 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Timestamped Embedding-Matching Acoustic-to-Word CTC ASR
Jun 20, 2023
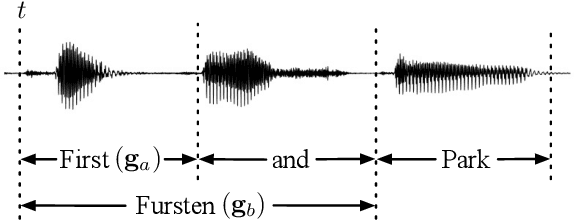
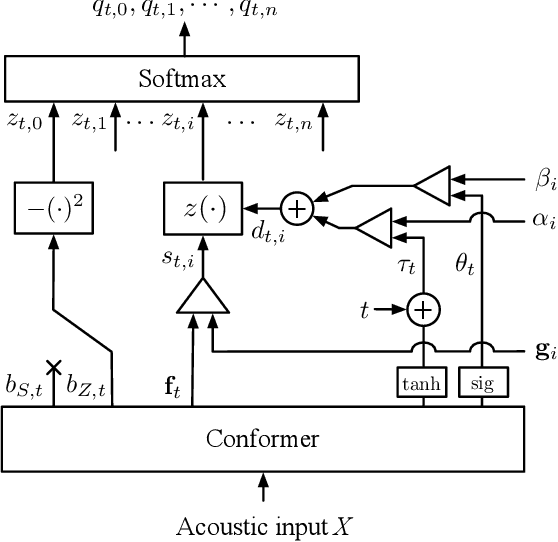
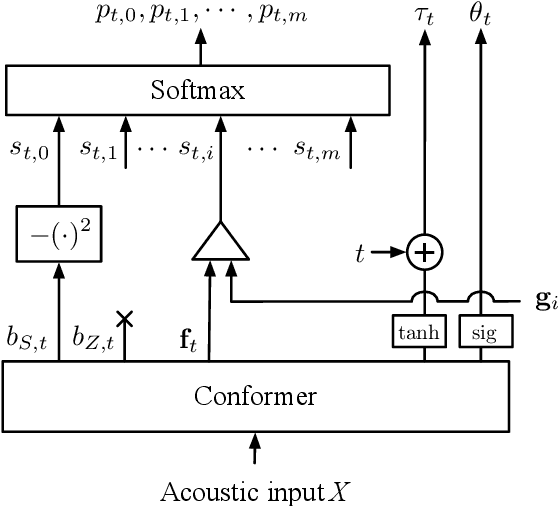
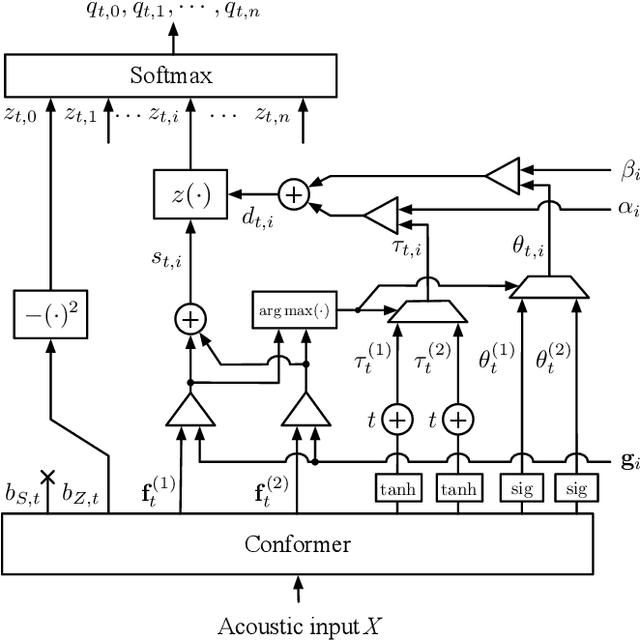
In this work, we describe a novel method of training an embedding-matching word-level connectionist temporal classification (CTC) automatic speech recognizer (ASR) such that it directly produces word start times and durations, required by many real-world applications, in addition to the transcription. The word timestamps enable the ASR to output word segmentations and word confusion networks without relying on a secondary model or forced alignment process when testing. Our proposed system has similar word segmentation accuracy as a hybrid DNN-HMM (Deep Neural Network-Hidden Markov Model) system, with less than 3ms difference in mean absolute error in word start times on TIMIT data. At the same time, we observed less than 5% relative increase in the word error rate compared to the non-timestamped system when using the same audio training data and nearly identical model size. We also contribute more rigorous analysis of multiple-hypothesis embedding-matching ASR in general.
