 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Acoustic correlates of the syllabic rhythm of speech: Modulation spectrum or local features of the temporal envelope
Jan 14, 2023
The syllable is a perceptually salient unit in speech. Since both the syllable and its acoustic correlate, i.e., the speech envelope, have a preferred range of rhythmicity between 4 and 8 Hz, it is hypothesized that theta-band neural oscillations play a major role in extracting syllables based on the envelope. A literature survey, however, reveals inconsistent evidence about the relationship between speech envelope and syllables, and the current study revisits this question by analyzing large speech corpora. It is shown that the center frequency of speech envelope, characterized by the modulation spectrum, reliably correlates with the rate of syllables only when the analysis is pooled over minutes of speech recordings. In contrast, in the time domain, a component of the speech envelope is reliably phase-locked to syllable onsets. Based on a speaker-independent model, the timing of syllable onsets explains about 24% variance of the speech envelope. These results indicate that local features in the speech envelope, instead of the modulation spectrum, are a more reliable acoustic correlate of syllables.
Topological Data Analysis for Speech Processing
Dec 02, 2022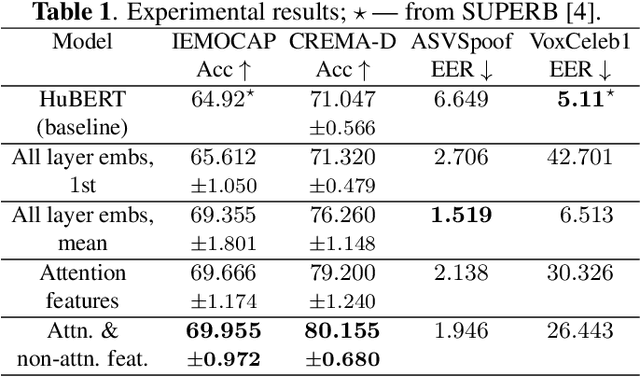
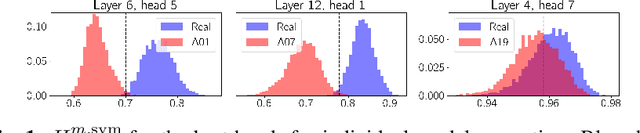
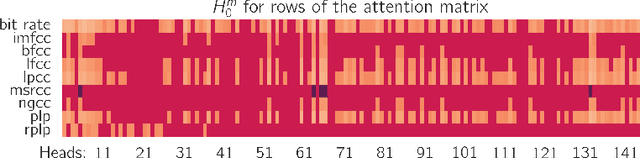
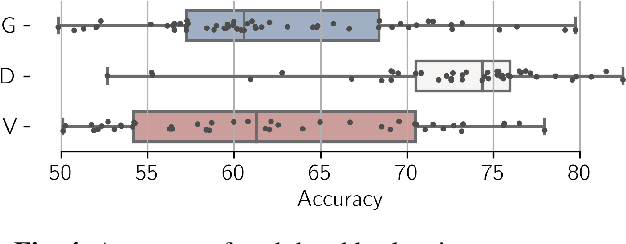
We apply topological data analysis (TDA) to speech classification problems and to the introspection of a pretrained speech model, HuBERT. To this end, we introduce a number of topological and algebraic features derived from Transformer attention maps and embeddings. We show that a simple linear classifier built on top of such features outperforms a fine-tuned classification head. In particular, we achieve an improvement of about $9\%$ accuracy and $5\%$ ERR on four common datasets; on CREMA-D, the proposed feature set reaches a new state of the art performance with accuracy $80.155$. We also show that topological features are able to reveal functional roles of speech Transformer heads; e.g., we find the heads capable to distinguish between pairs of sample sources (natural/synthetic) or voices without any downstream fine-tuning. Our results demonstrate that TDA is a promising new approach for speech analysis, especially for tasks that require structural prediction. Appendices, an introduction to TDA, and other additional materials are available here - https://topohubert.github.io/speech-topology-webpages/
