 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Improving Speech Representation Learning via Speech-level and Phoneme-level Masking Approach
Oct 25, 2022
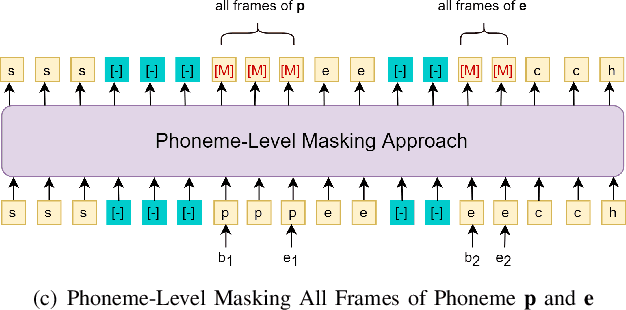
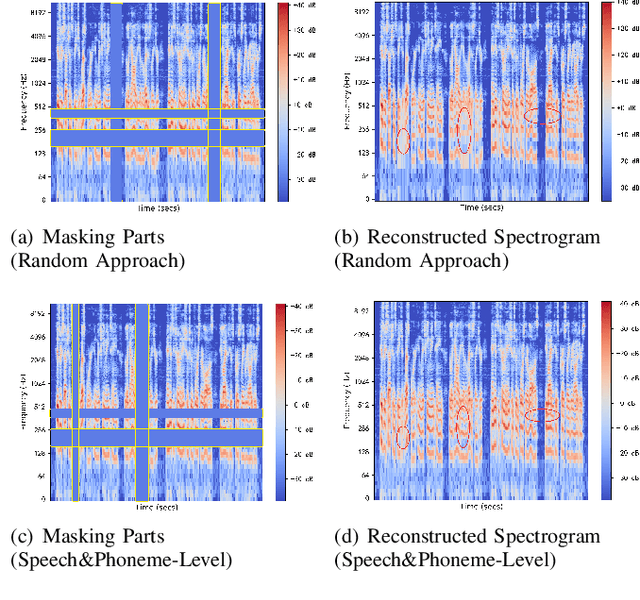

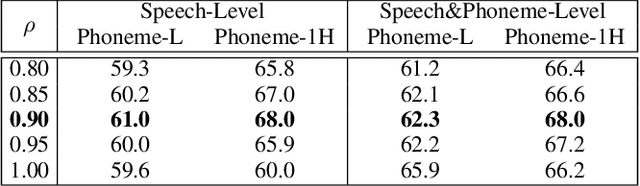
Recovering the masked speech frames is widely applied in speech representation learning. However, most of these models use random masking in the pre-training. In this work, we proposed two kinds of masking approaches: (1) speech-level masking, making the model to mask more speech segments than silence segments, (2) phoneme-level masking, forcing the model to mask the whole frames of the phoneme, instead of phoneme pieces. We pre-trained the model via these two approaches, and evaluated on two downstream tasks, phoneme classification and speaker recognition. The experiments demonstrated that the proposed masking approaches are beneficial to improve the performance of speech representation.