VideoDubber: Machine Translation with Speech-Aware Length Control for Video Dubbing
Nov 30, 2022
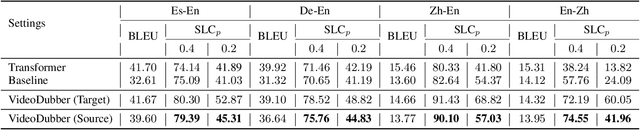
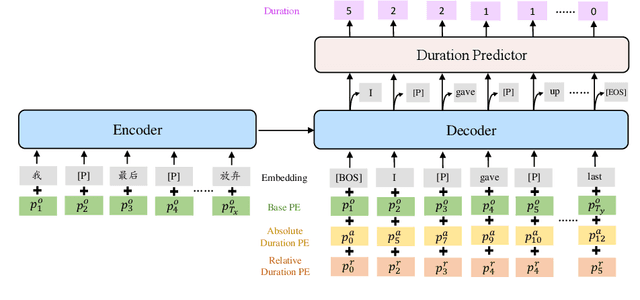
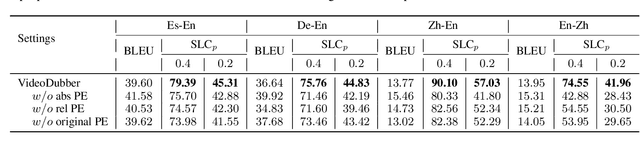
Video dubbing aims to translate the original speech in a film or television program into the speech in a target language, which can be achieved with a cascaded system consisting of speech recognition, machine translation and speech synthesis. To ensure the translated speech to be well aligned with the corresponding video, the length/duration of the translated speech should be as close as possible to that of the original speech, which requires strict length control. Previous works usually control the number of words or characters generated by the machine translation model to be similar to the source sentence, without considering the isochronicity of speech as the speech duration of words/characters in different languages varies. In this paper, we propose a machine translation system tailored for the task of video dubbing, which directly considers the speech duration of each token in translation, to match the length of source and target speech. Specifically, we control the speech length of generated sentence by guiding the prediction of each word with the duration information, including the speech duration of itself as well as how much duration is left for the remaining words. We design experiments on four language directions (German -> English, Spanish -> English, Chinese <-> English), and the results show that the proposed method achieves better length control ability on the generated speech than baseline methods. To make up the lack of real-world datasets, we also construct a real-world test set collected from films to provide comprehensive evaluations on the video dubbing task.
