 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Fast and small footprint Hybrid HMM-HiFiGAN based system for speech synthesis in Indian languages
Feb 13, 2023
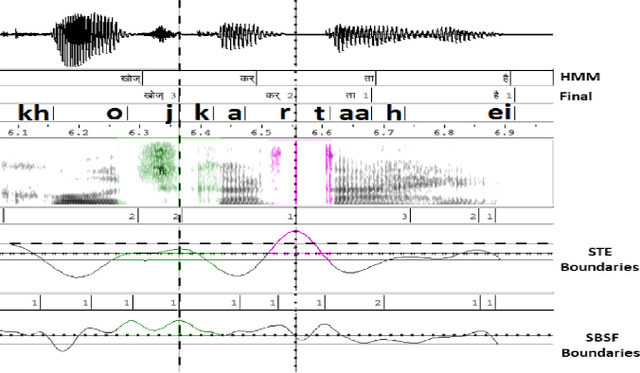

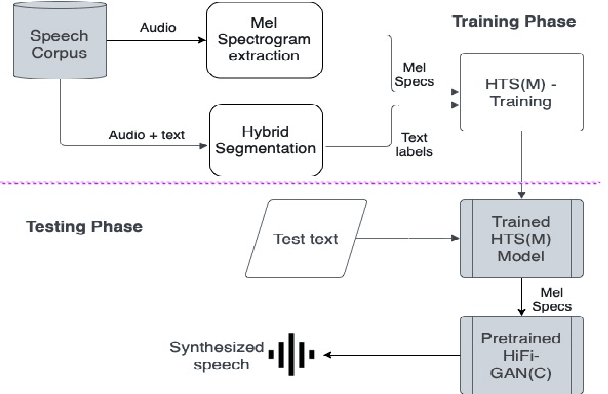
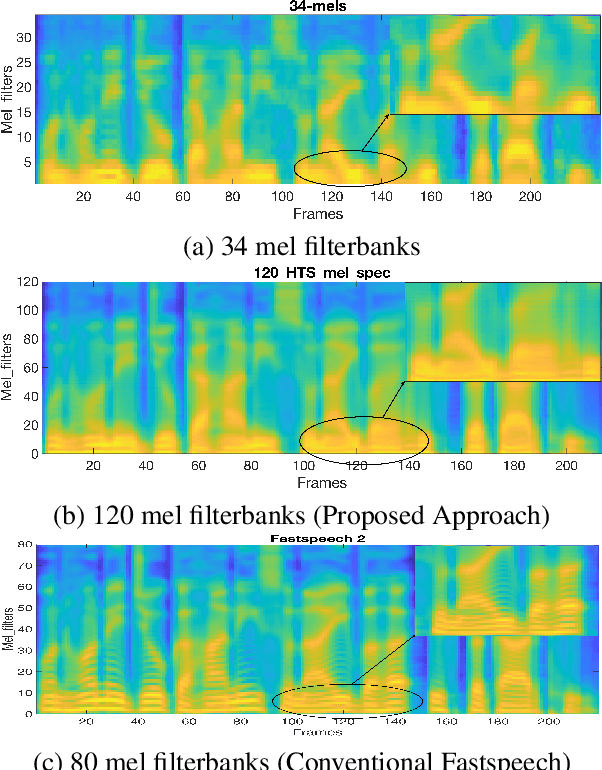
Hidden-Markov-model (HMM) based text-to-speech (HTS) offers flexibility in speaking styles along with fast training and synthesis while being computationally less intense. HTS performs well even in low-resource scenarios. The primary drawback is that the voice quality is poor compared to that of E2E systems. A hybrid approach combining HMM-based feature generation and neural-network-based HiFi-GAN vocoder to improve HTS synthesis quality is proposed. HTS is trained on high-resolution mel-spectrograms instead of conventional mel generalized coefficients (MGC), and the output mel-spectrogram corresponding to the input text is used in a HiFi-GAN vocoder trained on Indic languages, to produce naturalness that is equivalent to that of E2E systems, as evidenced from the DMOS and PC tests.
