 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Blind Signal Dereverberation for Machine Speech Recognition
Sep 30, 2022
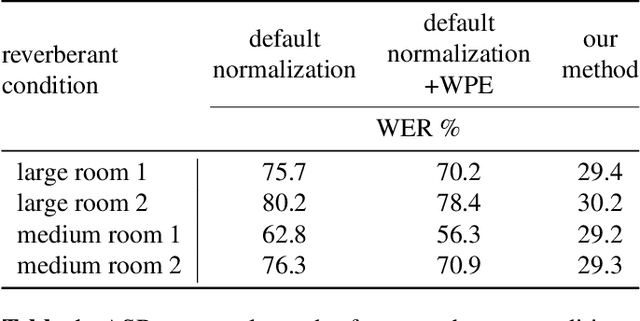
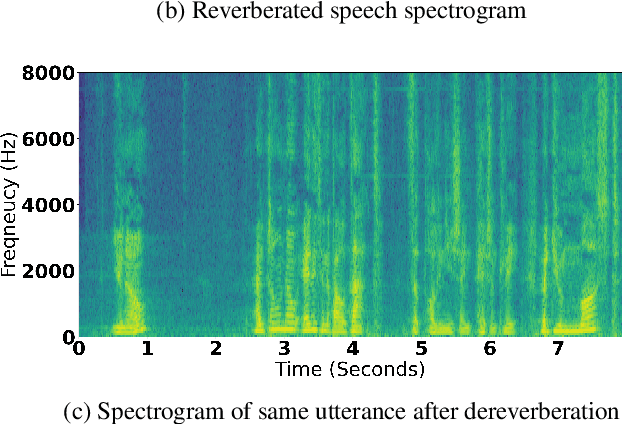
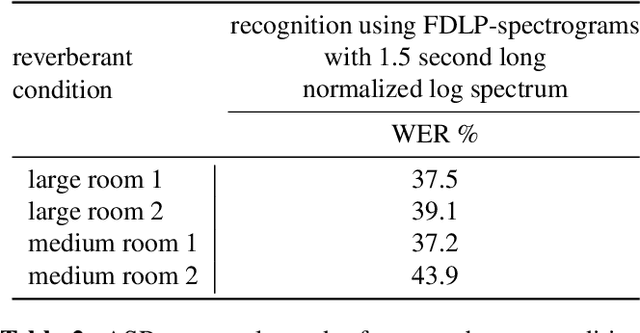
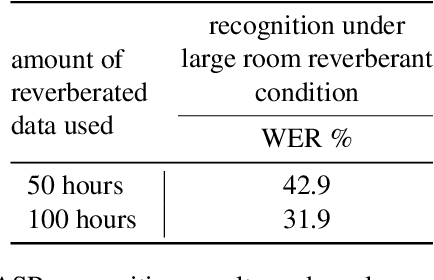
We present a method to remove unknown convolutive noise introduced to speech by reverberations of recording environments, utilizing some amount of training speech data from the reverberant environment, and any available non-reverberant speech data. Using Fourier transform computed over long temporal windows, which ideally cover the entire room impulse response, we convert room induced convolution to additions in the log spectral domain. Next, we compute a spectral normalization vector from statistics gathered over reverberated as well as over clean speech in the log spectral domain. During operation, this normalization vectors are used to alleviate reverberations from complex speech spectra recorded under the same reverberant conditions . Such dereverberated complex speech spectra are used to compute complex FDLP-spectrograms for use in automatic speech recognition.
