 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Towards Model-Size Agnostic, Compute-Free, Memorization-based Inference of Deep Learning
Jul 14, 2023
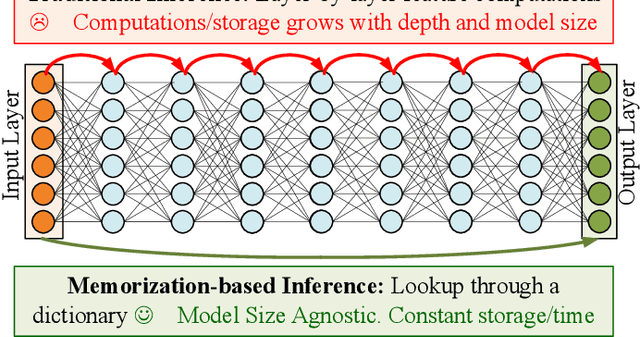
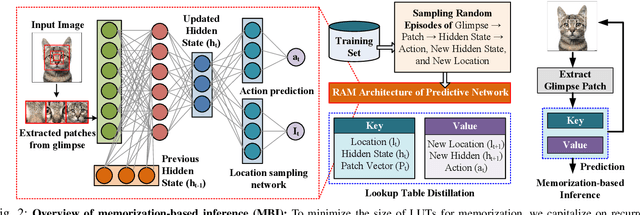
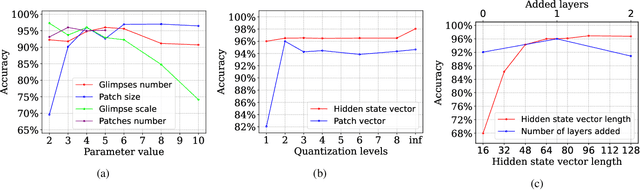
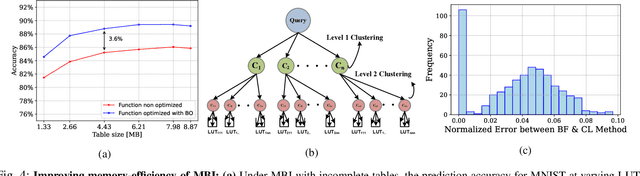
The rapid advancement of deep neural networks has significantly improved various tasks, such as image and speech recognition. However, as the complexity of these models increases, so does the computational cost and the number of parameters, making it difficult to deploy them on resource-constrained devices. This paper proposes a novel memorization-based inference (MBI) that is compute free and only requires lookups. Specifically, our work capitalizes on the inference mechanism of the recurrent attention model (RAM), where only a small window of input domain (glimpse) is processed in a one time step, and the outputs from multiple glimpses are combined through a hidden vector to determine the overall classification output of the problem. By leveraging the low-dimensionality of glimpse, our inference procedure stores key value pairs comprising of glimpse location, patch vector, etc. in a table. The computations are obviated during inference by utilizing the table to read out key-value pairs and performing compute-free inference by memorization. By exploiting Bayesian optimization and clustering, the necessary lookups are reduced, and accuracy is improved. We also present in-memory computing circuits to quickly look up the matching key vector to an input query. Compared to competitive compute-in-memory (CIM) approaches, MBI improves energy efficiency by almost 2.7 times than multilayer perceptions (MLP)-CIM and by almost 83 times than ResNet20-CIM for MNIST character recognition.
