 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Master-ASR: Achieving Multilingual Scalability and Low-Resource Adaptation in ASR with Modular Learning
Jun 23, 2023
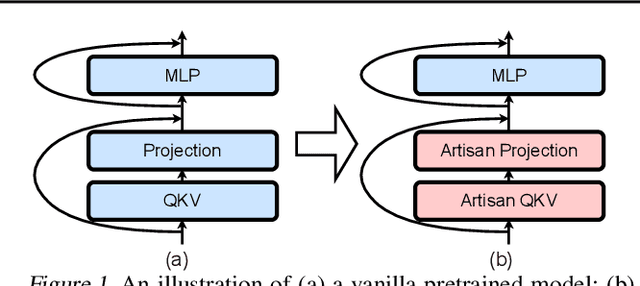
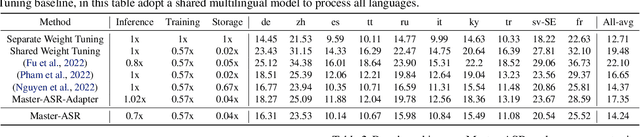
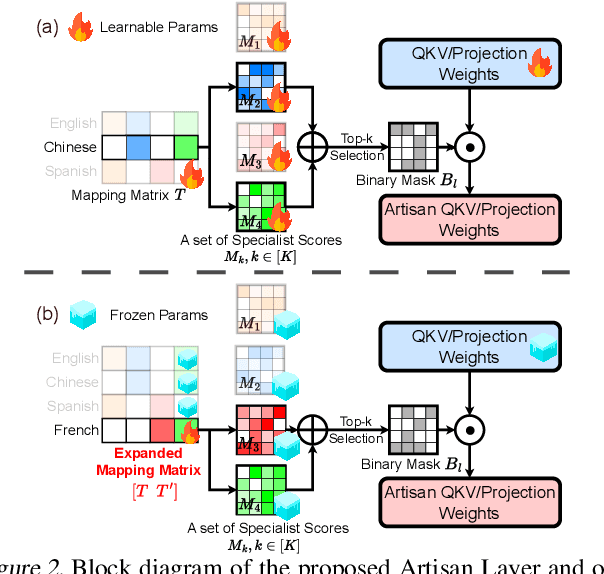
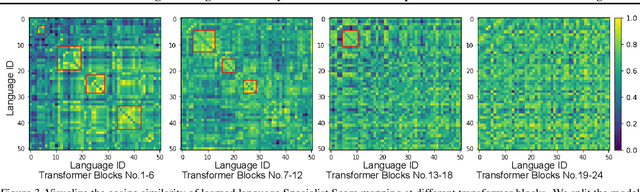
Despite the impressive performance recently achieved by automatic speech recognition (ASR), we observe two primary challenges that hinder its broader applications: (1) The difficulty of introducing scalability into the model to support more languages with limited training, inference, and storage overhead; (2) The low-resource adaptation ability that enables effective low-resource adaptation while avoiding over-fitting and catastrophic forgetting issues. Inspired by recent findings, we hypothesize that we can address the above challenges with modules widely shared across languages. To this end, we propose an ASR framework, dubbed \METHODNS, that, \textit{for the first time}, simultaneously achieves strong multilingual scalability and low-resource adaptation ability thanks to its modularize-then-assemble strategy. Specifically, \METHOD learns a small set of generalizable sub-modules and adaptively assembles them for different languages to reduce the multilingual overhead and enable effective knowledge transfer for low-resource adaptation. Extensive experiments and visualizations demonstrate that \METHOD can effectively discover language similarity and improve multilingual and low-resource ASR performance over state-of-the-art (SOTA) methods, e.g., under multilingual-ASR, our framework achieves a 0.13$\sim$2.41 lower character error rate (CER) with 30\% smaller inference overhead over SOTA solutions on multilingual ASR and a comparable CER, with nearly 50 times fewer trainable parameters over SOTA solutions on low-resource tuning, respectively.
