 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
LEACE: Perfect linear concept erasure in closed form
Jun 23, 2023
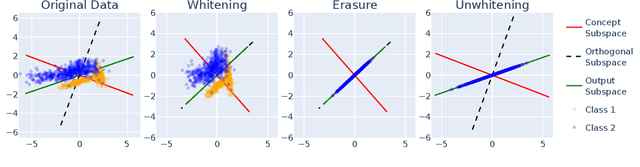
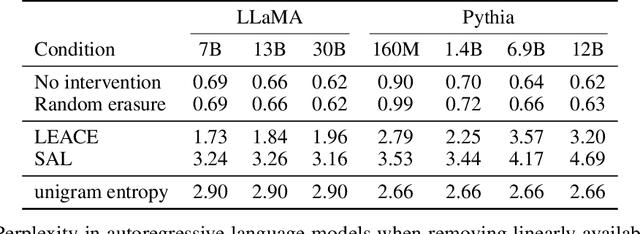
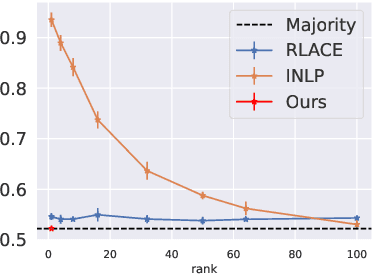
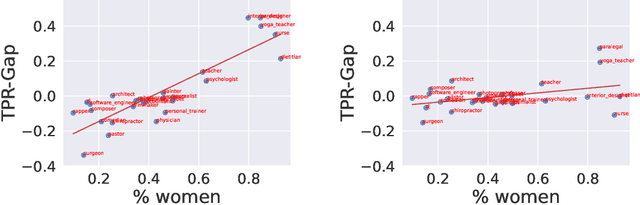
Concept erasure aims to remove specified features from a representation. It can improve fairness (e.g. preventing a classifier from using gender or race) and interpretability (e.g. removing a concept to observe changes in model behavior). We introduce LEAst-squares Concept Erasure (LEACE), a closed-form method which provably prevents all linear classifiers from detecting a concept while changing the representation as little as possible, as measured by a broad class of norms. We apply LEACE to large language models with a novel procedure called "concept scrubbing," which erases target concept information from every layer in the network. We demonstrate our method on two tasks: measuring the reliance of language models on part-of-speech information, and reducing gender bias in BERT embeddings. Code is available at https://github.com/EleutherAI/concept-erasure.
DasFormer: Deep Alternating Spectrogram Transformer for Multi/Single-Channel Speech Separation
