 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Leveraging characteristics of the output probability distribution for identifying adversarial audio examples
May 26, 2023


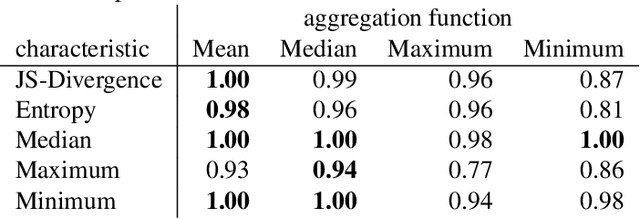
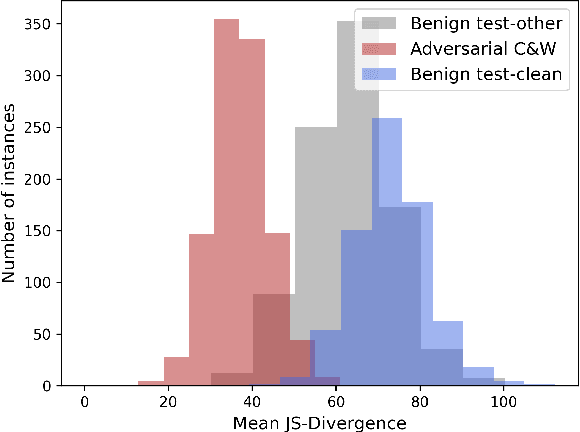
Adversarial attacks represent a security threat to machine learning based automatic speech recognition (ASR) systems. To prevent such attacks we propose an adversarial example detection strategy applicable to any ASR system that predicts a probability distribution over output tokens in each time step. We measure a set of characteristics of this distribution: the median, maximum, and minimum over the output probabilities, the entropy, and the Jensen-Shannon divergence of the distributions of subsequent time steps. Then, we fit a Gaussian distribution to the characteristics observed for benign data. By computing the likelihood of incoming new audio we can distinguish malicious inputs from samples from clean data with an area under the receiving operator characteristic (AUROC) higher than 0.99, which drops to 0.98 for less-quality audio. To assess the robustness of our method we build adaptive attacks. This reduces the AUROC to 0.96 but results in more noisy adversarial clips.