HuBERT-TR: Reviving Turkish Automatic Speech Recognition with Self-supervised Speech Representation Learning
Oct 13, 2022
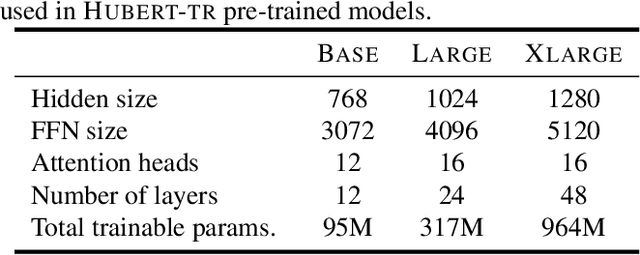
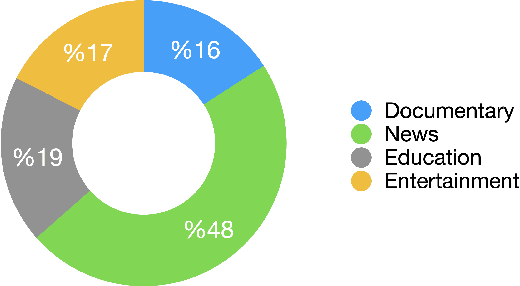
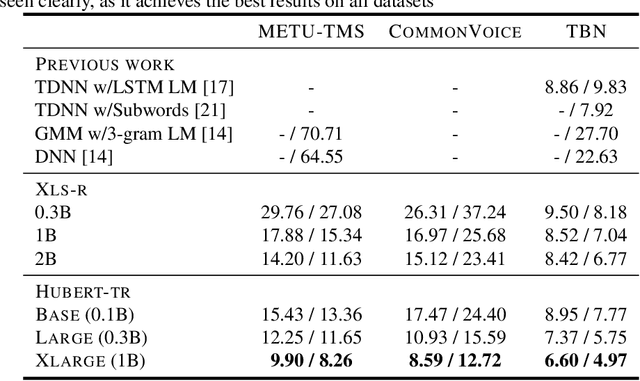
While the Turkish language is listed among low-resource languages, literature on Turkish automatic speech recognition (ASR) is relatively old. In this paper, we present HuBERT-TR, a speech representation model for Turkish based on HuBERT. HuBERT-TR achieves state-of-the-art results on several Turkish ASR datasets. We investigate pre-training HuBERT for Turkish with large-scale data curated from online resources. We pre-train HuBERT-TR using over 6,500 hours of speech data curated from YouTube that includes extensive variability in terms of quality and genre. We show that pre-trained models within a multi-lingual setup are inferior to language-specific models, where our Turkish model HuBERT-TR base performs better than its x10 times larger multi-lingual counterpart XLS-R-1B. Moreover, we study the effect of scaling on ASR performance by scaling our models up to 1B parameters. Our best model yields a state-of-the-art word error rate of 4.97% on the Turkish Broadcast News dataset. Models are available at huggingface.co/asafaya .
Accurate and Reliable Confidence Estimation Based on Non-Autoregressive End-to-End Speech Recognition System
May 25, 2023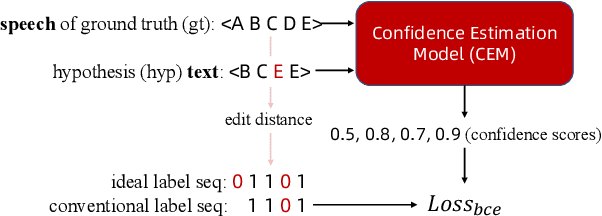
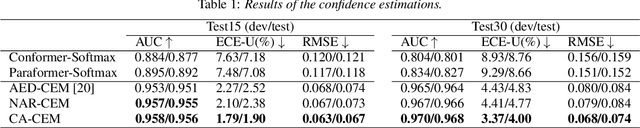
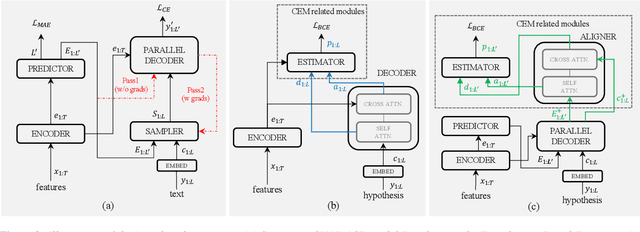
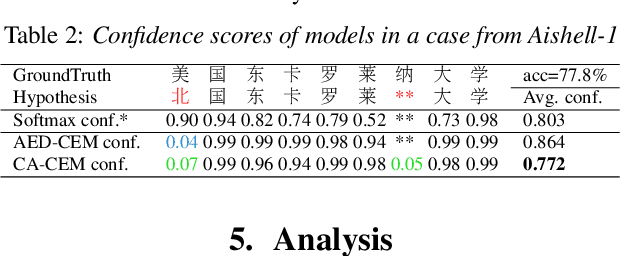
Estimating confidence scores for recognition results is a classic task in ASR field and of vital importance for kinds of downstream tasks and training strategies. Previous end-to-end~(E2E) based confidence estimation models (CEM) predict score sequences of equal length with input transcriptions, leading to unreliable estimation when deletion and insertion errors occur. In this paper we proposed CIF-Aligned confidence estimation model (CA-CEM) to achieve accurate and reliable confidence estimation based on