 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
TO-Rawnet: Improving RawNet with TCN and Orthogonal Regularization for Fake Audio Detection
May 23, 2023
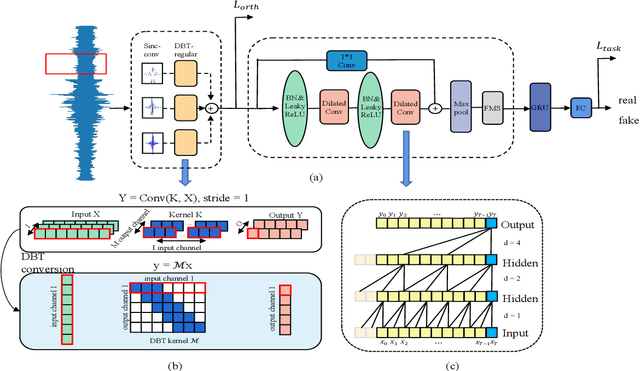
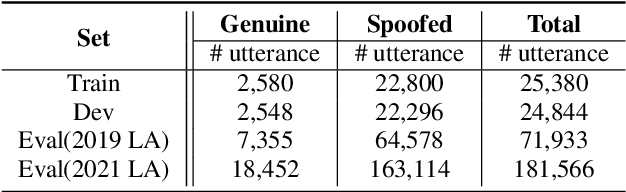
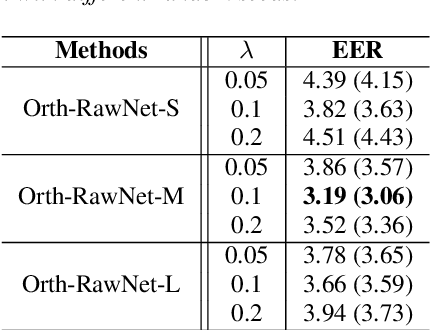
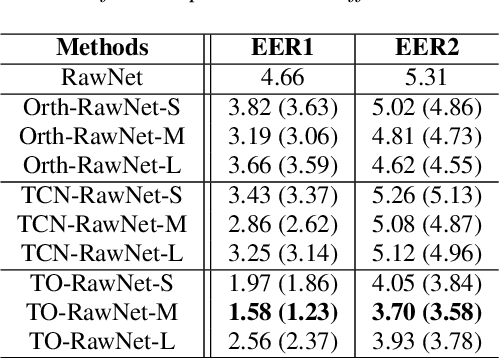
Current fake audio detection relies on hand-crafted features, which lose information during extraction. To overcome this, recent studies use direct feature extraction from raw audio signals. For example, RawNet is one of the representative works in end-to-end fake audio detection. However, existing work on RawNet does not optimize the parameters of the Sinc-conv during training, which limited its performance. In this paper, we propose to incorporate orthogonal convolution into RawNet, which reduces the correlation between filters when optimizing the parameters of Sinc-conv, thus improving discriminability. Additionally, we introduce temporal convolutional networks (TCN) to capture long-term dependencies in speech signals. Experiments on the ASVspoof 2019 show that the Our TO-RawNet system can relatively reduce EER by 66.09\% on logical access scenario compared with the RawNet, demonstrating its effectiveness in detecting fake audio attacks.
A Whisper transformer for audio captioning trained with synthetic captions and transfer learning
May 15, 2023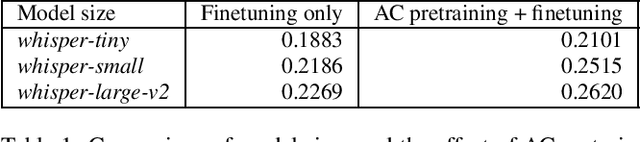

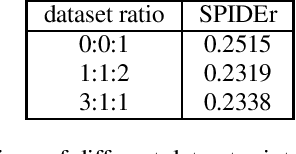
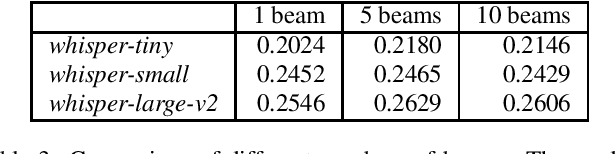
The field of audio captioning has seen significant advancements in recent years, driven by the availability of large-scale audio datasets and advancements in deep learning techniques. In this technical report, we present our approach to audio captioning, focusing on the use of a pretrained speech-to-text Whisper model and pretraining on synthetic captions. We discuss our training procedures and present our experiments' results, which include model size variations, dataset mixtures, and other hyperparameters. Our findings demonstrate the impact of different training strategies on the performance of the audio captioning model. Our code and trained models are publicly available on GitHub and Hugging Face Hub.