Feb 21, 2023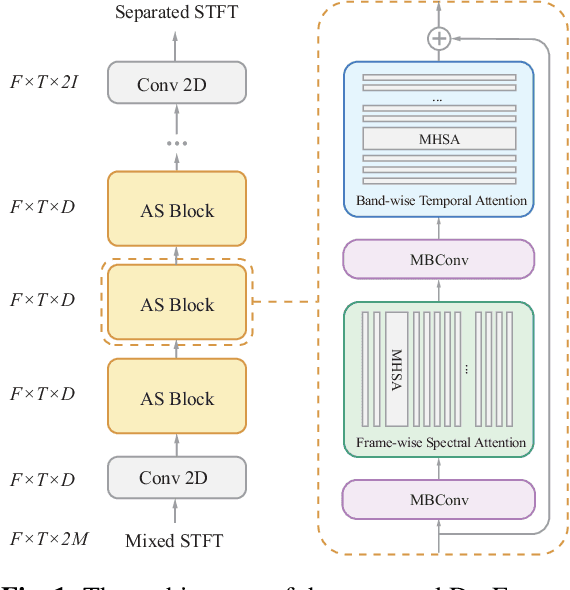
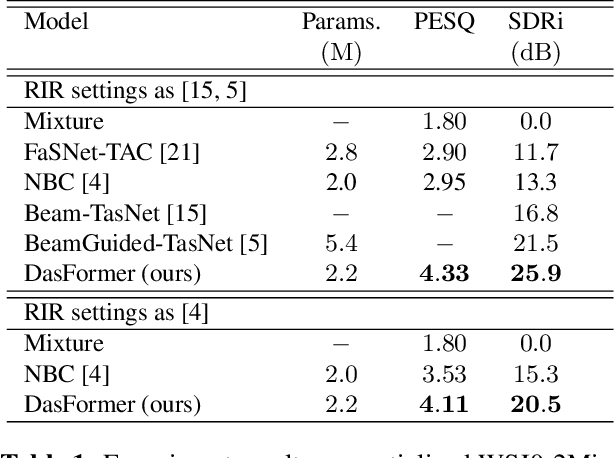
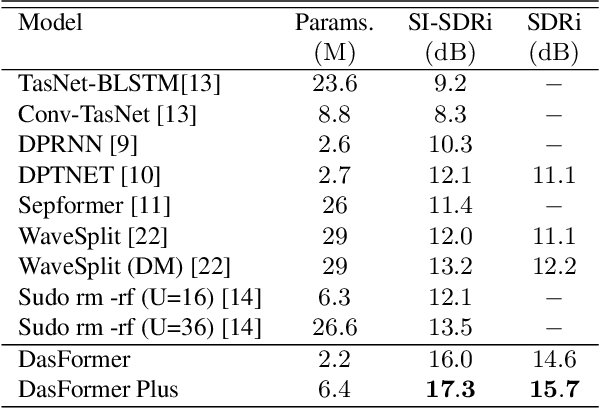
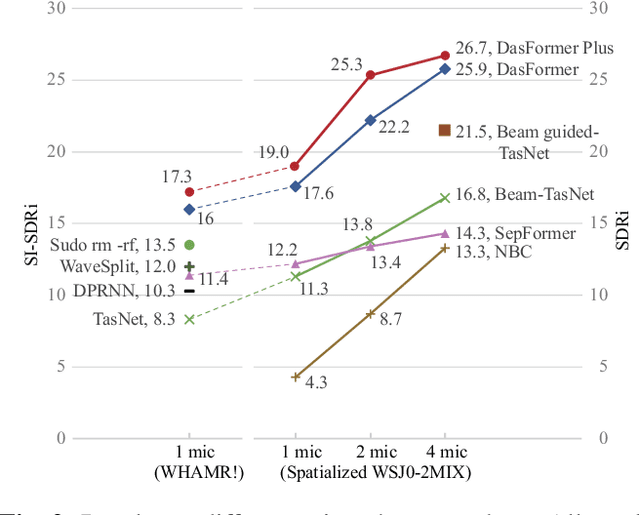
For the task of speech separation, previous study usually treats multi-channel and single-channel scenarios as two research tracks with specialized solutions developed respectively. Instead, we propose a simple and unified architecture - DasFormer (Deep alternating spectrogram transFormer) to handle both of them in the challenging reverberant environments. Unlike frame-wise sequence modeling, each TF-bin in the spectrogram is assigned with an embedding encoding spectral and spatial information. With such input, DasFormer is then formed by multiple repetition of simple blocks each of which integrates 1) two multi-head self-attention (MHSA) modules alternately processing within each frequency bin & temporal frame of the spectrogram 2) MBConv before each MHSA for modeling local features on the spectrogram. Experiments show that DasFormer has a powerful ability to model the time-frequency representation, whose performance far exceeds the current SOTA models in multi-channel speech separation, and also single-channel SOTA in the more challenging yet realistic reverberation scenario.