RobustDistiller: Compressing Universal Speech Representations for Enhanced Environment Robustness
Feb 18, 2023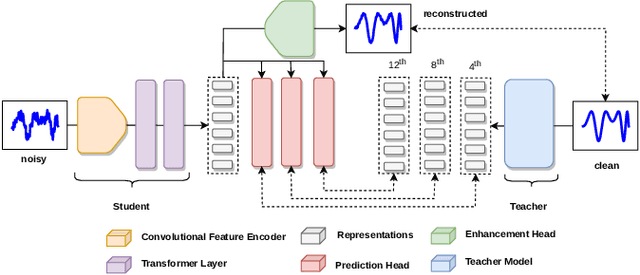
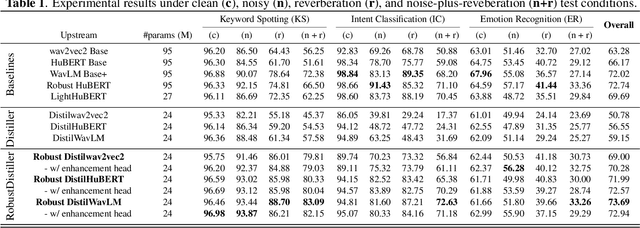
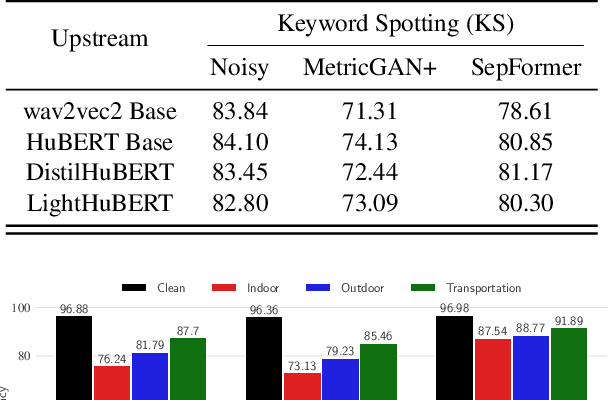

Self-supervised speech pre-training enables deep neural network models to capture meaningful and disentangled factors from raw waveform signals. The learned universal speech representations can then be used across numerous downstream tasks. These representations, however, are sensitive to distribution shifts caused by environmental factors, such as noise and/or room reverberation. Their large sizes, in turn, make them unfeasible for edge applications. In this work, we propose a knowledge distillation methodology termed RobustDistiller which compresses universal representations while making them more robust against environmental artifacts via a multi-task learning objective. The proposed layer-wise distillation recipe is evaluated on top of three well-established universal representations, as well as with three downstream tasks. Experimental results show the proposed methodology applied on top of the WavLM Base+ teacher model outperforming all other benchmarks across noise types and levels, as well as reverberation times. Oftentimes, the obtained results with the student model (24M parameters) achieved results inline with those of the teacher model (95M).
UnitY: Two-pass Direct Speech-to-speech Translation with Discrete Units
Dec 15, 2022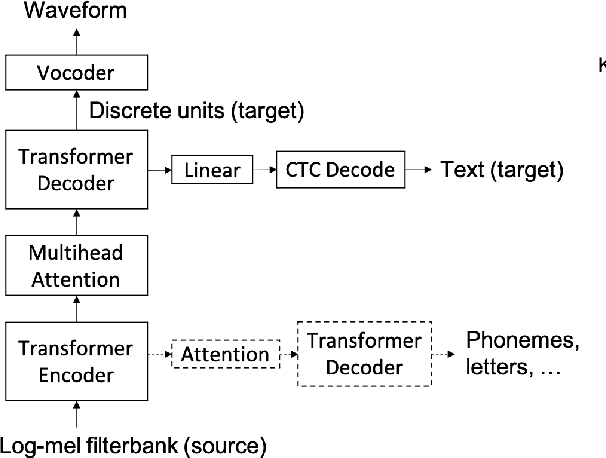
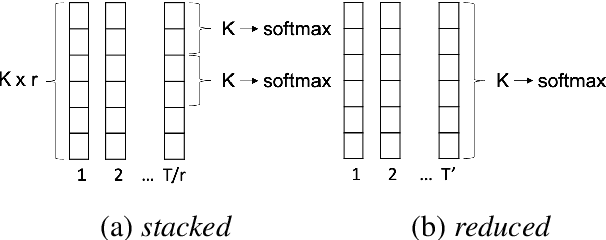
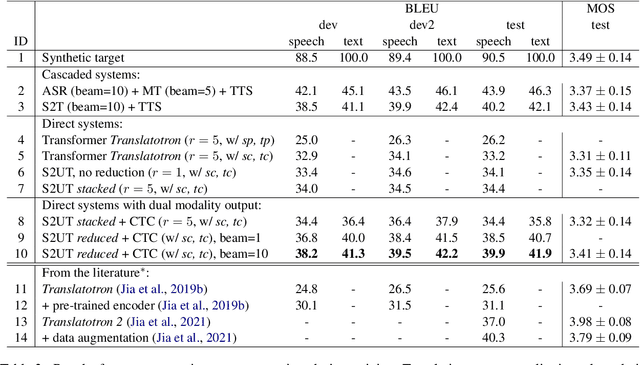
Direct speech-to-speech translation (S2ST), in which all components can be optimized jointly, is advantageous over cascaded approaches to achieve fast inference with a simplified pipeline. We present a novel two-pass direct S2ST architecture, {\textit UnitY}, which first generates textual representations and predicts discrete acoustic units subsequently. We enhance the model performance by subword prediction in the first-pass decoder, advanced two-pass decoder architecture design and search strategy, and better training regularization. To leverage large amounts of unlabeled text data, we pre-train the first-pass text decoder based on the self-supervised denoising auto-encoding task. Experimental evaluations on benchmark datasets at various data scales demonstrate that UnitY outperforms a single-pass speech-to-unit translation model by 2.5-4.2 ASR-BLEU with 2.83x decoding speed-up. We show that the proposed methods boost the performance even when predicting spectrogram in the second pass. However, predicting discrete units achieves 2.51x decoding speed-up compared to that case.
