 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
What has LeBenchmark Learnt about French Syntax?
Mar 04, 2024
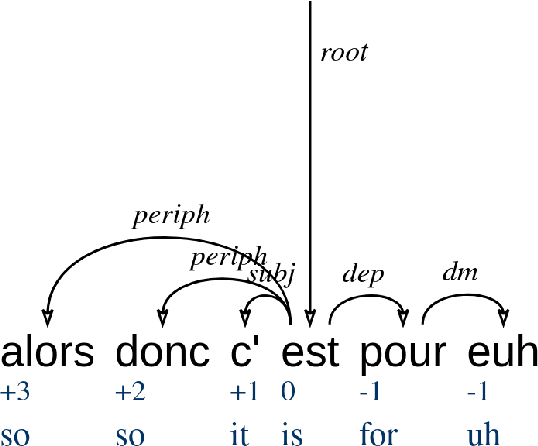
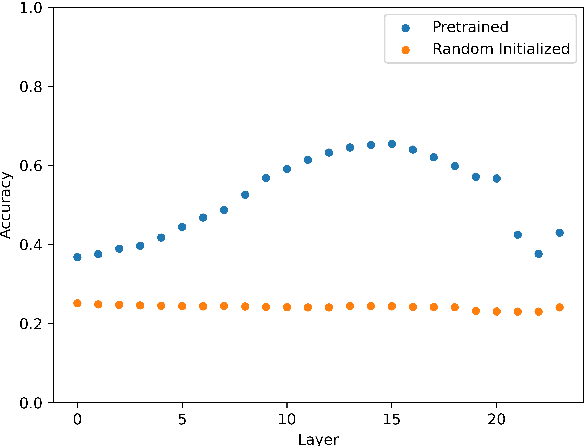
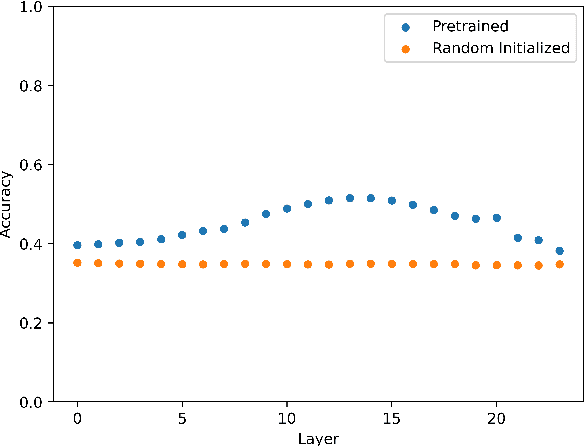
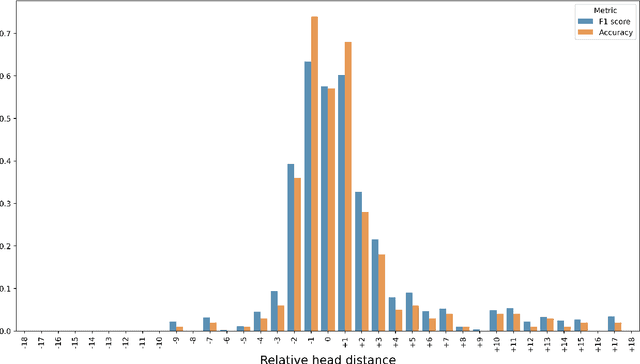
The paper reports on a series of experiments aiming at probing LeBenchmark, a pretrained acoustic model trained on 7k hours of spoken French, for syntactic information. Pretrained acoustic models are increasingly used for downstream speech tasks such as automatic speech recognition, speech translation, spoken language understanding or speech parsing. They are trained on very low level information (the raw speech signal), and do not have explicit lexical knowledge. Despite that, they obtained reasonable results on tasks that requires higher level linguistic knowledge. As a result, an emerging question is whether these models encode syntactic information. We probe each representation layer of LeBenchmark for syntax, using the Orf\'eo treebank, and observe that it has learnt some syntactic information. Our results show that syntactic information is more easily extractable from the middle layers of the network, after which a very sharp decrease is observed.
