 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Disentangling Prosody Representations with Unsupervised Speech Reconstruction
Dec 14, 2022
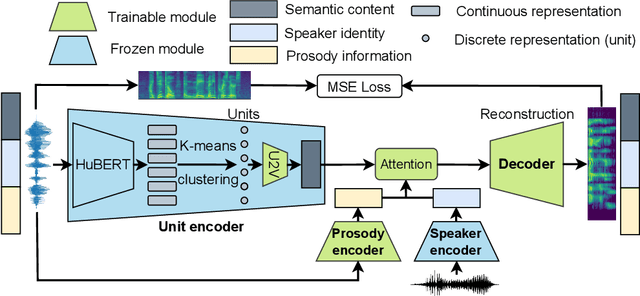
Human speech can be characterized by different components, including semantic content, speaker identity and prosodic information. Significant progress has been made in disentangling representations for semantic content and speaker identity in Automatic Speech Recognition (ASR) and speaker verification tasks respectively. However, it is still an open challenging research question to extract prosodic information because of the intrinsic association of different attributes, such as timbre and rhythm, and because of the need for unsupervised training schemes to achieve robust large-scale and speaker-independent ASR. The aim of this paper is to address the disentanglement of emotional prosody from speech based on unsupervised reconstruction. Specifically, we identify, design, implement and integrate three crucial components in our proposed speech reconstruction model Prosody2Vec: (1) a unit encoder that transforms speech signals into discrete units for semantic content, (2) a pretrained speaker verification model to generate speaker identity embeddings, and (3) a trainable prosody encoder to learn prosody representations. We first pretrain the Prosody2Vec representations on unlabelled emotional speech corpora, then fine-tune the model on specific datasets to perform Speech Emotion Recognition (SER) and Emotional Voice Conversion (EVC) tasks. Both objective and subjective evaluations on the EVC task suggest that Prosody2Vec effectively captures general prosodic features that can be smoothly transferred to other emotional speech. In addition, our SER experiments on the IEMOCAP dataset reveal that the prosody features learned by Prosody2Vec are complementary and beneficial for the performance of widely used speech pretraining models and surpass the state-of-the-art methods when combining Prosody2Vec with HuBERT representations. Some audio samples can be found on our demo website.
LMCodec: A Low Bitrate Speech Codec With Causal Transformer Models
Mar 23, 2023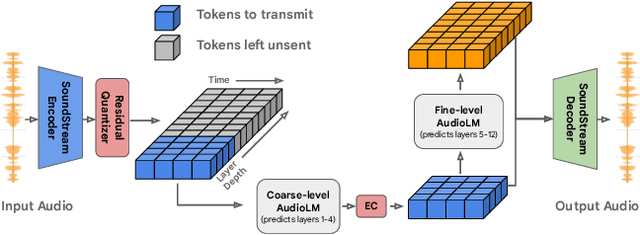
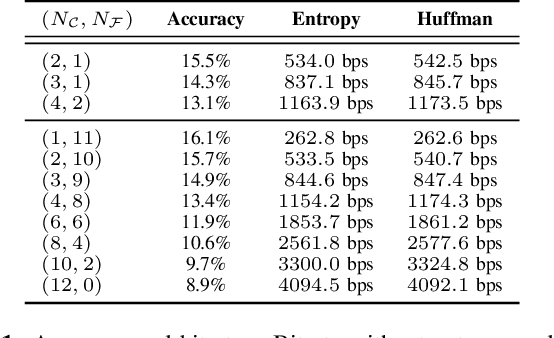
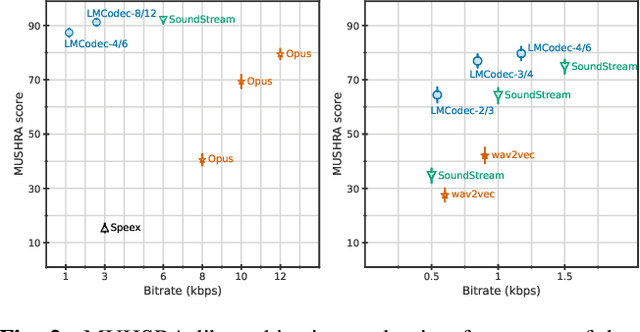
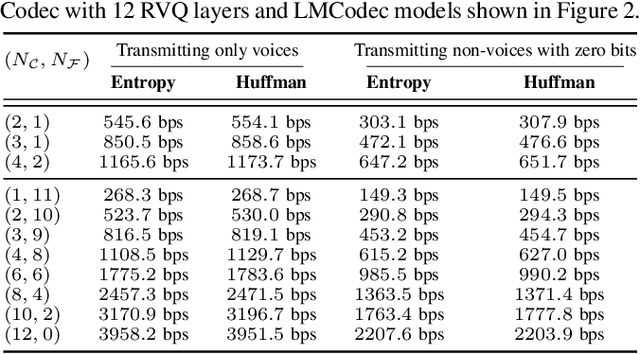
We introduce LMCodec, a causal neural speech codec that provides high quality audio at very low bitrates. The backbone of the system is a causal convolutional codec that encodes audio into a hierarchy of coarse-to-fine tokens using residual vector quantization. LMCodec trains a Transformer language model to predict the fine tokens from the coarse ones in a generative fashion, allowing for the transmission of fewer codes. A second Transformer predicts the uncertainty of the next codes given the past transmitted codes, and is used to perform conditional entropy coding. A MUSHRA subjective test was conducted and shows that the quality is comparable to reference codecs at higher bitrates. Example audio is available at https://mjenrungrot.github.io/chrome-media-audio-papers/publications/lmcodec.
