 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speech Enhancement with Intelligent Neural Homomorphic Synthesis
Oct 28, 2022
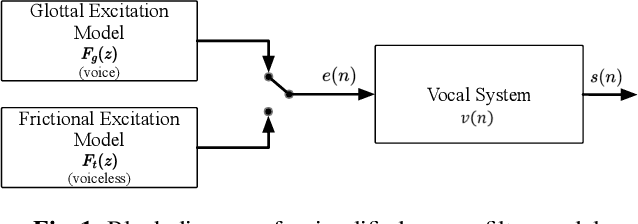
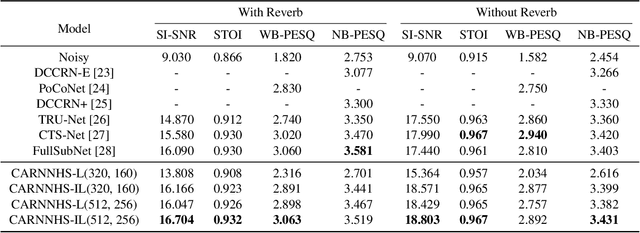

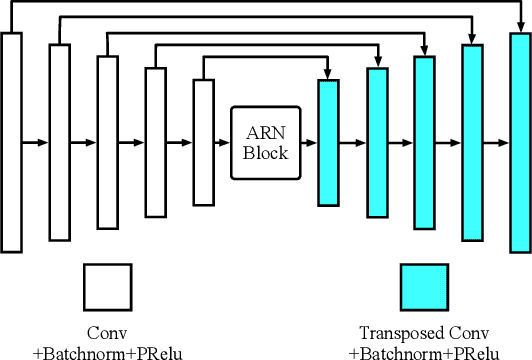
Most neural network speech enhancement models ignore speech production mathematical models by directly mapping Fourier transform spectrums or waveforms. In this work, we propose a neural source filter network for speech enhancement. Specifically, we use homomorphic signal processing and cepstral analysis to obtain noisy speech's excitation and vocal tract. Unlike traditional signal processing, we use an attentive recurrent network (ARN) model predicted ratio mask to replace the liftering separation function. Then two convolutional attentive recurrent network (CARN) networks are used to predict the excitation and vocal tract of clean speech, respectively. The system's output is synthesized from the estimated excitation and vocal. Experiments prove that our proposed method performs better, with SI-SNR improving by 1.363dB compared to FullSubNet.
Adversarial Speaker-Consistency Learning Using Untranscribed Speech Data for Zero-Shot Multi-Speaker Text-to-Speech
Oct 12, 2022
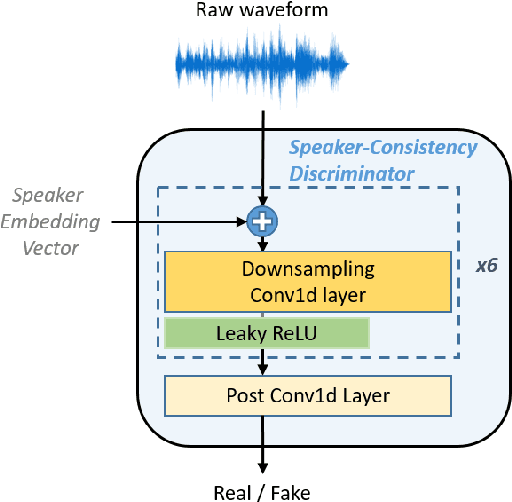
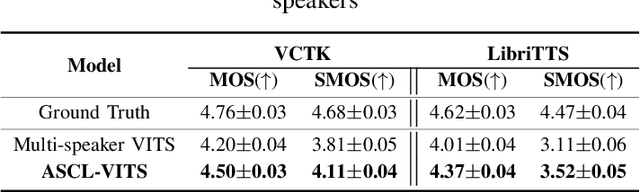
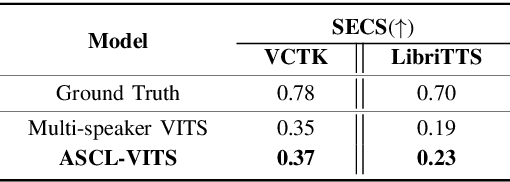
Several recently proposed text-to-speech (TTS) models achieved to generate the speech samples with the human-level quality in the single-speaker and multi-speaker TTS scenarios with a set of pre-defined speakers. However, synthesizing a new speaker's voice with a single reference audio, commonly known as zero-shot multi-speaker text-to-speech (ZSM-TTS), is still a very challenging task. The main challenge of ZSM-TTS is the speaker domain shift problem upon the speech generation of a new speaker. To mitigate this problem, we propose adversarial speaker-consistency learning (ASCL). The proposed method first generates an additional speech of a query speaker using the external untranscribed datasets at each training iteration. Then, the model learns to consistently generate the speech sample of the same speaker as the corresponding speaker embedding vector by employing an adversarial learning scheme. The experimental results show that the proposed method is effective compared to the baseline in terms of the quality and speaker similarity in ZSM-TTS.
