 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Sparse Modular Activation for Efficient Sequence Modeling
Jun 19, 2023
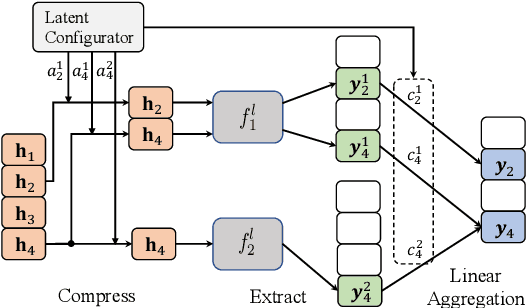
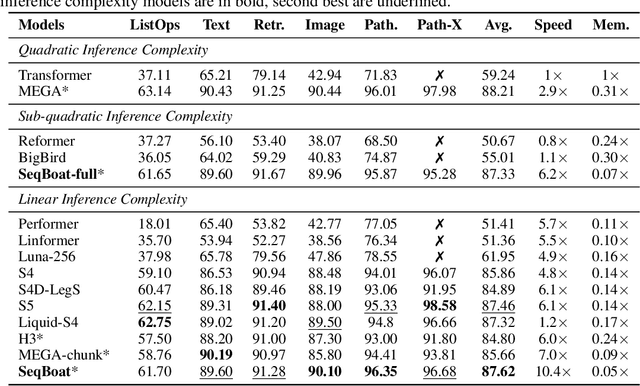
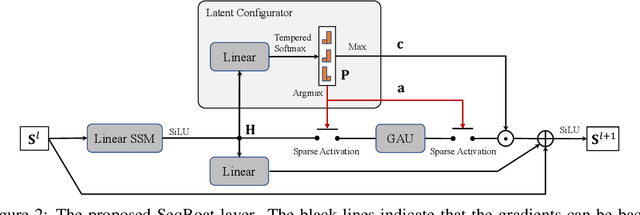

Linear State Space Models (SSMs) have demonstrated strong performance in a variety of sequence modeling tasks due to their efficient encoding of the recurrent structure. However, in more comprehensive tasks like language modeling and machine translation, self-attention-based models still outperform SSMs. Hybrid models employing both SSM and self-attention generally show promising performance, but current approaches apply attention modules statically and uniformly to all elements in the input sequences, leading to sub-optimal quality-efficiency trade-offs. In this work, we introduce Sparse Modular Activation (SMA), a general mechanism enabling neural networks to sparsely and dynamically activate sub-modules for sequence elements in a differentiable manner. Through allowing each element to skip non-activated sub-modules, SMA reduces computation and memory consumption at both training and inference stages of sequence modeling. As a specific instantiation of SMA, we design a novel neural architecture, SeqBoat, which employs SMA to sparsely activate a Gated Attention Unit (GAU) based on the state representations learned from an SSM. By constraining the GAU to only conduct local attention on the activated inputs, SeqBoat can achieve linear inference complexity with theoretically infinite attention span, and provide substantially better quality-efficiency trade-off than the chunking-based models. With experiments on a wide range of tasks, including language modeling, speech classification and long-range arena, SeqBoat brings new state-of-the-art results among hybrid models with linear complexity and reveals the amount of attention needed for each task through the learned sparse activation patterns.
