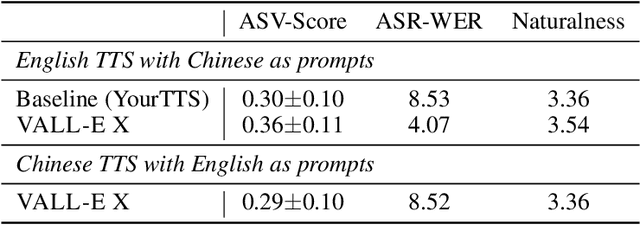
We propose a cross-lingual neural codec language model, VALL-E X, for cross-lingual speech synthesis. Specifically, we extend VALL-E and train a multi-lingual conditional codec language model to predict the acoustic token sequences of the target language speech by using both the source language speech and the target language text as prompts. VALL-E X inherits strong in-context learning capabilities and can be applied for zero-shot cross-lingual text-to-speech synthesis and zero-shot speech-to-speech translation tasks. Experimental results show that it can generate high-quality speech in the target language via just one speech utterance in the source language as a prompt while preserving the unseen speaker's voice, emotion, and acoustic environment. Moreover, VALL-E X effectively alleviates the foreign accent problems, which can be controlled by a language ID. Audio samples are available at \url{https://aka.ms/vallex}.
Improving Hypernasality Estimation with Automatic Speech Recognition in Cleft Palate Speech
Aug 10, 2022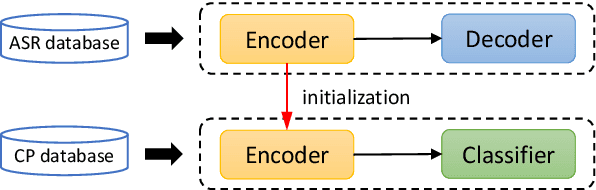
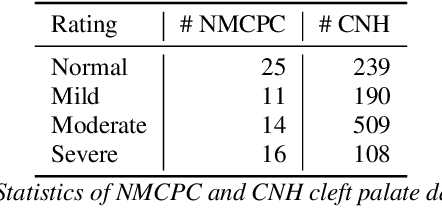
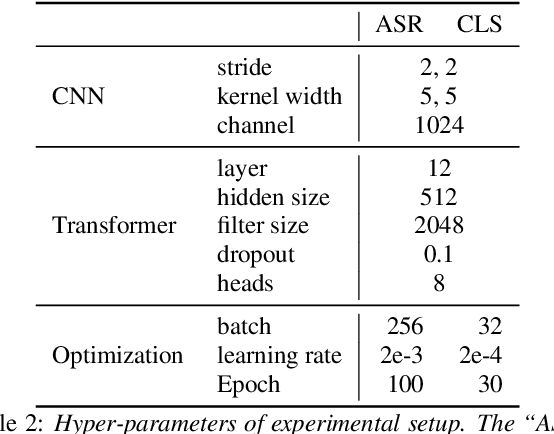
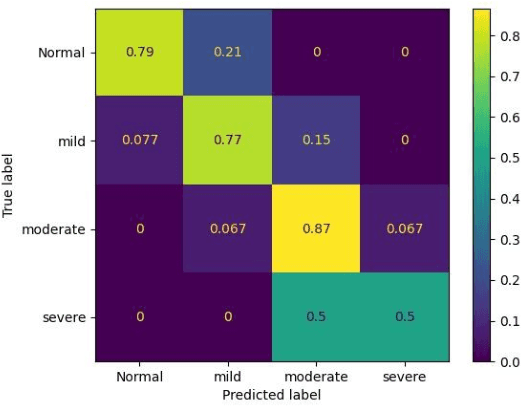
Hypernasality is an abnormal resonance in human speech production, especially in patients with craniofacial anomalies such as cleft palate. In clinical application, hypernasality estimation is crucial in cleft palate diagnosis, as its results determine the subsequent surgery and additional speech therapy. Therefore, designing an automatic hypernasality assessment method will facilitate speech-language pathologists to make precise diagnoses. Existing methods for hypernasality estimation only conduct acoustic analysis based on low-resource cleft palate dataset, by using statistical or neural network-based features. In this paper, we propose a novel approach that uses automatic speech recognition model to improve hypernasality estimation. Specifically, we first pre-train an encoder-decoder framework in an automatic speech recognition (ASR) objective by using speech-to-text dataset, and then fine-tune ASR encoder on the cleft palate dataset for hypernasality estimation. Benefiting from such design, our model for hypernasality estimation can enjoy the advantages of ASR model: 1) compared with low-resource cleft palate dataset, the ASR task usually includes large-scale speech data in the general domain, which enables better model generalization; 2) the text annotations in ASR dataset guide model to extract better acoustic features. Experimental results on two cleft palate datasets demonstrate that our method achieves superior performance compared with previous approaches.