Dialog act guided contextual adapter for personalized speech recognition
Mar 31, 2023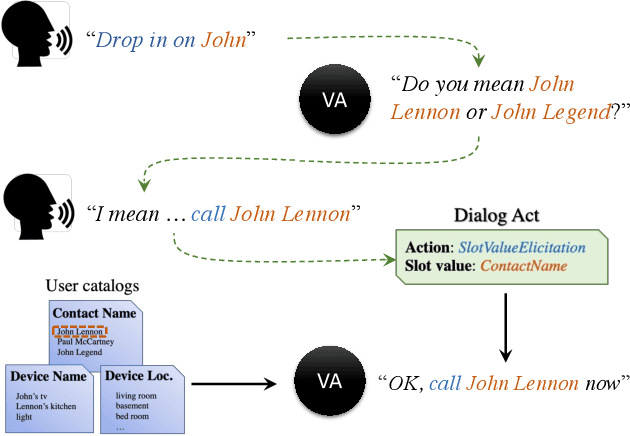
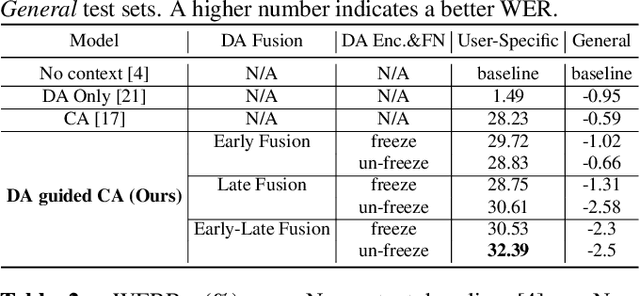
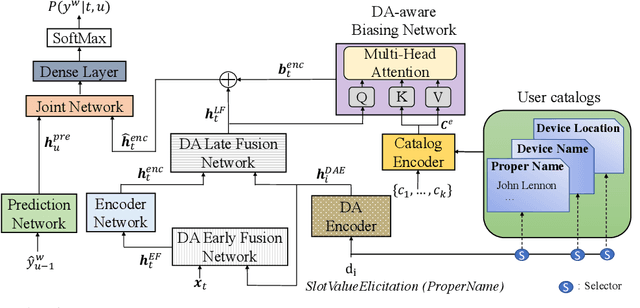

Personalization in multi-turn dialogs has been a long standing challenge for end-to-end automatic speech recognition (E2E ASR) models. Recent work on contextual adapters has tackled rare word recognition using user catalogs. This adaptation, however, does not incorporate an important cue, the dialog act, which is available in a multi-turn dialog scenario. In this work, we propose a dialog act guided contextual adapter network. Specifically, it leverages dialog acts to select the most relevant user catalogs and creates queries based on both -- the audio as well as the semantic relationship between the carrier phrase and user catalogs to better guide the contextual biasing. On industrial voice assistant datasets, our model outperforms both the baselines - dialog act encoder-only model, and the contextual adaptation, leading to the most improvement over the no-context model: 58% average relative word error rate reduction (WERR) in the multi-turn dialog scenario, in comparison to the prior-art contextual adapter, which has achieved 39% WERR over the no-context model.
