 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Using a Large Language Model to Control Speaking Style for Expressive TTS
May 17, 2023
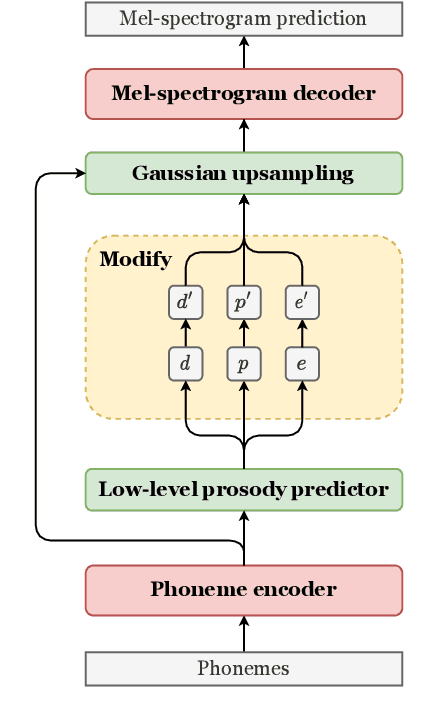
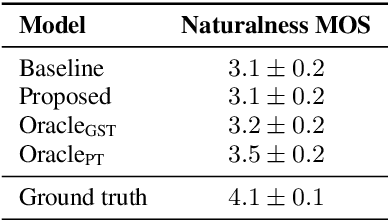
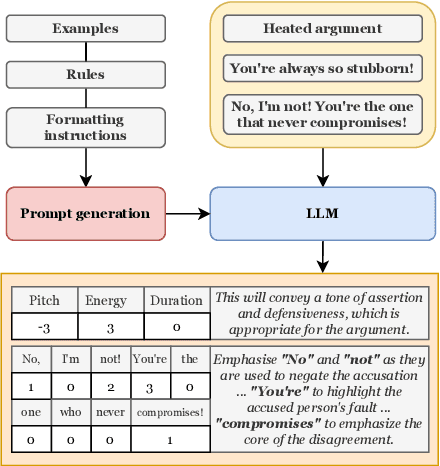
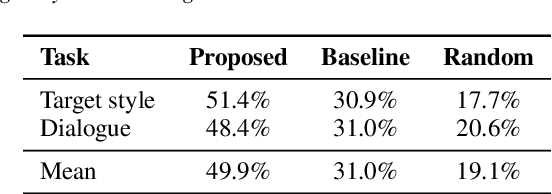
Appropriate prosody is critical for successful spoken communication. Contextual word embeddings are proven to be helpful in predicting prosody but do not allow for choosing between plausible prosodic renditions. Reference-based TTS models attempt to address this by conditioning speech generation on a reference speech sample. These models can generate expressive speech but this requires finding an appropriate reference. Sufficiently large generative language models have been used to solve various language-related tasks. We explore whether such models can be used to suggest appropriate prosody for expressive TTS. We train a TTS model on a non-expressive corpus and then prompt the language model to suggest changes to pitch, energy and duration. The prompt can be designed for any task and we prompt the model to make suggestions based on target speaking style and dialogue context. The proposed method is rated most appropriate in 49.9\% of cases compared to 31.0\% for a baseline model.
2nd Swiss German Speech to Standard German Text Shared Task at SwissText 2022
Jan 17, 2023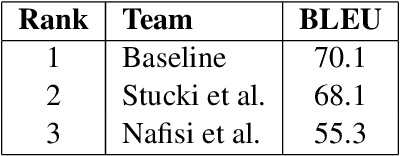
We present the results and findings of the 2nd Swiss German speech to Standard German text shared task at SwissText 2022. Participants were asked to build a sentence-level Swiss German speech to Standard German text system specialized on the Grisons dialect. The objective was to maximize the BLEU score on a test set of Grisons speech. 3 teams participated, with the best-performing system achieving a BLEU score of 70.1.