Alzheimer Disease Classification through ASR-based Transcriptions: Exploring the Impact of Punctuation and Pauses
Jun 06, 2023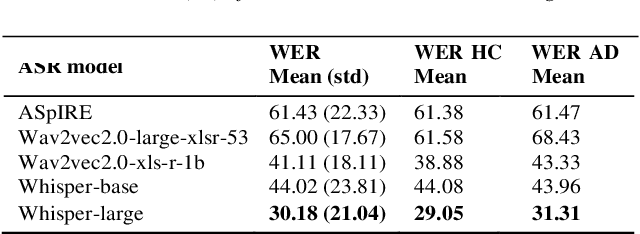
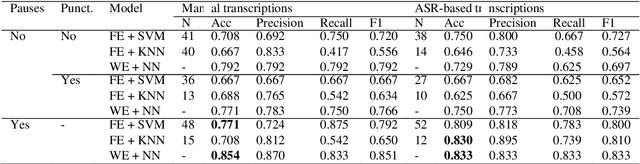
Alzheimer's Disease (AD) is the world's leading neurodegenerative disease, which often results in communication difficulties. Analysing speech can serve as a diagnostic tool for identifying the condition. The recent ADReSS challenge provided a dataset for AD classification and highlighted the utility of manual transcriptions. In this study, we used the new state-of-the-art Automatic Speech Recognition (ASR) model Whisper to obtain the transcriptions, which also include automatic punctuation. The classification models achieved test accuracy scores of 0.854 and 0.833 combining the pretrained FastText word embeddings and recurrent neural networks on manual and ASR transcripts respectively. Additionally, we explored the influence of including pause information and punctuation in the transcriptions. We found that punctuation only yielded minor improvements in some cases, whereas pause encoding aided AD classification for both manual and ASR transcriptions across all approaches investigated.
