 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Mu$^{2}$SLAM: Multitask, Multilingual Speech and Language Models
Dec 19, 2022
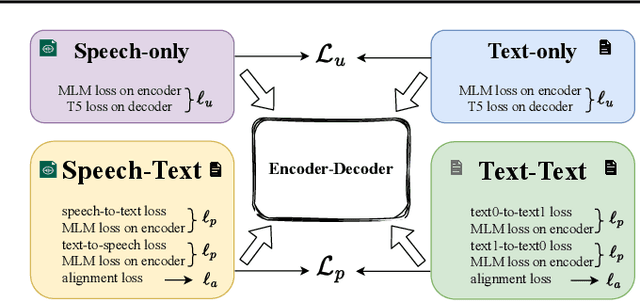
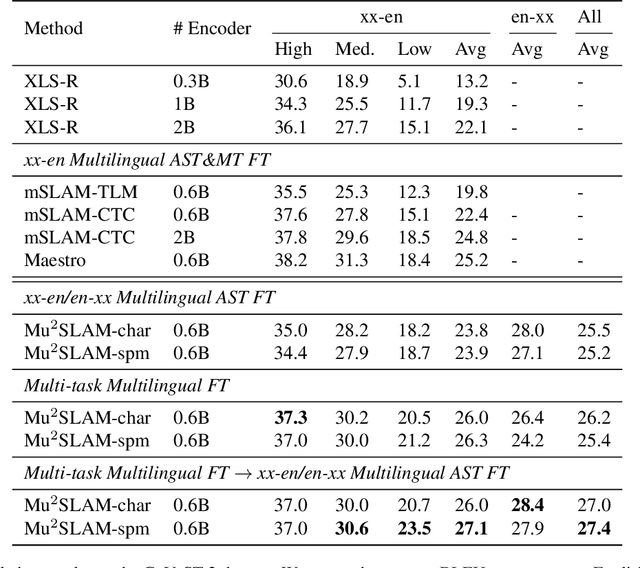
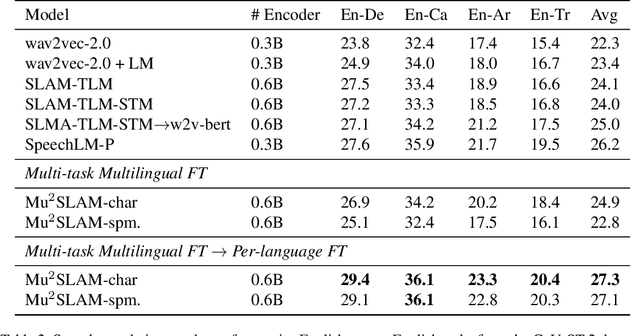
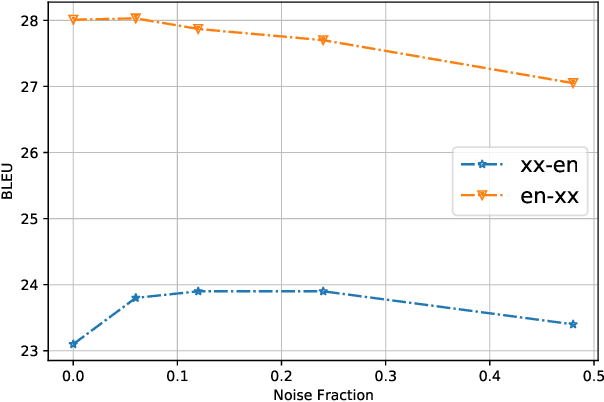
We present Mu$^{2}$SLAM, a multilingual sequence-to-sequence model pre-trained jointly on unlabeled speech, unlabeled text and supervised data spanning Automatic Speech Recognition (ASR), Automatic Speech Translation (AST) and Machine Translation (MT), in over 100 languages. By leveraging a quantized representation of speech as a target, Mu$^{2}$SLAM trains the speech-text models with a sequence-to-sequence masked denoising objective similar to T5 on the decoder and a masked language modeling (MLM) objective on the encoder, for both unlabeled speech and text, while utilizing the supervised tasks to improve cross-lingual and cross-modal representation alignment within the model. On CoVoST AST, Mu$^{2}$SLAM establishes a new state-of-the-art for models trained on public datasets, improving on xx-en translation over the previous best by 1.9 BLEU points and on en-xx translation by 1.1 BLEU points. On Voxpopuli ASR, our model matches the performance of an mSLAM model fine-tuned with an RNN-T decoder, despite using a relatively weaker sequence-to-sequence architecture. On text understanding tasks, our model improves by more than 6\% over mSLAM on XNLI, getting closer to the performance of mT5 models of comparable capacity on XNLI and TydiQA, paving the way towards a single model for all speech and text understanding tasks.