Analysis of Noisy-target Training for DNN-based speech enhancement
Nov 02, 2022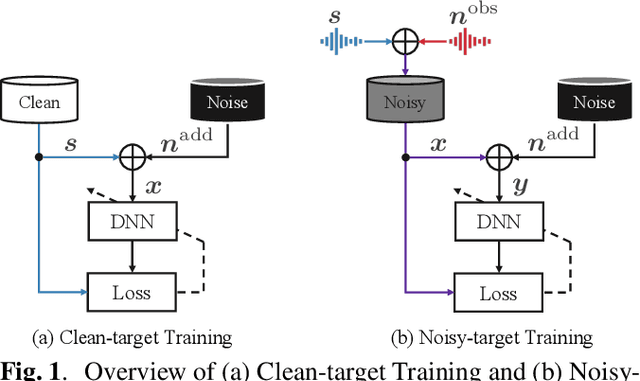
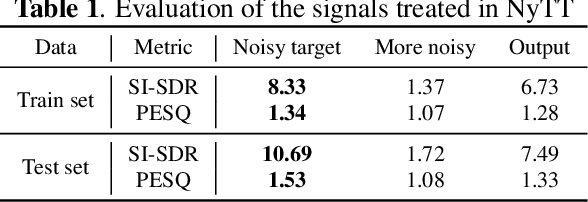
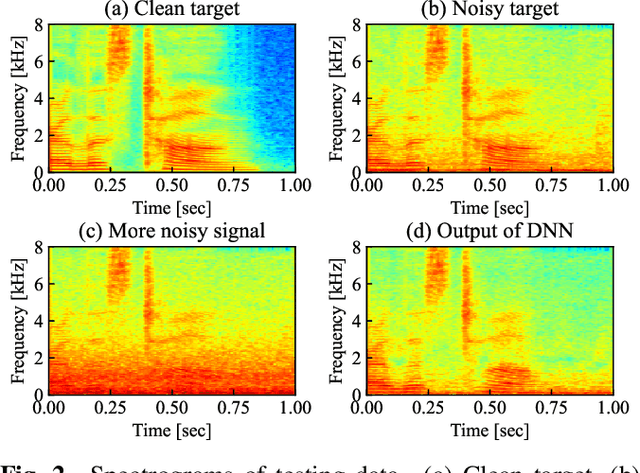

Deep neural network (DNN)-based speech enhancement usually uses a clean speech as a training target. However, it is hard to collect large amounts of clean speech because the recording is very costly. In other words, the performance of current speech enhancement has been limited by the amount of training data. To relax this limitation, Noisy-target Training (NyTT) that utilizes noisy speech as a training target has been proposed. Although it has been experimentally shown that NyTT can train a DNN without clean speech, a detailed analysis has not been conducted and its behavior has not been understood well. In this paper, we conduct various analyses to deepen our understanding of NyTT. In addition, based on the property of NyTT, we propose a refined method that is comparable to the method using clean speech. Furthermore, we show that we can improve the performance by using a huge amount of noisy speech with clean speech.
Lightweight Toxicity Detection in Spoken Language: A Transformer-based Approach for Edge Devices
Apr 22, 2023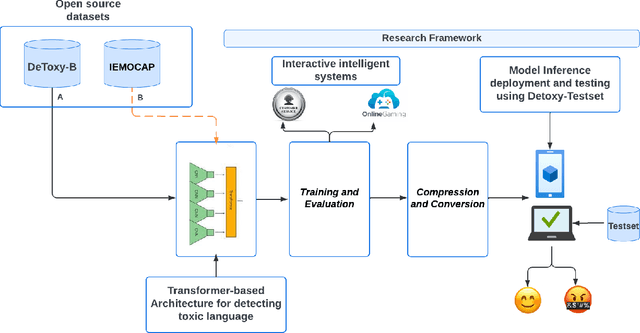
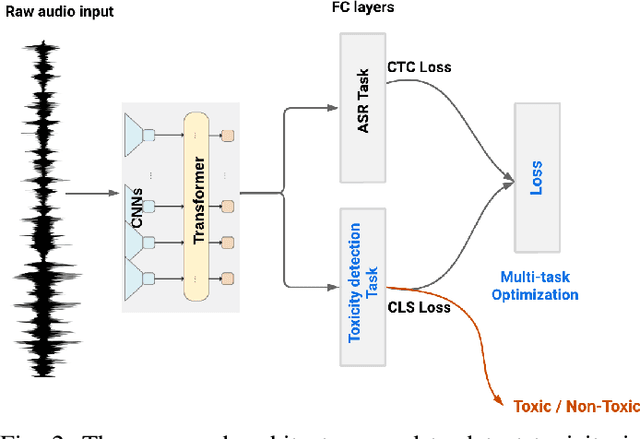
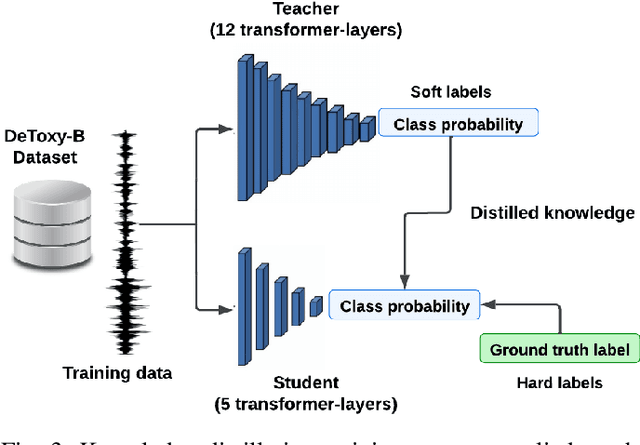
Toxicity is a prevalent social behavior that involves the use of hate speech, offensive language, bullying, and abusive speech. While text-based approaches for toxicity detection are common, there is limited research on processing speech signals in the physical world. Detecting toxicity in the physical world is challenging due to the difficulty of integrating AI-capable computers into the environment. We propose a lightweight transformer model based on wav2vec2.0 and optimize it using techniques such as quantization and knowledge distillation. Our