Leveraging Semantic Information for Efficient Self-Supervised Emotion Recognition with Audio-Textual Distilled Models
May 30, 2023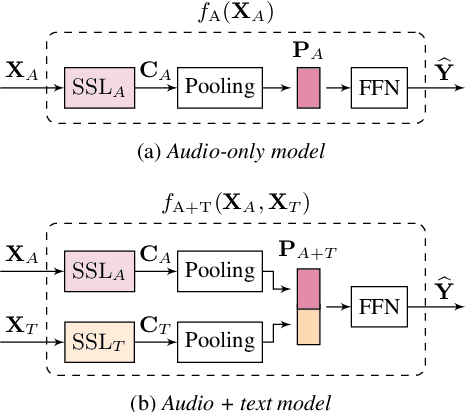
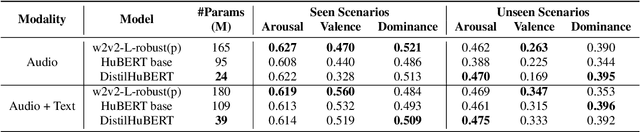
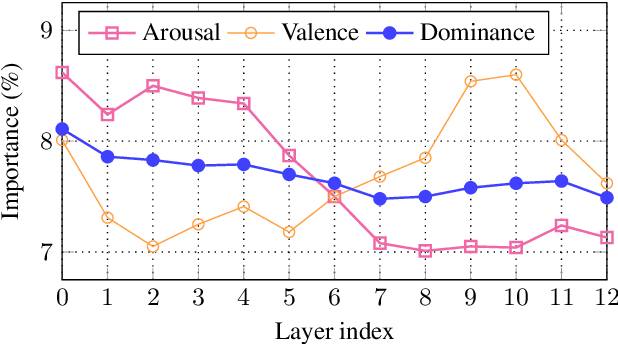

In large part due to their implicit semantic modeling, self-supervised learning (SSL) methods have significantly increased the performance of valence recognition in speech emotion recognition (SER) systems. Yet, their large size may often hinder practical implementations. In this work, we take HuBERT as an example of an SSL model and analyze the relevance of each of its layers for SER. We show that shallow layers are more important for arousal recognition while deeper layers are more important for valence. This observation motivates the importance of additional textual information for accurate valence recognition, as the distilled framework lacks the depth of its large-scale SSL teacher. Thus, we propose an audio-textual distilled SSL framework that, while having only ~20% of the trainable parameters of a large SSL model, achieves on par performance across the three emotion dimensions (arousal, valence, dominance) on the MSP-Podcast v1.10 dataset.
Human-in-the-Loop Hate Speech Classification in a Multilingual Context
Dec 05, 2022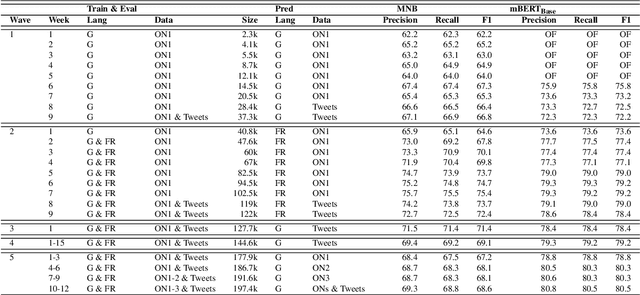
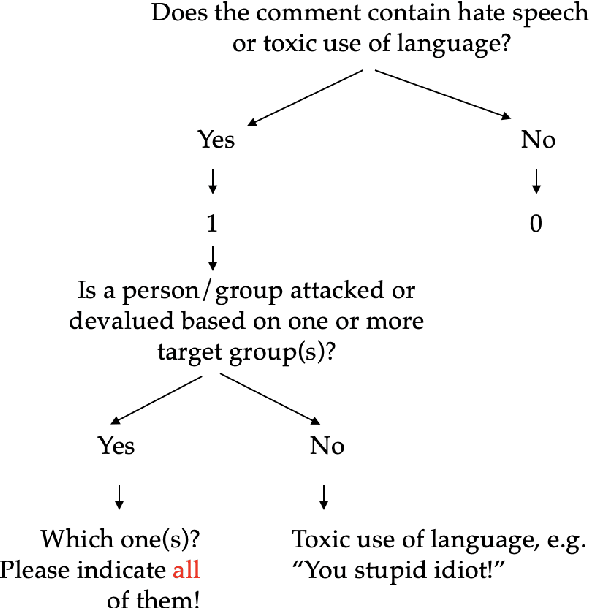


The shift of public debate to the digital sphere has been accompanied by a rise in online hate speech. While many promising approaches for hate speech classification have been proposed, studies often focus only on a single language, usually English, and do not address three key concerns: post-deployment performance, classifier maintenance and infrastructural limitations. In this paper, we introduce a new human-in-the-loop BERT-based hate speech classification pipeline and trace its development from initial data collection and annotation all the way to post-deployment. Our classifier, trained using data from our original corpus of over 422k examples, is specifically developed for the inherently multilingual setting of Switzerland and outperforms with its F1 score of 80.5 the currently best-performing BERT-based multilingual classifier by 5.8 F1 points in German and 3.6 F1 points in French. Our systematic evaluations over a 12-month period further highlight the vital importance of continuous, human-in-the-loop classifier maintenance to ensure robust hate speech classification post-deployment.