Fast and small footprint Hybrid HMM-HiFiGAN based system for speech synthesis in Indian languages
Feb 13, 2023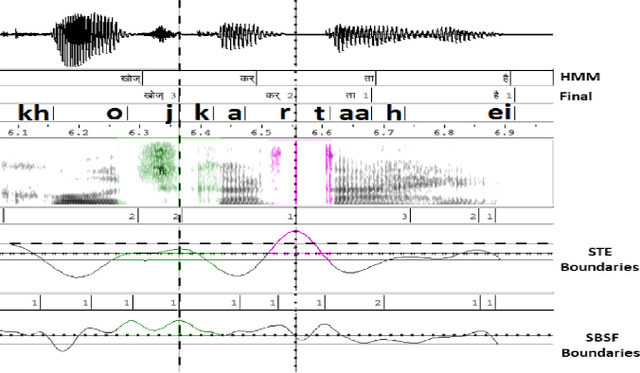

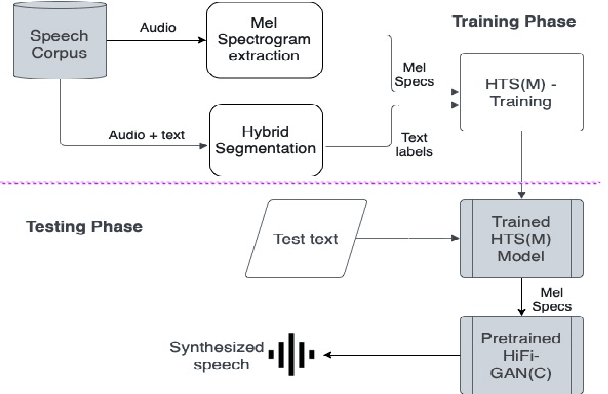
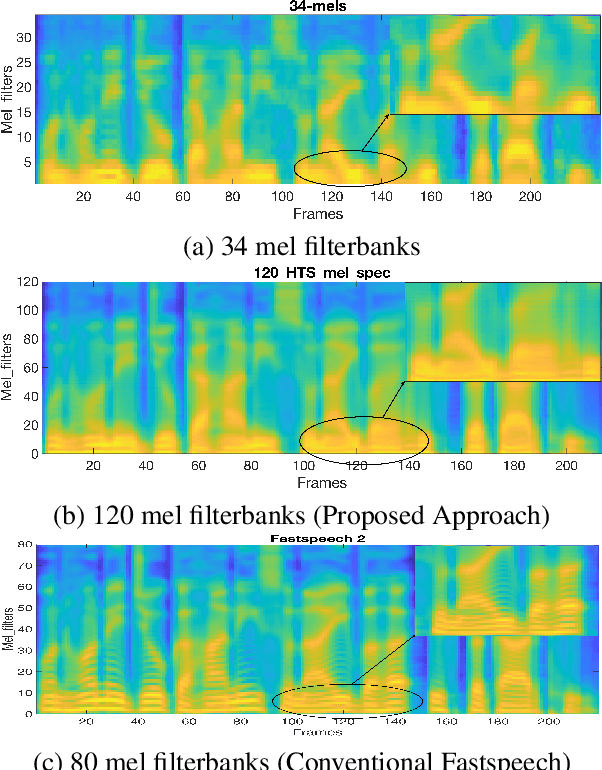
Hidden-Markov-model (HMM) based text-to-speech (HTS) offers flexibility in speaking styles along with fast training and synthesis while being computationally less intense. HTS performs well even in low-resource scenarios. The primary drawback is that the voice quality is poor compared to that of E2E systems. A hybrid approach combining HMM-based feature generation and neural-network-based HiFi-GAN vocoder to improve HTS synthesis quality is proposed. HTS is trained on high-resolution mel-spectrograms instead of conventional mel generalized coefficients (MGC), and the output mel-spectrogram corresponding to the input text is used in a HiFi-GAN vocoder trained on Indic languages, to produce naturalness that is equivalent to that of E2E systems, as evidenced from the DMOS and PC tests.