Leveraging Weakly Annotated Data for Hate Speech Detection in Code-Mixed Hinglish: A Feasibility-Driven Transfer Learning Approach with Large Language Models
Mar 04, 2024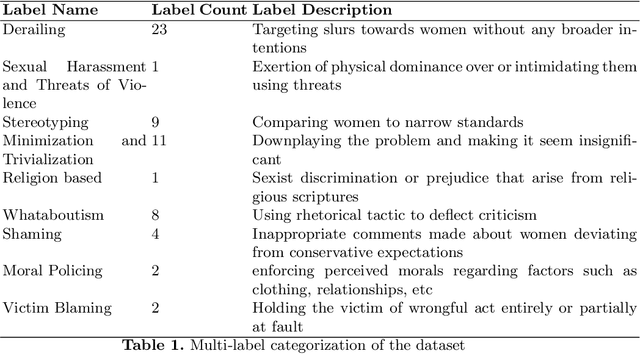
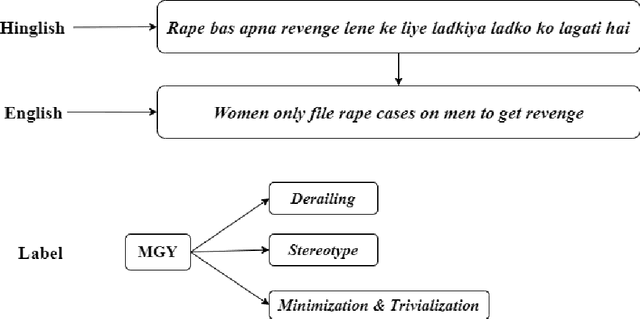
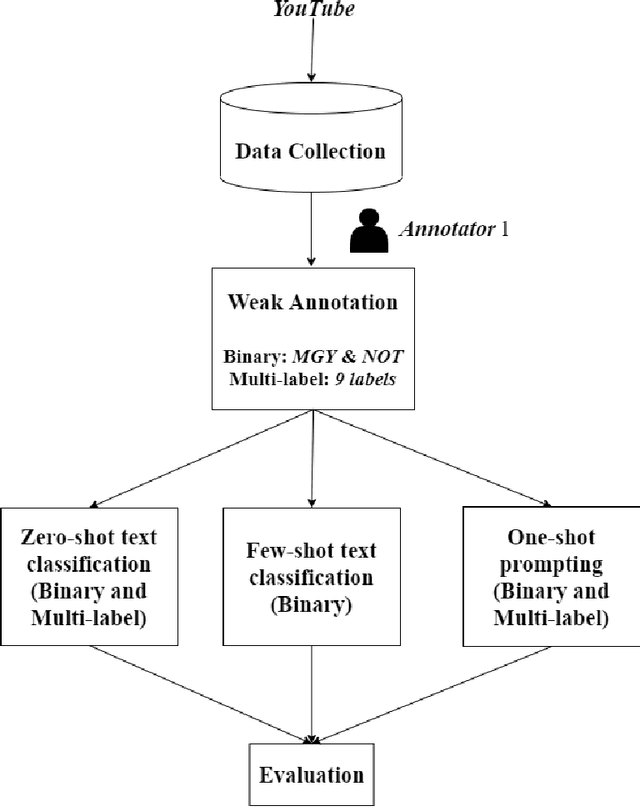
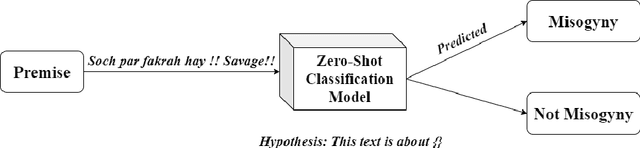
The advent of Large Language Models (LLMs) has advanced the benchmark in various Natural Language Processing (NLP) tasks. However, large amounts of labelled training data are required to train LLMs. Furthermore, data annotation and training are computationally expensive and time-consuming. Zero and few-shot learning have recently emerged as viable options for labelling data using large pre-trained models. Hate speech detection in mix-code low-resource languages is an active problem area where the use of LLMs has proven beneficial. In this study, we have compiled a dataset of 100 YouTube comments, and weakly labelled them for coarse and fine-grained misogyny classification in mix-code Hinglish. Weak annotation was applied due to the labor-intensive annotation process. Zero-shot learning, one-shot learning, and few-shot learning and prompting approaches have then been applied to assign labels to the comments and compare them to human-assigned labels. Out of all the approaches, zero-shot classification using the Bidirectional Auto-Regressive Transformers (BART) large model and few-shot prompting using Generative Pre-trained Transformer- 3 (ChatGPT-3) achieve the best results
Not All Weights Are Created Equal: Enhancing Energy Efficiency in On-Device Streaming Speech Recognition