Machine Unlearning: A Survey
Jun 06, 2023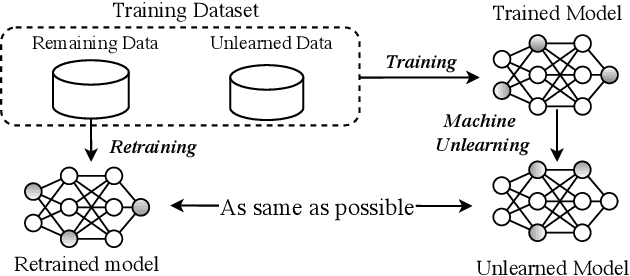
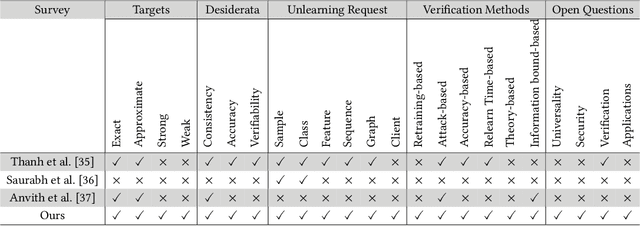
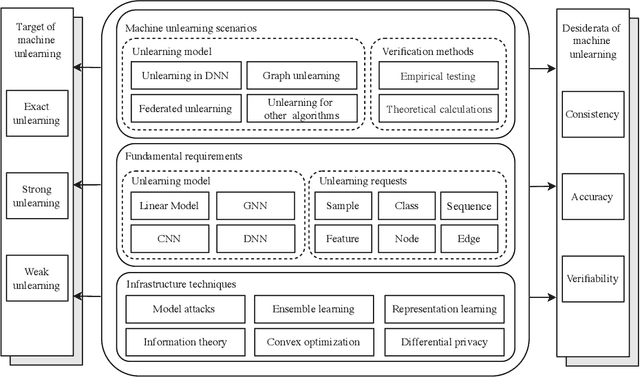
Machine learning has attracted widespread attention and evolved into an enabling technology for a wide range of highly successful applications, such as intelligent computer vision, speech recognition, medical diagnosis, and more. Yet a special need has arisen where, due to privacy, usability, and/or the right to be forgotten, information about some specific samples needs to be removed from a model, called machine unlearning. This emerging technology has drawn significant interest from both academics and industry due to its innovation and practicality. At the same time, this ambitious problem has led to numerous research efforts aimed at confronting its challenges. To the best of our knowledge, no study has analyzed this complex topic or compared the feasibility of existing unlearning solutions in different kinds of scenarios. Accordingly, with this survey, we aim to capture the key concepts of unlearning techniques. The existing solutions are classified and summarized based on their characteristics within an up-to-date and comprehensive review of each category's advantages and limitations. The survey concludes by highlighting some of the outstanding issues with unlearning techniques, along with some feasible directions for new research opportunities.