Audio-Driven Co-Speech Gesture Video Generation
Dec 05, 2022
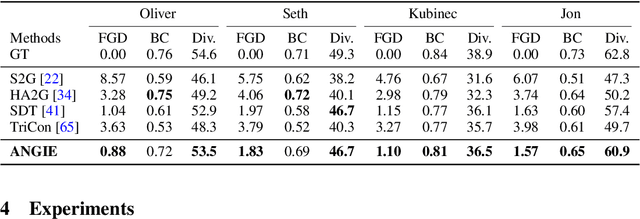
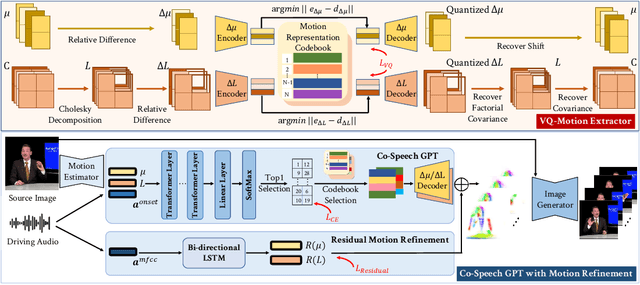
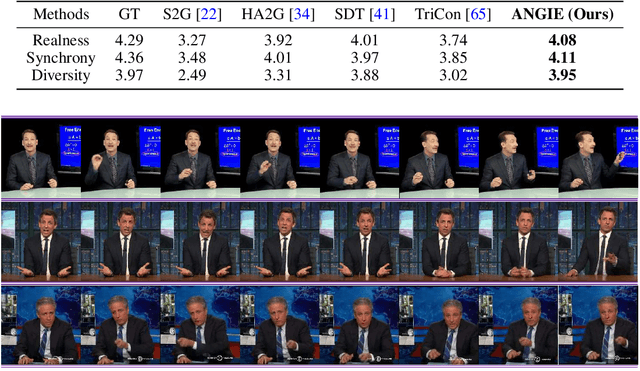
Co-speech gesture is crucial for human-machine interaction and digital entertainment. While previous works mostly map speech audio to human skeletons (e.g., 2D keypoints), directly generating speakers' gestures in the image domain remains unsolved. In this work, we formally define and study this challenging problem of audio-driven co-speech gesture video generation, i.e., using a unified framework to generate speaker image sequence driven by speech audio. Our key insight is that the co-speech gestures can be decomposed into common motion patterns and subtle rhythmic dynamics. To this end, we propose a novel framework, Audio-driveN Gesture vIdeo gEneration (ANGIE), to effectively capture the reusable co-speech gesture patterns as well as fine-grained rhythmic movements. To achieve high-fidelity image sequence generation, we leverage an unsupervised motion representation instead of a structural human body prior (e.g., 2D skeletons). Specifically, 1) we propose a vector quantized motion extractor (VQ-Motion Extractor) to summarize common co-speech gesture patterns from implicit motion representation to codebooks. 2) Moreover, a co-speech gesture GPT with motion refinement (Co-Speech GPT) is devised to complement the subtle prosodic motion details. Extensive experiments demonstrate that our framework renders realistic and vivid co-speech gesture video. Demo video and more resources can be found in: https://alvinliu0.github.io/projects/ANGIE
BIG-C: a Multimodal Multi-Purpose Dataset for Bemba
May 26, 2023
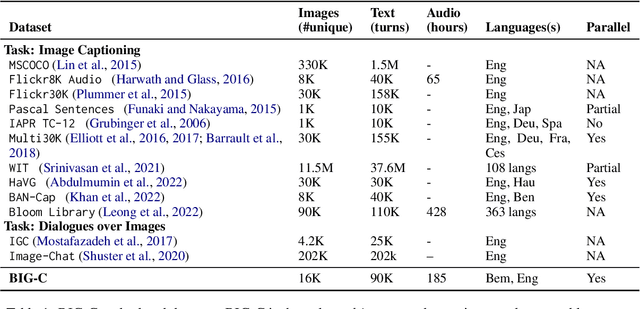
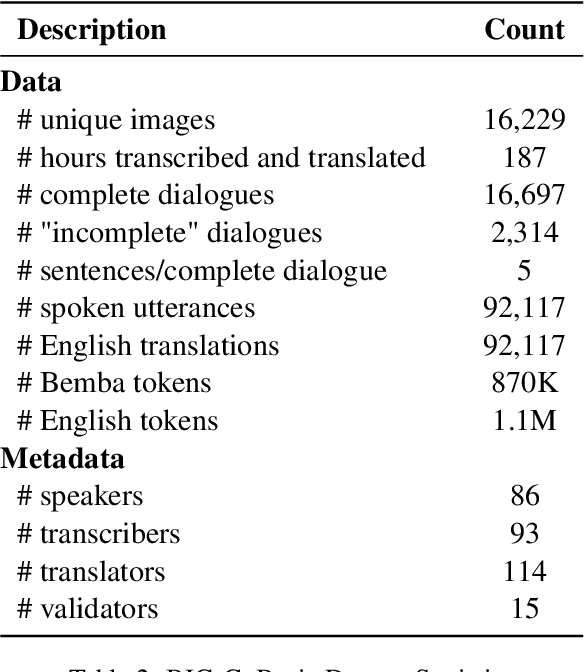