BayesSpeech: A Bayesian Transformer Network for Automatic Speech Recognition
Jan 16, 2023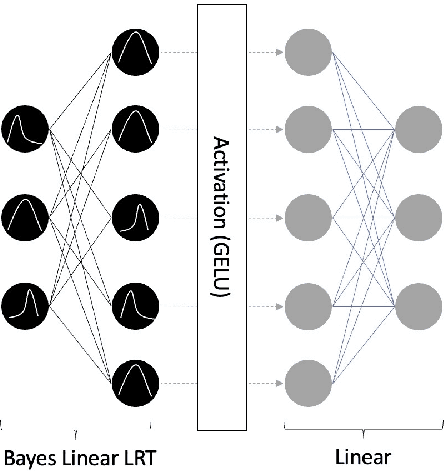
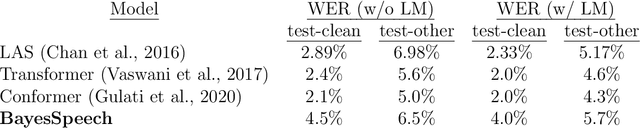
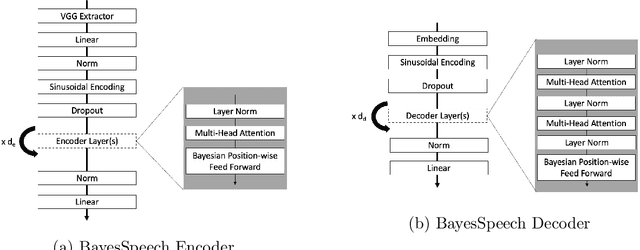
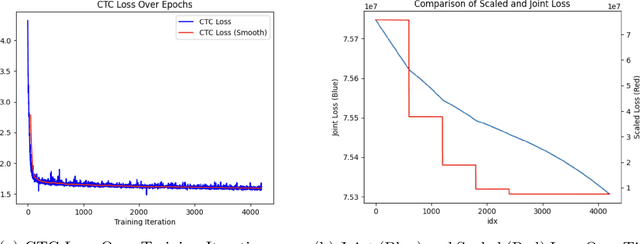
Recent developments using End-to-End Deep Learning models have been shown to have near or better performance than state of the art Recurrent Neural Networks (RNNs) on Automatic Speech Recognition tasks. These models tend to be lighter weight and require less training time than traditional RNN-based approaches. However, these models take frequentist approach to weight training. In theory, network weights are drawn from a latent, intractable probability distribution. We introduce BayesSpeech for end-to-end Automatic Speech Recognition. BayesSpeech is a Bayesian Transformer Network where these intractable posteriors are learned through variational inference and the local reparameterization trick without recurrence. We show how the introduction of variance in the weights leads to faster training time and near state-of-the-art performance on LibriSpeech-960.
Detecting and Characterizing Political Incivility on Social Media
May 24, 2023
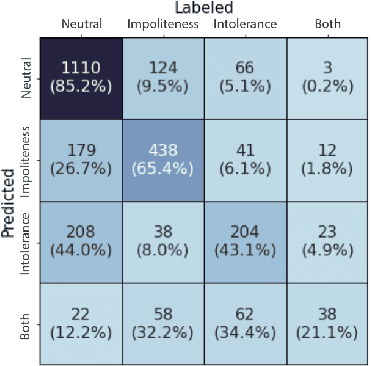
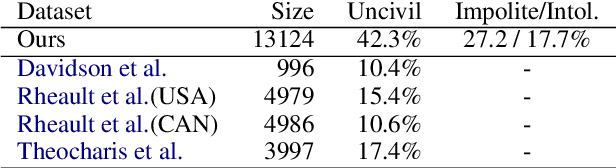
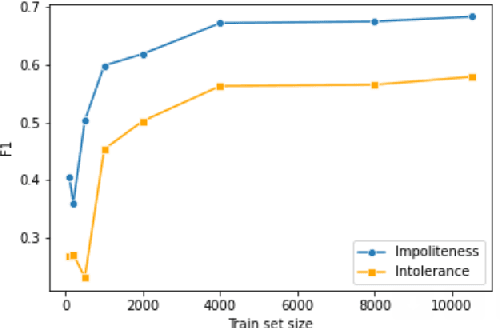
Researchers of political communication study the impact and perceptions of political incivility on social media. Yet, so far, relatively few works attempted to automatically detect and characterize political incivility. In our work, we study political incivility in Twitter, presenting several research contributions. First, we present state-of-the-art incivility detection results using a large dataset, which we collected and labeled via crowd sourcing. Importantly, we distinguish between uncivil political speech that is impolite and intolerant anti-democratic discourse. Applying political incivility detection at large-scale, we derive insights regarding the prevalence of this phenomenon across users, and explore the network characteristics of users who are susceptible to disseminating uncivil political content online. Finally, we propose an approach for modeling social context information about the tweet author alongside the tweet content, showing that this leads to significantly improved performance on the task of political incivility detection. This result holds promise for related tasks, such as hate speech and stance detection.