Towards generalizing deep-audio fake detection networks
May 22, 2023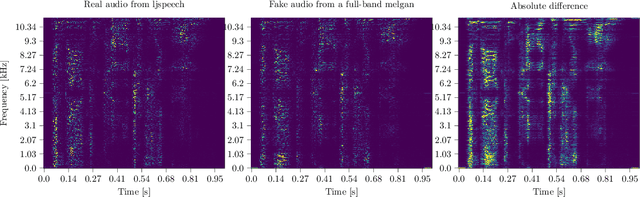
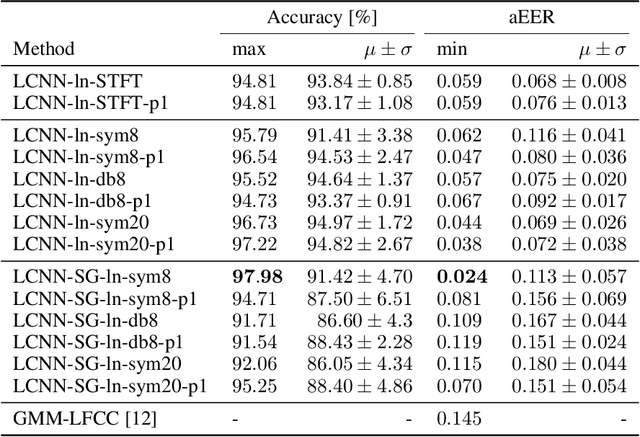
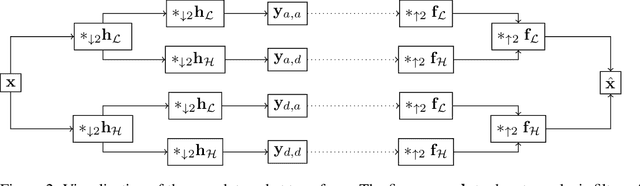
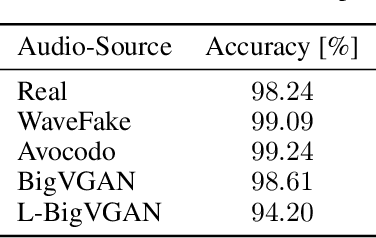
Today's generative neural networks allow the creation of high-quality synthetic speech at scale. While we welcome the creative use of this new technology, we must also recognize the risks. As synthetic speech is abused for both monetary and identity theft, we require a broad set of deep fake identification tools. Furthermore, previous work reported a limited ability of deep classifiers to generalize to unseen audio generators. By leveraging the wavelet-packet and short-time Fourier transform, we train excellent lightweight detectors that generalize. We report improved results on an extension of the WaveFake dataset. To account for the rapid progress in the field, we additionally consider samples drawn from the novel Avocodo and BigVGAN networks.
Losses Can Be Blessings: Routing Self-Supervised Speech Representations Towards Efficient Multilingual and Multitask Speech Processing
Nov 02, 2022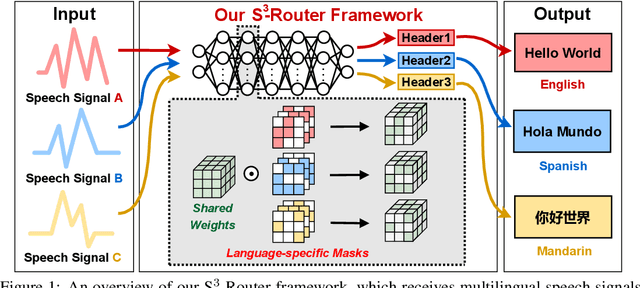
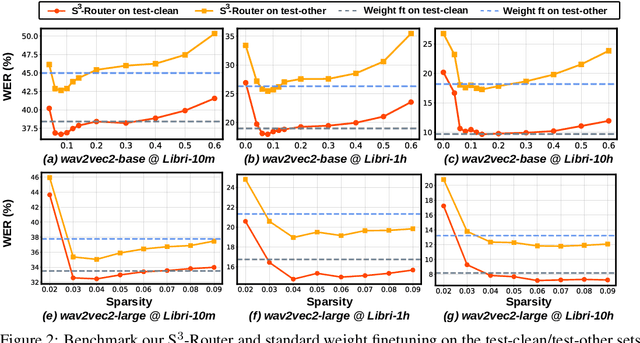
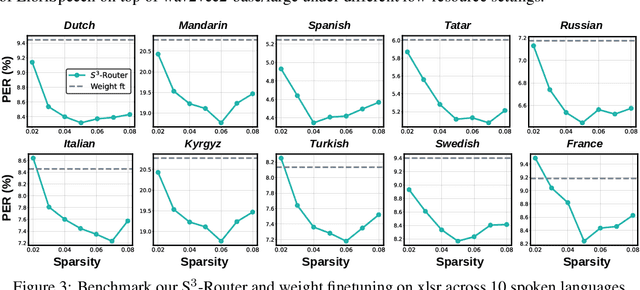
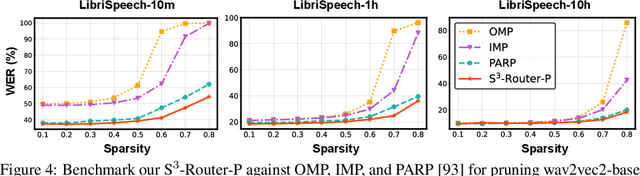
Self-supervised learning (SSL) for rich speech representations has achieved empirical success in low-resource Automatic Speech Recognition (ASR) and other speech processing tasks, which can mitigate the necessity of a large amount of transcribed speech and thus has driven a growing demand for on-device ASR and other speech processing. However, advanced speech SSL models have become