Ada-TTA: Towards Adaptive High-Quality Text-to-Talking Avatar Synthesis
Jun 06, 2023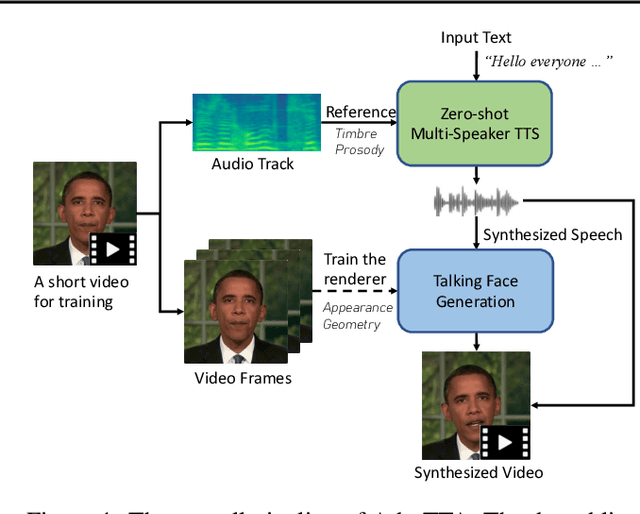

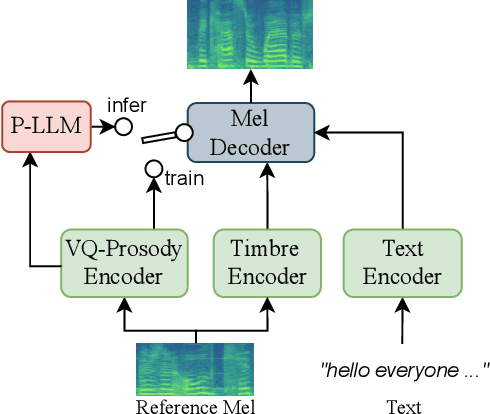

We are interested in a novel task, namely low-resource text-to-talking avatar. Given only a few-minute-long talking person video with the audio track as the training data and arbitrary texts as the driving input, we aim to synthesize high-quality talking portrait videos corresponding to the input text. This task has broad application prospects in the digital human industry but has not been technically achieved yet due to two challenges: (1) It is challenging to mimic the timbre from out-of-domain audio for a traditional multi-speaker Text-to-Speech system. (2) It is hard to render high-fidelity and lip-synchronized talking avatars with limited training data. In this paper, we introduce Adaptive Text-to-Talking Avatar (Ada-TTA), which (1) designs a generic zero-shot multi-speaker TTS model that well disentangles the text content, timbre, and prosody; and (2) embraces recent advances in neural rendering to achieve realistic audio-driven talking face video generation. With these designs, our method overcomes the aforementioned two challenges and achieves to generate identity-preserving speech and realistic talking person video. Experiments demonstrate that our method could synthesize realistic, identity-preserving, and audio-visual synchronized talking avatar videos.
Speech Aware Dialog System Technology Challenge (DSTC11)
Dec 16, 2022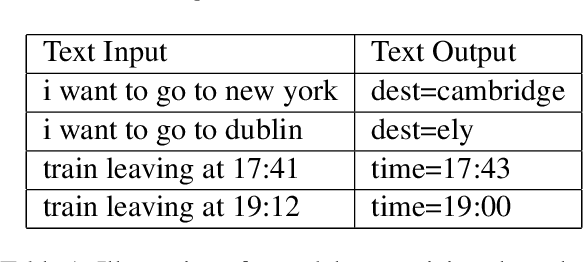
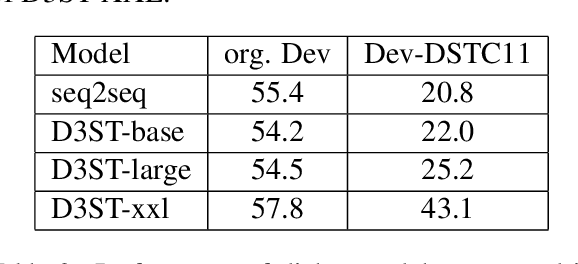
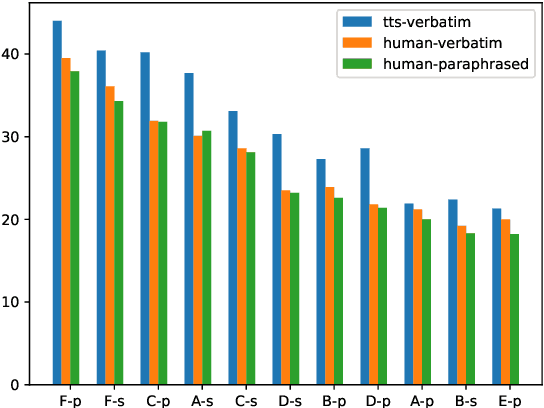
Most research on task oriented dialog modeling is based on written text input. However, users interact with practical dialog systems often using speech as input. Typically, systems convert speech into text using an Automatic Speech Recognition (ASR) system, introducing errors. Furthermore, these systems do not address the differences in written and spoken language. The research on this topic is stymied by the lack of a public corpus. Motivated by these considerations, our goal in hosting the speech-aware dialog state tracking challenge was to create a public corpus or task which can be used to investigate the performance gap between the written and spoken forms of input, develop models that could alleviate this gap, and establish whether Text-to-Speech-based (TTS) systems is a reasonable surrogate to the more-labor intensive human