 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Generating Holistic 3D Human Motion from Speech
Dec 08, 2022
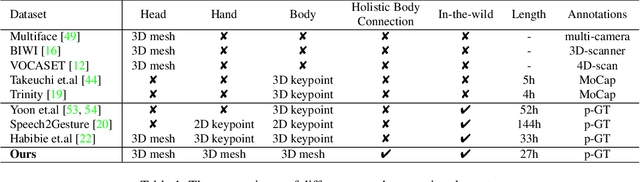

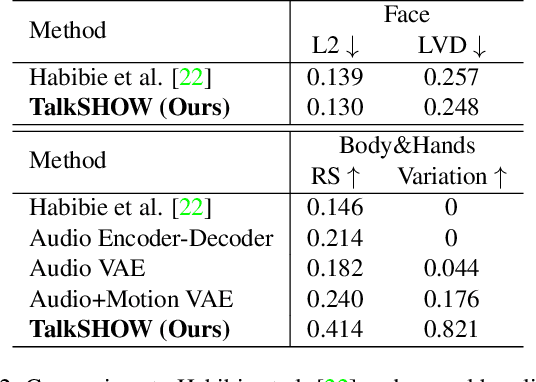
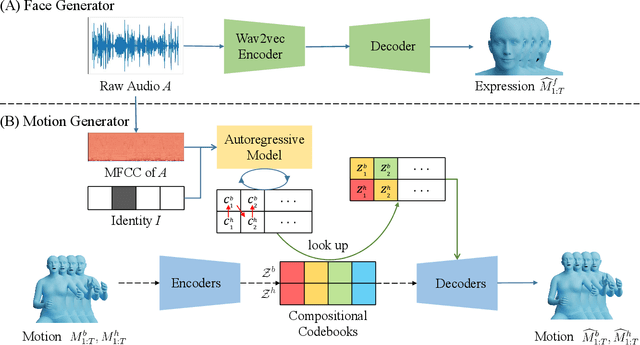
This work addresses the problem of generating 3D holistic body motions from human speech. Given a speech recording, we synthesize sequences of 3D body poses, hand gestures, and facial expressions that are realistic and diverse. To achieve this, we first build a high-quality dataset of 3D holistic body meshes with synchronous speech. We then define a novel speech-to-motion generation framework in which the face, body, and hands are modeled separately. The separated modeling stems from the fact that face articulation strongly correlates with human speech, while body poses and hand gestures are less correlated. Specifically, we employ an autoencoder for face motions, and a compositional vector-quantized variational autoencoder (VQ-VAE) for the body and hand motions. The compositional VQ-VAE is key to generating diverse results. Additionally, we propose a cross-conditional autoregressive model that generates body poses and hand gestures, leading to coherent and realistic motions. Extensive experiments and user studies demonstrate that our proposed approach achieves state-of-the-art performance both qualitatively and quantitatively. Our novel dataset and code will be released for research purposes at https://talkshow.is.tue.mpg.de.