PAMP: A unified framework boosting low resource automatic speech recognition
Feb 05, 2023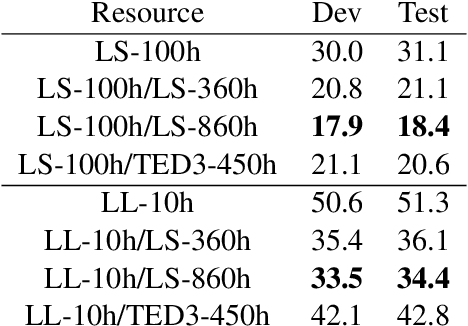
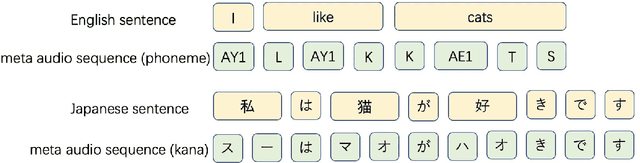
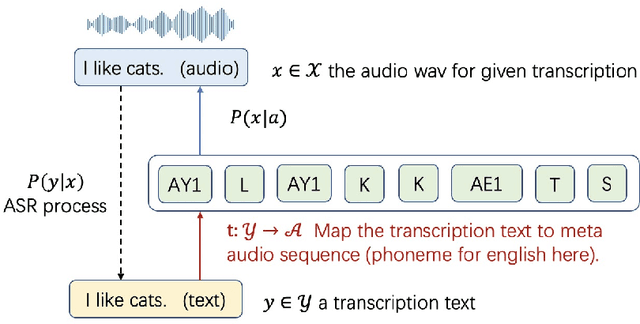
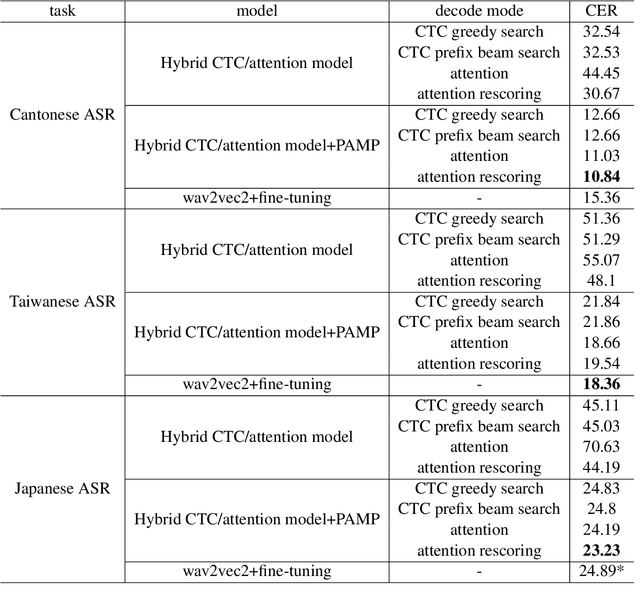
We propose a novel text-to-speech (TTS) data augmentation framework for low resource automatic speech recognition (ASR) tasks, named phoneme audio mix up (PAMP). The PAMP method is highly interpretable and can incorporate prior knowledge of pronunciation rules. Furthermore, PAMP can be easily deployed in almost any language, extremely for low resource ASR tasks. Extensive experiments have demonstrated the great effectiveness of PAMP on low resource ASR tasks: we achieve a \textbf{10.84\%} character error rate (CER) on the common voice Cantonese ASR task, bringing a great relative improvement of about \textbf{30\%} compared to the previous state-of-the-art which was achieved by fine-tuning the wav2vec2 pretrained model.
Voice Conversion With Just Nearest Neighbors
May 30, 2023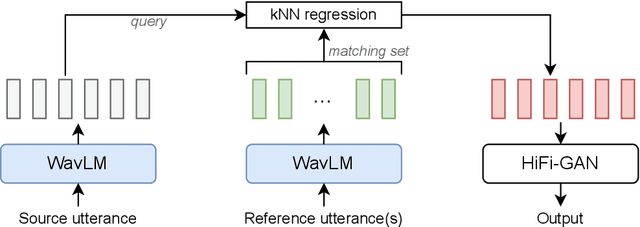
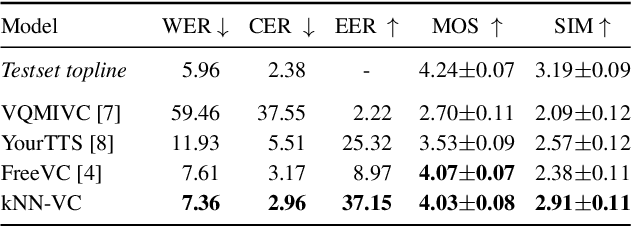
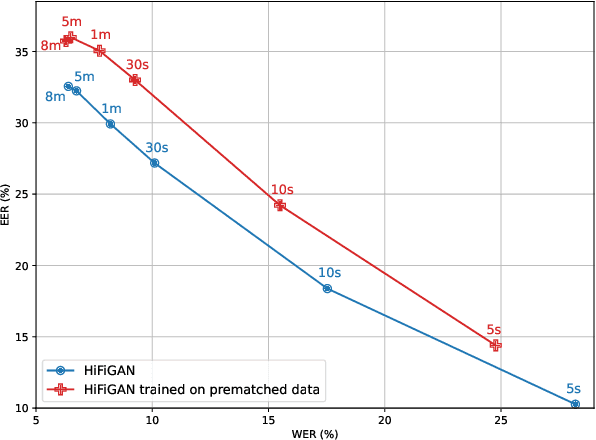
Any-to-any voice conversion aims to transform source speech into a target voice with just a few examples of the target speaker as a reference. Recent methods produce convincing conversions, but at the cost of increased complexity -- making results difficult to reproduce and build on. Instead, we keep it simple. We propose k-nearest neighbors voice conversion (kNN-VC): a straightforward yet effective method for any-to-any conversion. First, we extract self-supervised