Vicarious Offense and Noise Audit of Offensive Speech Classifiers
Feb 03, 2023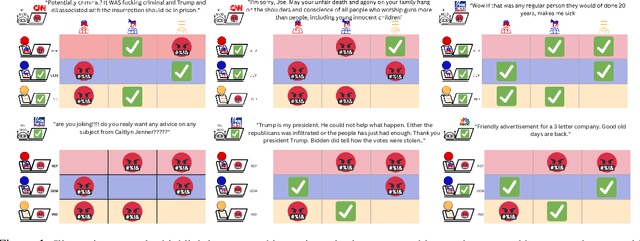

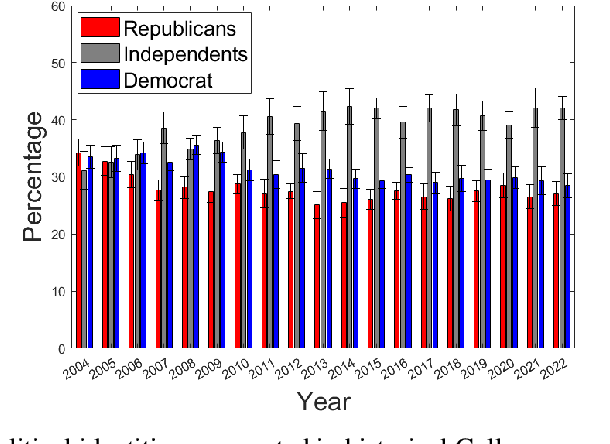

This paper examines social web content moderation from two key perspectives: automated methods (machine moderators) and human evaluators (human moderators). We conduct a noise audit at an unprecedented scale using nine machine moderators trained on well-known offensive speech data sets evaluated on a corpus sampled from 92 million YouTube comments discussing a multitude of issues relevant to US politics. We introduce a first-of-its-kind data set of vicarious offense. We ask annotators: (1) if they find a given social media post offensive; and (2) how offensive annotators sharing different political beliefs would find the same content. Our experiments with machine moderators reveal that moderation outcomes wildly vary across different machine moderators. Our experiments with human moderators suggest that (1) political leanings considerably affect first-person offense perspective; (2) Republicans are the worst predictors of vicarious offense; (3) predicting vicarious offense for the Republicans is most challenging than predicting vicarious offense for the Independents and the Democrats; and (4) disagreement across political identity groups considerably increases when sensitive issues such as reproductive rights or gun control/rights are discussed. Both experiments suggest that offense, is indeed, highly subjective and raise important questions concerning content moderation practices.
