 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
hierarchical network with decoupled knowledge distillation for speech emotion recognition
Mar 09, 2023
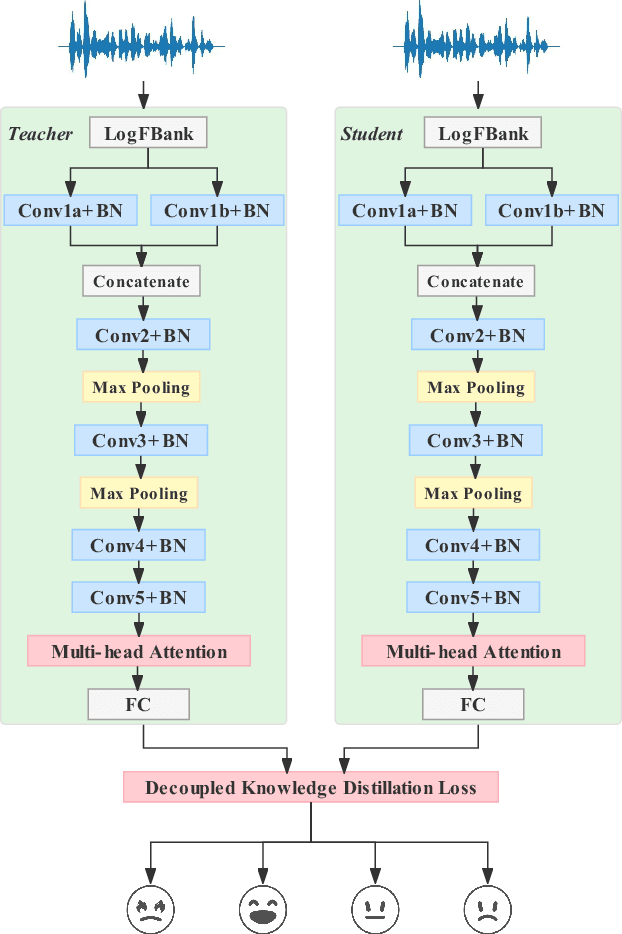
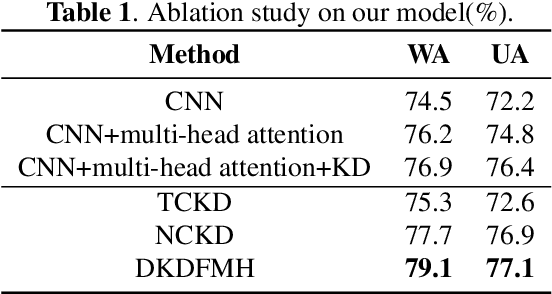
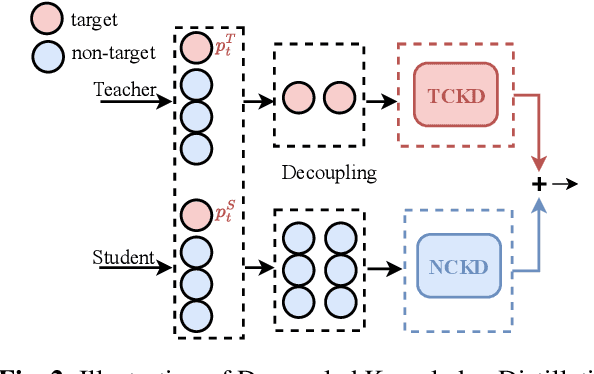
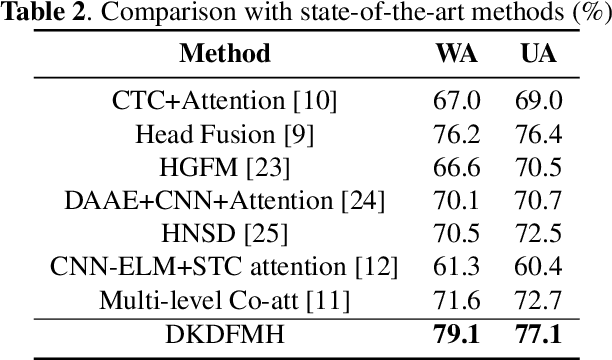
The goal of Speech Emotion Recognition (SER) is to enable computers to recognize the emotion category of a given utterance in the same way that humans do. The accuracy of SER is strongly dependent on the validity of the utterance-level representation obtained by the model. Nevertheless, the ``dark knowledge" carried by non-target classes is always ignored by previous studies. In this paper, we propose a hierarchical network, called DKDFMH, which employs decoupled knowledge distillation in a deep convolutional neural network with a fused multi-head attention mechanism. Our approach applies logit distillation to obtain higher-level semantic features from different scales of attention sets and delve into the knowledge carried by non-target classes, thus guiding the model to focus more on the differences between sentiment features. To validate the effectiveness of our model, we conducted experiments on the Interactive Emotional Dyadic Motion Capture (IEMOCAP) dataset. We achieved competitive performance, with 79.1% weighted accuracy (WA) and 77.1% unweighted accuracy (UA). To the best of our knowledge, this is the first time since 2015 that logit distillation has been returned to state-of-the-art status.