Adapting an Unadaptable ASR System
Jun 01, 2023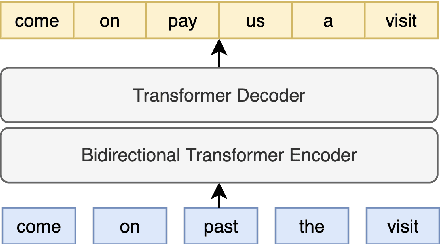
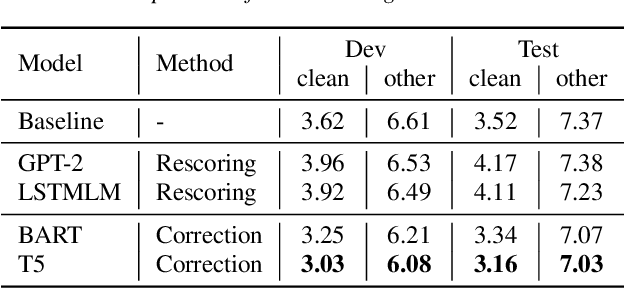
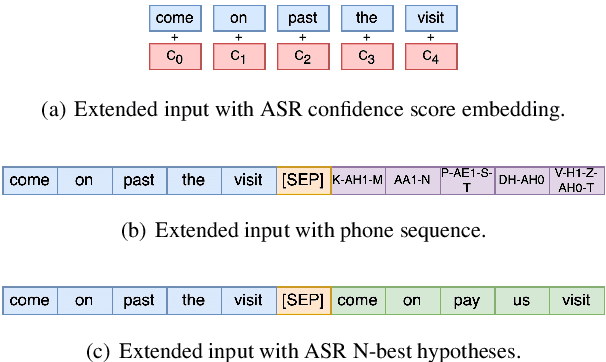
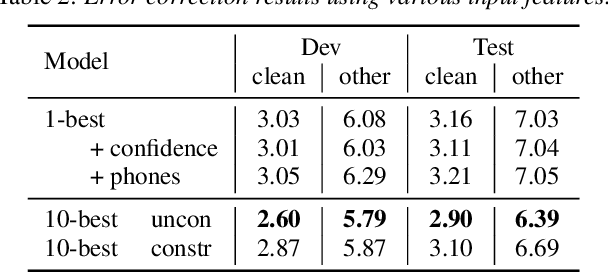
As speech recognition model sizes and training data requirements grow, it is increasingly common for systems to only be available via APIs from online service providers rather than having direct access to models themselves. In this scenario it is challenging to adapt systems to a specific target domain. To address this problem we consider the recently released OpenAI Whisper ASR as an example of a large-scale ASR system to assess adaptation methods. An error correction based approach is adopted, as this does not require access to the model, but can be trained from either 1-best or N-best outputs that are normally available via the ASR API. LibriSpeech is used as the primary target domain for adaptation. The generalization ability of the system in two distinct dimensions are then evaluated. First, whether the form of correction model is portable to other speech recognition domains, and secondly whether it can be used for ASR models having a different architecture.