model uses multitask learning and achieves an average macro F1-score of 90.3\% and a weighted accuracy of 88\%, outperforming state-of-the-art methods on DeToxy-B and a public dataset. Our results show that quantization reduces the model size by almost 4 times and RAM usage by 3.3\%, with only a 1\% F1 score decrease. Knowledge distillation reduces the model size by 3.7 times, RAM usage by 1.9, and inference time by 2 times, but decreases accuracy by 8\%. Combining both techniques reduces the model size by 14.6 times and RAM usage by around 4.3 times, with a two-fold inference time improvement. Our compact model is the first end-to-end speech-based toxicity detection model based on a lightweight transformer model suitable for deployment in physical spaces. The results show its feasibility for toxicity detection on edge devices in real-world environments.
DDSupport: Language Learning Support System that Displays Differences and Distances from Model Speech
Dec 08, 2022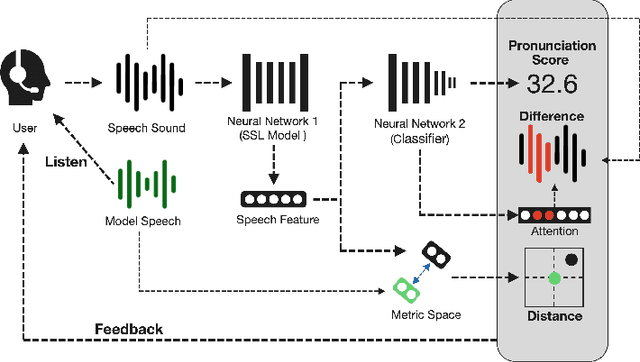
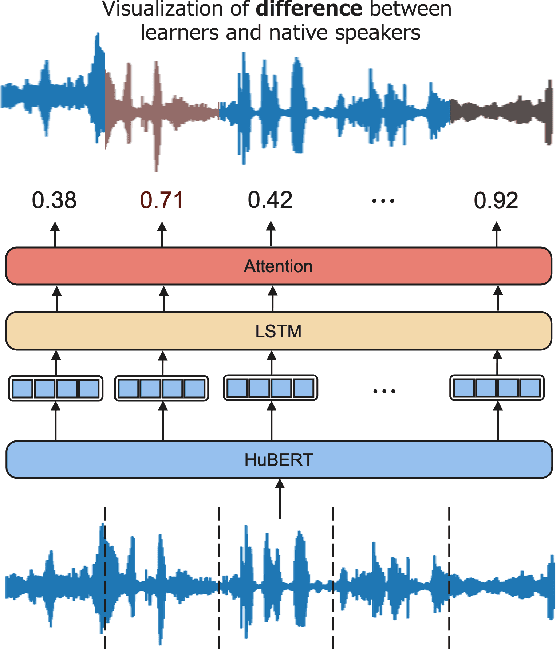
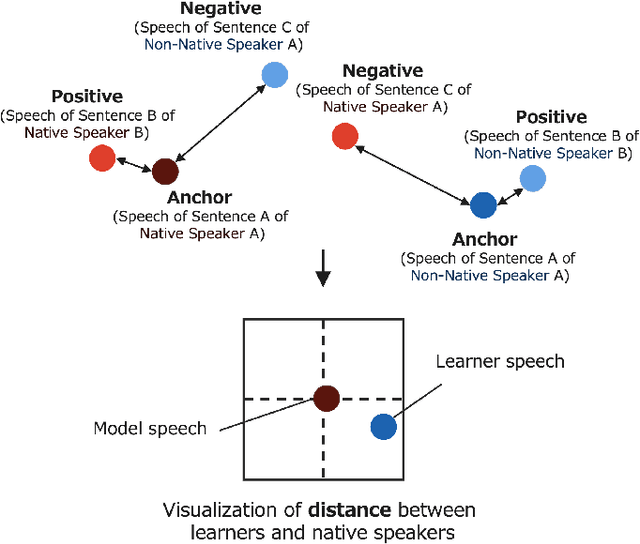
When beginners learn to speak a non-native language, it is difficult for them to judge for themselves whether they are speaking well. Therefore, computer-assisted pronunciation training systems are used to detect learner mispronunciations. These systems typically compare the user's speech with that of a specific native speaker as a model in units of rhythm, phonemes, or words and calculate the differences. However, they require extensive speech data with detailed annotations or can only compare with one specific native speaker. To overcome these problems, we propose a new language learning support system that calculates speech scores and detects mispronunciations by beginners based on a small amount of unannotated speech data without comparison to a specific person. The proposed system uses deep