Contrastive Learning-Based Audio to Lyrics Alignment for Multiple Languages
Jun 13, 2023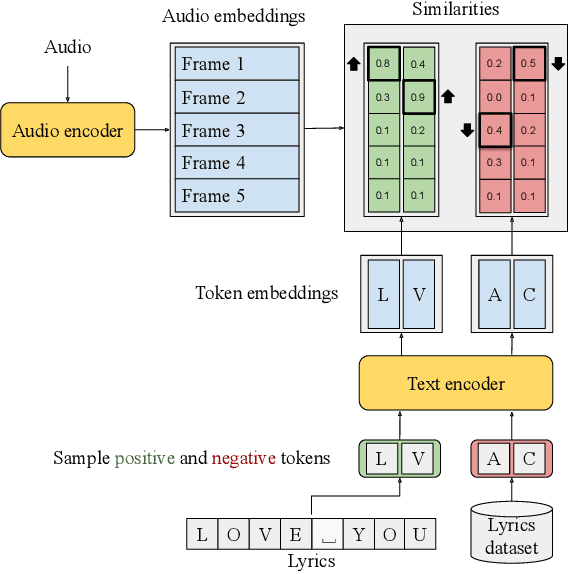
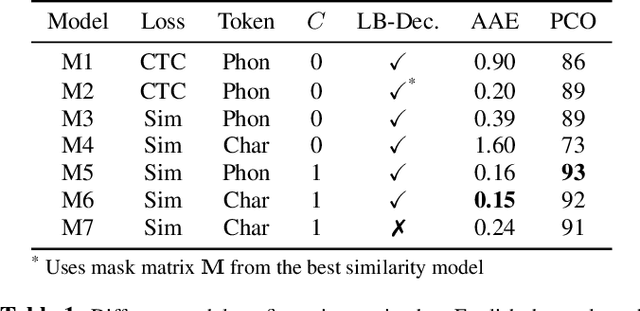
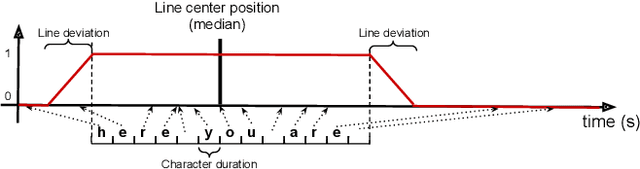
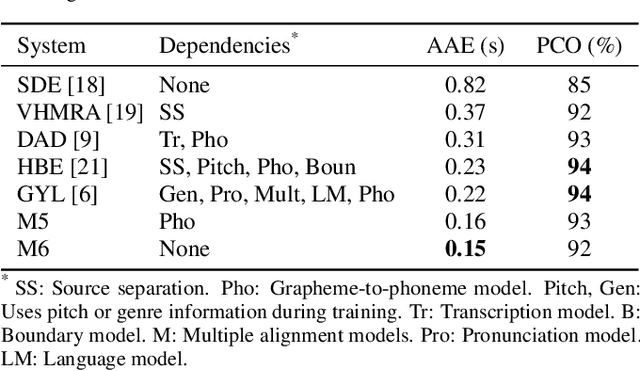
Lyrics alignment gained considerable attention in recent years. State-of-the-art systems either re-use established speech recognition toolkits, or design end-to-end solutions involving a Connectionist Temporal Classification (CTC) loss. However, both approaches suffer from specific weaknesses: toolkits are known for their complexity, and CTC systems use a loss designed for transcription which can limit alignment accuracy. In this paper, we use instead a contrastive learning procedure that derives cross-modal embeddings linking the audio and text domains. This way, we obtain a novel system that is simple to train end-to-end, can make use of weakly annotated training data, jointly learns a powerful text model, and is tailored to alignment. The system is not only the first to yield an average absolute error below 0.2 seconds on the standard Jamendo dataset but it is also robust to other languages, even when trained on English data only. Finally, we release word-level alignments for the JamendoLyrics Multi-Lang dataset.
* 5 pages, accepted at the International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2023
Large-scale Language Model Rescoring on Long-form Data
Jun 13, 2023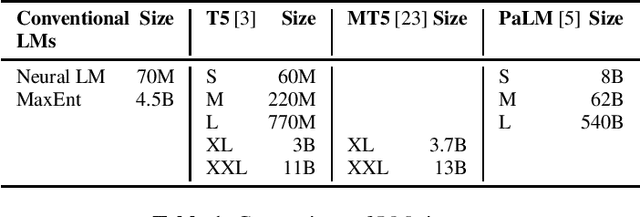
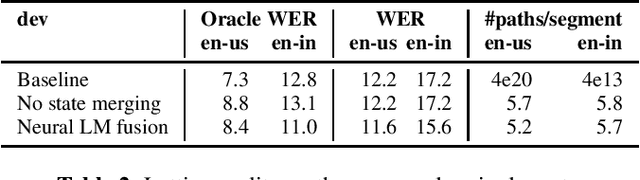


In this work, we study the impact of Large-scale Language Models (LLM) on Automated Speech Recognition (ASR) of YouTube videos, which we use as a source for long-form ASR. We demonstrate up to 8\% relative reduction in Word Error Eate (WER) on US English (en-us) and code-switched Indian English (en-in) long-form ASR test sets and a reduction of up to 30\% relative on Salient Term Error Rate (STER) over a strong first-pass baseline that uses a maximum-entropy based language model. Improved lattice processing that results in a lattice with a proper (non-tree) digraph topology and carrying context from the 1-best hypothesis of the previous segment(s) results in significant wins in rescoring with LLMs. We also find that the gains in performance from the combination of LLMs trained on vast quantities of available data (such as C4) and conventional neural LMs is additive and significantly outperforms a strong first-pass baseline with a maximum entropy LM.