increasingly large, which contradicts the limited on-device resources. This gap could be more severe in multilingual/multitask scenarios requiring simultaneously recognizing multiple languages or executing multiple speech processing tasks. Additionally, strongly overparameterized speech SSL models tend to suffer from overfitting when being finetuned on low-resource speech corpus. This work aims to enhance the practical usage of speech SSL models towards a win-win in both enhanced efficiency and alleviated overfitting via our proposed S$^3$-Router framework, which for the first time discovers that simply discarding no more than 10\% of model weights via only finetuning model connections of speech SSL models can achieve better accuracy over standard weight finetuning on downstream speech processing tasks. More importantly, S$^3$-Router can serve as an all-in-one technique to enable (1) a new finetuning scheme, (2) an efficient multilingual/multitask solution, (3) a state-of-the-art ASR pruning technique, and (4) a new tool to quantitatively analyze the learned speech representation. We believe S$^3$-Router has provided a new perspective for practical deployment of speech SSL models. Our codes are available at: https://github.com/GATECH-EIC/S3-Router.
Anytime, Anywhere: Human Arm Pose from Smartwatch Data for Ubiquitous Robot Control and Teleoperation
Jun 22, 2023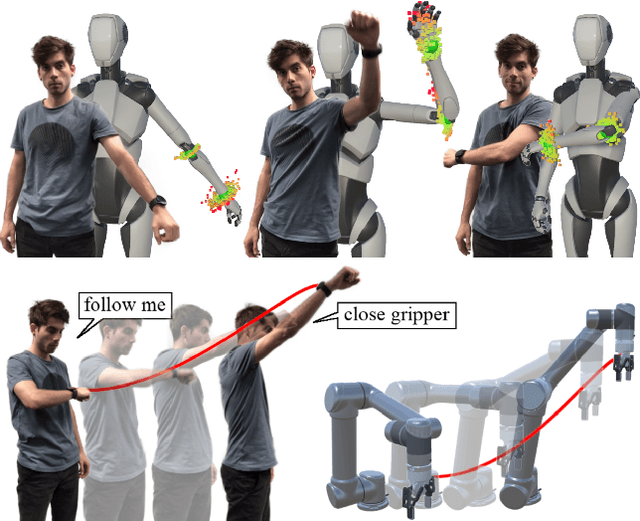

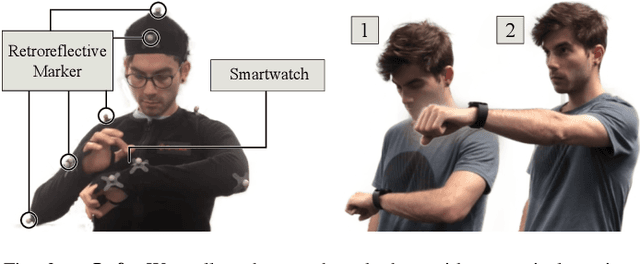
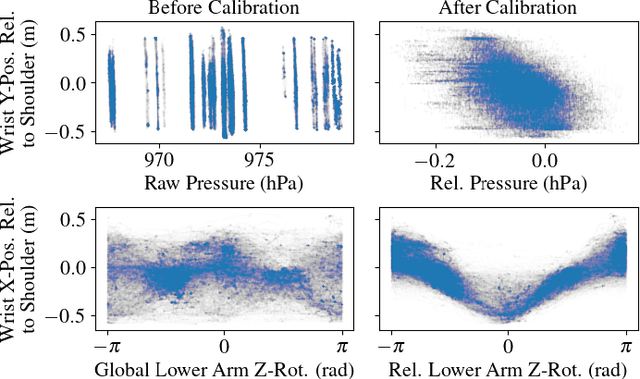
