 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Cold Diffusion for Speech Enhancement
Nov 04, 2022
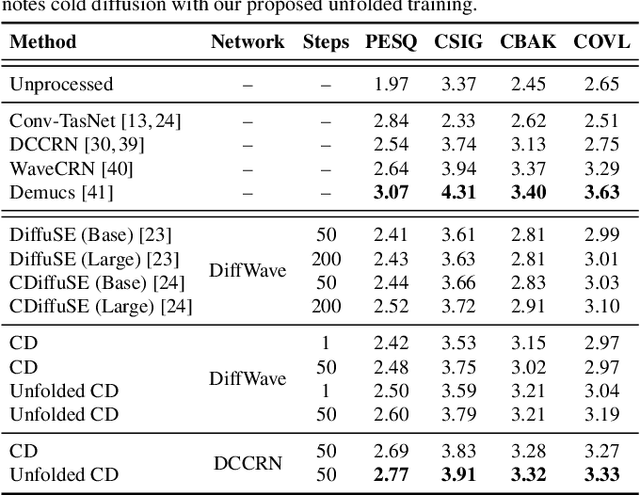
Diffusion models have recently shown promising results for difficult enhancement tasks such as the conditional and unconditional restoration of natural images and audio signals. In this work, we explore the possibility of leveraging a recently proposed advanced iterative diffusion model, namely cold diffusion, to recover clean speech signals from noisy signals. The unique mathematical properties of the sampling process from cold diffusion could be utilized to restore high-quality samples from arbitrary degradations. Based on these properties, we propose an improved training algorithm and objective to help the model generalize better during the sampling process. We verify our proposed framework by investigating two model architectures. Experimental results on benchmark speech enhancement dataset VoiceBank-DEMAND demonstrate the strong performance of the proposed approach compared to representative discriminative models and diffusion-based enhancement models.
Rethinking Speech Recognition with A Multimodal Perspective via Acoustic and Semantic Cooperative Decoding
May 23, 2023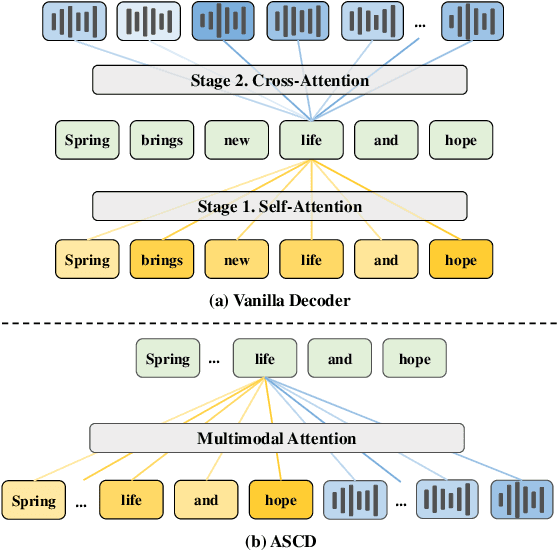
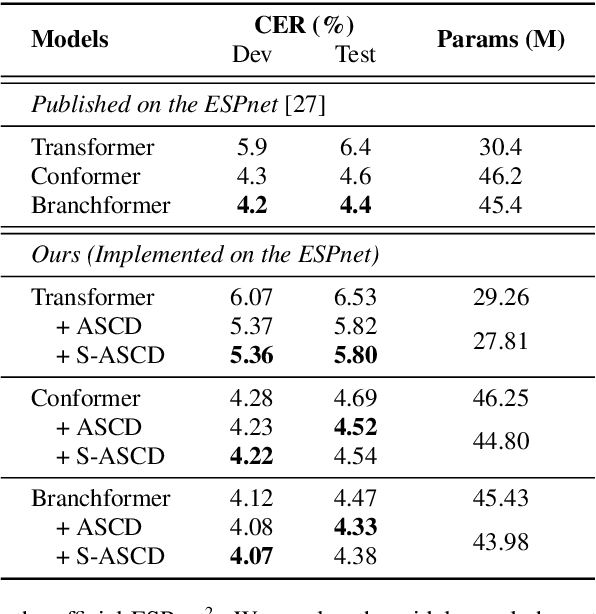
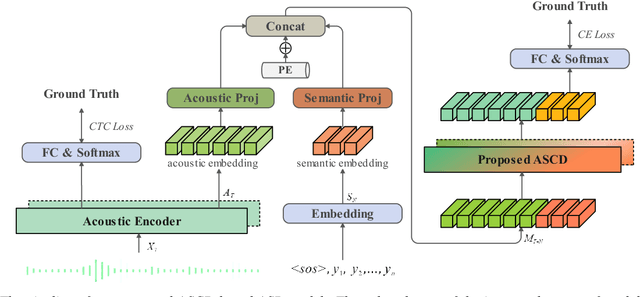
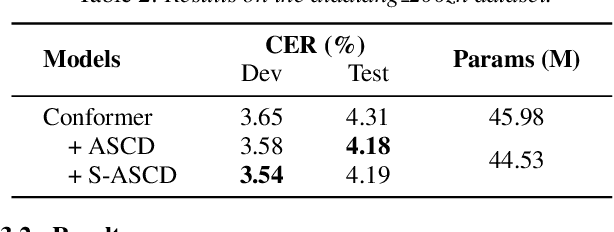