Feb 20, 2024Power consumption plays an important role in on-device streaming speech recognition, as it has a direct impact on the user experience. This study delves into how weight parameters in speech recognition models influence the overall power consumption of these models. We discovered that the impact of weight parameters on power consumption varies, influenced by factors including how often they are invoked and their placement in memory. Armed with this insight, we developed design guidelines aimed at optimizing on-device speech recognition models. These guidelines focus on minimizing power use without substantially affecting accuracy. Our method, which employs targeted compression based on the varying sensitivities of weight parameters, demonstrates superior performance compared to state-of-the-art compression methods. It achieves a reduction in energy usage of up to 47% while maintaining similar model accuracy and improving the real-time factor.
SpeechCLIP+: Self-supervised multi-task representation learning for speech via CLIP and speech-image data
Feb 10, 2024The recently proposed visually grounded speech model SpeechCLIP is an innovative framework that bridges speech and text through images via CLIP without relying on text transcription. On this basis, this paper introduces two extensions to SpeechCLIP. First, we apply the Continuous Integrate-and-Fire (CIF) module to replace a fixed number of CLS tokens in the cascaded architecture. Second, we propose a new hybrid architecture that merges the cascaded and parallel architectures of SpeechCLIP into a multi-task learning framework. Our experimental evaluation is performed on the Flickr8k and SpokenCOCO datasets. The results show that in the speech keyword extraction task, the CIF-based cascaded SpeechCLIP model outperforms the previous cascaded SpeechCLIP model using a fixed number of CLS tokens. Furthermore, through our hybrid architecture, cascaded task learning boosts the performance of the parallel branch in image-speech retrieval tasks.
sVAD: A Robust, Low-Power, and Light-Weight Voice Activity Detection with Spiking Neural Networks
Mar 09, 2024
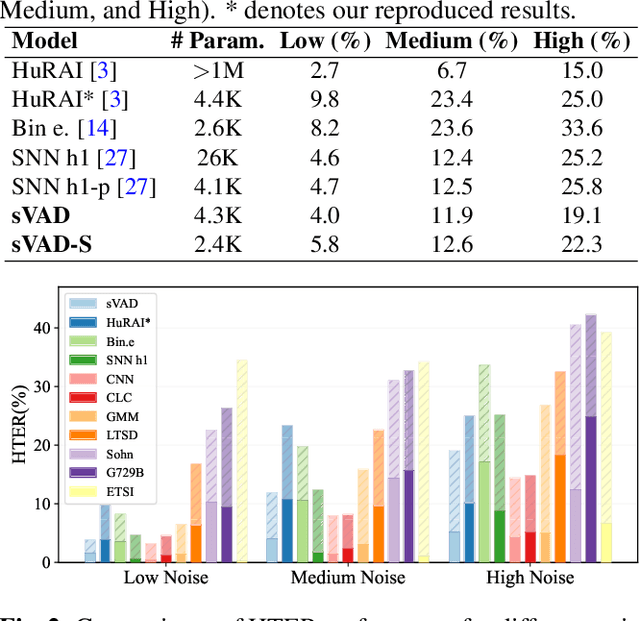
