 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Pushing the Limits of ChatGPT on NLP Tasks
Jun 16, 2023

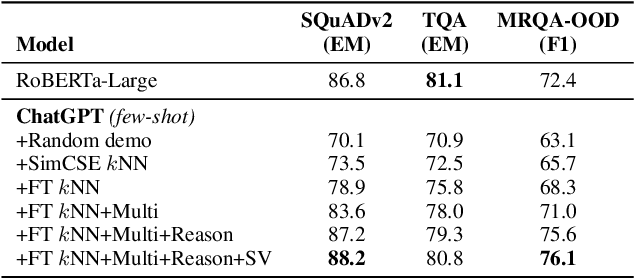
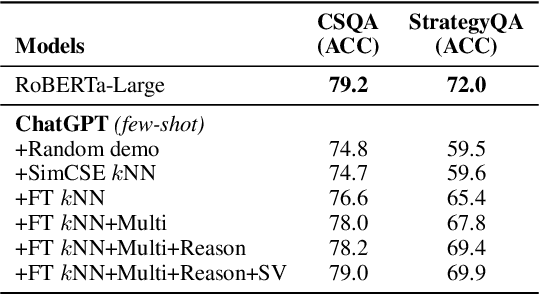
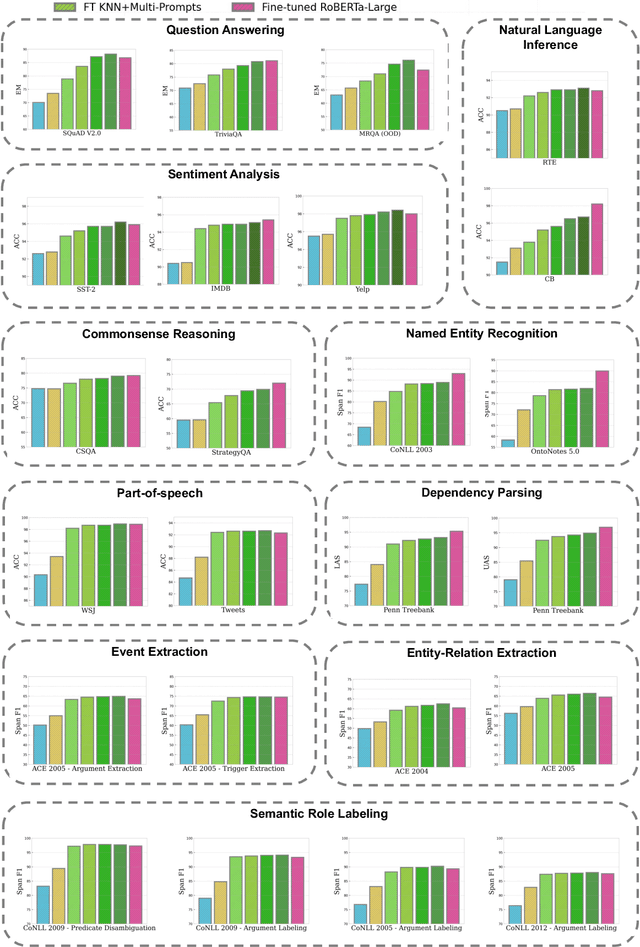
Despite the success of ChatGPT, its performances on most NLP tasks are still well below the supervised baselines. In this work, we looked into the causes, and discovered that its subpar performance was caused by the following factors: (1) token limit in the prompt does not allow for the full utilization of the supervised datasets; (2) mismatch between the generation nature of ChatGPT and NLP tasks; (3) intrinsic pitfalls of LLMs models, e.g., hallucination, overly focus on certain keywords, etc. In this work, we propose a collection of general modules to address these issues, in an attempt to push the limits of ChatGPT on NLP tasks. Our proposed modules include (1) a one-input-multiple-prompts strategy that employs multiple prompts for one input to accommodate more demonstrations; (2) using fine-tuned models for better demonstration retrieval; (3) transforming tasks to formats that are more tailored to the generation nature; (4) employing reasoning strategies that are tailored to addressing the task-specific complexity; (5) the self-verification strategy to address the hallucination issue of LLMs; (6) the paraphrase strategy to improve the robustness of model predictions. We conduct experiments on 21 datasets of 10 representative NLP tasks, including question answering, commonsense reasoning, natural language inference, sentiment analysis, named entity recognition, entity-relation extraction, event extraction, dependency parsing, semantic role labeling, and part-of-speech tagging. Using the proposed assemble of techniques, we are able to significantly boost the performance of ChatGPT on the selected NLP tasks, achieving performances comparable to or better than supervised baselines, or even existing SOTA performances.