High Fidelity Speech Enhancement with Band-split RNN
Dec 01, 2022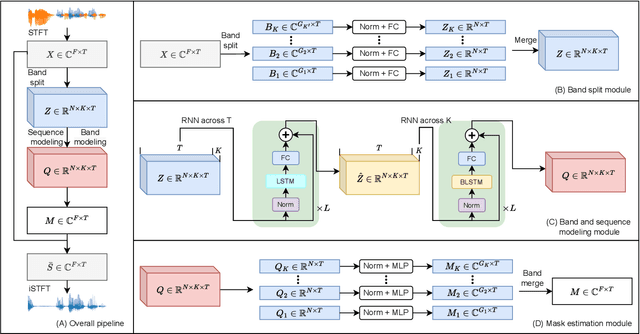
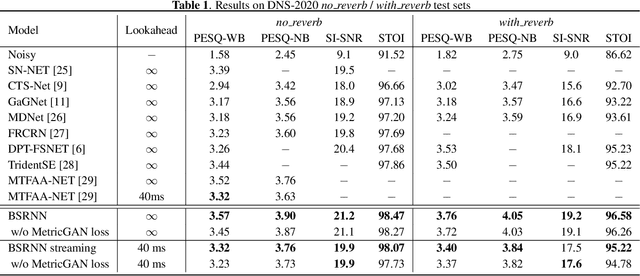
This report presents the development of our speech enhancement system, which includes the use of a recently proposed music separation model, the band-split recurrent neural network (BSRNN), and a MetricGAN-based training objective to improve non-differentiable quality metrics such as perceptual evaluation of speech quality (PESQ) score. Experiment conducted on Interspeech 2021 DNS challenge shows that our BSRNN system outperforms various top-ranking benchmark systems in previous deep noise suppression (DNS) challenges and achieves state-of-the-art (SOTA) result on the DNS-2020 non-blind test set in both offline and online scenarios.
Semantic Segmentation with Bidirectional Language Models Improves Long-form ASR
May 28, 2023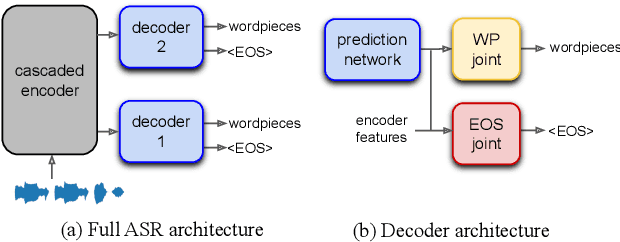
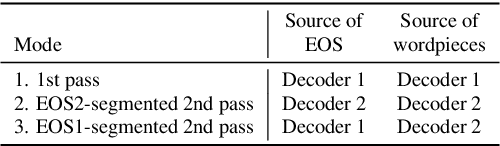
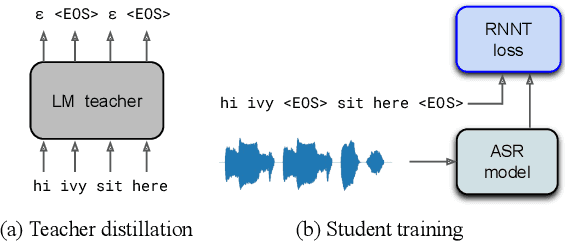
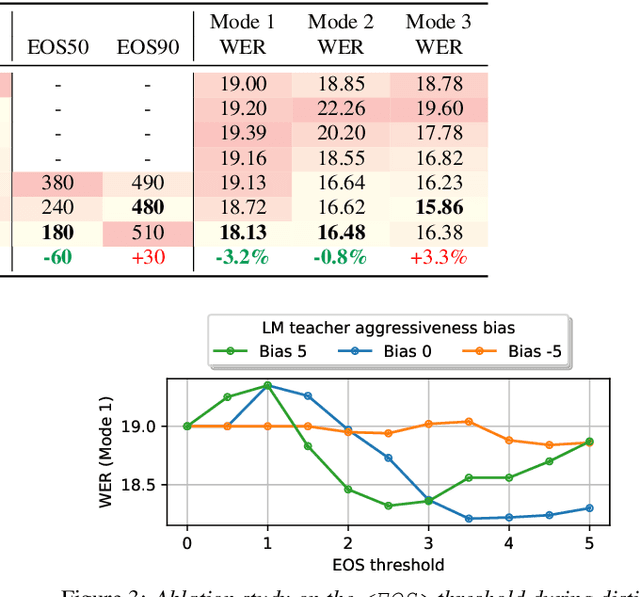
We propose a method of segmenting long-form speech by separating semantically complete sentences within the utterance. This prevents the ASR decoder from needlessly processing faraway context while also preventing it from missing relevant context within the current sentence. Semantically complete sentence boundaries are typically demarcated by punctuation in written text; but unfortunately, spoken real-world utterances rarely contain punctuation. We address this limitation by distilling punctuation knowledge from a bidirectional teacher language model (LM) trained on written, punctuated text. We compare our segmenter, which is distilled from the LM teacher, against a segmenter distilled from a acoustic-pause-based teacher used in other works, on a streaming ASR pipeline. The pipeline with our segmenter achieves a 3.2% relative WER gain along with a 60 ms median end-of-segment latency reduction on a YouTube captioning task.