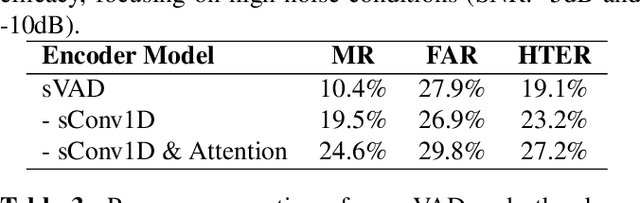
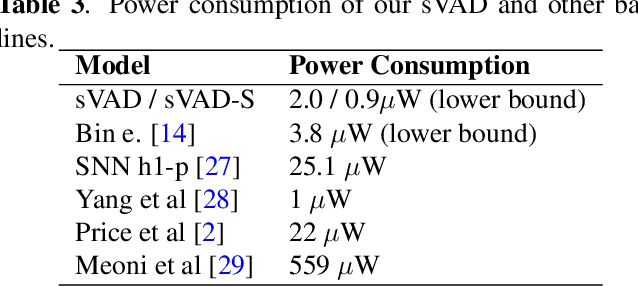
Speech applications are expected to be low-power and robust under noisy conditions. An effective Voice Activity Detection (VAD) front-end lowers the computational need. Spiking Neural Networks (SNNs) are known to be biologically plausible and power-efficient. However, SNN-based VADs have yet to achieve noise robustness and often require large models for high performance. This paper introduces a novel SNN-based VAD model, referred to as sVAD, which features an auditory encoder with an SNN-based attention mechanism. Particularly, it provides effective auditory feature representation through SincNet and 1D convolution, and improves noise robustness with attention mechanisms. The classifier utilizes Spiking Recurrent Neural Networks (sRNN) to exploit temporal speech information. Experimental results demonstrate that our sVAD achieves remarkable noise robustness and meanwhile maintains low power consumption and a small footprint, making it a promising solution for real-world VAD applications.
MaiBaam: A Multi-Dialectal Bavarian Universal Dependency Treebank
Mar 15, 2024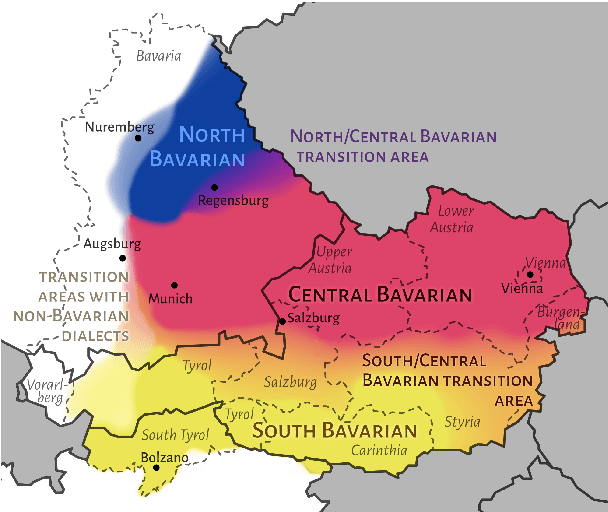
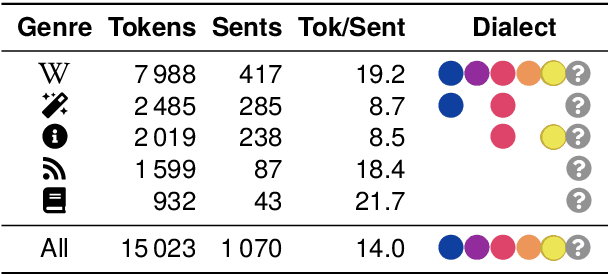
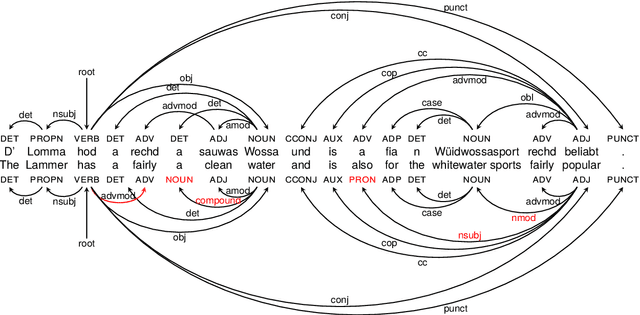
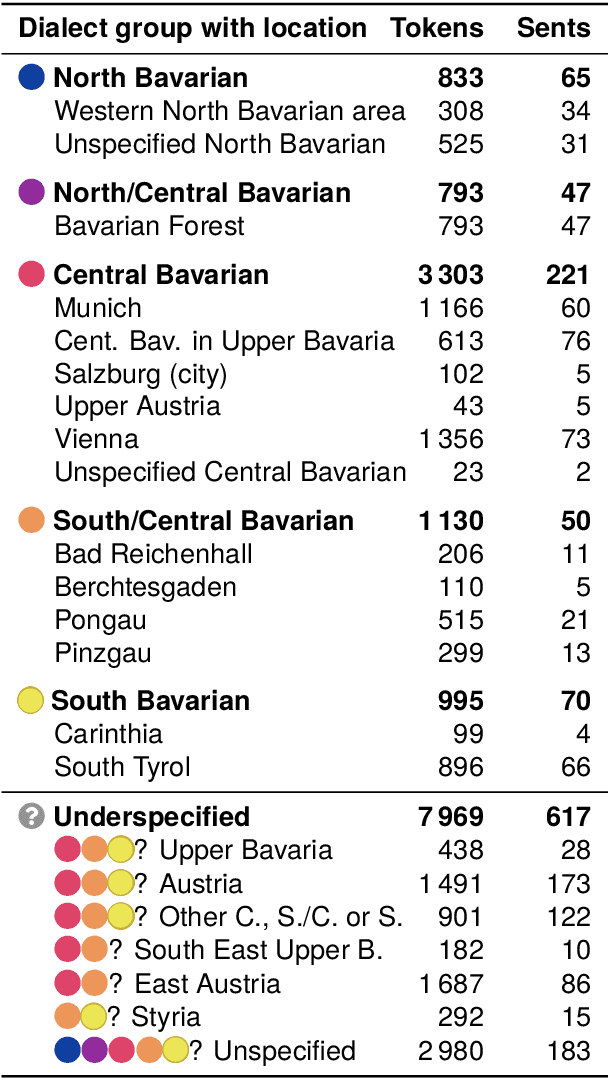
Despite the success of the Universal Dependencies (UD) project exemplified by its impressive language breadth, there is still a lack in `within-language breadth': most treebanks focus on standard languages. Even for German, the language with the most annotations in UD, so far no treebank exists for one of its language varieties spoken by over 10M people: Bavarian. To contribute to closing this gap, we present the first multi-dialect Bavarian treebank (MaiBaam) manually annotated with part-of-speech and syntactic dependency information in UD, covering multiple text genres (wiki, fiction, grammar