Stutter-TTS: Controlled Synthesis and Improved Recognition of Stuttered Speech
Nov 04, 2022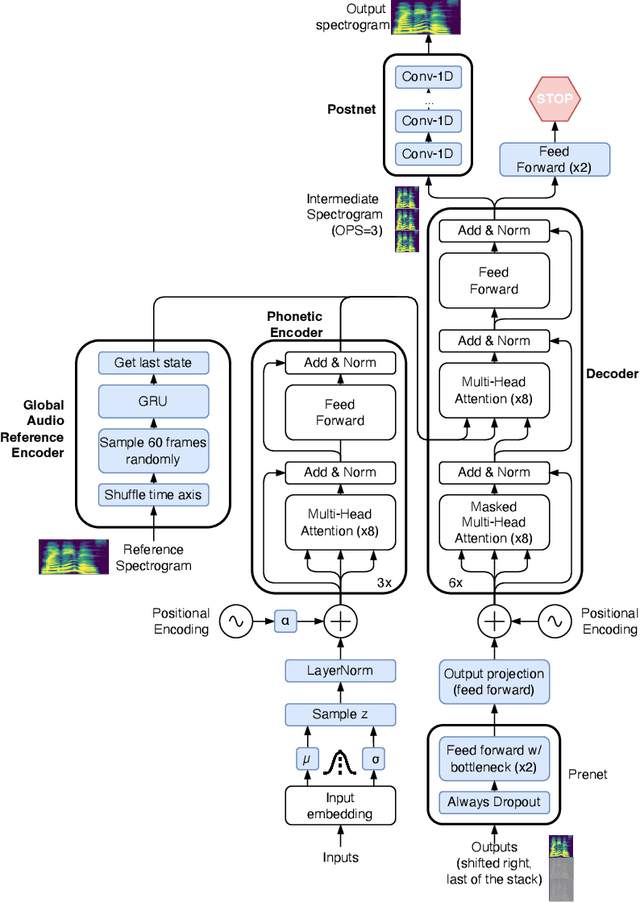

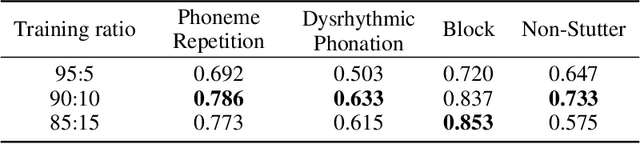
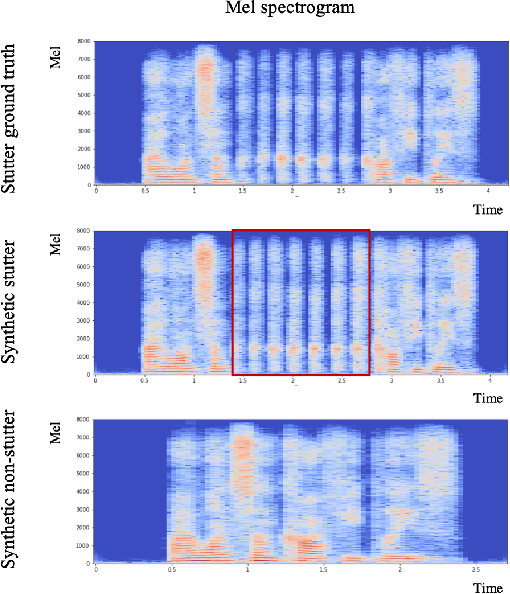
Stuttering is a speech disorder where the natural flow of speech is interrupted by blocks, repetitions or prolongations of syllables, words and phrases. The majority of existing automatic speech recognition (ASR) interfaces perform poorly on utterances with stutter, mainly due to lack of matched training data. Synthesis of speech with stutter thus presents an opportunity to improve ASR for this type of speech. We describe Stutter-TTS, an end-to-end neural text-to-speech model capable of synthesizing diverse types of stuttering utterances. We develop a simple, yet effective prosody-control strategy whereby additional tokens are introduced into source text during training to represent specific stuttering characteristics. By choosing the position of the stutter tokens, Stutter-TTS allows word-level control of where stuttering occurs in the synthesized utterance. We are able to synthesize stutter events with high accuracy (F1-scores between 0.63 and 0.84, depending on stutter type). By fine-tuning an ASR model on synthetic stuttered speech we are able to reduce word error by 5.7% relative on stuttered utterances, with only minor (<0.2% relative) degradation for fluent utterances.
