 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
I run as fast as a rabbit, can you? A Multilingual Simile Dialogue Dataset
Jun 09, 2023

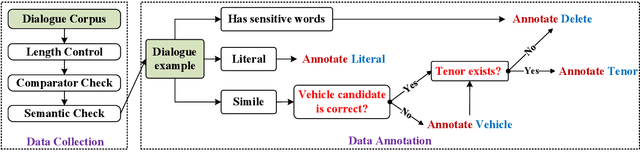
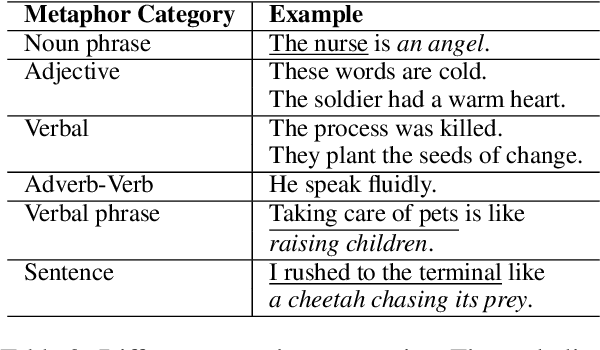
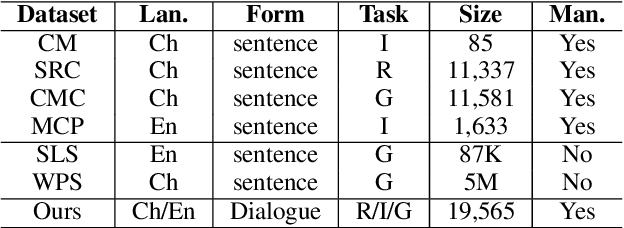
A simile is a figure of speech that compares two different things (called the tenor and the vehicle) via shared properties. The tenor and the vehicle are usually connected with comparator words such as "like" or "as". The simile phenomena are unique and complex in a real-life dialogue scene where the tenor and the vehicle can be verbal phrases or sentences, mentioned by different speakers, exist in different sentences, or occur in reversed order. However, the current simile research usually focuses on similes in a triplet tuple (tenor, property, vehicle) or a single sentence where the tenor and vehicle are usually entities or noun phrases, which could not reflect complex simile phenomena in real scenarios. In this paper, we propose a novel and high-quality multilingual simile dialogue (MSD) dataset to facilitate the study of complex simile phenomena. The MSD is the largest manually annotated simile data ($\sim$20K) and it contains both English and Chinese data. Meanwhile, the MSD data can also be used on dialogue tasks to test the ability of dialogue systems when using similes. We design 3 simile tasks (recognition, interpretation, and generation) and 2 dialogue tasks (retrieval and generation) with MSD. For each task, we provide experimental results from strong pre-trained or state-of-the-art models. The experiments demonstrate the challenge of MSD and we have released the data/code on GitHub.
Feature Selection using Sparse Adaptive Bottleneck Centroid-Encoder
Jun 09, 2023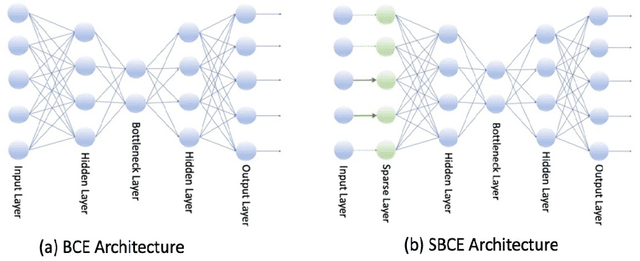

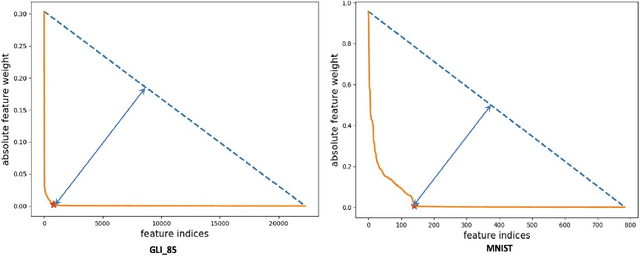
We introduce a novel nonlinear model, Sparse Adaptive Bottleneck Centroid-Encoder (SABCE), for determining the features that discriminate between two or more classes. The algorithm aims to extract discriminatory features in groups while reconstructing the class centroids in the ambient space and simultaneously use additional penalty terms in the bottleneck layer to decrease within-class scatter and increase the separation of different class centroids. The model has a sparsity-promoting layer (SPL) with a one-to-one connection to the input layer. Along with the primary objective, we minimize the $l_{2,1}$-norm of the sparse layer, which filters out unnecessary features from input data. During training, we update class centroids by taking the Hadamard product of the centroids and weights of the sparse layer, thus ignoring the irrelevant features from the target. Therefore the proposed method learns to reconstruct the critical components of class centroids rather than the whole centroids. The algorithm is applied to various real-world data sets, including high-dimensional biological, image, speech, and accelerometer sensor data. We compared our method to different state-of-the-art feature selection techniques, including supervised Concrete Autoencoders (SCAE), Feature Selection Networks (FsNet), Stochastic Gates (STG), and LassoNet. We empirically showed that SABCE features often produced better classification accuracy than other methods on the sequester test sets, setting new state-of-the-art results.