novel non-autoregressive E2E ASR model - Paraformer. CA-CEM utilizes the modeling character of continuous integrate-and-fire (CIF) mechanism to generate token-synchronous acoustic embedding, which solves the estimation failure issue above. We measure the quality of estimation with AUC and RMSE in token level and ECE-U - a proposed metrics in utterance level. CA-CEM gains 24% and 19% relative reduction on ECE-U and also better AUC and RMSE on two test sets. Furthermore, we conduct analysis to explore the potential of CEM for different ASR related usage.
Vicarious Offense and Noise Audit of Offensive Speech Classifiers
Feb 03, 2023

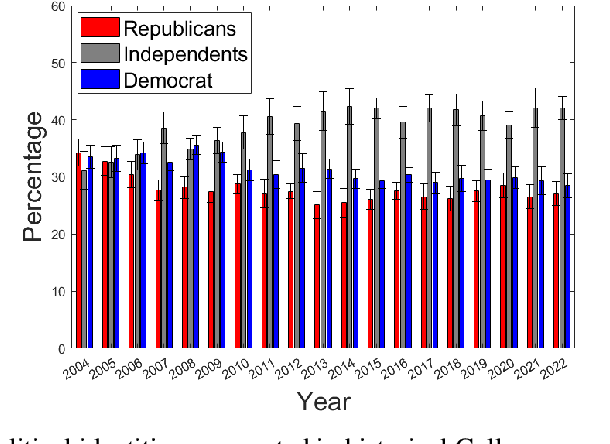

This paper examines social web content moderation from two key perspectives: automated methods (machine moderators) and human evaluators (human moderators). We conduct a noise audit at an unprecedented scale using nine machine moderators trained on well-known offensive speech data sets evaluated on a corpus sampled from 92 million YouTube comments discussing a multitude of issues relevant to US politics. We introduce a first-of-its-kind data set of vicarious offense. We ask annotators: (1) if they find a given social media post offensive; and (2) how offensive annotators sharing different political beliefs would find the same content. Our experiments with machine moderators reveal that moderation outcomes wildly vary across different machine moderators. Our experiments with human moderators suggest that (1) political leanings considerably affect first-person offense perspective; (2) Republicans are the worst predictors of vicarious offense; (3) predicting vicarious offense for the Republicans is most challenging than predicting vicarious offense for the Independents and the Democrats; and (4) disagreement across political identity groups considerably increases when sensitive issues such as reproductive rights or gun control/rights are discussed. Both experiments suggest that offense, is indeed, highly subjective and raise important questions concerning content moderation practices.