Time-domain Speech Enhancement Assisted by Multi-resolution Frequency Encoder and Decoder
Mar 26, 2023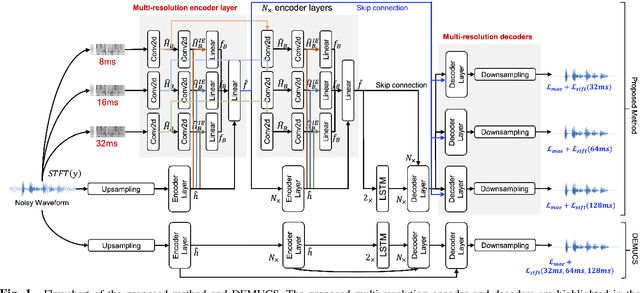

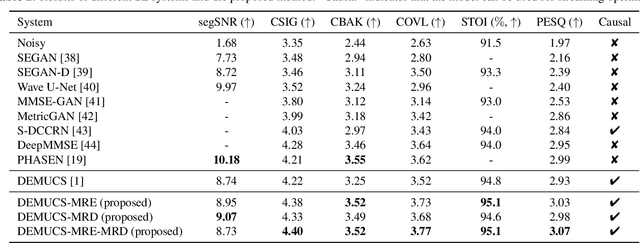

Time-domain speech enhancement (SE) has recently been intensively investigated. Among recent works, DEMUCS introduces multi-resolution STFT loss to enhance performance. However, some resolutions used for STFT contain non-stationary signals, and it is challenging to learn multi-resolution frequency losses simultaneously with only one output. For better use of multi-resolution frequency information, we supplement multiple spectrograms in different frame lengths into the time-domain encoders. They extract stationary frequency information in both narrowband and wideband. We also adopt multiple decoder outputs, each of which computes its corresponding resolution frequency loss. Experimental results show that (1) it is more effective to fuse stationary frequency features than non-stationary features in the encoder, and (2) the multiple outputs consistent with the frequency loss improve performance. Experiments on the Voice-Bank dataset show that the proposed method obtained a 0.14 PESQ improvement.
Retraining-free Customized ASR for Enharmonic Words Based on a Named-Entity-Aware Model and Phoneme Similarity Estimation
May 29, 2023End-to-end automatic speech recognition (E2E-ASR) has the potential to improve performance, but a specific issue that needs to be addressed is the difficulty it has in handling enharmonic words: named entities (NEs) with the same pronunciation and part of speech that are spelled differently. This often occurs with Japanese personal names that have the same pronunciation but different Kanji characters. Since such NE words tend to be important keywords, ASR easily loses user trust if it misrecognizes them. To solve these problems, this paper proposes a novel retraining-free customized method for E2E-ASRs based on a named-entity-aware E2E-ASR model and phoneme similarity estimation. Experimental results show that the proposed method improves the target NE character error rate by 35.7% on average relative to the conventional E2E-ASR model when selecting personal names as a target NE.
