 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Leveraging Redundancy in Multiple Audio Signals for Far-Field Speech Recognition
Mar 01, 2023
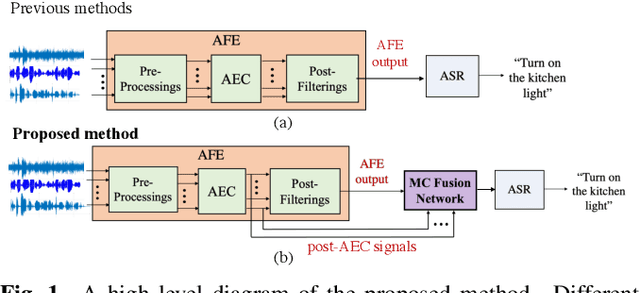

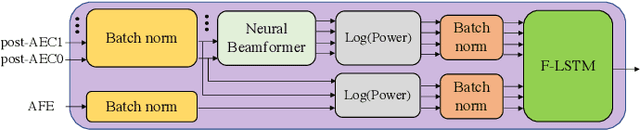
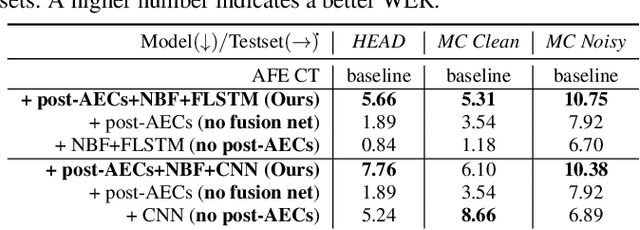
To achieve robust far-field automatic speech recognition (ASR), existing techniques typically employ an acoustic front end (AFE) cascaded with a neural transducer (NT) ASR model. The AFE output, however, could be unreliable, as the beamforming output in AFE is steered to a wrong direction. A promising way to address this issue is to exploit the microphone signals before the beamforming stage and after the acoustic echo cancellation (post-AEC) in AFE. We argue that both, post-AEC and AFE outputs, are complementary and it is possible to leverage the redundancy between these signals to compensate for potential AFE processing errors. We present two fusion networks to explore this redundancy and aggregate these multi-channel (MC) signals: (1) Frequency-LSTM based, and (2) Convolutional Neural Network based fusion networks. We augment the MC fusion networks to a conformer transducer model and train it in an end-to-end fashion. Our experimental results on commercial virtual assistant tasks demonstrate that using the AFE output and two post-AEC signals with fusion networks offers up to 25.9% word error rate (WER) relative improvement over the model using the AFE output only, at the cost of <= 2% parameter increase.
Improved DeepFake Detection Using Whisper Features
Jun 02, 2023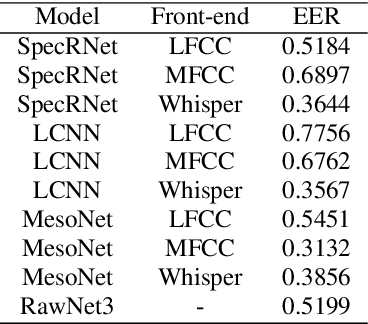
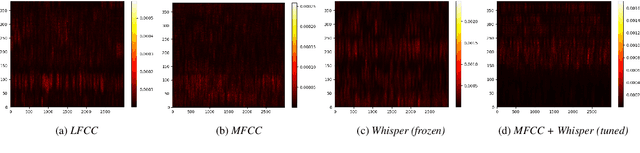

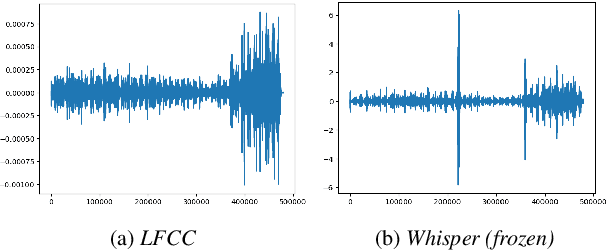
With a recent influx of voice generation methods, the threat introduced by audio DeepFake (DF) is ever-increasing. Several different detection methods have been presented as a countermeasure. Many methods are based on so-called front-ends, which, by transforming the raw audio, emphasize features crucial for assessing the genuineness of the audio sample. Our contribution contains investigating the influence of the state-of-the-art Whisper automatic speech recognition model as a DF detection front-end. We compare various combinations of Whisper and well-established front-ends by training 3 detection models (LCNN, SpecRNet, and MesoNet) on a widely used ASVspoof 2021 DF dataset and later evaluating them on the DF In-The-Wild dataset. We show that using Whisper-based features improves the detection for each model and outperforms recent results on the In-The-Wild dataset by reducing Equal Error Rate by 21%.