Continual Learning for On-Device Speech Recognition using Disentangled Conformers
Dec 02, 2022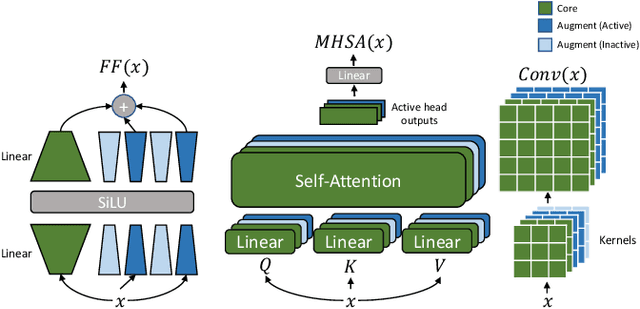
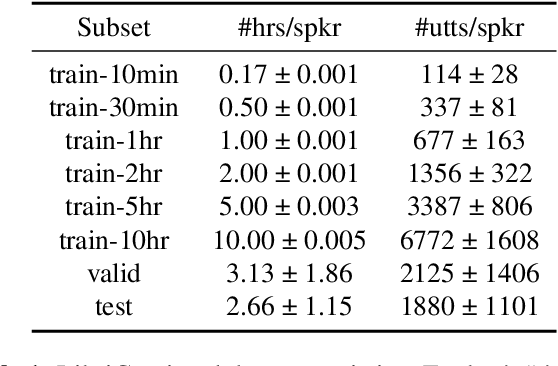
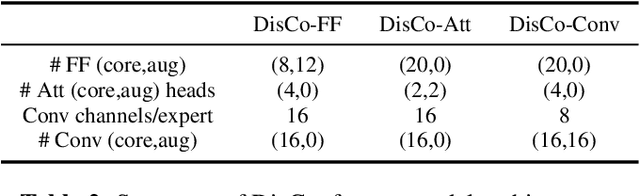
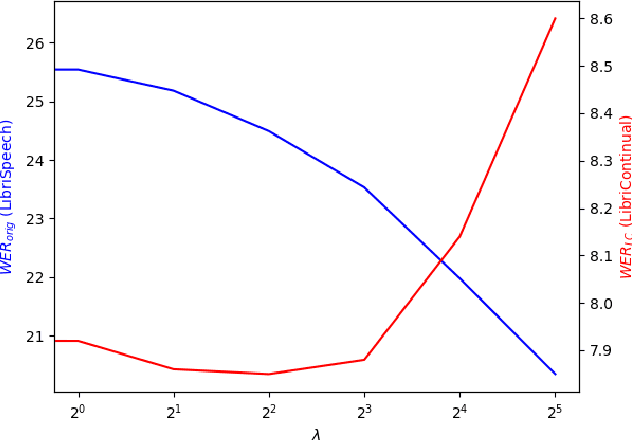
Automatic speech recognition research focuses on training and evaluating on static datasets. Yet, as speech models are increasingly deployed on personal devices, such models encounter user-specific distributional shifts. To simulate this real-world scenario, we introduce LibriContinual, a continual learning benchmark for speaker-specific domain adaptation derived from LibriVox audiobooks, with data corresponding to 118 individual speakers and 6 train splits per speaker of different sizes. Additionally, current speech recognition models and continual learning algorithms are not optimized to be compute-efficient. We adapt a general-purpose training algorithm NetAug for ASR and create a novel Conformer variant called the DisConformer (Disentangled Conformer). This algorithm produces ASR models consisting of a frozen 'core' network for general-purpose use and several tunable 'augment' networks for speaker-specific tuning. Using such models, we propose a novel compute-efficient continual learning algorithm called DisentangledCL. Our experiments show that the DisConformer models significantly outperform baselines on general ASR i.e. LibriSpeech (15.58% rel. WER on test-other). On speaker-specific LibriContinual they significantly outperform trainable-parameter-matched baselines (by 20.65% rel. WER on test) and even match fully finetuned baselines in some settings.