learning--based speech processing to display the pronunciation score of the learner's speech and the difference/distance between the learner's and a group of models' pronunciation in an intuitively visual manner. Learners can gradually improve their pronunciation by eliminating differences and shortening the distance from the model until they become sufficiently proficient. Furthermore, since the pronunciation score and difference/distance are not calculated compared to specific sentences of a particular model, users are free to study the sentences they wish to study. We also built an application to help non-native speakers learn English and confirmed that it can improve users' speech intelligibility.
Exploring Effective Fusion Algorithms for Speech Based Self-Supervised Learning Models
Dec 20, 2022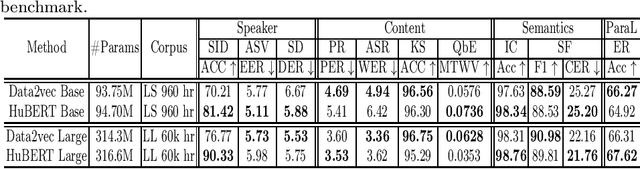
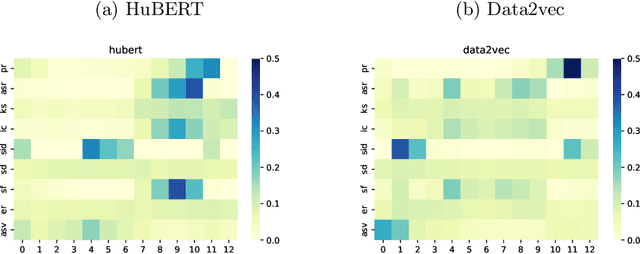
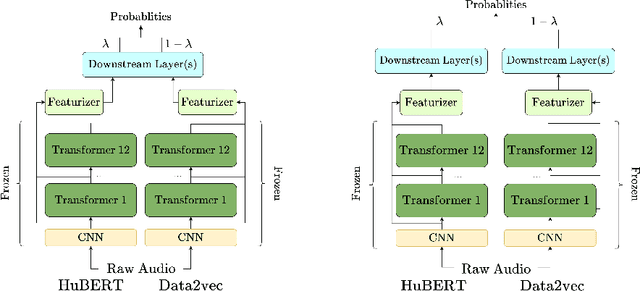
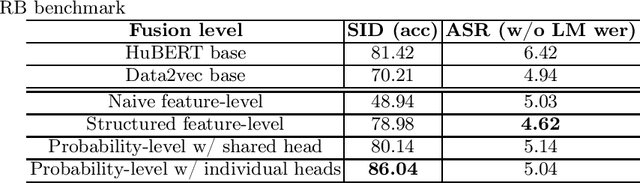
Self-supervised learning (SSL) has achieved great success in various areas including speech processing. Recently, it is proven that speech based SSL models are able to extract superior universal representations on a range of downstream tasks compared to traditional hand-craft feature (e.g. FBank, MFCC) in the SUPERB benchmark. However, different types of SSL models might exhibit distinct strengths on different downstream tasks. In order to better utilize the potential power of SSL models, in this work, we explore the effective fusion on multiple SSL models. A series of model fusion algorithms are investigated and compared by combining two types of SSL models, Hubert and Data2vec, on two representative tasks from SUPERB benchmark, which are speaker identification (SID) and automatic speech recognition (ASR) tasks. The experimental results demonstrate that our proposed fusion algorithms can further boost the individual model significantly.