M-SpeechCLIP: Leveraging Large-Scale, Pre-Trained Models for Multilingual Speech to Image Retrieval
Nov 02, 2022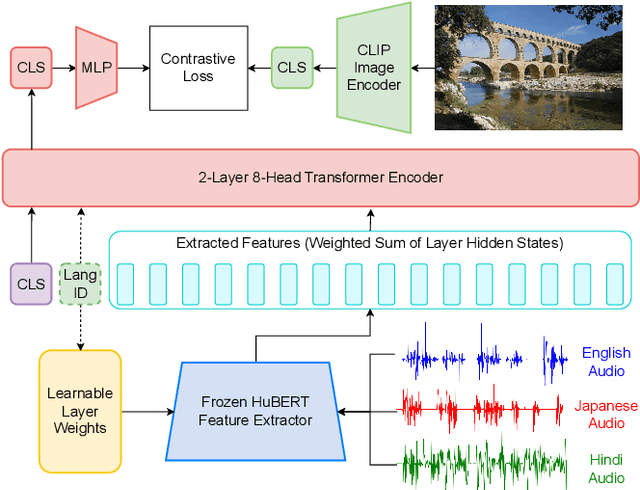
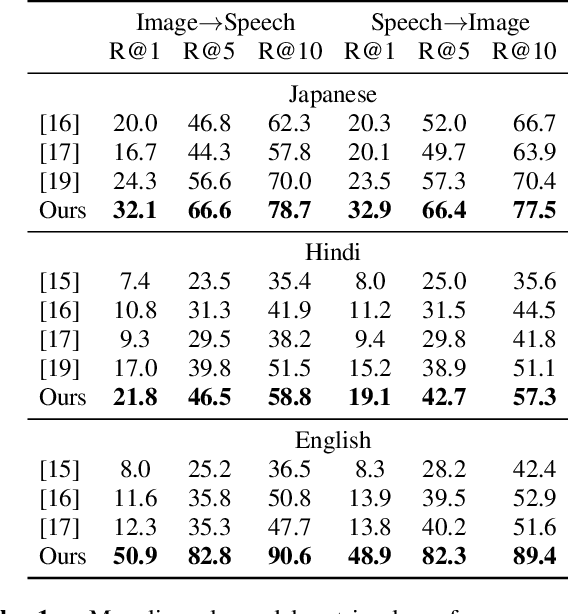
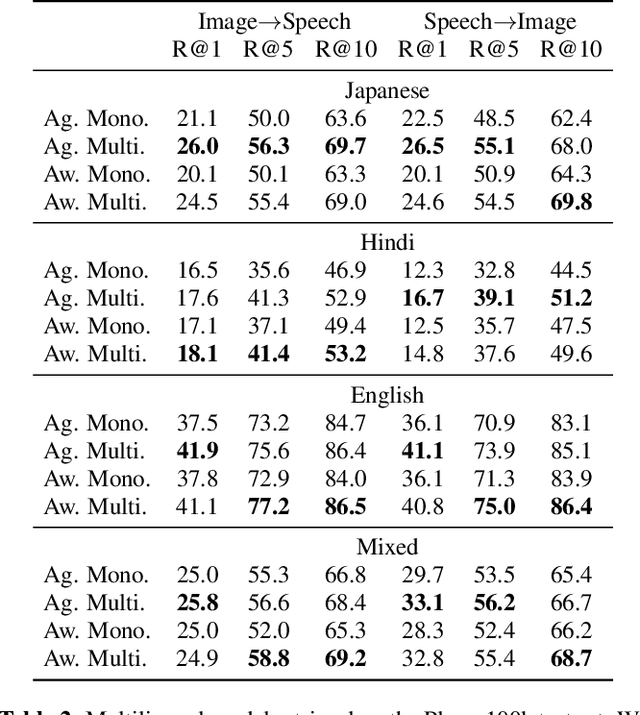
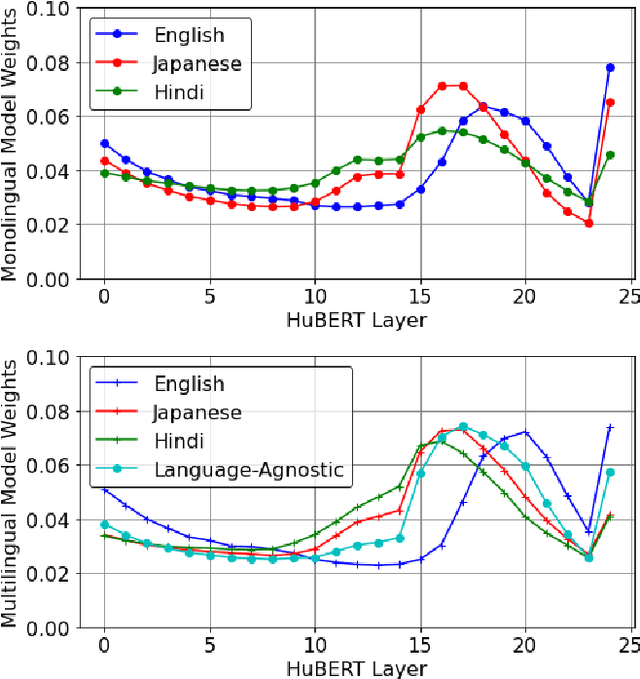
This work investigates the use of large-scale, pre-trained models (CLIP and HuBERT) for multilingual speech-image retrieval. For non-English speech-image retrieval, we outperform the current state-of-the-art performance by a wide margin when training separate models for each language, and show that a single model which processes speech in all three languages still achieves retrieval scores comparable with the prior state-of-the-art. We identify key differences in model behavior and performance between English and non-English settings, presumably attributable to the English-only pre-training of CLIP and HuBERT. Finally, we show that our models can be used for mono- and cross-lingual speech-text retrieval and cross-lingual speech-speech retrieval, despite never having seen any parallel speech-text or speech-speech data during training.