data collection. We created three spoken versions of the popular written-domain MultiWoz task -- (a) TTS-Verbatim: written user inputs were converted into speech waveforms using a TTS system, (b) Human-Verbatim: humans spoke the user inputs verbatim, and (c) Human-paraphrased: humans paraphrased the user inputs. Additionally, we provided different forms of ASR output to encourage wider participation from teams that may not have access to state-of-the-art ASR systems. These included ASR transcripts, word time stamps, and latent representations of the audio (audio encoder outputs). In this paper, we describe the corpus, report results from participating teams, provide preliminary analyses of their results, and summarize the current state-of-the-art in this domain.
Prompt Tuning of Deep Neural Networks for Speaker-adaptive Visual Speech Recognition
Feb 16, 2023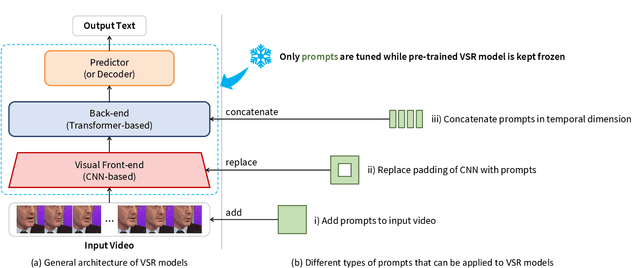
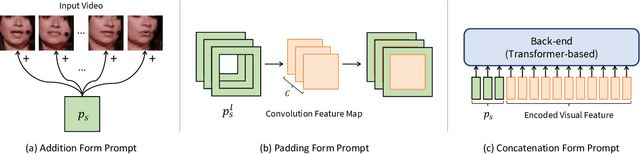
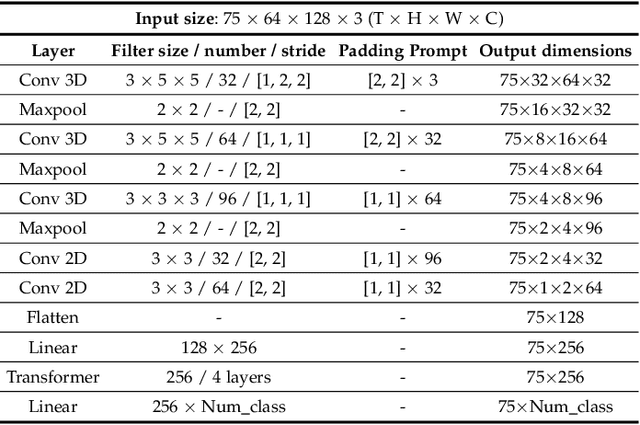
Visual Speech Recognition (VSR) aims to infer speech into text depending on lip movements alone. As it focuses on visual information to model the speech, its performance is inherently sensitive to personal lip appearances and movements, and this makes the VSR models show degraded performance when they are applied to unseen speakers. In this paper, to remedy the performance degradation of the VSR model on unseen speakers, we propose prompt tuning methods of Deep Neural Networks (DNNs) for speaker-adaptive VSR. Specifically, motivated by recent advances in Natural Language Processing (NLP), we finetune prompts on adaptation data of target speakers instead of modifying the pre-trained model parameters. Different from the previous prompt tuning methods mainly limited to Transformer variant architecture, we explore different types of prompts, the addition, the padding, and the concatenation form prompts that can be applied to the VSR model which is composed of CNN and Transformer in general. With the proposed prompt tuning, we show that the performance of the pre-trained VSR model on unseen speakers can be largely improved by using a small amount of adaptation data (e.g., less than 5 minutes), even if the pre-trained model is already developed with large speaker variations. Moreover, by analyzing the performance and parameters of different types of prompts, we investigate when the prompt tuning is preferred over the finetuning methods. The effectiveness of the proposed method is evaluated on both word- and sentence-level VSR databases, LRW-ID and GRID.