* 5 pages, accepted in ICASSP 2023
TEA-PSE 3.0: Tencent-Ethereal-Audio-Lab Personalized Speech Enhancement System For ICASSP 2023 DNS Challenge
Mar 14, 2023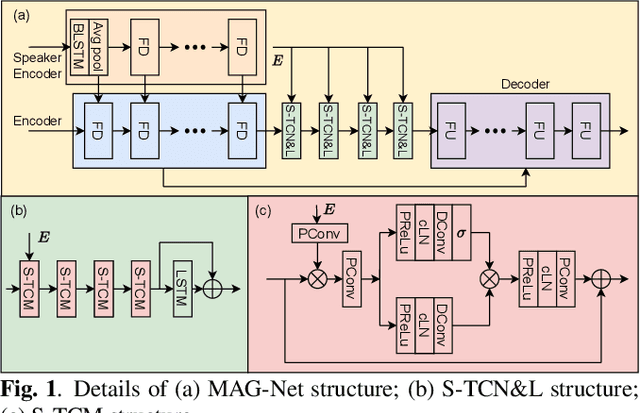
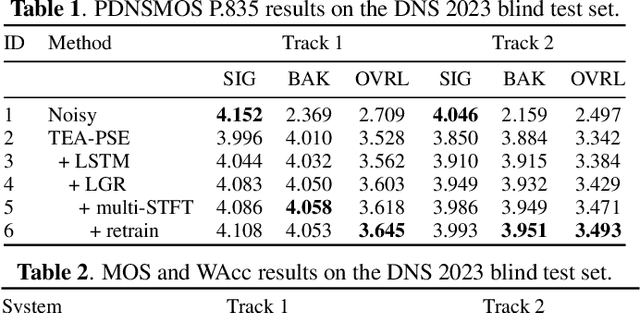
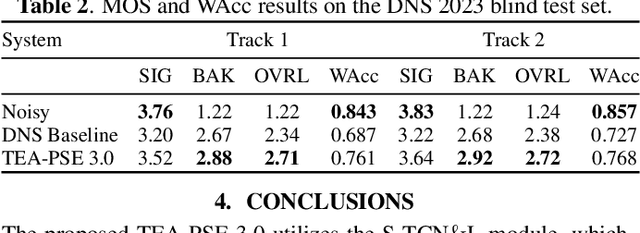
This paper introduces the Unbeatable Team's submission to the ICASSP 2023 Deep Noise Suppression (DNS) Challenge. We expand our previous work, TEA-PSE, to its upgraded version -- TEA-PSE 3.0. Specifically, TEA-PSE 3.0 incorporates a residual LSTM after squeezed temporal convolution network (S-TCN) to enhance sequence modeling capabilities. Additionally, the local-global representation (LGR) structure is introduced to boost speaker information extraction, and multi-STFT resolution loss is used to effectively capture the time-frequency characteristics of the speech signals. Moreover, retraining methods are employed based on the freeze training strategy to fine-tune the system. According to the official results, TEA-PSE 3.0 ranks 1st in both ICASSP 2023 DNS-Challenge track 1 and track 2.