APNet: An All-Frame-Level Neural Vocoder Incorporating Direct Prediction of Amplitude and Phase Spectra
May 13, 2023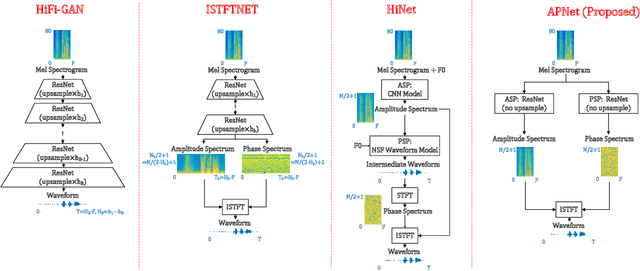
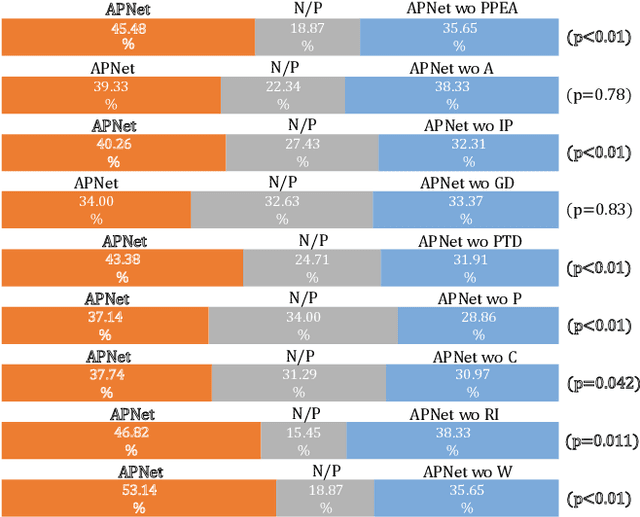
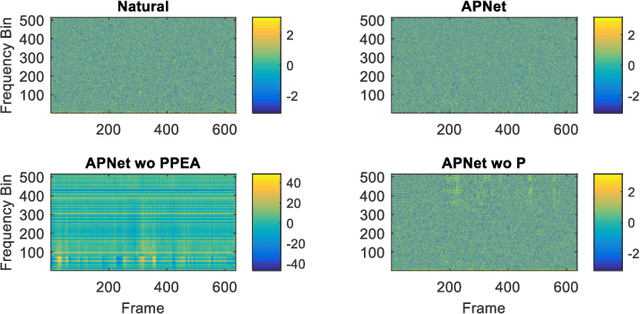
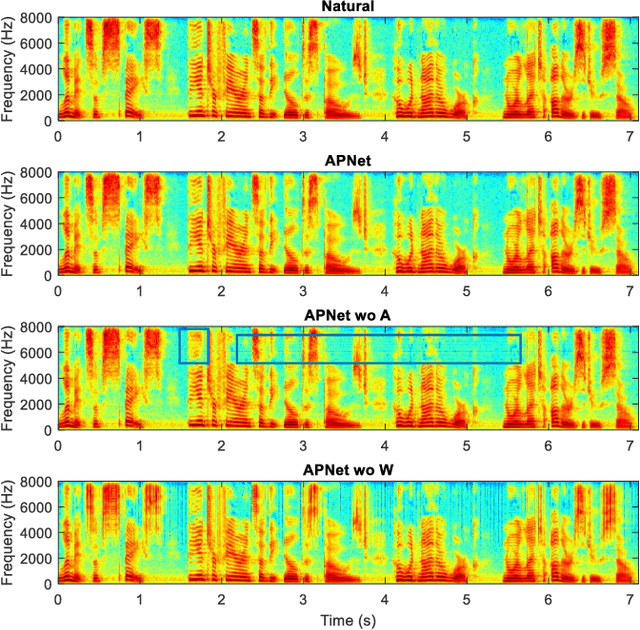
This paper presents a novel neural vocoder named APNet which reconstructs speech waveforms from acoustic features by predicting amplitude and phase spectra directly. The APNet vocoder is composed of an amplitude spectrum predictor (ASP) and a phase spectrum predictor (PSP). The ASP is a residual convolution network which predicts frame-level log amplitude spectra from acoustic features. The PSP also adopts a residual convolution network using acoustic features as input, then passes the output of this network through two parallel linear convolution layers respectively, and finally integrates into a phase calculation formula to estimate frame-level phase spectra. Finally, the outputs of ASP and PSP are combined to reconstruct speech waveforms by inverse short-time Fourier transform (ISTFT). All operations of the ASP and PSP are performed at the frame level. We train the ASP and PSP jointly and define multilevel loss functions based on amplitude mean square error, phase anti-wrapping error, short-time spectral inconsistency error and time domain reconstruction error. Experimental results show that our proposed APNet vocoder achieves an approximately 8x faster inference speed than HiFi-GAN v1 on a CPU due to the all-frame-level operations, while its synthesized speech quality is comparable to HiFi-GAN v1. The synthesized speech quality of the APNet vocoder is also better than that of several equally efficient models. Ablation experiments also confirm that the proposed parallel phase estimation architecture is essential to phase modeling and the proposed loss functions are helpful for improving the synthesized speech quality.