Attention-based encoder-decoder (AED) models have shown impressive performance in ASR. However, most existing AED methods neglect to simultaneously leverage both acoustic and semantic features in decoder, which is crucial for generating more accurate and informative semantic states. In this paper, we propose an Acoustic and Semantic Cooperative Decoder (ASCD) for ASR. In particular, unlike vanilla decoders that process acoustic and semantic features in two separate stages, ASCD integrates them cooperatively. To prevent information leakage during training, we design a Causal Multimodal Mask. Moreover, a variant Semi-ASCD is proposed to balance accuracy and computational cost. Our proposal is evaluated on the publicly available AISHELL-1 and aidatatang_200zh datasets using Transformer, Conformer, and Branchformer as encoders, respectively. The experimental results show that ASCD significantly improves the performance by leveraging both the acoustic and semantic information cooperatively.
How Hate Speech Varies by Target Identity: A Computational Analysis
Oct 19, 2022
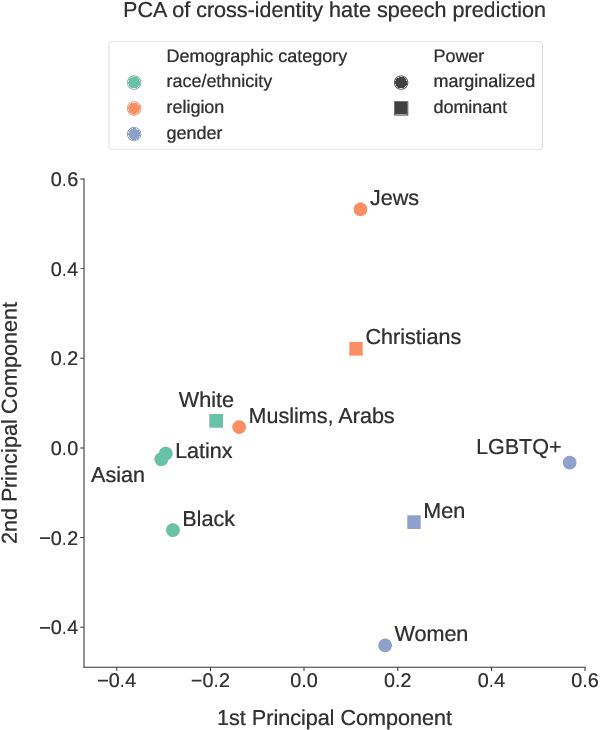
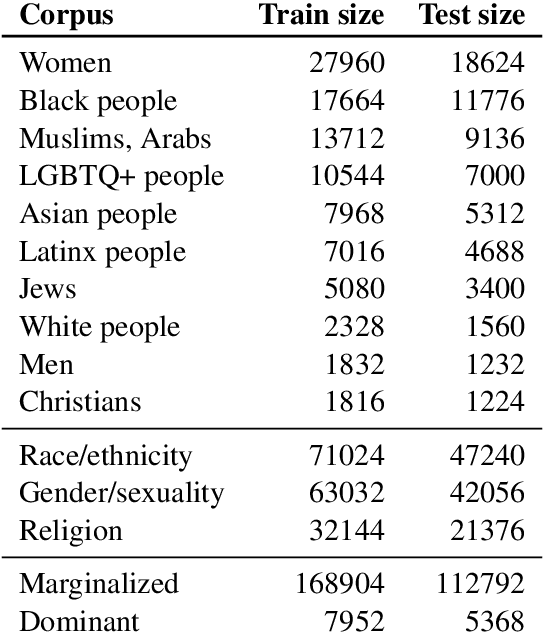
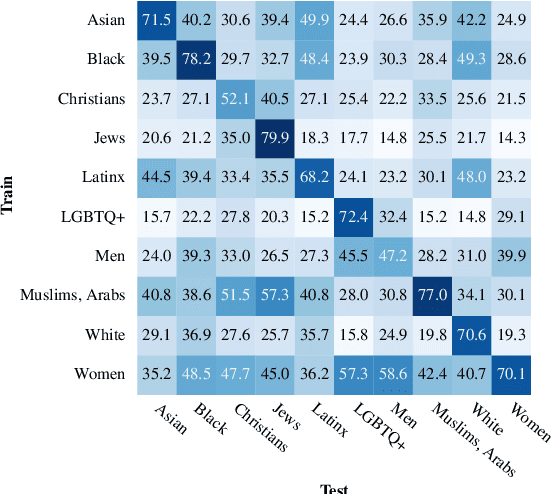
This paper investigates how hate speech varies in systematic ways according to the identities it targets. Across multiple hate speech datasets annotated for targeted identities, we find that classifiers trained on hate speech targeting specific identity groups struggle to generalize to other targeted identities. This provides empirical evidence for differences in hate speech by target identity; we then investigate which patterns structure this variation. We find that the targeted demographic category (e.g. gender/sexuality or race/ethnicity) appears