BuboGPT: Enabling Visual Grounding in Multi-Modal LLMs
Jul 17, 2023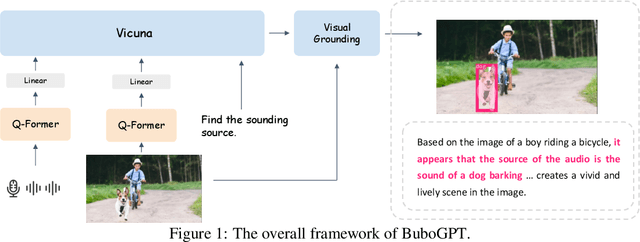

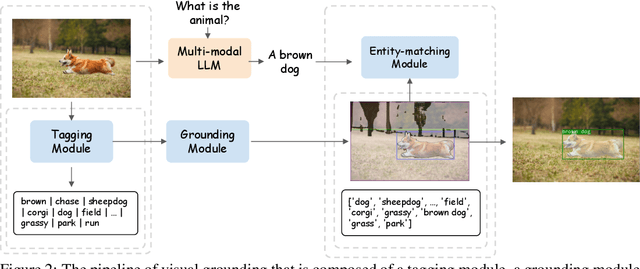
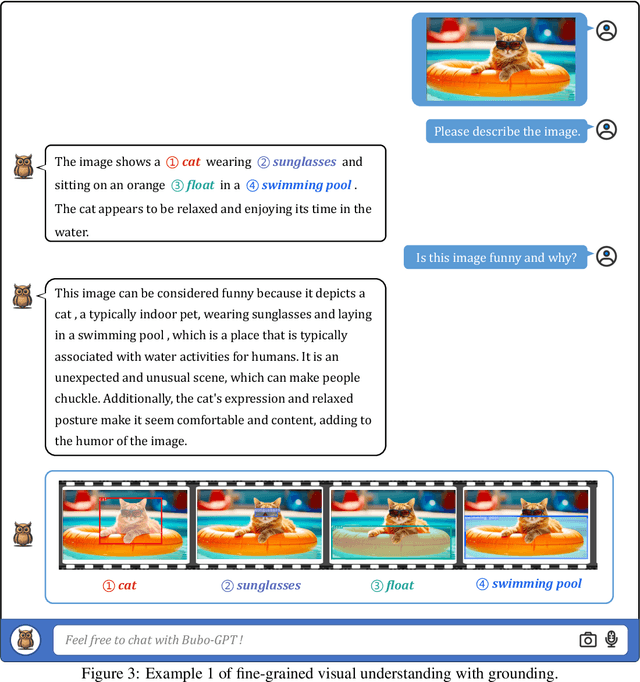
LLMs have demonstrated remarkable abilities at interacting with humans through language, especially with the usage of instruction-following data. Recent advancements in LLMs, such as MiniGPT-4, LLaVA, and X-LLM, further enlarge their abilities by incorporating multi-modal inputs, including image, video, and speech. Despite their effectiveness at generating precise and detailed language understanding of the given modality signal, these LLMs give up the ability to ground specific parts of inputs, thus only constructing a coarse-grained mapping. However, explicit and informative correspondence between text and other modalities will not only improve the user experience but also help to expand the application scenario of multi-modal LLMs. Therefore, we propose BuboGPT, a multi-modal LLM with visual grounding that can perform cross-modal interaction between vision, audio and language, providing fine-grained understanding of visual objects and other given modalities. As a result, BuboGPT is able to point out the specific location of an object in the image, when it is generating response or description for that object. Our contributions are two-fold: 1) An off-the-shelf visual grounding module based on SAM that extracts entities in a sentence and find corresponding masks in the image. 2) A two-stage training scheme and instruction dataset to endow joint text-image-audio understanding. Our experiments show that BuboGPT achieves impressive multi-modality understanding and visual grounding abilities during the interaction with human. It performs consistently well when provided by arbitrary modality combinations (either aligned or unaligned). Our code, model and dataset are available at https://bubo-gpt.github.io .
MAC: A unified framework boosting low resource automatic speech recognition
Feb 15, 2023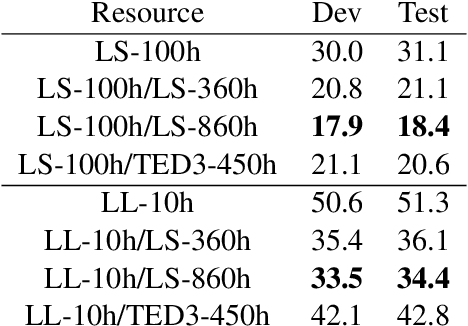
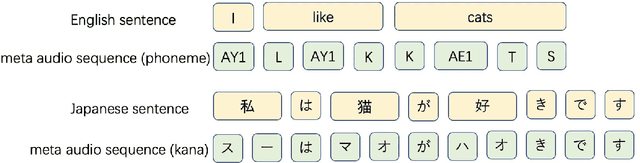
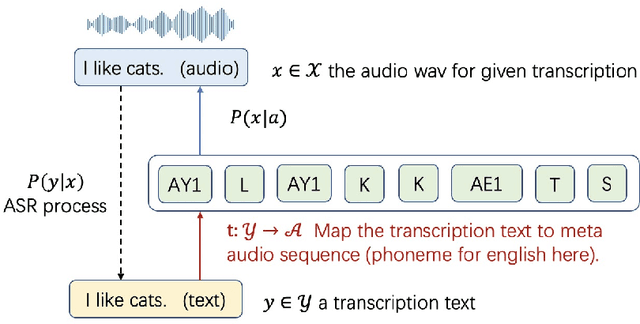
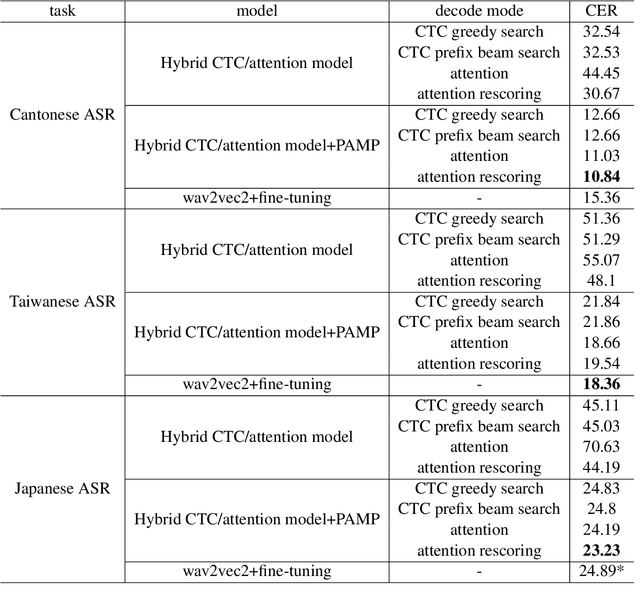
We propose a unified framework for low resource automatic speech recognition tasks named meta audio concatenation (MAC). It is easy to implement and can be carried out in extremely low resource environments. Mathematically, we give a clear description of MAC framework from the perspective of bayesian sampling. In this framework, we leverage a novel concatenative synthesis text-to-speech