LongFNT: Long-form Speech Recognition with Factorized Neural Transducer
Nov 17, 2022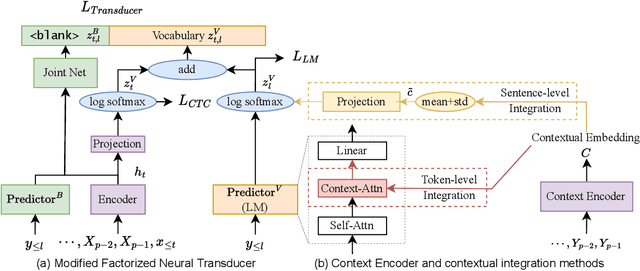
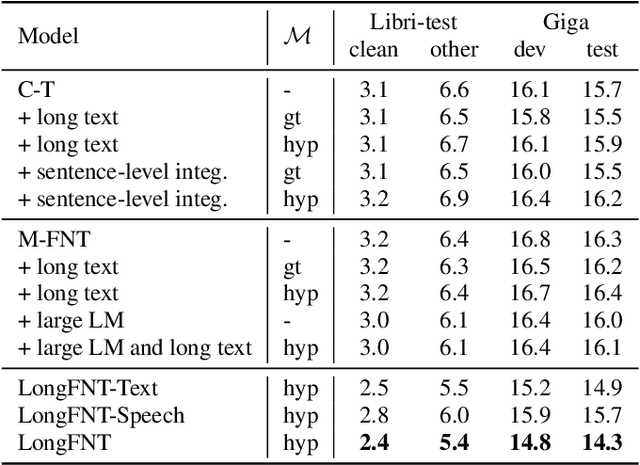
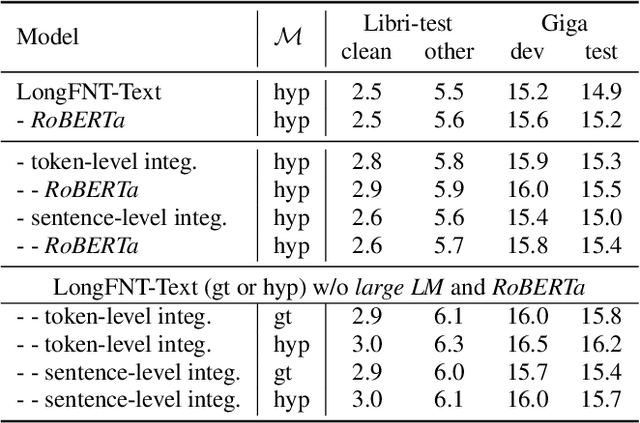

Traditional automatic speech recognition~(ASR) systems usually focus on individual utterances, without considering long-form speech with useful historical information, which is more practical in real scenarios. Simply attending longer transcription history for a vanilla neural transducer model shows no much gain in our preliminary experiments, since the prediction network is not a pure language model. This motivates us to leverage the factorized neural transducer structure, containing a real language model, the vocabulary predictor. We propose the {LongFNT-Text} architecture, which fuses the sentence-level long-form features directly with the output of the vocabulary predictor and then embeds token-level long-form features inside the vocabulary predictor, with a pre-trained contextual encoder RoBERTa to further boost the performance. Moreover, we propose the {LongFNT} architecture by extending the long-form speech to the original speech input and achieve the best performance. The effectiveness of our LongFNT approach is validated on LibriSpeech and GigaSpeech corpora with 19% and 12% relative word error rate~(WER) reduction, respectively.