This work devises an optimized machine learning approach for human arm pose estimation from a single smartwatch. Our approach results in a distribution of possible wrist and elbow positions, which allows for a measure of uncertainty and the detection of multiple possible arm posture solutions, i.e., multimodal pose distributions. Combining estimated arm postures with speech recognition, we turn the smartwatch into a ubiquitous, low-cost and versatile robot control interface. We demonstrate in two use-cases that this intuitive control interface enables users to swiftly intervene in robot behavior, to temporarily adjust their goal, or to train completely new control policies by imitation. Extensive experiments show that the approach results in a 40% reduction in prediction error over the current state-of-the-art and achieves a mean error of 2.56cm for wrist and elbow positions.
Evaluation of Automated Speech Recognition Systems for Conversational Speech: A Linguistic Perspective
Nov 05, 2022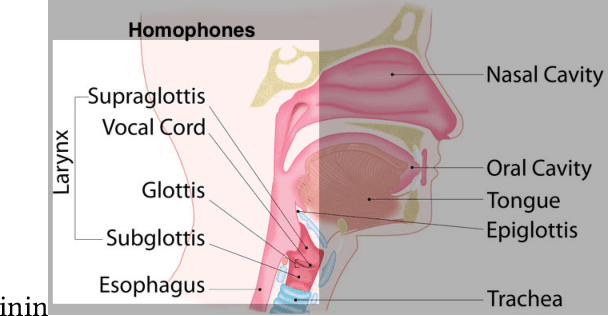

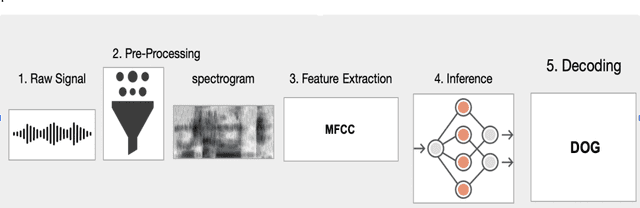

Automatic speech recognition (ASR) meets more informal and free-form input data as voice user interfaces and conversational agents such as the voice assistants such as Alexa, Google Home, etc., gain popularity. Conversational speech is both the most difficult and environmentally relevant sort of data for speech recognition. In this paper, we take a linguistic perspective, and take the French language as a case study toward disambiguation of the French homophones. Our contribution aims to provide more insight into human speech transcription accuracy in conditions to reproduce those of state-of-the-art ASR systems, although in a much focused situation. We investigate a case study involving the most common errors encountered in the automatic transcription of French language.
