 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Evaluation of Automated Speech Recognition Systems for Conversational Speech: A Linguistic Perspective
Nov 05, 2022
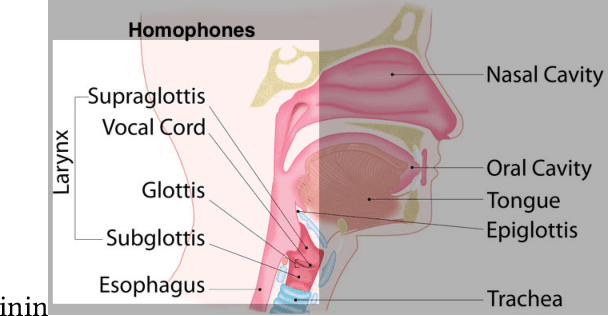

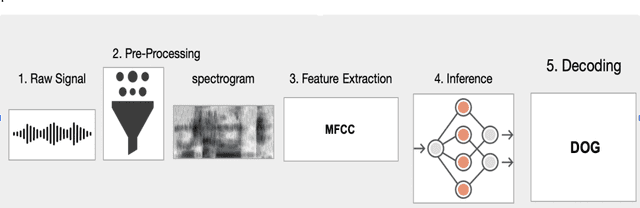

Automatic speech recognition (ASR) meets more informal and free-form input data as voice user interfaces and conversational agents such as the voice assistants such as Alexa, Google Home, etc., gain popularity. Conversational speech is both the most difficult and environmentally relevant sort of data for speech recognition. In this paper, we take a linguistic perspective, and take the French language as a case study toward disambiguation of the French homophones. Our contribution aims to provide more insight into human speech transcription accuracy in conditions to reproduce those of state-of-the-art ASR systems, although in a much focused situation. We investigate a case study involving the most common errors encountered in the automatic transcription of French language.
Exploring Non-Verbal Predicates in Semantic Role Labeling: Challenges and Opportunities
Jul 04, 2023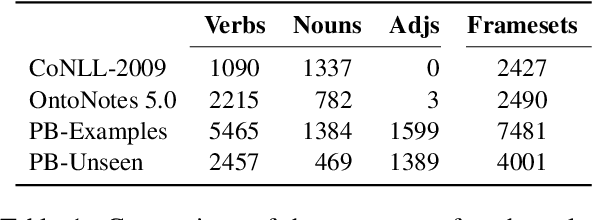
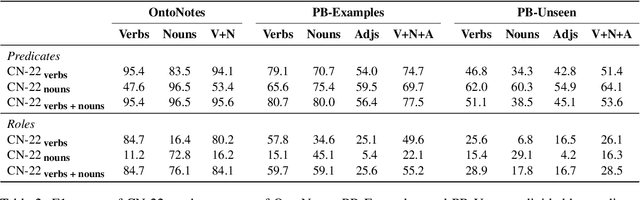
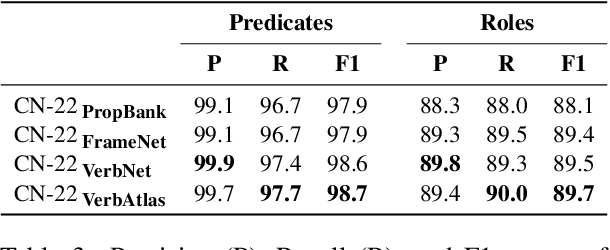
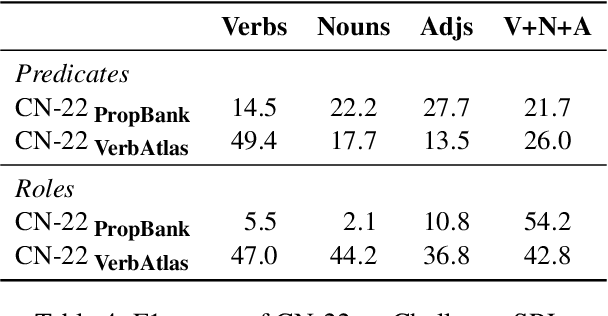
Although we have witnessed impressive progress in Semantic Role Labeling (SRL), most of the research in the area is carried out assuming that the majority of predicates are verbs. Conversely, predicates can also be expressed using other parts of speech, e.g., nouns and adjectives. However, non-verbal predicates appear in the benchmarks we commonly use to measure progress in SRL less frequently than in some real-world settings -- newspaper headlines, dialogues, and tweets, among others. In this paper, we put forward a new PropBank dataset which boasts wide coverage of multiple predicate types. Thanks to it, we demonstrate empirically that standard benchmarks do not provide an accurate picture of the current situation in SRL and that state-of-the-art systems are still incapable of transferring knowledge across different predicate types. Having observed these issues, we also present a novel, manually-annotated challenge set designed to give equal importance to verbal, nominal, and adjectival predicate-argument structures. We use such dataset to investigate whether we can leverage different linguistic resources to promote knowledge transfer. In conclusion, we claim that SRL is far from "solved", and its integration with other semantic tasks might enable significant improvements in the future, especially for the long tail of non-verbal predicates, thereby facilitating further research on SRL for non-verbal predicates.