Fake News and Hate Speech: Language in Common
Dec 05, 2022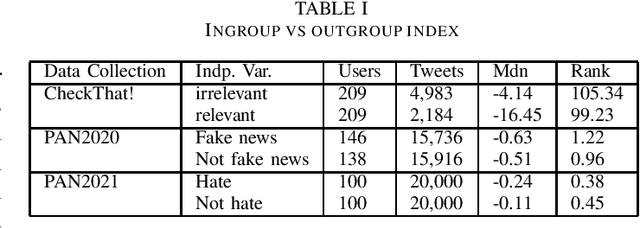
In this paper we raise the research question of whether fake news and hate speech spreaders share common patterns in language. We compute a novel index, the ingroup vs outgroup index, in three different datasets and we show that both phenomena share an "us vs them" narrative.
ArzEn-ST: A Three-way Speech Translation Corpus for Code-Switched Egyptian Arabic - English
Nov 22, 2022
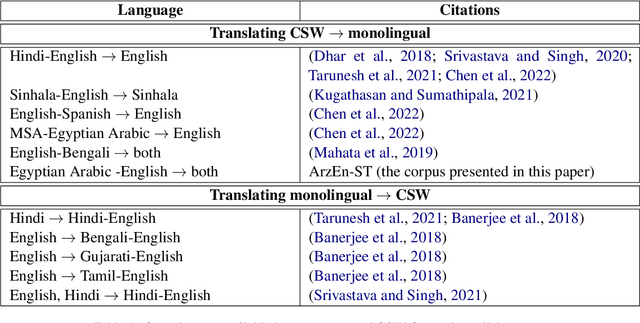

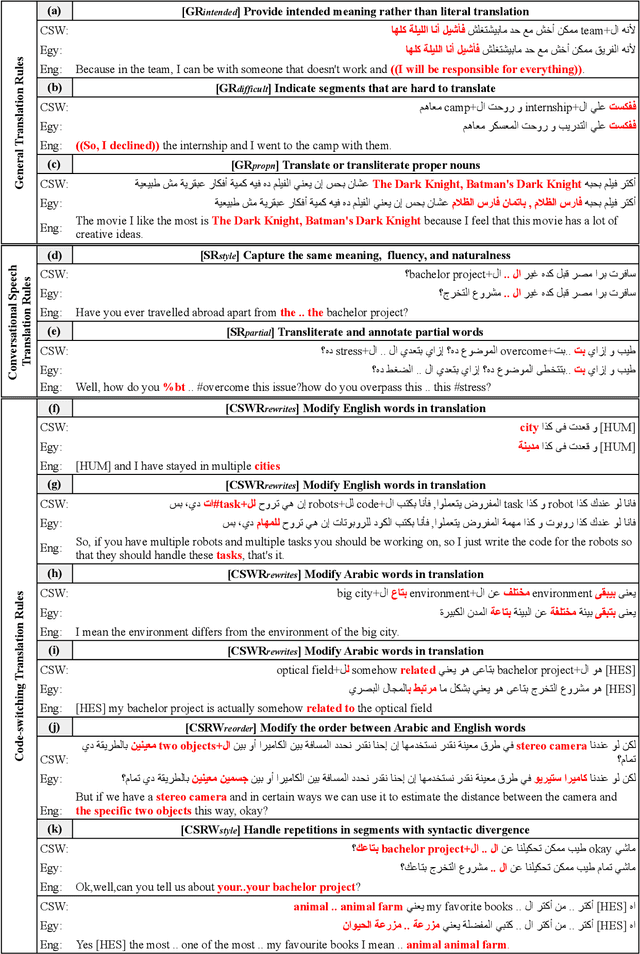
We present our work on collecting ArzEn-ST, a code-switched Egyptian Arabic - English Speech Translation Corpus. This corpus is an extension of the ArzEn speech corpus, which was collected through informal interviews with bilingual speakers. In this work, we collect translations in both directions, monolingual Egyptian Arabic and monolingual English, forming a three-way speech translation corpus. We make the translation guidelines and corpus publicly available. We also report results for baseline systems for machine translation and speech translation tasks. We believe this is a valuable resource that can motivate and facilitate further research studying the code-switching phenomenon from a linguistic perspective and can be used to train and evaluate NLP systems.