Emphasizing Unseen Words: New Vocabulary Acquisition for End-to-End Speech Recognition
Feb 21, 2023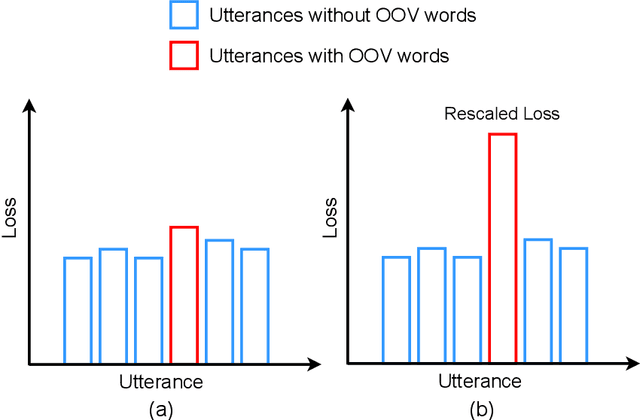
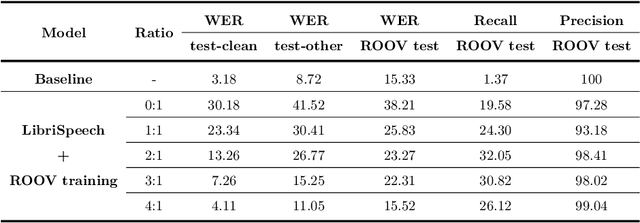
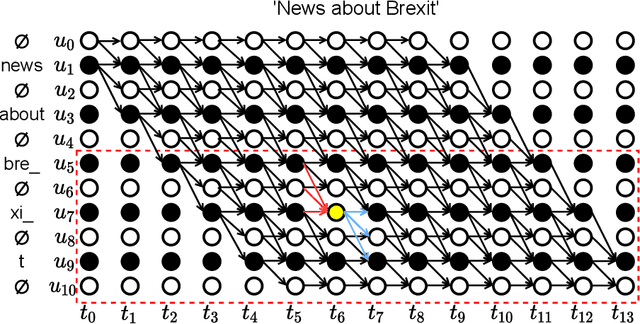
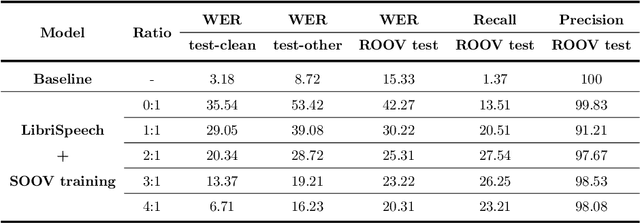
Due to the dynamic nature of human language, automatic speech recognition (ASR) systems need to continuously acquire new vocabulary. Out-Of-Vocabulary (OOV) words, such as trending words and new named entities, pose problems to modern ASR systems that require long training times to adapt their large numbers of parameters. Different from most previous research focusing on language model post-processing, we tackle this problem on an earlier processing level and eliminate the bias in acoustic modeling to recognize OOV words acoustically. We propose to generate OOV words using text-to-speech systems and to rescale losses to encourage neural networks to pay more attention to OOV words. Specifically, we enlarge the classification loss used for training neural networks' parameters of utterances containing OOV words (sentence-level), or rescale the gradient used for back-propagation for OOV words (word-level), when fine-tuning a previously trained model on synthetic audio. To overcome catastrophic forgetting, we also explore the combination of loss rescaling and model regularization, i.e. L2 regularization and elastic weight consolidation (EWC). Compared with previous methods that just fine-tune synthetic audio with EWC, the experimental results on the LibriSpeech benchmark reveal that our proposed loss rescaling approach can achieve significant improvement on the recall rate with only a slight decrease on word error rate. Moreover, word-level rescaling is more stable than utterance-level rescaling and leads to higher recall rates and precision on OOV word recognition. Furthermore, our proposed combined loss rescaling and weight consolidation methods can support continual learning of an ASR system.