PROCTER: PROnunciation-aware ConTextual adaptER for personalized speech recognition in neural transducers
Mar 30, 2023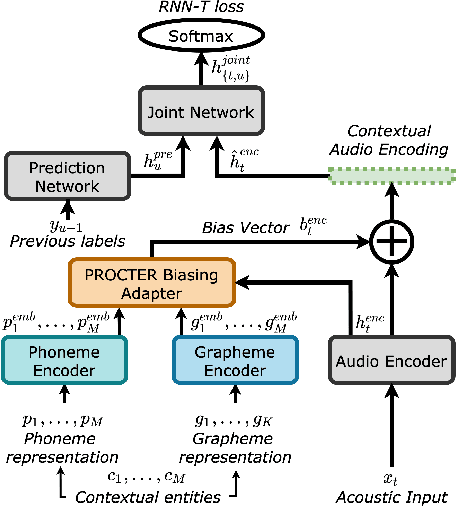
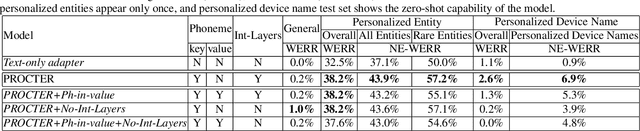

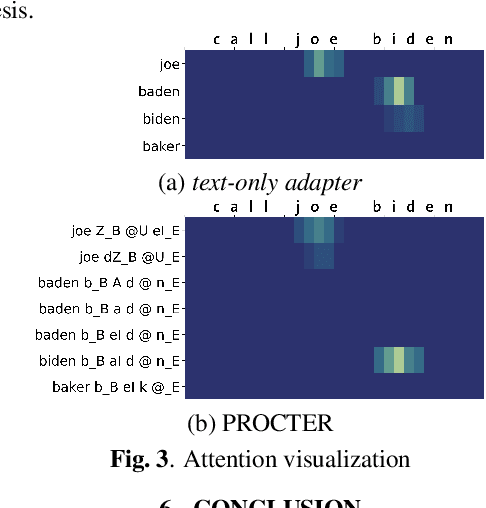
End-to-End (E2E) automatic speech recognition (ASR) systems used in voice assistants often have difficulties recognizing infrequent words personalized to the user, such as names and places. Rare words often have non-trivial pronunciations, and in such cases, human knowledge in the form of a pronunciation lexicon can be useful. We propose a PROnunCiation-aware conTextual adaptER (PROCTER) that dynamically injects lexicon knowledge into an RNN-T model by adding a phonemic embedding along with a textual embedding. The experimental results show that the proposed PROCTER architecture outperforms the baseline RNN-T model by improving the word error rate (WER) by 44% and 57% when measured on personalized entities and personalized rare entities, respectively, while increasing the model size (number of trainable parameters) by only 1%. Furthermore, when evaluated in a zero-shot setting to recognize personalized device names, we observe 7% WER improvement with PROCTER, as compared to only 1% WER improvement with text-only contextual attention
Reducing the gap between streaming and non-streaming Transducer-based ASR by adaptive two-stage knowledge distillation
Jun 27, 2023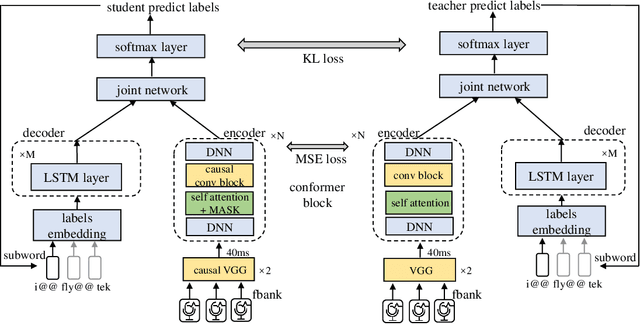
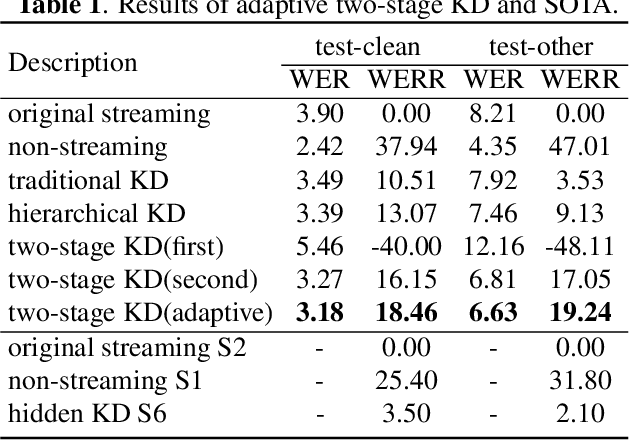
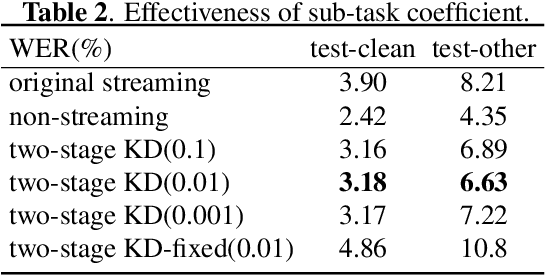
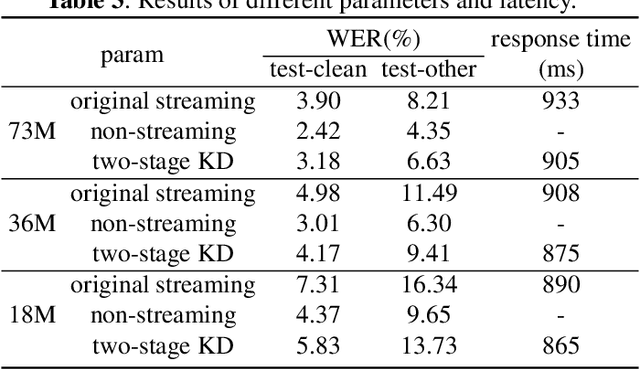
Transducer is one of the mainstream frameworks for streaming speech recognition. There is a performance gap between the streaming and non-streaming transducer models due to limited context. To reduce this gap, an effective way is to ensure that their hidden and output distributions are consistent, which can be achieved by hierarchical knowledge