Efficient Spoken Language Recognition via Multilabel Classification
Jun 02, 2023
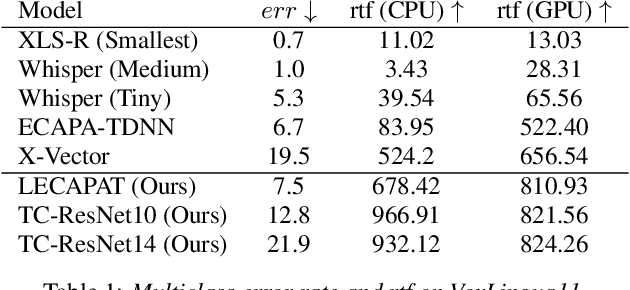
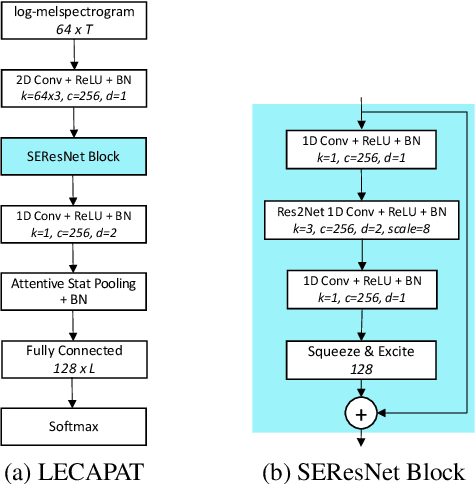
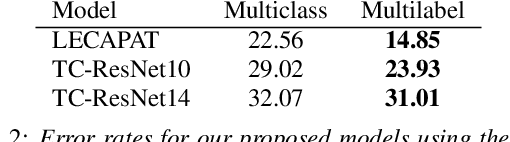
Spoken language recognition (SLR) is the task of automatically identifying the language present in a speech signal. Existing SLR models are either too computationally expensive or too large to run effectively on devices with limited resources. For real-world deployment, a model should also gracefully handle unseen languages outside of the target language set, yet prior work has focused on closed-set classification where all input languages are known a-priori. In this paper we address these two limitations: we explore efficient model architectures for SLR based on convolutional networks, and propose a multilabel training strategy to handle non-target languages at inference time. Using the VoxLingua107 dataset, we show that our models obtain competitive results while being orders of magnitude smaller and faster than current state-of-the-art methods, and that our multilabel strategy is more robust to unseen non-target languages compared to multiclass classification.
Can Contextual Biasing Remain Effective with Whisper and GPT-2?
Jun 02, 2023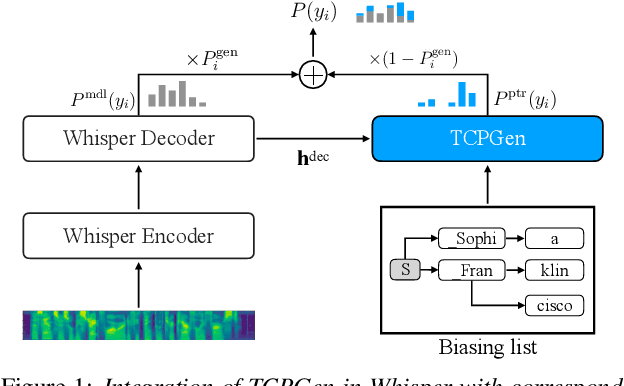
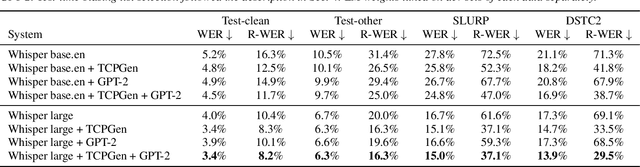


End-to-end automatic speech recognition (ASR) and large language models, such as Whisper and GPT-2, have recently been scaled to use vast amounts of training data. Despite the large amount of training data, infrequent content words that occur in a particular task may still exhibit poor ASR performance, with contextual biasing a possible remedy. This paper investigates the effectiveness of neural contextual biasing for Whisper combined with GPT-2. Specifically, this paper proposes integrating an adapted tree-constrained pointer generator (TCPGen) component for Whisper and a dedicated training scheme to dynamically adjust the final output without modifying any Whisper model parameters. Experiments across three datasets show a considerable reduction in errors on biasing words with a biasing list of 1000 words. Contextual biasing was more effective when applied to domain-specific data and can boost the performance of Whisper and GPT-2 without losing their generality.