Improving Autoregressive NLP Tasks via Modular Linearized Attention
Apr 24, 2023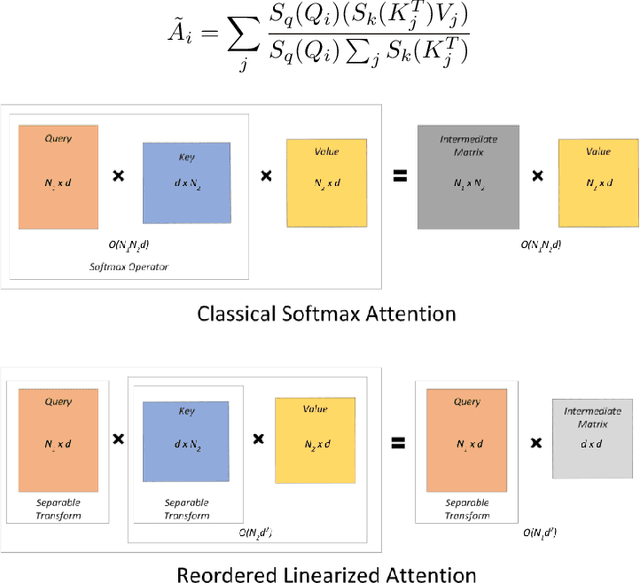
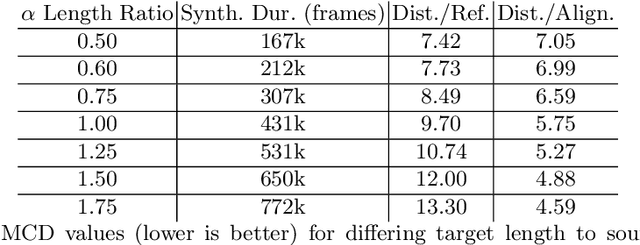
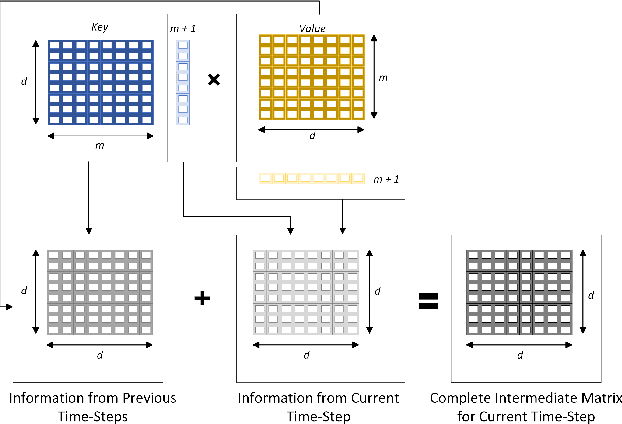
Various natural language processing (NLP) tasks necessitate models that are efficient and small based on their ultimate application at the edge or in other resource-constrained environments. While prior research has reduced the size of these models, increasing computational efficiency without considerable performance impacts remains difficult, especially for autoregressive tasks. This paper proposes {modular linearized attention (MLA), which combines multiple efficient attention mechanisms, including cosFormer, to maximize inference quality while achieving notable speedups. We validate this approach on several autoregressive NLP tasks, including speech-to-text neural machine translation (S2T NMT), speech-to-text simultaneous translation (SimulST), and autoregressive text-to-spectrogram, noting efficiency gains on TTS and competitive performance for NMT and SimulST during training and inference.