Transformer-based Sequence Labeling for Audio Classification based on MFCCs
Apr 30, 2023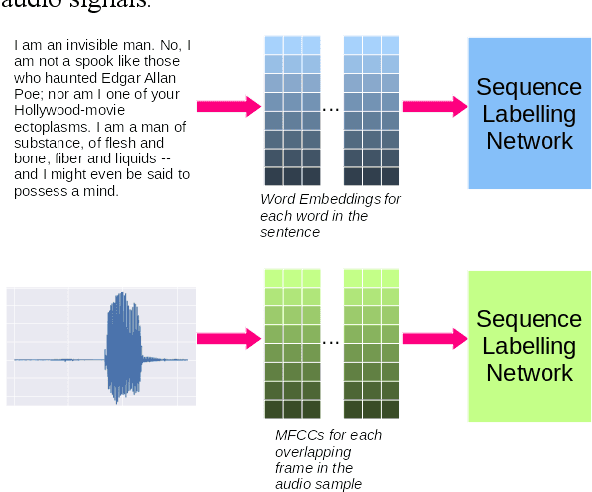
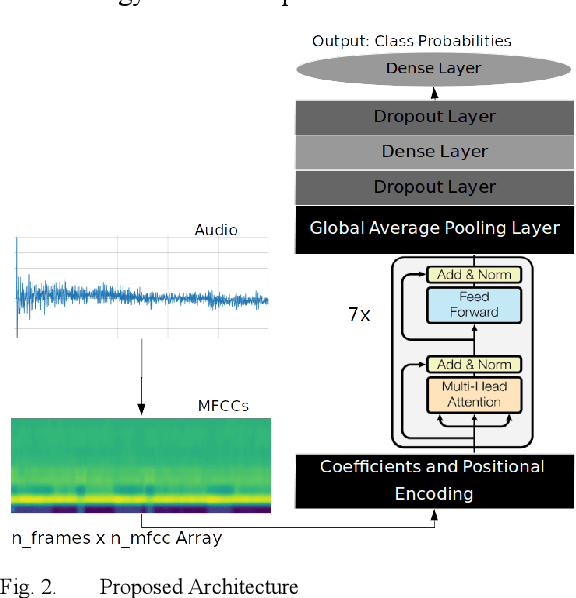
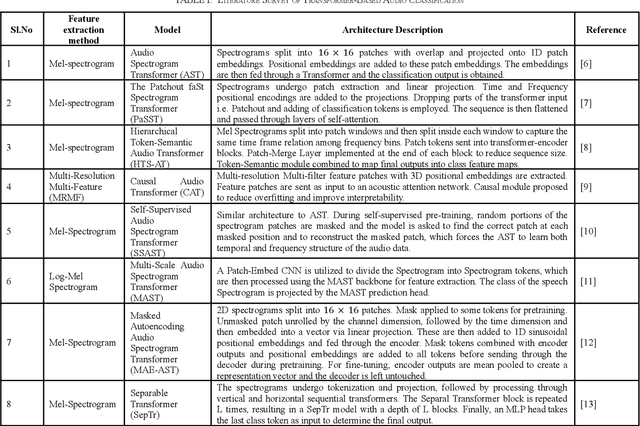
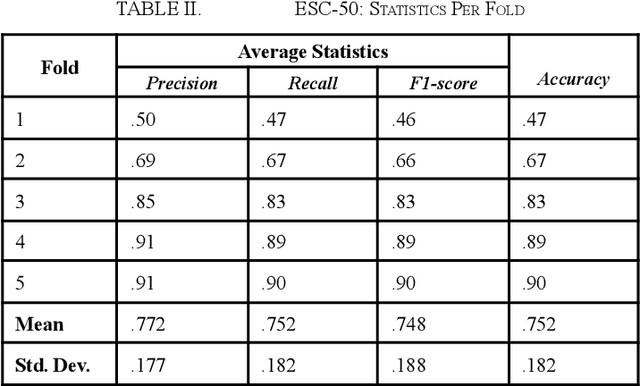
Audio classification is vital in areas such as speech and music recognition. Feature extraction from the audio signal, such as Mel-Spectrograms and MFCCs, is a critical step in audio classification. These features are transformed into spectrograms for classification. Researchers have explored various techniques, including traditional machine and deep learning methods to classify spectrograms, but these can be computationally expensive. To simplify this process, a more straightforward approach inspired by sequence classification in NLP can be used. This paper proposes a Transformer-encoder-based model for audio classification using MFCCs. The model was benchmarked against the ESC-50, Speech Commands v0.02 and UrbanSound8k datasets and has shown strong performance, with