Improving Generalization Ability of Countermeasures for New Mismatch Scenario by Combining Multiple Advanced Regularization Terms
May 18, 2023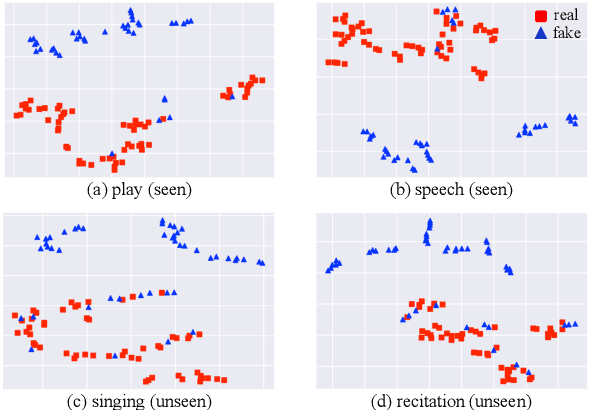


The ability of countermeasure models to generalize from seen speech synthesis methods to unseen ones has been investigated in the ASVspoof challenge. However, a new mismatch scenario in which fake audio may be generated from real audio with unseen genres has not been studied thoroughly. To this end, we first use five different vocoders to create a new dataset called CN-Spoof based on the CN-Celeb1\&2 datasets. Then, we design two auxiliary objectives for regularization via meta-optimization and a genre alignment module, respectively, and combine them with the main anti-spoofing objective using learnable weights for multiple loss terms. The results on our cross-genre evaluation dataset for anti-spoofing show that the proposed method significantly improved the generalization ability of the countermeasures compared with the baseline system in the genre mismatch scenario.
Data Redaction from Conditional Generative Models
May 18, 2023

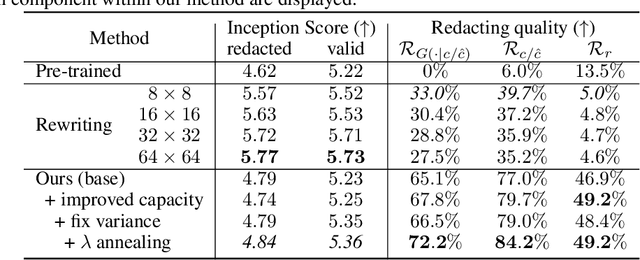

Deep generative models are known to produce undesirable samples such as harmful content. Traditional mitigation methods include re-training from scratch, filtering, or editing; however, these are either computationally expensive or can be circumvented by third parties. In this paper, we take a different approach and study how to post-edit an already-trained conditional generative model so that it redacts certain conditionals that will, with high probability, lead to undesirable content. This is done by distilling the conditioning network in the models, giving a solution that is effective, efficient, controllable, and universal for a class of deep generative models. We conduct experiments on redacting prompts in text-to-image models and redacting voices in text-to-speech models. Our method is computationally light, leads to better redaction quality and robustness than baseline methods while still retaining high generation quality.
Multi-Speaker Multi-Lingual VQTTS System for LIMMITS 2023 Challenge
Apr 25, 2023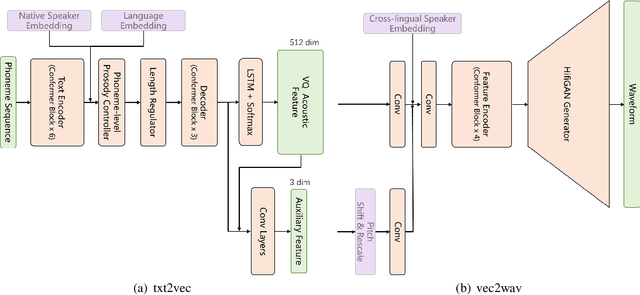
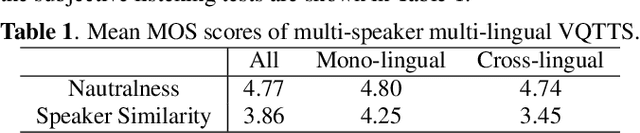
In this paper, we describe the systems developed by the SJTU X-LANCE team for LIMMITS 2023 Challenge, and we mainly focus on the winning system on naturalness for track 1. The aim of this challenge is to build a multi-speaker multi-lingual text-to-speech (TTS) system for Marathi, Hindi and Telugu. Each of the languages has a male and a female speaker in the given dataset. In track 1, only 5 hours data from each speaker can be selected to train the TTS model. Our system is based on the recently proposed VQTTS that utilizes VQ acoustic feature rather than mel-spectrogram. We introduce additional speaker embeddings and language embeddings to VQTTS for controlling the speaker and language information. In the cross-lingual evaluations where we need to synthesize speech in a cross-lingual speaker's voice, we provide a native speaker's embedding to the acoustic model and the target speaker's embedding to the vocoder. In the subjective MOS listening test on naturalness, our system achieves 4.77 which ranks first.