Emphasizing Unseen Words: New Vocabulary Acquisition for End-to-End Speech Recognition
Feb 21, 2023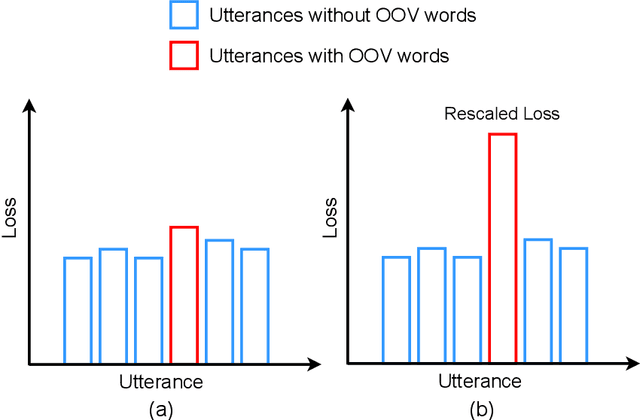
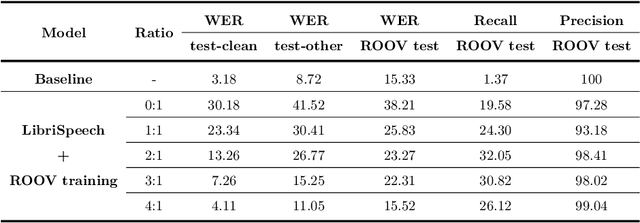
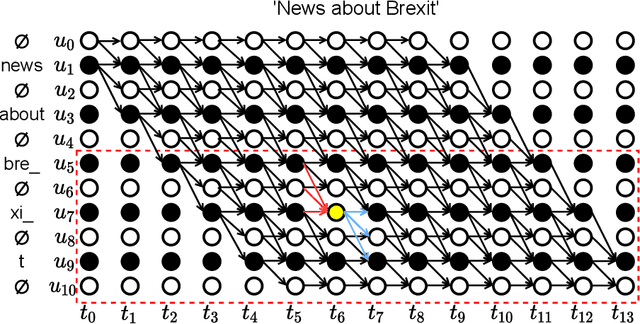
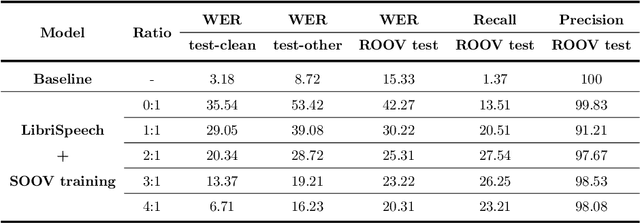
Due to the dynamic nature of human language, automatic speech recognition (ASR) systems need to continuously acquire new vocabulary. Out-Of-Vocabulary (OOV) words, such as trending words and new named entities, pose problems to modern ASR systems that require long training times to adapt their large numbers of parameters. Different from most previous research focusing on language model post-processing, we tackle this problem on an earlier processing level and eliminate the bias in acoustic modeling to recognize OOV words acoustically. We propose to generate OOV words using text-to-speech systems and to rescale losses to encourage neural networks to pay more attention to OOV words. Specifically, we enlarge the classification loss used for training neural networks' parameters of utterances containing OOV words (sentence-level), or rescale the gradient used for back-propagation for OOV words (word-level), when fine-tuning a previously trained model on synthetic audio. To overcome catastrophic forgetting, we also explore the combination of loss rescaling and model regularization, i.e. L2 regularization and elastic weight consolidation (EWC). Compared with previous methods that just fine-tune synthetic audio with EWC, the experimental results on the LibriSpeech benchmark reveal that our proposed loss rescaling approach can achieve significant improvement on the recall rate with only a slight decrease on word error rate. Moreover, word-level rescaling is more stable than utterance-level rescaling and leads to higher recall rates and precision on OOV word recognition. Furthermore, our proposed combined loss rescaling and weight consolidation methods can support continual learning of an ASR system.