the highest accuracy of 95.2% obtained upon training the model on the UrbanSound8k dataset. The model consisted of a mere 127,544 total parameters, making it light-weight yet highly efficient at the audio classification task.
High Fidelity Speech Enhancement with Band-split RNN
Dec 01, 2022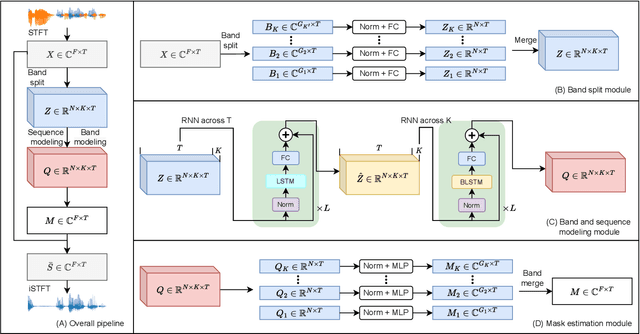
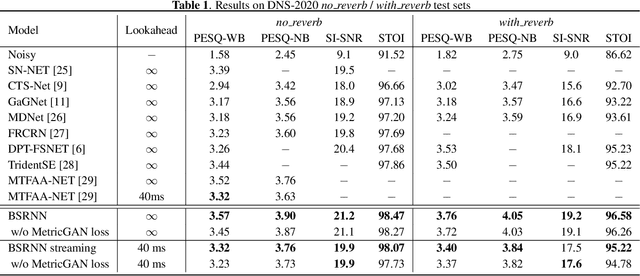
This report presents the development of our speech enhancement system, which includes the use of a recently proposed music separation model, the band-split recurrent neural network (BSRNN), and a MetricGAN-based training objective to improve non-differentiable quality metrics such as perceptual evaluation of speech quality (PESQ) score. Experiment conducted on Interspeech 2021 DNS challenge shows that our BSRNN system outperforms various top-ranking benchmark systems in previous deep noise suppression (DNS) challenges and achieves state-of-the-art (SOTA) result on the DNS-2020 non-blind test set in both offline and online scenarios.