distillation. However, it is difficult to ensure the distribution consistency simultaneously because the learning of the output distribution depends on the hidden one. In this paper, we propose an adaptive two-stage knowledge distillation method consisting of hidden layer learning and output layer learning. In the former stage, we learn hidden representation with full context by applying mean square error loss function. In the latter stage, we design a power transformation based adaptive smoothness method to learn stable output distribution. It achieved 19\% relative reduction in word error rate, and a faster response for the first token compared with the original streaming model in LibriSpeech corpus.
Using a Large Language Model to Control Speaking Style for Expressive TTS
May 17, 2023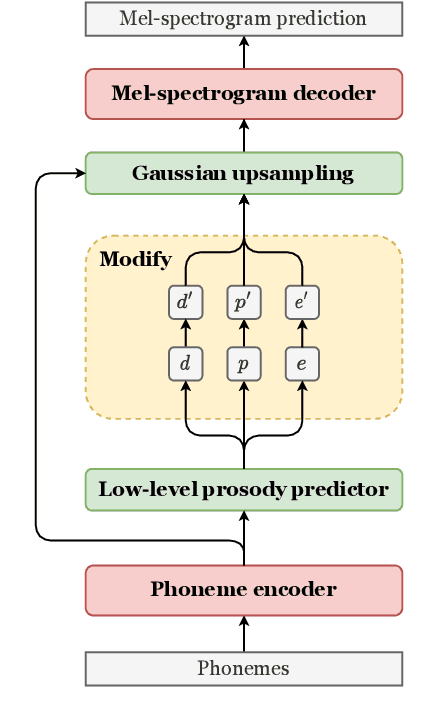
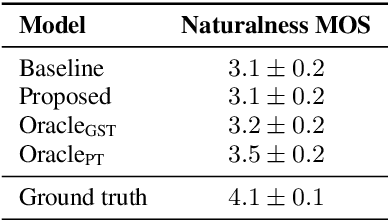
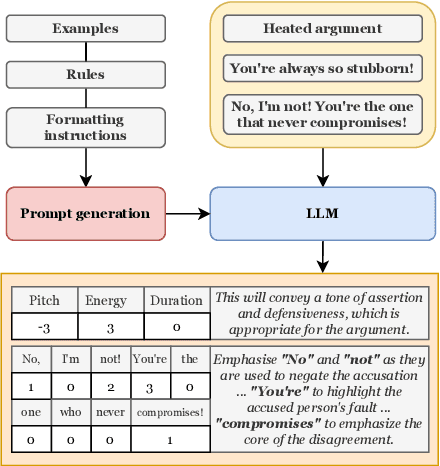
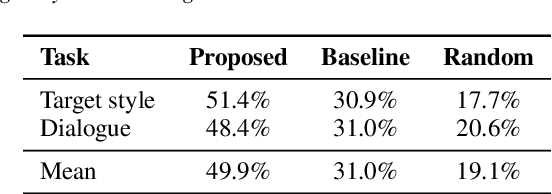
Appropriate prosody is critical for successful spoken communication. Contextual word embeddings are proven to be helpful in predicting prosody but do not allow for choosing between plausible prosodic renditions. Reference-based TTS models attempt to address this by conditioning speech generation on a reference speech sample. These models can generate expressive speech but this requires finding an appropriate reference. Sufficiently large generative language models have been used to solve various language-related tasks. We explore whether such models can be used to suggest appropriate prosody for expressive TTS. We train a TTS model on a non-expressive corpus and then prompt the language model to suggest changes to pitch, energy and duration. The prompt can be designed for any task and we prompt the model to make suggestions based on target speaking style and dialogue context. The proposed method is rated most appropriate in 49.9\% of cases compared to 31.0\% for a baseline model.