representations of the source and reference speech. To convert to the target speaker, we replace each frame of the source representation with its nearest neighbor in the reference. Finally, a pretrained vocoder synthesizes audio from the converted representation. Objective and subjective evaluations show that kNN-VC improves speaker similarity with similar intelligibility scores to existing methods. Code, samples, trained models: https://bshall.github.io/knn-vc
A Stutter Seldom Comes Alone -- Cross-Corpus Stuttering Detection as a Multi-label Problem
May 30, 2023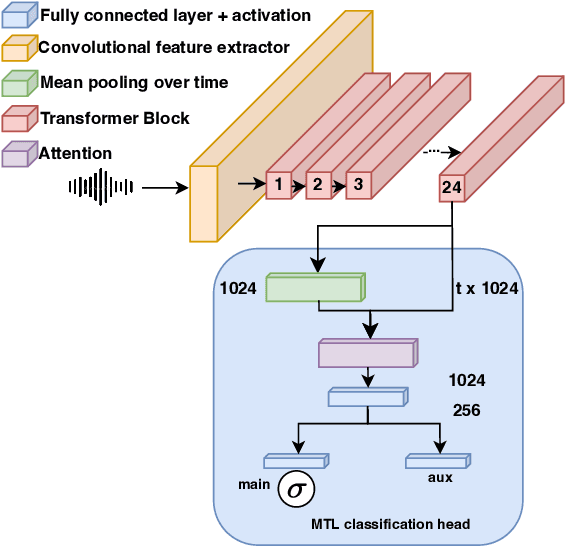
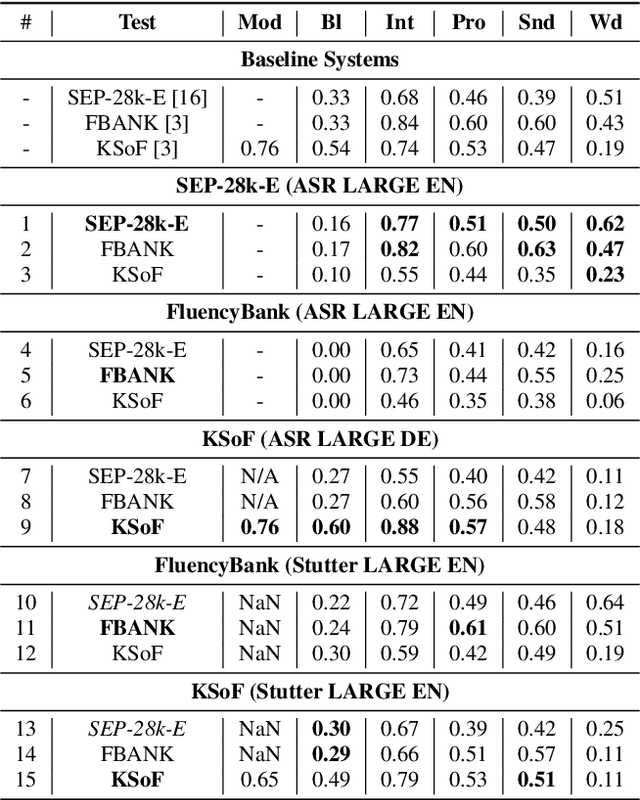
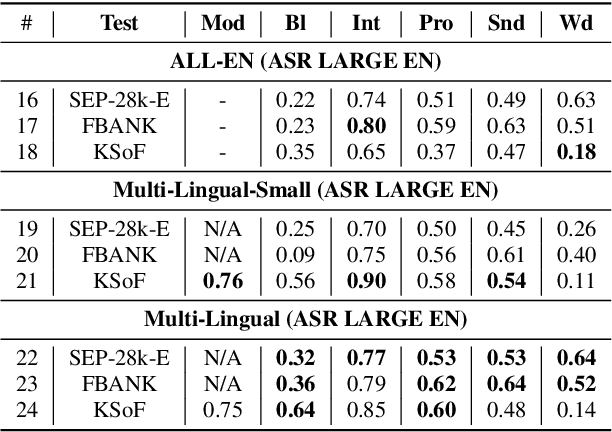
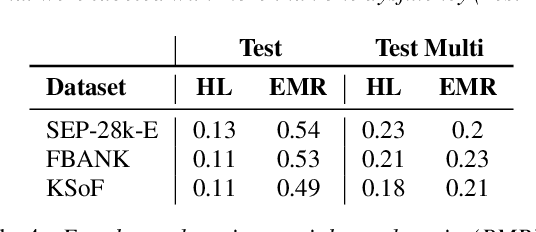
Most stuttering detection and classification research has viewed stuttering as a multi-class classification problem or a binary detection task for each dysfluency type; however, this does not match the nature of stuttering, in which one dysfluency seldom comes alone but rather co-occurs with others. This paper explores multi-language and cross-corpus end-to-end stuttering detection as a multi-label problem using a modified wav2vec 2.0 system with an attention-based classification head and multi-task learning. We evaluate the method using combinations of three datasets containing English and German stuttered speech, one containing speech modified by fluency shaping. The experimental results and an error analysis show that multi-label stuttering detection systems trained on cross-corpus and multi-language data achieve competitive results but performance on samples with multiple labels stays below over-all detection results.