Context-aware Fine-tuning of Self-supervised Speech Models
Dec 16, 2022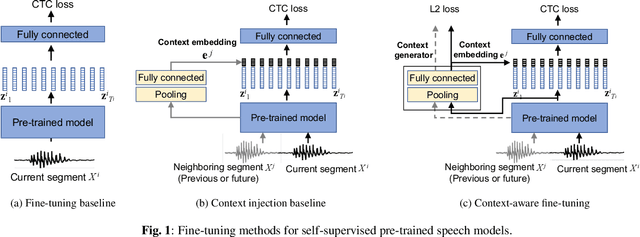
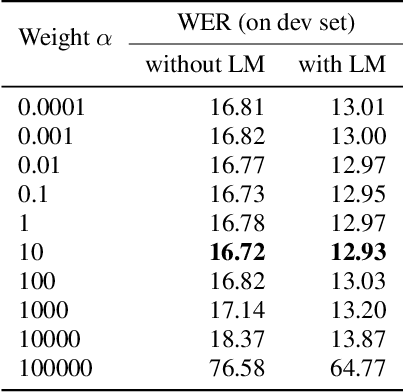
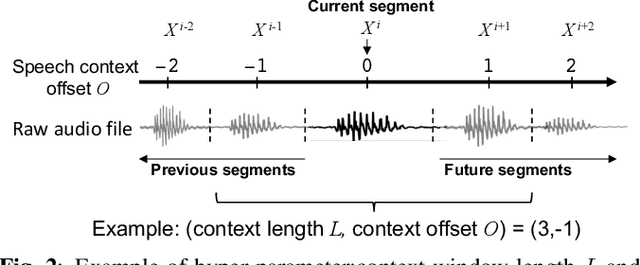
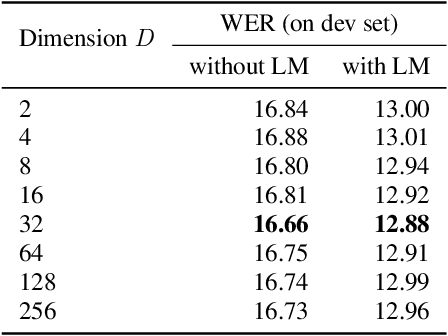
Self-supervised pre-trained transformers have improved the state of the art on a variety of speech tasks. Due to the quadratic time and space complexity of self-attention, they usually operate at the level of relatively short (e.g., utterance) segments. In this paper, we study the use of context, i.e., surrounding segments, during fine-tuning and propose a new approach called context-aware fine-tuning. We attach a context module on top of the last layer of a pre-trained model to encode the whole segment into a context embedding vector which is then used as an additional feature for the final prediction. During the fine-tuning stage, we introduce an auxiliary loss that encourages this context embedding vector to be similar to context vectors of surrounding segments. This allows the model to make predictions without access to these surrounding segments at inference time and requires only a tiny overhead compared to standard fine-tuned models. We evaluate the proposed approach using the SLUE and Librilight benchmarks for several downstream tasks: Automatic speech recognition (ASR), named entity recognition (NER), and sentiment analysis (SA). The results show that context-aware fine-tuning not only outperforms a standard fine-tuning baseline but also rivals a strong context injection baseline that uses neighboring speech segments during inference.
Stabilising and accelerating light gated recurrent units for automatic speech recognition
Feb 16, 2023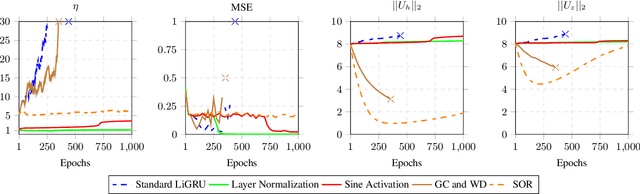

The light gated recurrent units (Li-GRU) is well-known for achieving impressive results in automatic speech recognition (ASR) tasks while being lighter and faster to train than a standard gated recurrent units (GRU). However, the unbounded nature of its rectified linear unit on the candidate recurrent gate induces an important gradient exploding phenomenon disrupting the training process and preventing it from being applied to famous datasets. In this paper, we theoretically and empirically derive the necessary conditions for its stability as well as engineering mechanisms to speed up by a factor of five its training time, hence introducing a novel version of this architecture named SLi-GRU. Then, we evaluate its performance both on a toy task illustrating its newly acquired capabilities and a set of three different ASR datasets demonstrating lower word error rates compared to more complex recurrent neural networks.