Structured State Space Decoder for Speech Recognition and Synthesis
Oct 31, 2022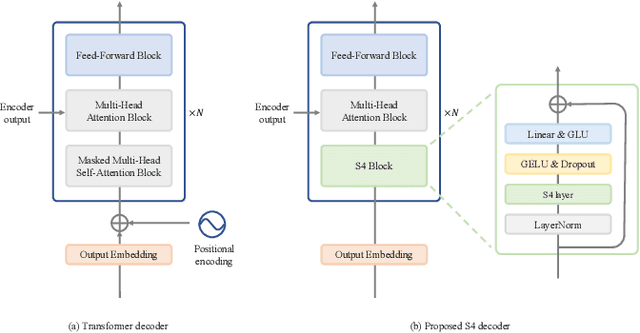
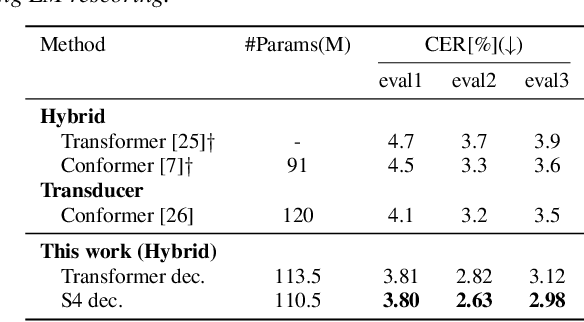
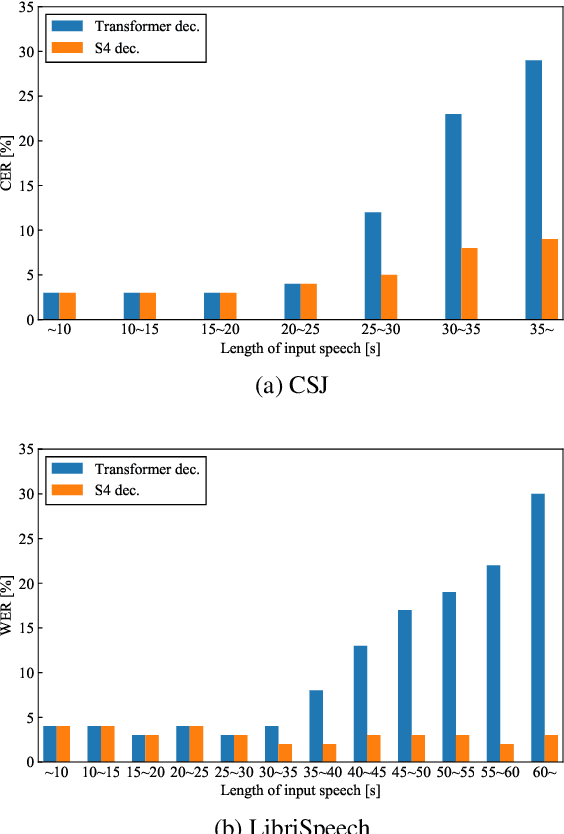
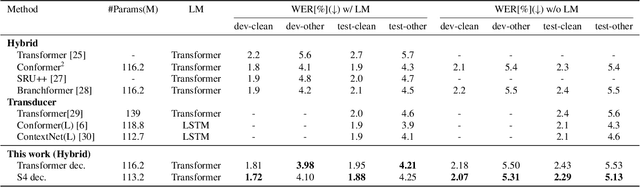
Automatic speech recognition (ASR) systems developed in recent years have shown promising results with self-attention models (e.g., Transformer and Conformer), which are replacing conventional recurrent neural networks. Meanwhile, a structured state space model (S4) has been recently proposed, producing promising results for various long-sequence modeling tasks, including raw speech classification. The S4 model can be trained in parallel, same as the Transformer model. In this study, we applied S4 as a decoder for ASR and text-to-speech (TTS) tasks by comparing it with the Transformer decoder. For the ASR task, our experimental results demonstrate that the proposed model achieves a competitive word error rate (WER) of 1.88%/4.25% on LibriSpeech test-clean/test-other set and a character error rate (CER) of 3.80%/2.63%/2.98% on the CSJ eval1/eval2/eval3 set. Furthermore, the proposed model is more robust than the standard Transformer model, particularly for long-form speech on both the datasets. For the TTS task, the proposed method outperforms the Transformer baseline.