Sharing Low Rank Conformer Weights for Tiny Always-On Ambient Speech Recognition Models
Mar 15, 2023
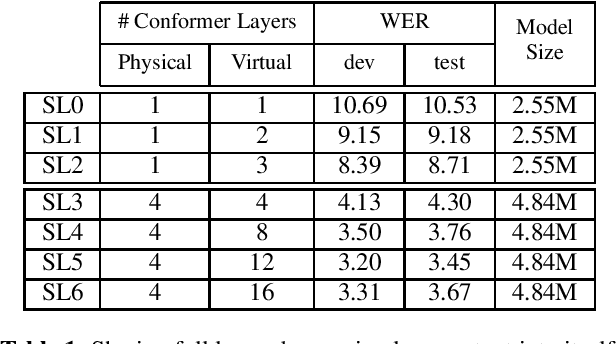

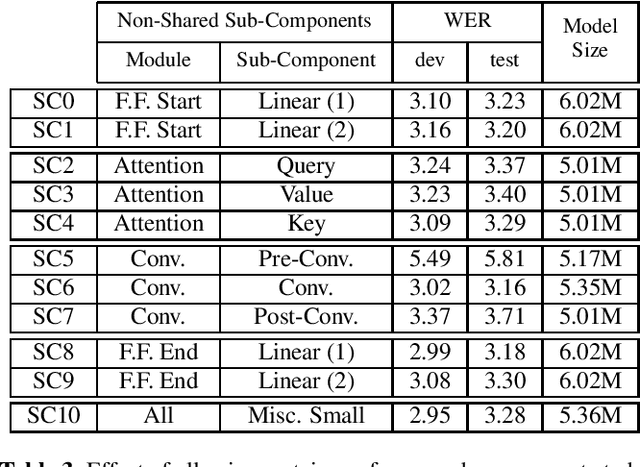
Continued improvements in machine learning techniques offer exciting new opportunities through the use of larger models and larger training datasets. However, there is a growing need to offer these new capabilities on-board low-powered devices such as smartphones, wearables and other embedded environments where only low memory is available. Towards this, we consider methods to reduce the model size of Conformer-based speech recognition models which typically require models with greater than 100M parameters down to just $5$M parameters while minimizing impact on model quality. Such a model allows us to achieve always-on ambient speech recognition on edge devices with low-memory neural processors. We propose model weight reuse at different levels within our model architecture: (i) repeating full conformer block layers, (ii) sharing specific conformer modules across layers, (iii) sharing sub-components per conformer module, and (iv) sharing decomposed sub-component weights after low-rank decomposition. By sharing weights at different levels of our model, we can retain the full model in-memory while increasing the number of virtual transformations applied to the input. Through a series of ablation studies and evaluations, we find that with weight sharing and a low-rank architecture, we can achieve a WER of 2.84 and 2.94 for Librispeech dev-clean and test-clean respectively with a $5$M parameter model.