Looking Similar, Sounding Different: Leveraging Counterfactual Cross-Modal Pairs for Audiovisual Representation Learning
Apr 12, 2023

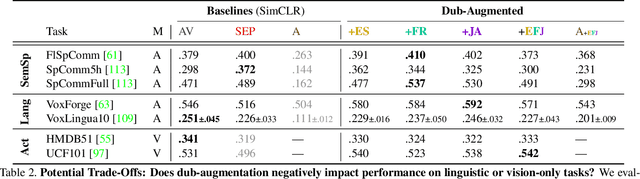

Audiovisual representation learning typically relies on the correspondence between sight and sound. However, there are often multiple audio tracks that can correspond with a visual scene. Consider, for example, different conversations on the same crowded street. The effect of such counterfactual pairs on audiovisual representation learning has not been previously explored. To investigate this, we use dubbed versions of movies to augment cross-modal contrastive learning. Our approach learns to represent alternate audio tracks, differing only in speech content, similarly to the same video. Our results show that dub-augmented training improves performance on a range of auditory and audiovisual tasks, without significantly affecting linguistic task performance overall. We additionally compare this approach to a strong baseline where we remove speech before pretraining, and find that dub-augmented training is more effective, including for paralinguistic and audiovisual tasks where speech removal leads to worse performance. These findings highlight the importance of considering speech variation when learning scene-level audiovisual correspondences and suggest that dubbed audio can be a useful augmentation technique for training audiovisual models toward more robust performance.
Human-in-the-Loop Hate Speech Classification in a Multilingual Context
Dec 05, 2022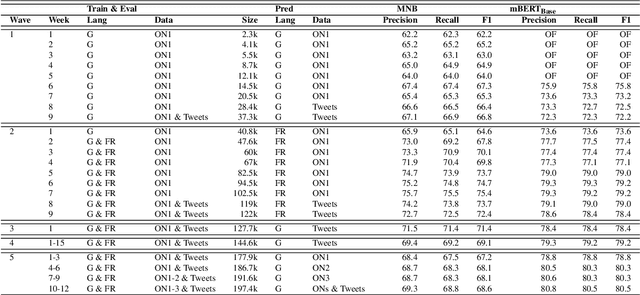
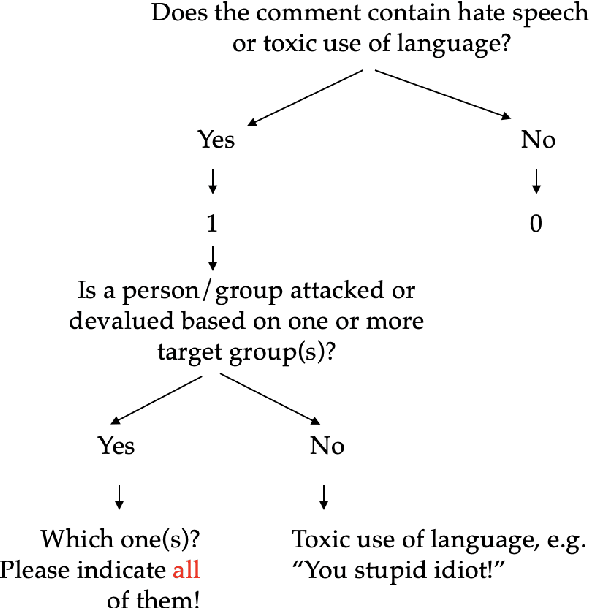


The shift of public debate to the digital sphere has been accompanied by a rise in online hate speech. While many promising approaches for hate speech classification have been proposed, studies often focus only on a single language, usually English, and do not address three key concerns: post-deployment performance, classifier maintenance and infrastructural limitations. In this paper, we introduce a new human-in-the-loop BERT-based hate speech classification pipeline and trace its development from initial data collection and annotation all the way to post-deployment. Our classifier, trained using data from our original corpus of over 422k examples, is specifically developed for the inherently multilingual setting of Switzerland and outperforms with its F1 score of 80.5 the currently best-performing BERT-based multilingual classifier by 5.8 F1 points in German and 3.6 F1 points in French. Our systematic evaluations over a 12-month period further highlight the vital importance of continuous, human-in-the-loop classifier maintenance to ensure robust hate speech classification post-deployment.