Learning to Speak from Text: Zero-Shot Multilingual Text-to-Speech with Unsupervised Text Pretraining
Jan 30, 2023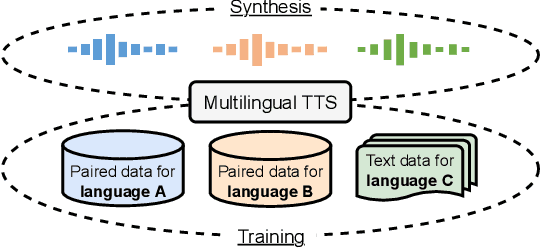
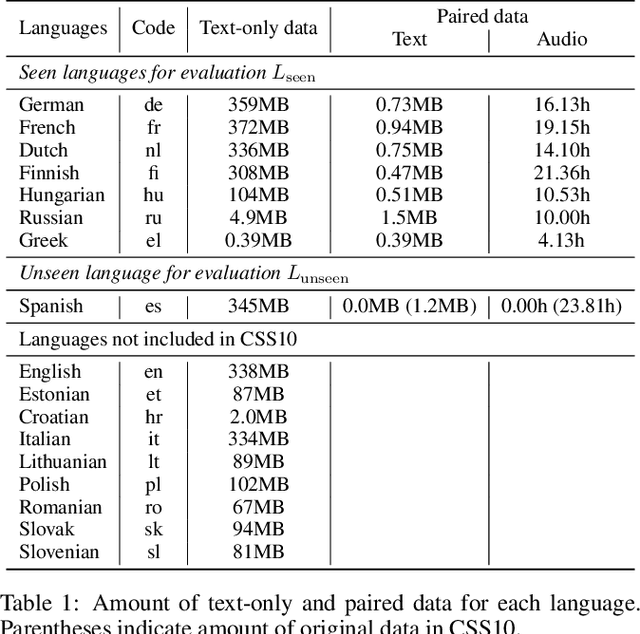
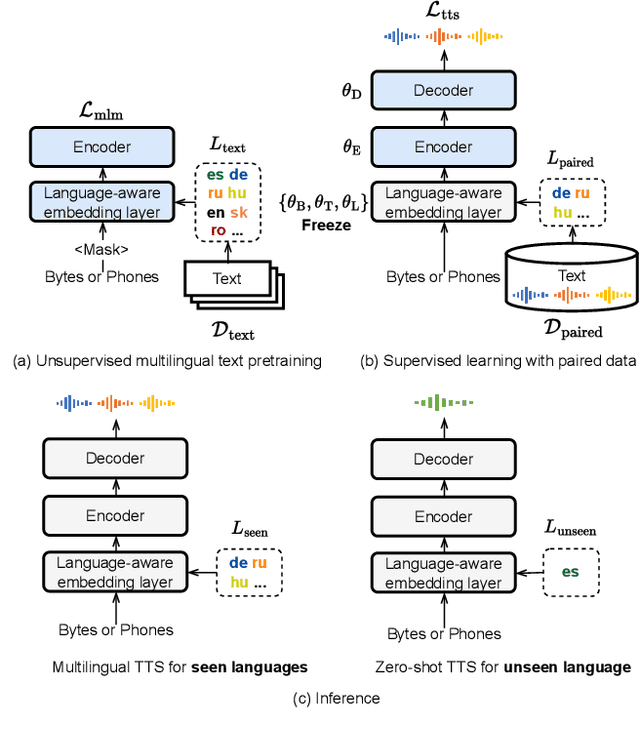
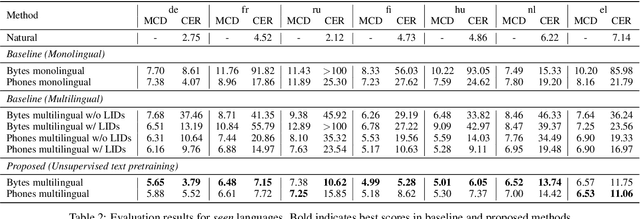
While neural text-to-speech (TTS) has achieved human-like natural synthetic speech, multilingual TTS systems are limited to resource-rich languages due to the need for paired text and studio-quality audio data. This paper proposes a method for zero-shot multilingual TTS using text-only data for the target language. The use of text-only data allows the development of TTS systems for low-resource languages for which only textual resources are available, making TTS accessible to thousands of languages. Inspired by the strong cross-lingual transferability of multilingual language models, our framework first performs masked language model pretraining with multilingual text-only data. Then we train this model with a paired data in a supervised manner, while freezing a language-aware embedding layer. This allows inference even for languages not included in the paired data but present in the text-only data. Evaluation results demonstrate highly intelligible zero-shot TTS with a character error rate of less than 12% for an unseen language. All experiments were conducted using public datasets and the implementation will be made available for reproducibility.