* 8 pages, 3 figures, 2 tables
Utilizing Longitudinal Chest X-Rays and Reports to Pre-Fill Radiology Reports
Jun 14, 2023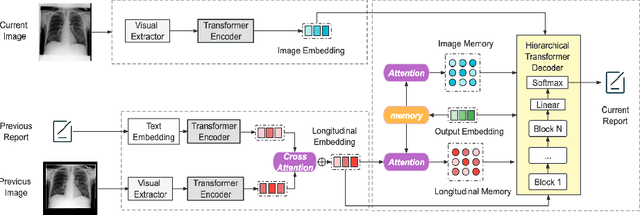

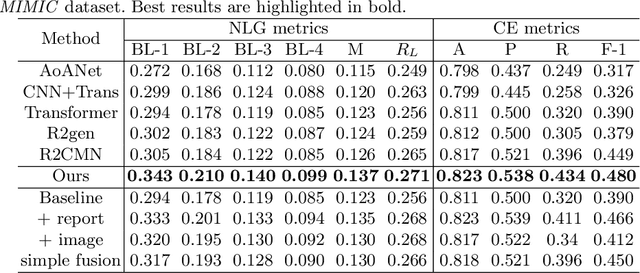

Despite the reduction in turn-around times in radiology reports with the use of speech recognition software, persistent communication errors can significantly impact the interpretation of the radiology report. Pre-filling a radiology report holds promise in mitigating reporting errors, and despite efforts in the literature to generate medical reports, there exists a lack of approaches that exploit the longitudinal nature of patient visit records in the MIMIC-CXR dataset. To address this gap, we propose to use longitudinal multi-modal data, i.e., previous patient visit CXR, current visit CXR, and previous visit report, to pre-fill the 'findings' section of a current patient visit report. We first gathered the longitudinal visit information for 26,625 patients from the MIMIC-CXR dataset and created a new dataset called Longitudinal-MIMIC. With this new dataset, a transformer-based model was trained to capture the information from longitudinal patient visit records containing multi-modal data (CXR images + reports) via a cross-attention-based multi-modal fusion module and a hierarchical memory-driven decoder. In contrast to previous work that only uses current visit data as input to train a model, our work exploits the longitudinal information available to pre-fill the 'findings' section of radiology reports. Experiments show that our approach outperforms several recent approaches by >=3% on F1 score, and >=2% for BLEU-4, METEOR and ROUGE-L respectively. The dataset and code will be made publicly available.