End-to-End Speech Translation of Arabic to English Broadcast News
Dec 11, 2022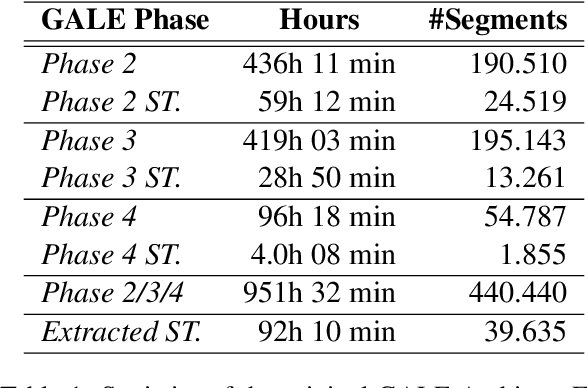
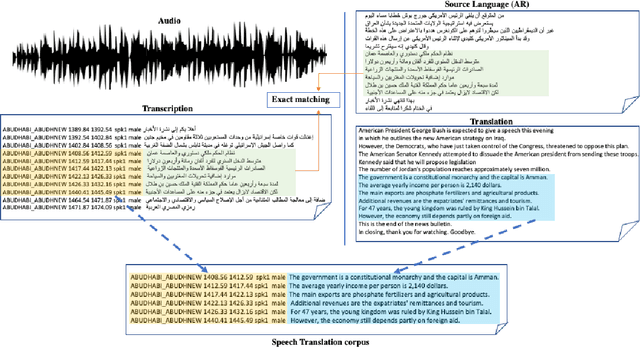
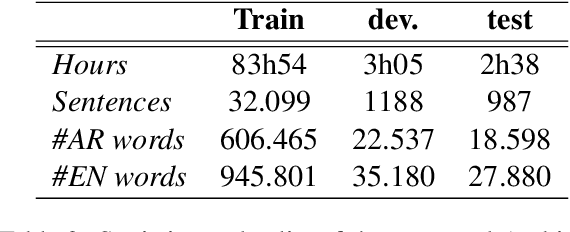

Speech translation (ST) is the task of directly translating acoustic speech signals in a source language into text in a foreign language. ST task has been addressed, for a long time, using a pipeline approach with two modules : first an Automatic Speech Recognition (ASR) in the source language followed by a text-to-text Machine translation (MT). In the past few years, we have seen a paradigm shift towards the end-to-end approaches using sequence-to-sequence deep neural network models. This paper presents our efforts towards the development of the first Broadcast News end-to-end Arabic to English speech translation system. Starting from independent ASR and MT LDC releases, we were able to identify about 92 hours of Arabic audio recordings for which the manual transcription was also translated into English at the segment level. These data was used to train and compare pipeline and end-to-end speech translation systems under multiple scenarios including transfer learning and data augmentation techniques.