MIXPGD: Hybrid Adversarial Training for Speech Recognition Systems
Mar 10, 2023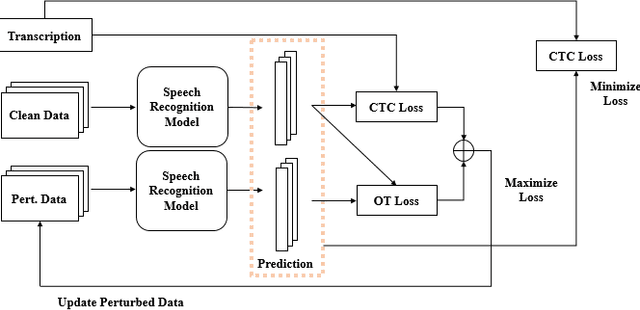
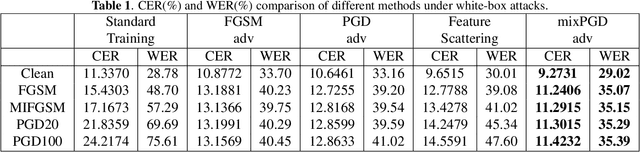
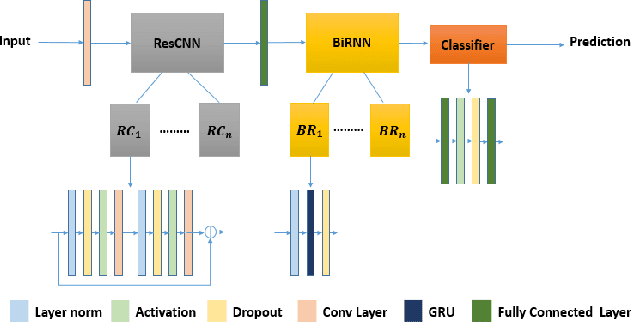
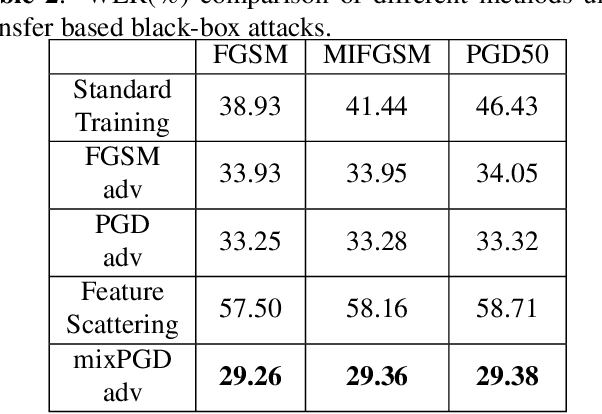
Automatic speech recognition (ASR) systems based on deep neural networks are weak against adversarial perturbations. We propose mixPGD adversarial training method to improve the robustness of the model for ASR systems. In standard adversarial training, adversarial samples are generated by leveraging supervised or unsupervised methods. We merge the capabilities of both supervised and unsupervised approaches in our method to generate new adversarial samples which aid in improving model robustness. Extensive experiments and comparison across various state-of-the-art defense methods and adversarial attacks have been performed to show that mixPGD gains 4.1% WER of better performance than previous best performing models under white-box adversarial attack setting. We tested our proposed defense method against both white-box and transfer based black-box attack settings to ensure that our defense strategy is robust against various types of attacks. Empirical results on several adversarial attacks validate the effectiveness of our proposed approach.