Towards Unified All-Neural Beamforming for Time and Frequency Domain Speech Separation
Dec 16, 2022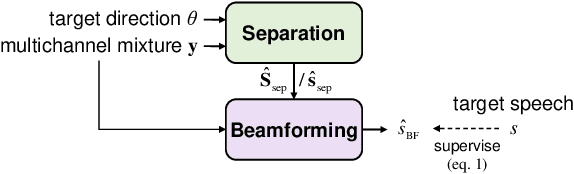
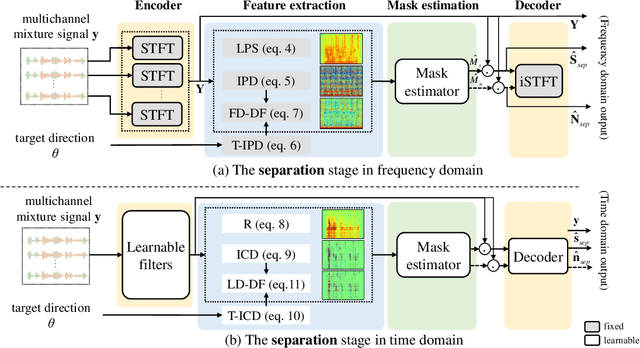
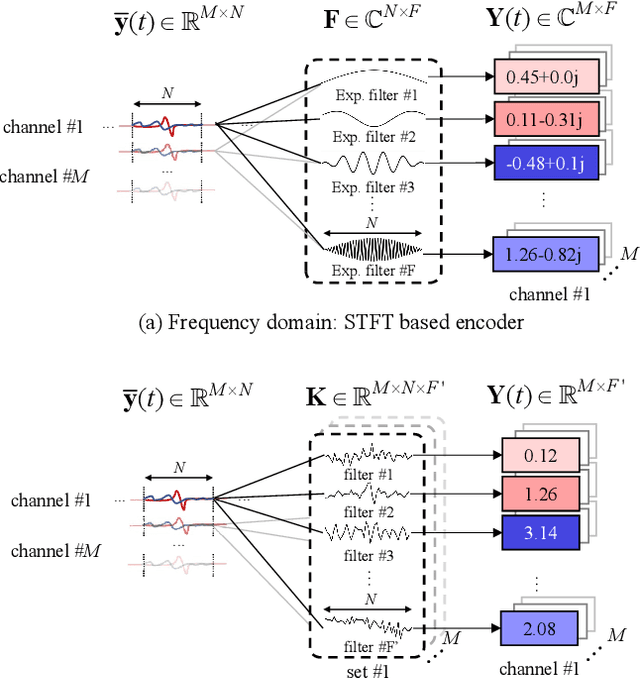
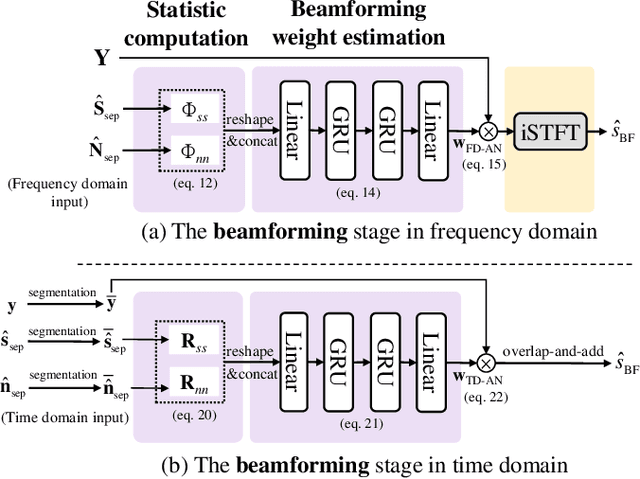
Recently, frequency domain all-neural beamforming methods have achieved remarkable progress for multichannel speech separation. In parallel, the integration of time domain network structure and beamforming also gains significant attention. This study proposes a novel all-neural beamforming method in time domain and makes an attempt to unify the all-neural beamforming pipelines for time domain and frequency domain multichannel speech separation. The proposed model consists of two modules: separation and beamforming. Both modules perform temporal-spectral-spatial modeling and are trained from end-to-end using a joint loss function. The novelty of this study lies in two folds. Firstly, a time domain directional feature conditioned on the direction of the target speaker is proposed, which can be jointly optimized within the time domain architecture to enhance target signal estimation. Secondly, an all-neural beamforming network in time domain is designed to refine the pre-separated results. This module features with parametric time-variant beamforming coefficient estimation, without explicitly following the derivation of optimal filters that may lead to an upper bound. The proposed method is evaluated on simulated reverberant overlapped speech data derived from the AISHELL-1 corpus. Experimental results demonstrate significant performance improvements over frequency domain state-of-the-arts, ideal magnitude masks and existing time domain neural beamforming methods.