CASA-ASR: Context-Aware Speaker-Attributed ASR
May 21, 2023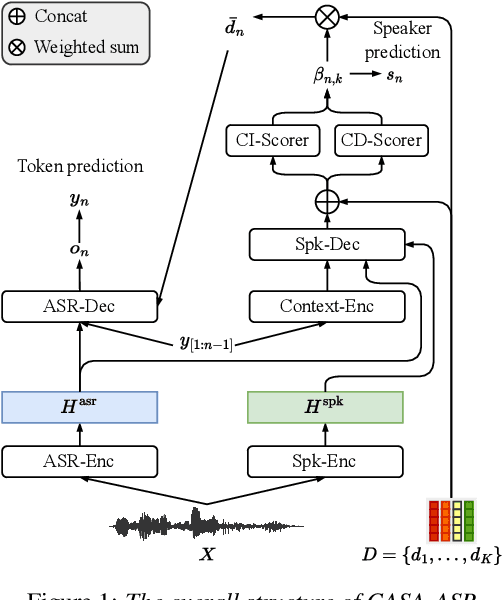
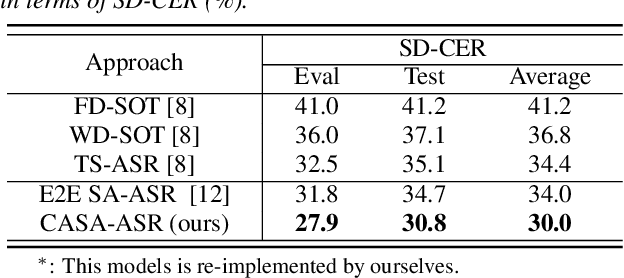
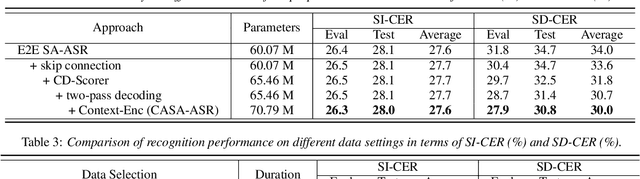
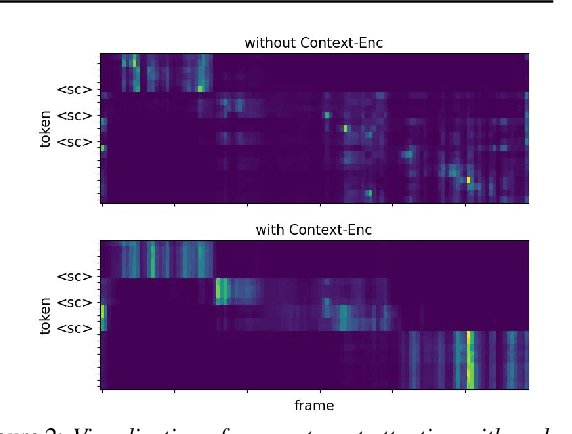
Recently, speaker-attributed automatic speech recognition (SA-ASR) has attracted a wide attention, which aims at answering the question ``who spoke what''. Different from modular systems, end-to-end (E2E) SA-ASR minimizes the speaker-dependent recognition errors directly and shows a promising applicability. In this paper, we propose a context-aware SA-ASR (CASA-ASR) model by enhancing the contextual modeling ability of E2E SA-ASR. Specifically, in CASA-ASR, a contextual text encoder is involved to aggregate the semantic information of the whole utterance, and a context-dependent scorer is employed to model the speaker discriminability by contrasting with speakers in the context. In addition, a two-pass decoding strategy is further proposed to fully leverage the contextual modeling ability resulting in a better recognition performance. Experimental results on AliMeeting corpus show that the proposed CASA-ASR model outperforms the original E2E SA-ASR system with a relative improvement of 11.76% in terms of speaker-dependent character error rate.