 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
When LLMs Meets Acoustic Landmarks: An Efficient Approach to Integrate Speech into Large Language Models for Depression Detection
Feb 17, 2024
Depression is a critical concern in global mental health, prompting extensive research into AI-based detection methods. Among various AI technologies, Large Language Models (LLMs) stand out for their versatility in mental healthcare applications. However, their primary limitation arises from their exclusive dependence on textual input, which constrains their overall capabilities. Furthermore, the utilization of LLMs in identifying and analyzing depressive states is still relatively untapped. In this paper, we present an innovative approach to integrating acoustic speech information into the LLMs framework for multimodal depression detection. We investigate an efficient method for depression detection by integrating speech signals into LLMs utilizing Acoustic Landmarks. By incorporating acoustic landmarks, which are specific to the pronunciation of spoken words, our method adds critical dimensions to text transcripts. This integration also provides insights into the unique speech patterns of individuals, revealing the potential mental states of individuals. Evaluations of the proposed approach on the DAIC-WOZ dataset reveal state-of-the-art results when compared with existing Audio-Text baselines. In addition, this approach is not only valuable for the detection of depression but also represents a new perspective in enhancing the ability of LLMs to comprehend and process speech signals.
TweetInfo: An Interactive System to Mitigate Online Harm
Mar 03, 2024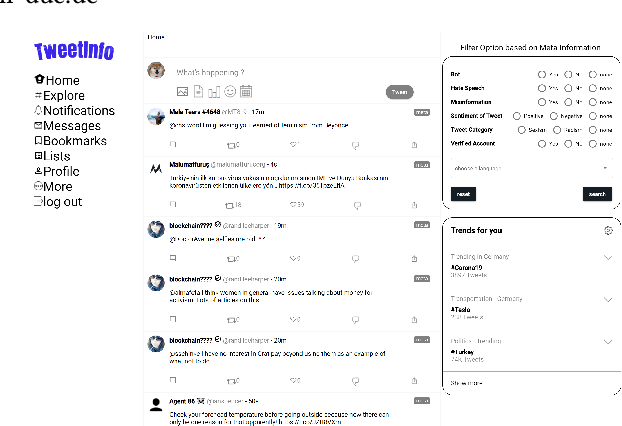

The increase in active users on social networking sites (SNSs) has also observed an increase in harmful content on social media sites. Harmful content is described as an inappropriate activity to harm or deceive an individual or a group of users. Alongside existing methods to detect misinformation and hate speech, users still need to be well-informed about the harmfulness of the content on SNSs. This study proposes a user-interactive system TweetInfo for mitigating the consumption of harmful content by providing metainformation about the posts. It focuses on two types of harmful content: hate speech and misinformation. TweetInfo provides insights into tweets by doing content analysis. Based on previous research, we have selected a list of metainformation. We offer the option to filter content based on metainformation Bot, Hate Speech, Misinformation, Verified Account, Sentiment, Tweet Category, Language. The proposed user interface allows customising the user's timeline to mitigate harmful content. This study present the demo version of the propose user interface of TweetInfo.
Syllable based DNN-HMM Cantonese Speech to Text System
Feb 13, 2024This paper reports our work on building up a Cantonese Speech-to-Text (STT) system with a syllable based acoustic model. This is a part of an effort in building a STT system to aid dyslexic students who have cognitive deficiency in writing skills but have no problem expressing their ideas through speech. For Cantonese speech recognition, the basic unit of acoustic models can either be the conventional Initial-Final (IF) syllables, or the Onset-Nucleus-Coda (ONC) syllables where finals are further split into nucleus and coda to reflect the intra-syllable variations in Cantonese. By using the Kaldi toolkit, our system is trained using the stochastic gradient descent optimization model with the aid of GPUs for the hybrid Deep Neural Network and Hidden Markov Model (DNN-HMM) with and without I-vector based speaker adaptive training technique. The input features of the same Gaussian Mixture Model with speaker adaptive training (GMM-SAT) to DNN are used in all cases. Experiments show that the ONC-based syllable acoustic modeling with I-vector based DNN-HMM achieves the best performance with the word error rate (WER) of 9.66% and the real time factor (RTF) of 1.38812.