Evaluation of Virtual Acoustic Environments with Different Acoustic Level of Detail
Jun 29, 2023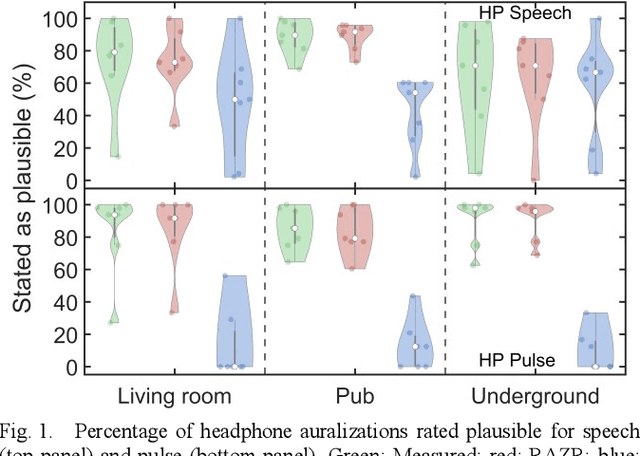
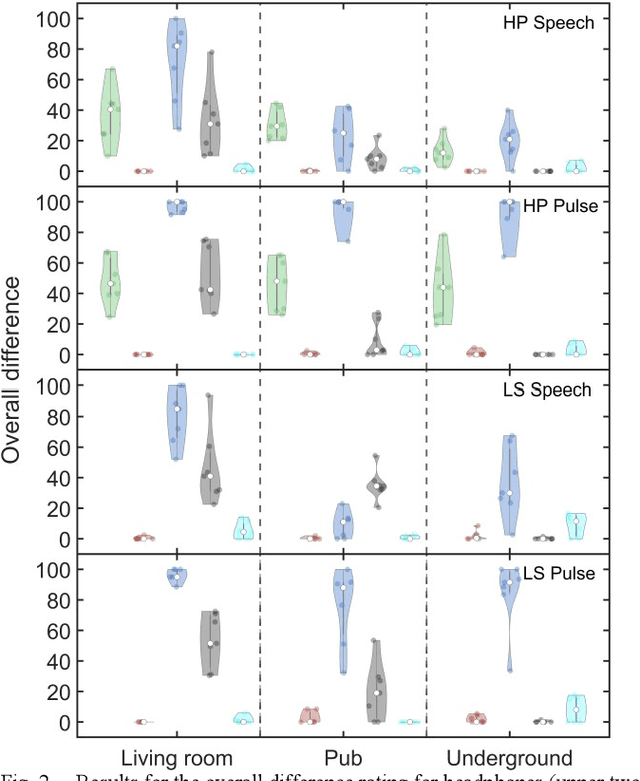
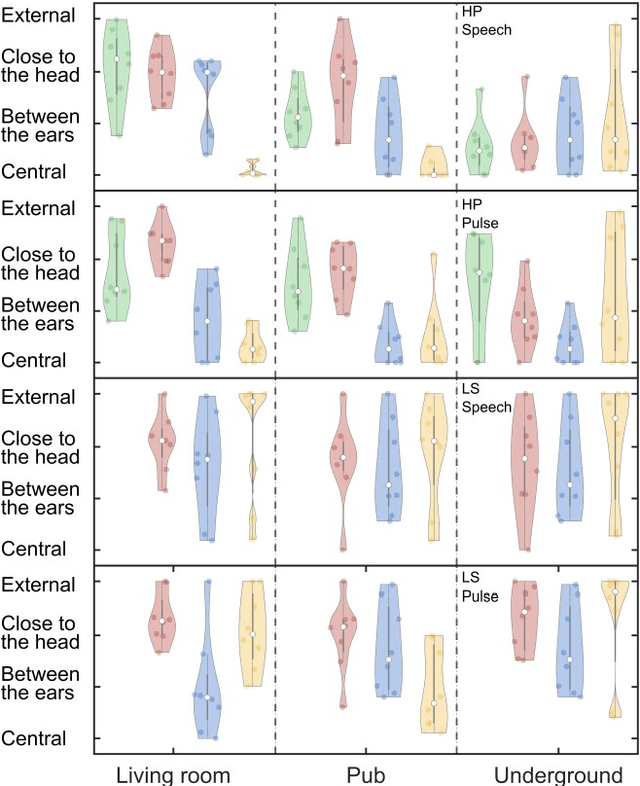
Virtual acoustic environments enable the creation and simulation of realistic and ecologically valid daily-life situations with applications in hearing research and audiology. Hereby, reverberant indoor environments play an important role. For real-time applications, simplifications in the room acoustics simulation are required, however, it remains unclear what acoustic level of detail (ALOD) is necessary to capture all perceptually relevant effects. This study investigates the effect of varying ALOD in the simulation of three different real environments, a living room with a coupled kitchen, a pub, and an underground station. ALOD was varied by generating different numbers of image sources for early reflections, or by excluding geometrical room details specific for each environment. The simulations were perceptually evaluated using headphones in comparison to binaural room impulse responses measured with a dummy head in the corresponding real environments. The study assessed the perceived overall difference for a pink pulse, and a speech token. Furthermore, plausibility and externalization were evaluated. The results show that a strong reduction in ALOD is possible while obtaining similar plausibility and externalization as with dummy head recordings. The number and accuracy of early reflections appear less relevant, provided diffuse late reverberation is appropriately accounted for.