Generating Holistic 3D Human Motion from Speech
Dec 08, 2022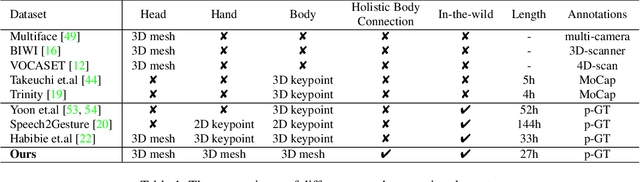

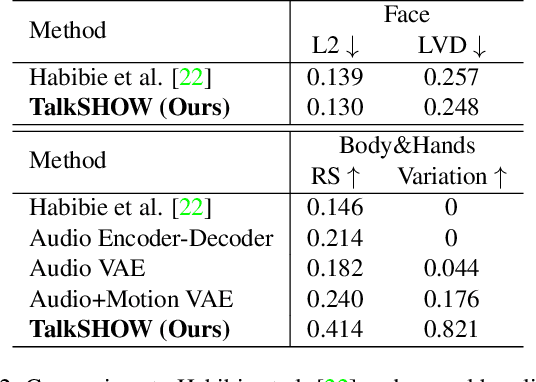
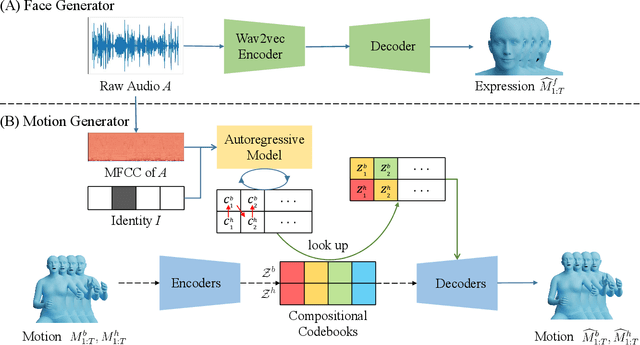
This work addresses the problem of generating 3D holistic body motions from human speech. Given a speech recording, we synthesize sequences of 3D body poses, hand gestures, and facial expressions that are realistic and diverse. To achieve this, we first build a high-quality dataset of 3D holistic body meshes with synchronous speech. We then define a novel speech-to-motion generation framework in which the face, body, and hands are modeled separately. The separated modeling stems from the fact that face articulation strongly correlates with human speech, while body poses and hand gestures are less correlated. Specifically, we employ an autoencoder for face motions, and a compositional vector-quantized variational autoencoder (VQ-VAE) for the body and hand motions. The compositional VQ-VAE is key to generating diverse results. Additionally, we propose a cross-conditional autoregressive model that generates body poses and hand gestures, leading to coherent and realistic motions. Extensive experiments and user studies demonstrate that our proposed approach achieves state-of-the-art performance both qualitatively and quantitatively. Our novel dataset and code will be released for research purposes at https://talkshow.is.tue.mpg.de.
Ada-TTA: Towards Adaptive High-Quality Text-to-Talking Avatar Synthesis
Jun 06, 2023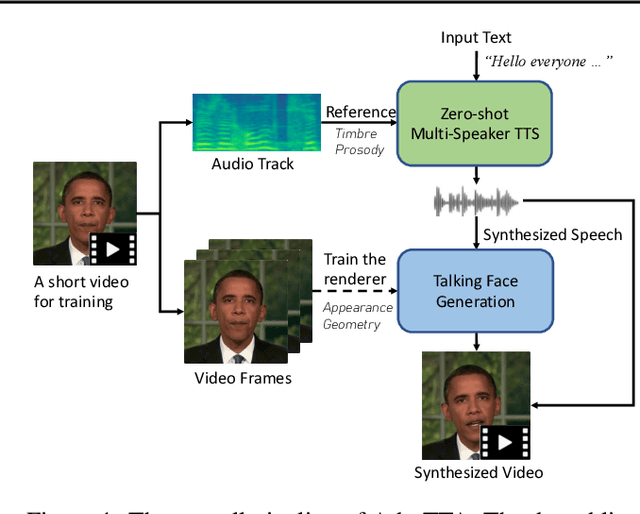

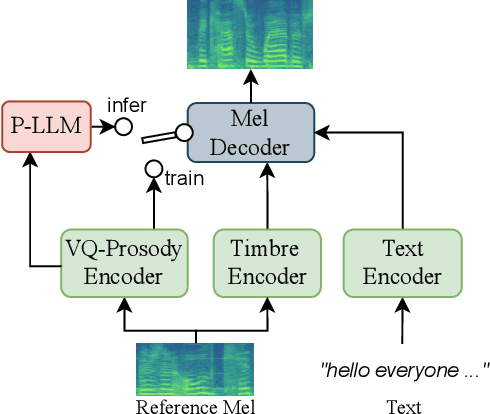

We are interested in a novel task, namely low-resource text-to-talking avatar. Given only a few-minute-long talking person video with the audio track as the training data and arbitrary texts as the driving input, we aim to synthesize high-quality talking portrait videos corresponding to the input text. This task has broad application prospects in the digital human industry but has not been technically