Automatic design optimization of preference-based subjective evaluation with online learning in crowdsourcing environment
Mar 10, 2024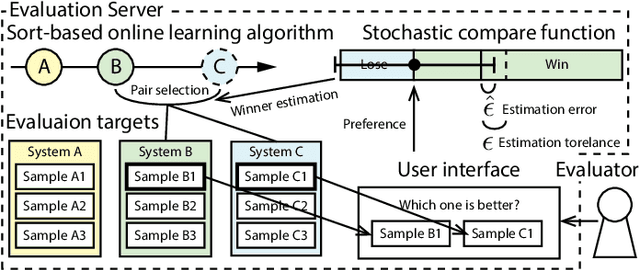
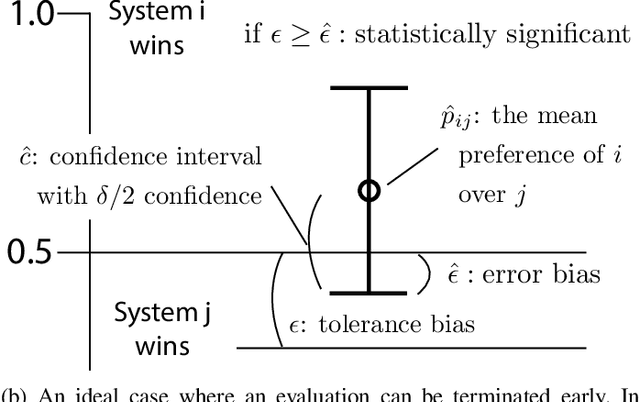
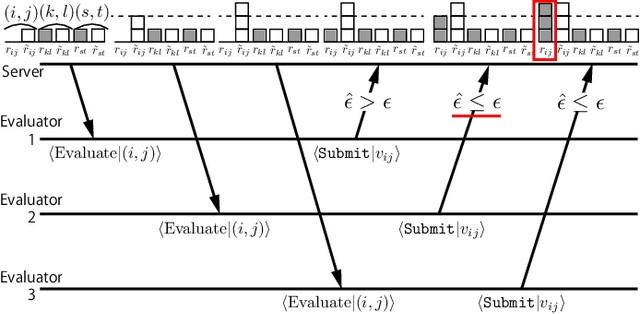

A preference-based subjective evaluation is a key method for evaluating generative media reliably. However, its huge combinations of pairs prohibit it from being applied to large-scale evaluation using crowdsourcing. To address this issue, we propose an automatic optimization method for preference-based subjective evaluation in terms of pair combination selections and allocation of evaluation volumes with online learning in a crowdsourcing environment. We use a preference-based online learning method based on a sorting algorithm to identify the total order of evaluation targets with minimum sample volumes. Our online learning algorithm supports parallel and asynchronous execution under fixed-budget conditions required for crowdsourcing. Our experiment on preference-based subjective evaluation of synthetic speech shows that our method successfully optimizes the test by reducing pair combinations from 351 to 83 and allocating optimal evaluation volumes for each pair ranging from 30 to 663 without compromising evaluation accuracies and wasting budget allocations.