On the relevance of acoustic measurements for creating realistic virtual acoustic environments
Jun 29, 2023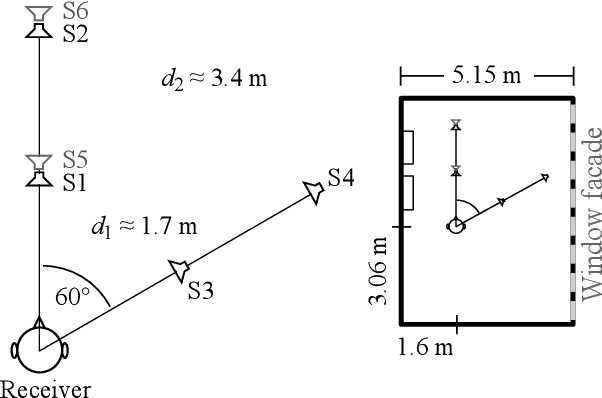
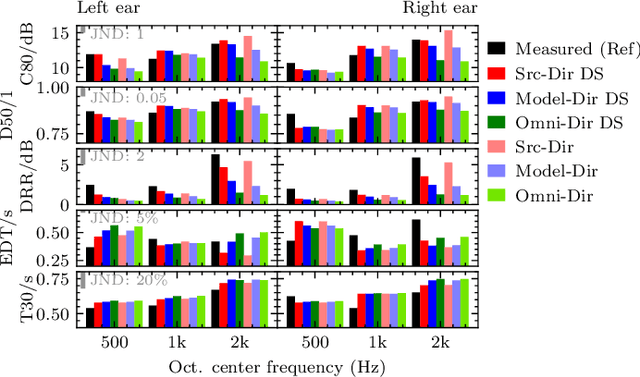
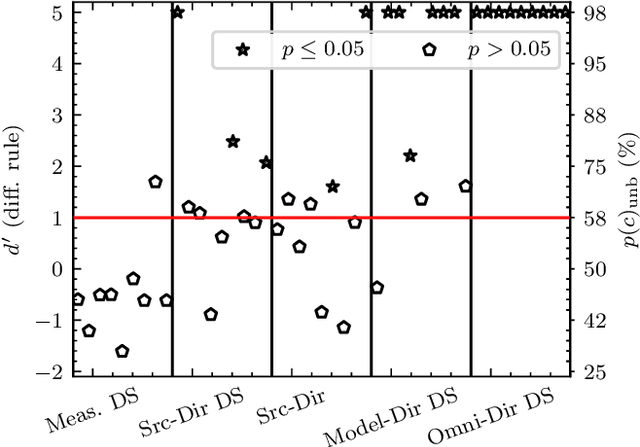
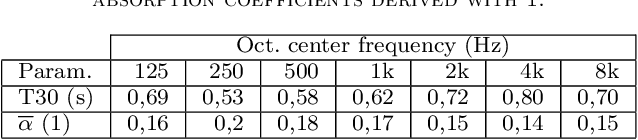
Geometrical approaches for room acoustics simulation have the advantage of requiring limited computational resources while still achieving a high perceptual plausibility. A common approach is using the image source model for direct and early reflections in connection with further simplified models such as a feedback delay network for the diffuse reverberant tail. When recreating real spaces as virtual acoustic environments using room acoustics simulation, the perceptual relevance of individual parameters in the simulation is unclear. Here we investigate the importance of underlying acoustical measurements and technical evaluation methods to obtain high-quality room acoustics simulations in agreement with dummy-head recordings of a real space. We focus on the role of source directivity. The effect of including measured, modelled, and omnidirectional source directivity in room acoustics simulations was assessed in comparison to the measured reference. Technical evaluation strategies to verify and improve the accuracy of various elements in