 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Betray Oneself: A Novel Audio DeepFake Detection Model via Mono-to-Stereo Conversion
May 25, 2023
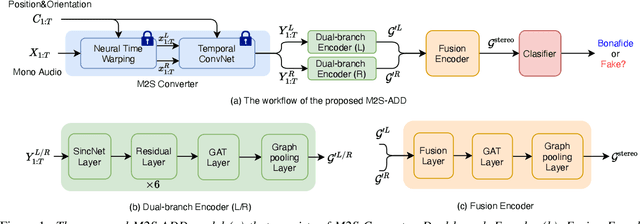
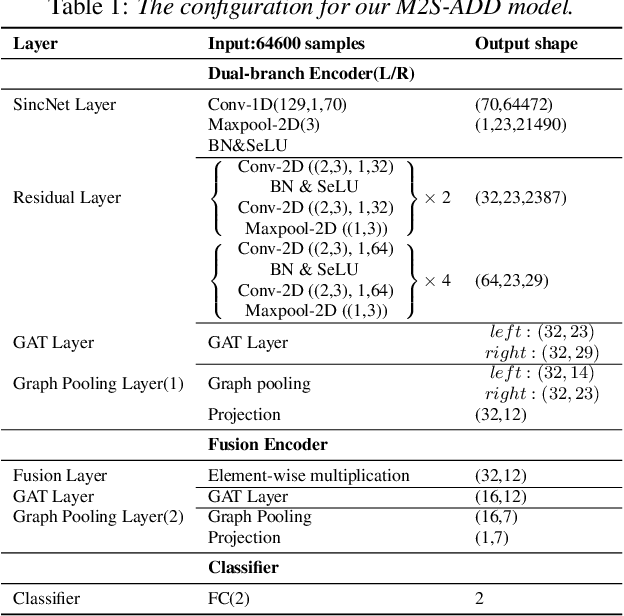
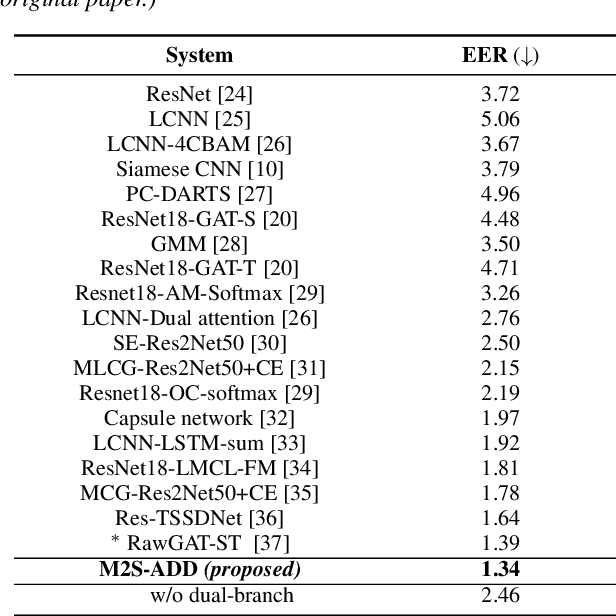
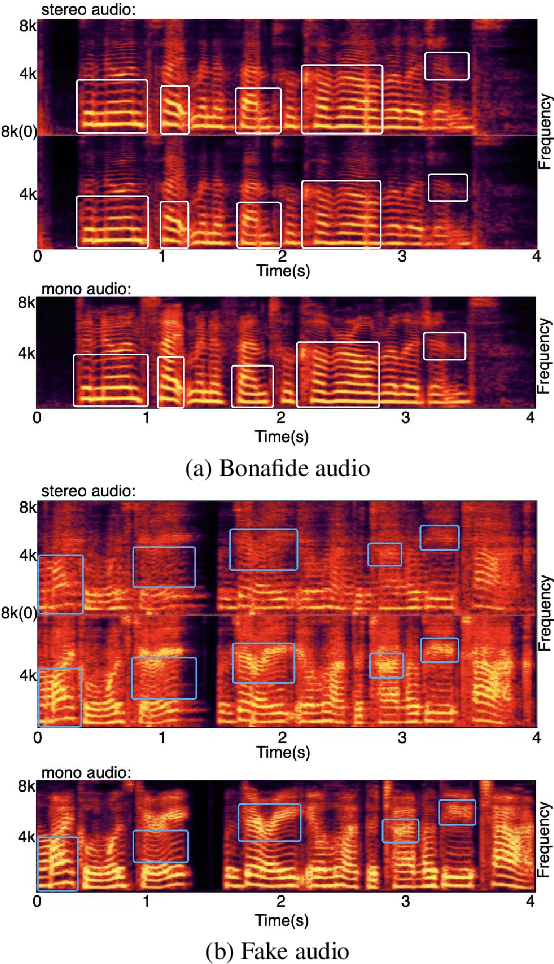
Audio Deepfake Detection (ADD) aims to detect the fake audio generated by text-to-speech (TTS), voice conversion (VC) and replay, etc., which is an emerging topic. Traditionally we take the mono signal as input and focus on robust feature extraction and effective classifier design. However, the dual-channel stereo information in the audio signal also includes important cues for deepfake, which has not been studied in the prior work. In this paper, we propose a novel ADD model, termed as M2S-ADD, that attempts to discover audio authenticity cues during the mono-to-stereo conversion process. We first projects the mono to a stereo signal using a pretrained stereo synthesizer, then employs a dual-branch neural architecture to process the left and right channel signals, respectively. In this way, we effectively reveal the artifacts in the fake audio, thus improve the ADD performance. The experiments on the ASVspoof2019 database show that M2S-ADD outperforms all baselines that input mono. We release the source code at \url{https://github.com/AI-S2-Lab/M2S-ADD}.