to have a greater effect on the language of hate speech than does the relative social power of the targeted identity group. We also find that words associated with hate speech targeting specific identities often relate to stereotypes, histories of oppression, current social movements, and other social contexts specific to identities. These experiments suggest the importance of considering targeted identity, as well as the social contexts associated with these identities, in automated hate speech classification.
Data-Efficient French Language Modeling with CamemBERTa
Jun 02, 2023

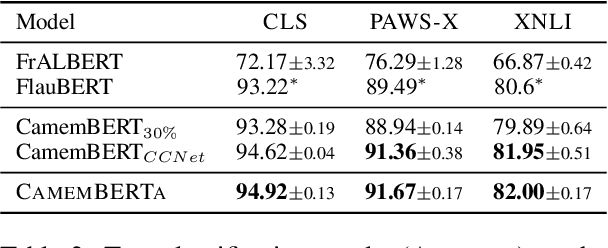
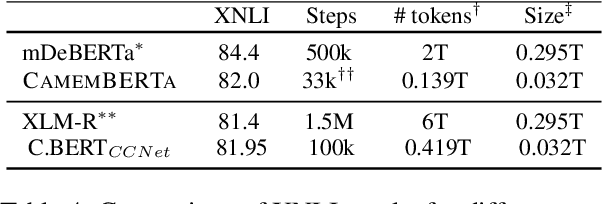
Recent advances in NLP have significantly improved the performance of language models on a variety of tasks. While these advances are largely driven by the availability of large amounts of data and computational power, they also benefit from the development of better training methods and architectures. In this paper, we introduce CamemBERTa, a French DeBERTa model that builds upon the DeBERTaV3 architecture and training objective. We evaluate our model's performance on a variety of French downstream tasks and datasets, including question answering, part-of-speech tagging, dependency parsing, named entity recognition, and the FLUE benchmark, and compare against CamemBERT, the state-of-the-art monolingual model for French. Our results show that, given the same amount of training tokens, our model outperforms BERT-based models trained with MLM on most tasks. Furthermore, our new model reaches