The Double Helix inside the NLP Transformer
Jun 23, 2023
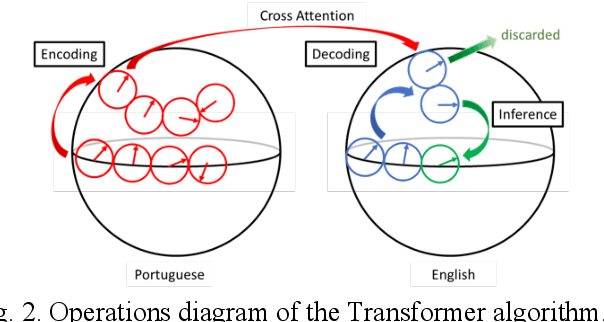
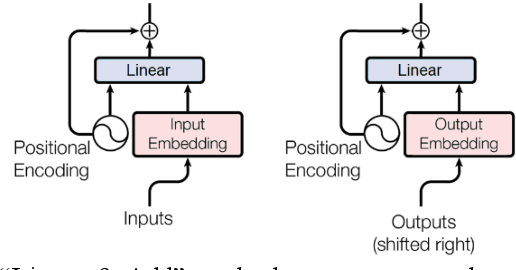
We introduce a framework for analyzing various types of information in an NLP Transformer. In this approach, we distinguish four layers of information: positional, syntactic, semantic, and contextual. We also argue that the common practice of adding positional information to semantic embedding is sub-optimal and propose instead a Linear-and-Add approach. Our analysis reveals an autogenetic separation of positional information through the deep layers. We show that the distilled positional components of the embedding vectors follow the path of a helix, both on the encoder side and on the decoder side. We additionally show that on the encoder side, the conceptual dimensions generate Part-of-Speech (PoS) clusters. On the decoder side, we show that a di-gram approach helps to reveal the PoS clusters of the next token. Our approach paves a way to elucidate the processing of information through the deep layers of an NLP Transformer.
Implementing contextual biasing in GPU decoder for online ASR
Jun 23, 2023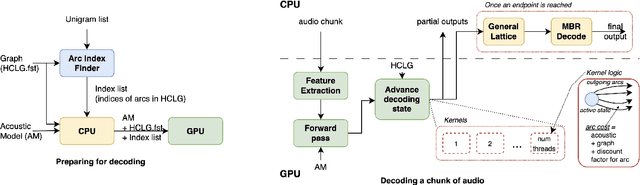
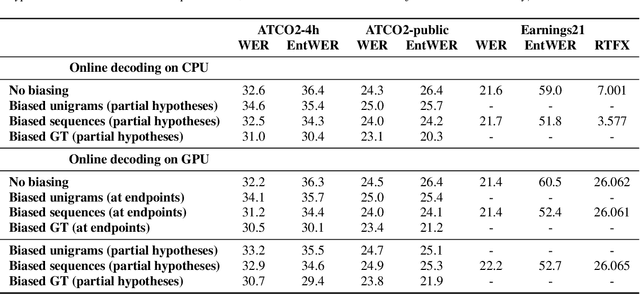
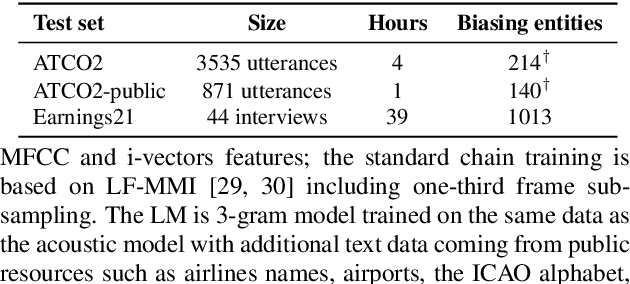
GPU decoding significantly accelerates the output of ASR predictions. While GPUs are already being used for online ASR decoding, post-processing and rescoring on GPUs have not been properly investigated yet. Rescoring with available contextual information can considerably improve ASR predictions. Previous studies have proven the viability of lattice rescoring in decoding and biasing language model (LM) weights in offline and online CPU scenarios. In real-time GPU decoding, partial recognition hypotheses are produced without lattice generation, which makes the implementation of biasing more complex. The paper proposes and describes an approach to integrate contextual biasing in real-time GPU decoding while exploiting the standard Kaldi GPU decoder. Besides the biasing of partial ASR predictions, our approach also permits dynamic context switching allowing a flexible rescoring per each speech segment directly on GPU. The code is publicly released and tested with open-sourced test sets.