ASDF: A Differential Testing Framework for Automatic Speech Recognition Systems
Feb 11, 2023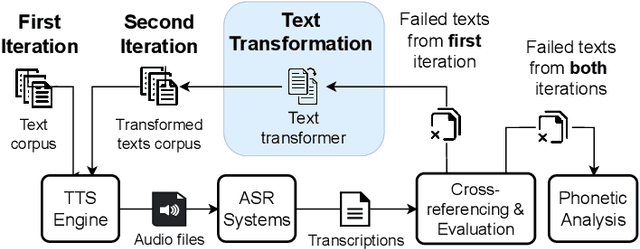
Recent years have witnessed wider adoption of Automated Speech Recognition (ASR) techniques in various domains. Consequently, evaluating and enhancing the quality of ASR systems is of great importance. This paper proposes ASDF, an Automated Speech Recognition Differential Testing Framework for testing ASR systems. ASDF extends an existing ASR testing tool, the CrossASR++, which synthesizes test cases from a text corpus. However, CrossASR++ fails to make use of the text corpus efficiently and provides limited information on how the failed test cases can improve ASR systems. To address these limitations, our tool incorporates two novel features: (1) a text transformation module to boost the number of generated test cases and uncover more errors in ASR systems and (2) a phonetic analysis module to identify on which phonemes the ASR system tend to produce errors. ASDF generates more high-quality test cases by applying various text transformation methods (e.g., change tense) to the texts in failed test cases. By doing so, ASDF can utilize a small text corpus to generate a large number of audio test cases, something which CrossASR++ is not capable of. In addition, ASDF implements more metrics to evaluate the performance of ASR systems from multiple perspectives. ASDF performs phonetic analysis on the identified failed test cases to identify the phonemes that ASR systems tend to transcribe incorrectly, providing useful information for developers to improve ASR systems. The demonstration video of our tool is made online at https://www.youtube.com/watch?v=DzVwfc3h9As. The implementation is available at https://github.com/danielyuenhx/asdf-differential-testing.
AnnoBERT: Effectively Representing Multiple Annotators' Label Choices to Improve Hate Speech Detection
Dec 20, 2022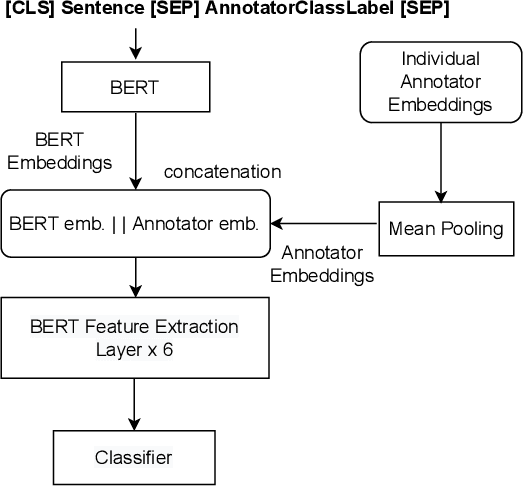

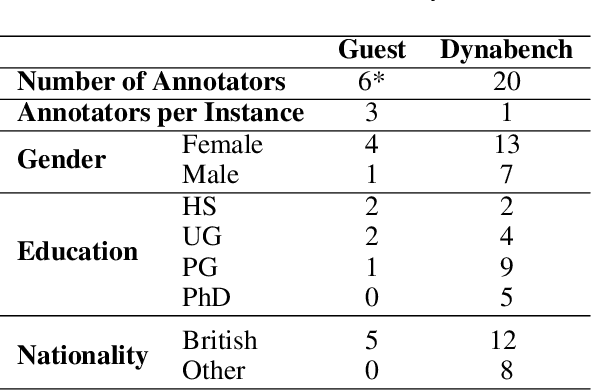
Supervised approaches generally rely on majority-based labels. However, it is hard to achieve high agreement among annotators in subjective tasks such as hate speech detection. Existing neural network models principally regard labels as categorical variables, while ignoring the semantic information in diverse label texts. In this paper, we propose AnnoBERT, a first-of-its-kind architecture integrating annotator characteristics and label text with a transformer-based model to detect hate speech, with unique representations based on each annotator's characteristics via Collaborative Topic Regression (CTR) and integrate label text to enrich textual representations. During training, the model associates annotators with their label choices given a piece of text; during evaluation, when label information is not available, the model predicts the aggregated label given by the participating annotators by utilising the learnt association. The proposed approach displayed an advantage in detecting hate speech, especially in the minority class and edge cases with annotator disagreement. Improvement in the overall performance is the largest when the dataset is more label-imbalanced, suggesting its practical value in identifying real-world hate speech, as the volume of hate speech in-the-wild is extremely small on social media, when compared with normal (non-hate) speech. Through ablation studies, we show the relative contributions of annotator embeddings and label text to the model performance, and tested a range of alternative annotator embeddings and label text combinations.