AudioDec: An Open-source Streaming High-fidelity Neural Audio Codec
May 26, 2023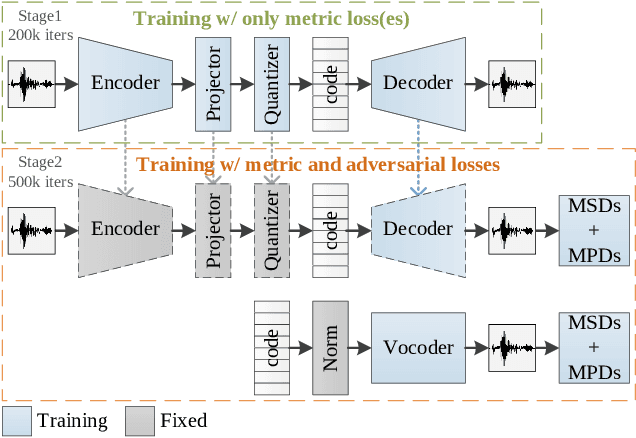
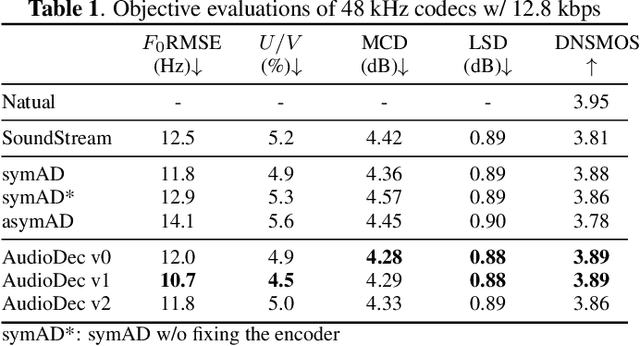

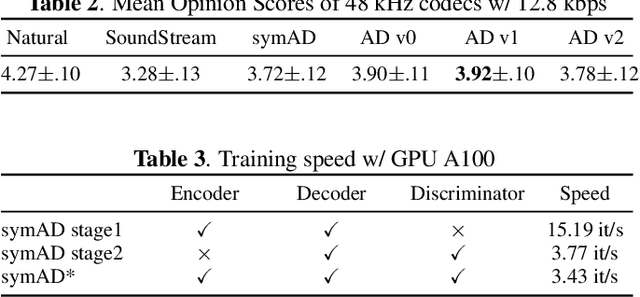
A good audio codec for live applications such as telecommunication is characterized by three key properties: (1) compression, i.e.\ the bitrate that is required to transmit the signal should be as low as possible; (2) latency, i.e.\ encoding and decoding the signal needs to be fast enough to enable communication without or with only minimal noticeable delay; and (3) reconstruction quality of the signal. In this work, we propose an open-source, streamable, and real-time neural audio codec that achieves strong performance along all three axes: it can reconstruct highly natural sounding 48~kHz speech signals while operating at only 12~kbps and running with less than 6~ms (GPU)/10~ms (CPU) latency. An efficient training paradigm is also demonstrated for developing such neural audio codecs for real-world scenarios. Both objective and subjective evaluations using the VCTK corpus are provided. To sum up, AudioDec is a well-developed plug-and-play benchmark for audio codec applications.