L2 proficiency assessment using self-supervised speech representations
Nov 16, 2022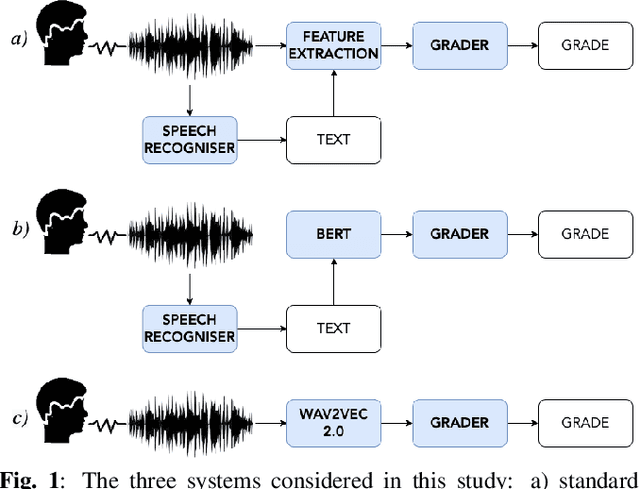
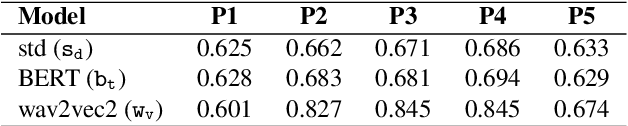
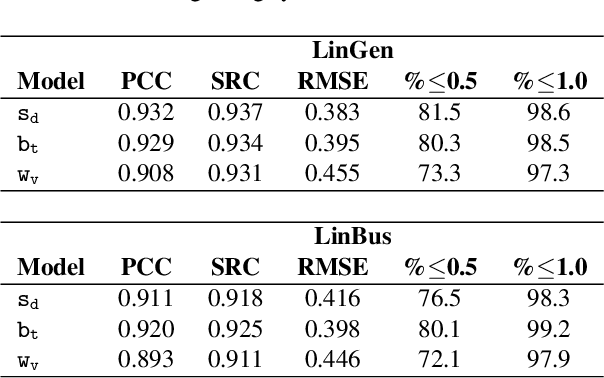
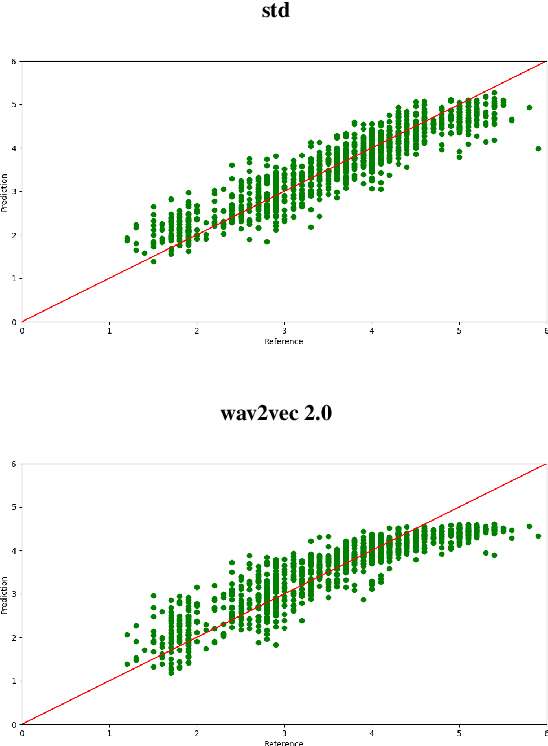
There has been a growing demand for automated spoken language assessment systems in recent years. A standard pipeline for this process is to start with a speech recognition system and derive features, either hand-crafted or based on deep-learning, that exploit the transcription and audio. Though these approaches can yield high performance systems, they require speech recognition systems that can be used for L2 speakers, and preferably tuned to the specific form of test being deployed. Recently a self-supervised speech representation based scheme, requiring no speech recognition, was proposed. This work extends the initial analysis conducted on this approach to a large scale proficiency test, Linguaskill, that comprises multiple parts, each designed to assess different attributes of a candidate's speaking proficiency. The performance of the self-supervised, wav2vec 2.0, system is compared to a high performance hand-crafted assessment system and a BERT-based text system both of which use speech transcriptions. Though the wav2vec 2.0 based system is found to be sensitive to the nature of the response, it can be configured to yield comparable performance to systems requiring a speech transcription, and yields gains when appropriately combined with standard approaches.