Blind Signal Dereverberation for Machine Speech Recognition
Sep 30, 2022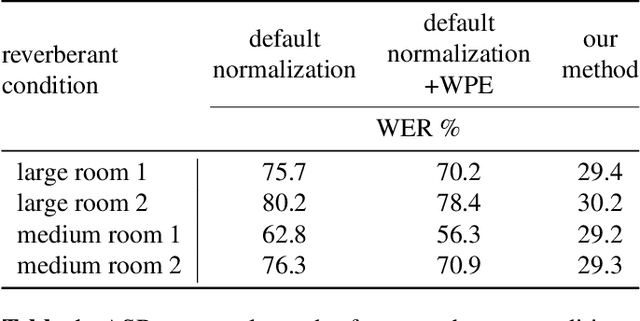
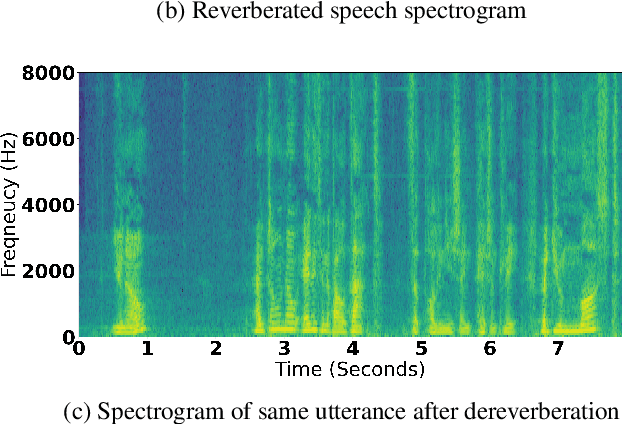
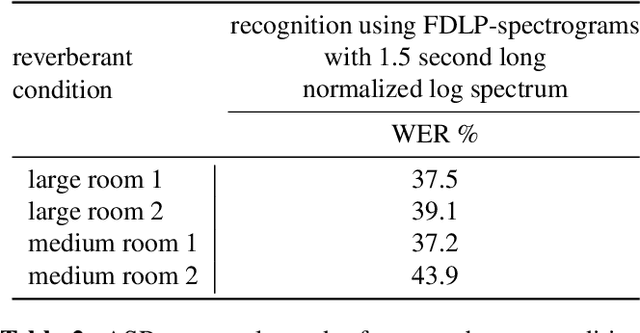
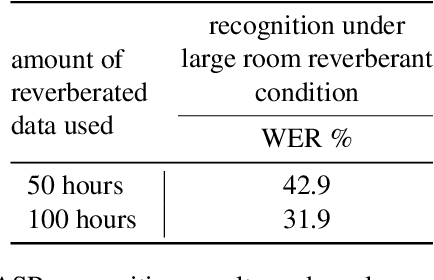
We present a method to remove unknown convolutive noise introduced to speech by reverberations of recording environments, utilizing some amount of training speech data from the reverberant environment, and any available non-reverberant speech data. Using Fourier transform computed over long temporal windows, which ideally cover the entire room impulse response, we convert room induced convolution to additions in the log spectral domain. Next, we compute a spectral normalization vector from statistics gathered over reverberated as well as over clean speech in the log spectral domain. During operation, this normalization vectors are used to alleviate reverberations from complex speech spectra recorded under the same reverberant conditions . Such dereverberated complex speech spectra are used to compute complex FDLP-spectrograms for use in automatic speech recognition.