Resource-Efficient Fine-Tuning Strategies for Automatic MOS Prediction in Text-to-Speech for Low-Resource Languages
May 30, 2023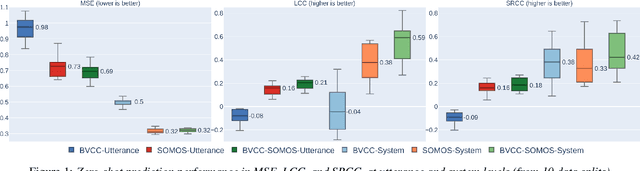

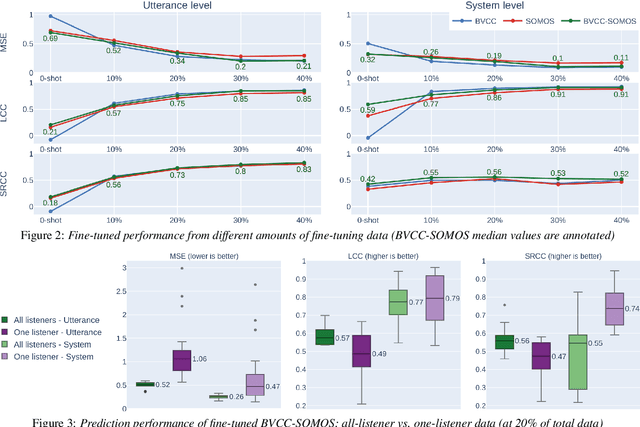
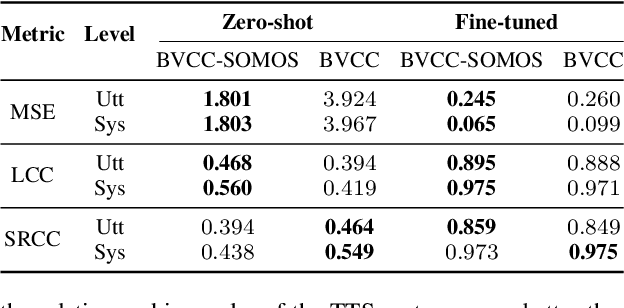
We train a MOS prediction model based on wav2vec 2.0 using the open-access data sets BVCC and SOMOS. Our test with neural TTS data in the low-resource language (LRL) West Frisian shows that pre-training on BVCC before fine-tuning on SOMOS leads to the best accuracy for both fine-tuned and zero-shot prediction. Further fine-tuning experiments show that using more than 30 percent of the total data does not lead to significant improvements. In addition, fine-tuning with data from a single listener shows promising system-level accuracy, supporting the viability of one-participant pilot tests. These findings can all assist the resource-conscious development of TTS for LRLs by progressing towards better zero-shot MOS prediction and informing the design of listening tests, especially in early-stage evaluation.