Controllable speech synthesis by learning discrete phoneme-level prosodic representations
Nov 29, 2022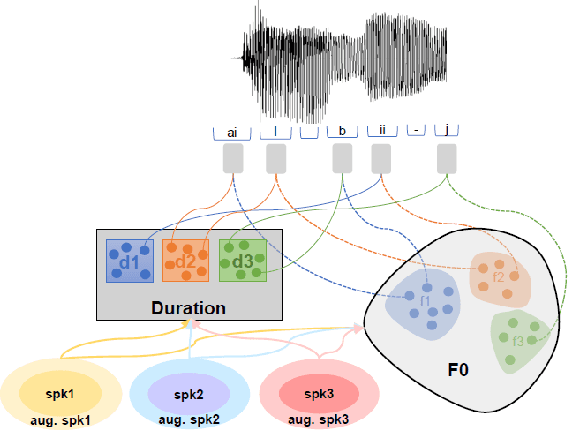
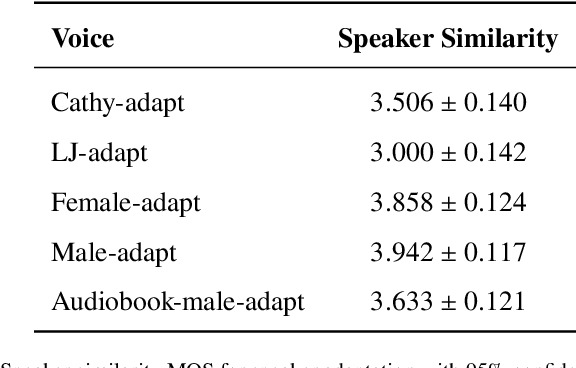
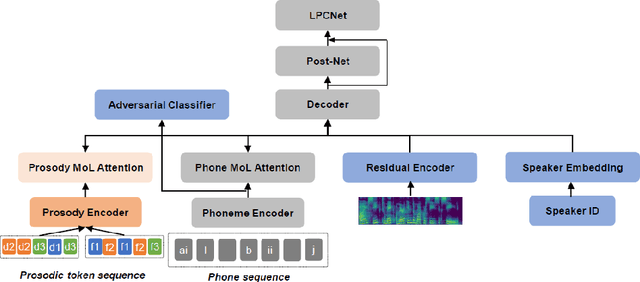
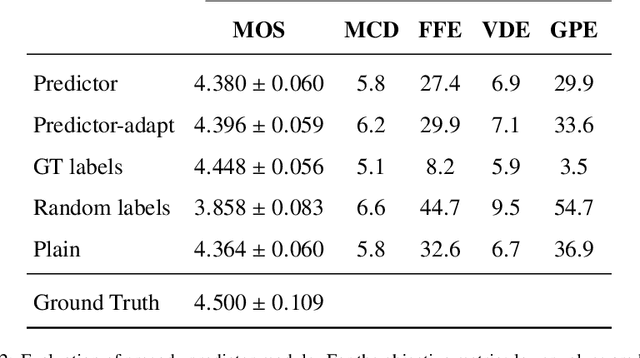
In this paper, we present a novel method for phoneme-level prosody control of F0 and duration using intuitive discrete labels. We propose an unsupervised prosodic clustering process which is used to discretize phoneme-level F0 and duration features from a multispeaker speech dataset. These features are fed as an input sequence of prosodic labels to a prosody encoder module which augments an autoregressive attention-based text-to-speech model. We utilize various methods in order to improve prosodic control range and coverage, such as augmentation, F0 normalization, balanced clustering for duration and speaker-independent clustering. The final model enables fine-grained phoneme-level prosody control for all speakers contained in the training set, while maintaining the speaker identity. Instead of relying on reference utterances for inference, we introduce a prior prosody encoder which learns the style of each speaker and enables speech synthesis without the requirement of reference audio. We also fine-tune the multispeaker model to unseen speakers with limited amounts of data, as a realistic application scenario and show that the prosody control capabilities are maintained, verifying that the speaker-independent prosodic clustering is effective. Experimental results show that the model has high output speech quality and that the proposed method allows efficient prosody control within each speaker's range despite the variability that a multispeaker setting introduces.