Synthetic Wave-Geometric Impulse Responses for Improved Speech Dereverberation
Dec 10, 2022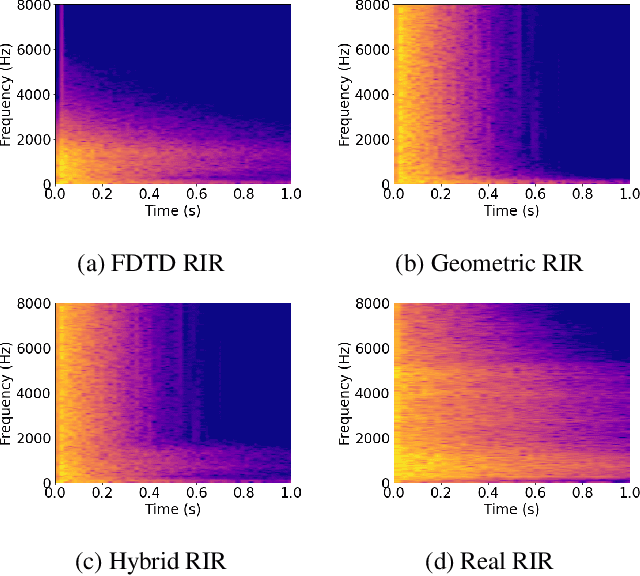
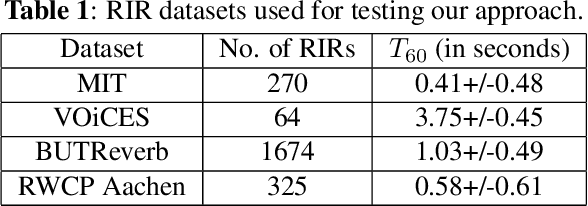
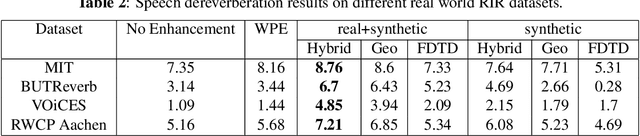
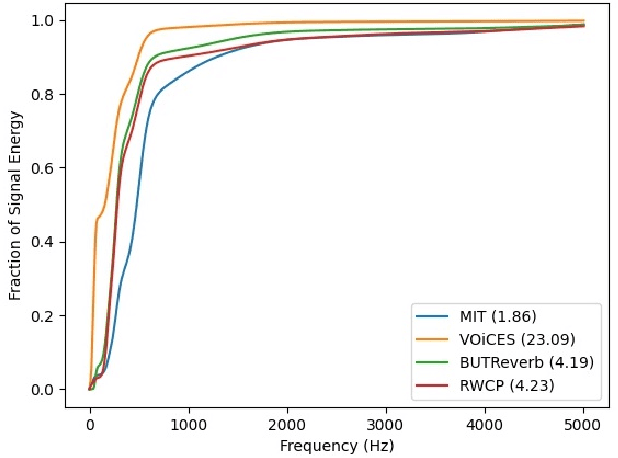
We present a novel approach to improve the performance of learning-based speech dereverberation using accurate synthetic datasets. Our approach is designed to recover the reverb-free signal from a reverberant speech signal. We show that accurately simulating the low-frequency components of Room Impulse Responses (RIRs) is important to achieving good dereverberation. We use the GWA dataset that consists of synthetic RIRs generated in a hybrid fashion: an accurate wave-based solver is used to simulate the lower frequencies and geometric ray tracing methods simulate the higher frequencies. We demonstrate that speech dereverberation models trained on hybrid synthetic RIRs outperform models trained on RIRs generated by prior geometric ray tracing methods on four real-world RIR datasets.
ASDF: A Differential Testing Framework for Automatic Speech Recognition Systems
Feb 11, 2023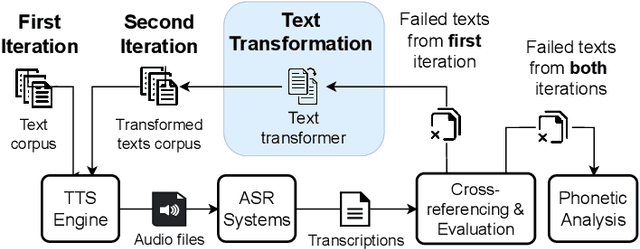
Recent years have witnessed wider adoption of Automated Speech Recognition (ASR) techniques in various domains. Consequently, evaluating and enhancing the quality of ASR systems is of great importance. This paper proposes ASDF, an Automated Speech Recognition Differential Testing Framework for testing ASR systems. ASDF extends an existing ASR testing tool, the CrossASR++, which synthesizes test cases from a text corpus. However, CrossASR++ fails to make use of the text corpus efficiently and provides limited information on how the failed test cases can improve ASR systems. To address these limitations, our tool incorporates two novel features: (1) a text transformation module to boost the number of generated test cases and uncover more errors in ASR systems and (2) a phonetic analysis module to identify on which phonemes the ASR system tend to produce errors. ASDF generates more high-quality test cases by applying various text transformation methods (e.g., change tense) to the texts in failed test cases. By doing so, ASDF can utilize a small text corpus to generate a large number of audio test cases, something which CrossASR++ is not capable of. In addition, ASDF implements more metrics to evaluate the performance of ASR systems from multiple perspectives. ASDF performs phonetic analysis on the identified failed test cases to identify the phonemes that ASR systems tend to transcribe incorrectly, providing useful information for developers to improve ASR systems. The demonstration video of our tool is made online at https://www.youtube.com/watch?v=DzVwfc3h9As. The implementation is available at https://github.com/danielyuenhx/asdf-differential-testing.