Context-aware Fine-tuning of Self-supervised Speech Models
Dec 16, 2022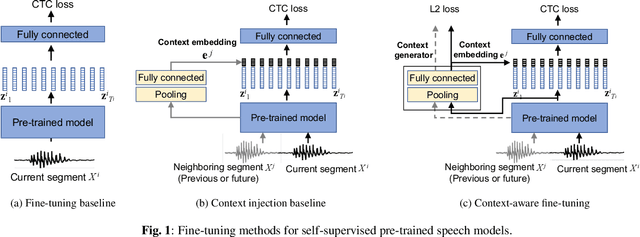
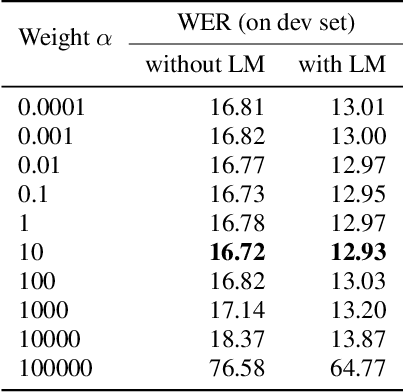
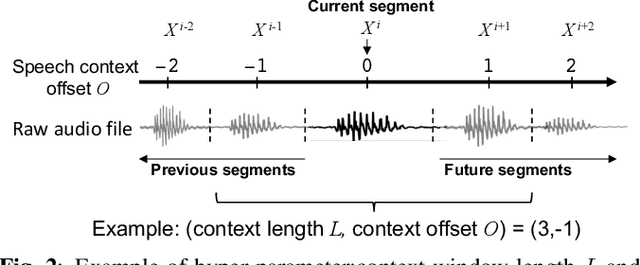
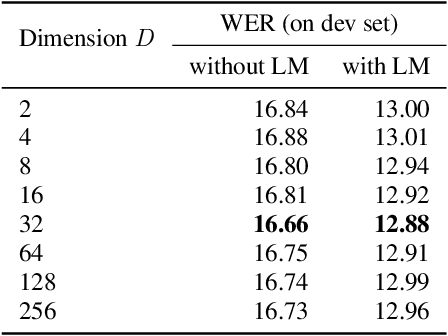
Self-supervised pre-trained transformers have improved the state of the art on a variety of speech tasks. Due to the quadratic time and space complexity of self-attention, they usually operate at the level of relatively short (e.g., utterance) segments. In this paper, we study the use of context, i.e., surrounding segments, during fine-tuning and propose a new approach called context-aware fine-tuning. We attach a context module on top of the last layer of a pre-trained model to encode the whole segment into a context embedding vector which is then used as an additional feature for the final prediction. During the fine-tuning stage, we introduce an auxiliary loss that encourages this context embedding vector to be similar to context vectors of surrounding segments. This allows the model to make predictions without access to these surrounding segments at inference time and requires only a tiny overhead compared to standard fine-tuned models. We evaluate the proposed approach using the SLUE and Librilight benchmarks for several downstream tasks: Automatic speech recognition (ASR), named entity recognition (NER), and sentiment analysis (SA). The results show that context-aware fine-tuning not only outperforms a standard fine-tuning baseline but also rivals a strong context injection baseline that uses neighboring speech segments during inference.
EarSpy: Spying Caller Speech and Identity through Tiny Vibrations of Smartphone Ear Speakers
Dec 23, 2022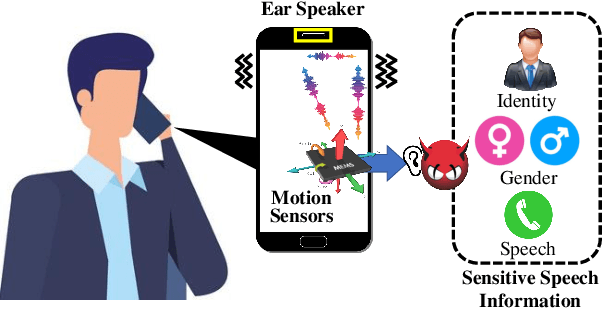
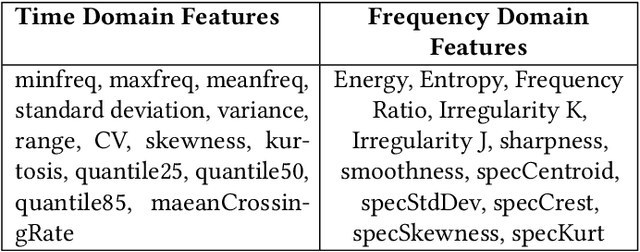
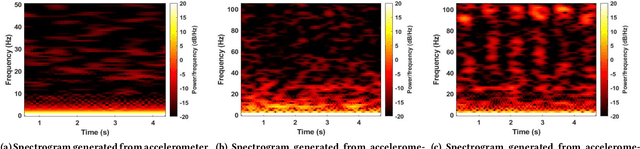
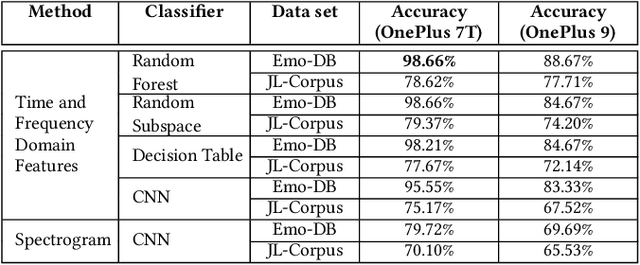
Eavesdropping from the user's smartphone is a well-known threat to the user's safety and privacy. Existing studies show that loudspeaker reverberation can inject speech into motion sensor readings, leading to speech eavesdropping. While more devastating attacks on ear speakers, which produce much smaller scale vibrations, were believed impossible to eavesdrop with zero-permission motion