Towards Unified All-Neural Beamforming for Time and Frequency Domain Speech Separation
Dec 24, 2022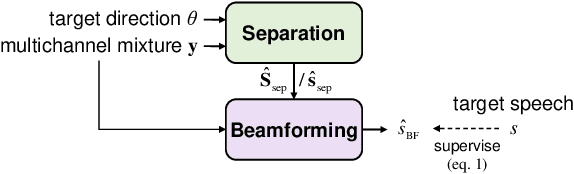
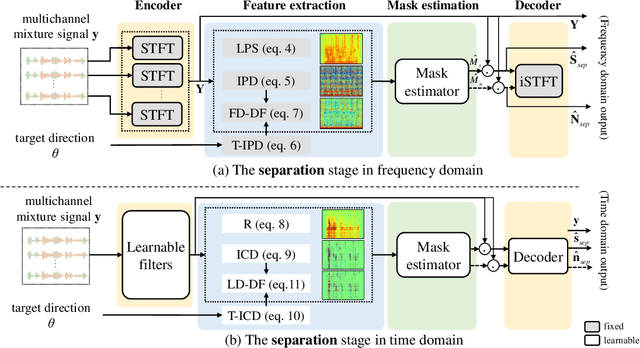
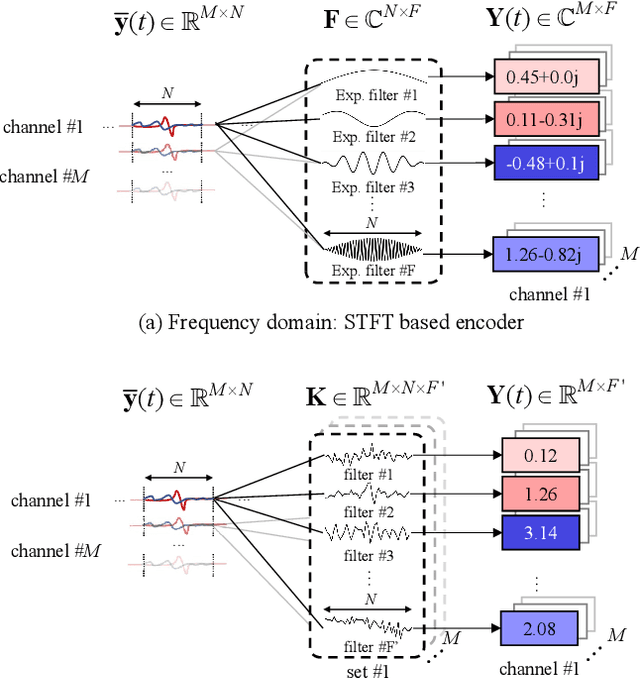
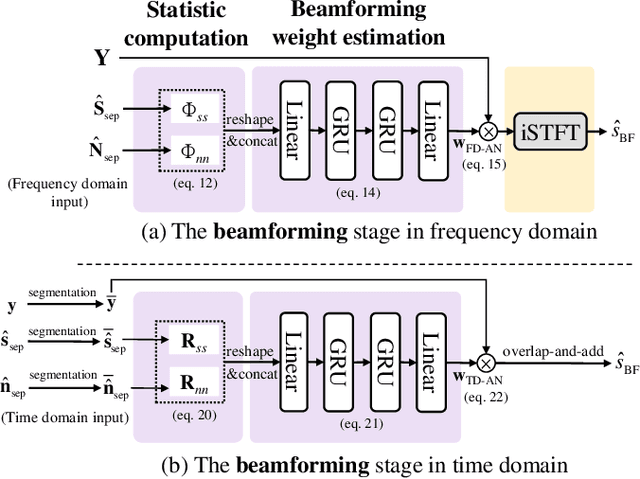
Recently, frequency domain all-neural beamforming methods have achieved remarkable progress for multichannel speech separation. In parallel, the integration of time domain network structure and beamforming also gains significant attention. This study proposes a novel all-neural beamforming method in time domain and makes an attempt to unify the all-neural beamforming pipelines for time domain and frequency domain multichannel speech separation. The proposed model consists of two modules: separation and beamforming. Both modules perform temporal-spectral-spatial modeling and are trained from end-to-end using a joint loss function. The novelty of this study lies in two folds. Firstly, a time domain directional feature conditioned on the direction of the target speaker is proposed, which can be jointly optimized within the time domain architecture to enhance target signal estimation. Secondly, an all-neural beamforming network in time domain is designed to refine the pre-separated results. This module features with parametric time-variant beamforming coefficient estimation, without explicitly following the derivation of optimal filters that may lead to an upper bound. The proposed method is evaluated on simulated reverberant overlapped speech data derived from the AISHELL-1 corpus. Experimental results demonstrate significant performance improvements over frequency domain state-of-the-arts, ideal magnitude masks and existing time domain neural beamforming methods.