the simulation processing chain from source, the room properties, to the receiver are presented. Perceptual results from an ABX listening experiment with random speech tokens are shown and compared with technical measures for a ranking of simulation approaches.
ADAPTERMIX: Exploring the Efficacy of Mixture of Adapters for Low-Resource TTS Adaptation
May 29, 2023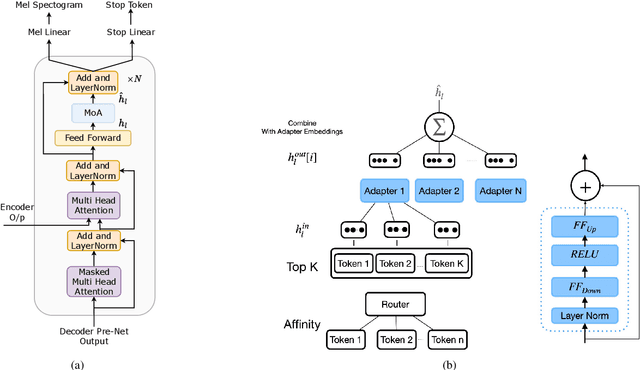

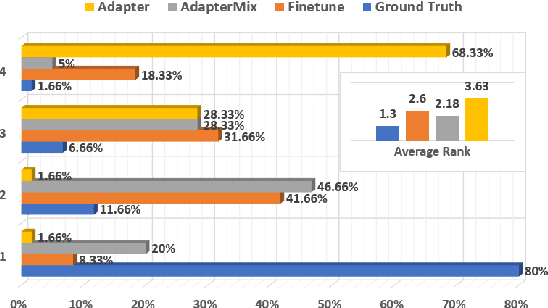
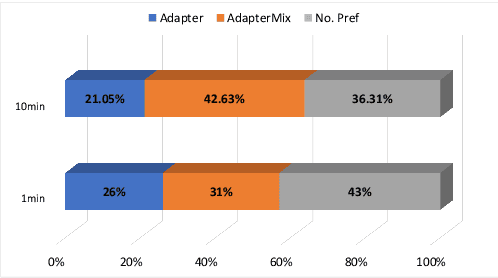
There are significant challenges for speaker adaptation in text-to-speech for languages that are not widely spoken or for speakers with accents or dialects that are not well-represented in the training data. To address this issue, we propose the use of the "mixture of adapters" method. This approach involves adding multiple adapters within a backbone-model layer to learn the unique characteristics of different speakers. Our approach outperforms the baseline, with a noticeable improvement of 5% observed in speaker preference tests when using only one minute of data for each new speaker. Moreover, following the adapter paradigm, we fine-tune only the adapter parameters (11% of the total model parameters). This is a significant achievement in parameter-efficient speaker adaptation, and one of the first models of its kind. Overall, our proposed approach offers a promising solution to the speech synthesis techniques, particularly for adapting to speakers from diverse backgrounds.