Efficient Speech Translation with Dynamic Latent Perceivers
Oct 28, 2022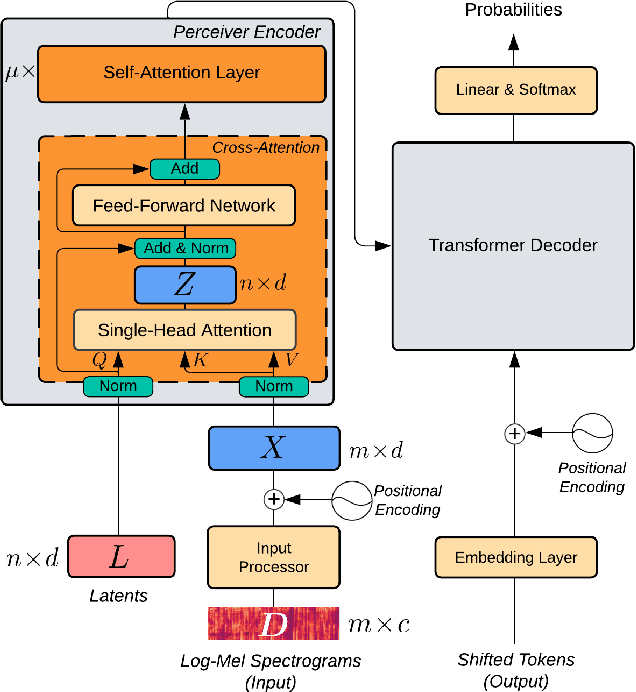
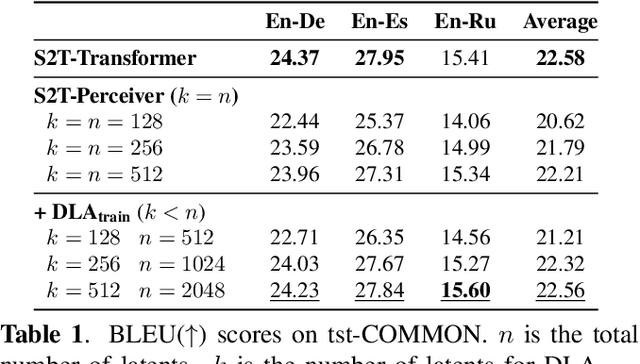
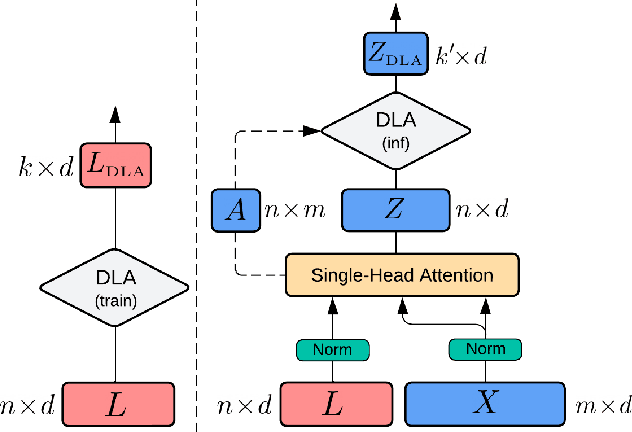
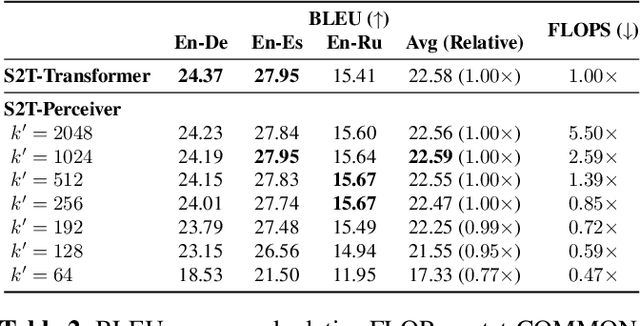
Transformers have been the dominant architecture for Speech Translation in recent years, achieving significant improvements in translation quality. Since speech signals are longer than their textual counterparts, and due to the quadratic complexity of the Transformer, a down-sampling step is essential for its adoption in Speech Translation. Instead, in this research, we propose to ease the complexity by using a Perceiver encoder to map the speech inputs to a fixed-length latent representation. Furthermore, we introduce a novel way of training Perceivers, with Dynamic Latent Access (DLA), unlocking larger latent spaces without any additional computational overhead. Speech-to-Text Perceivers with DLA can match the performance of a Transformer baseline across three language pairs in MuST-C. Finally, a DLA-trained model is easily adaptable to DLA at inference, and can be flexibly deployed with various computational budgets, without significant drops in translation quality.