Designing and Evaluating Speech Emotion Recognition Systems: A reality check case study with IEMOCAP
Apr 03, 2023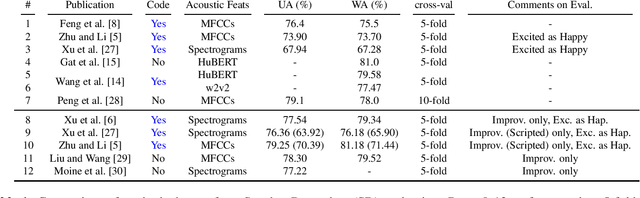

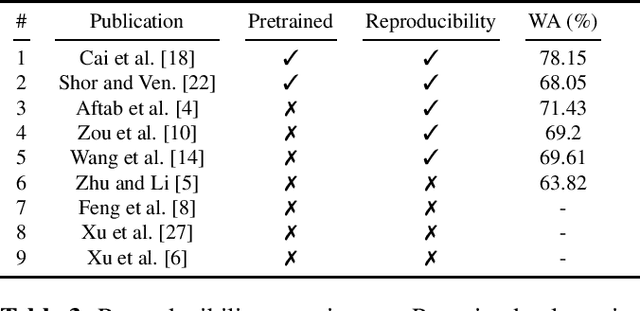
There is an imminent need for guidelines and standard test sets to allow direct and fair comparisons of speech emotion recognition (SER). While resources, such as the Interactive Emotional Dyadic Motion Capture (IEMOCAP) database, have emerged as widely-adopted reference corpora for researchers to develop and test models for SER, published work reveals a wide range of assumptions and variety in its use that challenge reproducibility and generalization. Based on a critical review of the latest advances in SER using IEMOCAP as the use case, our work aims at two contributions: First, using an analysis of the recent literature, including assumptions made and metrics used therein, we provide a set of SER evaluation guidelines. Second, using recent publications with open-sourced implementations, we focus on reproducibility assessment in SER.
UnifySpeech: A Unified Framework for Zero-shot Text-to-Speech and Voice Conversion
Jan 10, 2023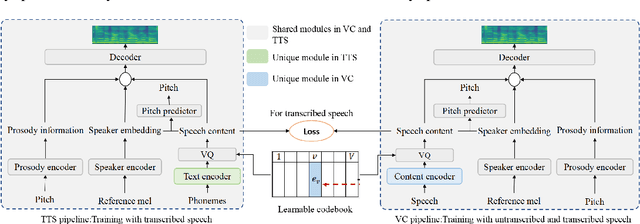

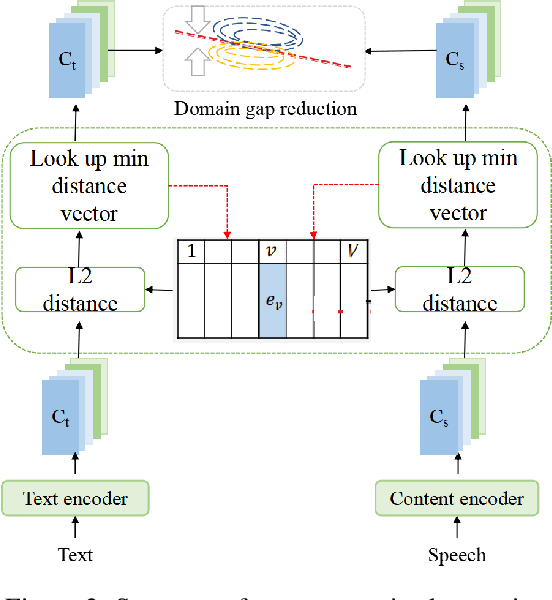
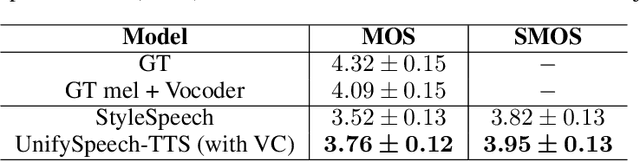
Text-to-speech (TTS) and voice conversion (VC) are two different tasks both aiming at generating high quality speaking voice according to different input modality. Due to their similarity, this paper proposes UnifySpeech, which brings TTS and VC into a unified framework for the first time. The model is based on the assumption that speech can be decoupled into three independent components: content information, speaker information, prosody information. Both TTS and VC can be regarded as mining these three parts of information from the input and completing the reconstruction of speech. For TTS, the speech content information is derived from the text, while in VC it's derived from the source speech, so all the remaining units are shared except for the speech content extraction module in the two tasks. We applied vector quantization and domain constrain to bridge the gap between the content domains of TTS and VC. Objective and subjective evaluation shows that by combining the two task, TTS obtains better speaker modeling ability while VC gets hold of impressive speech content decoupling capability.