Losses Can Be Blessings: Routing Self-Supervised Speech Representations Towards Efficient Multilingual and Multitask Speech Processing
Nov 02, 2022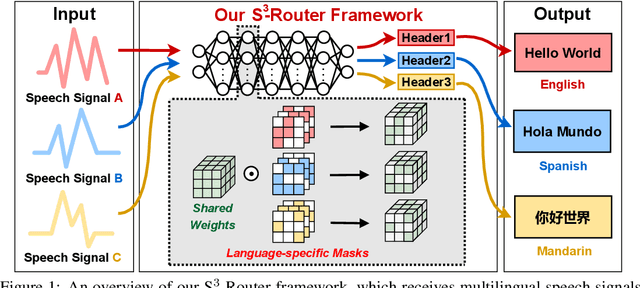
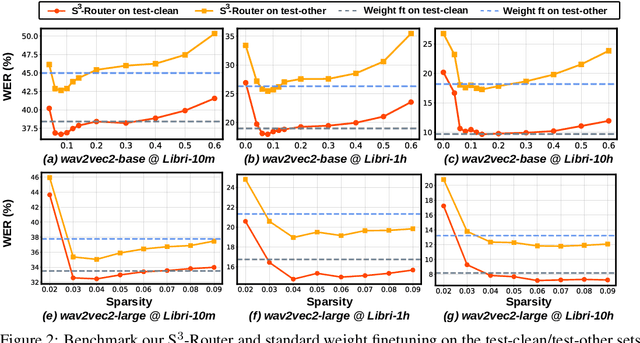
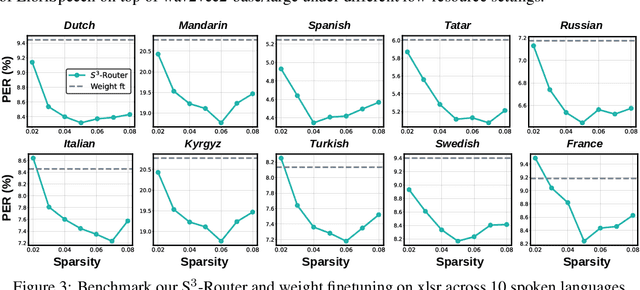
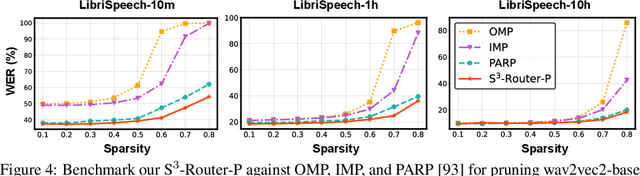
Self-supervised learning (SSL) for rich speech representations has achieved empirical success in low-resource Automatic Speech Recognition (ASR) and other speech processing tasks, which can mitigate the necessity of a large amount of transcribed speech and thus has driven a growing demand for on-device ASR and other speech processing. However, advanced speech SSL models have become increasingly large, which contradicts the limited on-device resources. This gap could be more severe in multilingual/multitask scenarios requiring simultaneously recognizing multiple languages or executing multiple speech processing tasks. Additionally, strongly overparameterized speech SSL models tend to suffer from overfitting when being finetuned on low-resource speech corpus. This work aims to enhance the practical usage of speech SSL models towards a win-win in both enhanced efficiency and alleviated overfitting via our proposed S$^3$-Router framework, which for the first time discovers that simply discarding no more than 10\% of model weights via only finetuning model connections of speech SSL models can achieve better accuracy over standard weight finetuning on downstream speech processing tasks. More importantly, S$^3$-Router can serve as an all-in-one technique to enable (1) a new finetuning scheme, (2) an efficient multilingual/multitask solution, (3) a state-of-the-art ASR pruning technique, and (4) a new tool to quantitatively analyze the learned speech representation. We believe S$^3$-Router has provided a new perspective for practical deployment of speech SSL models. Our codes are available at: https://github.com/GATECH-EIC/S3-Router.
Evaluation of Automated Speech Recognition Systems for Conversational Speech: A Linguistic Perspective
Nov 05, 2022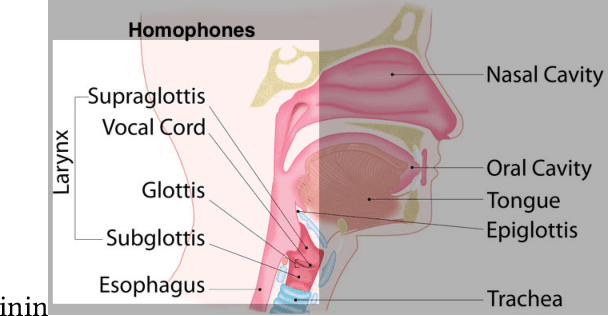

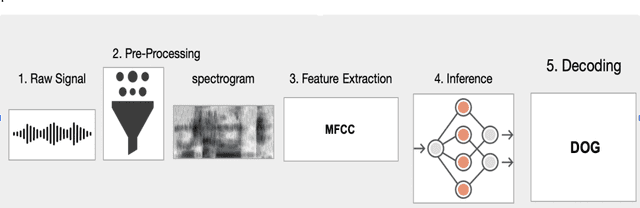

Automatic speech recognition (ASR) meets more informal and free-form input data as voice user interfaces and conversational agents such as the voice assistants such as Alexa, Google Home, etc., gain popularity. Conversational speech is both the most difficult and environmentally relevant sort of data for speech recognition. In this paper, we take a linguistic perspective, and take the French language as a case study toward disambiguation of the French homophones. Our contribution aims to provide more insight into human speech transcription accuracy in conditions to reproduce those of state-of-the-art ASR systems, although in a much focused situation. We investigate a case study involving the most common errors encountered in the automatic transcription of French language.
