 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training
Jun 06, 2023
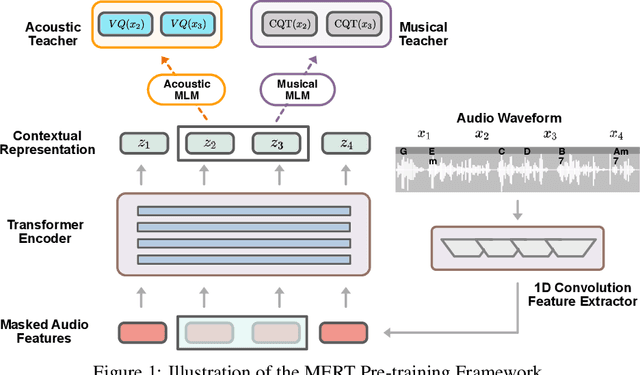
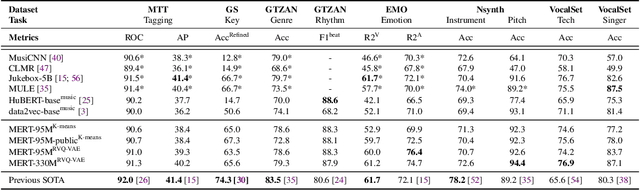
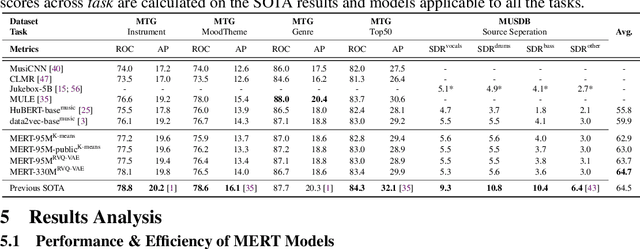
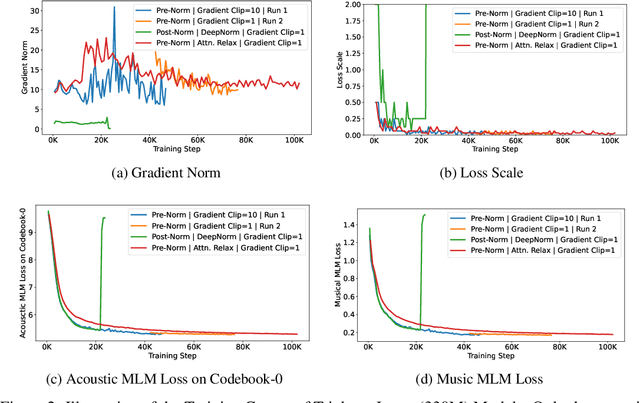
Self-supervised learning (SSL) has recently emerged as a promising paradigm for training generalisable models on large-scale data in the fields of vision, text, and speech. Although SSL has been proven effective in speech and audio, its application to music audio has yet to be thoroughly explored. This is primarily due to the distinctive challenges associated with modelling musical knowledge, particularly its tonal and pitched characteristics of music. To address this research gap, we propose an acoustic Music undERstanding model with large-scale self-supervised Training (MERT), which incorporates teacher models to provide pseudo labels in the masked language modelling (MLM) style acoustic pre-training. In our exploration, we identified a superior combination of teacher models, which outperforms conventional speech and audio approaches in terms of performance. This combination includes an acoustic teacher based on Residual Vector Quantization - Variational AutoEncoder (RVQ-VAE) and a musical teacher based on the Constant-Q Transform (CQT). These teachers effectively guide our student model, a BERT-style transformer encoder, to better model music audio. In addition, we introduce an in-batch noise mixture augmentation to enhance the representation robustness. Furthermore, we explore a wide range of settings to overcome the instability in acoustic language model pre-training, which allows our designed paradigm to scale from 95M to 330M parameters. Experimental results indicate that our model can generalise and perform well on 14 music understanding tasks and attains state-of-the-art (SOTA) overall scores. The code and models are online: https://github.com/yizhilll/MERT.