Prompt Tuning of Deep Neural Networks for Speaker-adaptive Visual Speech Recognition
Feb 16, 2023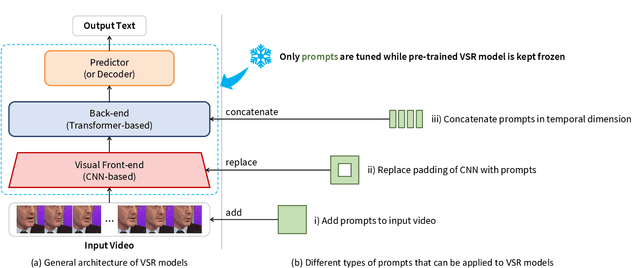
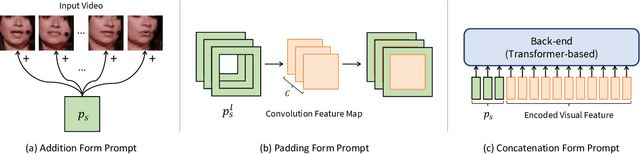
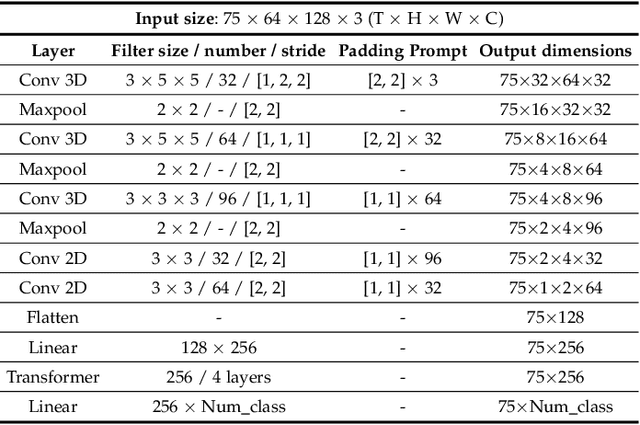
Visual Speech Recognition (VSR) aims to infer speech into text depending on lip movements alone. As it focuses on visual information to model the speech, its performance is inherently sensitive to personal lip appearances and movements, and this makes the VSR models show degraded performance when they are applied to unseen speakers. In this paper, to remedy the performance degradation of the VSR model on unseen speakers, we propose prompt tuning methods of Deep Neural Networks (DNNs) for speaker-adaptive VSR. Specifically, motivated by recent advances in Natural Language Processing (NLP), we finetune prompts on adaptation data of target speakers instead of modifying the pre-trained model parameters. Different from the previous prompt tuning methods mainly limited to Transformer variant architecture, we explore different types of prompts, the addition, the padding, and the concatenation form prompts that can be applied to the VSR model which is composed of CNN and Transformer in general. With the proposed prompt tuning, we show that the performance of the pre-trained VSR model on unseen speakers can be largely improved by using a small amount of adaptation data (e.g., less than 5 minutes), even if the pre-trained model is already developed with large speaker variations. Moreover, by analyzing the performance and parameters of different types of prompts, we investigate when the prompt tuning is preferred over the finetuning methods. The effectiveness of the proposed method is evaluated on both word- and sentence-level VSR databases, LRW-ID and GRID.