Efficient Speech Quality Assessment using Self-supervised Framewise Embeddings
Nov 12, 2022
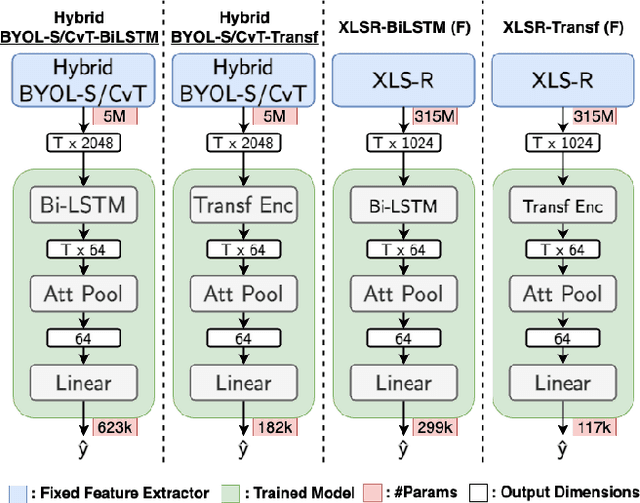
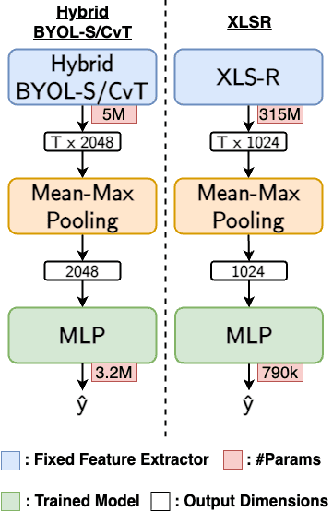
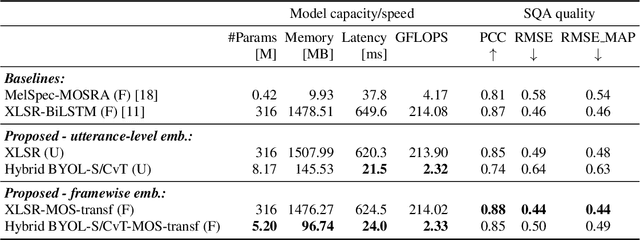
Automatic speech quality assessment is essential for audio researchers, developers, speech and language pathologists, and system quality engineers. The current state-of-the-art systems are based on framewise speech features (hand-engineered or learnable) combined with time dependency modeling. This paper proposes an efficient system with results comparable to the best performing model in the ConferencingSpeech 2022 challenge. Our proposed system is characterized by a smaller number of parameters (40-60x), fewer FLOPS (100x), lower memory consumption (10-15x), and lower latency (30x). Speech quality practitioners can therefore iterate much faster, deploy the system on resource-limited hardware, and, overall, the proposed system contributes to sustainable machine learning. The paper also concludes that framewise embeddings outperform utterance-level embeddings and that multi-task training with acoustic conditions modeling does not degrade speech quality prediction while providing better interpretation.