Exploratory Data Analysis on Code-mixed Misogynistic Comments
Mar 09, 2024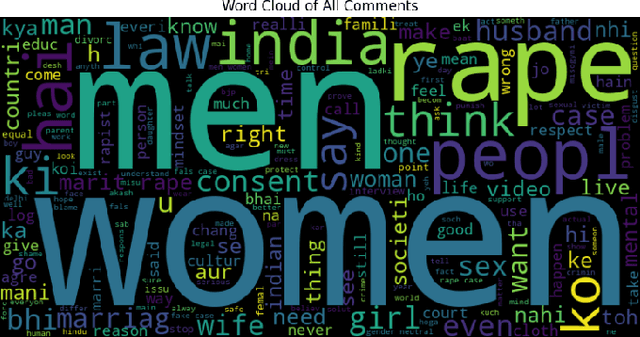
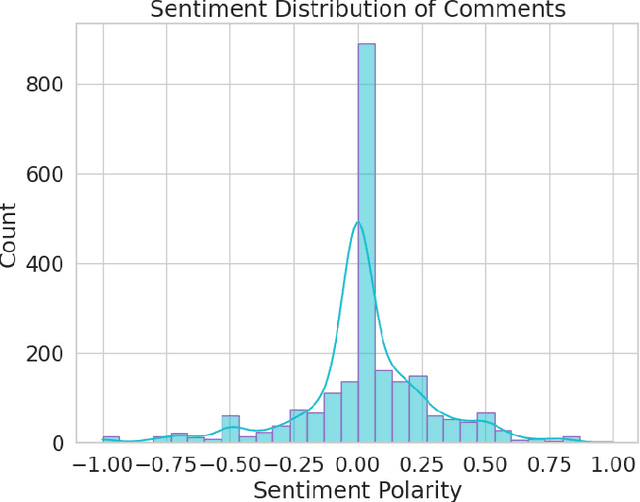
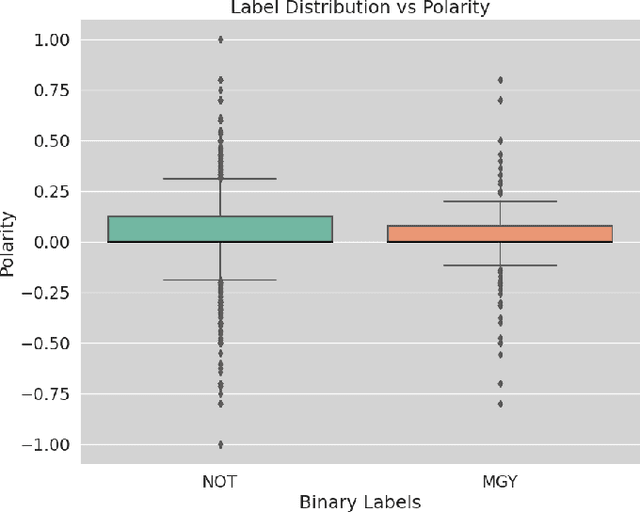
The problems of online hate speech and cyberbullying have significantly worsened since the increase in popularity of social media platforms such as YouTube and Twitter (X). Natural Language Processing (NLP) techniques have proven to provide a great advantage in automatic filtering such toxic content. Women are disproportionately more likely to be victims of online abuse. However, there appears to be a lack of studies that tackle misogyny detection in under-resourced languages. In this short paper, we present a novel dataset of YouTube comments in mix-code Hinglish collected from YouTube videos which have been weak labelled as `Misogynistic' and `Non-misogynistic'. Pre-processing and Exploratory Data Analysis (EDA) techniques have been applied on the dataset to gain insights on its characteristics. The process has provided a better understanding of the dataset through sentiment scores, word clouds, etc.
A Rational Analysis of the Speech-to-Song Illusion
Feb 10, 2024The speech-to-song illusion is a robust psychological phenomenon whereby a spoken sentence sounds increasingly more musical as it is repeated. Despite decades of research, a complete formal account of this transformation is still lacking, and some of its nuanced characteristics, namely, that certain phrases appear to transform while others do not, is not well understood. Here we provide a formal account of this phenomenon, by recasting it as a statistical inference whereby a rational agent attempts to decide whether a sequence of utterances is more likely to have been produced in a song or speech. Using this approach and analyzing song and speech corpora, we further introduce a novel prose-to-lyrics illusion that is purely text-based. In this illusion, simply duplicating written sentences makes them appear more like song lyrics. We provide robust evidence for this new illusion in both human participants and large language models.