Evaluating context-invariance in unsupervised speech representations
Oct 27, 2022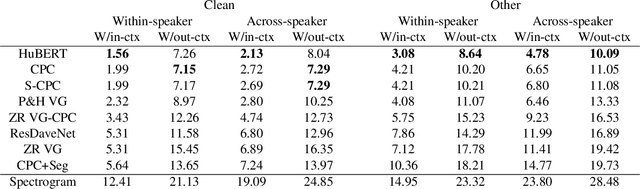
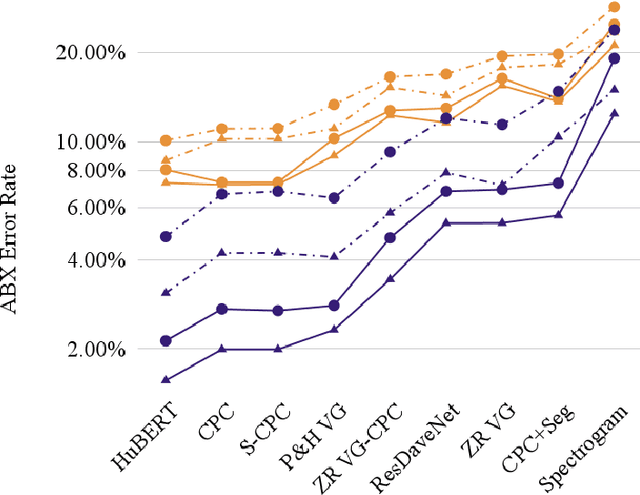
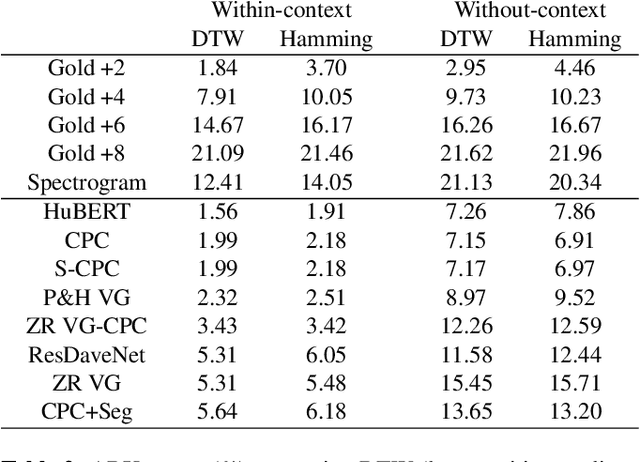
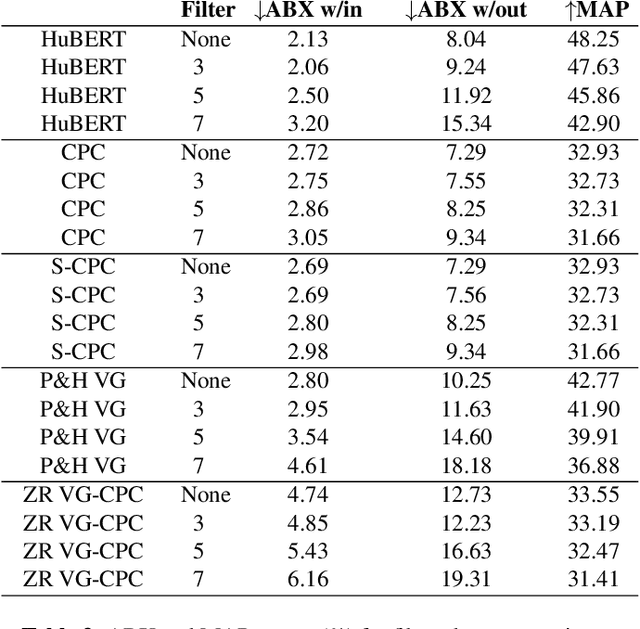
Unsupervised speech representations have taken off, with benchmarks (SUPERB, ZeroSpeech) demonstrating major progress on semi-supervised speech recognition, speech synthesis, and speech-only language modelling. Inspiration comes from the promise of ``discovering the phonemes'' of a language or a similar low-bitrate encoding. However, one of the critical properties of phoneme transcriptions is context-invariance: the phonetic context of a speech sound can have massive influence on the way it is pronounced, while the text remains stable. This is what allows tokens of the same word to have the same transcriptions -- key to language understanding. Current benchmarks do not measure context-invariance. We develop a new version of the ZeroSpeech ABX benchmark that measures context-invariance, and apply it to recent self-supervised representations. We demonstrate that the context-independence of representations is predictive of the stability of word-level representations. We suggest research concentrate on improving context-independence of self-supervised and unsupervised representations.