Spoofing Attacker Also Benefits from Self-Supervised Pretrained Model
May 24, 2023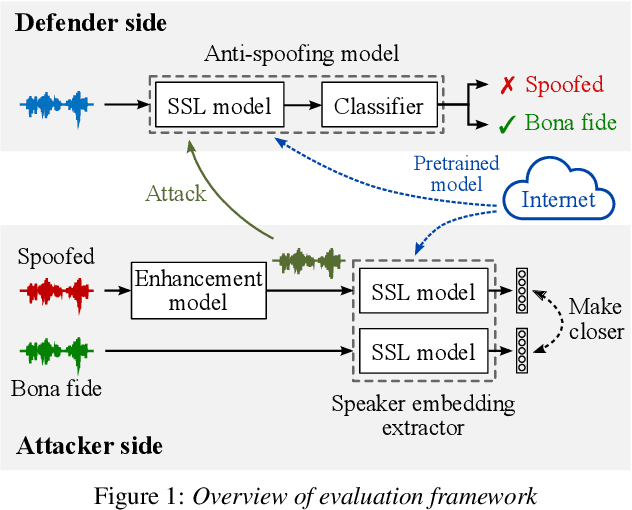
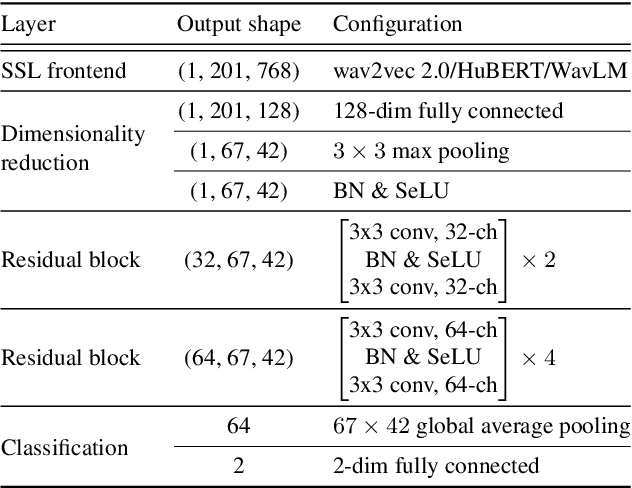
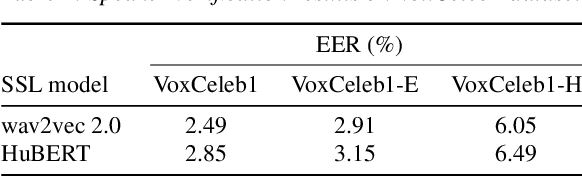

Large-scale pretrained models using self-supervised learning have reportedly improved the performance of speech anti-spoofing. However, the attacker side may also make use of such models. Also, since it is very expensive to train such models from scratch, pretrained models on the Internet are often used, but the attacker and defender may possibly use the same pretrained model. This paper investigates whether the improvement in anti-spoofing with pretrained models holds under the condition that the models are available to attackers. As the attacker, we train a model that enhances spoofed utterances so that the speaker embedding extractor based on the pretrained models cannot distinguish between bona fide and spoofed utterances. Experimental results show that the gains the anti-spoofing models obtained by using the pretrained models almost disappear if the attacker also makes use of the pretrained models.
How Hate Speech Varies by Target Identity: A Computational Analysis
Oct 19, 2022
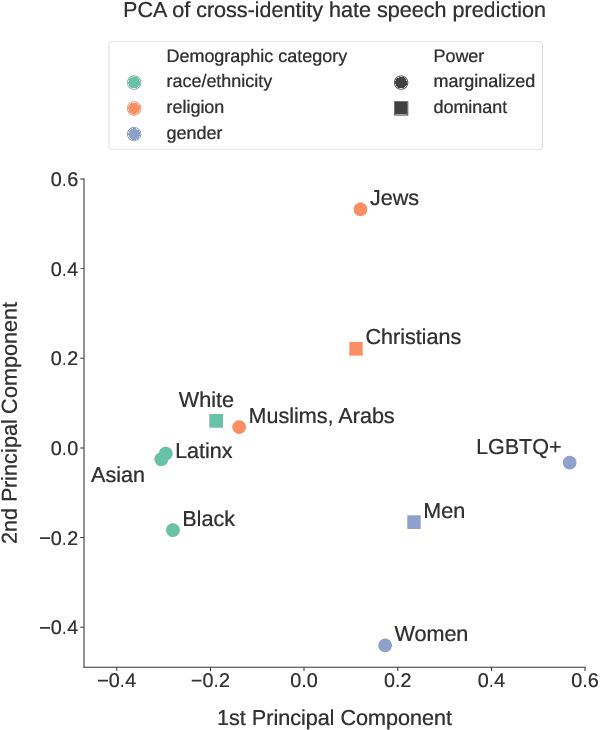
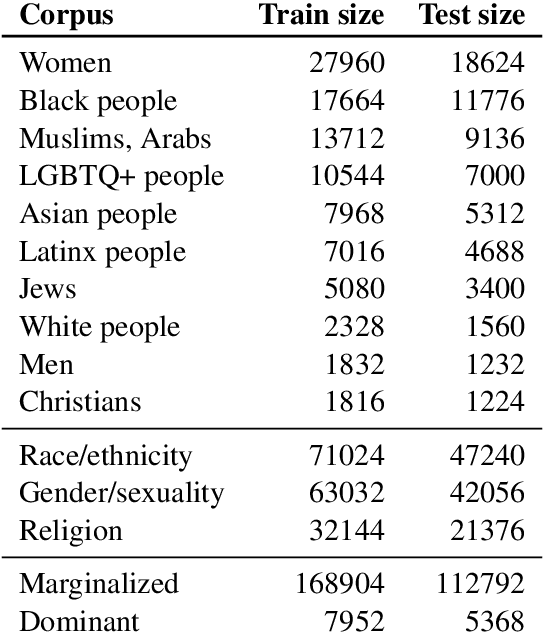
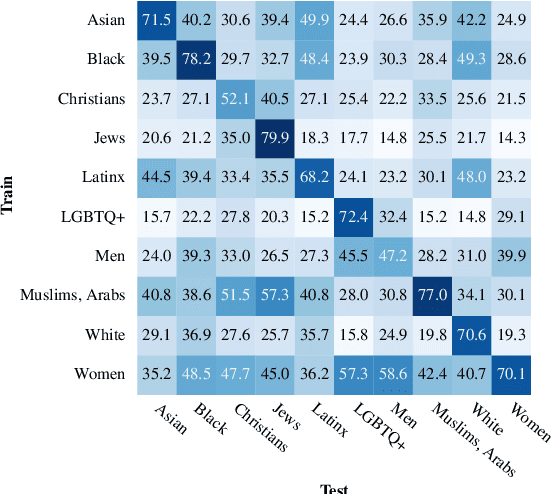
This paper investigates how hate speech varies in systematic ways according to the identities it targets. Across multiple hate speech datasets annotated for targeted identities, we find that classifiers trained on hate speech targeting specific identity groups struggle to generalize to other targeted identities. This provides empirical evidence for differences in hate speech by target identity; we then investigate which