achieved yet due to two challenges: (1) It is challenging to mimic the timbre from out-of-domain audio for a traditional multi-speaker Text-to-Speech system. (2) It is hard to render high-fidelity and lip-synchronized talking avatars with limited training data. In this paper, we introduce Adaptive Text-to-Talking Avatar (Ada-TTA), which (1) designs a generic zero-shot multi-speaker TTS model that well disentangles the text content, timbre, and prosody; and (2) embraces recent advances in neural rendering to achieve realistic audio-driven talking face video generation. With these designs, our method overcomes the aforementioned two challenges and achieves to generate identity-preserving speech and realistic talking person video. Experiments demonstrate that our method could synthesize realistic, identity-preserving, and audio-visual synchronized talking avatar videos.
Multi-resolution location-based training for multi-channel continuous speech separation
Jan 16, 2023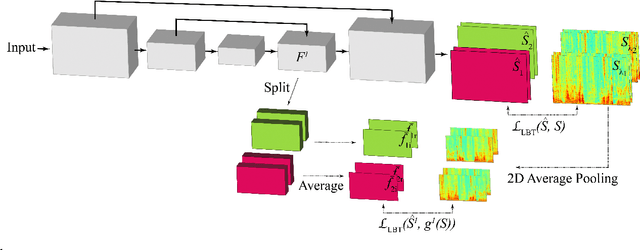
The performance of automatic speech recognition (ASR) systems severely degrades when multi-talker speech overlap occurs. In meeting environments, speech separation is typically performed to improve the robustness of ASR systems. Recently, location-based training (LBT) was proposed as a new training criterion for multi-channel talker-independent speaker separation. Assuming fixed array geometry, LBT outperforms widely-used permutation-invariant training in fully overlapped utterances and matched reverberant conditions. This paper extends LBT to conversational multi-channel speaker separation. We introduce multi-resolution LBT to estimate the complex spectrograms from low to high time and frequency resolutions. With multi-resolution LBT, convolutional kernels are assigned consistently based on speaker locations in physical space. Evaluation results show that multi-resolution LBT consistently outperforms other competitive methods on the recorded LibriCSS corpus.