BASE TTS: Lessons from building a billion-parameter Text-to-Speech model on 100K hours of data
Feb 12, 2024We introduce a text-to-speech (TTS) model called BASE TTS, which stands for $\textbf{B}$ig $\textbf{A}$daptive $\textbf{S}$treamable TTS with $\textbf{E}$mergent abilities. BASE TTS is the largest TTS model to-date, trained on 100K hours of public domain speech data, achieving a new state-of-the-art in speech naturalness. It deploys a 1-billion-parameter autoregressive Transformer that converts raw texts into discrete codes ("speechcodes") followed by a convolution-based decoder which converts these speechcodes into waveforms in an incremental, streamable manner. Further, our speechcodes are built using a novel speech tokenization technique that features speaker ID disentanglement and compression with byte-pair encoding. Echoing the widely-reported "emergent abilities" of large language models when trained on increasing volume of data, we show that BASE TTS variants built with 10K+ hours and 500M+ parameters begin to demonstrate natural prosody on textually complex sentences. We design and share a specialized dataset to measure these emergent abilities for text-to-speech. We showcase state-of-the-art naturalness of BASE TTS by evaluating against baselines that include publicly available large-scale text-to-speech systems: YourTTS, Bark and TortoiseTTS. Audio samples generated by the model can be heard at https://amazon-ltts-paper.com/.
Efficient Post-Training Augmentation for Adaptive Inference in Heterogeneous and Distributed IoT Environments
Mar 12, 2024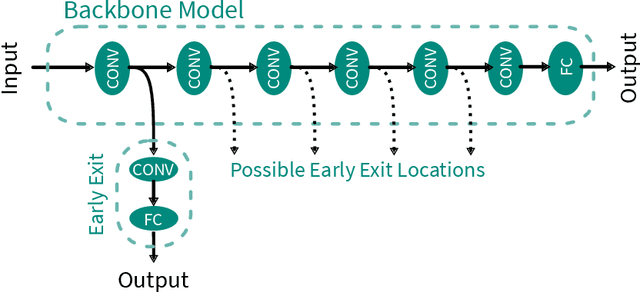
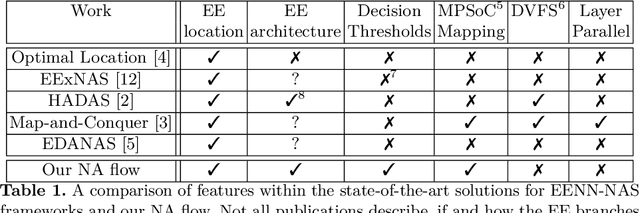
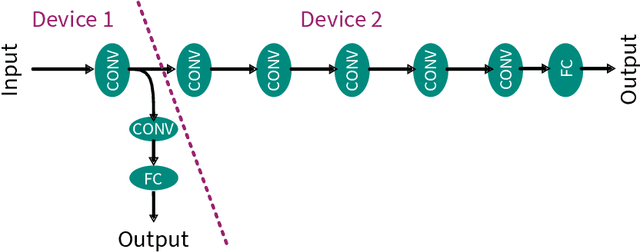
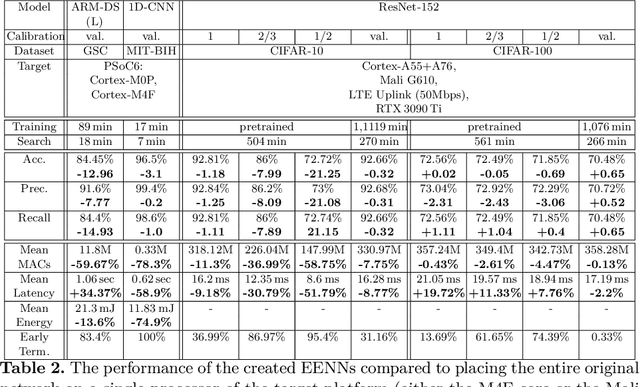
Early Exit Neural Networks (EENNs) present a solution to enhance the efficiency of neural network deployments. However, creating EENNs is challenging and requires specialized domain knowledge, due to the large amount of additional design choices. To address this issue, we propose an automated augmentation flow that focuses on converting an existing model into an EENN. It performs all required design decisions for the deployment to heterogeneous or distributed hardware targets: Our framework constructs the EENN architecture, maps its subgraphs to the hardware targets, and configures its decision mechanism. To the best of our knowledge, it is the first framework that is able to perform all of these steps. We evaluated our approach on a collection of Internet-of-Things and standard image classification use cases. For a speech command detection task, our solution was able to reduce the mean operations per inference by 59.67%. For an ECG classification task, it was able to terminate all samples early, reducing the mean inference energy by 74.9% and computations by 78.3%. On CIFAR-10, our solution was able to achieve up to a 58.75% reduction in computations. The search on a ResNet-152 base model for CIFAR-10 took less than nine hours on a laptop CPU. Our proposed approach enables the creation of EENN optimized for IoT environments and can reduce the inference cost of Deep Learning applications on embedded and fog platforms, while also significantly reducing the search cost - making it more accessible for scientists and engineers in industry and research. The low search cost improves the accessibility of EENNs, with the potential to improve the efficiency of neural networks in a wide range of practical applications.