Complex-Valued Time-Frequency Self-Attention for Speech Dereverberation
Nov 22, 2022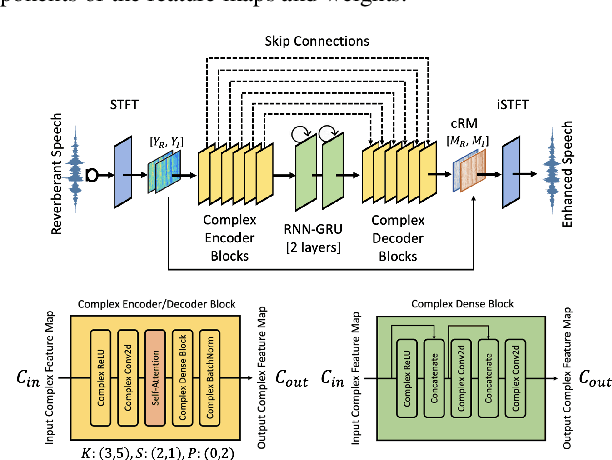
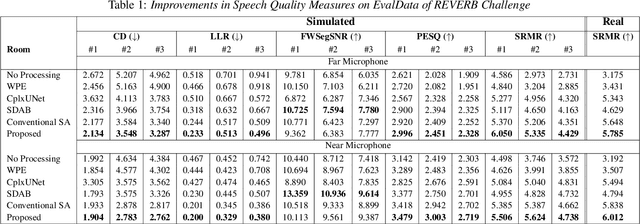
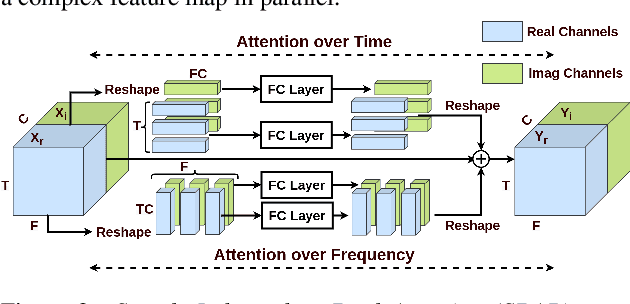
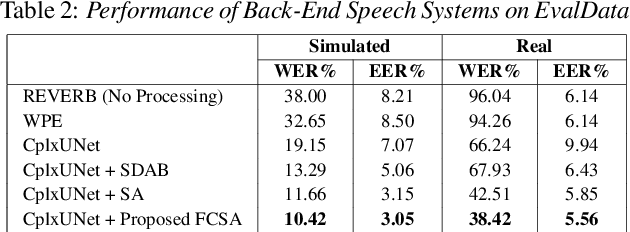
Several speech processing systems have demonstrated considerable performance improvements when deep complex neural networks (DCNN) are coupled with self-attention (SA) networks. However, the majority of DCNN-based studies on speech dereverberation that employ self-attention do not explicitly account for the inter-dependencies between real and imaginary features when computing attention. In this study, we propose a complex-valued T-F attention (TFA) module that models spectral and temporal dependencies by computing two-dimensional attention maps across time and frequency dimensions. We validate the effectiveness of our proposed complex-valued TFA module with the deep complex convolutional recurrent network (DCCRN) using the REVERB challenge corpus. Experimental findings indicate that integrating our complex-TFA module with DCCRN improves overall speech quality and performance of back-end speech applications, such as automatic speech recognition, compared to earlier approaches for self-attention.