Speech-to-Speech Translation For A Real-world Unwritten Language
Nov 11, 2022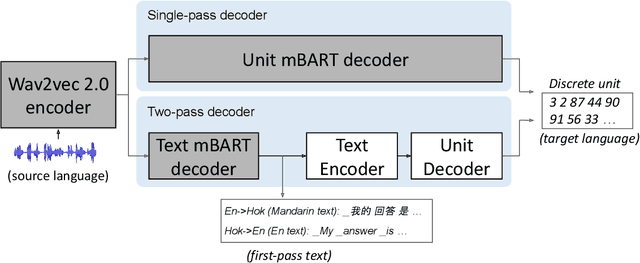
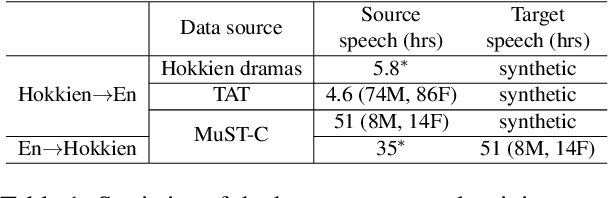
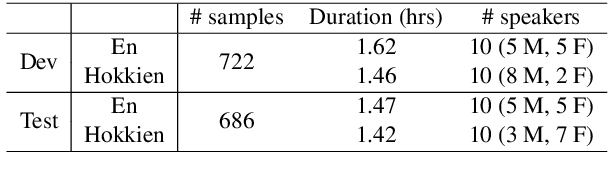
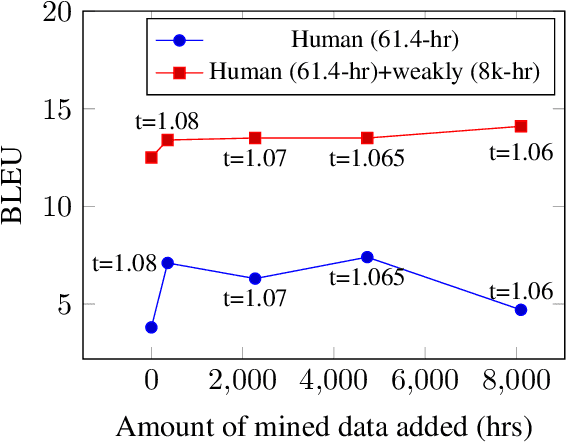
We study speech-to-speech translation (S2ST) that translates speech from one language into another language and focuses on building systems to support languages without standard text writing systems. We use English-Taiwanese Hokkien as a case study, and present an end-to-end solution from training data collection, modeling choices to benchmark dataset release. First, we present efforts on creating human annotated data, automatically mining data from large unlabeled speech datasets, and adopting pseudo-labeling to produce weakly supervised data. On the modeling, we take advantage of recent advances in applying self-supervised discrete representations as target for prediction in S2ST and show the effectiveness of leveraging additional text supervision from Mandarin, a language similar to Hokkien, in model training. Finally, we release an S2ST benchmark set to facilitate future research in this field. The demo can be found at https://huggingface.co/spaces/facebook/Hokkien_Translation .
Connecting Humanities and Social Sciences: Applying Language and Speech Technology to Online Panel Surveys
Feb 21, 2023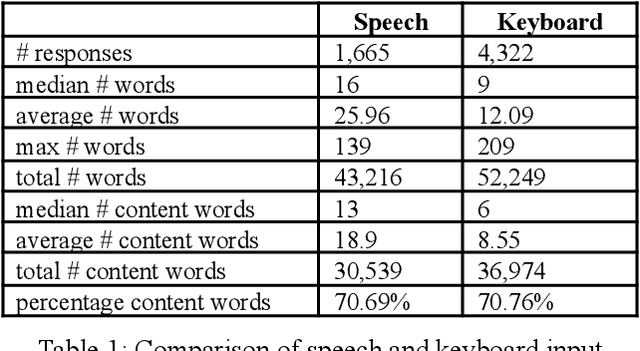
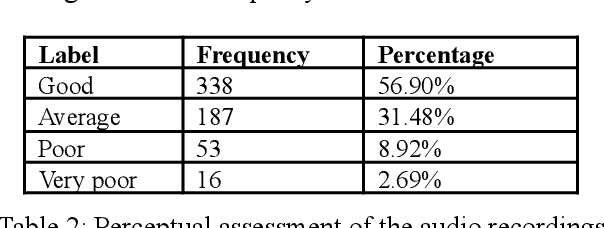
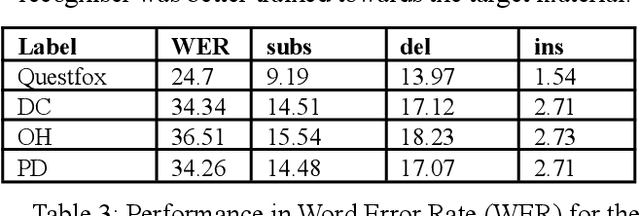
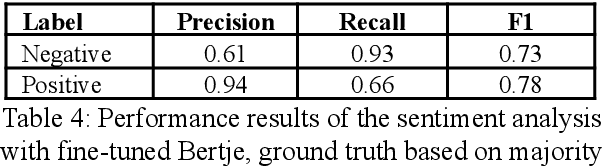
In this paper, we explore the application of language and speech technology to open-ended questions in a Dutch panel survey. In an experimental wave respondents could choose to answer open questions via speech or keyboard. Automatic speech recognition (ASR) was used to process spoken responses. We evaluated answers from these input modalities to investigate differences between spoken and typed answers.We report the errors the ASR system produces and investigate the impact of these errors on downstream analyses. Open-ended questions give more freedom to answer for respondents, but