Dynamic Speech Endpoint Detection with Regression Targets
Oct 25, 2022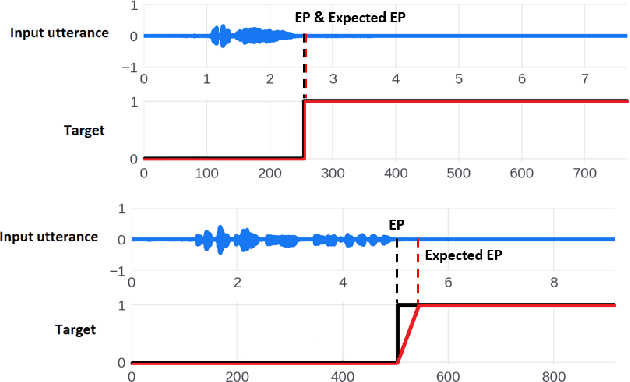

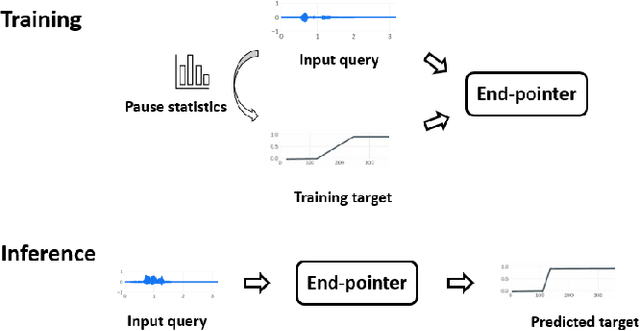

Interactive voice assistants have been widely used as input interfaces in various scenarios, e.g. on smart homes devices, wearables and on AR devices. Detecting the end of a speech query, i.e. speech end-pointing, is an important task for voice assistants to interact with users. Traditionally, speech end-pointing is based on pure classification methods along with arbitrary binary targets. In this paper, we propose a novel regression-based speech end-pointing model, which enables an end-pointer to adjust its detection behavior based on context of user queries. Specifically, we present a pause modeling method and show its effectiveness for dynamic end-pointing. Based on our experiments with vendor-collected smartphone and wearables speech queries, our strategy shows a better trade-off between endpointing latency and accuracy, compared to the traditional classification-based method. We further discuss the benefits of this model and generalization of the framework in the paper.