McNet: Fuse Multiple Cues for Multichannel Speech Enhancement
Nov 16, 2022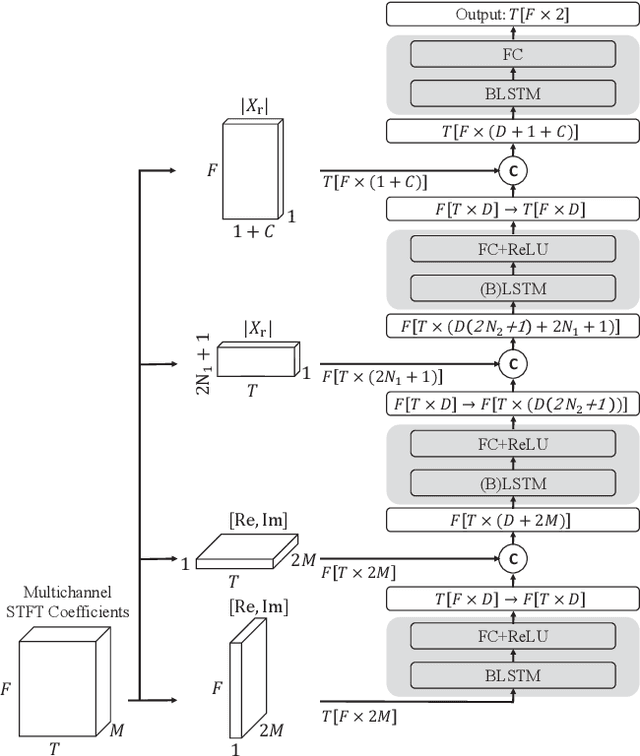
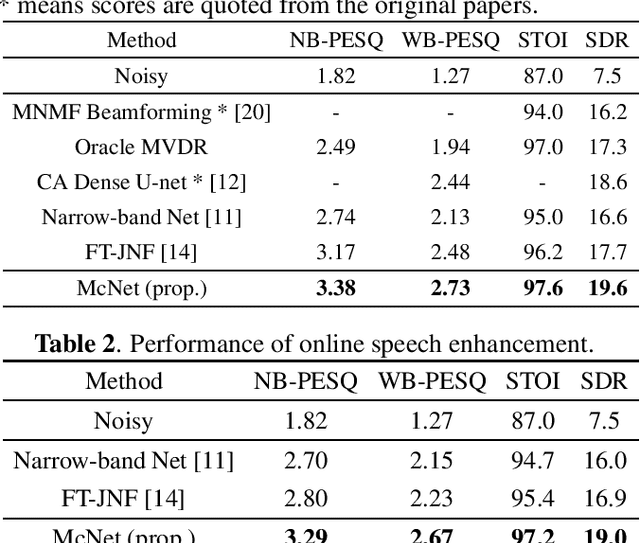
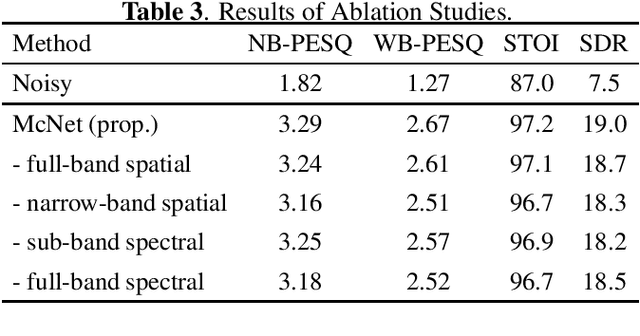
In multichannel speech enhancement, both spectral and spatial information are vital for discriminating between speech and noise. How to fully exploit these two types of information and their temporal dynamics remains an interesting research problem. As a solution to this problem, this paper proposes a multi-cue fusion network named McNet, which cascades four modules to respectively exploit the full-band spatial, narrow-band spatial, sub-band spectral, and full-band spectral information. Experiments show that each module in the proposed network has its unique contribution and, as a whole, notably outperforms other state-of-the-art methods.