entail a non-trivial amount of work to analyse. We evaluated the feasibility of using transformer-based models (e.g. BERT) to apply sentiment analysis and topic modelling on the answers of open questions. A big advantage of transformer-based models is that they are trained on a large amount of language materials and do not necessarily need training on the target materials. This is especially advantageous for survey data, which does not contain a lot of text materials. We tested the quality of automatic sentiment analysis by comparing automatic labeling with three human raters and tested the robustness of topic modelling by comparing the generated models based on automatic and manually transcribed spoken answers.
An ASR-Based Tutor for Learning to Read: How to Optimize Feedback to First Graders
Jun 07, 2023The interest in employing automatic speech recognition (ASR) in applications for reading practice has been growing in recent years. In a previous study, we presented an ASR-based Dutch reading tutor application that was developed to provide instantaneous feedback to first-graders learning to read. We saw that ASR has potential at this stage of the reading process, as the results suggested that pupils made progress in reading accuracy and fluency by using the software. In the current study, we used children's speech from an existing corpus (JASMIN) to develop two new ASR systems, and compared the results to those of the previous study. We analyze correct/incorrect classification of the ASR systems using human transcripts at word level, by means of evaluation measures such as Cohen's Kappa, Matthews Correlation Coefficient (MCC), precision, recall and F-measures. We observe improvements for the newly developed ASR systems regarding the agreement with human-based judgment and correct rejection (CR). The accuracy of the ASR systems varies for different reading tasks and word types. Our results suggest that, in the current configuration, it is difficult to classify isolated words. We discuss these results, possible ways to improve our systems and avenues for future research.