Making Flow-Matching-Based Zero-Shot Text-to-Speech Laugh as You Like
Feb 12, 2024Laughter is one of the most expressive and natural aspects of human speech, conveying emotions, social cues, and humor. However, most text-to-speech (TTS) systems lack the ability to produce realistic and appropriate laughter sounds, limiting their applications and user experience. While there have been prior works to generate natural laughter, they fell short in terms of controlling the timing and variety of the laughter to be generated. In this work, we propose ELaTE, a zero-shot TTS that can generate natural laughing speech of any speaker based on a short audio prompt with precise control of laughter timing and expression. Specifically, ELaTE works on the audio prompt to mimic the voice characteristic, the text prompt to indicate the contents of the generated speech, and the input to control the laughter expression, which can be either the start and end times of laughter, or the additional audio prompt that contains laughter to be mimicked. We develop our model based on the foundation of conditional flow-matching-based zero-shot TTS, and fine-tune it with frame-level representation from a laughter detector as additional conditioning. With a simple scheme to mix small-scale laughter-conditioned data with large-scale pre-training data, we demonstrate that a pre-trained zero-shot TTS model can be readily fine-tuned to generate natural laughter with precise controllability, without losing any quality of the pre-trained zero-shot TTS model. Through the evaluations, we show that ELaTE can generate laughing speech with significantly higher quality and controllability compared to conventional models. See https://aka.ms/elate/ for demo samples.
VLSP 2023 -- LTER: A Summary of the Challenge on Legal Textual Entailment Recognition
Mar 06, 2024
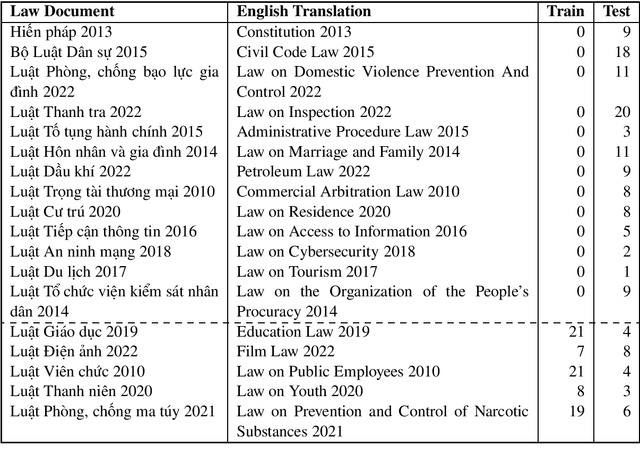


In this new era of rapid AI development, especially in language processing, the demand for AI in the legal domain is increasingly critical. In the context where research in other languages such as English, Japanese, and Chinese has been well-established, we introduce the first fundamental research for the Vietnamese language in the legal domain: legal textual entailment recognition through the Vietnamese Language and Speech Processing workshop. In analyzing participants' results, we discuss certain linguistic aspects critical in the legal domain that pose challenges that need to be addressed.