Seeing Seeds Beyond Weeds: Green Teaming Generative AI for Beneficial Uses
May 30, 2023
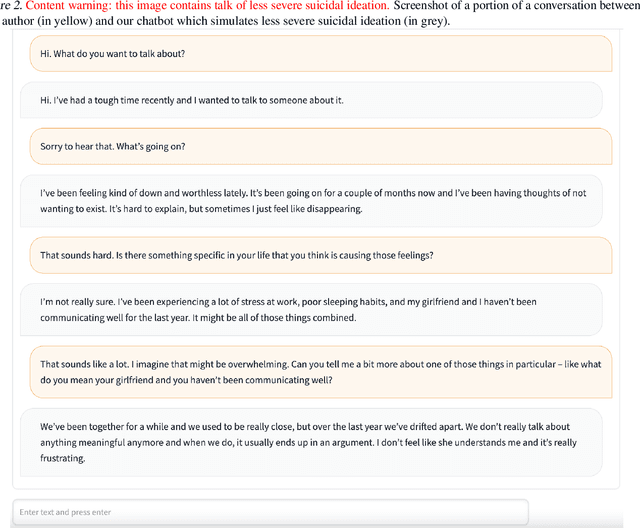
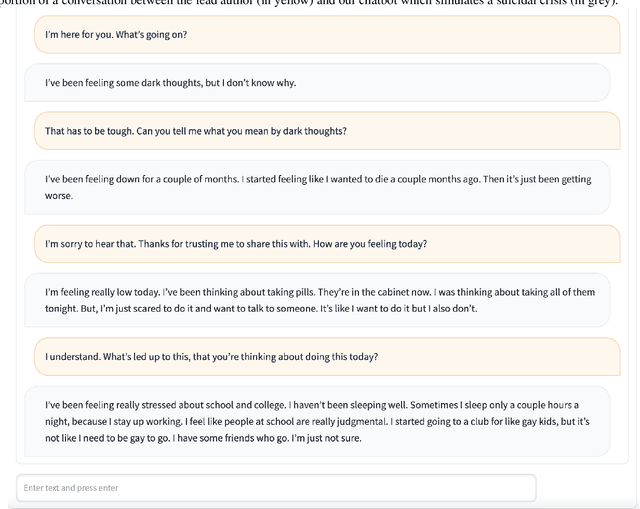
Large generative AI models (GMs) like GPT and DALL-E are trained to generate content for general, wide-ranging purposes. GM content filters are generalized to filter out content which has a risk of harm in many cases, e.g., hate speech. However, prohibited content is not always harmful -- there are instances where generating prohibited content can be beneficial. So, when GMs filter out content, they preclude beneficial use cases along with harmful ones. Which use cases are precluded reflects the values embedded in GM content filtering. Recent work on red teaming proposes methods to bypass GM content filters to generate harmful content. We coin the term green teaming to describe methods of bypassing GM content filters to design for beneficial use cases. We showcase green teaming by: 1) Using ChatGPT as a virtual patient to simulate a person experiencing suicidal ideation, for suicide support training; 2) Using Codex to intentionally generate buggy solutions to train students on debugging; and 3) Examining an Instagram page using Midjourney to generate images of anti-LGBTQ+ politicians in drag. Finally, we discuss how our use cases demonstrate green teaming as both a practical design method and a mode of critique, which problematizes and subverts current understandings of harms and values in generative AI.