Learning to Speak from Text: Zero-Shot Multilingual Text-to-Speech with Unsupervised Text Pretraining
Jan 30, 2023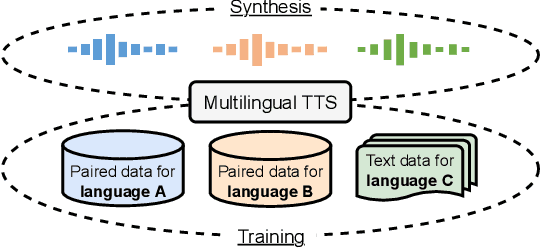
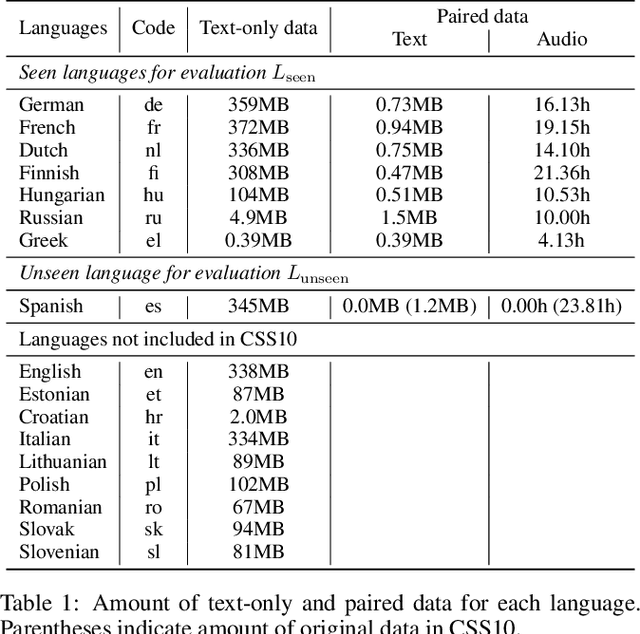
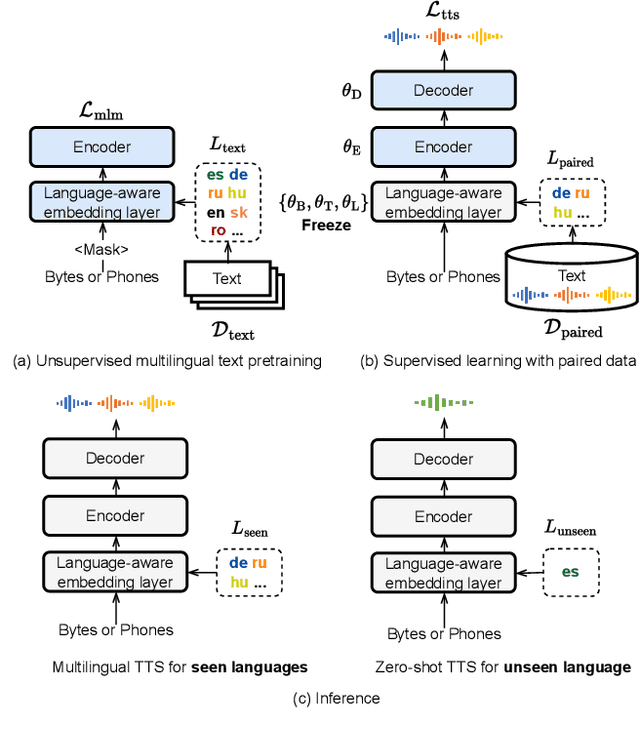
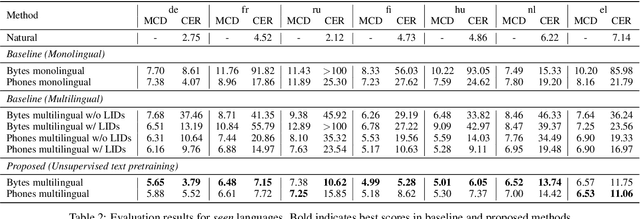
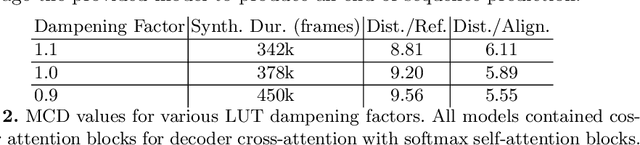
While neural text-to-speech (TTS) has achieved human-like natural synthetic speech, multilingual TTS systems are limited to resource-rich languages due to the need for paired text and studio-quality audio data. This paper proposes a method for zero-shot multilingual TTS using text-only data for the target language. The use of text-only data allows the development of TTS systems for low-resource languages for which only textual resources are available, making TTS accessible to thousands of languages. Inspired by the strong cross-lingual transferability of multilingual language models, our framework first performs masked language model pretraining with multilingual text-only data. Then we train this model with a paired data in a supervised manner, while freezing a language-aware embedding layer. This allows inference even for languages not included in the paired data but present in the text-only data. Evaluation results demonstrate highly intelligible zero-shot TTS with a character error rate of less than 12% for an unseen language. All experiments were conducted using public datasets and the implementation will be made available for reproducibility.
Watch or Listen: Robust Audio-Visual Speech Recognition with Visual Corruption Modeling and Reliability Scoring