PLCMOS -- a data-driven non-intrusive metric for the evaluation of packet loss concealment algorithms
May 24, 2023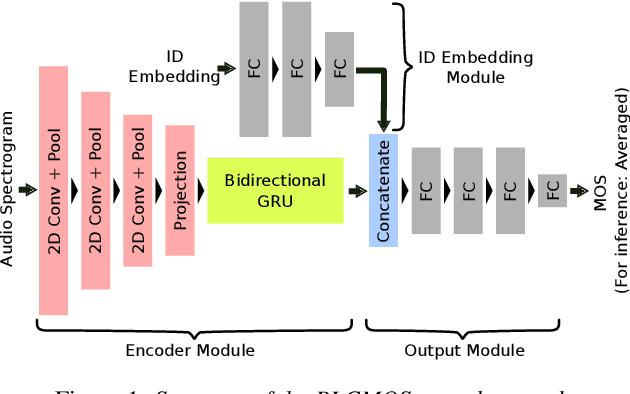
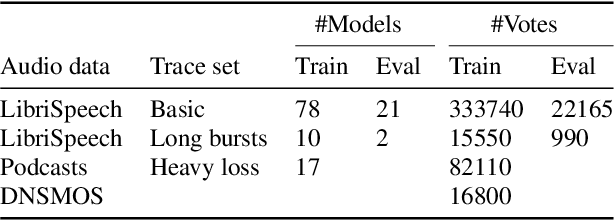
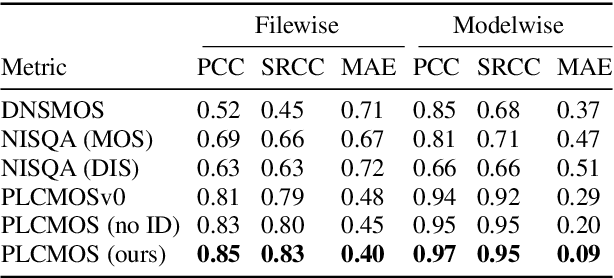
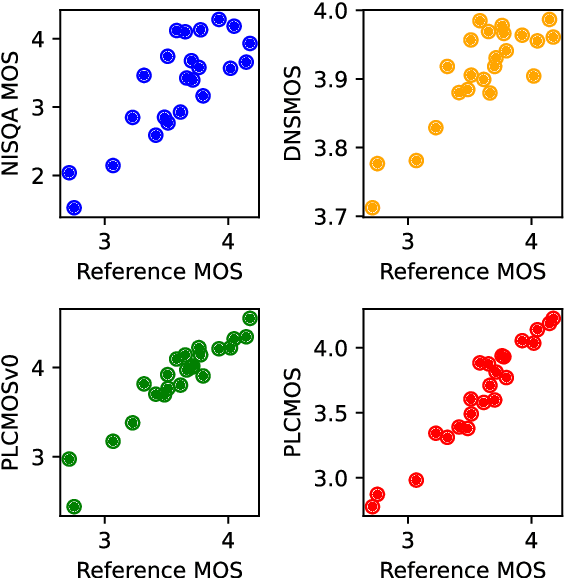
Speech quality assessment is a problem for every researcher working on models that produce or process speech. Human subjective ratings, the gold standard in speech quality assessment, are expensive and time-consuming to acquire in a quantity that is sufficient to get reliable data, while automated objective metrics show a low correlation with gold standard ratings. This paper presents PLCMOS, a non-intrusive data-driven tool for generating a robust, accurate estimate of the mean opinion score a human rater would assign an audio file that has been processed by being transmitted over a degraded packet-switched network with missing packets being healed by a packet loss concealment algorithm. Our new model shows a model-wise Pearson's correlation of ~0.97 and rank correlation of ~0.95 with human ratings, substantially above all other available intrusive and non-intrusive metrics. The model is released as an ONNX model for other researchers to use when building PLC systems.