Supplementary Features of BiLSTM for Enhanced Sequence Labeling
Jun 08, 2023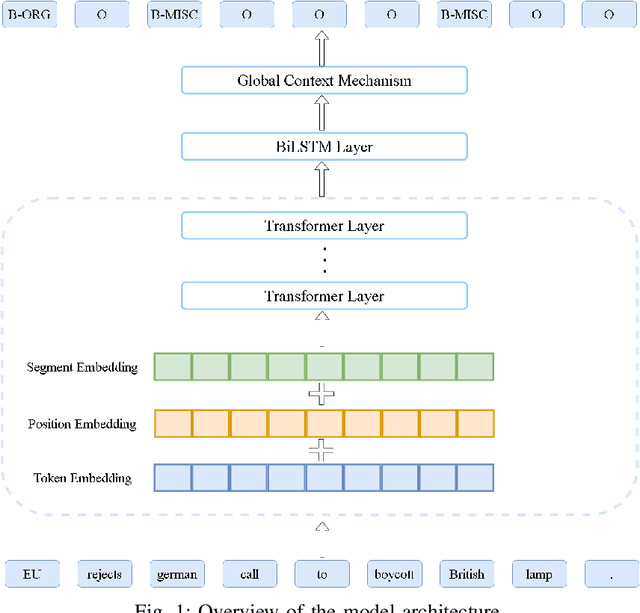
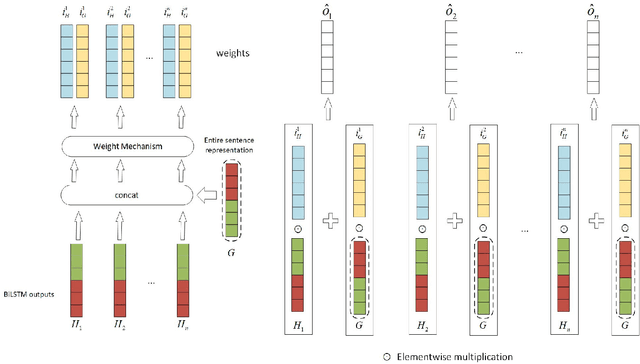
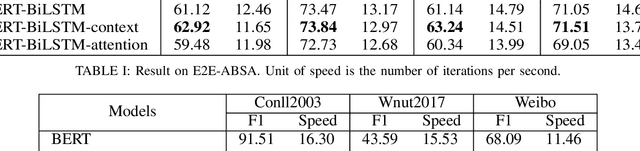
Sequence labeling tasks require the computation of sentence representations for each word within a given sentence. With the rise of advanced pretrained language models; one common approach involves incorporating a BiLSTM layer to enhance the sequence structure information at the output level. Nevertheless, it has been empirically demonstrated (P.-H. Li, 2020) that BiLSTM's potential for generating sentence representations for sequence labeling tasks is constrained, primarily due to the integration of fragments from past and future sentence representations to form a complete sentence representation. In this study, we observed that the entire sentence representation, found in both the first and last cells of BiLSTM, can supplement each cell's sentence representation. Accordingly, we devised a global context mechanism to integrate entire future and past sentence representations into each cell's sentence representation within BiLSTM, leading to a significant improvement in both F1 score and accuracy. By embedding the BERT model within BiLSTM as a demonstration, and conducting exhaustive experiments on nine datasets for sequence labeling tasks, including named entity recognition (NER), part of speech (POS) tagging and End-to-End Aspect-Based sentiment analysis (E2E-ABSA). We noted significant improvements in F1 scores and accuracy across all examined datasets.