ADAPTERMIX: Exploring the Efficacy of Mixture of Adapters for Low-Resource TTS Adaptation
May 29, 2023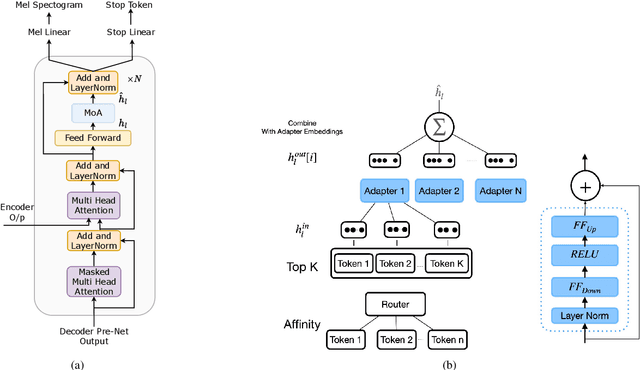

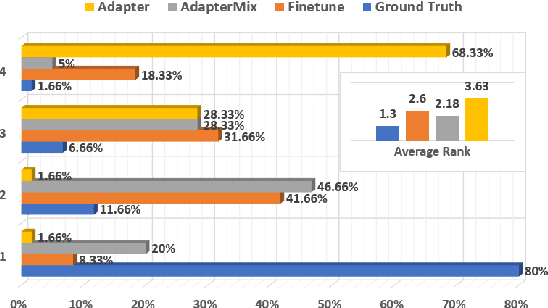
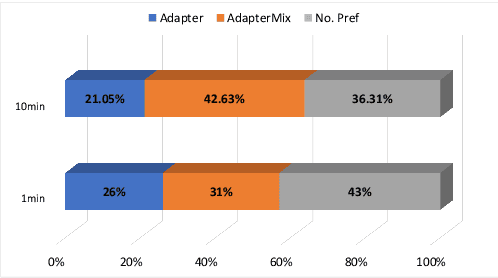
There are significant challenges for speaker adaptation in text-to-speech for languages that are not widely spoken or for speakers with accents or dialects that are not well-represented in the training data. To address this issue, we propose the use of the "mixture of adapters" method. This approach involves adding multiple adapters within a backbone-model layer to learn the unique characteristics of different speakers. Our approach outperforms the baseline, with a noticeable improvement of 5% observed in speaker preference tests when using only one minute of data for each new speaker. Moreover, following the adapter paradigm, we fine-tune only the adapter parameters (11% of the total model parameters). This is a significant achievement in parameter-efficient speaker adaptation, and one of the first models of its kind. Overall, our proposed approach offers a promising solution to the speech synthesis techniques, particularly for adapting to speakers from diverse backgrounds.