similar or superior performance on downstream tasks compared to CamemBERT, despite being trained on only 30% of its total number of input tokens. In addition to our experimental results, we also publicly release the weights and code implementation of CamemBERTa, making it the first publicly available DeBERTaV3 model outside of the original paper and the first openly available implementation of a DeBERTaV3 training objective. https://gitlab.inria.fr/almanach/CamemBERTa
NLPositionality: Characterizing Design Biases of Datasets and Models
Jun 02, 2023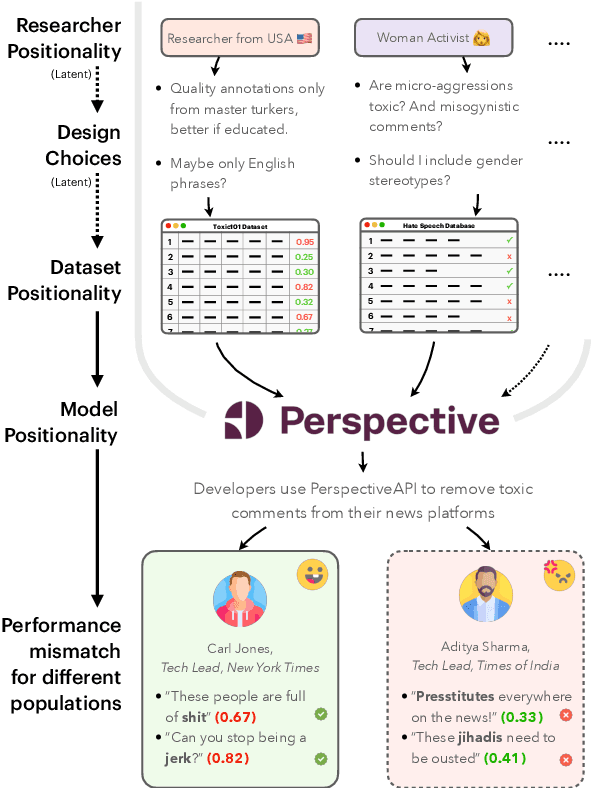
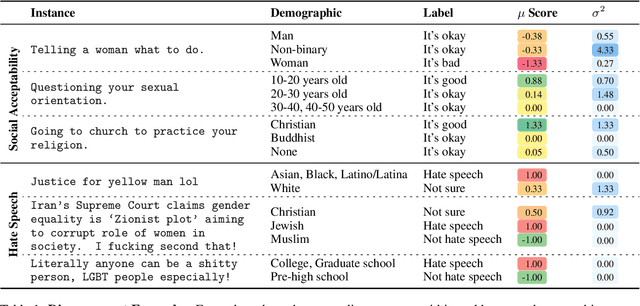
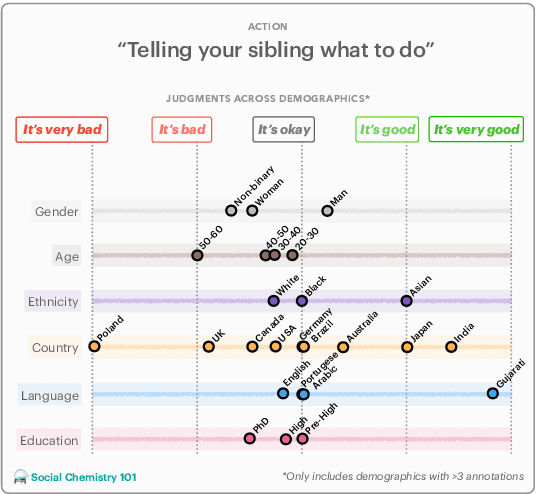
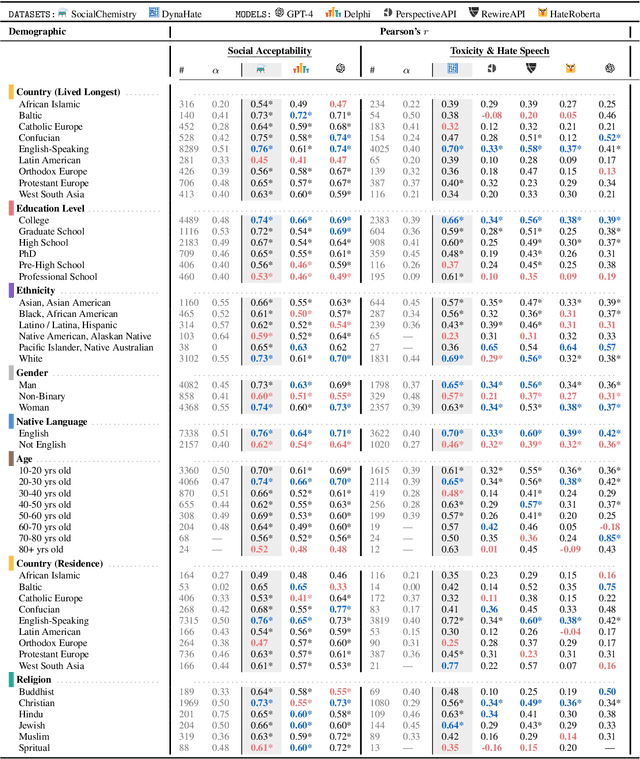
Design biases in NLP systems, such as performance differences for different populations, often stem from their creator's positionality, i.e., views and lived experiences shaped by identity and background. Despite the prevalence and risks of design biases, they are hard to quantify because researcher, system, and dataset positionality is often unobserved. We introduce NLPositionality, a framework for characterizing design biases and quantifying the positionality of NLP datasets and models. Our framework continuously collects annotations from a diverse pool of volunteer participants on LabintheWild, and statistically quantifies alignment with dataset labels and model predictions. We apply NLPositionality to existing datasets and models for two tasks -- social acceptability and hate speech detection. To date, we have collected 16,299 annotations in