When the Majority is Wrong: Leveraging Annotator Disagreement for Subjective Tasks
May 11, 2023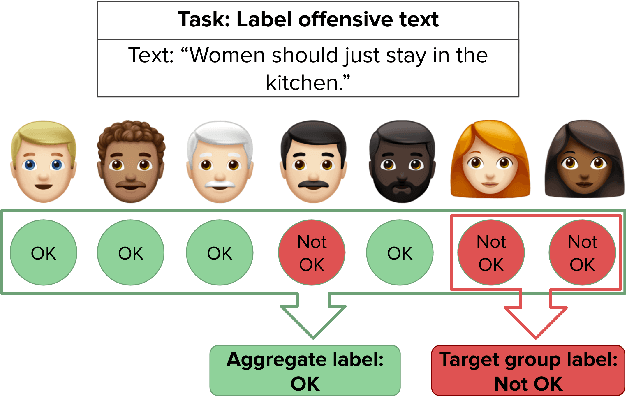
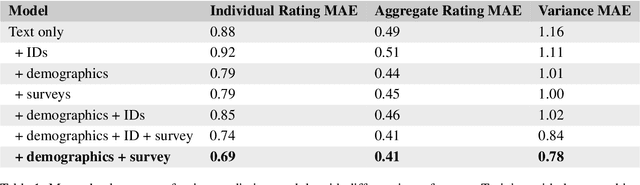
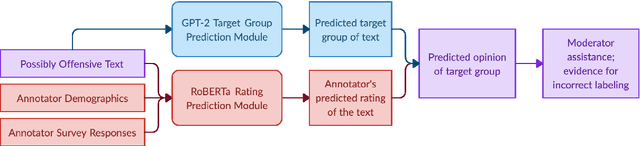
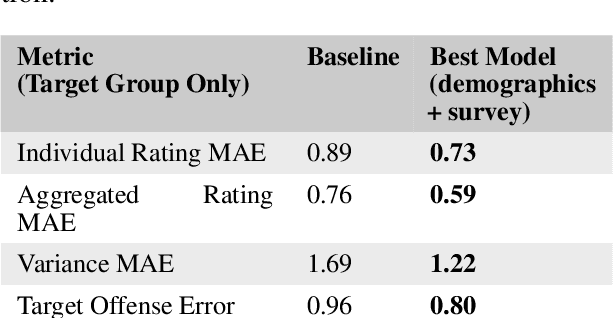
Though majority vote among annotators is typically used for ground truth labels in natural language processing, annotator disagreement in tasks such as hate speech detection may reflect differences among group opinions, not noise. Thus, a crucial problem in hate speech detection is whether a statement is offensive to the demographic group that it targets, which may constitute a small fraction of the annotator pool. We construct a model that predicts individual annotator ratings on potentially offensive text and combines this information with the predicted target group of the text to model the opinions of target group members. We show gains across a range of metrics, including raising performance over the baseline by 22% at predicting individual annotators' ratings and 33% at predicting variance among annotators, which provides a method of measuring model uncertainty downstream. We find that annotators' ratings can be predicted using their demographic information and opinions on online content, without the need to track identifying annotator IDs that link each annotator to their ratings. We also find that use of non-invasive survey questions on annotators' online experiences helps to maximize privacy and minimize unnecessary collection of demographic information when predicting annotators' opinions.
Continuous Emotional Intensity Controllable Speech Synthesis using Semi-supervised Learning
Nov 11, 2022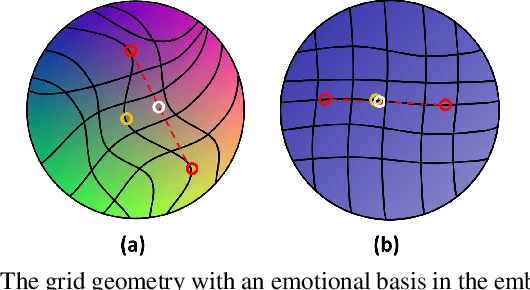
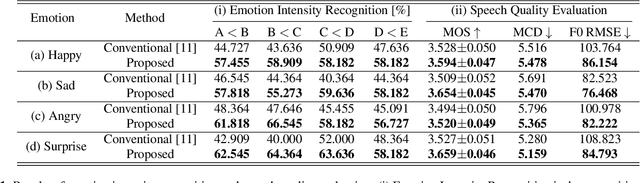


With the rapid development of the speech synthesis system, recent text-to-speech models have reached the level of generating natural speech similar to what humans say. But there still have limitations in terms of expressiveness. In particular, the existing emotional speech synthesis models have shown controllability using interpolated features with scaling parameters in emotional latent space. However, the emotional latent space generated from the existing models is difficult to control the continuous emotional intensity because of the entanglement of features like emotions, speakers, etc. In this paper, we propose a novel method to control the continuous intensity of emotions using semi-supervised learning. The model learns emotions of intermediate intensity using pseudo-labels generated from phoneme-level sequences of speech information. An embedding space built from the proposed model satisfies the uniform grid geometry with an emotional basis. In addition, to improve the naturalness of intermediate emotional speech, a discriminator is applied to the generation of low-level elements like duration, pitch and energy. The experimental results showed that the proposed method was superior in controllability and naturalness. The synthesized speech samples are available at https://tinyurl.com/34zaehh2