Modality Influence in Multimodal Machine Learning
Jun 10, 2023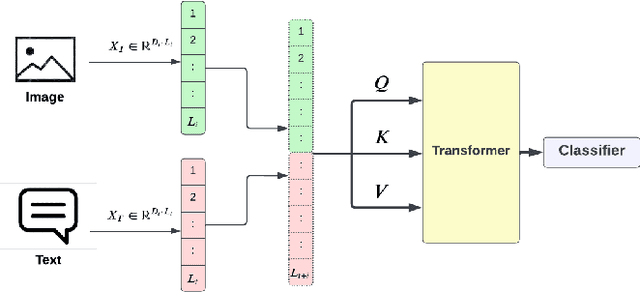
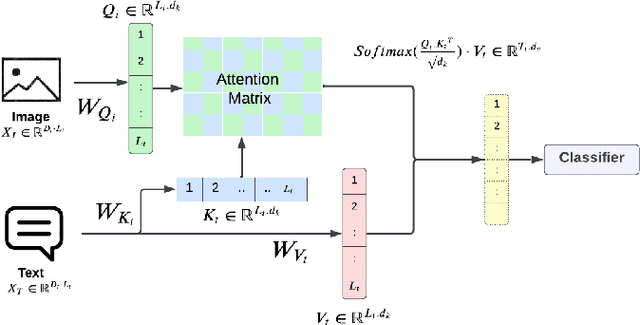
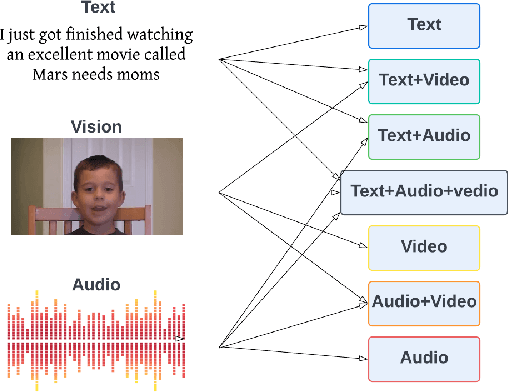
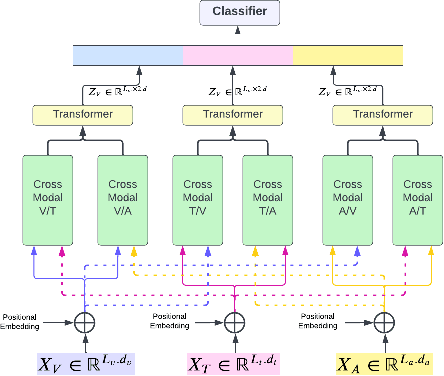
Multimodal Machine Learning has emerged as a prominent research direction across various applications such as Sentiment Analysis, Emotion Recognition, Machine Translation, Hate Speech Recognition, and Movie Genre Classification. This approach has shown promising results by utilizing modern deep learning architectures. Despite the achievements made, challenges remain in data representation, alignment techniques, reasoning, generation, and quantification within multimodal learning. Additionally, assumptions about the dominant role of textual modality in decision-making have been made. However, limited investigations have been conducted on the influence of different modalities in Multimodal Machine Learning systems. This paper aims to address this gap by studying the impact of each modality on multimodal learning tasks. The research focuses on verifying presumptions and gaining insights into the usage of different modalities. The main contribution of this work is the proposal of a methodology to determine the effect of each modality on several Multimodal Machine Learning models and datasets from various tasks. Specifically, the study examines Multimodal Sentiment Analysis, Multimodal Emotion Recognition, Multimodal Hate Speech Recognition, and Multimodal Disease Detection. The study objectives include training SOTA MultiModal Machine Learning models with masked modalities to evaluate their impact on performance. Furthermore, the research aims to identify the most influential modality or set of modalities for each task and draw conclusions for diverse multimodal classification tasks. By undertaking these investigations, this research contributes to a better understanding of the role of individual modalities in multi-modal learning and provides valuable insights for future advancements in this field.