Is ChatGPT better than Human Annotators? Potential and Limitations of ChatGPT in Explaining Implicit Hate Speech
Feb 11, 2023
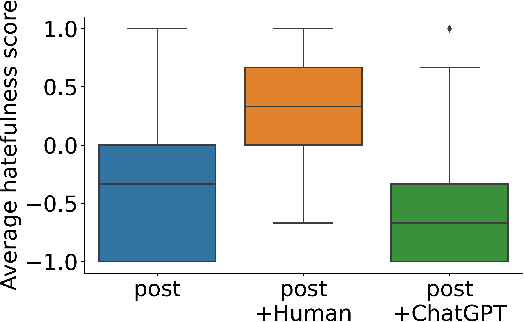
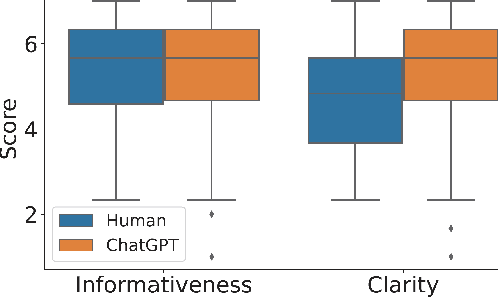
Recent studies have alarmed that many online hate speeches are implicit. With its subtle nature, the explainability of the detection of such hateful speech has been a challenging problem. In this work, we examine whether ChatGPT can be used for providing natural language explanations (NLEs) for implicit hateful speech detection. We design our prompt to elicit concise ChatGPT-generated NLEs and conduct user studies to evaluate their qualities by comparison with human-generated NLEs. We discuss the potential and limitations of ChatGPT in the context of implicit hateful speech research.
Skit-S2I: An Indian Accented Speech to Intent dataset
Dec 26, 2022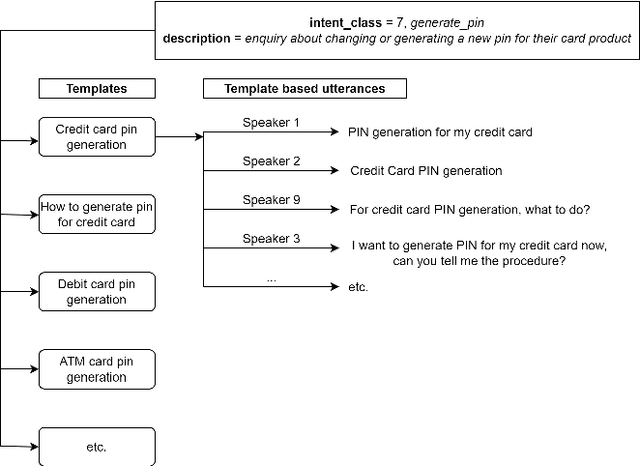
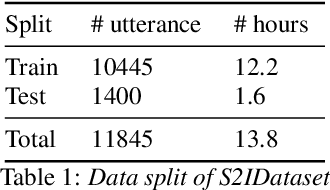
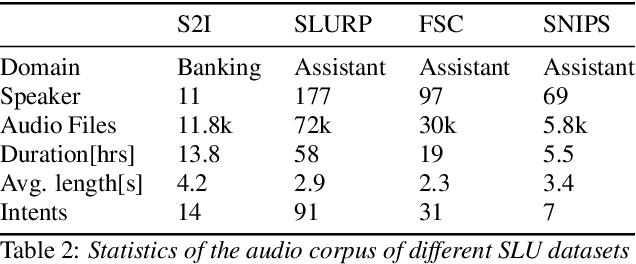
Conventional conversation assistants extract text transcripts from the speech signal using automatic speech recognition (ASR) and then predict intent from the transcriptions. Using end-to-end spoken language understanding (SLU), the intents of the speaker are predicted directly from the speech signal without requiring intermediate text transcripts. As a result, the model can optimize directly for intent classification and avoid cascading errors from ASR. The end-to-end SLU system also helps in reducing the latency of the intent prediction model. Although many datasets are available publicly for text-to-intent tasks, the availability of labeled speech-to-intent datasets is limited, and there are no datasets available in the Indian accent. In this paper, we release the Skit-S2I dataset, the first publicly available Indian-accented SLU dataset