End-to-End Speech Recognition: A Survey
Mar 03, 2023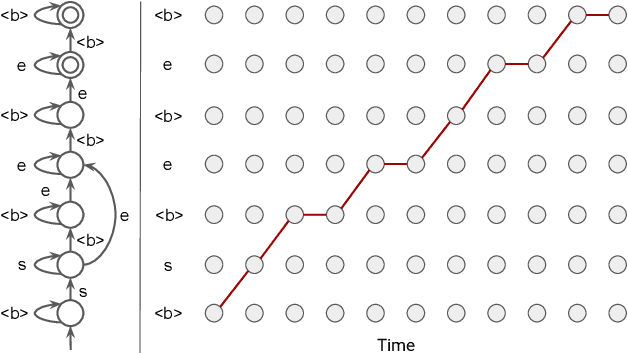
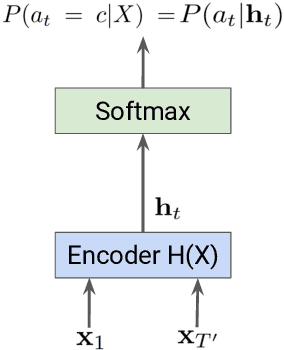
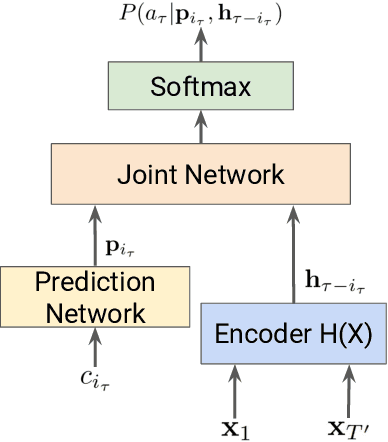

In the last decade of automatic speech recognition (ASR) research, the introduction of deep learning brought considerable reductions in word error rate of more than 50% relative, compared to modeling without deep learning. In the wake of this transition, a number of all-neural ASR architectures were introduced. These so-called end-to-end (E2E) models provide highly integrated, completely neural ASR models, which rely strongly on general machine learning knowledge, learn more consistently from data, while depending less on ASR domain-specific experience. The success and enthusiastic adoption of deep learning accompanied by more generic model architectures lead to E2E models now becoming the prominent ASR approach. The goal of this survey is to provide a taxonomy of E2E ASR models and corresponding improvements, and to discuss their properties and their relation to the classical hidden Markov model (HMM) based ASR architecture. All relevant aspects of E2E ASR are covered in this work: modeling, training, decoding, and external language model integration, accompanied by discussions of performance and deployment opportunities, as well as an outlook into potential future developments.