* Published (double-blind peer-reviewed) on SPECOM 2021
Anytime, Anywhere: Human Arm Pose from Smartwatch Data for Ubiquitous Robot Control and Teleoperation
Jun 22, 2023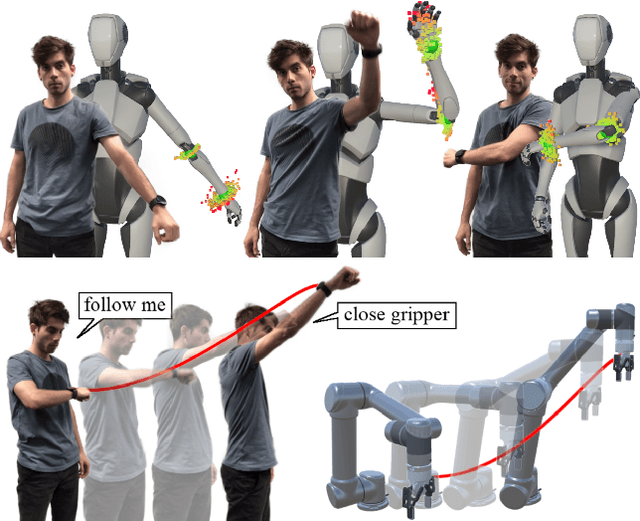

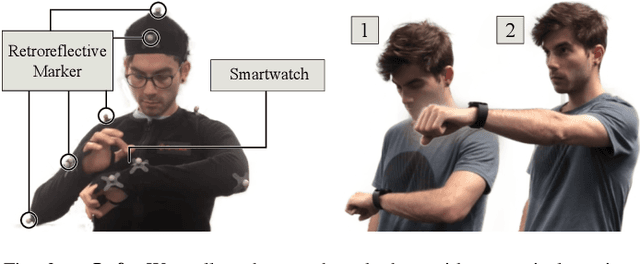
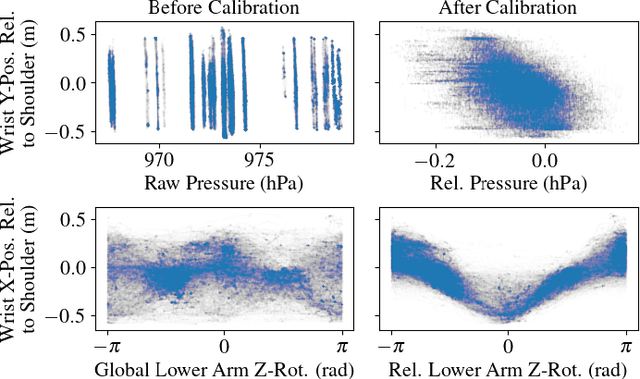
This work devises an optimized machine learning approach for human arm pose estimation from a single smartwatch. Our approach results in a distribution of possible wrist and elbow positions, which allows for a measure of uncertainty and the detection of multiple possible arm posture solutions, i.e., multimodal pose distributions. Combining estimated arm postures with speech recognition, we turn the smartwatch into a ubiquitous, low-cost and versatile robot control interface. We demonstrate in two use-cases that this intuitive control interface enables users to swiftly intervene in robot behavior, to temporarily adjust their goal, or to train completely new control policies by imitation. Extensive experiments show that the approach results in a 40% reduction in prediction error over the current state-of-the-art and achieves a mean error of 2.56cm for wrist and elbow positions.
Duration-aware pause insertion using pre-trained language model for multi-speaker text-to-speech
Feb 27, 2023
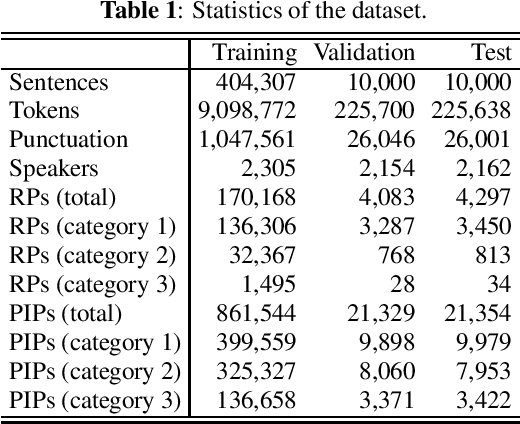
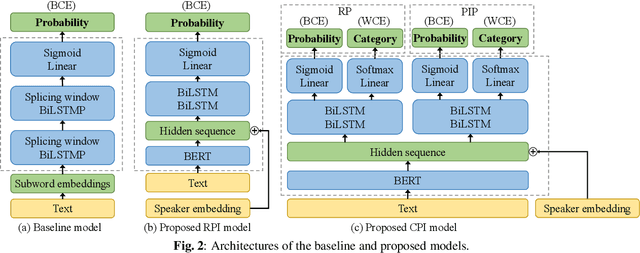
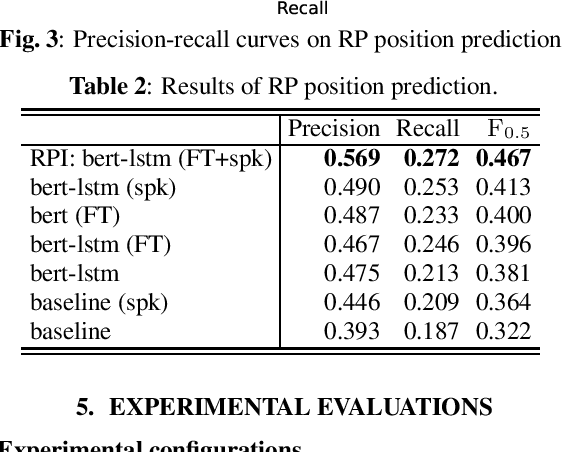
Pause insertion, also known as phrase break prediction and phrasing, is an essential part of TTS systems because proper pauses with natural duration significantly enhance the rhythm and intelligibility of synthetic speech. However, conventional phrasing models ignore various speakers' different styles of inserting silent pauses, which can degrade the performance of the model trained on a multi-speaker speech corpus. To this end, we propose more powerful pause insertion frameworks based on a pre-trained language model. Our approach uses bidirectional encoder representations from