Antisemitic Messages? A Guide to High-Quality Annotation and a Labeled Dataset of Tweets
Apr 28, 2023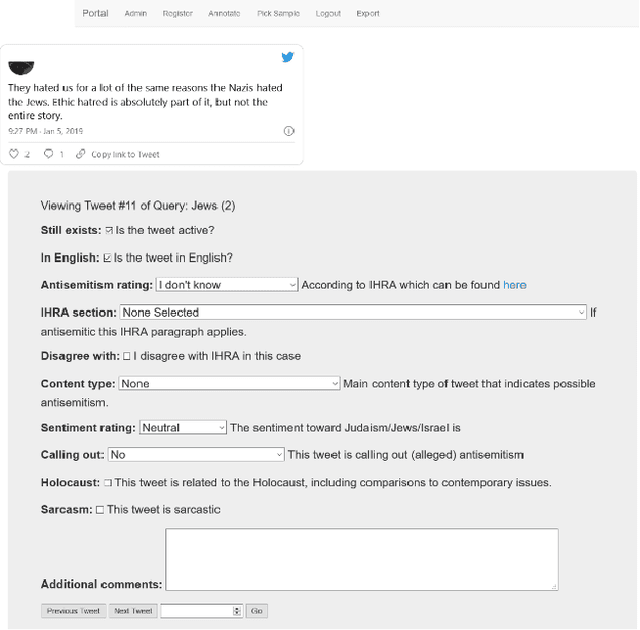
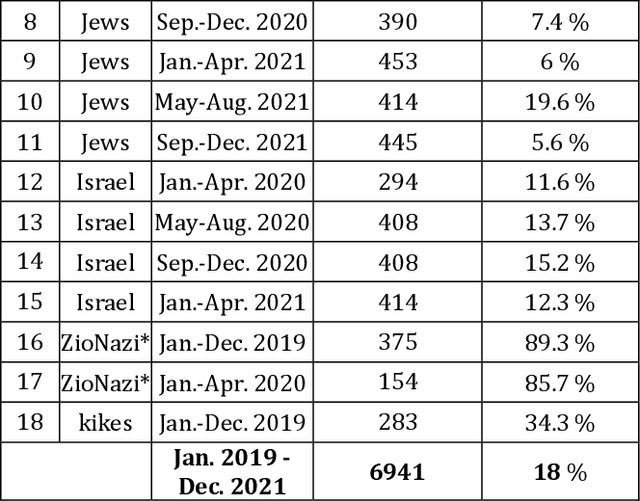
One of the major challenges in automatic hate speech detection is the lack of datasets that cover a wide range of biased and unbiased messages and that are consistently labeled. We propose a labeling procedure that addresses some of the common weaknesses of labeled datasets. We focus on antisemitic speech on Twitter and create a labeled dataset of 6,941 tweets that cover a wide range of topics common in conversations about Jews, Israel, and antisemitism between January 2019 and December 2021 by drawing from representative samples with relevant keywords. Our annotation process aims to strictly apply a commonly used definition of antisemitism by forcing annotators to specify which part of the definition applies, and by giving them the option to personally disagree with the definition on a case-by-case basis. Labeling tweets that call out antisemitism, report antisemitism, or are otherwise related to antisemitism (such as the Holocaust) but are not actually antisemitic can help reduce false positives in automated detection. The dataset includes 1,250 tweets (18%) that are antisemitic according to the International Holocaust Remembrance Alliance (IHRA) definition of antisemitism. It is important to note, however, that the dataset is not comprehensive. Many topics are still not covered, and it only includes tweets collected from Twitter between January 2019 and December 2021. Additionally, the dataset only includes tweets that were written in English. Despite these limitations, we hope that this is a meaningful contribution to improving the automated detection of antisemitic speech.