sensors. In this work, we revisit this important line of reach. We explore recent trends in smartphone manufacturers that include extra/powerful speakers in place of small ear speakers, and demonstrate the feasibility of using motion sensors to capture such tiny speech vibrations. We investigate the impacts of these new ear speakers on built-in motion sensors and examine the potential to elicit private speech information from the minute vibrations. Our designed system EarSpy can successfully detect word regions, time, and frequency domain features and generate a spectrogram for each word region. We train and test the extracted data using classical machine learning algorithms and convolutional neural networks. We found up to 98.66% accuracy in gender detection, 92.6% detection in speaker detection, and 56.42% detection in digit detection (which is 5X more significant than the random selection (10%)). Our result unveils the potential threat of eavesdropping on phone conversations from ear speakers using motion sensors.
Human-in-the-Loop Hate Speech Classification in a Multilingual Context
Dec 05, 2022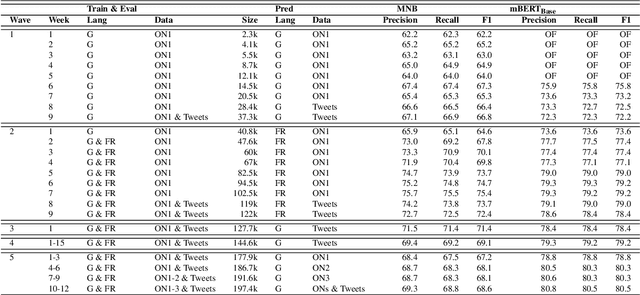


The shift of public debate to the digital sphere has been accompanied by a rise in online hate speech. While many promising approaches for hate speech classification have been proposed, studies often focus only on a single language, usually English, and do not address three key concerns: post-deployment performance, classifier maintenance and infrastructural limitations. In this paper, we introduce a new human-in-the-loop BERT-based hate speech classification pipeline and trace its development from initial data collection and annotation all the way to post-deployment. Our classifier, trained using data from our original corpus of over 422k examples, is specifically developed for the inherently multilingual setting of Switzerland and outperforms with its F1 score of 80.5 the currently best-performing BERT-based multilingual classifier by 5.8 F1 points in German and 3.6 F1 points in French. Our systematic evaluations over a 12-month period further highlight the vital importance of continuous, human-in-the-loop classifier maintenance to ensure robust hate speech classification post-deployment.