system to boost the low resource ASR task. By the concatenative synthesis text-to-speech system, we can integrate language pronunciation rules and adjust the TTS process. Furthermore, we propose a broad notion of meta audio set to meet the modeling needs of different languages and different scenes when using the system. Extensive experiments have demonstrated the great effectiveness of MAC on low resource ASR tasks. For CTC greedy search, CTC prefix, attention, and attention rescoring decode mode in Cantonese ASR task, Taiwanese ASR task, and Japanese ASR task the MAC method can reduce the CER by more than 15\%. Furthermore, in the ASR task, MAC beats wav2vec2 (with fine-tuning) on common voice datasets of Cantonese and gets really competitive results on common voice datasets of Taiwanese and Japanese. Among them, it is worth mentioning that we achieve a \textbf{10.9\%} character error rate (CER) on the common voice Cantonese ASR task, bringing about \textbf{30\%} relative improvement compared to the wav2vec2 (with fine-tuning).
On using the UA-Speech and TORGO databases to validate automatic dysarthric speech classification approaches
Nov 16, 2022


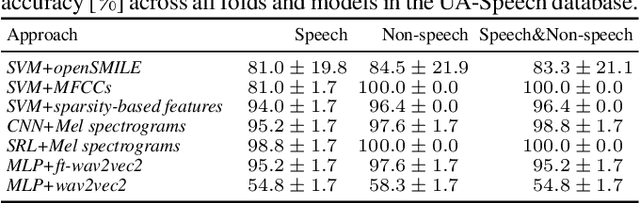
Although the UA-Speech and TORGO databases of control and dysarthric speech are invaluable resources made available to the research community with the objective of developing robust automatic speech recognition systems, they have also been used to validate a considerable number of automatic dysarthric speech classification approaches. Such approaches typically rely on the underlying assumption that recordings from control and dysarthric speakers are collected in the same noiseless environment using the same recording setup. In this paper, we show that this assumption is violated for the UA-Speech and TORGO databases. Using voice activity detection to extract speech and non-speech segments, we show that the majority of state-of-the-art dysarthria classification approaches achieve the same or a considerably better performance when using the non-speech segments of these databases than when using the speech segments. These results demonstrate that such approaches trained and validated on the UA-Speech and TORGO databases are potentially learning characteristics of the recording environment or setup rather than dysarthric speech characteristics. We hope that these results raise awareness in the research community about the importance of the quality of recordings when developing and evaluating automatic dysarthria classification approaches.