Wireless Deep Speech Semantic Transmission
Nov 04, 2022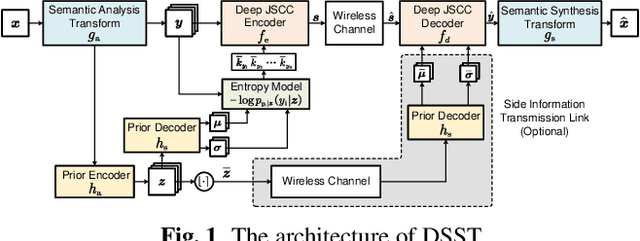
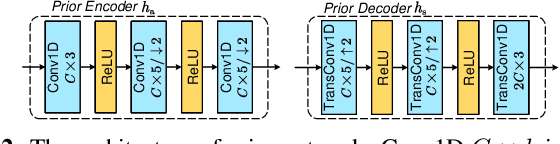
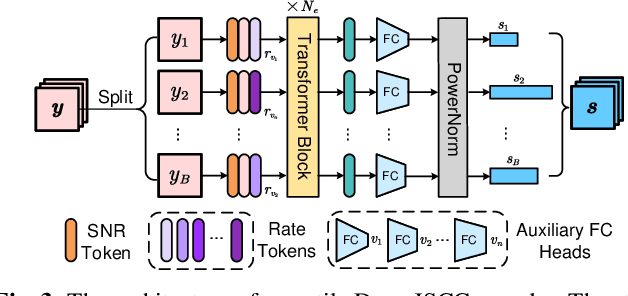
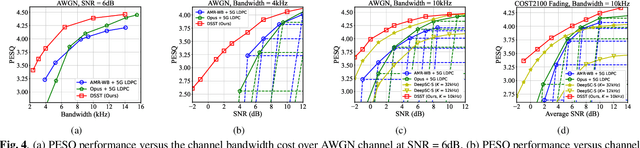
In this paper, we propose a new class of high-efficiency semantic coded transmission methods for end-to-end speech transmission over wireless channels. We name the whole system as deep speech semantic transmission (DSST). Specifically, we introduce a nonlinear transform to map the speech source to semantic latent space and feed semantic features into source-channel encoder to generate the channel-input sequence. Guided by the variational modeling idea, we build an entropy model on the latent space to estimate the importance diversity among semantic feature embeddings. Accordingly, these semantic features of different importance can be allocated with different coding rates reasonably, which maximizes the system coding gain. Furthermore, we introduce a channel signal-to-noise ratio (SNR) adaptation mechanism such that a single model can be applied over various channel states. The end-to-end optimization of our model leads to a flexible rate-distortion (RD) trade-off, supporting versatile wireless speech semantic transmission. Experimental results verify that our DSST system clearly outperforms current engineered speech transmission systems on both objective and subjective metrics. Compared with existing neural speech semantic transmission methods, our model saves up to 75% of channel bandwidth costs when achieving the same quality. An intuitive comparison of audio demos can be found at https://ximoo123.github.io/DSST.
Self-supervised learning with bi-label masked speech prediction for streaming multi-talker speech recognition
Nov 10, 2022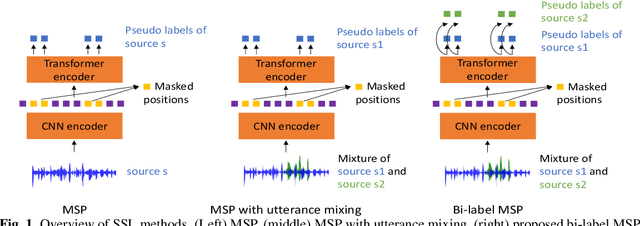
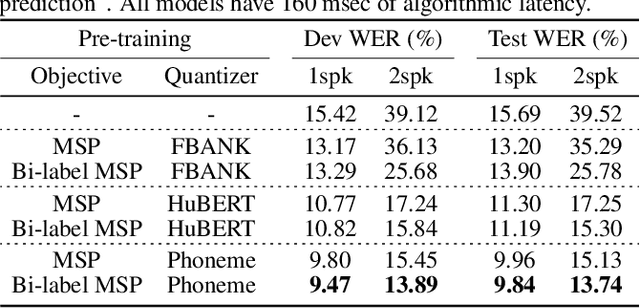

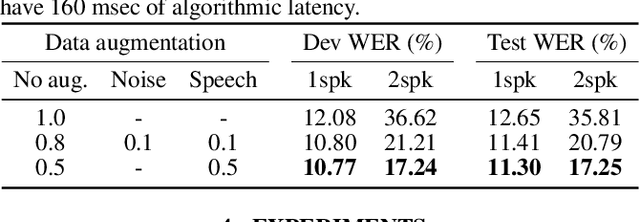
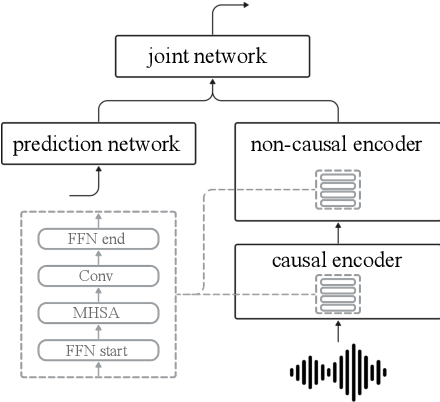