Mu$^{2}$SLAM: Multitask, Multilingual Speech and Language Models
Dec 19, 2022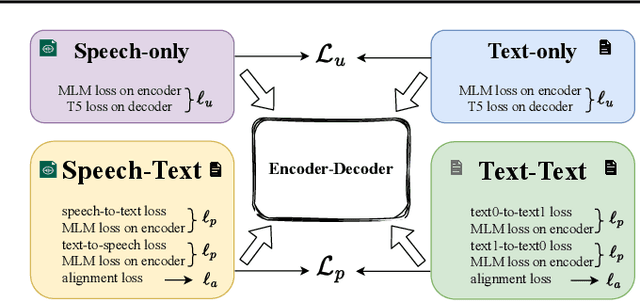
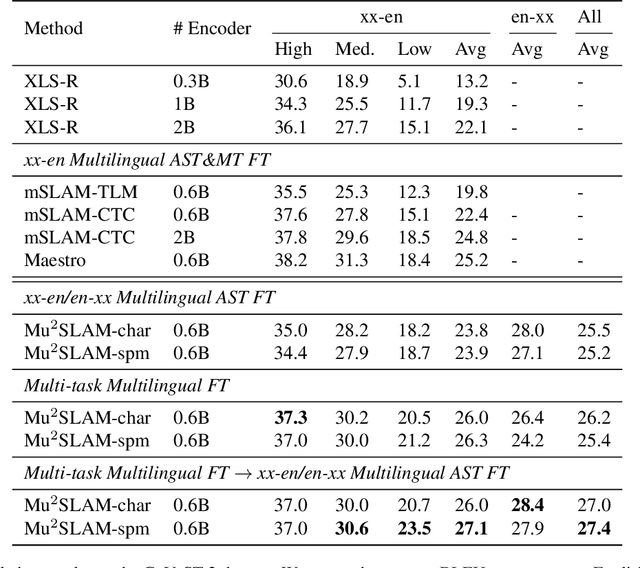
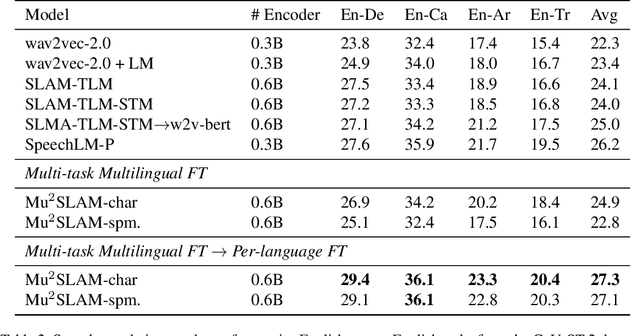
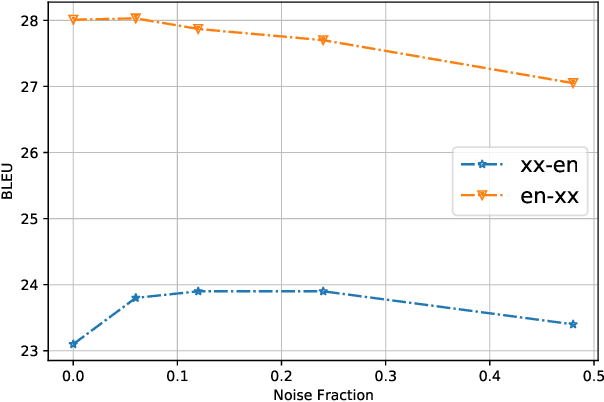
We present Mu$^{2}$SLAM, a multilingual sequence-to-sequence model pre-trained jointly on unlabeled speech, unlabeled text and supervised data spanning Automatic Speech Recognition (ASR), Automatic Speech Translation (AST) and Machine Translation (MT), in over 100 languages. By leveraging a quantized representation of speech as a target, Mu$^{2}$SLAM trains the speech-text models with a sequence-to-sequence masked denoising objective similar to T5 on the decoder and a masked language modeling (MLM) objective on the encoder, for both unlabeled speech and text, while utilizing the supervised tasks to improve cross-lingual and cross-modal representation alignment within the model. On CoVoST AST, Mu$^{2}$SLAM establishes a new state-of-the-art for models trained on public datasets, improving on xx-en translation over the previous best by 1.9 BLEU points and on en-xx translation by 1.1 BLEU points. On Voxpopuli ASR, our model matches the performance of an mSLAM model fine-tuned with an RNN-T decoder, despite using a relatively weaker sequence-to-sequence architecture. On text understanding tasks, our model improves by more than 6\% over mSLAM on XNLI, getting closer to the performance of mT5 models of comparable capacity on XNLI and TydiQA, paving the way towards a single model for all speech and text understanding tasks.