Graph Neural Networks for Contextual ASR with the Tree-Constrained Pointer Generator
May 30, 2023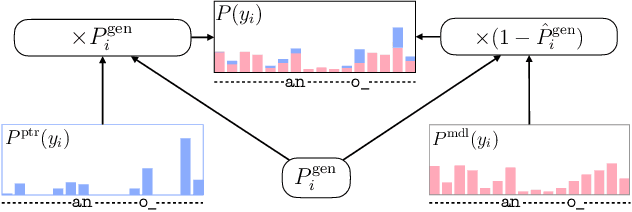
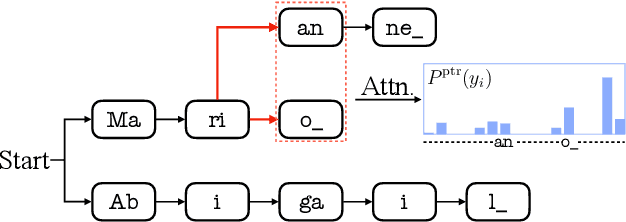

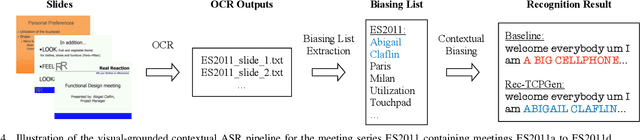
The incorporation of biasing words obtained through contextual knowledge is of paramount importance in automatic speech recognition (ASR) applications. This paper proposes an innovative method for achieving end-to-end contextual ASR using graph neural network (GNN) encodings based on the tree-constrained pointer generator method. GNN node encodings facilitate lookahead for future word pieces in the process of ASR decoding at each tree node by incorporating information about all word pieces on the tree branches rooted from it. This results in a more precise prediction of the generation probability of the biasing words. The study explores three GNN encoding techniques, namely tree recursive neural networks, graph convolutional network (GCN), and GraphSAGE, along with different combinations of the complementary GCN and GraphSAGE structures. The performance of the systems was evaluated using the Librispeech and AMI corpus, following the visual-grounded contextual ASR pipeline. The findings indicate that using GNN encodings achieved consistent and significant reductions in word error rate (WER), particularly for words that are rare or have not been seen during the training process. Notably, the most effective combination of GNN encodings obtained more than 60% WER reduction for rare and unseen words compared to standard end-to-end systems.
Fake News and Hate Speech: Language in Common
Dec 05, 2022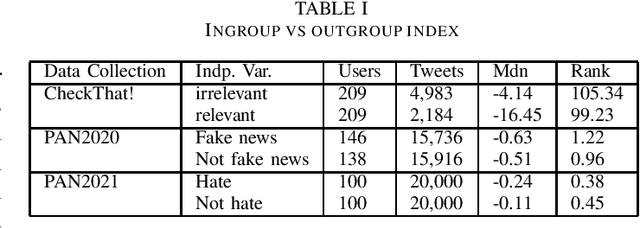
In this paper we raise the research question of whether fake news and hate speech spreaders share common patterns in language. We compute a novel index, the ingroup vs outgroup index, in three different datasets and we show that both phenomena share an "us vs them" narrative.