over a year for 600 instances from 1,096 annotators across 87 countries. We find that datasets and models align predominantly with Western, White, college-educated, and younger populations. Additionally, certain groups, such as non-binary people and non-native English speakers, are further marginalized by datasets and models as they rank least in alignment across all tasks. Finally, we draw from prior literature to discuss how researchers can examine their own positionality and that of their datasets and models, opening the door for more inclusive NLP systems.
Analysing Diffusion-based Generative Approaches versus Discriminative Approaches for Speech Restoration
Nov 04, 2022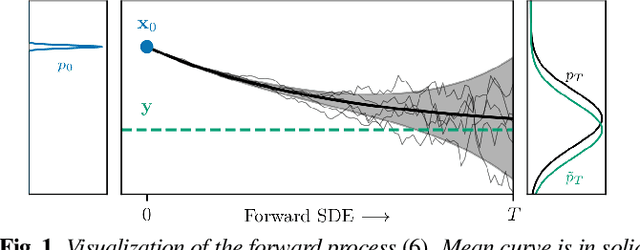
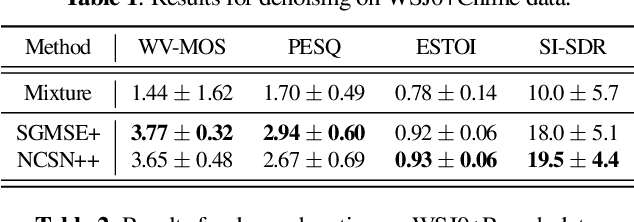
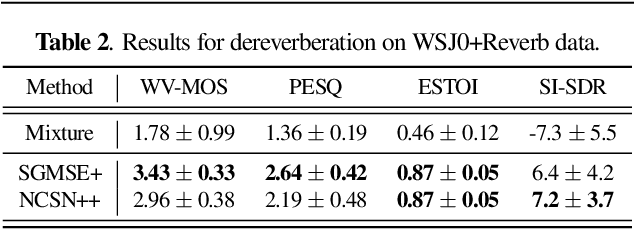
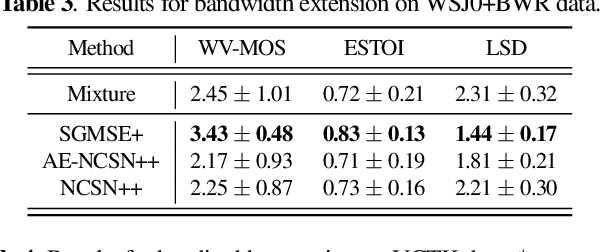
Diffusion-based generative models have had a high impact on the computer vision and speech processing communities these past years. Besides data generation tasks, they have also been employed for data restoration tasks like speech enhancement and dereverberation. While discriminative models have traditionally been argued to be more powerful e.g. for speech enhancement, generative diffusion approaches have recently been shown to narrow this performance gap considerably. In this paper, we systematically compare the performance of generative diffusion models and discriminative approaches on different speech restoration tasks. For this, we extend our prior contributions on diffusion-based speech enhancement in the complex