Self-supervised learning (SSL), which utilizes the input data itself for representation learning, has achieved state-of-the-art results for various downstream speech tasks. However, most of the previous studies focused on offline single-talker applications, with limited investigations in multi-talker cases, especially for streaming scenarios. In this paper, we investigate SSL for streaming multi-talker speech recognition, which generates transcriptions of overlapping speakers in a streaming fashion. We first observe that conventional SSL techniques do not work well on this task due to the poor representation of overlapping speech. We then propose a novel SSL training objective, referred to as bi-label masked speech prediction, which explicitly preserves representations of all speakers in overlapping speech. We investigate various aspects of the proposed system including data configuration and quantizer selection. The proposed SSL setup achieves substantially better word error rates on the LibriSpeechMix dataset.
Modular Domain Adaptation for Conformer-Based Streaming ASR
May 22, 2023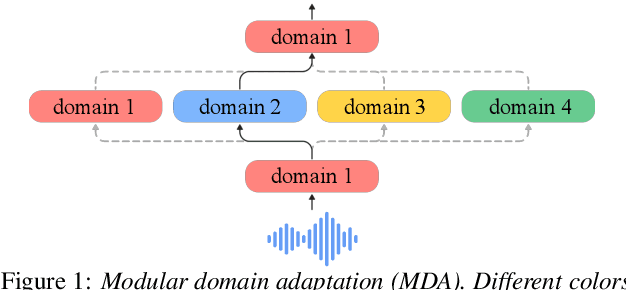
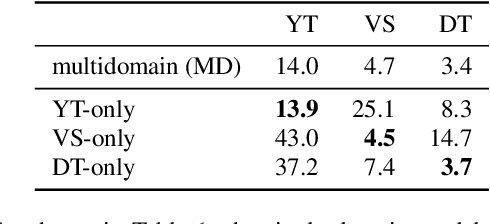
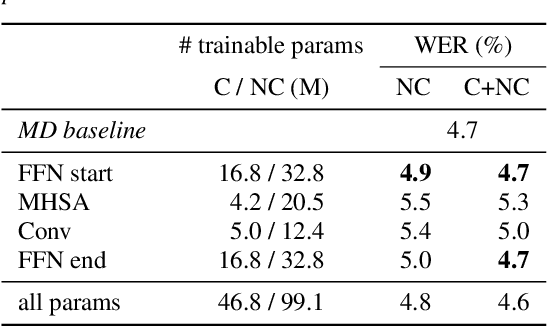
Speech data from different domains has distinct acoustic and linguistic characteristics. It is common to train a single multidomain model such as a Conformer transducer for speech recognition on a mixture of data from all domains. However, changing data in one domain or adding a new domain would require the multidomain model to be retrained. To this end, we propose a framework called modular domain adaptation (MDA) that enables a single model to process multidomain data while keeping all parameters domain-specific, i.e., each parameter is only trained by data from one domain. On a streaming Conformer transducer trained only on video caption data, experimental results show that an MDA-based model can reach similar performance as the multidomain model on other domains such as voice search and dictation by adding per-domain adapters and per-domain feed-forward networks in the Conformer encoder.