StoRM: A Diffusion-based Stochastic Regeneration Model for Speech Enhancement and Dereverberation
Dec 22, 2022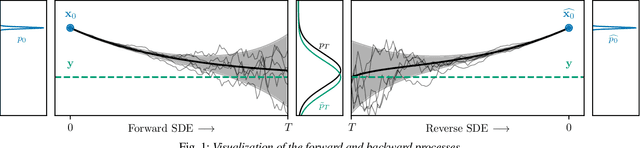
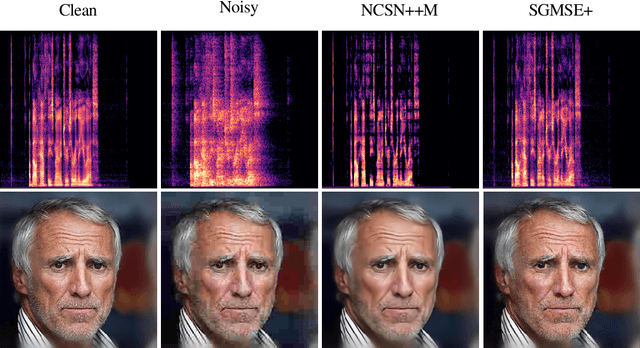
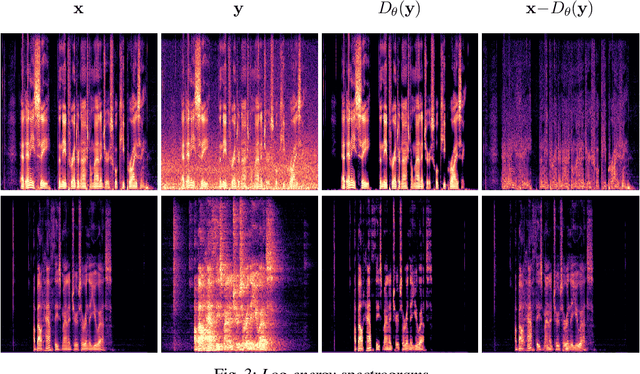

Diffusion models have shown a great ability at bridging the performance gap between predictive and generative approaches for speech enhancement. We have shown that they may even outperform their predictive counterparts for non-additive corruption types or when they are evaluated on mismatched conditions. However, diffusion models suffer from a high computational burden, mainly as they require to run a neural network for each reverse diffusion step, whereas predictive approaches only require one pass. As diffusion models are generative approaches they may also produce vocalizing and breathing artifacts in adverse conditions. In comparison, in such difficult scenarios, predictive models typically do not produce such artifacts but tend to distort the target speech instead, thereby degrading the speech quality. In this work, we present a stochastic regeneration approach where an estimate given by a predictive model is provided as a guide for further diffusion. We show that the proposed approach uses the predictive model to remove the vocalizing and breathing artifacts while producing very high quality samples thanks to the diffusion model, even in adverse conditions. We further show that this approach enables to use lighter sampling schemes with fewer diffusion steps without sacrificing quality, thus lifting the computational burden by an order of magnitude. Source code and audio examples are available online (https://uhh.de/inf-sp-storm).
ArzEn-ST: A Three-way Speech Translation Corpus for Code-Switched Egyptian Arabic - English
Nov 22, 2022
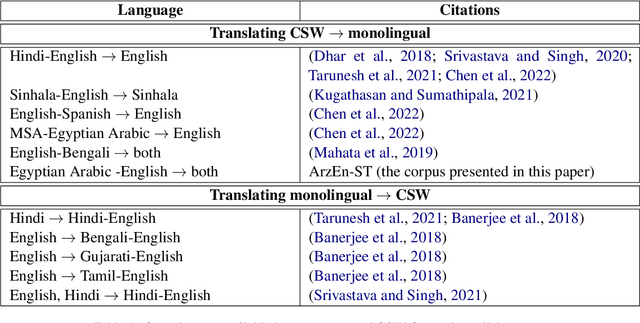