* accepted at ICWSM 2023
Parameter Efficient Transfer Learning for Various Speech Processing Tasks
Dec 06, 2022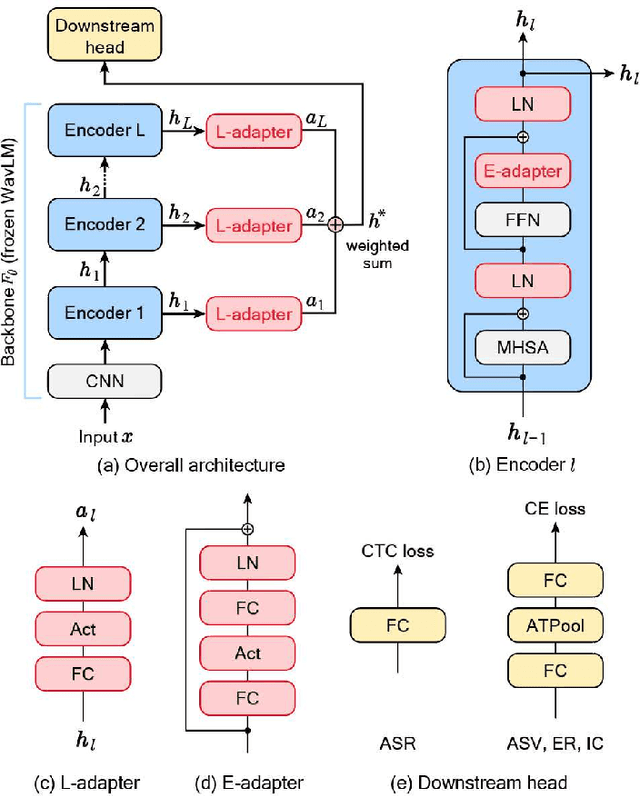
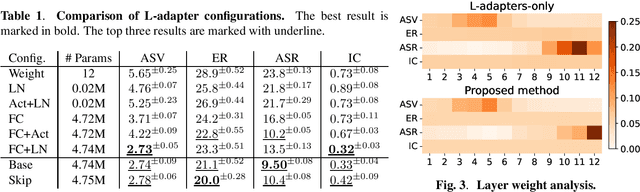
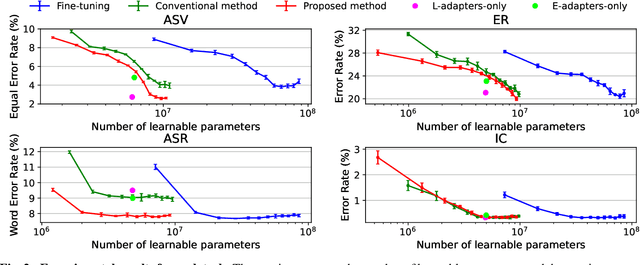
Fine-tuning of self-supervised models is a powerful transfer learning method in a variety of fields, including speech processing, since it can utilize generic feature representations obtained from large amounts of unlabeled data. Fine-tuning, however, requires a new parameter set for each downstream task, which is parameter inefficient. Adapter architecture is proposed to partially solve this issue by inserting lightweight learnable modules into a frozen pre-trained model. However, existing adapter architectures fail to adaptively leverage low- to high-level features stored in different layers, which is necessary for solving various kinds of speech processing tasks. Thus, we propose a new adapter architecture to acquire feature representations more flexibly for various speech tasks. In experiments, we applied this adapter to WavLM on four speech tasks. It performed on par or better than naive fine-tuning, with only 11% of learnable parameters. It also outperformed an existing adapter architecture.