Adversarial Speaker Disentanglement Using Unannotated External Data for Self-supervised Representation Based Voice Conversion
May 16, 2023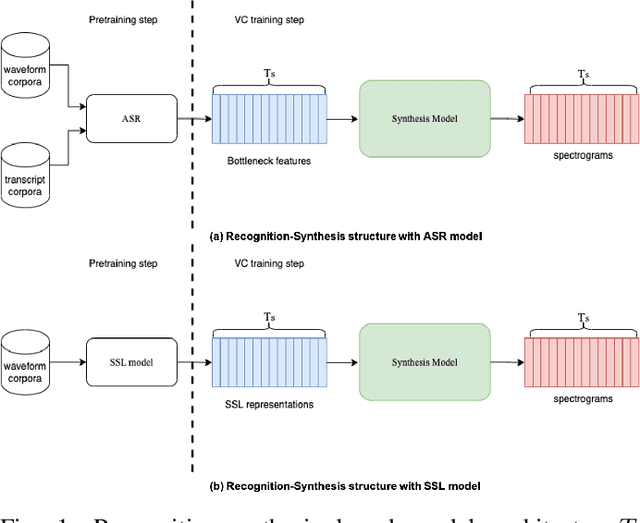
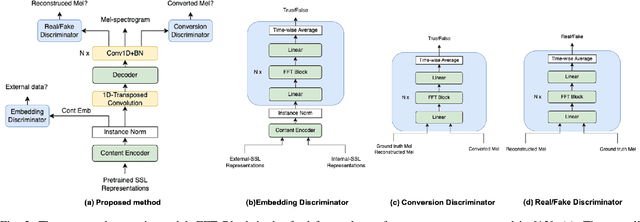
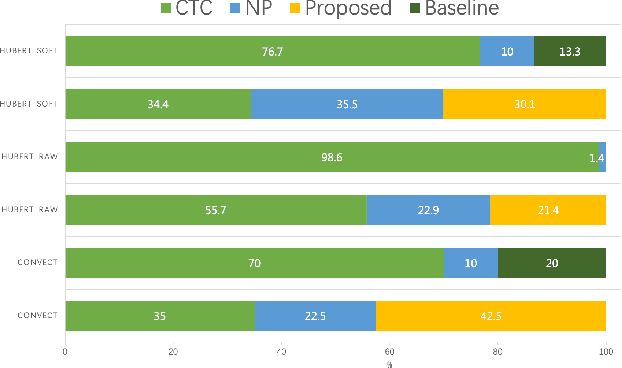
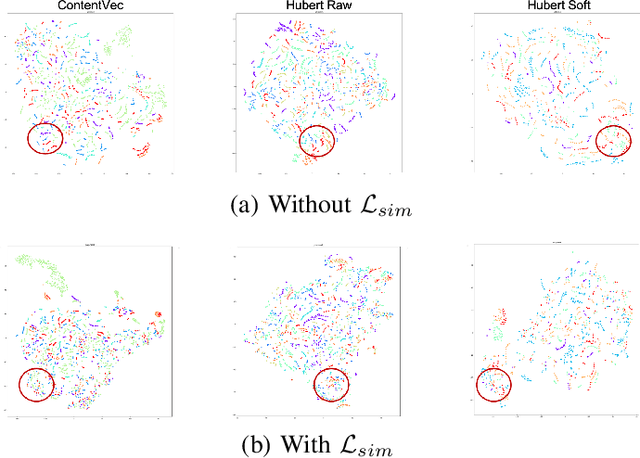
Nowadays, recognition-synthesis-based methods have been quite popular with voice conversion (VC). By introducing linguistics features with good disentangling characters extracted from an automatic speech recognition (ASR) model, the VC performance achieved considerable breakthroughs. Recently, self-supervised learning (SSL) methods trained with a large-scale unannotated speech corpus have been applied to downstream tasks focusing on the content information, which is suitable for VC tasks. However, a huge amount of speaker information in SSL representations degrades timbre similarity and the quality of converted speech significantly. To address this problem, we proposed a high-similarity any-to-one voice conversion method with the input of SSL representations. We incorporated adversarial training mechanisms in the synthesis module using external unannotated corpora. Two auxiliary discriminators were trained to distinguish whether a sequence of mel-spectrograms has been converted by the acoustic model and whether a sequence of content embeddings contains speaker information from external corpora. Experimental results show that our proposed method achieves comparable similarity and higher naturalness than the supervised method, which needs a huge amount of annotated corpora for training and is applicable to improve similarity for VC methods with other SSL representations as input.