We present BIG-C (Bemba Image Grounded Conversations), a large multimodal dataset for Bemba. While Bemba is the most populous language of Zambia, it exhibits a dearth of resources which render the development of language technologies or language processing research almost impossible. The dataset is comprised of multi-turn dialogues between Bemba speakers based on images, transcribed and translated into English. There are more than 92,000 utterances/sentences, amounting to more than 180 hours of audio data with corresponding transcriptions and English translations. We also provide baselines on speech recognition (ASR), machine translation (MT) and speech translation (ST) tasks, and sketch out other potential future multimodal uses of our dataset. We hope that by making the dataset available to the research community, this work will foster research and encourage collaboration across the language, speech, and vision communities especially for languages outside the "traditionally" used high-resourced ones. All data and code are publicly available: https://github.com/csikasote/bigc.
Robustness of Multi-Source MT to Transcription Errors
May 26, 2023
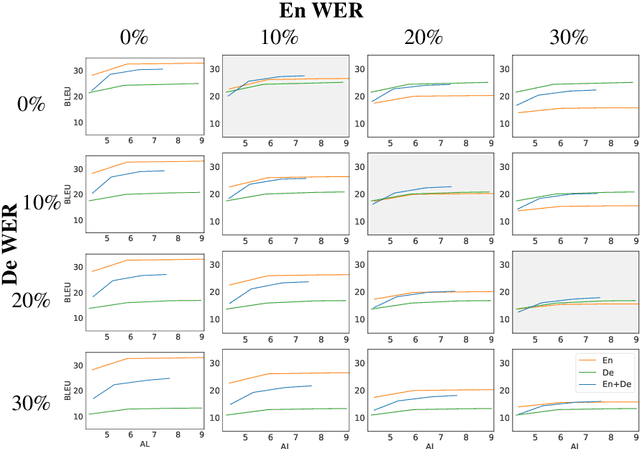

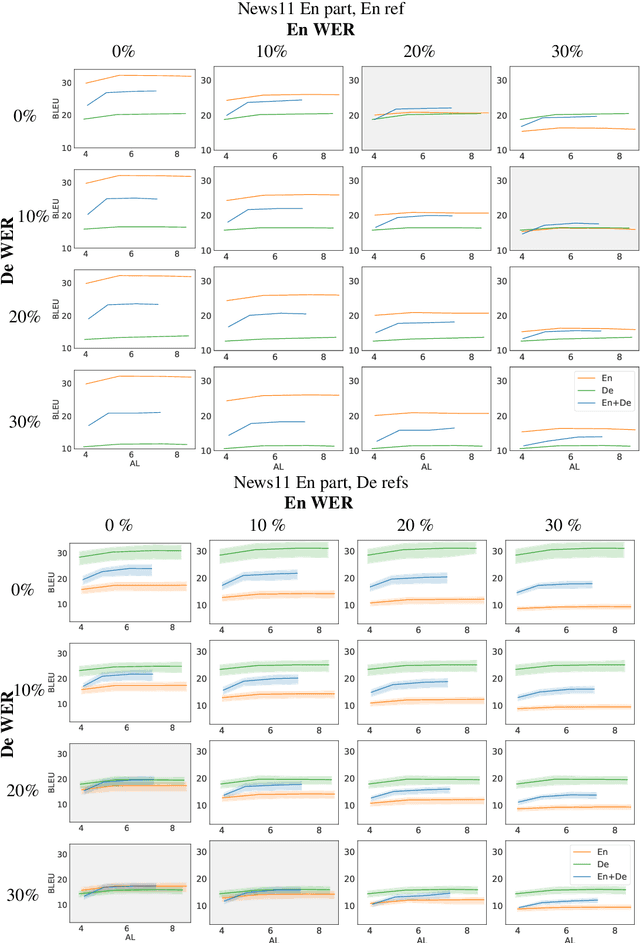
Automatic speech translation is sensitive to speech recognition errors, but in a multilingual scenario, the same content may be available in various languages via simultaneous interpreting, dubbing or subtitling. In this paper, we hypothesize that leveraging multiple sources will improve translation quality if the sources complement one another in terms of correct information they contain. To this end, we first show that on a 10-hour ESIC corpus, the ASR errors in the original English speech and its simultaneous interpreting into German and Czech are mutually independent. We then use two sources, English and German, in a multi-source setting for translation into Czech to establish its robustness to ASR errors. Furthermore, we observe this robustness when translating both noisy sources together in a simultaneous translation setting. Our results show that multi-source neural machine translation has the potential to be useful in a real-time simultaneous translation setting, thereby motivating further investigation in this area.