Generating Holistic 3D Human Motion from Speech
Dec 08, 2022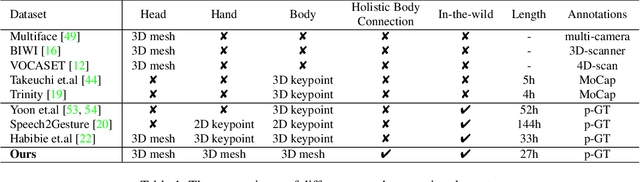

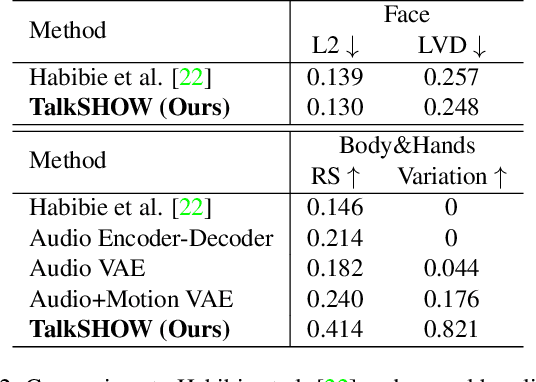
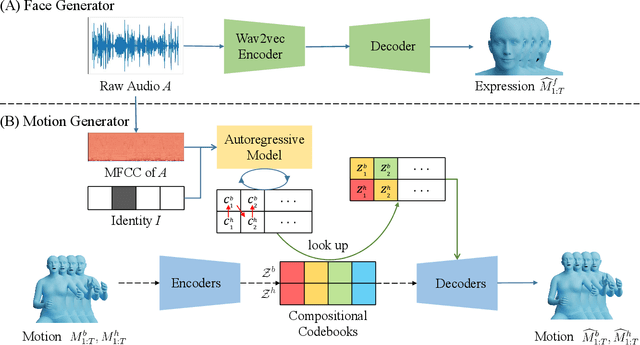
This work addresses the problem of generating 3D holistic body motions from human speech. Given a speech recording, we synthesize sequences of 3D body poses, hand gestures, and facial expressions that are realistic and diverse. To achieve this, we first build a high-quality dataset of 3D holistic body meshes with synchronous speech. We then define a novel speech-to-motion generation framework in which the face, body, and hands are modeled separately. The separated modeling stems from the fact that face articulation strongly correlates with human speech, while body poses and hand gestures are less correlated. Specifically, we employ an autoencoder for face motions, and a compositional vector-quantized variational autoencoder (VQ-VAE) for the body and hand motions. The compositional VQ-VAE is key to generating diverse results. Additionally, we propose a cross-conditional autoregressive model that generates body poses and hand gestures, leading to coherent and realistic motions. Extensive experiments and user studies demonstrate that our proposed approach achieves state-of-the-art performance both qualitatively and quantitatively. Our novel dataset and code will be released for research purposes at https://talkshow.is.tue.mpg.de.
Multi-resolution location-based training for multi-channel continuous speech separation
Jan 16, 2023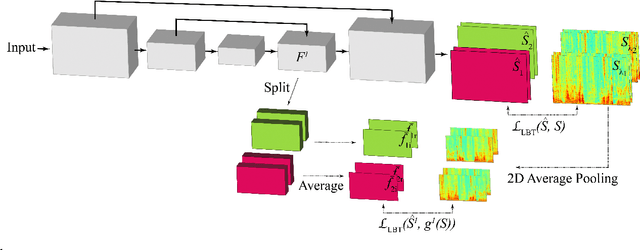
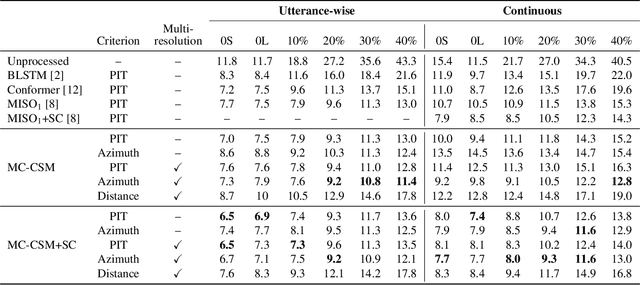
The performance of automatic speech recognition (ASR) systems severely degrades when multi-talker speech overlap occurs. In meeting environments, speech separation is typically performed to improve the robustness of ASR systems. Recently, location-based training (LBT) was proposed as a new training criterion for multi-channel talker-independent speaker separation. Assuming fixed array geometry, LBT outperforms widely-used permutation-invariant training in fully overlapped utterances and matched reverberant conditions. This paper extends LBT to conversational multi-channel speaker separation. We introduce multi-resolution LBT to estimate the complex spectrograms from low to high time and frequency resolutions. With multi-resolution LBT, convolutional kernels are assigned consistently based on speaker locations in physical space. Evaluation results show that multi-resolution LBT consistently outperforms other competitive methods on the recorded LibriCSS corpus.