One-Step Knowledge Distillation and Fine-Tuning in Using Large Pre-Trained Self-Supervised Learning Models for Speaker Verification
Jun 08, 2023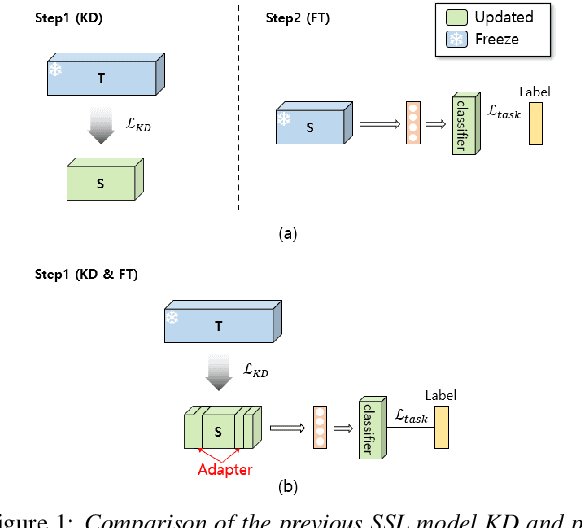

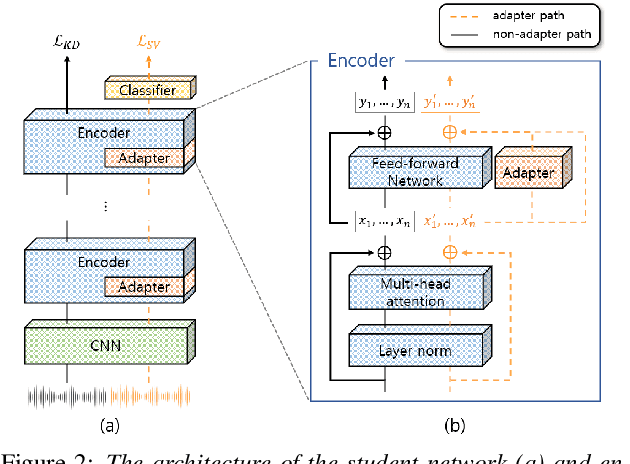
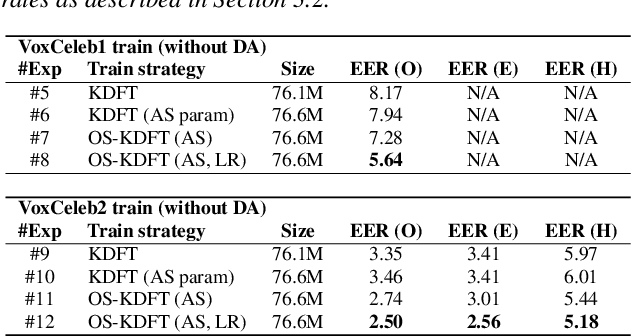
The application of speech self-supervised learning (SSL) models has achieved remarkable performance in speaker verification (SV). However, there is a computational cost hurdle in employing them, which makes development and deployment difficult. Several studies have simply compressed SSL models through knowledge distillation (KD) without considering the target task. Consequently, these methods could not extract SV-tailored features. This paper suggests One-Step Knowledge Distillation and Fine-Tuning (OS-KDFT), which incorporates KD and fine-tuning (FT). We optimize a student model for SV during KD training to avert the distillation of inappropriate information for the SV. OS-KDFT could downsize Wav2Vec 2.0 based ECAPA-TDNN size by approximately 76.2%, and reduce the SSL model's inference time by 79% while presenting an EER of 0.98%. The proposed OS-KDFT is validated across VoxCeleb1 and VoxCeleb2 datasets and W2V2 and HuBERT SSL models. Experiments are available on our GitHub.
Meta-Gating Framework for Fast and Continuous Resource Optimization in Dynamic Wireless Environments
Jun 23, 2023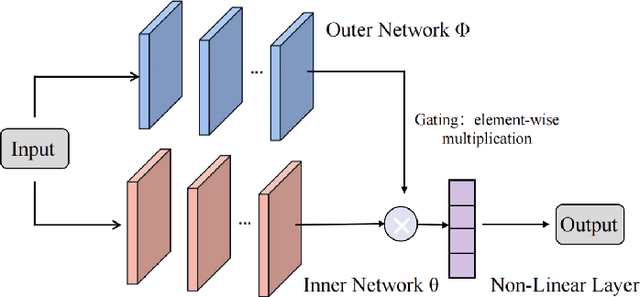
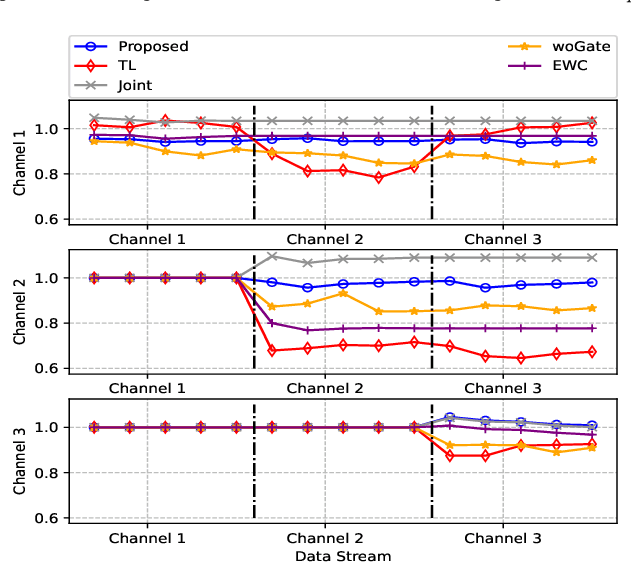
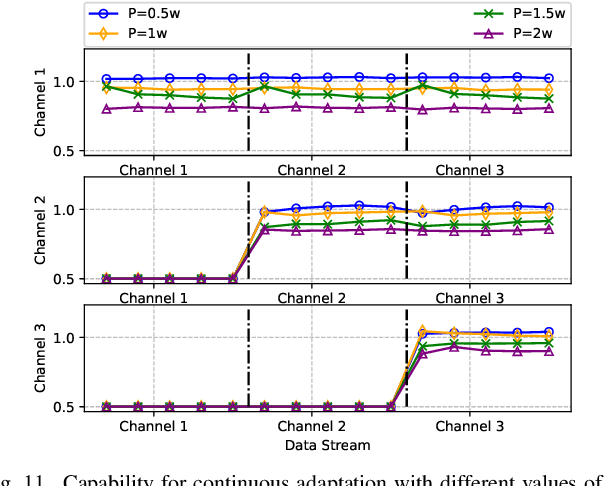
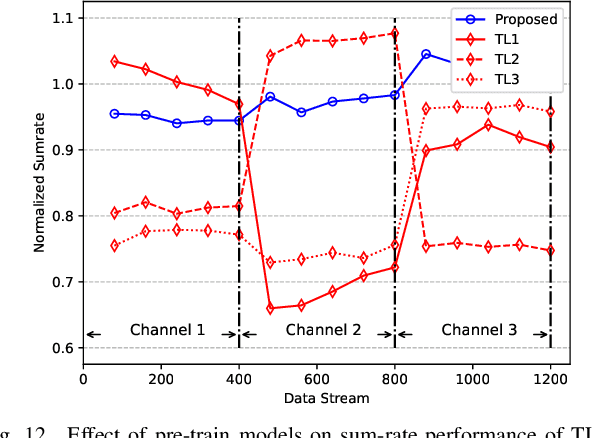
With the great success of deep learning (DL) in image classification, speech recognition, and other fields, more and more studies have applied various neural networks (NNs) to wireless resource allocation. Generally speaking, these artificial intelligent (AI) models are trained under some special learning hypotheses, especially that the statistics of the training data are static during the training stage. However, the distribution of channel state information (CSI) is constantly changing in the real-world wireless communication environment. Therefore, it is essential to study effective dynamic DL technologies to solve wireless resource allocation problems. In this paper, we propose a novel framework, named meta-gating, for solving resource allocation problems in an episodically dynamic wireless environment, where the CSI distribution changes over periods and remains constant within each period. The proposed framework, consisting of an inner network and an outer network, aims to adapt to the dynamic wireless environment by achieving three important goals, i.e., seamlessness, quickness and continuity. Specifically, for the former two goals, we propose a training method by combining a model-agnostic meta-learning (MAML) algorithm with an unsupervised learning mechanism. With this training method, the inner network is able to fast adapt to different channel distributions because of the good initialization. As for the goal of continuity, the outer network can learn to evaluate the importance of inner network's parameters under different CSI distributions, and then decide which subset of the inner network should be activated through the gating operation. Additionally, we theoretically analyze the performance of the proposed meta-gating framework.