Politeness Stereotypes and Attack Vectors: Gender Stereotypes in Japanese and Korean Language Models
Jun 16, 2023
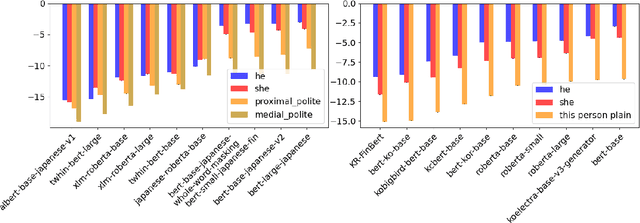
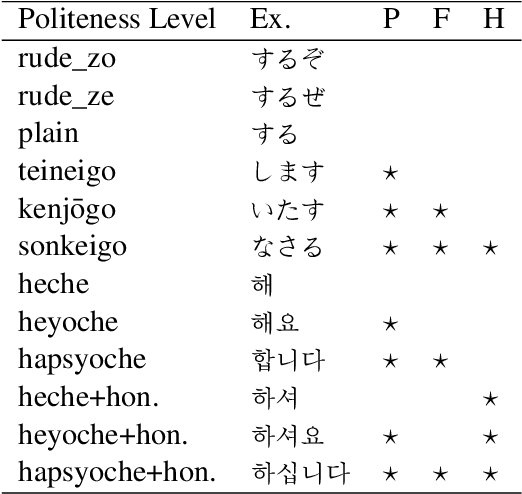
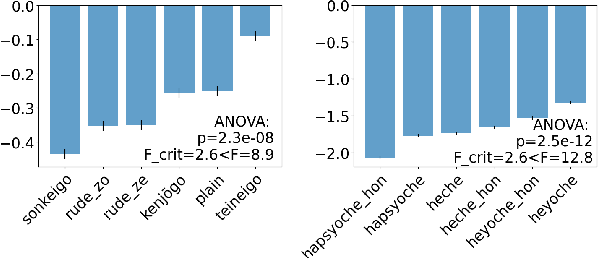
In efforts to keep up with the rapid progress and use of large language models, gender bias research is becoming more prevalent in NLP. Non-English bias research, however, is still in its infancy with most work focusing on English. In our work, we study how grammatical gender bias relating to politeness levels manifests in Japanese and Korean language models. Linguistic studies in these languages have identified a connection between gender bias and politeness levels, however it is not yet known if language models reproduce these biases. We analyze relative prediction probabilities of the male and female grammatical genders using templates and find that informal polite speech is most indicative of the female grammatical gender, while rude and formal speech is most indicative of the male grammatical gender. Further, we find politeness levels to be an attack vector for allocational gender bias in cyberbullying detection models. Cyberbullies can evade detection through simple techniques abusing politeness levels. We introduce an attack dataset to (i) identify representational gender bias across politeness levels, (ii) demonstrate how gender biases can be abused to bypass cyberbullying detection