LongFNT: Long-form Speech Recognition with Factorized Neural Transducer
Nov 17, 2022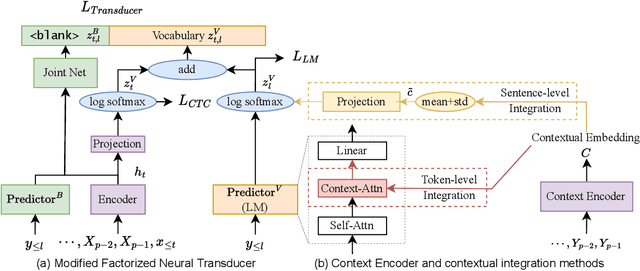
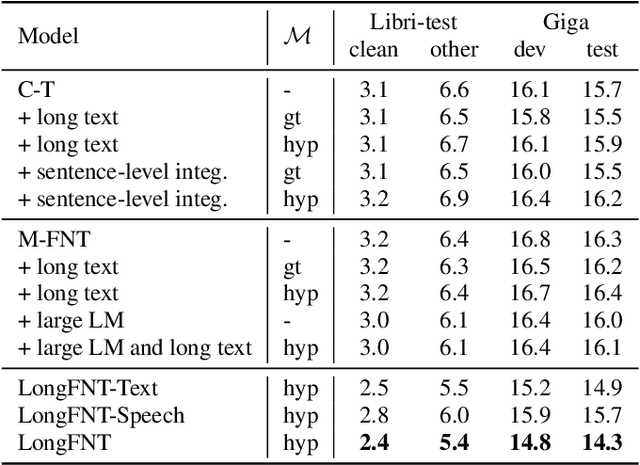
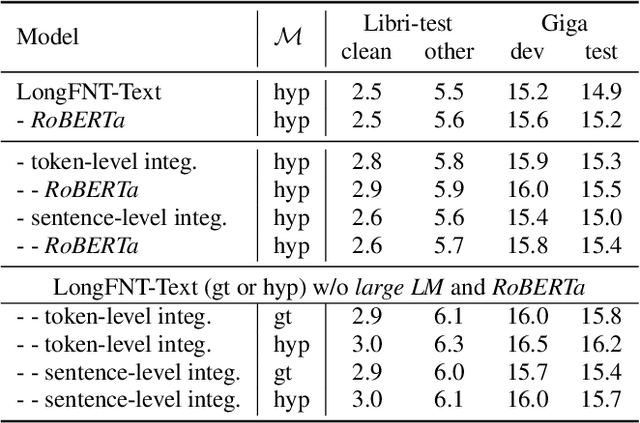

Traditional automatic speech recognition~(ASR) systems usually focus on individual utterances, without considering long-form speech with useful historical information, which is more practical in real scenarios. Simply attending longer transcription history for a vanilla neural transducer model shows no much gain in our preliminary experiments, since the prediction network is not a pure language model. This motivates us to leverage the factorized neural transducer structure, containing a real language model, the vocabulary predictor. We propose the {LongFNT-Text} architecture, which fuses the sentence-level long-form features directly with the output of the vocabulary predictor and then embeds token-level long-form features inside the vocabulary predictor, with a pre-trained contextual encoder RoBERTa to further boost the performance. Moreover, we propose the {LongFNT} architecture by extending the long-form speech to the original speech input and achieve the best performance. The effectiveness of our LongFNT approach is validated on LibriSpeech and GigaSpeech corpora with 19% and 12% relative word error rate~(WER) reduction, respectively.