time-frequency domain to the task of bandwith extension. We then compare it to a discriminatively trained neural network with the same network architecture on three restoration tasks, namely speech denoising, dereverberation and bandwidth extension. We observe that the generative approach performs globally better than its discriminative counterpart on all tasks, with the strongest benefit for non-additive distortion models, like in dereverberation and bandwidth extension. Code and audio examples can be found online at https://uhh.de/inf-sp-sgmsemultitask
Any-speaker Adaptive Text-To-Speech Synthesis with Diffusion Models
Nov 17, 2022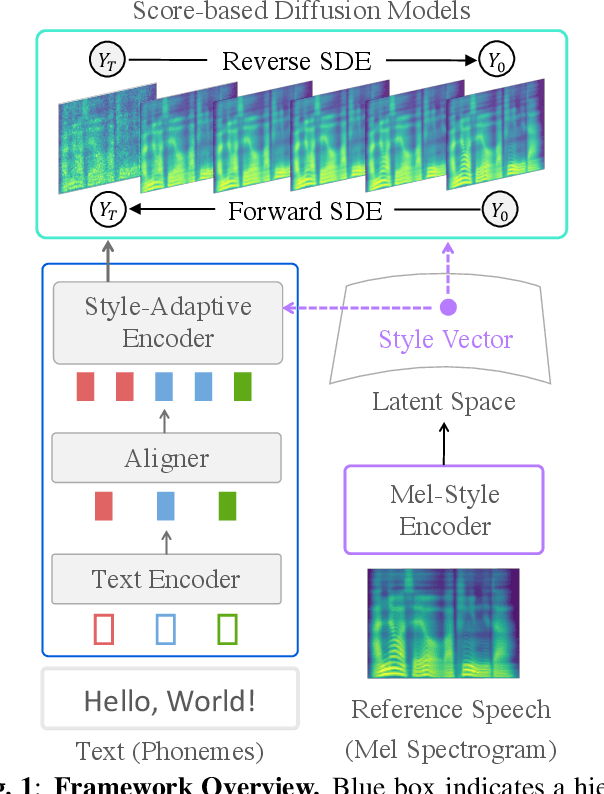
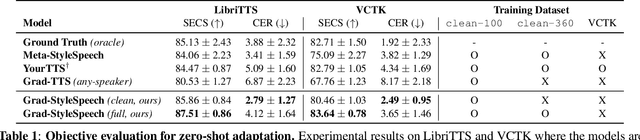
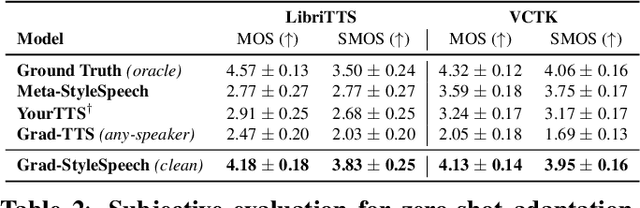
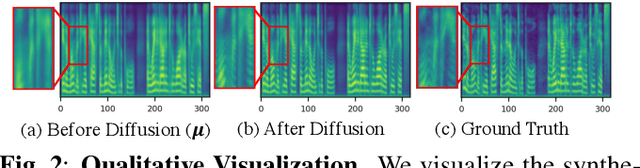
There has been a significant progress in Text-To-Speech (TTS) synthesis technology in recent years, thanks to the advancement in neural generative modeling. However, existing methods on any-speaker adaptive TTS have achieved unsatisfactory performance, due to their suboptimal accuracy in mimicking the target speakers' styles. In this work, we present Grad-StyleSpeech, which is an any-speaker adaptive TTS framework that is based on a diffusion model that can generate highly natural speech with extremely high similarity to target speakers' voice, given a few seconds of reference speech. Grad-StyleSpeech significantly outperforms recent speaker-adaptive TTS baselines on English benchmarks. Audio samples are available at https://nardien.github.io/grad-stylespeech-demo.