Modality Influence in Multimodal Machine Learning
Jun 10, 2023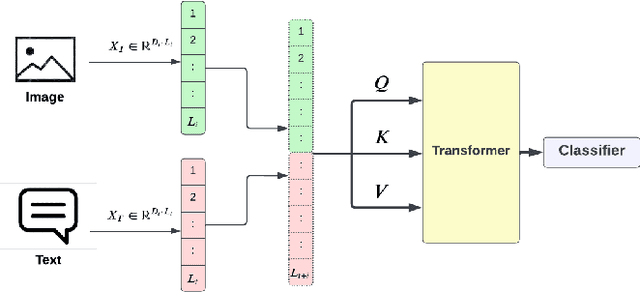
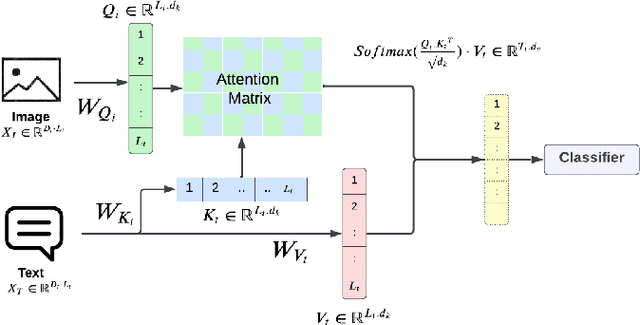
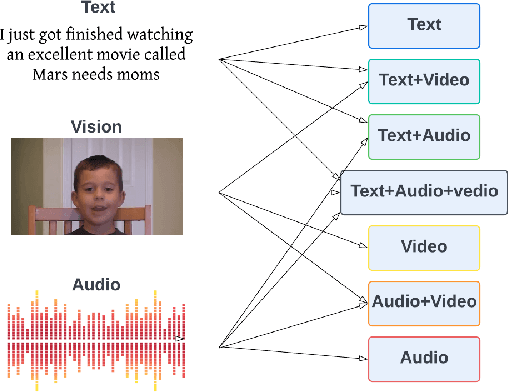
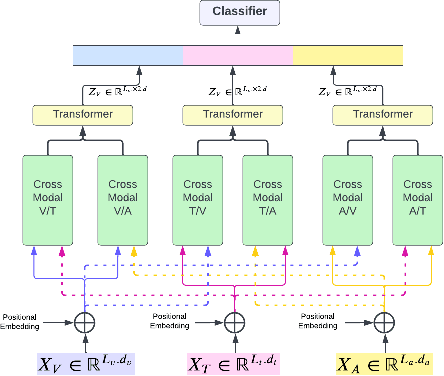
Multimodal Machine Learning has emerged as a prominent research direction across various applications such as Sentiment Analysis, Emotion Recognition, Machine Translation, Hate Speech Recognition, and Movie Genre Classification. This approach has shown promising results by utilizing modern deep learning architectures. Despite the achievements made, challenges remain in data representation, alignment techniques, reasoning, generation, and quantification within multimodal learning. Additionally, assumptions about the dominant role of textual modality in decision-making have been made. However, limited investigations have been conducted on the influence of different modalities in Multimodal Machine Learning systems. This paper aims to address this gap by studying the impact of each modality on multimodal learning tasks. The research focuses on verifying presumptions and gaining insights into the usage of different modalities. The main contribution of this work is the proposal of a methodology to determine the effect of each modality on several Multimodal Machine Learning models and datasets from various tasks. Specifically, the study examines Multimodal Sentiment Analysis, Multimodal Emotion Recognition, Multimodal Hate Speech Recognition, and Multimodal Disease Detection. The study objectives include training SOTA MultiModal Machine Learning models with masked modalities to evaluate their impact on performance. Furthermore, the research aims to identify the most influential modality or set of modalities for each task and draw conclusions for diverse multimodal classification tasks. By undertaking these investigations, this research contributes to a better understanding of the role of individual modalities in multi-modal learning and provides valuable insights for future advancements in this field.