Looking Similar, Sounding Different: Leveraging Counterfactual Cross-Modal Pairs for Audiovisual Representation Learning
Apr 12, 2023

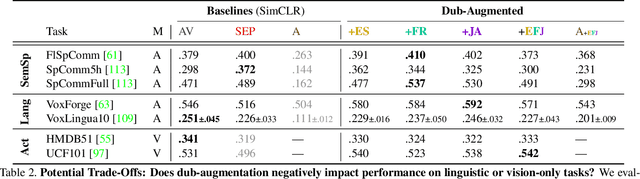

Audiovisual representation learning typically relies on the correspondence between sight and sound. However, there are often multiple audio tracks that can correspond with a visual scene. Consider, for example, different conversations on the same crowded street. The effect of such counterfactual pairs on audiovisual representation learning has not been previously explored. To investigate this, we use dubbed versions of movies to augment cross-modal contrastive learning. Our approach learns to represent alternate audio tracks, differing only in speech content, similarly to the same video. Our results show that dub-augmented training improves performance on a range of auditory and audiovisual tasks, without significantly affecting linguistic task performance overall. We additionally compare this approach to a strong baseline where we remove speech before pretraining, and find that dub-augmented training is more effective, including for paralinguistic and audiovisual tasks where speech removal leads to worse performance. These findings highlight the importance of considering speech variation when learning scene-level audiovisual correspondences and suggest that dubbed audio can be a useful augmentation technique for training audiovisual models toward more robust performance.
Tensor decomposition for minimization of E2E SLU model toward on-device processing
Jun 02, 2023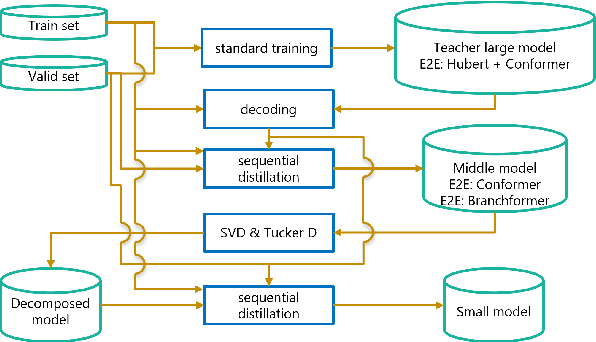
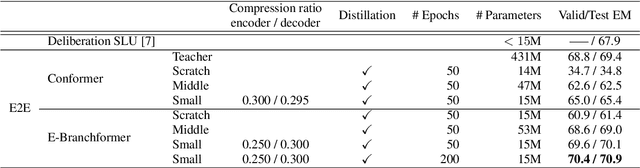

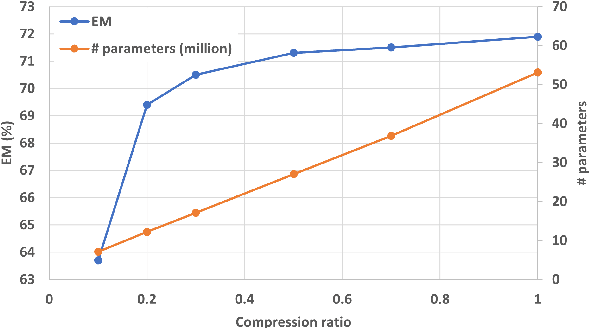
Spoken Language Understanding (SLU) is a critical speech recognition application and is often deployed on edge devices. Consequently, on-device processing plays a significant role in the practical implementation of SLU. This paper focuses on the end-to-end (E2E) SLU model due to its small latency property, unlike a cascade system, and aims to minimize the computational cost. We reduce the model size by applying tensor decomposition to the Conformer and E-Branchformer architectures used in our E2E SLU models. We propose to apply singular value decomposition to linear layers and the Tucker decomposition to convolution layers, respectively. We also compare COMP/PARFAC decomposition and Tensor-Train decomposition to the Tucker decomposition. Since the E2E model is represented by a single neural network, our tensor decomposition can flexibly control the number of parameters without changing feature dimensions. On the STOP dataset, we achieved 70.9% exact match accuracy under the tight constraint of only 15 million parameters.