ABC-KD: Attention-Based-Compression Knowledge Distillation for Deep Learning-Based Noise Suppression
May 26, 2023
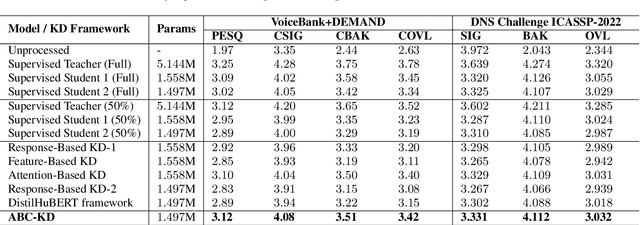
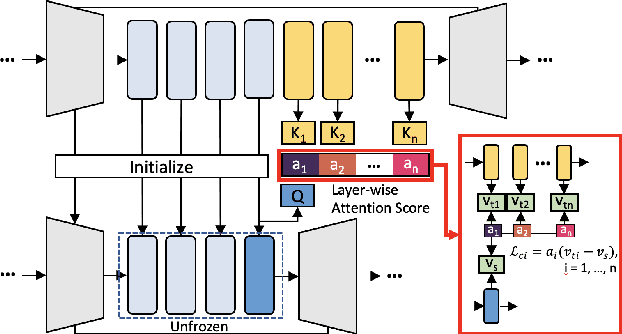
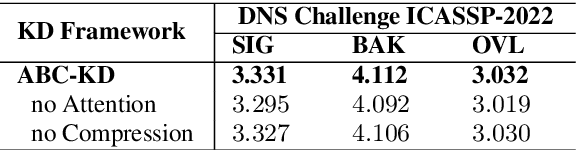
Noise suppression (NS) models have been widely applied to enhance speech quality. Recently, Deep Learning-Based NS, which we denote as Deep Noise Suppression (DNS), became the mainstream NS method due to its excelling performance over traditional ones. However, DNS models face 2 major challenges for supporting the real-world applications. First, high-performing DNS models are usually large in size, causing deployment difficulties. Second, DNS models require extensive training data, including noisy audios as inputs and clean audios as labels. It is often difficult to obtain clean labels for training DNS models. We propose the use of knowledge distillation (KD) to resolve both challenges. Our study serves 2 main purposes. To begin with, we are among the first to comprehensively investigate mainstream KD techniques on DNS models to resolve the two challenges. Furthermore, we propose a novel Attention-Based-Compression KD method that outperforms all investigated mainstream KD frameworks on DNS task.
Quran Recitation Recognition using End-to-End Deep Learning
May 10, 2023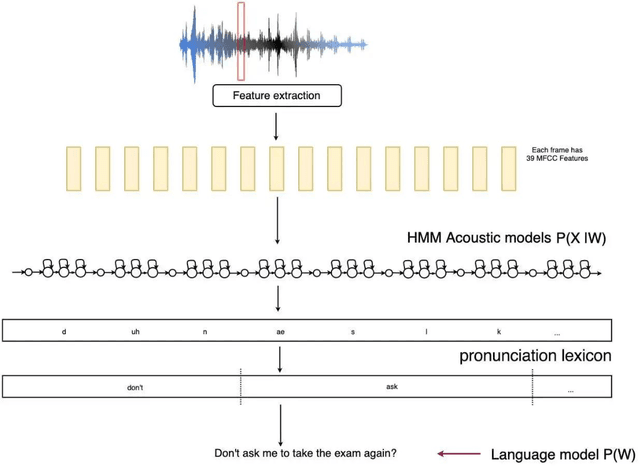
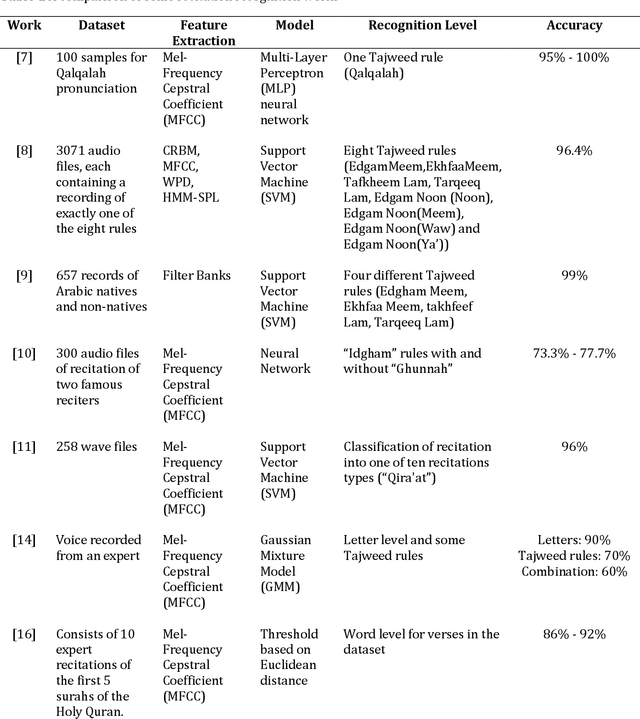
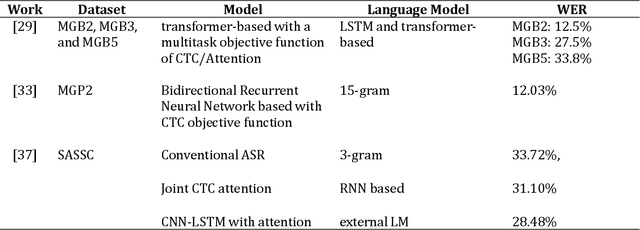
The Quran is the holy scripture of Islam, and its recitation is an important aspect of the religion. Recognizing the recitation of the Holy Quran automatically is a challenging task due to its unique rules that are not applied in normal speaking speeches. A lot of research has been done in this domain, but previous works have detected recitation errors as a classification task or used traditional automatic speech recognition (ASR). In this paper, we proposed a novel end-to-end deep learning model for recognizing the recitation of the Holy Quran. The proposed model is a CNN-Bidirectional GRU encoder that uses CTC as an objective function, and a character-based decoder which is a beam search decoder. Moreover, all previous works were done on small private datasets