Improving Prosody for Cross-Speaker Style Transfer by Semi-Supervised Style Extractor and Hierarchical Modeling in Speech Synthesis
Mar 14, 2023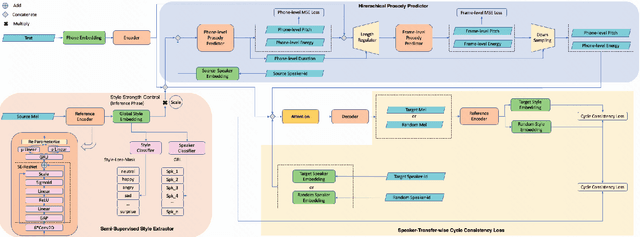
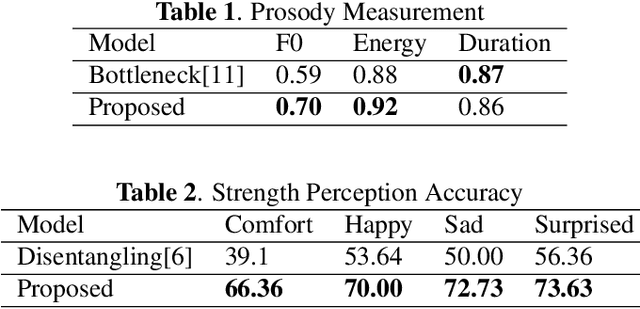
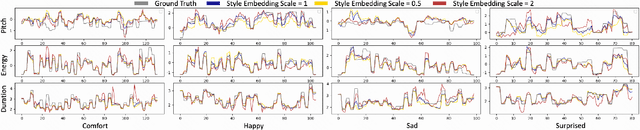
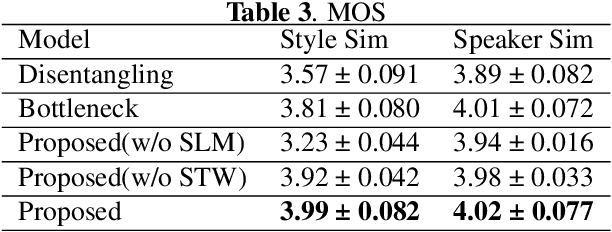
Cross-speaker style transfer in speech synthesis aims at transferring a style from source speaker to synthesized speech of a target speaker's timbre. In most previous methods, the synthesized fine-grained prosody features often represent the source speaker's average style, similar to the one-to-many problem(i.e., multiple prosody variations correspond to the same text). In response to this problem, a strength-controlled semi-supervised style extractor is proposed to disentangle the style from content and timbre, improving the representation and interpretability of the global style embedding, which can alleviate the one-to-many mapping and data imbalance problems in prosody prediction. A hierarchical prosody predictor is proposed to improve prosody modeling. We find that better style transfer can be achieved by using the source speaker's prosody features that are easily predicted. Additionally, a speaker-transfer-wise cycle consistency loss is proposed to assist the model in learning unseen style-timbre combinations during the training phase. Experimental results show that the method outperforms the baseline. We provide a website with audio samples.