EarSpy: Spying Caller Speech and Identity through Tiny Vibrations of Smartphone Ear Speakers
Dec 23, 2022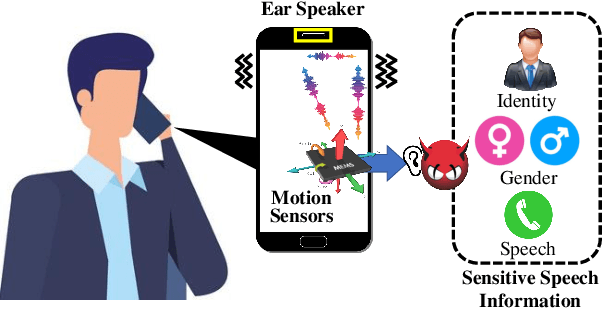
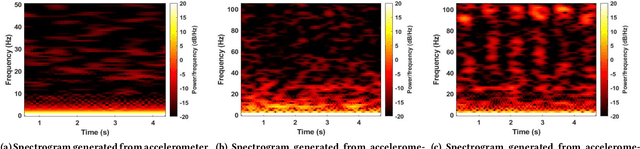
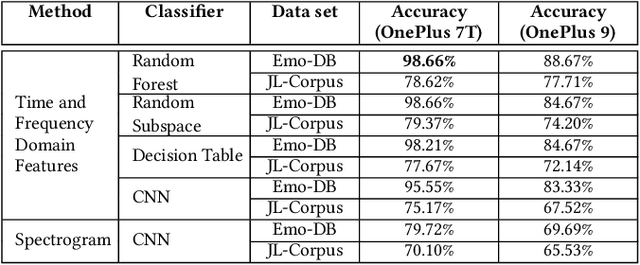
Eavesdropping from the user's smartphone is a well-known threat to the user's safety and privacy. Existing studies show that loudspeaker reverberation can inject speech into motion sensor readings, leading to speech eavesdropping. While more devastating attacks on ear speakers, which produce much smaller scale vibrations, were believed impossible to eavesdrop with zero-permission motion sensors. In this work, we revisit this important line of reach. We explore recent trends in smartphone manufacturers that include extra/powerful speakers in place of small ear speakers, and demonstrate the feasibility of using motion sensors to capture such tiny speech vibrations. We investigate the impacts of these new ear speakers on built-in motion sensors and examine the potential to elicit private speech information from the minute vibrations. Our designed system EarSpy can successfully detect word regions, time, and frequency domain features and generate a spectrogram for each word region. We train and test the extracted data using classical machine learning algorithms and convolutional neural networks. We found up to 98.66% accuracy in gender detection, 92.6% detection in speaker detection, and 56.42% detection in digit detection (which is 5X more significant than the random selection (10%)). Our result unveils the potential threat of eavesdropping on phone conversations from ear speakers using motion sensors.
High Fidelity Speech Enhancement with Band-split RNN
Dec 01, 2022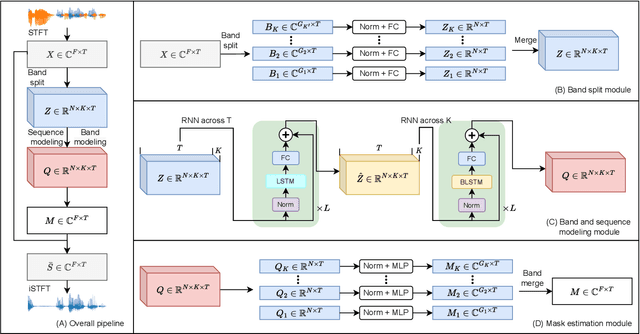
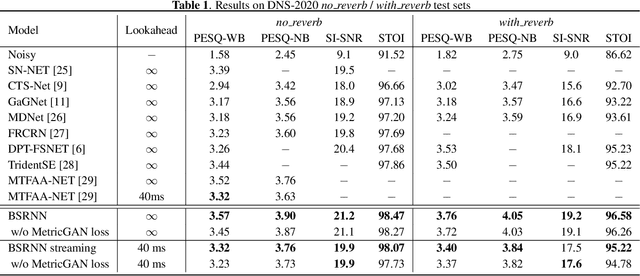
This report presents the development of our speech enhancement system, which includes the use of a recently proposed music separation model, the band-split recurrent neural network (BSRNN), and a MetricGAN-based training objective to improve non-differentiable quality metrics such as perceptual evaluation of speech quality (PESQ) score. Experiment conducted on Interspeech 2021 DNS challenge shows that our BSRNN system outperforms various top-ranking benchmark systems in previous deep noise suppression (DNS) challenges and achieves state-of-the-art (SOTA) result on the DNS-2020 non-blind test set in both offline and online scenarios.