examples, social, non-fiction). We highlight the morphosyntactic differences between the closely-related Bavarian and German and showcase the rich variability of speakers' orthographies. Our corpus includes 15k tokens, covering dialects from all Bavarian-speaking areas spanning three countries. We provide baseline parsing and POS tagging results, which are lower than results obtained on German and vary substantially between different graph-based parsers. To support further research on Bavarian syntax, we make our dataset, language-specific guidelines and code publicly available.
Speaking in Wavelet Domain: A Simple and Efficient Approach to Speed up Speech Diffusion Model
Feb 16, 2024Recently, Denoising Diffusion Probabilistic Models (DDPMs) have attained leading performances across a diverse range of generative tasks. However, in the field of speech synthesis, although DDPMs exhibit impressive performance, their long training duration and substantial inference costs hinder practical deployment. Existing approaches primarily focus on enhancing inference speed, while approaches to accelerate training a key factor in the costs associated with adding or customizing voices often necessitate complex modifications to the model, compromising their universal applicability. To address the aforementioned challenges, we propose an inquiry: is it possible to enhance the training/inference speed and performance of DDPMs by modifying the speech signal itself? In this paper, we double the training and inference speed of Speech DDPMs by simply redirecting the generative target to the wavelet domain. This method not only achieves comparable or superior performance to the original model in speech synthesis tasks but also demonstrates its versatility. By investigating and utilizing different wavelet bases, our approach proves effective not just in speech synthesis, but also in speech enhancement.