Expressive Speech-driven Facial Animation with controllable emotions
Jan 05, 2023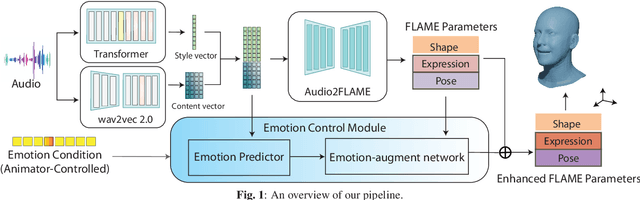

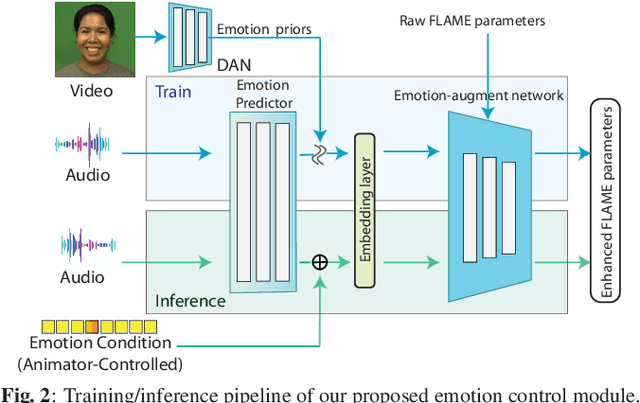
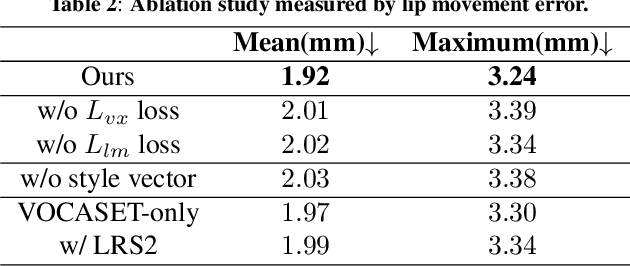
It is in high demand to generate facial animation with high realism, but it remains a challenging task. Existing approaches of speech-driven facial animation can produce satisfactory mouth movement and lip synchronization, but show weakness in dramatic emotional expressions and flexibility in emotion control. This paper presents a novel deep learning-based approach for expressive facial animation generation from speech that can exhibit wide-spectrum facial expressions with controllable emotion type and intensity. We propose an emotion controller module to learn the relationship between the emotion variations (e.g., types and intensity) and the corresponding facial expression parameters. It enables emotion-controllable facial animation, where the target expression can be continuously adjusted as desired. The qualitative and quantitative evaluations show that the animation generated by our method is rich in facial emotional expressiveness while retaining accurate lip movement, outperforming other state-of-the-art methods.
Why We Should Report the Details in Subjective Evaluation of TTS More Rigorously
Jun 03, 2023
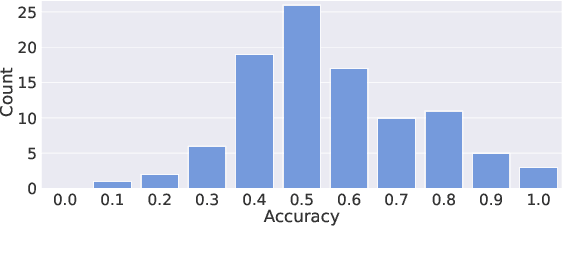
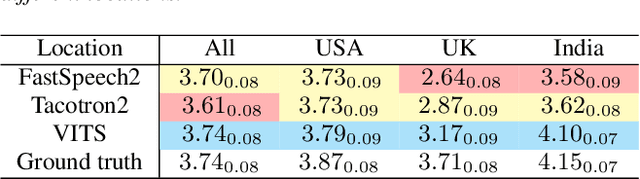
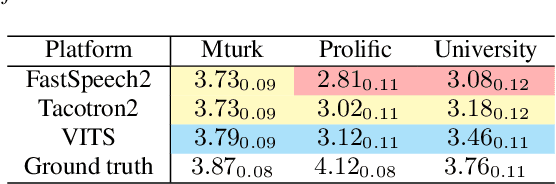
This paper emphasizes the importance of reporting experiment details in subjective evaluations and demonstrates how such details can significantly impact evaluation results in the field of speech synthesis. Through an analysis of 80 papers presented at INTERSPEECH 2022, we find a lack of thorough reporting on critical details such as evaluator recruitment and filtering, instructions and payments, and the geographic and linguistic backgrounds of evaluators. To illustrate the effect of these details on evaluation outcomes, we conducted mean opinion score (MOS) tests on three well-known TTS systems under different evaluation settings and we obtain at least three distinct rankings of TTS models. We urge the community to report experiment details in subjective evaluations to improve the reliability and interpretability of experimental results.