Efficient Sequence Transduction by Jointly Predicting Tokens and Durations
Apr 13, 2023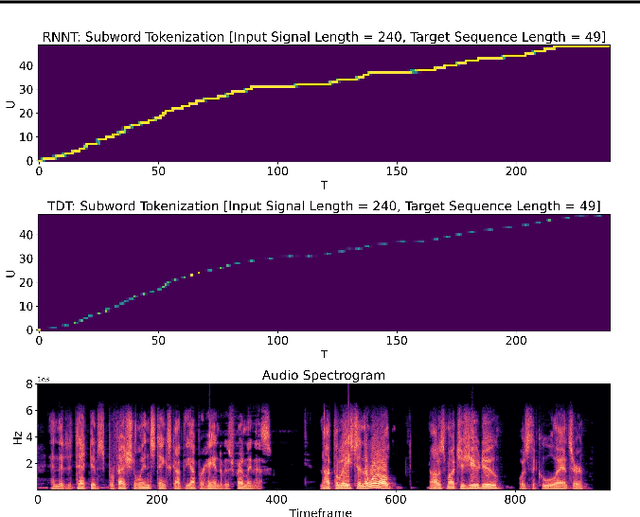
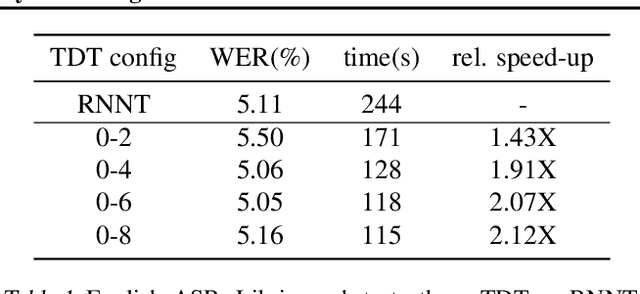
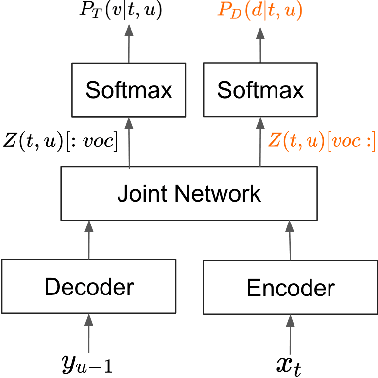
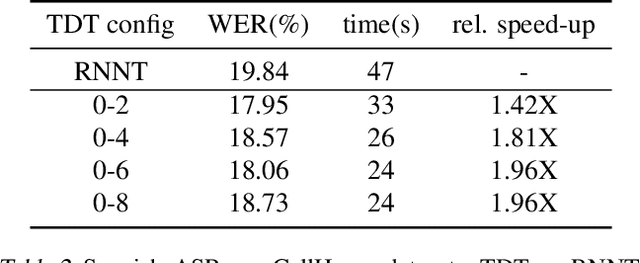
This paper introduces a novel Token-and-Duration Transducer (TDT) architecture for sequence-to-sequence tasks. TDT extends conventional RNN-Transducer architectures by jointly predicting both a token and its duration, i.e. the number of input frames covered by the emitted token. This is achieved by using a joint network with two outputs which are independently normalized to generate distributions over tokens and durations. During inference, TDT models can skip input frames guided by the predicted duration output, which makes them significantly faster than conventional Transducers which process the encoder output frame by frame. TDT models achieve both better accuracy and significantly faster inference than conventional Transducers on different sequence transduction tasks. TDT models for Speech Recognition achieve better accuracy and up to 2.82X faster inference than RNN-Transducers. TDT models for Speech Translation achieve an absolute gain of over 1 BLEU on the MUST-C test compared with conventional Transducers, and its inference is 2.27X faster. In Speech Intent Classification and Slot Filling tasks, TDT models improve the intent accuracy up to over 1% (absolute) over conventional Transducers, while running up to 1.28X faster.