in the banking domain in a conversational tonality. We experiment with multiple baselines, compare different pretrained speech encoder's representations, and find that SSL pretrained representations perform slightly better than ASR pretrained representations lacking prosodic features for speech-to-intent classification. The dataset and baseline code is available at \url{https://github.com/skit-ai/speech-to-intent-dataset}
Using External Off-Policy Speech-To-Text Mappings in Contextual End-To-End Automated Speech Recognition
Jan 06, 2023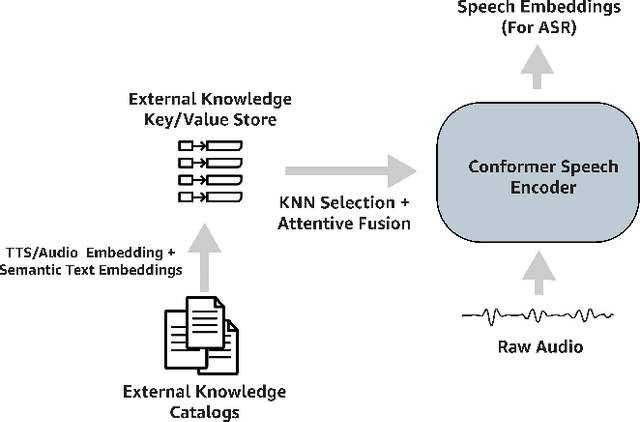
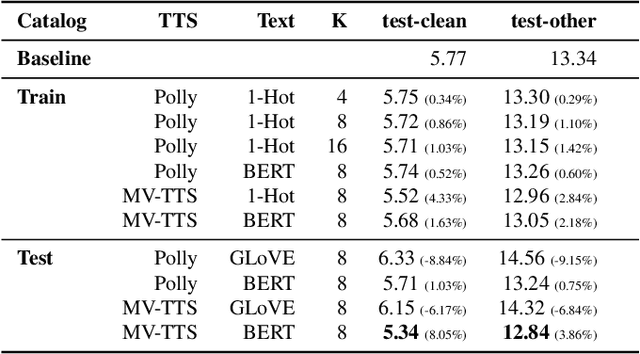
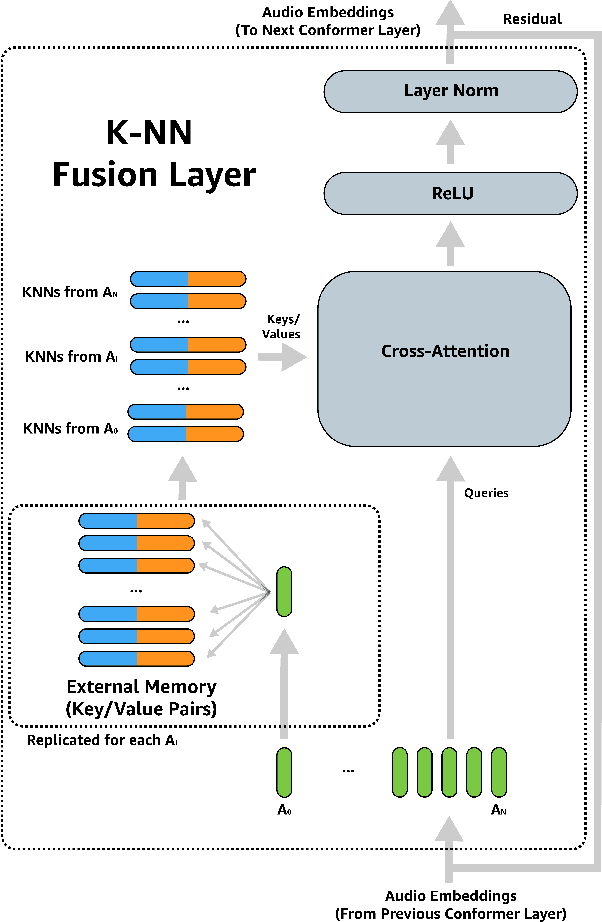
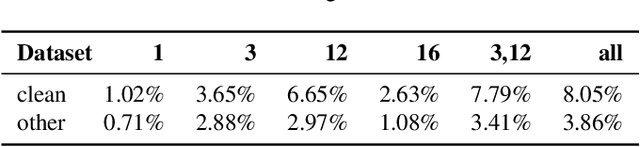
Despite improvements to the generalization performance of automated speech recognition (ASR) models, specializing ASR models for downstream tasks remains a challenging task, primarily due to reduced data availability (necessitating increased data collection), and rapidly shifting data distributions (requiring more frequent model fine-tuning). In this work, we investigate the potential of leveraging external knowledge, particularly through off-policy key-value stores generated with text-to-speech methods, to allow for flexible post-training adaptation to new data distributions. In our approach, audio embeddings captured from text-to-speech, along with semantic text embeddings, are used to bias ASR via an approximate k-nearest-neighbor (KNN) based attentive fusion step. Our experiments on LibiriSpeech and in-house voice assistant/search datasets show that the proposed approach can reduce domain adaptation time by up to 1K GPU-hours while providing up to 3% WER improvement compared to a fine-tuning baseline, suggesting a promising approach for adapting production ASR systems in challenging zero and few-shot scenarios.