LyricWhiz: Robust Multilingual Zero-shot Lyrics Transcription by Whispering to ChatGPT
Jul 07, 2023

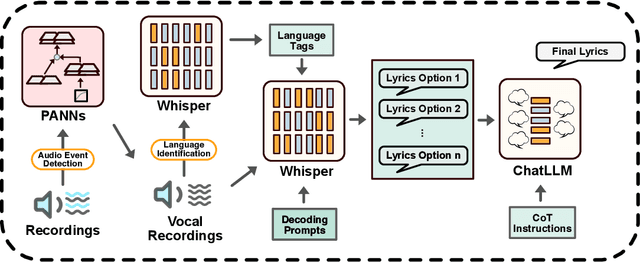
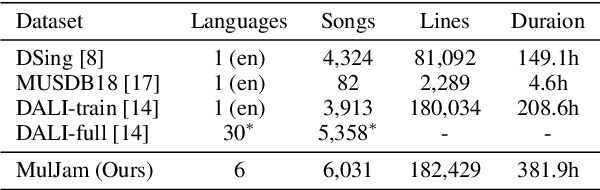
We introduce LyricWhiz, a robust, multilingual, and zero-shot automatic lyrics transcription method achieving state-of-the-art performance on various lyrics transcription datasets, even in challenging genres such as rock and metal. Our novel, training-free approach utilizes Whisper, a weakly supervised robust speech recognition model, and GPT-4, today's most performant chat-based large language model. In the proposed method, Whisper functions as the "ear" by transcribing the audio, while GPT-4 serves as the "brain," acting as an annotator with a strong performance for contextualized output selection and correction. Our experiments show that LyricWhiz significantly reduces Word Error Rate compared to existing methods in English and can effectively transcribe lyrics across multiple languages. Furthermore, we use LyricWhiz to create the first publicly available, large-scale, multilingual lyrics transcription dataset with a CC-BY-NC-SA copyright license, based on MTG-Jamendo, and offer a human-annotated subset for noise level estimation and evaluation. We anticipate that our proposed method and dataset will advance the development of multilingual lyrics transcription, a challenging and emerging task.