The Double Helix inside the NLP Transformer
Jun 23, 2023
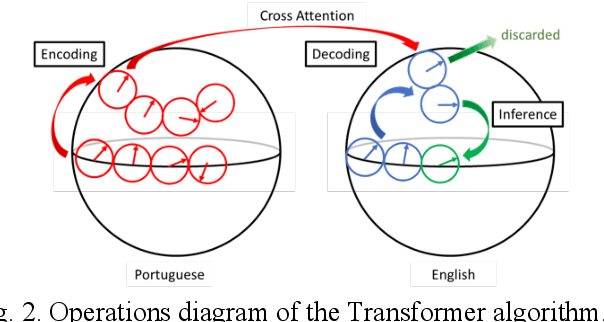
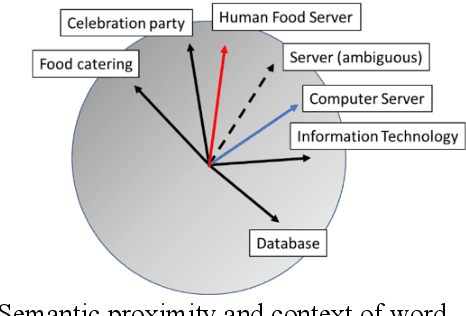
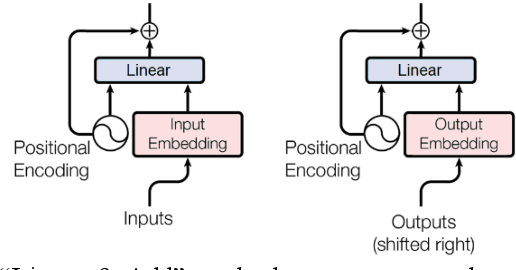
We introduce a framework for analyzing various types of information in an NLP Transformer. In this approach, we distinguish four layers of information: positional, syntactic, semantic, and contextual. We also argue that the common practice of adding positional information to semantic embedding is sub-optimal and propose instead a Linear-and-Add approach. Our analysis reveals an autogenetic separation of positional information through the deep layers. We show that the distilled positional components of the embedding vectors follow the path of a helix, both on the encoder side and on the decoder side. We additionally show that on the encoder side, the conceptual dimensions generate Part-of-Speech (PoS) clusters. On the decoder side, we show that a di-gram approach helps to reveal the PoS clusters of the next token. Our approach paves a way to elucidate the processing of information through the deep layers of an NLP Transformer.
Implementing contextual biasing in GPU decoder for online ASR
Jun 23, 2023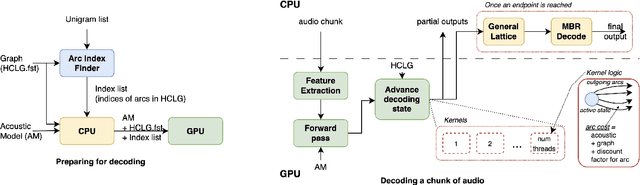
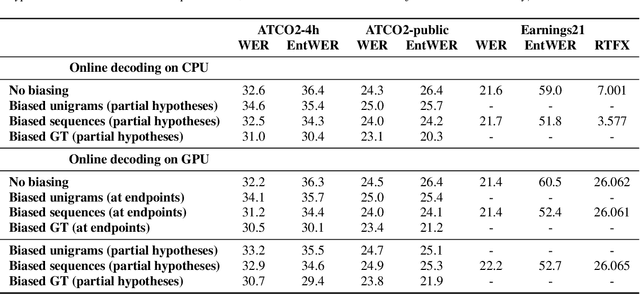
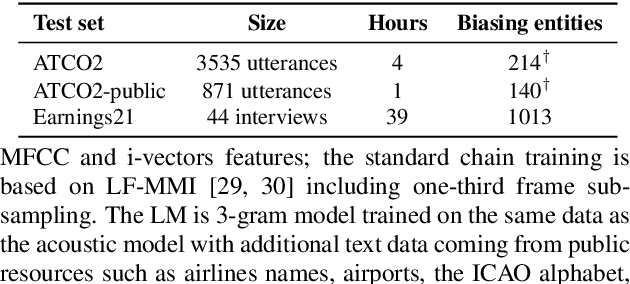
GPU decoding significantly accelerates the output of ASR predictions. While GPUs are already being used for online ASR decoding, post-processing and rescoring on GPUs have not been properly investigated yet. Rescoring with available contextual information can considerably improve ASR predictions. Previous studies have proven the viability of lattice rescoring in decoding and biasing language model (LM) weights in offline and online CPU scenarios. In real-time GPU decoding, partial recognition hypotheses are produced without lattice generation, which makes the implementation of biasing more complex. The paper proposes and describes an approach to integrate contextual biasing in real-time GPU decoding while exploiting the standard Kaldi GPU decoder. Besides the biasing of partial ASR predictions, our approach also permits dynamic context switching allowing a flexible rescoring per each speech segment directly on GPU. The code is publicly released and tested with open-sourced test sets.