Reducing the gap between streaming and non-streaming Transducer-based ASR by adaptive two-stage knowledge distillation
Jun 27, 2023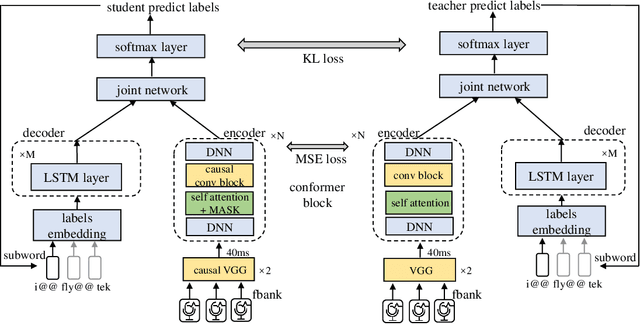
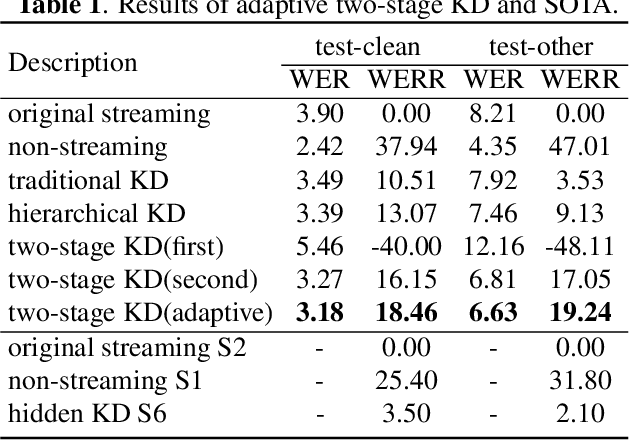
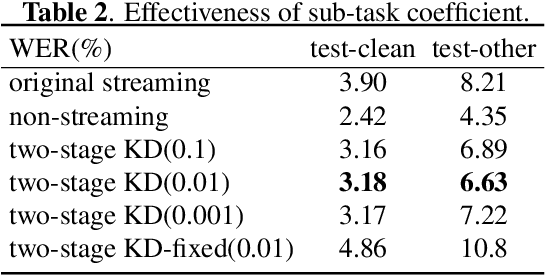
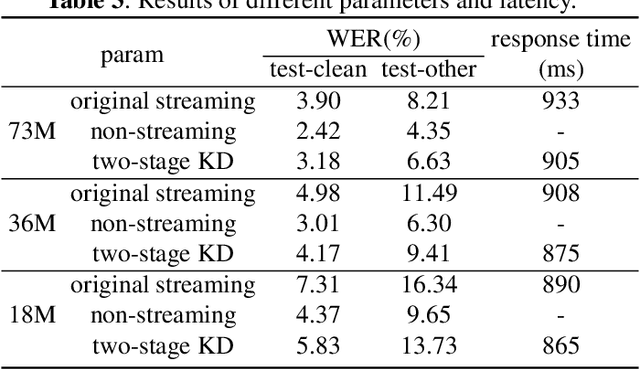
Transducer is one of the mainstream frameworks for streaming speech recognition. There is a performance gap between the streaming and non-streaming transducer models due to limited context. To reduce this gap, an effective way is to ensure that their hidden and output distributions are consistent, which can be achieved by hierarchical knowledge distillation. However, it is difficult to ensure the distribution consistency simultaneously because the learning of the output distribution depends on the hidden one. In this paper, we propose an adaptive two-stage knowledge distillation method consisting of hidden layer learning and output layer learning. In the former stage, we learn hidden representation with full context by applying mean square error loss function. In the latter stage, we design a power transformation based adaptive smoothness method to learn stable output distribution. It achieved 19\% relative reduction in word error rate, and a faster response for the first token compared with the original streaming model in LibriSpeech corpus.