Align With Purpose: Optimize Desired Properties in CTC Models with a General Plug-and-Play Framework
Jul 06, 2023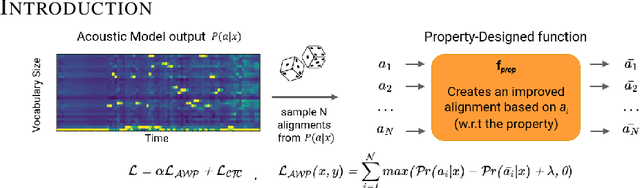

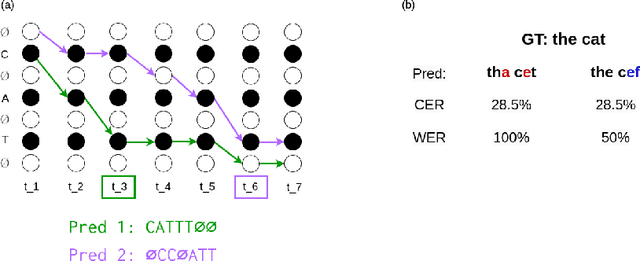
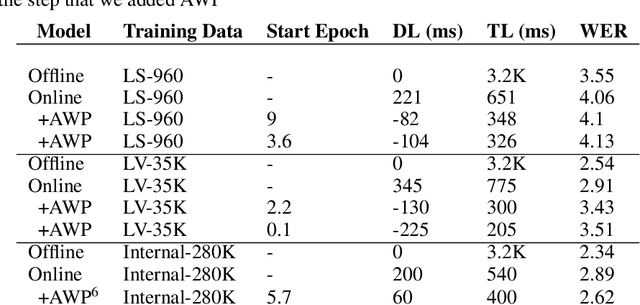
Connectionist Temporal Classification (CTC) is a widely used criterion for training supervised sequence-to-sequence (seq2seq) models. It enables learning the relations between input and output sequences, termed alignments, by marginalizing over perfect alignments (that yield the ground truth), at the expense of imperfect alignments. This binary differentiation of perfect and imperfect alignments falls short of capturing other essential alignment properties that hold significance in other real-world applications. Here we propose $\textit{Align With Purpose}$, a $\textbf{general Plug-and-Play framework}$ for enhancing a desired property in models trained with the CTC criterion. We do that by complementing the CTC with an additional loss term that prioritizes alignments according to a desired property. Our method does not require any intervention in the CTC loss function, enables easy optimization of a variety of properties, and allows differentiation between both perfect and imperfect alignments. We apply our framework in the domain of Automatic Speech Recognition (ASR) and show its generality in terms of property selection, architectural choice, and scale of training dataset (up to 280,000 hours). To demonstrate the effectiveness of our framework, we apply it to two unrelated properties: emission time and word error rate (WER). For the former, we report an improvement of up to 570ms in latency optimization with a minor reduction in WER, and for the latter, we report a relative improvement of 4.5% WER over the baseline models. To the best of our knowledge, these applications have never been demonstrated to work on a scale of data as large as ours. Notably, our method can be implemented using only a few lines of code, and can be extended to other alignment-free loss functions and to domains other than ASR.
Streaming Punctuation: A Novel Punctuation Technique Leveraging Bidirectional Context for Continuous Speech Recognition
Jan 10, 2023


While speech recognition Word Error Rate (WER) has reached human parity for English, continuous speech recognition scenarios such as voice typing and meeting transcriptions still suffer from segmentation and punctuation problems, resulting from irregular pausing patterns or slow speakers. Transformer sequence tagging models are effective at capturing long bi-directional context, which is crucial for automatic punctuation. Automatic Speech Recognition (ASR) production systems, however, are constrained by real-time requirements, making it hard to incorporate the right context when making punctuation decisions. Context within the segments produced by ASR decoders can be helpful but limiting in overall punctuation performance for a continuous speech session. In this paper, we propose a streaming approach for punctuation or re-punctuation of ASR output using dynamic decoding windows and measure its impact on punctuation and segmentation accuracy across scenarios. The new system tackles over-segmentation issues, improving segmentation F0.5-score by 13.9%. Streaming punctuation achieves an average BLEUscore improvement of 0.66 for the downstream task of Machine Translation (MT).