ESB: A Benchmark For Multi-Domain End-to-End Speech Recognition
Oct 24, 2022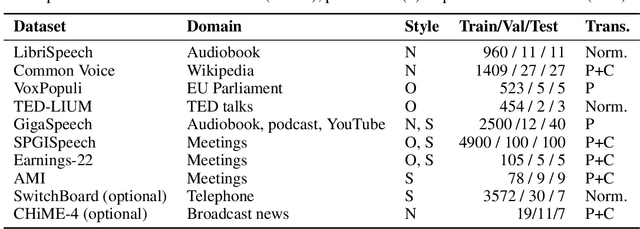
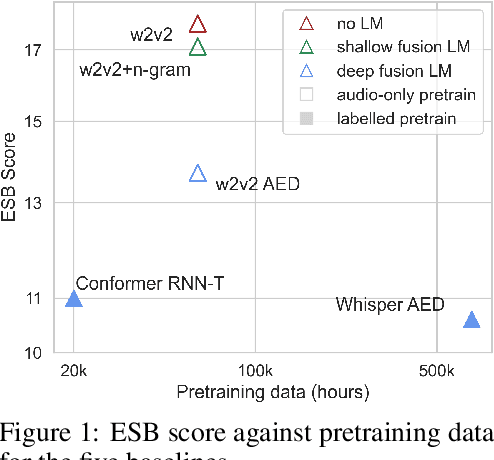
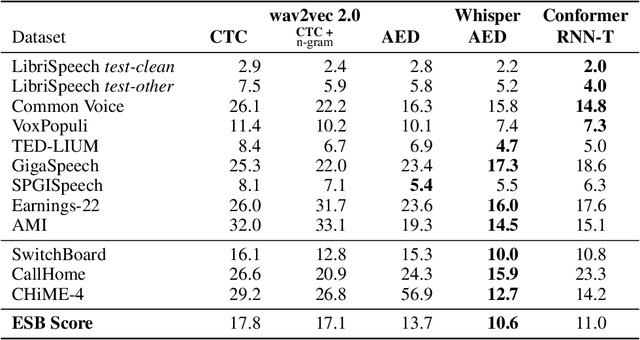
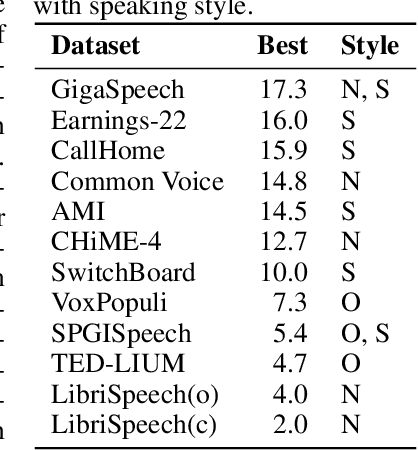
Speech recognition applications cover a range of different audio and text distributions, with different speaking styles, background noise, transcription punctuation and character casing. However, many speech recognition systems require dataset-specific tuning (audio filtering, punctuation removal and normalisation of casing), therefore assuming a-priori knowledge of both the audio and text distributions. This tuning requirement can lead to systems failing to generalise to other datasets and domains. To promote the development of multi-domain speech systems, we introduce the End-to-end Speech Benchmark (ESB) for evaluating the performance of a single automatic speech recognition (ASR) system across a broad set of speech datasets. Benchmarked systems must use the same data pre- and post-processing algorithm across datasets - assuming the audio and text data distributions are a-priori unknown. We compare a series of state-of-the-art (SoTA) end-to-end (E2E) systems on this benchmark, demonstrating how a single speech system can be applied and evaluated on a wide range of data distributions. We find E2E systems to be effective across datasets: in a fair comparison, E2E systems achieve within 2.6% of SoTA systems tuned to a specific dataset. Our analysis reveals that transcription artefacts, such as punctuation and casing, pose difficulties for ASR systems and should be included in evaluation. We believe E2E benchmarking over a range of datasets promotes the research of multi-domain speech recognition systems. ESB is available at https://huggingface.co/esb.