HiddenSinger: High-Quality Singing Voice Synthesis via Neural Audio Codec and Latent Diffusion Models
Jun 12, 2023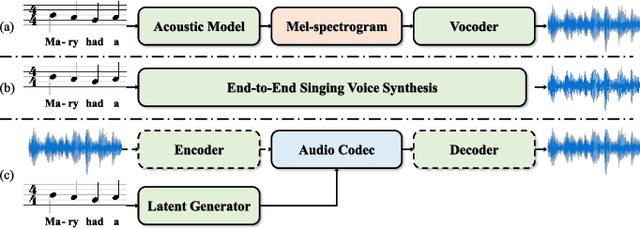
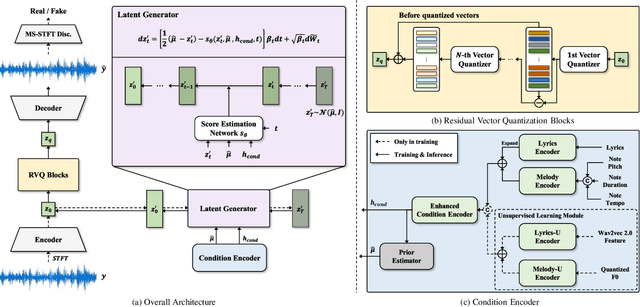
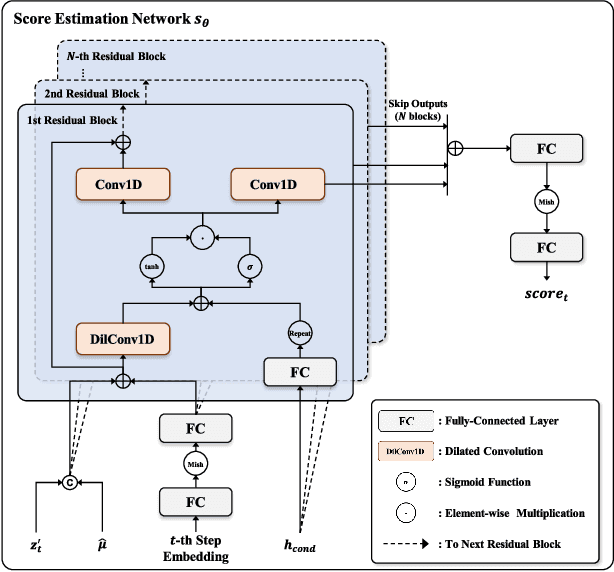
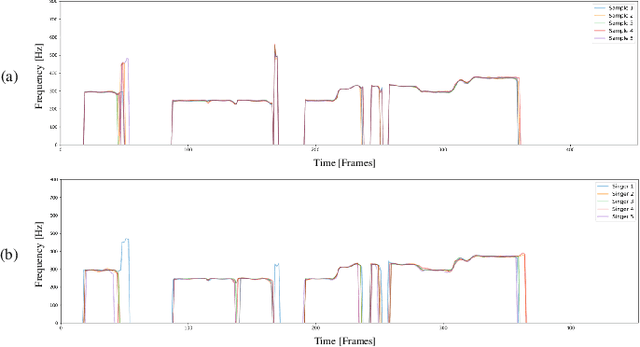
Recently, denoising diffusion models have demonstrated remarkable performance among generative models in various domains. However, in the speech domain, the application of diffusion models for synthesizing time-varying audio faces limitations in terms of complexity and controllability, as speech synthesis requires very high-dimensional samples with long-term acoustic features. To alleviate the challenges posed by model complexity in singing voice synthesis, we propose HiddenSinger, a high-quality singing voice synthesis system using a neural audio codec and latent diffusion models. To ensure high-fidelity audio, we introduce an audio autoencoder that can encode audio into an audio codec as a compressed representation and reconstruct the high-fidelity audio from the low-dimensional compressed latent vector. Subsequently, we use the latent diffusion models to sample a latent representation from a musical score. In addition, our proposed model is extended to an unsupervised singing voice learning framework, HiddenSinger-U, to train the model using an unlabeled singing voice dataset. Experimental results demonstrate that our model outperforms previous models in terms of audio quality. Furthermore, the HiddenSinger-U can synthesize high-quality singing voices of speakers trained solely on unlabeled data.