consisting of short verses and a few chapters of the Holy Quran. As a result of using private datasets, no comparisons were done. To overcome this issue, we used a public dataset that has recently been published (Ar-DAD) and contains about 37 chapters that were recited by 30 reciters, with different recitation speeds and different types of pronunciation rules. The proposed model performance was evaluated using the most common evaluation metrics in speech recognition, word error rate (WER), and character error rate (CER). The results were 8.34% WER and 2.42% CER. We hope this research will be a baseline for comparisons with future research on this public new dataset (Ar-DAD).
wav2vec and its current potential to Automatic Speech Recognition in German for the usage in Digital History: A comparative assessment of available ASR-technologies for the use in cultural heritage contexts
Mar 06, 2023In this case study we trained and published a state-of-the-art open-source model for Automatic Speech Recognition (ASR) for German to evaluate the current potential of this technology for the use in the larger context of Digital Humanities and cultural heritage indexation. Along with this paper we publish our wav2vec2 based speech to text model while we evaluate its performance on a corpus of historical recordings we assembled compared against commercial cloud-based and proprietary services. While our model achieves moderate results, we see that proprietary cloud services fare significantly better. As our results show, recognition rates over 90 percent can currently be achieved, however, these numbers drop quickly once the recordings feature limited audio quality or use of non-every day or outworn language. A big issue is the high variety of different dialects and accents in the German language. Nevertheless, this paper highlights that the currently available quality of recognition is high enough to address various use cases in the Digital Humanities. We argue that ASR will become a key technology for the documentation and analysis of audio-visual sources and identify an array of important questions that the DH community and cultural heritage stakeholders will have to address in the near future.