Exploring Tokenization Strategies and Vocabulary Sizes for Enhanced Arabic Language Models
Mar 17, 2024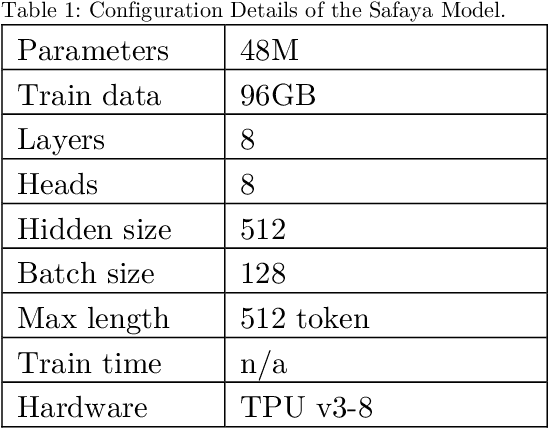
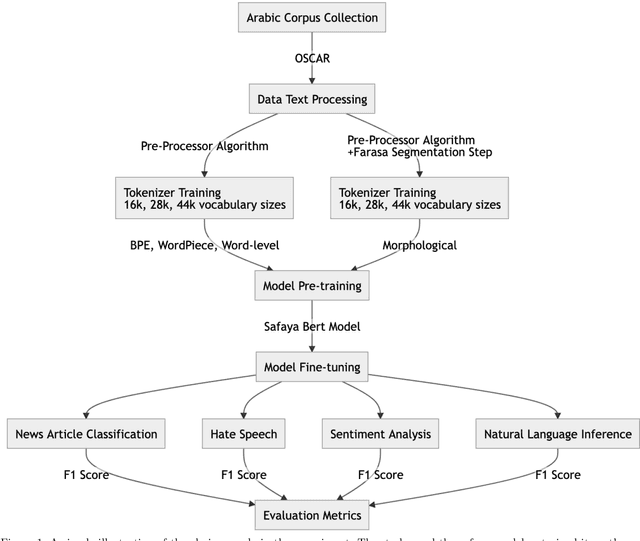
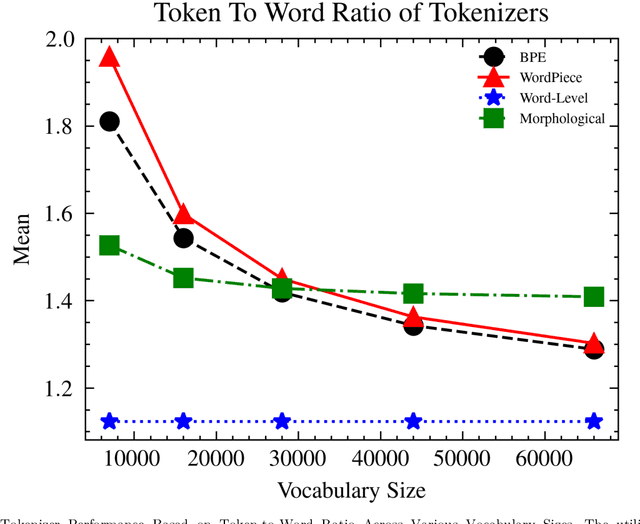
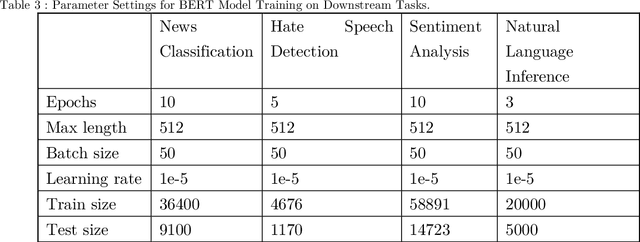
This paper presents a comprehensive examination of the impact of tokenization strategies and vocabulary sizes on the performance of Arabic language models in downstream natural language processing tasks. Our investigation focused on the effectiveness of four tokenizers across various tasks, including News Classification, Hate Speech Detection, Sentiment Analysis, and Natural Language Inference. Leveraging a diverse set of vocabulary sizes, we scrutinize the intricate interplay between tokenization approaches and model performance. The results reveal that Byte Pair Encoding (BPE) with Farasa outperforms other strategies in multiple tasks, underscoring the significance of morphological analysis in capturing the nuances of the Arabic language. However, challenges arise in sentiment analysis, where dialect specific segmentation issues impact model efficiency. Computational efficiency analysis demonstrates the stability of BPE with Farasa, suggesting its practical viability. Our study uncovers limited impacts of vocabulary size on model performance while keeping the model size unchanged. This is challenging the established beliefs about the relationship between vocabulary, model size, and downstream tasks, emphasizing the need for the study of models' size and their corresponding vocabulary size to generalize across domains and mitigate biases, particularly in dialect based datasets. Paper's recommendations include refining tokenization strategies to address dialect challenges, enhancing model robustness across diverse linguistic contexts, and expanding datasets to encompass the rich dialect based Arabic. This work not only advances our understanding of Arabic language models but also lays the foundation for responsible and ethical developments in natural language processing technologies tailored to the intricacies of the Arabic language.
Comparison of Conventional Hybrid and CTC/Attention Decoders for Continuous Visual Speech Recognition