Leveraging supplementary text data to kick-start automatic speech recognition system development with limited transcriptions
Feb 09, 2023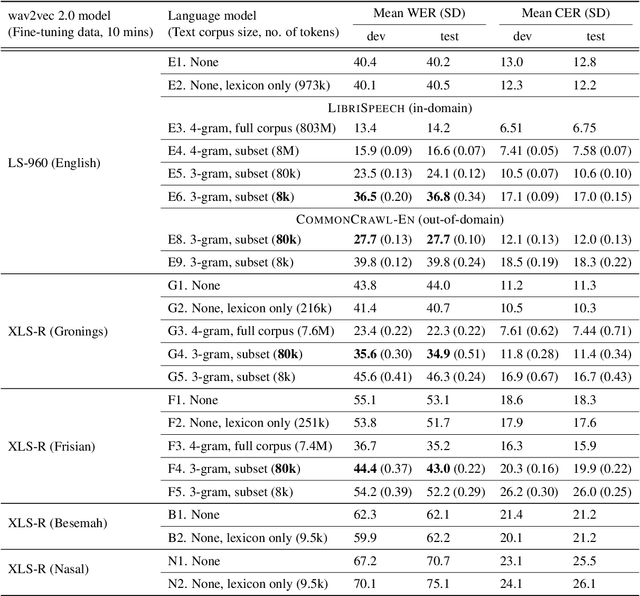
Recent research using pre-trained transformer models suggests that just 10 minutes of transcribed speech may be enough to fine-tune such a model for automatic speech recognition (ASR) -- at least if we can also leverage vast amounts of text data (803 million tokens). But is that much text data necessary? We study the use of different amounts of text data, both for creating a lexicon that constrains ASR decoding to possible words (e.g. *dogz vs. dogs), and for training larger language models that bias the system toward probable word sequences (e.g. too dogs vs. two dogs). We perform experiments using 10 minutes of transcribed speech from English (for replicating prior work) and two additional pairs of languages differing in the availability of supplemental text data: Gronings and Frisian (~7.5M token corpora available), and Besemah and Nasal (only small lexica available). For all languages, we found that using only a lexicon did not appreciably improve ASR performance. For Gronings and Frisian, we found that lexica and language models derived from 'novel-length' 80k token subcorpora reduced the word error rate (WER) to 39% on average. Our findings suggest that where a text corpus in the upper tens of thousands of tokens or more is available, fine-tuning a transformer model with just tens of minutes of transcribed speech holds some promise towards obtaining human-correctable transcriptions near the 30% WER rule-of-thumb.
Lexical Retrieval Hypothesis in Multimodal Context
May 28, 2023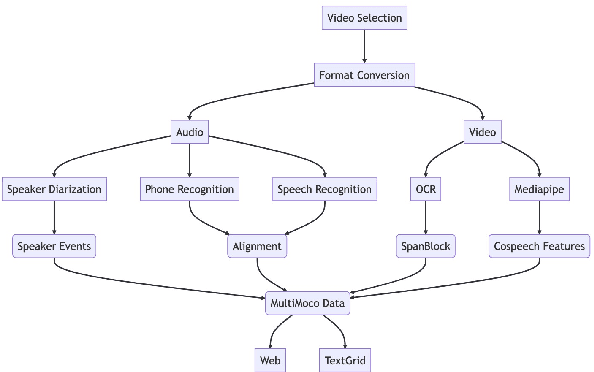
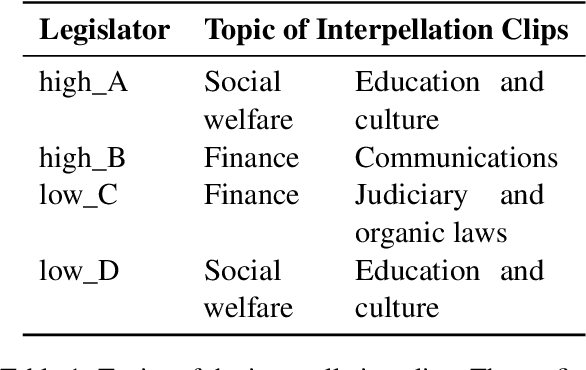
Multimodal corpora have become an essential language resource for language science and grounded natural language processing (NLP) systems due to the growing need to understand and interpret human communication across various channels. In this paper, we first present our efforts in building the first Multimodal Corpus for Languages in Taiwan (MultiMoco). Based on the corpus, we conduct a case study investigating the Lexical Retrieval Hypothesis (LRH), specifically examining whether the hand gestures co-occurring with speech constants facilitate lexical retrieval or serve other discourse functions. With detailed annotations on eight parliamentary interpellations in Taiwan Mandarin, we explore the co-occurrence between speech constants and non-verbal features (i.e., head movement, face movement, hand gesture, and function of hand gesture). Our findings suggest that while hand gestures do serve as facilitators for lexical retrieval in some cases, they also serve the purpose of information emphasis. This study highlights the potential of the MultiMoco Corpus to provide an important resource for in-depth analysis and further research in multimodal communication studies.