Joint unsupervised and supervised learning for context-aware language identification
Apr 14, 2023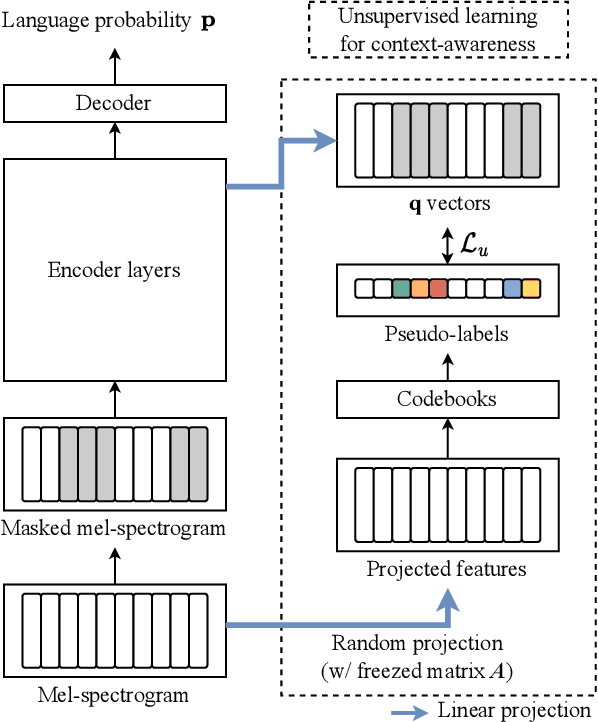
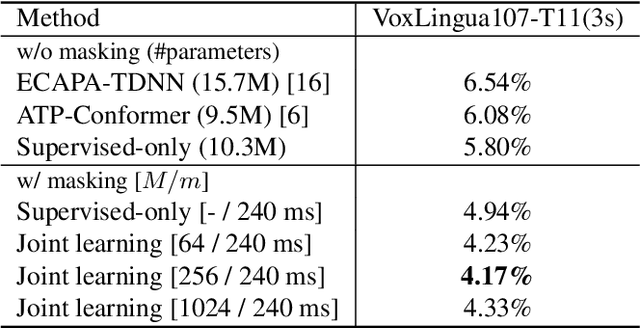
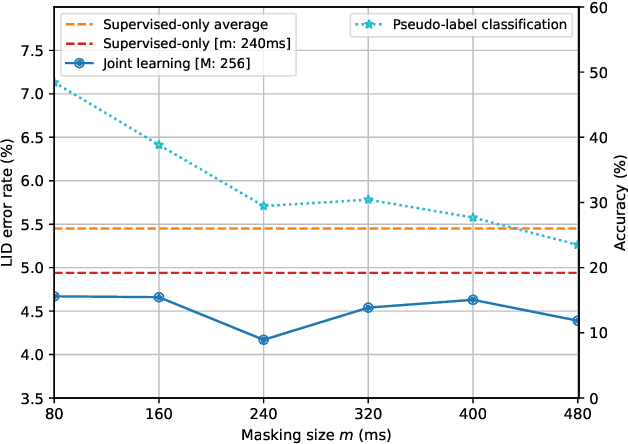
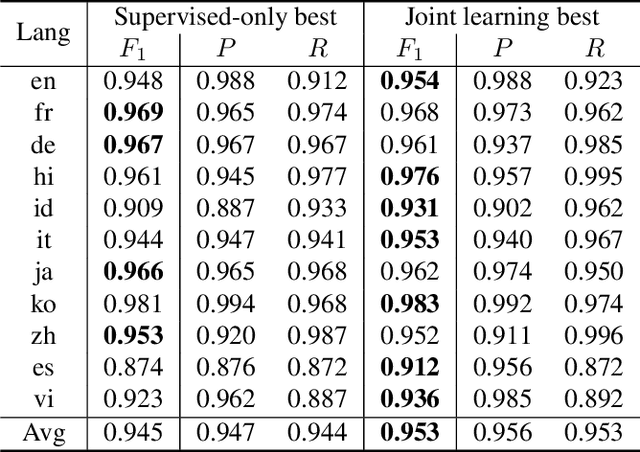
Language identification (LID) recognizes the language of a spoken utterance automatically. According to recent studies, LID models trained with an automatic speech recognition (ASR) task perform better than those trained with a LID task only. However, we need additional text labels to train the model to recognize speech, and acquiring the text labels is a cost high. In order to overcome this problem, we propose context-aware language identification using a combination of unsupervised and supervised learning without any text labels. The proposed method learns the context of speech through masked language modeling (MLM) loss and simultaneously trains to determine the language of the utterance with supervised learning loss. The proposed joint learning was found to reduce the error rate by 15.6% compared to the same structure model trained by supervised-only learning on a subset of the VoxLingua107 dataset consisting of sub-three-second utterances in 11 languages.