Mar 20, 2023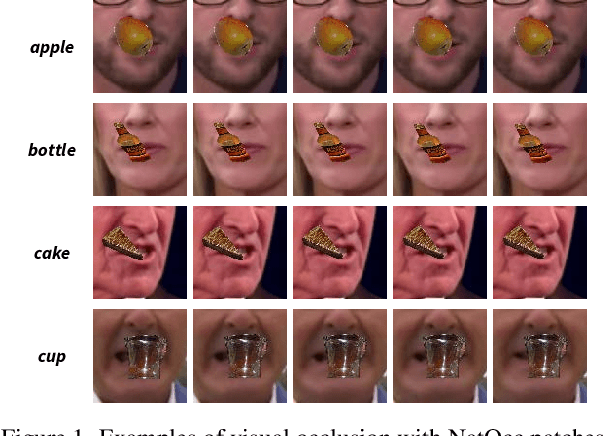
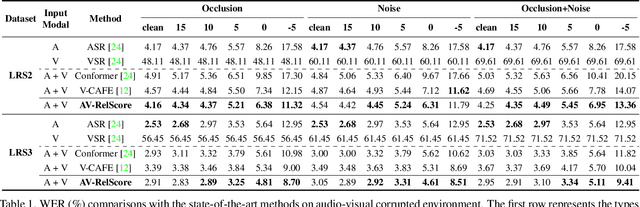


This paper deals with Audio-Visual Speech Recognition (AVSR) under multimodal input corruption situations where audio inputs and visual inputs are both corrupted, which is not well addressed in previous research directions. Previous studies have focused on how to complement the corrupted audio inputs with the clean visual inputs with the assumption of the availability of clean visual inputs. However, in real life, clean visual inputs are not always accessible and can even be corrupted by occluded lip regions or noises. Thus, we firstly analyze that the previous AVSR models are not indeed robust to the corruption of multimodal input streams, the audio and the visual inputs, compared to uni-modal models. Then, we design multimodal input corruption modeling to develop robust AVSR models. Lastly, we propose a novel AVSR framework, namely Audio-Visual Reliability Scoring module (AV-RelScore), that is robust to the corrupted multimodal inputs. The AV-RelScore can determine which input modal stream is reliable or not for the prediction and also can exploit the more reliable streams in prediction. The effectiveness of the proposed method is evaluated with comprehensive experiments on popular benchmark databases, LRS2 and LRS3. We also show that the reliability scores obtained by AV-RelScore well reflect the degree of corruption and make the proposed model focus on the reliable multimodal representations.