Encoder-decoder multimodal speaker change detection
Jun 01, 2023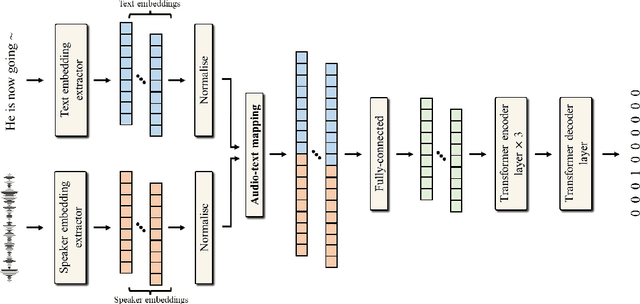

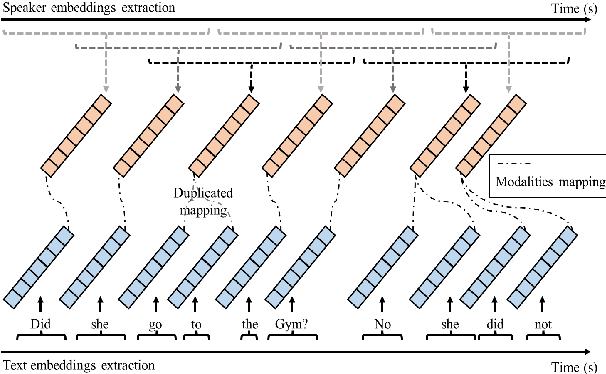

The task of speaker change detection (SCD), which detects points where speakers change in an input, is essential for several applications. Several studies solved the SCD task using audio inputs only and have shown limited performance. Recently, multimodal SCD (MMSCD) models, which utilise text modality in addition to audio, have shown improved performance. In this study, the proposed model are built upon two main proposals, a novel mechanism for modality fusion and the adoption of a encoder-decoder architecture. Different to previous MMSCD works that extract speaker embeddings from extremely short audio segments, aligned to a single word, we use a speaker embedding extracted from 1.5s. A transformer decoder layer further improves the performance of an encoder-only MMSCD model. The proposed model achieves state-of-the-art results among studies that report SCD performance and is also on par with recent work that combines SCD with automatic speech recognition via human transcription.
Enhancing the Unified Streaming and Non-streaming Model with Contrastive Learning
Jun 01, 2023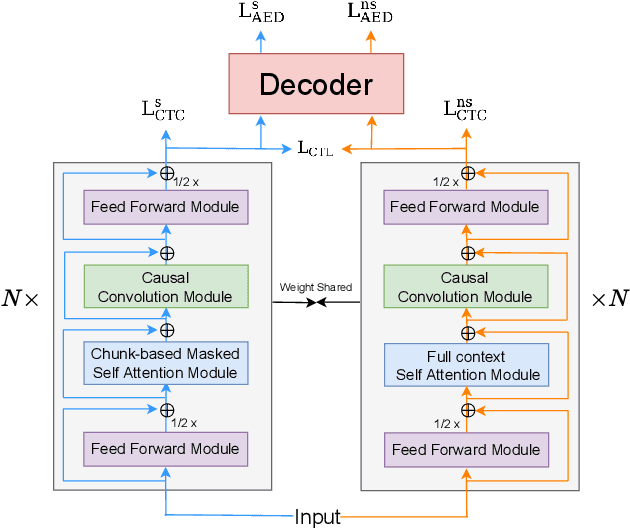

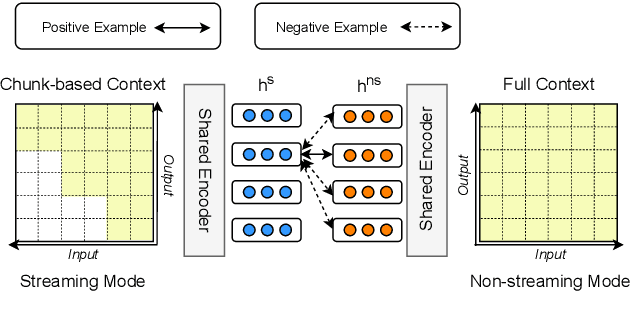

The unified streaming and non-streaming speech recognition model has achieved great success due to its comprehensive capabilities. In this paper, we propose to improve the accuracy of the unified model by bridging the inherent representation gap between the streaming and non-streaming modes with a contrastive objective. Specifically, the top-layer hidden representation at the same frame of the streaming and non-streaming modes are regarded as a positive pair, encouraging the representation of the streaming mode close to its non-streaming counterpart. The multiple negative samples are randomly selected from the rest frames of the same sample under the non-streaming mode. Experimental results demonstrate that the proposed method achieves consistent improvements toward the unified model in both streaming and non-streaming modes. Our method achieves CER of 4.66% in the streaming mode and CER of 4.31% in the non-streaming mode, which sets a new state-of-the-art on the AISHELL-1 benchmark.