AV-data2vec: Self-supervised Learning of Audio-Visual Speech Representations with Contextualized Target Representations
Feb 10, 2023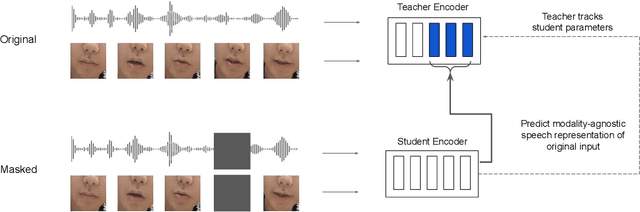
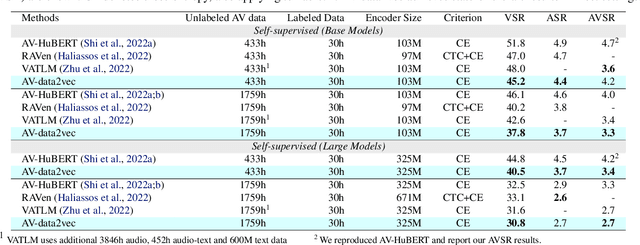
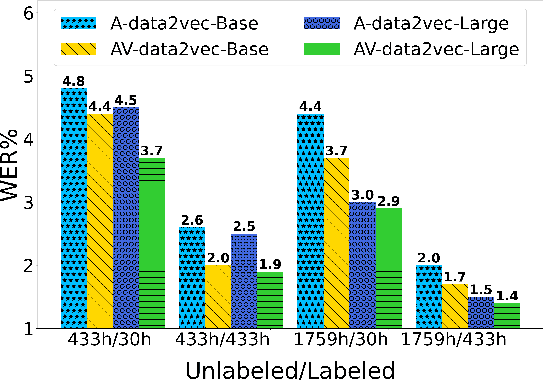
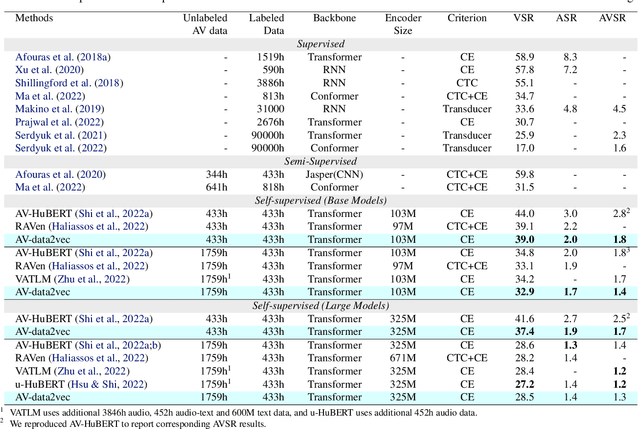
Self-supervision has shown great potential for audio-visual speech recognition by vastly reducing the amount of labeled data required to build good systems. However, existing methods are either not entirely end-to-end or do not train joint representations of both modalities. In this paper, we introduce AV-data2vec which addresses these challenges and builds audio-visual representations based on predicting contextualized representations which has been successful in the uni-modal case. The model uses a shared transformer encoder for both audio and video and can combine both modalities to improve speech recognition. Results on LRS3 show that AV-data2vec consistently outperforms existing methods under most settings.