Benchmarking Evaluation Metrics for Code-Switching Automatic Speech Recognition
Nov 22, 2022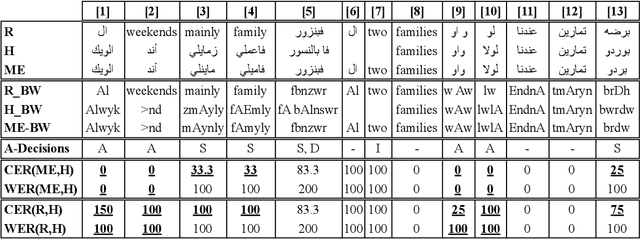

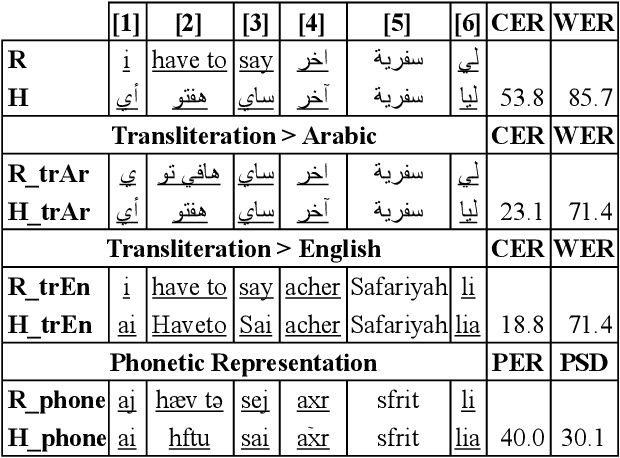

Code-switching poses a number of challenges and opportunities for multilingual automatic speech recognition. In this paper, we focus on the question of robust and fair evaluation metrics. To that end, we develop a reference benchmark data set of code-switching speech recognition hypotheses with human judgments. We define clear guidelines for minimal editing of automatic hypotheses. We validate the guidelines using 4-way inter-annotator agreement. We evaluate a large number of metrics in terms of correlation with human judgments. The metrics we consider vary in terms of representation (orthographic, phonological, semantic), directness (intrinsic vs extrinsic), granularity (e.g. word, character), and similarity computation method. The highest correlation to human judgment is achieved using transliteration followed by text normalization. We release the first corpus for human acceptance of code-switching speech recognition results in dialectal Arabic/English conversation speech.
Robust Speech Recognition via Large-Scale Weak Supervision
Dec 06, 2022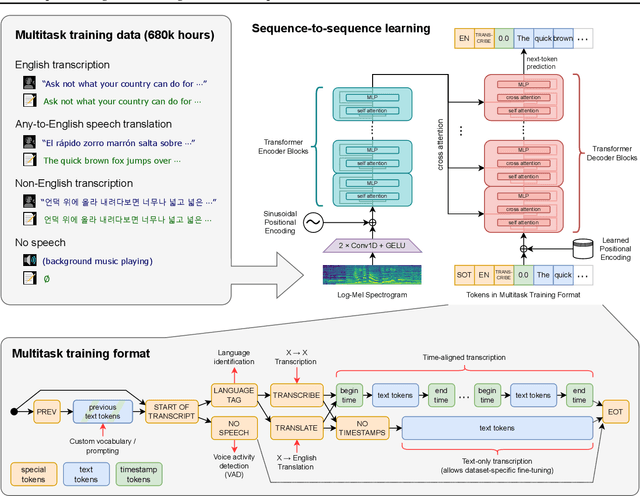
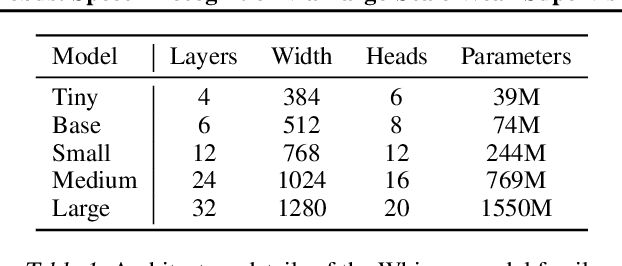
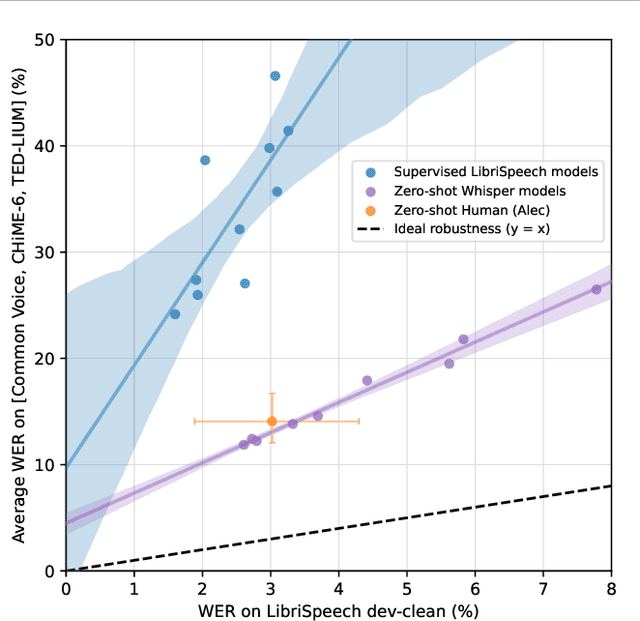
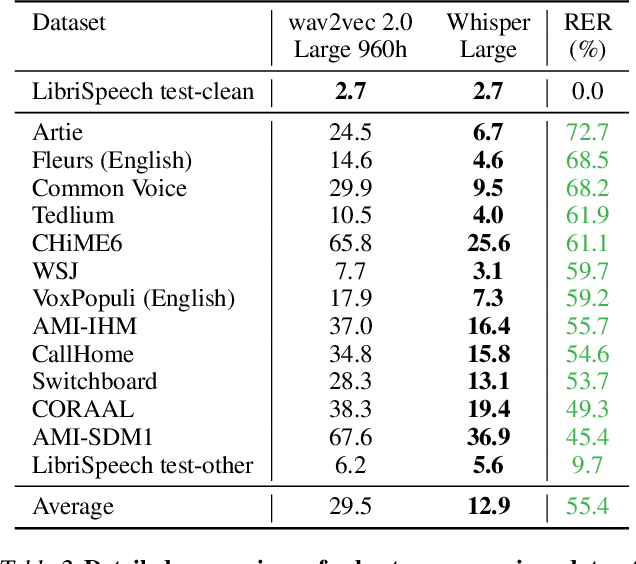