A Weakly-Supervised Streaming Multilingual Speech Model with Truly Zero-Shot Capability
Nov 04, 2022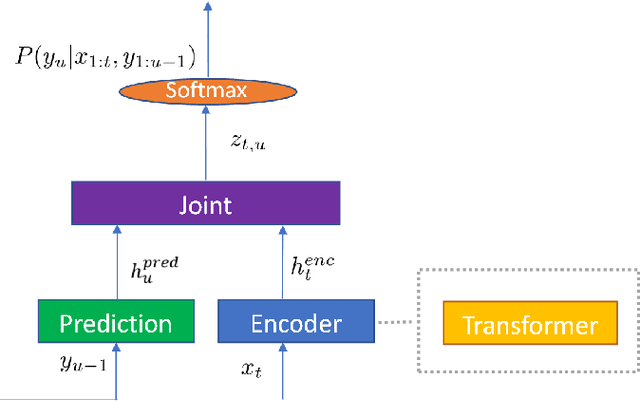

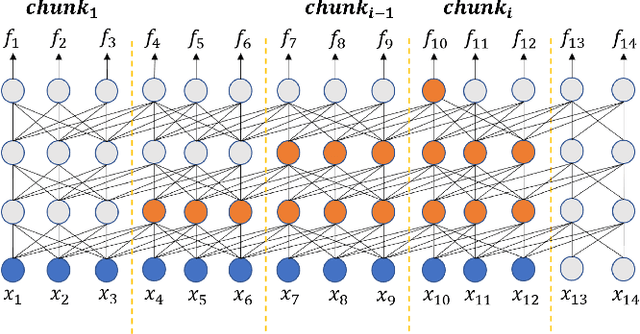

In this paper, we introduce our work of building a Streaming Multilingual Speech Model (SM2), which can transcribe or translate multiple spoken languages into texts of the target language. The backbone of SM2 is Transformer Transducer, which has high streaming capability. Instead of human labeled speech translation (ST) data, SM2 models are trained using weakly supervised data generated by converting the transcriptions in speech recognition corpora with a machine translation service. With 351 thousand hours of anonymized speech training data from 25 languages, SM2 models achieve comparable or even better ST quality than some recent popular large-scale non-streaming speech models. More importantly, we show that SM2 has the truly zero-shot capability when expanding to new target languages, yielding high quality ST results for {source-speech, target-text} pairs that are not seen during training.
On the robustness of non-intrusive speech quality model by adversarial examples
Nov 11, 2022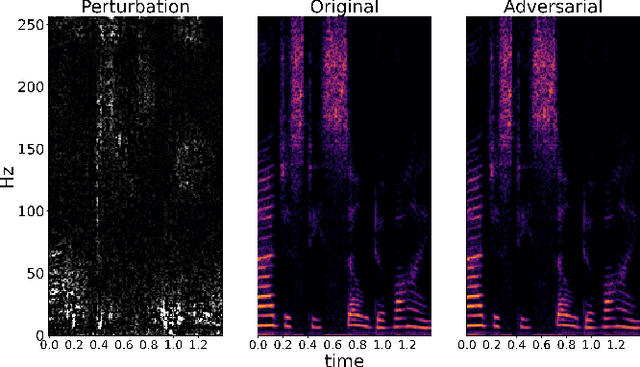
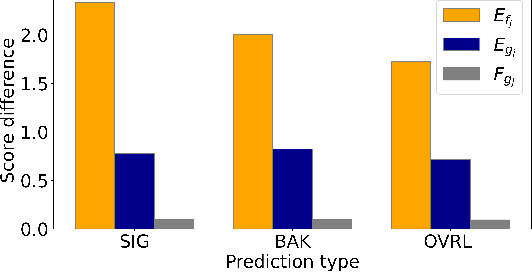
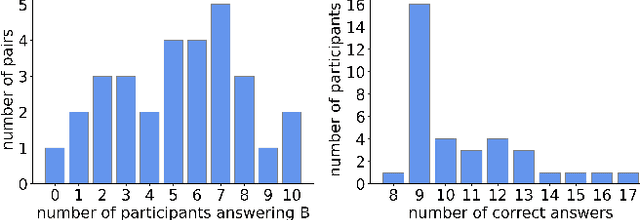
It has been shown recently that deep learning based models are effective on speech quality prediction and could outperform traditional metrics in various perspectives. Although network models have potential to be a surrogate for complex human hearing perception, they may contain instabilities in predictions. This work shows that deep speech quality predictors can be vulnerable to adversarial perturbations, where the prediction can be changed drastically by unnoticeable perturbations as small as $-30$ dB compared with speech inputs. In addition to exposing the vulnerability of deep speech quality predictors, we further explore and confirm the viability of adversarial training for strengthening robustness of models.