Timestamped Embedding-Matching Acoustic-to-Word CTC ASR
Jun 20, 2023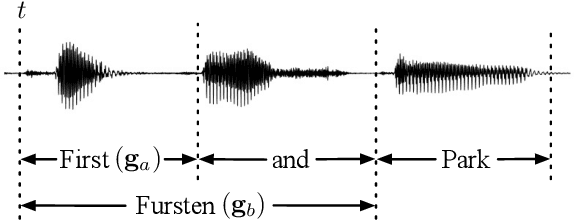
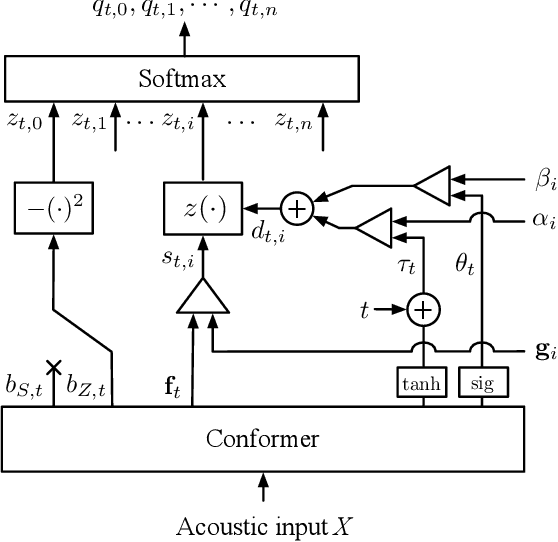
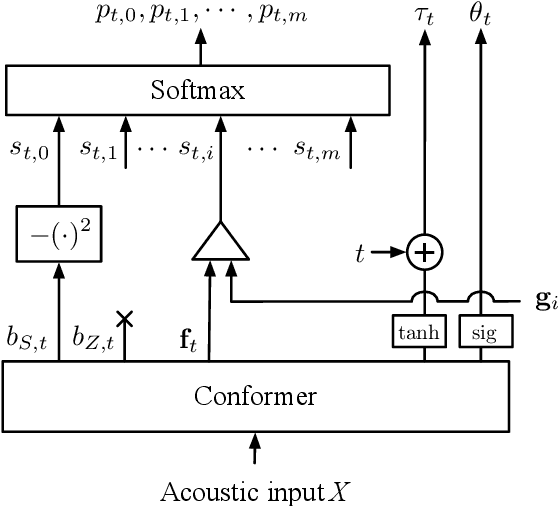
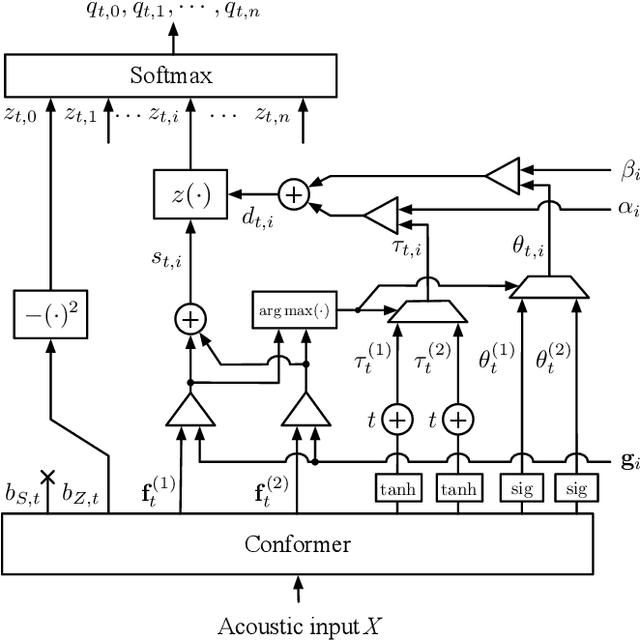
In this work, we describe a novel method of training an embedding-matching word-level connectionist temporal classification (CTC) automatic speech recognizer (ASR) such that it directly produces word start times and durations, required by many real-world applications, in addition to the transcription. The word timestamps enable the ASR to output word segmentations and word confusion networks without relying on a secondary model or forced alignment process when testing. Our proposed system has similar word segmentation accuracy as a hybrid DNN-HMM (Deep Neural Network-Hidden Markov Model) system, with less than 3ms difference in mean absolute error in word start times on TIMIT data. At the same time, we observed less than 5% relative increase in the word error rate compared to the non-timestamped system when using the same audio training data and nearly identical model size. We also contribute more rigorous analysis of multiple-hypothesis embedding-matching ASR in general.