transformers (BERT) pre-trained on a large-scale text corpus, injecting speaker embedding to capture various speaker characteristics. We also leverage duration-aware pause insertion for more natural multi-speaker TTS. We develop and evaluate two types of models. The first improves conventional phrasing models on the position prediction of respiratory pauses (RPs), i.e., silent pauses at word transitions without punctuation. It performs speaker-conditioned RP prediction considering contextual information and is used to demonstrate the effect of speaker information on the prediction. The second model is further designed for phoneme-based TTS models and performs duration-aware pause insertion, predicting both RPs and punctuation-indicated pauses (PIPs) that are categorized by duration. The evaluation results show that our models improve the precision and recall of pause insertion and the rhythm of synthetic speech.
Relate auditory speech to EEG by shallow-deep attention-based network
Mar 20, 2023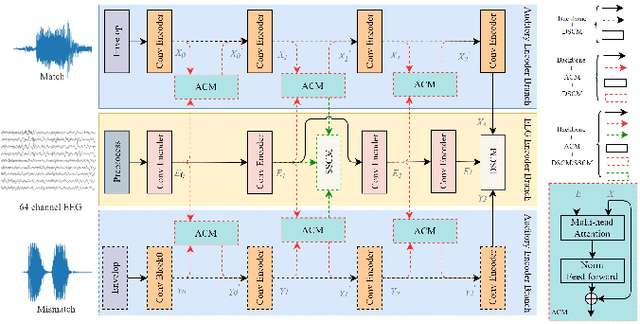
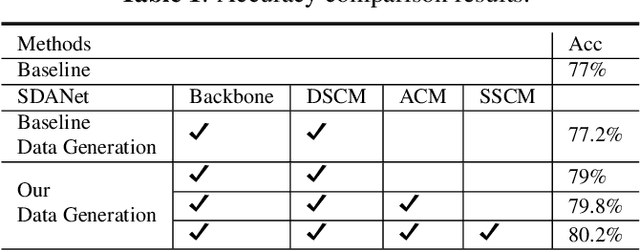
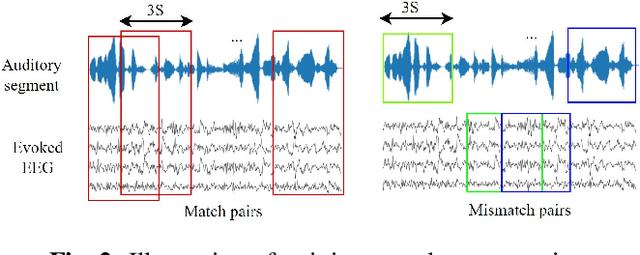
Electroencephalography (EEG) plays a vital role in detecting how brain responses to different stimulus. In this paper, we propose a novel Shallow-Deep Attention-based Network (SDANet) to classify the correct auditory stimulus evoking the EEG signal. It adopts the Attention-based Correlation Module (ACM) to discover the connection between auditory speech and EEG from global aspect, and the Shallow-Deep Similarity Classification Module (SDSCM) to decide the classification result via the embeddings learned from the shallow and deep layers. Moreover, various training strategies and data augmentation are used to boost the model robustness. Experiments are conducted on the dataset provided by Auditory EEG challenge (ICASSP Signal Processing Grand Challenge 2023). Results show that the proposed model has a significant gain over the baseline on the match-mismatch track.