The Ethical Implications of Generative Audio Models: A Systematic Literature Review
Jul 07, 2023Generative audio models typically focus their applications in music and speech generation, with recent models having human-like quality in their audio output. This paper conducts a systematic literature review of 884 papers in the area of generative audio models in order to both quantify the degree to which researchers in the field are considering potential negative impacts and identify the types of ethical implications researchers in this area need to consider. Though 65% of generative audio research papers note positive potential impacts of their work, less than 10% discuss any negative impacts. This jarringly small percentage of papers considering negative impact is particularly worrying because the issues brought to light by the few papers doing so are raising serious ethical implications and concerns relevant to the broader field such as the potential for fraud, deep-fakes, and copyright infringement. By quantifying this lack of ethical consideration in generative audio research and identifying key areas of potential harm, this paper lays the groundwork for future work in the field at a critical point in time in order to guide more conscientious research as this field progresses.
EMNS /Imz/ Corpus: An emotive single-speaker dataset for narrative storytelling in games, television and graphic novels
May 22, 2023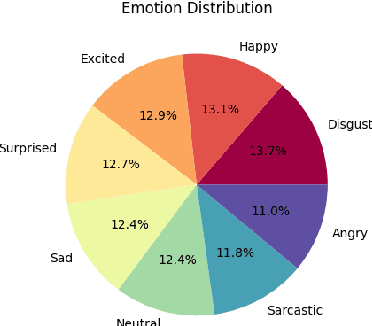
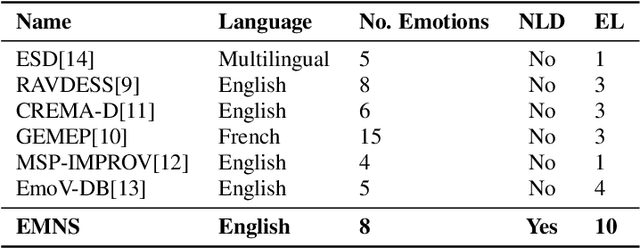
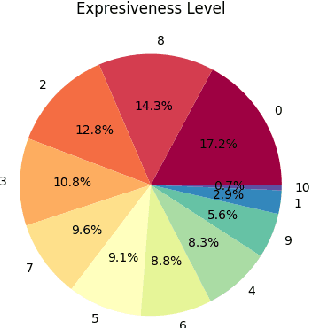

The increasing adoption of text-to-speech technologies has led to a growing demand for natural and emotive voices that adapt to a conversation's context and emotional tone. This need is particularly relevant for interactive narrative-driven systems such as video games, TV shows, and graphic novels. To address this need, we present the Emotive Narrative Storytelling (EMNS) corpus, a dataset of high-quality British English speech with labelled utterances designed to enhance interactive experiences with dynamic and expressive language. We provide high-quality clean audio recordings and natural language description pairs with transcripts and user-reviewed and self-reported labels for features such as word emphasis, expressiveness, and emotion labels. EMNS improves on existing datasets by providing higher quality and clean recording to aid more natural and expressive speech synthesis techniques for interactive narrative-driven experiences. Additionally, we release our remote and scalable data collection system to the research community.