Mingling or Misalignment? Temporal Shift for Speech Emotion Recognition with Pre-trained Representations
Mar 01, 2023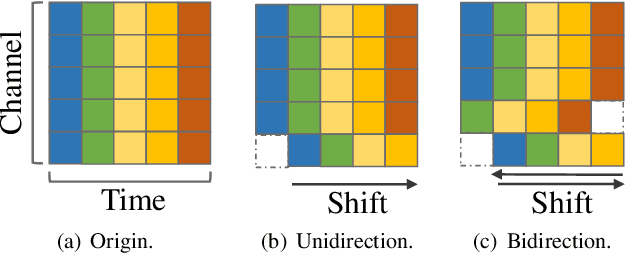
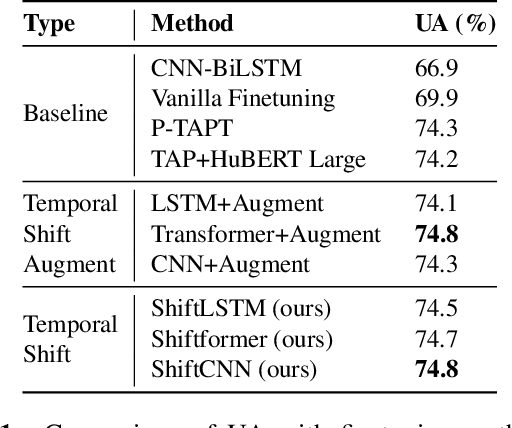
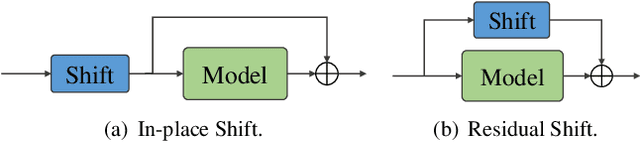
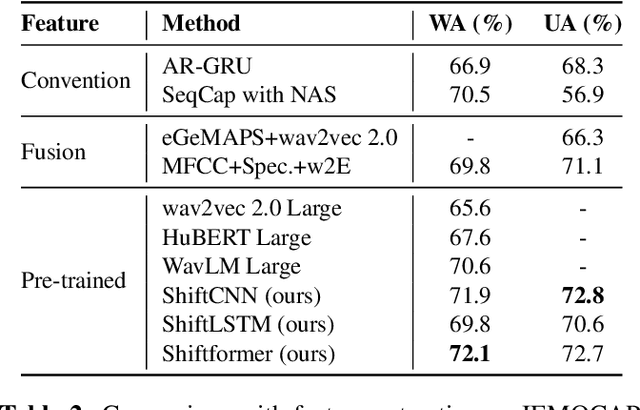
Fueled by recent advances of self-supervised models, pre-trained speech representations proved effective for the downstream speech emotion recognition (SER) task. Most prior works mainly focus on exploiting pre-trained representations and just adopt a linear head on top of the pre-trained model, neglecting the design of the downstream network. In this paper, we propose a temporal shift module to mingle channel-wise information without introducing any parameter or FLOP. With the temporal shift module, three designed baseline building blocks evolve into corresponding shift variants, i.e. ShiftCNN, ShiftLSTM, and Shiftformer. Moreover, to balance the trade-off between mingling and misalignment, we propose two technical strategies, placement of shift and proportion of shift. The family of temporal shift models all outperforms the state-of-the-art methods on the benchmark IEMOCAP dataset under both finetuning and feature extraction settings. Our code is available at https://github.com/ECNU-Cross-Innovation-Lab/ShiftSER.