Stuttering Detection Using Speaker Representations and Self-supervised Contextual Embeddings
Jun 01, 2023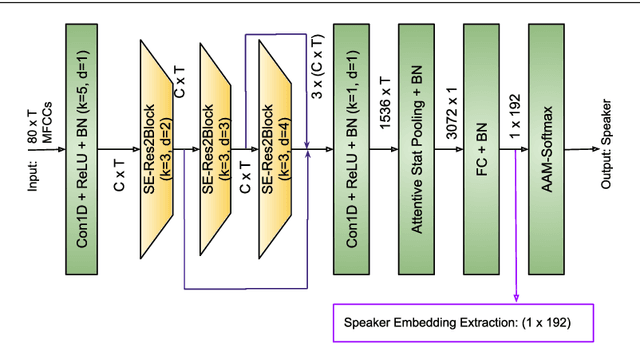
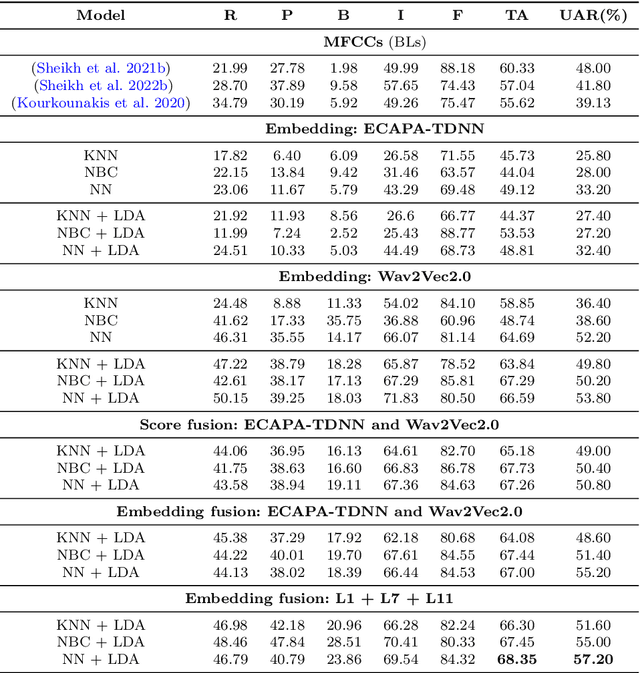
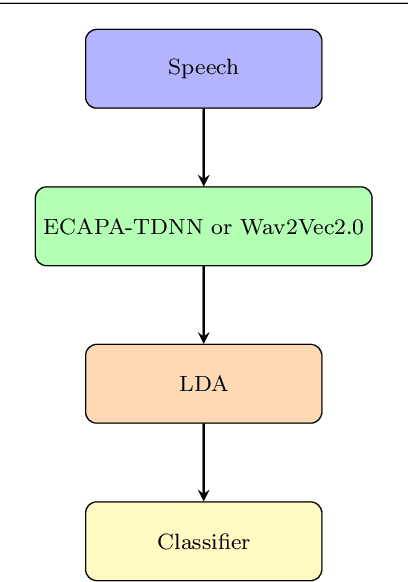
The adoption of advanced deep learning architectures in stuttering detection (SD) tasks is challenging due to the limited size of the available datasets. To this end, this work introduces the application of speech embeddings extracted from pre-trained deep learning models trained on large audio datasets for different tasks. In particular, we explore audio representations obtained using emphasized channel attention, propagation, and aggregation time delay neural network (ECAPA-TDNN) and Wav2Vec2.0 models trained on VoxCeleb and LibriSpeech datasets respectively. After extracting the embeddings, we benchmark with several traditional classifiers, such as the K-nearest neighbour (KNN), Gaussian naive Bayes, and neural network, for the SD tasks. In comparison to the standard SD systems trained only on the limited SEP-28k dataset, we obtain a relative improvement of 12.08%, 28.71%, 37.9% in terms of unweighted average recall (UAR) over the baselines. Finally, we have shown that combining two embeddings and concatenating multiple layers of Wav2Vec2.0 can further improve the UAR by up to 2.60% and 6.32% respectively.