Joint Acoustic Echo Cancellation and Speech Dereverberation Using Kalman filters
Feb 09, 2023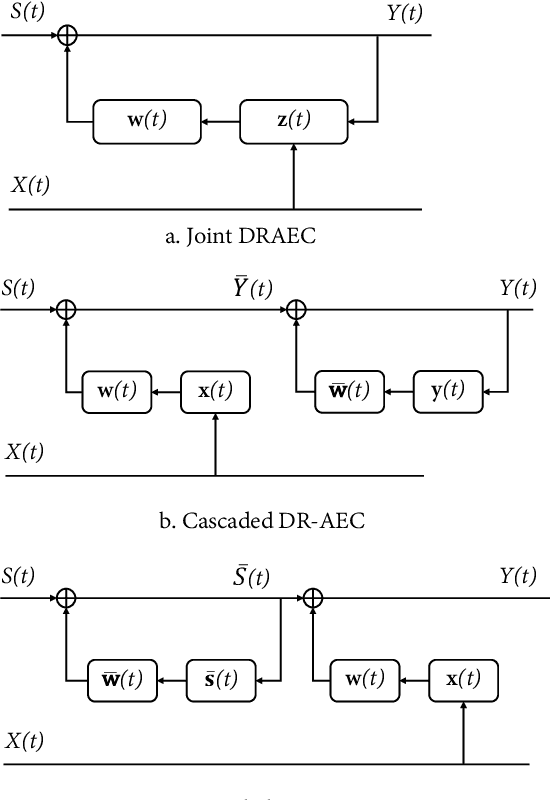
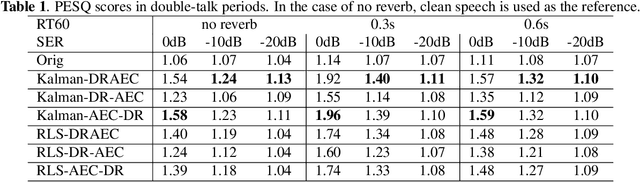
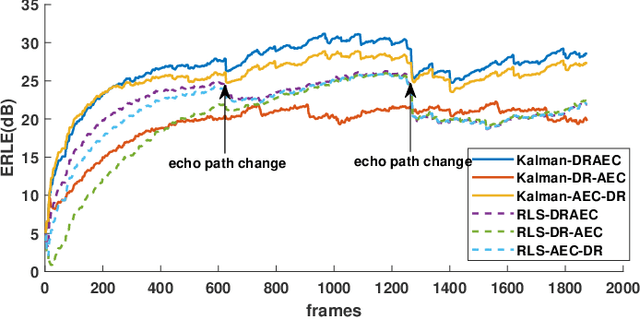
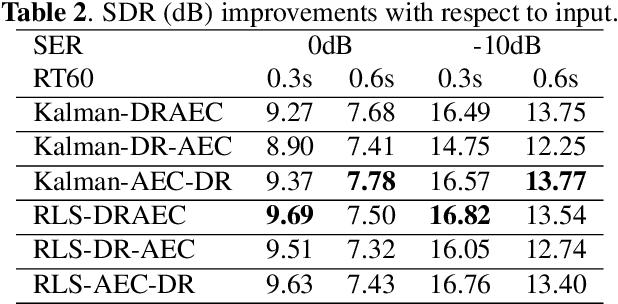
This paper proposes a joint acoustic echo cancellation (AEC) and speech dereverberation (DR) algorithm in the short-time Fourier transform domain. The reverberant microphone signals are described using an auto-regressive (AR) model. The AR coefficients and the loudspeaker-to-microphone acoustic transfer functions (ATFs) are considered time-varying and are modeled simultaneously using a first-order Markov process. This leads to a solution where these parameters can be optimally estimated using Kalman filters. It is shown that the proposed algorithm outperforms vanilla solutions that solve AEC and DR sequentially and one state-of-the-art joint DRAEC algorithm based on semi-blind source separation, in terms of both speech quality and echo reduction performance.
Analysing the Masked predictive coding training criterion for pre-training a Speech Representation Model
Mar 13, 2023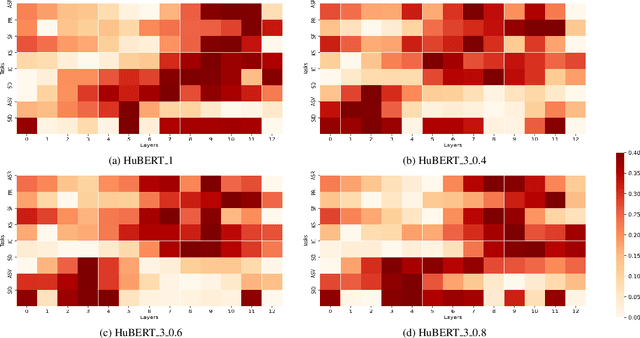

Recent developments in pre-trained speech representation utilizing self-supervised learning (SSL) have yielded exceptional results on a variety of downstream tasks. One such technique, known as masked predictive coding (MPC), has been employed by some of the most high-performing models. In this study, we investigate the impact of MPC loss on the type of information learnt at various layers in the HuBERT model, using nine probing tasks. Our findings indicate that the amount of content information learned at various layers of the HuBERT model has a positive correlation to the MPC loss. Additionally, it is also observed that any speaker-related information learned at intermediate layers of the model, is an indirect consequence of the learning process, and therefore cannot be controlled using the MPC loss. These findings may serve as inspiration for further research in the speech community, specifically in the development of new pre-training tasks or the exploration of new pre-training criterion's that directly preserves both speaker and content information at various layers of a learnt model.