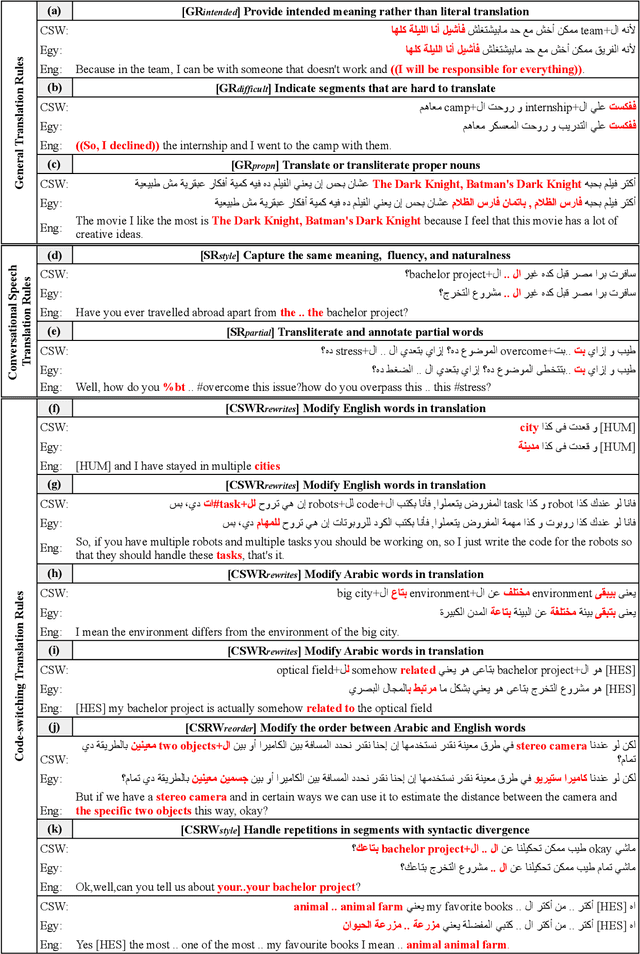
We present our work on collecting ArzEn-ST, a code-switched Egyptian Arabic - English Speech Translation Corpus. This corpus is an extension of the ArzEn speech corpus, which was collected through informal interviews with bilingual speakers. In this work, we collect translations in both directions, monolingual Egyptian Arabic and monolingual English, forming a three-way speech translation corpus. We make the translation guidelines and corpus publicly available. We also report results for baseline systems for machine translation and speech translation tasks. We believe this is a valuable resource that can motivate and facilitate further research studying the code-switching phenomenon from a linguistic perspective and can be used to train and evaluate NLP systems.
Fast and small footprint Hybrid HMM-HiFiGAN based system for speech synthesis in Indian languages
Feb 13, 2023

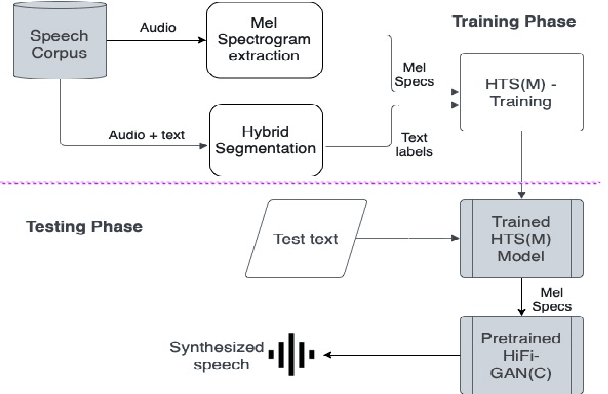
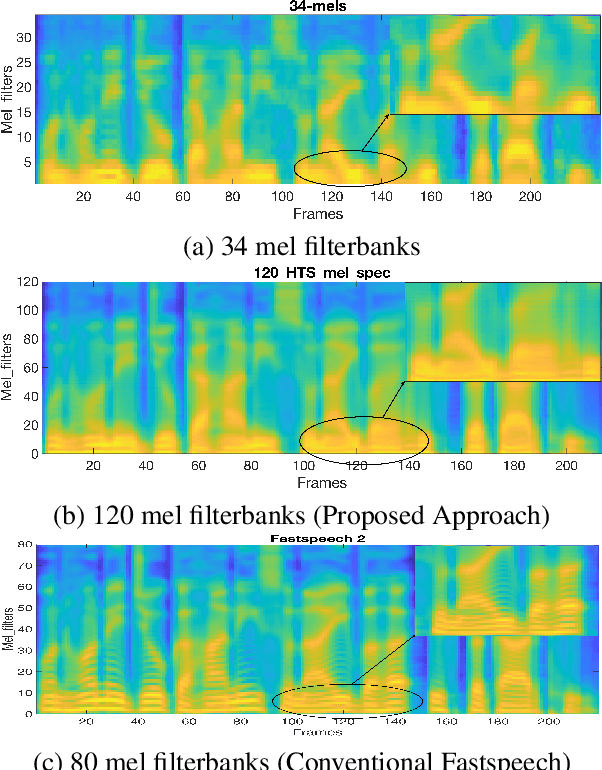
Hidden-Markov-model (HMM) based text-to-speech (HTS) offers flexibility in speaking styles along with fast training and synthesis while being computationally less intense. HTS performs well even in low-resource scenarios. The primary drawback is that the voice quality is poor compared to that of E2E systems. A hybrid approach combining HMM-based feature generation and neural-network-based HiFi-GAN vocoder to improve HTS synthesis quality is proposed. HTS is trained on high-resolution mel-spectrograms instead of conventional mel generalized coefficients (MGC), and the output mel-spectrogram corresponding to the input text is used in a HiFi-GAN vocoder trained on Indic languages, to produce naturalness that is equivalent to that of E2E systems, as evidenced from the DMOS and PC tests.