Exploring Non-Verbal Predicates in Semantic Role Labeling: Challenges and Opportunities
Jul 04, 2023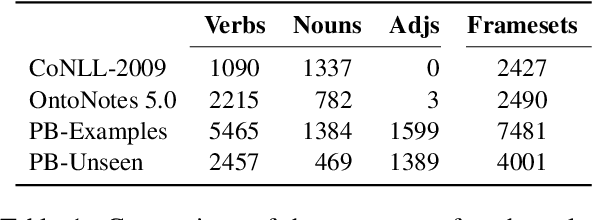
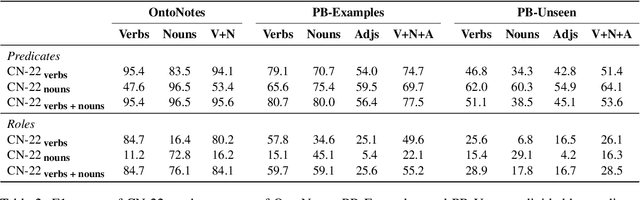
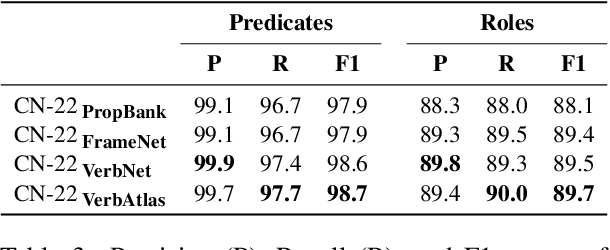
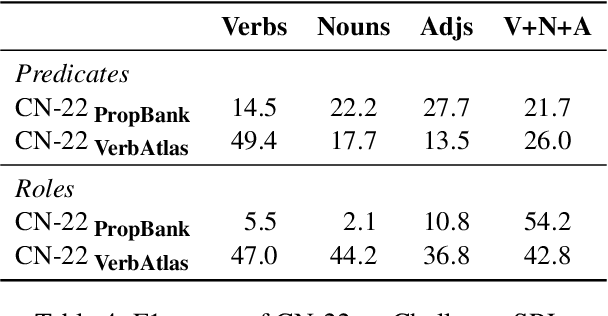
Although we have witnessed impressive progress in Semantic Role Labeling (SRL), most of the research in the area is carried out assuming that the majority of predicates are verbs. Conversely, predicates can also be expressed using other parts of speech, e.g., nouns and adjectives. However, non-verbal predicates appear in the benchmarks we commonly use to measure progress in SRL less frequently than in some real-world settings -- newspaper headlines, dialogues, and tweets, among others. In this paper, we put forward a new PropBank dataset which boasts wide coverage of multiple predicate types. Thanks to it, we demonstrate empirically that standard benchmarks do not provide an accurate picture of the current situation in SRL and that state-of-the-art systems are still incapable of transferring knowledge across different predicate types. Having observed these issues, we also present a novel, manually-annotated challenge set designed to give equal importance to verbal, nominal, and adjectival predicate-argument structures. We use such dataset to investigate whether we can leverage different linguistic resources to promote knowledge transfer. In conclusion, we claim that SRL is far from "solved", and its integration with other semantic tasks might enable significant improvements in the future, especially for the long tail of non-verbal predicates, thereby facilitating further research on SRL for non-verbal predicates.