Structured State Space Decoder for Speech Recognition and Synthesis
Oct 31, 2022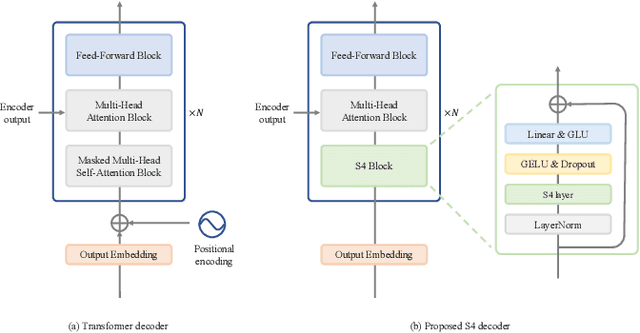
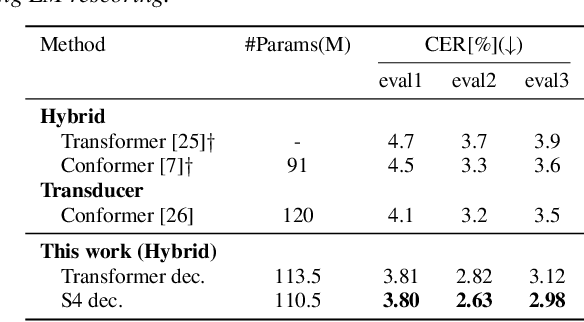
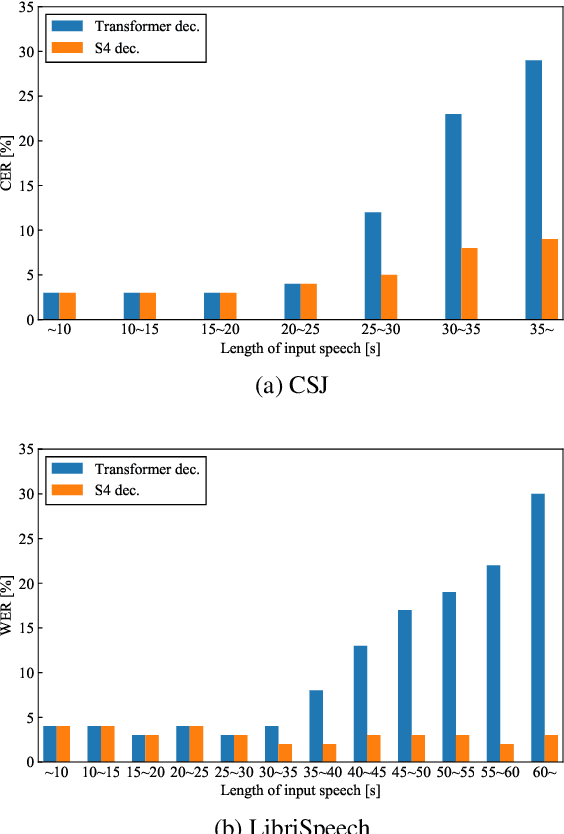
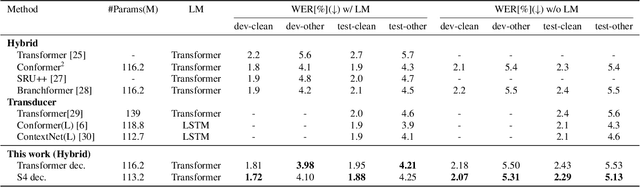
Automatic speech recognition (ASR) systems developed in recent years have shown promising results with self-attention models (e.g., Transformer and Conformer), which are replacing conventional recurrent neural networks. Meanwhile, a structured state space model (S4) has been recently proposed, producing promising results for various long-sequence modeling tasks, including raw speech classification. The S4 model can be trained in parallel, same as the Transformer model. In this study, we applied S4 as a decoder for ASR and text-to-speech (TTS) tasks by comparing it with the Transformer decoder. For the ASR task, our experimental results demonstrate that the proposed model achieves a competitive word error rate (WER) of 1.88%/4.25% on LibriSpeech test-clean/test-other set and a character error rate (CER) of 3.80%/2.63%/2.98% on the CSJ eval1/eval2/eval3 set. Furthermore, the proposed model is more robust than the standard Transformer model, particularly for long-form speech on both the datasets. For the TTS task, the proposed method outperforms the Transformer baseline.