Seeing What You Said: Talking Face Generation Guided by a Lip Reading Expert
Mar 29, 2023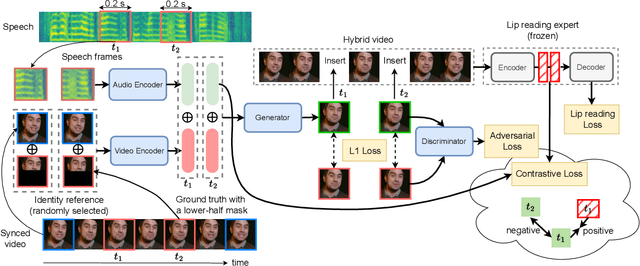
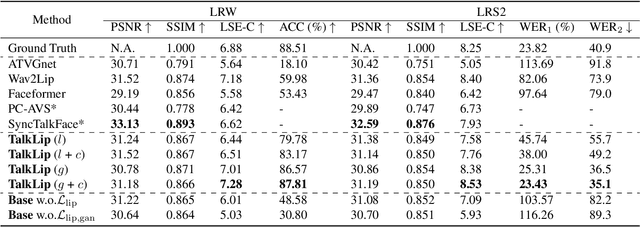
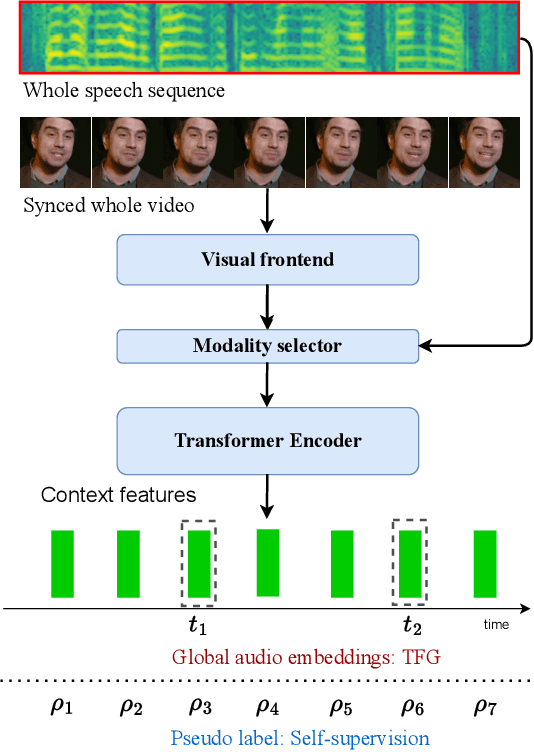
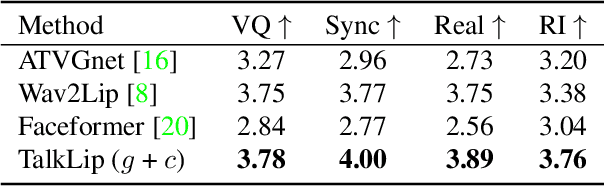
Talking face generation, also known as speech-to-lip generation, reconstructs facial motions concerning lips given coherent speech input. The previous studies revealed the importance of lip-speech synchronization and visual quality. Despite much progress, they hardly focus on the content of lip movements i.e., the visual intelligibility of the spoken words, which is an important aspect of generation quality. To address the problem, we propose using a lip-reading expert to improve the intelligibility of the generated lip regions by penalizing the incorrect generation results. Moreover, to compensate for data scarcity, we train the lip-reading expert in an audio-visual self-supervised manner. With a lip-reading expert, we propose a novel contrastive learning to enhance lip-speech synchronization, and a transformer to encode audio synchronically with video, while considering global temporal dependency of audio. For evaluation, we propose a new strategy with two different lip-reading experts to measure intelligibility of the generated videos. Rigorous experiments show that our proposal is superior to other State-of-the-art (SOTA) methods, such as Wav2Lip, in reading intelligibility i.e., over 38% Word Error Rate (WER) on LRS2 dataset and 27.8% accuracy on LRW dataset. We also achieve the SOTA performance in lip-speech synchronization and comparable performances in visual quality.