patterns structure this variation. We find that the targeted demographic category (e.g. gender/sexuality or race/ethnicity) appears to have a greater effect on the language of hate speech than does the relative social power of the targeted identity group. We also find that words associated with hate speech targeting specific identities often relate to stereotypes, histories of oppression, current social movements, and other social contexts specific to identities. These experiments suggest the importance of considering targeted identity, as well as the social contexts associated with these identities, in automated hate speech classification.
Cold Diffusion for Speech Enhancement
Nov 04, 2022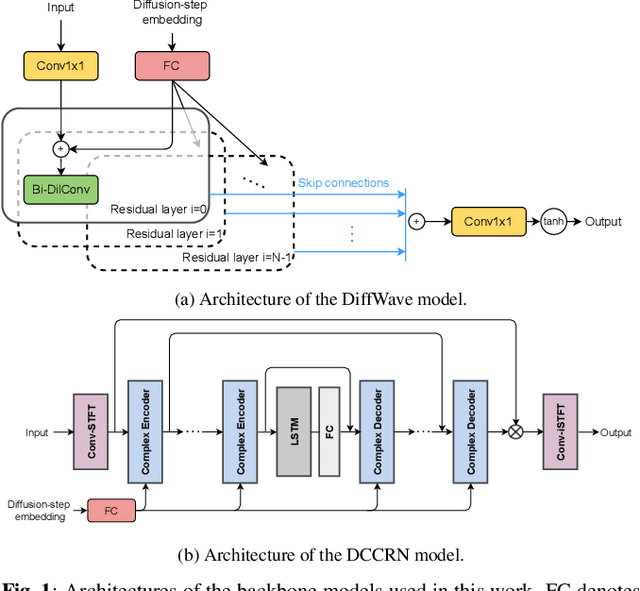
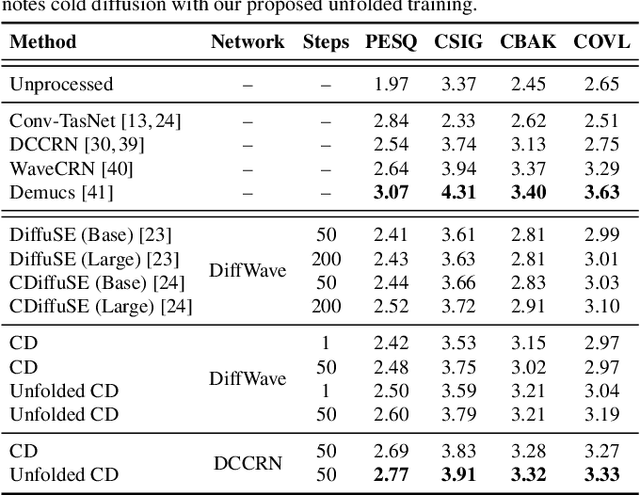
Diffusion models have recently shown promising results for difficult enhancement tasks such as the conditional and unconditional restoration of natural images and audio signals. In this work, we explore the possibility of leveraging a recently proposed advanced iterative diffusion model, namely cold diffusion, to recover clean speech signals from noisy signals. The unique mathematical properties of the sampling process from cold diffusion could be utilized to restore high-quality samples from arbitrary degradations. Based on these properties, we propose an improved training algorithm and objective to help the model generalize better during the sampling process. We verify our proposed framework by investigating two model architectures. Experimental results on benchmark speech enhancement dataset VoiceBank-DEMAND demonstrate the strong performance of the proposed approach compared to representative discriminative models and diffusion-based enhancement models.