XNOR-FORMER: Learning Accurate Approximations in Long Speech Transformers
Oct 29, 2022
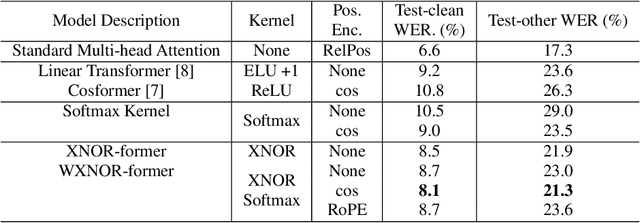
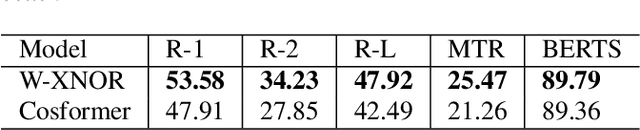
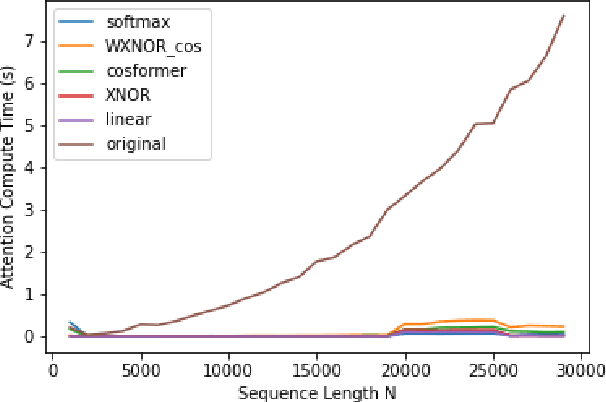
Transformers are among the state of the art for many tasks in speech, vision, and natural language processing, among others. Self-attentions, which are crucial contributors to this performance have quadratic computational complexity, which makes training on longer input sequences challenging. Prior work has produced state-of-the-art transformer variants with linear attention, however, current models sacrifice performance to achieve efficient implementations. In this work, we develop a novel linear transformer by examining the properties of the key-query product within self-attentions. Our model outperforms state of the art approaches on speech recognition and speech summarization, resulting in 1 % absolute WER improvement on the Librispeech-100 speech recognition benchmark and a new INTERVIEW speech recognition benchmark, and 5 points on ROUGE for summarization with How2.
Towards Building Voice-based Conversational Recommender Systems: Datasets, Potential Solutions, and Prospects
Jun 14, 2023
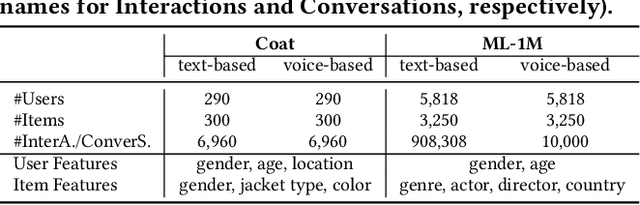
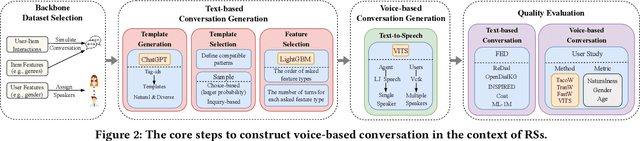
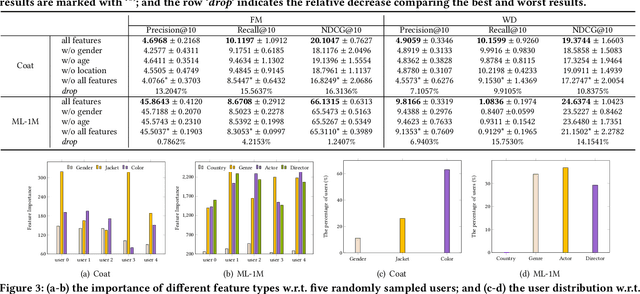
Conversational recommender systems (CRSs) have become crucial emerging research topics in the field of RSs, thanks to their natural advantages of explicitly acquiring user preferences via interactive conversations and revealing the reasons behind recommendations. However, the majority of current CRSs are text-based, which is less user-friendly and may pose challenges for certain users, such as those with visual impairments or limited writing and reading abilities. Therefore, for the first time, this paper investigates the potential of voice-based CRS (VCRSs) to revolutionize the way users interact with RSs in a natural, intuitive, convenient, and accessible fashion. To support such studies, we create two VCRSs benchmark datasets in the e-commerce and movie domains, after realizing the lack of such datasets through an exhaustive literature review. Specifically, we first empirically verify the benefits and necessity of creating such datasets. Thereafter, we convert the user-item interactions to text-based conversations through the ChatGPT-driven prompts for generating diverse and natural templates, and then synthesize the corresponding audios via the text-to-speech model. Meanwhile, a number of strategies are delicately designed to ensure the naturalness and high quality of voice conversations. On this basis, we further explore the potential solutions and point out possible directions to build end-to-end VCRSs by seamlessly extracting and integrating voice-based inputs, thus delivering performance-enhanced, self-explainable, and user-friendly VCRSs. Our study aims to establish the foundation and motivate further pioneering research in the emerging field of VCRSs. This aligns with the principles of explainable AI and AI for social good, viz., utilizing technology's potential to create a fair, sustainable, and just world.