Imitator: Personalized Speech-driven 3D Facial Animation
Dec 30, 2022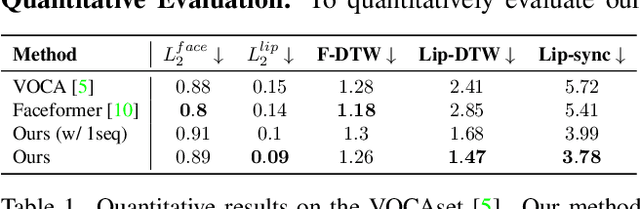
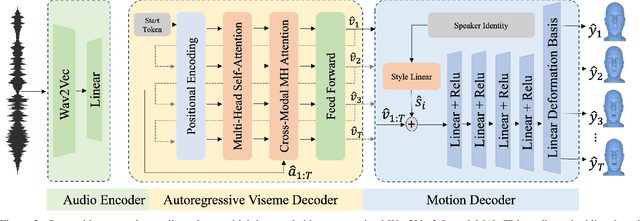

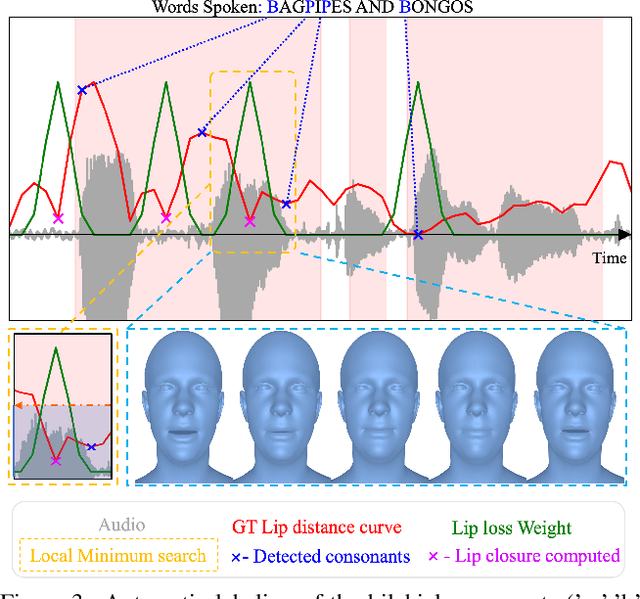
Speech-driven 3D facial animation has been widely explored, with applications in gaming, character animation, virtual reality, and telepresence systems. State-of-the-art methods deform the face topology of the target actor to sync the input audio without considering the identity-specific speaking style and facial idiosyncrasies of the target actor, thus, resulting in unrealistic and inaccurate lip movements. To address this, we present Imitator, a speech-driven facial expression synthesis method, which learns identity-specific details from a short input video and produces novel facial expressions matching the identity-specific speaking style and facial idiosyncrasies of the target actor. Specifically, we train a style-agnostic transformer on a large facial expression dataset which we use as a prior for audio-driven facial expressions. Based on this prior, we optimize for identity-specific speaking style based on a short reference video. To train the prior, we introduce a novel loss function based on detected bilabial consonants to ensure plausible lip closures and consequently improve the realism of the generated expressions. Through detailed experiments and a user study, we show that our approach produces temporally coherent facial expressions from input audio while preserving the speaking style of the target actors.