* arXiv admin note: substantial text overlap with arXiv:2210.05756
MF-PAM: Accurate Pitch Estimation through Periodicity Analysis and Multi-level Feature Fusion
Jun 16, 2023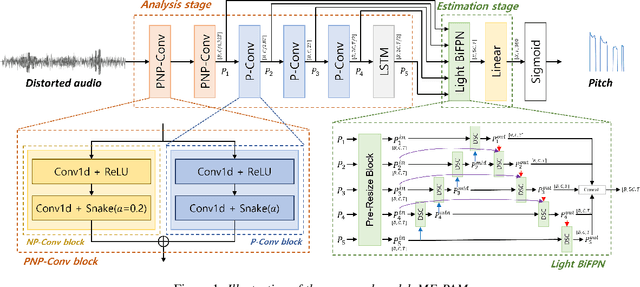
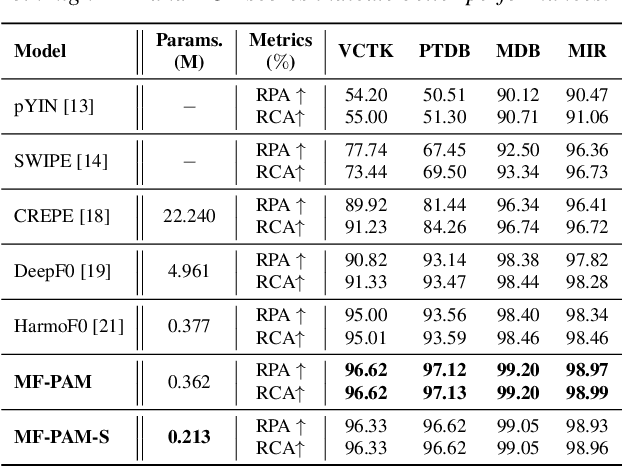
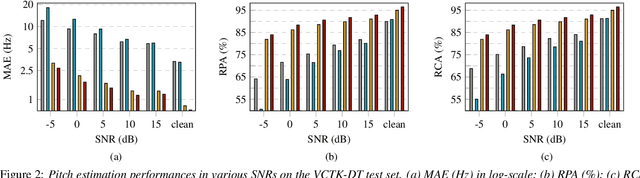
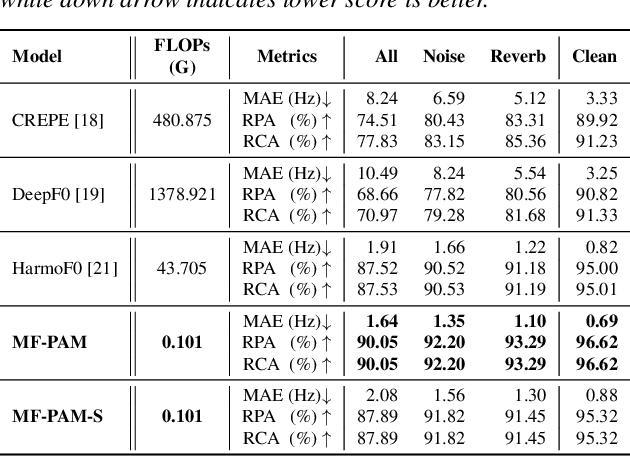
We introduce Multi-level feature Fusion-based Periodicity Analysis Model (MF-PAM), a novel deep learning-based pitch estimation model that accurately estimates pitch trajectory in noisy and reverberant acoustic environments. Our model leverages the periodic characteristics of audio signals and involves two key steps: extracting pitch periodicity using periodic non-periodic convolution (PNP-Conv) blocks and estimating pitch by aggregating multi-level features using a modified bi-directional feature pyramid network (BiFPN). We evaluate our model on speech and music datasets and achieve superior pitch estimation performance compared to state-of-the-art baselines while using fewer model parameters. Our model achieves 99.20 % accuracy in pitch estimation on a clean musical dataset. Overall, our proposed model provides a promising solution for accurate pitch estimation in challenging acoustic environments and has potential applications in audio signal processing.