Multilingual Contextual Adapters To Improve Custom Word Recognition In Low-resource Languages
Jul 03, 2023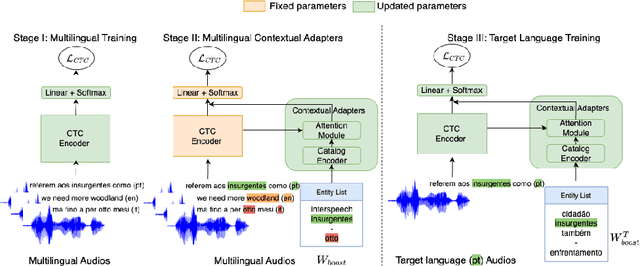
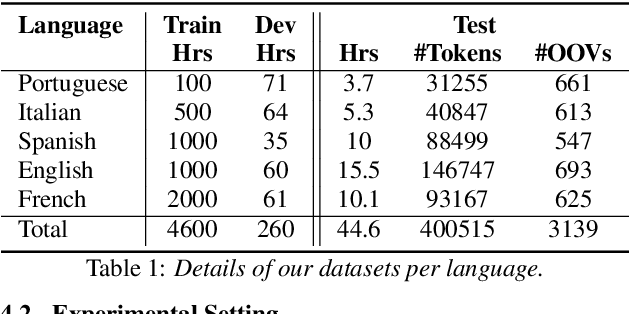
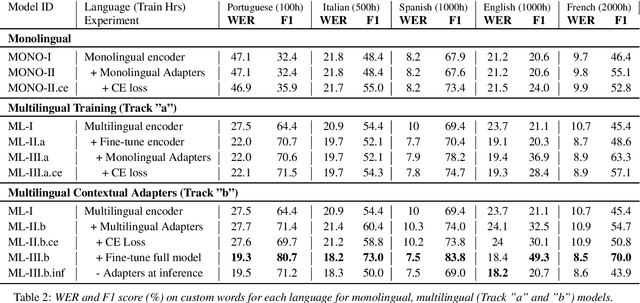
Connectionist Temporal Classification (CTC) models are popular for their balance between speed and performance for Automatic Speech Recognition (ASR). However, these CTC models still struggle in other areas, such as personalization towards custom words. A recent approach explores Contextual Adapters, wherein an attention-based biasing model for CTC is used to improve the recognition of custom entities. While this approach works well with enough data, we showcase that it isn't an effective strategy for low-resource languages. In this work, we propose a supervision loss for smoother training of the Contextual Adapters. Further, we explore a multilingual strategy to improve performance with limited training data. Our method achieves 48% F1 improvement in retrieving unseen custom entities for a low-resource language. Interestingly, as a by-product of training the Contextual Adapters, we see a 5-11% Word Error Rate (WER) reduction in the performance of the base CTC model as well.
Dual-Attention Neural Transducers for Efficient Wake Word Spotting in Speech Recognition
Apr 03, 2023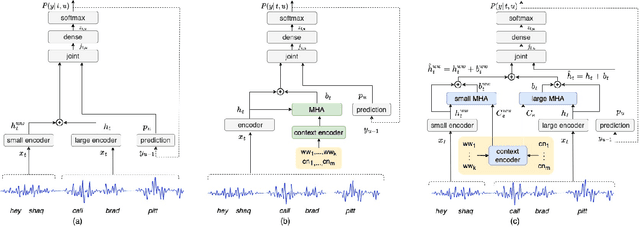
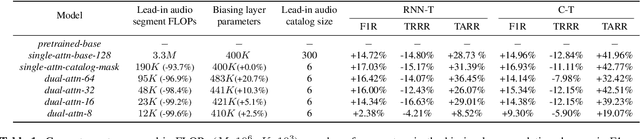
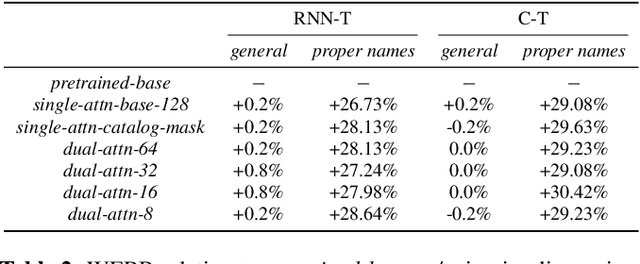
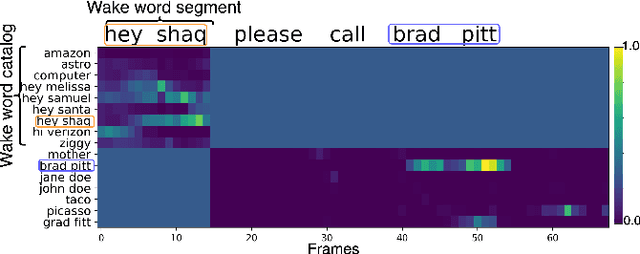
We present dual-attention neural biasing, an architecture designed to boost Wake Words (WW) recognition and improve inference time latency on speech recognition tasks. This architecture enables a dynamic switch for its runtime compute paths by exploiting WW spotting to select which branch of its attention networks to execute for an input audio frame. With this approach, we effectively improve WW spotting accuracy while saving runtime compute cost as defined by floating point operations (FLOPs). Using an in-house de-identified dataset, we demonstrate that the proposed dual-attention network can reduce the compute cost by $90\%$ for WW audio frames, with only $1\%$ increase in the number of parameters. This architecture improves WW F1 score by $16\%$ relative and improves generic rare word error rate by $3\%$ relative compared to the baselines.