Temporal Convolution Network Based Onset Detection and Query by Humming System Design
May 09, 2023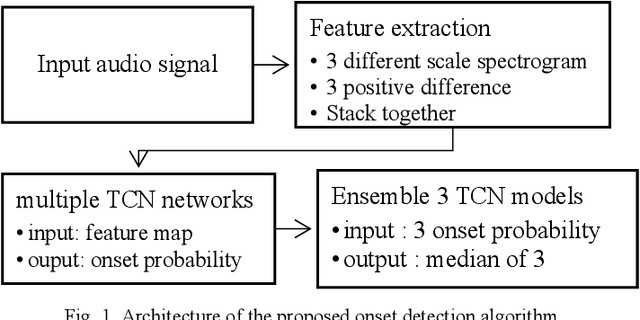
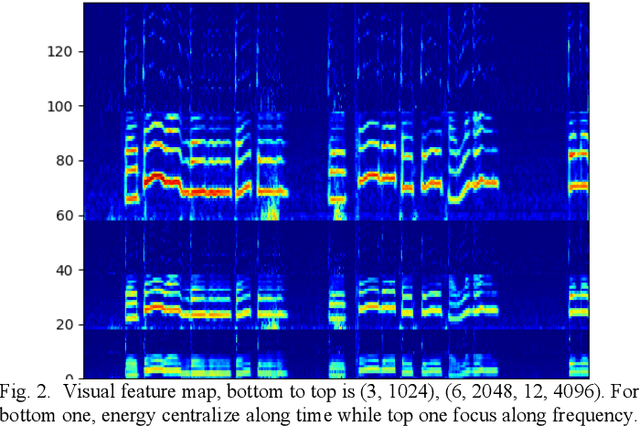
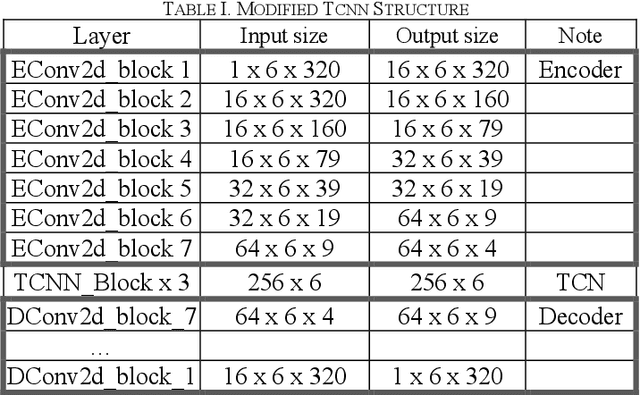
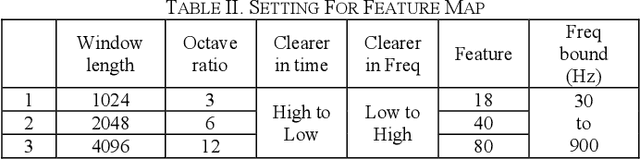
Onsets are a key factor to split audio into several notes. In this paper, we ensemble multiple temporal convolution network (TCN) based model and utilize a restricted frequency range spectrogram to achieve more robust onset detection. Different from the present onset detection of QBH system which is only available in a clean scenario, our proposal of onset detection and speech enhancement can prevent noise from affecting onset detection function (ODF). Compared to the CNN model which exploits spatial features of the spectrogram, the TCN model exploits both spatial and temporal features of the spectrogram. As the usage of QBH in noisy scenarios, we apply the TCN-based speech enhancement as a preprocessor of QBH. With the combinations of TCN-based speech enhancement and onset detection, simulations show that the proposal can enable the QBH system in both noisy and clean circumstances with short response time.