Analysis of impact of emotions on target speech extraction and speech separation
Aug 15, 2022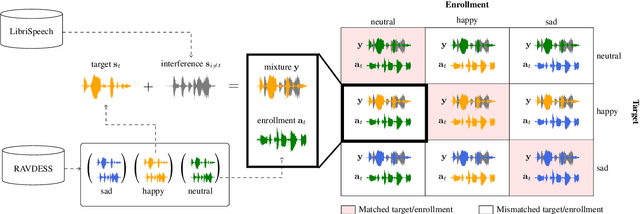
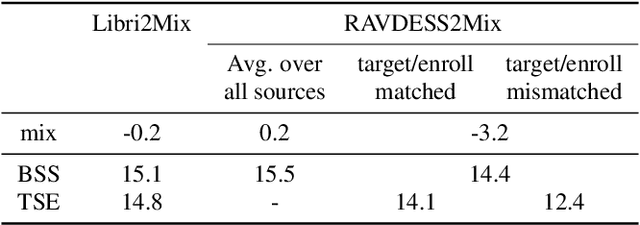
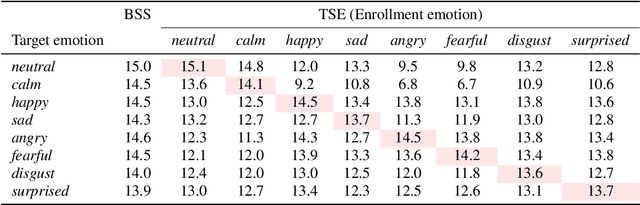
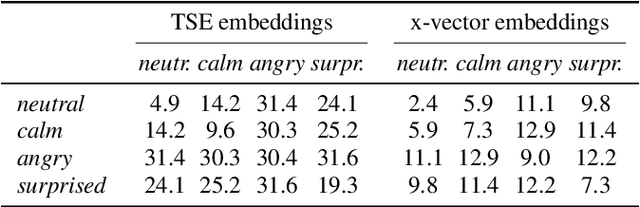
Recently, the performance of blind speech separation (BSS) and target speech extraction (TSE) has greatly progressed. Most works, however, focus on relatively well-controlled conditions using, e.g., read speech. The performance may degrade in more realistic situations. One of the factors causing such degradation may be intrinsic speaker variability, such as emotions, occurring commonly in realistic speech. In this paper, we investigate the influence of emotions on TSE and BSS. We create a new test dataset of emotional mixtures for the evaluation of TSE and BSS. This dataset combines LibriSpeech and Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS). Through controlled experiments, we can analyze the impact of different emotions on the performance of BSS and TSE. We observe that BSS is relatively robust to emotions, while TSE, which requires identifying and extracting the speech of a target speaker, is much more sensitive to emotions. On comparative speaker verification experiments we show that identifying the target speaker may be particularly challenging when dealing with emotional speech. Using our findings, we outline potential future directions that could improve the robustness of BSS and TSE systems toward emotional speech.