Exploring Speaker-Related Information in Spoken Language Understanding for Better Speaker Diarization
May 22, 2023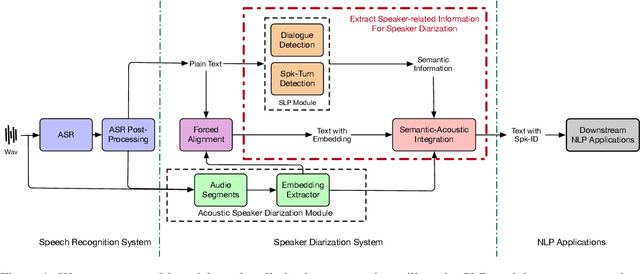
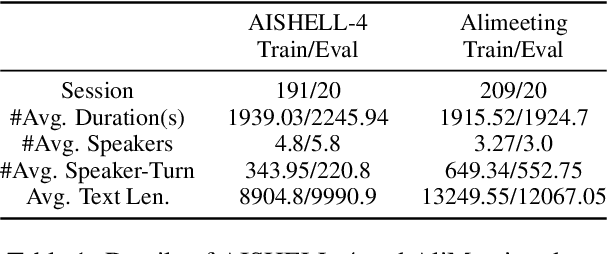
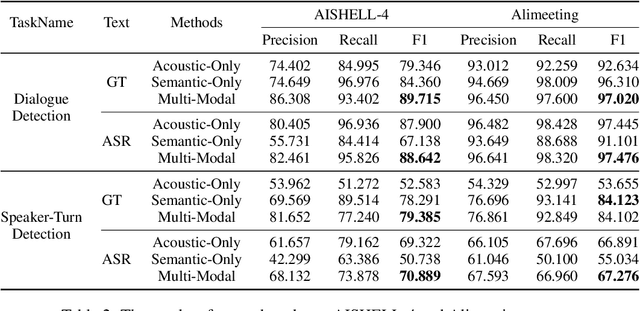
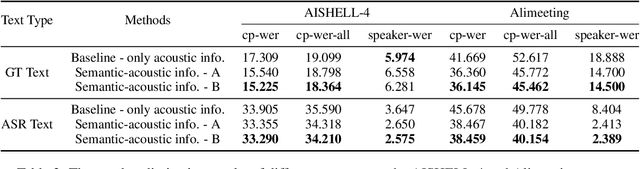
Speaker diarization(SD) is a classic task in speech processing and is crucial in multi-party scenarios such as meetings and conversations. Current mainstream speaker diarization approaches consider acoustic information only, which result in performance degradation when encountering adverse acoustic conditions. In this paper, we propose methods to extract speaker-related information from semantic content in multi-party meetings, which, as we will show, can further benefit speaker diarization. We introduce two sub-tasks, Dialogue Detection and Speaker-Turn Detection, in which we effectively extract speaker information from conversational semantics. We also propose a simple yet effective algorithm to jointly model acoustic and semantic information and obtain speaker-identified texts. Experiments on both AISHELL-4 and AliMeeting datasets show that our method achieves consistent improvements over acoustic-only speaker diarization systems.
Understanding temporally weakly supervised training: A case study for keyword spotting
May 30, 2023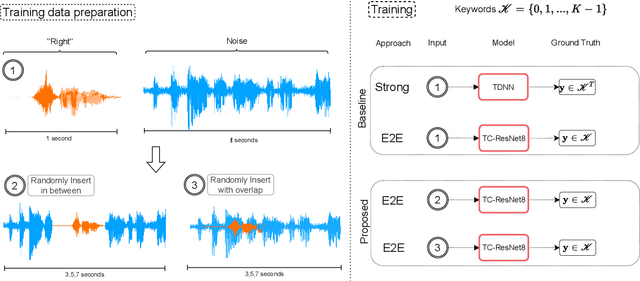

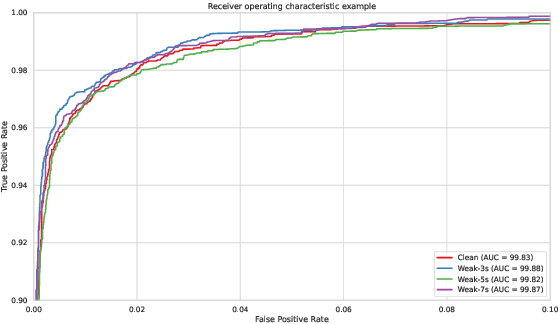
The currently most prominent algorithm to train keyword spotting (KWS) models with deep neural networks (DNNs) requires strong supervision i.e., precise knowledge of the spoken keyword location in time. Thus, most KWS approaches treat the presence of redundant data, such as noise, within their training set as an obstacle. A common training paradigm to deal with data redundancies is to use temporally weakly supervised learning, which only requires providing labels on a coarse scale. This study explores the limits of DNN training using temporally weak labeling with applications in KWS. We train a simple end-to-end classifier on the common Google Speech Commands dataset with increased difficulty by randomly appending and adding noise to the training dataset. Our results indicate that temporally weak labeling can achieve comparable results to strongly supervised baselines while having a less stringent labeling requirement. In the presence of noise, weakly supervised models are capable to localize and extract target keywords without explicit supervision, leading to a performance increase compared to strongly supervised approaches.