Feb 20, 2024Thanks to the rise of deep learning and the availability of large-scale audio-visual databases, recent advances have been achieved in Visual Speech Recognition (VSR). Similar to other speech processing tasks, these end-to-end VSR systems are usually based on encoder-decoder architectures. While encoders are somewhat general, multiple decoding approaches have been explored, such as the conventional hybrid model based on Deep Neural Networks combined with Hidden Markov Models (DNN-HMM) or the Connectionist Temporal Classification (CTC) paradigm. However, there are languages and tasks in which data is scarce, and in this situation, there is not a clear comparison between different types of decoders. Therefore, we focused our study on how the conventional DNN-HMM decoder and its state-of-the-art CTC/Attention counterpart behave depending on the amount of data used for their estimation. We also analyzed to what extent our visual speech features were able to adapt to scenarios for which they were not explicitly trained, either considering a similar dataset or another collected for a different language. Results showed that the conventional paradigm reached recognition rates that improve the CTC/Attention model in data-scarcity scenarios along with a reduced training time and fewer parameters.
MobileSpeech: A Fast and High-Fidelity Framework for Mobile Zero-Shot Text-to-Speech
Feb 14, 2024Zero-shot text-to-speech (TTS) has gained significant attention due to its powerful voice cloning capabilities, requiring only a few seconds of unseen speaker voice prompts. However, all previous work has been developed for cloud-based systems. Taking autoregressive models as an example, although these approaches achieve high-fidelity voice cloning, they fall short in terms of inference speed, model size, and robustness. Therefore, we propose MobileSpeech, which is a fast, lightweight, and robust zero-shot text-to-speech system based on mobile devices for the first time. Specifically: 1) leveraging discrete codec, we design a parallel speech mask decoder module called SMD, which incorporates hierarchical information from the speech codec and weight mechanisms across different codec layers during the generation process. Moreover, to bridge the gap between text and speech, we introduce a high-level probabilistic mask that simulates the progression of information flow from less to more during speech generation. 2) For speaker prompts, we extract fine-grained prompt duration from the prompt speech and incorporate text, prompt speech by cross attention in SMD. We demonstrate the effectiveness of MobileSpeech on multilingual datasets at different levels, achieving state-of-the-art results in terms of generating speed and speech quality. MobileSpeech achieves RTF of 0.09 on a single A100 GPU and we have successfully deployed MobileSpeech on mobile devices. Audio samples are available at \url{https://mobilespeech.github.io/} .