We study the capabilities of speech processing systems trained simply to predict large amounts of transcripts of audio on the internet. When scaled to 680,000 hours of multilingual and multitask supervision, the resulting models generalize well to standard benchmarks and are often competitive with prior fully supervised results but in a zero-shot transfer setting without the need for any fine-tuning. When compared to humans, the models approach their accuracy and robustness. We are releasing models and inference code to serve as a foundation for further work on robust speech processing.
Model Extraction Attack against Self-supervised Speech Models
Nov 29, 2022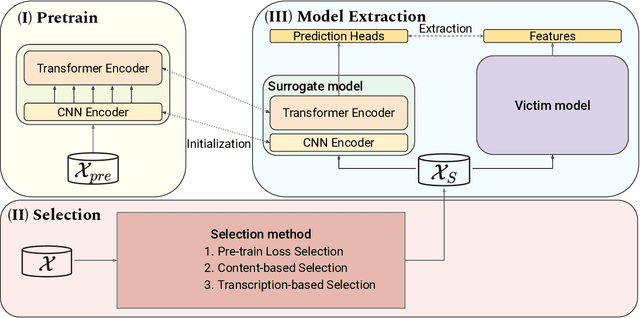
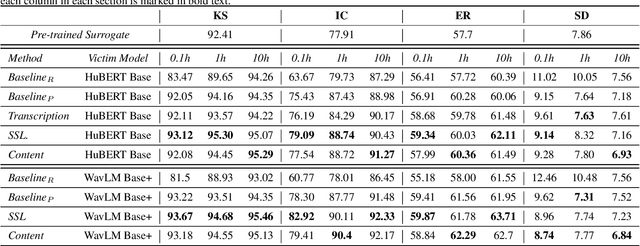
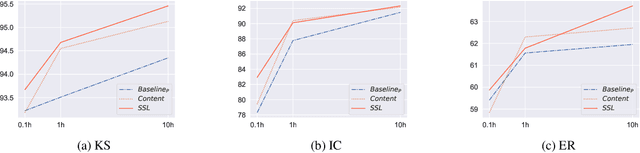
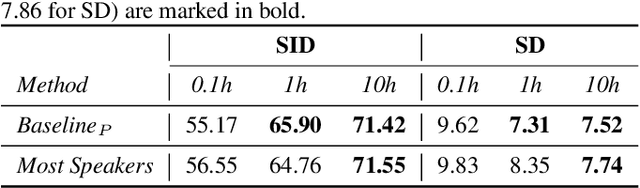
Self-supervised learning (SSL) speech models generate meaningful representations of given clips and achieve incredible performance across various downstream tasks. Model extraction attack (MEA) often refers to an adversary stealing the functionality of the victim model with only query access. In this work, we study the MEA problem against SSL speech model with a small number of queries. We propose a two-stage framework to extract the model. In the first stage, SSL is conducted on the large-scale unlabeled corpus to pre-train a small speech model. Secondly, we actively sample a small portion of clips from the unlabeled corpus and query the target model with these clips to acquire their representations as labels for the small model's second-stage training. Experiment results show that our sampling methods can effectively extract the target model without knowing any information about its model architecture.