hierarchical network with decoupled knowledge distillation for speech emotion recognition
Mar 09, 2023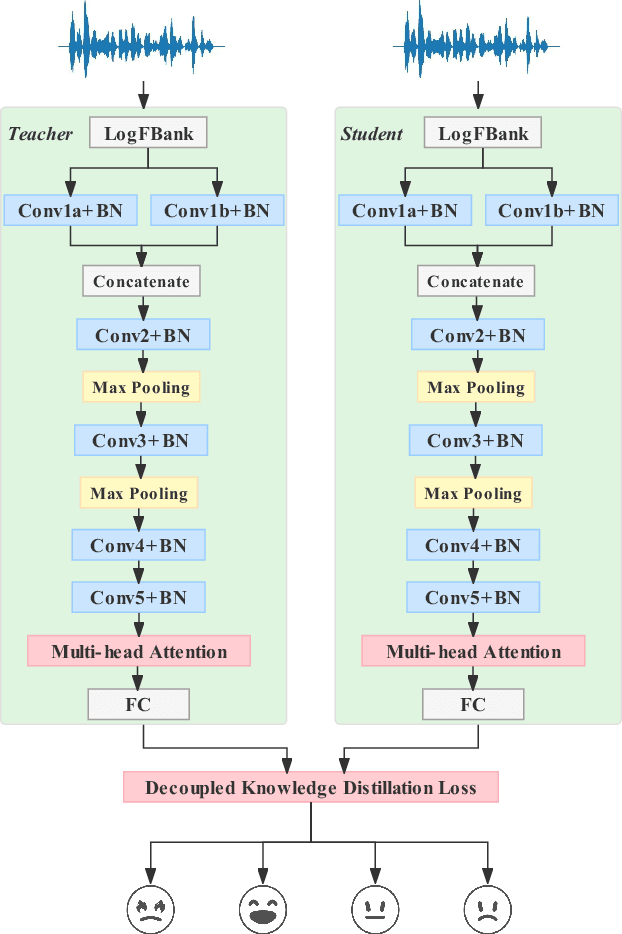
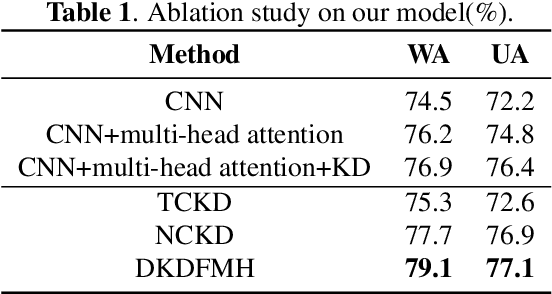
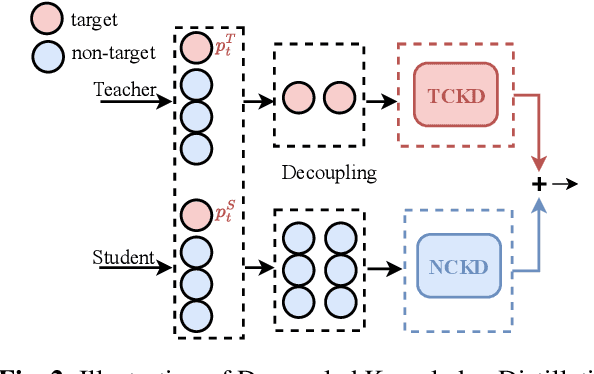
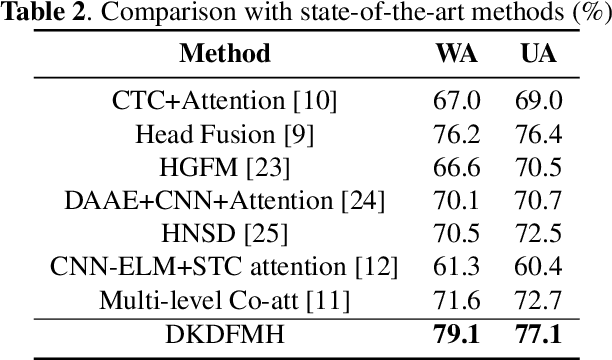
The goal of Speech Emotion Recognition (SER) is to enable computers to recognize the emotion category of a given utterance in the same way that humans do. The accuracy of SER is strongly dependent on the validity of the utterance-level representation obtained by the model. Nevertheless, the ``dark knowledge" carried by non-target classes is always ignored by previous studies. In this paper, we propose a hierarchical network, called DKDFMH, which employs decoupled knowledge distillation in a deep convolutional neural network with a fused multi-head attention mechanism. Our approach applies logit distillation to obtain higher-level semantic features from different scales of attention sets and delve into the knowledge carried by non-target classes, thus guiding the model to focus more on the differences between sentiment features. To validate the effectiveness of our model, we conducted experiments on the Interactive Emotional Dyadic Motion Capture (IEMOCAP) dataset. We achieved competitive performance, with 79.1% weighted accuracy (WA) and 77.1% unweighted accuracy (UA). To the best of our knowledge, this is the first time since 2015 that logit distillation has been returned to state-of-the-art status.