models and (iii) show that allocational biases can be mitigated via training on our proposed dataset. Through our findings we highlight the importance of bias research moving beyond its current English-centrism.
Svarah: Evaluating English ASR Systems on Indian Accents
May 25, 2023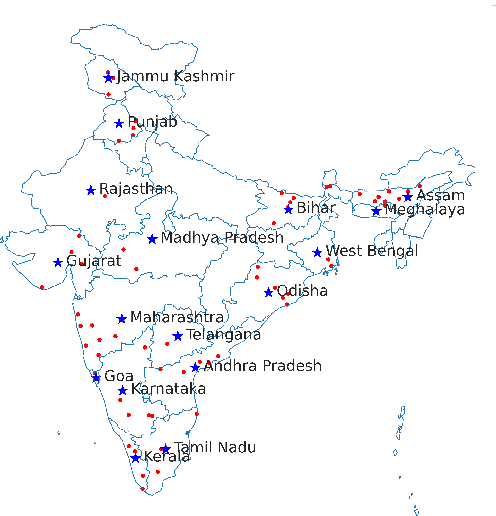
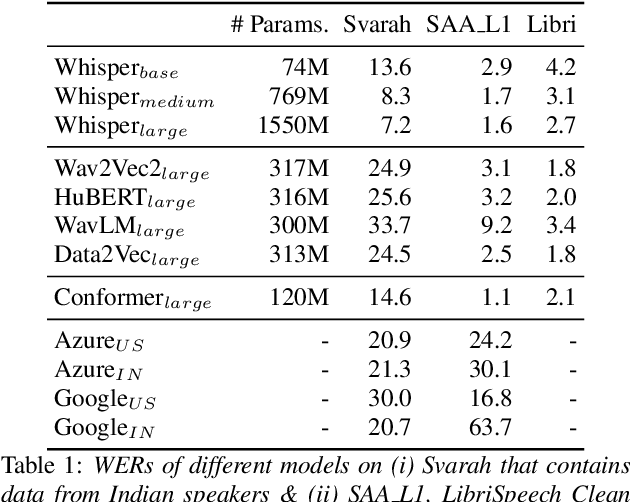
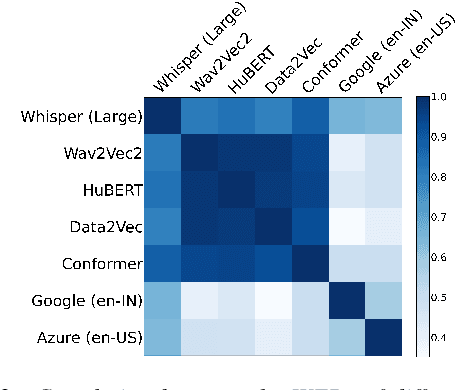
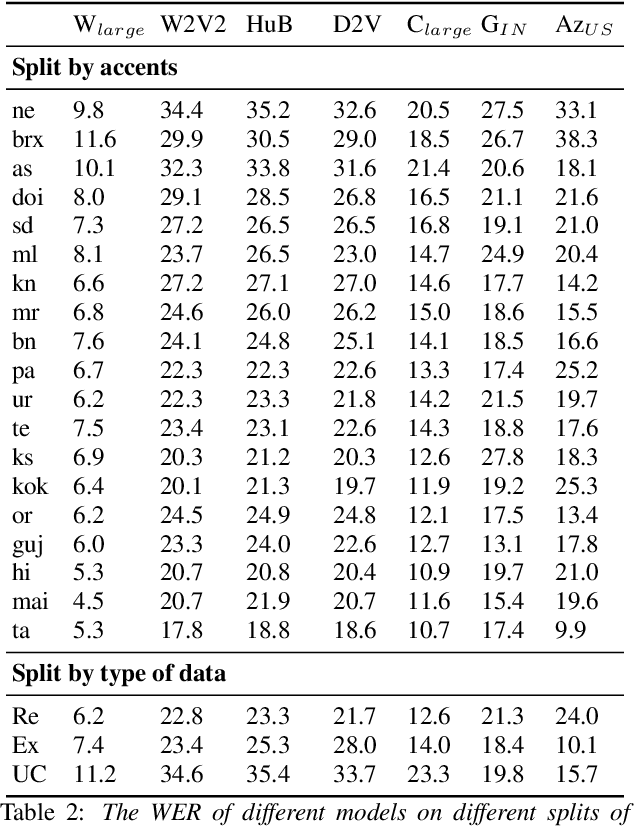
India is the second largest English-speaking country in the world with a speaker base of roughly 130 million. Thus, it is imperative that automatic speech recognition (ASR) systems for English should be evaluated on Indian accents. Unfortunately, Indian speakers find a very poor representation in existing English ASR benchmarks such as LibriSpeech, Switchboard, Speech Accent Archive, etc. In this work, we address this gap by creating Svarah, a benchmark that contains 9.6 hours of transcribed English audio from 117 speakers across 65 geographic locations throughout India, resulting in a diverse range of accents. Svarah comprises both read speech and spontaneous conversational data, covering various domains, such as history, culture, tourism, etc., ensuring a diverse vocabulary. We evaluate 6 open source ASR models and 2 commercial ASR systems on Svarah and show that there is clear scope for improvement on Indian accents. Svarah as well as all our code will be publicly available.