Evaluation of Virtual Acoustic Environments with Different Acoustic Level of Detail
Jun 29, 2023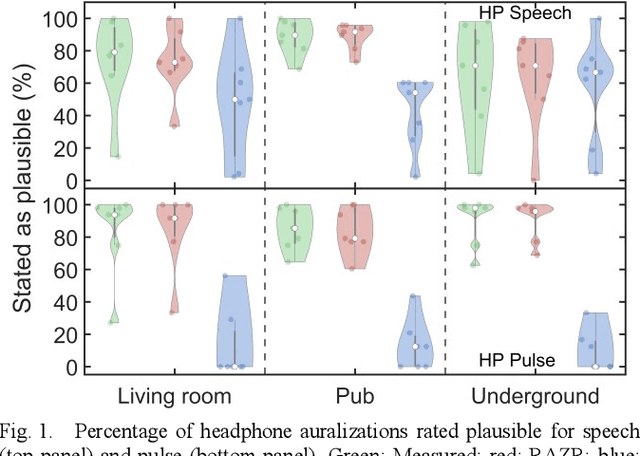
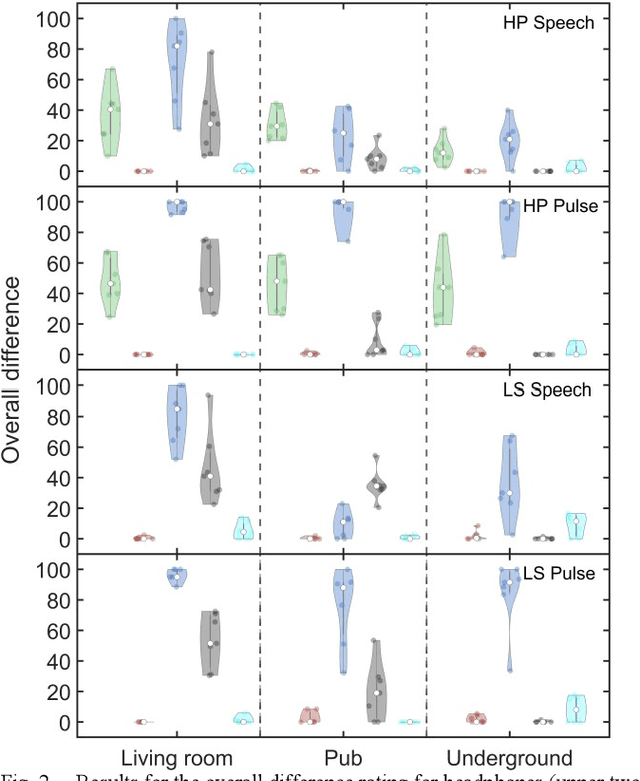
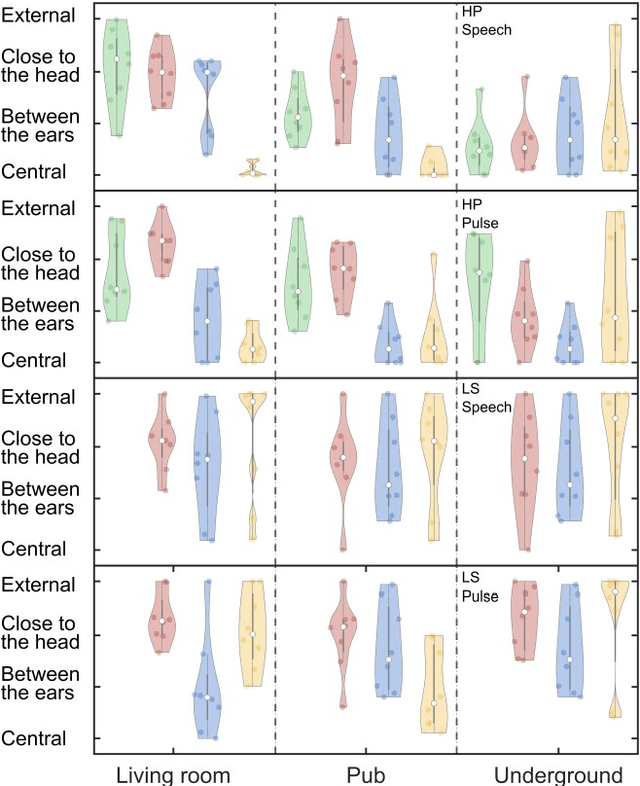
Virtual acoustic environments enable the creation and simulation of realistic and ecologically valid daily-life situations with applications in hearing research and audiology. Hereby, reverberant indoor environments play an important role. For real-time applications, simplifications in the room acoustics simulation are required, however, it remains unclear what acoustic level of detail (ALOD) is necessary to capture all perceptually relevant effects. This study investigates the effect of varying ALOD in the simulation of three different real environments, a living room with a coupled kitchen, a pub, and an underground station. ALOD was varied by generating different numbers of image sources for early reflections, or by excluding geometrical room details specific for each environment. The simulations were perceptually evaluated using headphones in comparison to binaural room impulse responses measured with a dummy head in the corresponding real environments. The study assessed the perceived overall difference for a pink pulse, and a speech token. Furthermore, plausibility and externalization were evaluated. The results show that a strong reduction in ALOD is possible while obtaining similar plausibility and externalization as with dummy head recordings. The number and accuracy of early reflections appear less relevant, provided diffuse late reverberation is appropriately accounted for.