Seeing What You Said: Talking Face Generation Guided by a Lip Reading Expert
Mar 29, 2023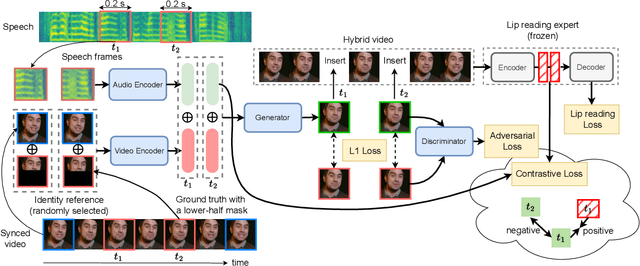
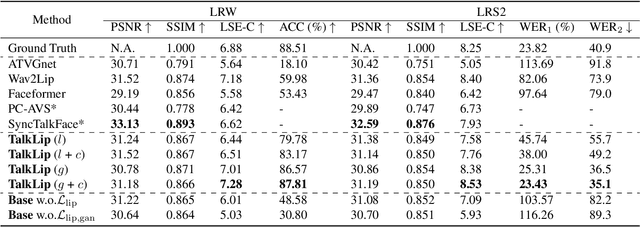
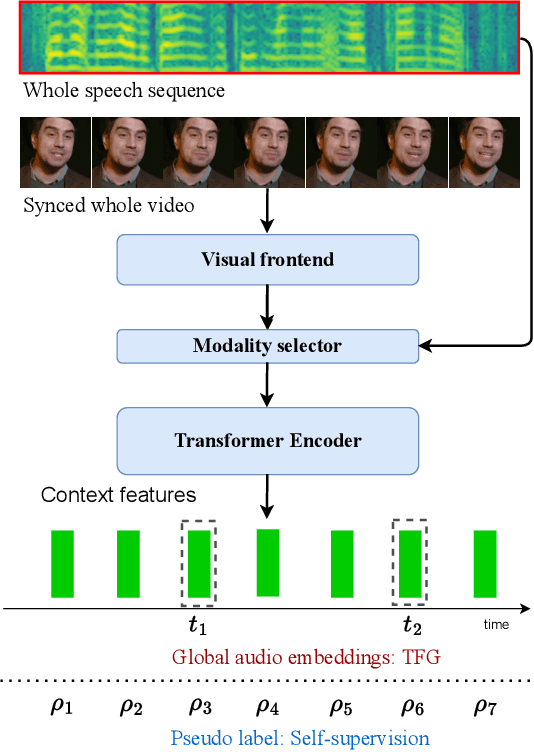
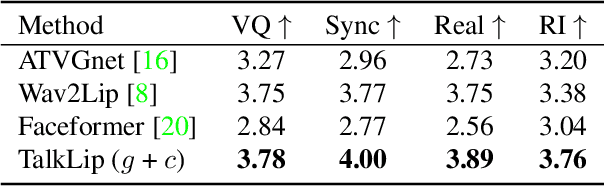
Talking face generation, also known as speech-to-lip generation, reconstructs facial motions concerning lips given coherent speech input. The previous studies revealed the importance of lip-speech synchronization and visual quality. Despite much progress, they hardly focus on the content of lip movements i.e., the visual intelligibility of the spoken words, which is an important aspect of generation quality. To address the problem, we propose using a lip-reading expert to improve the intelligibility of the generated lip regions by penalizing the incorrect generation results. Moreover, to compensate for data scarcity, we train the lip-reading expert in an audio-visual self-supervised manner. With a lip-reading expert, we propose a novel contrastive learning to enhance lip-speech synchronization, and a transformer to encode audio synchronically with video, while considering global temporal dependency of audio. For evaluation, we propose a new strategy with two different lip-reading experts to measure intelligibility of the generated videos. Rigorous experiments show that our proposal is superior to other State-of-the-art (SOTA) methods, such as Wav2Lip, in reading intelligibility i.e., over 38% Word Error Rate (WER) on LRS2 dataset and 27.8% accuracy on LRW dataset. We also achieve the SOTA performance in lip-speech synchronization and comparable performances in visual quality.