I3D: Transformer architectures with input-dependent dynamic depth for speech recognition
Mar 14, 2023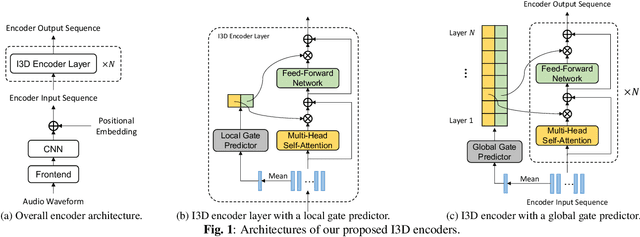
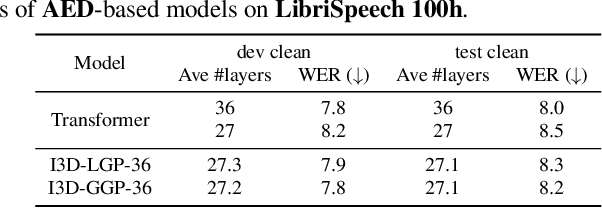
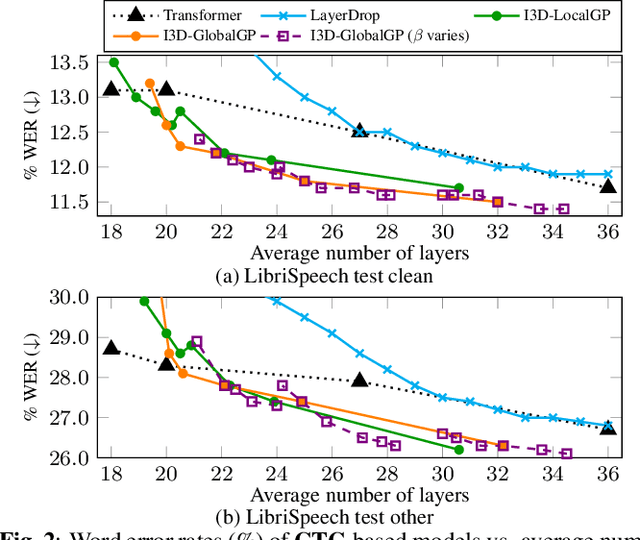
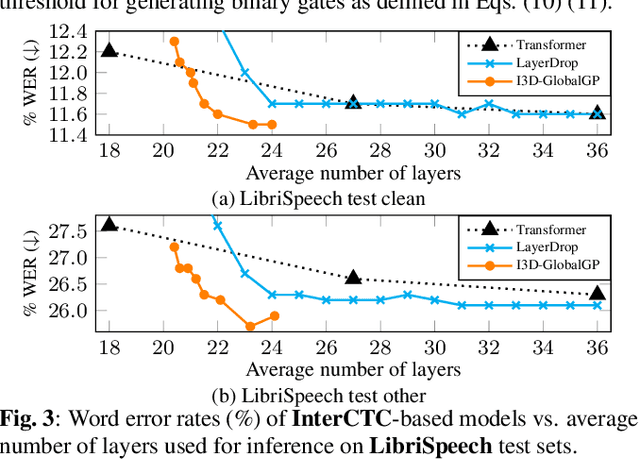
Transformer-based end-to-end speech recognition has achieved great success. However, the large footprint and computational overhead make it difficult to deploy these models in some real-world applications. Model compression techniques can reduce the model size and speed up inference, but the compressed model has a fixed architecture which might be suboptimal. We propose a novel Transformer encoder with Input-Dependent Dynamic Depth (I3D) to achieve strong performance-efficiency trade-offs. With a similar number of layers at inference time, I3D-based models outperform the vanilla Transformer and the static pruned model via iterative layer pruning. We also present interesting analysis on the gate probabilities and the input-dependency, which helps us better understand deep encoders.