Cellular Network Speech Enhancement: Removing Background and Transmission Noise
Jan 22, 2023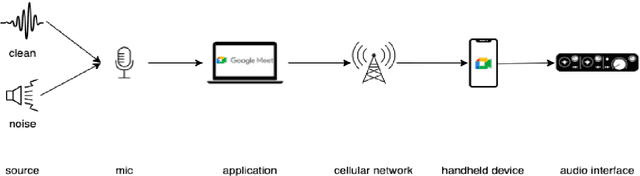
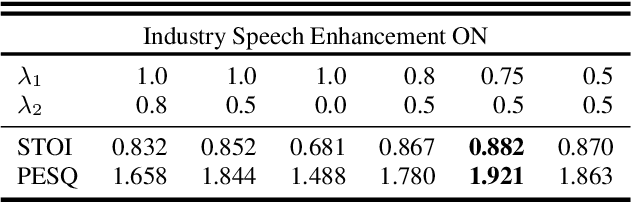
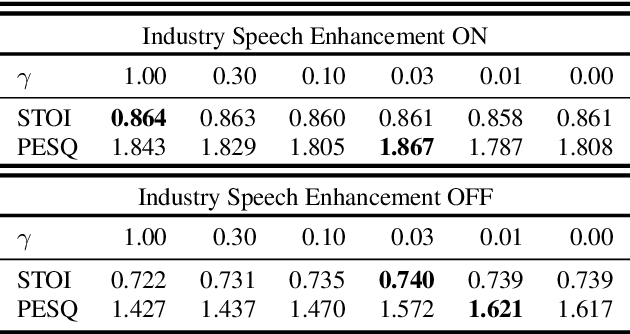
The primary objective of speech enhancement is to reduce background noise while preserving the target's speech. A common dilemma occurs when a speaker is confined to a noisy environment and receives a call with high background and transmission noise. To address this problem, the Deep Noise Suppression (DNS) Challenge focuses on removing the background noise with the next-generation deep learning models to enhance the target's speech; however, researchers fail to consider Voice Over IP (VoIP) applications their transmission noise. Focusing on Google Meet and its cellular application, our work achieves state-of-the-art performance on the Google Meet To Phone Track of the VoIP DNS Challenge. This paper demonstrates how to beat industrial performance and achieve 1.92 PESQ and 0.88 STOI, as well as superior acoustic fidelity, perceptual quality, and intelligibility in various metrics.
On granularity of prosodic representations in expressive text-to-speech
Jan 26, 2023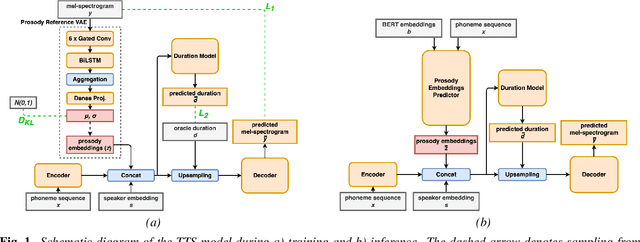
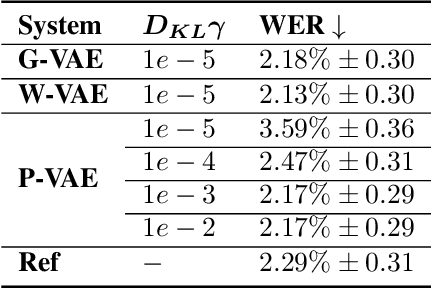
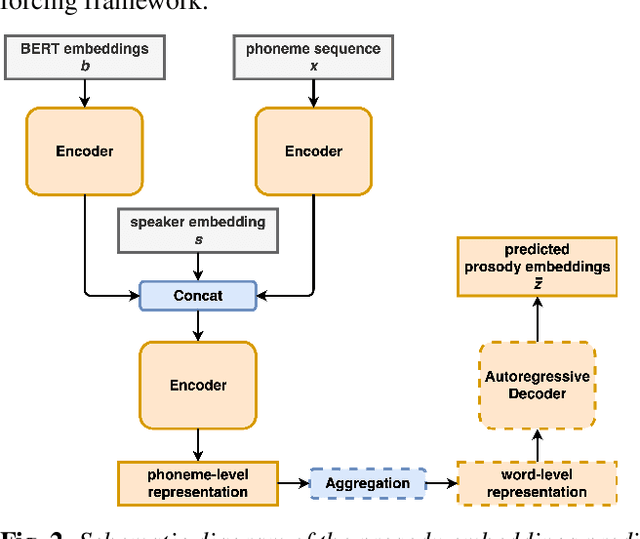

In expressive speech synthesis it is widely adopted to use latent prosody representations to deal with variability of the data during training. Same text may correspond to various acoustic realizations, which is known as a one-to-many mapping problem in text-to-speech. Utterance, word, or phoneme-level representations are extracted from target signal in an auto-encoding setup, to complement phonetic input and simplify that mapping. This paper compares prosodic embeddings at different levels of granularity and examines their prediction from text. We show that utterance-level embeddings have insufficient capacity and phoneme-level tend to introduce instabilities when predicted from text. Word-level representations impose balance between capacity and predictability. As a result, we close the gap in naturalness by 90% between synthetic speech and recordings on LibriTTS dataset, without sacrificing intelligibility.