Language-Universal Adapter Learning with Knowledge Distillation for End-to-End Multilingual Speech Recognition
Feb 28, 2023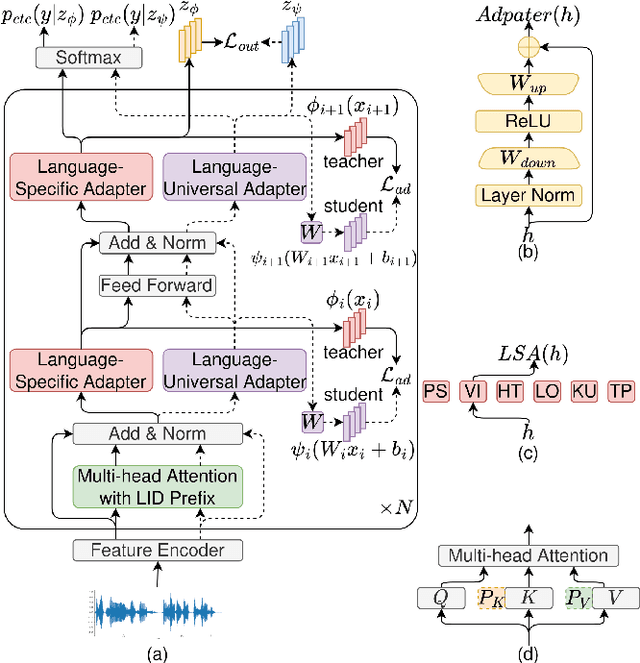
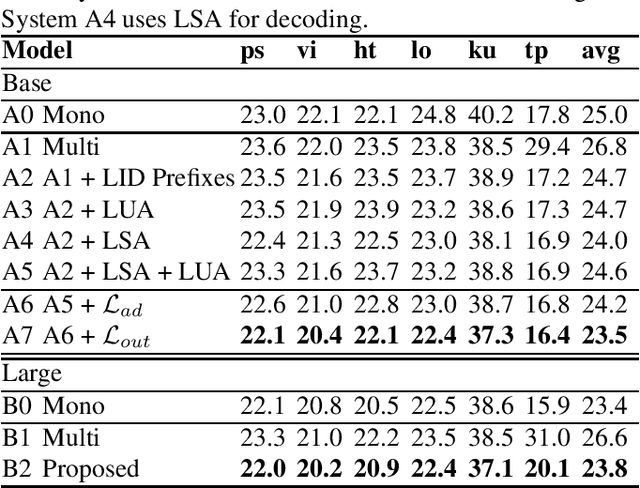

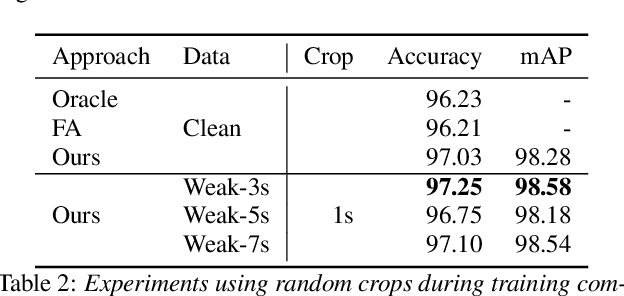
In this paper, we propose a language-universal adapter learning framework based on a pre-trained model for end-to-end multilingual automatic speech recognition (ASR). For acoustic modeling, the wav2vec 2.0 pre-trained model is fine-tuned by inserting language-specific and language-universal adapters. An online knowledge distillation is then used to enable the language-universal adapters to learn both language-specific and universal features. The linguistic information confusion is also reduced by leveraging language identifiers (LIDs). With LIDs we perform a position-wise modification on the multi-head attention outputs. In the inference procedure, the language-specific adapters are removed while the language-universal adapters are kept activated. The proposed method improves the recognition accuracy and addresses the linear increase of the number of adapters' parameters with the number of languages in common multilingual ASR systems. Experiments on the BABEL dataset confirm the effectiveness of the proposed framework. Compared to the conventional multilingual model, a 3.3% absolute error rate reduction is achieved. The code is available at: https://github.com/shen9712/UniversalAdapterLearning.