Improving Autoregressive NLP Tasks via Modular Linearized Attention
Apr 17, 2023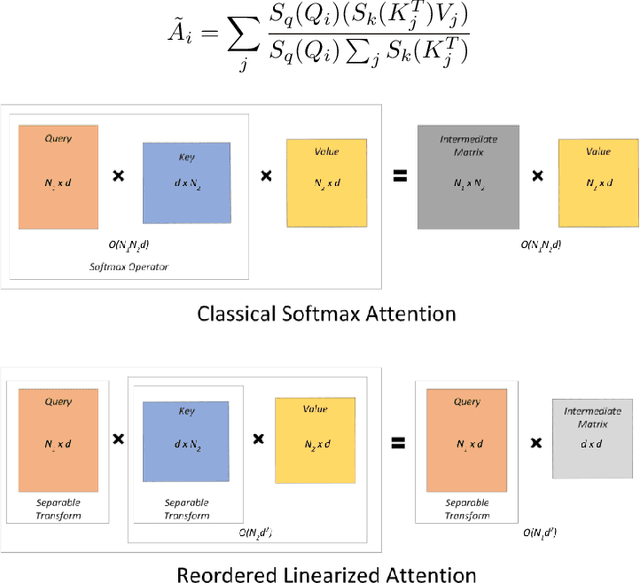
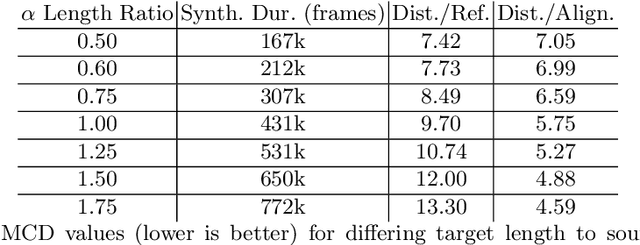
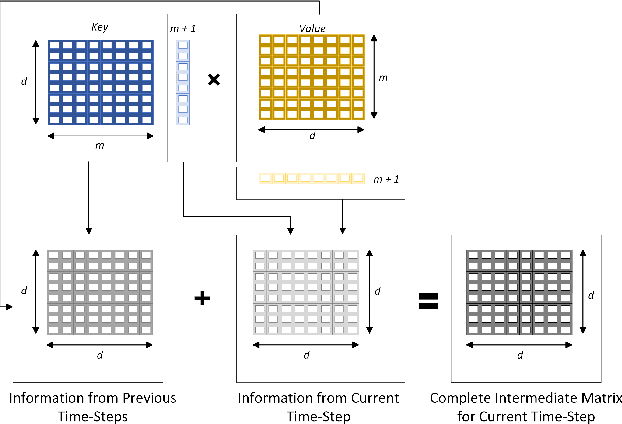
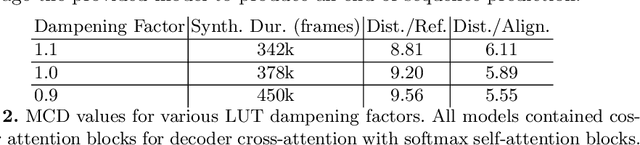
Various natural language processing (NLP) tasks necessitate models that are efficient and small based on their ultimate application at the edge or in other resource-constrained environments. While prior research has reduced the size of these models, increasing computational efficiency without considerable performance impacts remains difficult, especially for autoregressive tasks. This paper proposes \textit{modular linearized attention (MLA)}, which combines multiple efficient attention mechanisms, including cosFormer \cite{zhen2022cosformer}, to maximize inference quality while achieving notable speedups. We validate this approach on several autoregressive NLP tasks, including speech-to-text neural machine translation (S2T NMT), speech-to-text simultaneous translation (SimulST), and autoregressive text-to-spectrogram, noting efficiency gains on TTS and competitive performance for NMT and SimulST during training and inference.
Progressive Multi-Scale Self-Supervised Learning for Speech Recognition
Dec 07, 2022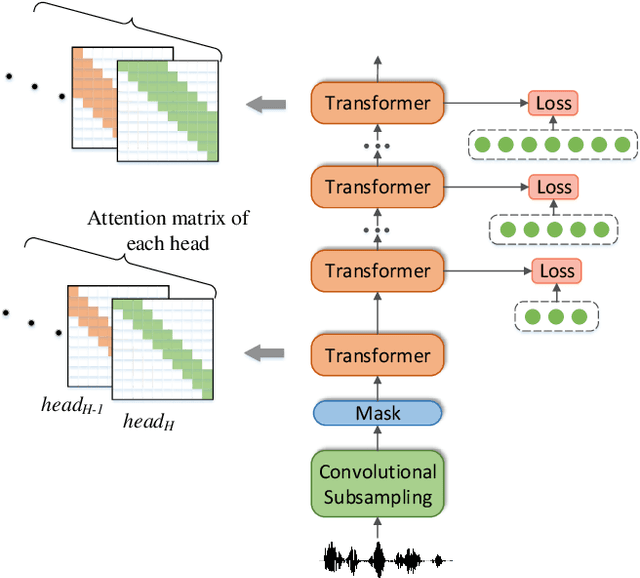
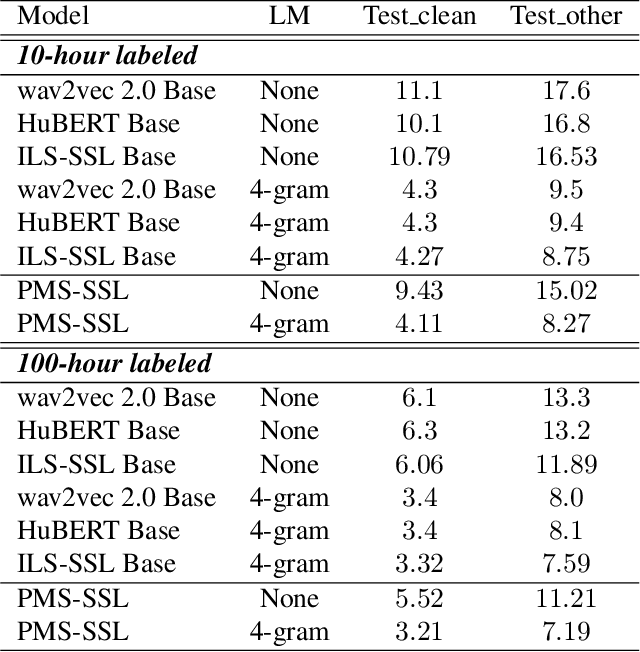

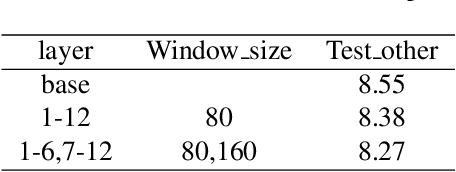
Self-supervised learning (SSL) models have achieved considerable improvements in automatic speech recognition (ASR). In addition, ASR performance could be further improved if the model is dedicated to audio content information learning theoretically. To this end, we propose a progressive multi-scale self-supervised learning (PMS-SSL) method, which uses fine-grained target sets to compute SSL loss at top layer while uses coarse-grained target sets at intermediate layers. Furthermore, PMS-SSL introduces multi-scale structure into multi-head self-attention for better speech representation, which restricts the attention area into a large scope at higher layers while restricts the attention area into a small scope at lower layers. Experiments on Librispeech dataset indicate the effectiveness of our proposed method. Compared with HuBERT, PMS-SSL achieves 13.7% / 12.7% relative WER reduction on test other evaluation subsets respectively when fine-tuned on 10hours / 100hours subsets.