 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Svarah: Evaluating English ASR Systems on Indian Accents
May 25, 2023
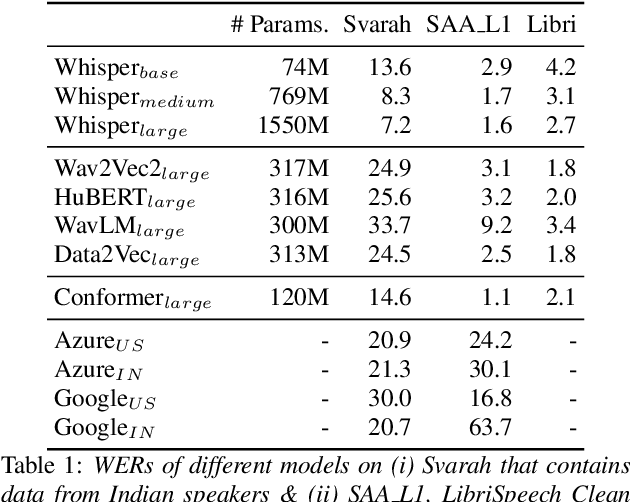
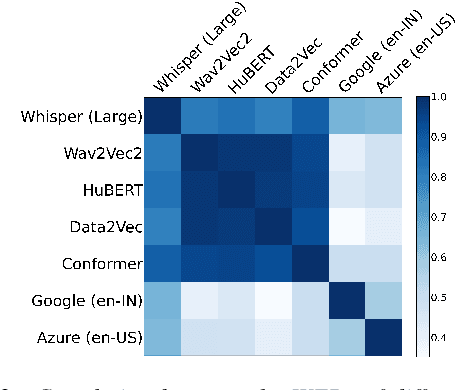
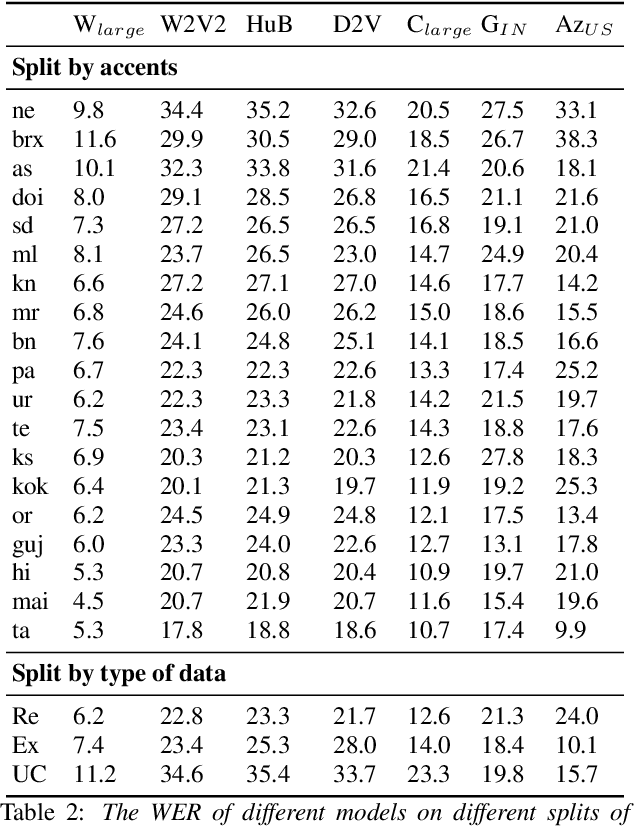
India is the second largest English-speaking country in the world with a speaker base of roughly 130 million. Thus, it is imperative that automatic speech recognition (ASR) systems for English should be evaluated on Indian accents. Unfortunately, Indian speakers find a very poor representation in existing English ASR benchmarks such as LibriSpeech, Switchboard, Speech Accent Archive, etc. In this work, we address this gap by creating Svarah, a benchmark that contains 9.6 hours of transcribed English audio from 117 speakers across 65 geographic locations throughout India, resulting in a diverse range of accents. Svarah comprises both read speech and spontaneous conversational data, covering various domains, such as history, culture, tourism, etc., ensuring a diverse vocabulary. We evaluate 6 open source ASR models and 2 commercial ASR systems on Svarah and show that there is clear scope for improvement on Indian accents. Svarah as well as all our code will be publicly available.
The Ethical Implications of Generative Audio Models: A Systematic Literature Review
Jul 07, 2023Generative audio models typically focus their applications in music and speech generation, with recent models having human-like quality in their audio output. This paper conducts a systematic literature review of 884 papers in the area of generative audio models in order to both quantify the degree to which researchers in the field are considering potential negative impacts and identify the types of ethical implications researchers in this area need to consider. Though 65% of generative audio research papers note positive potential impacts of their work, less than 10% discuss any negative impacts. This jarringly small percentage of papers considering negative impact is particularly worrying because the issues brought to light by the few papers doing so are raising serious ethical implications and concerns relevant to the broader field such as the potential for fraud, deep-fakes, and copyright infringement. By quantifying this lack of ethical consideration in generative audio research and identifying key areas of potential harm, this paper lays the groundwork for future work in the field at a critical point in time in order to guide more conscientious research as this field progresses.
How Good is Automatic Segmentation as a Multimodal Discourse Annotation Aid?
May 27, 2023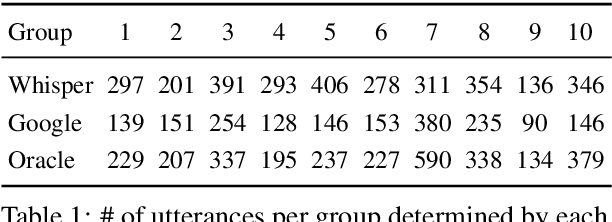
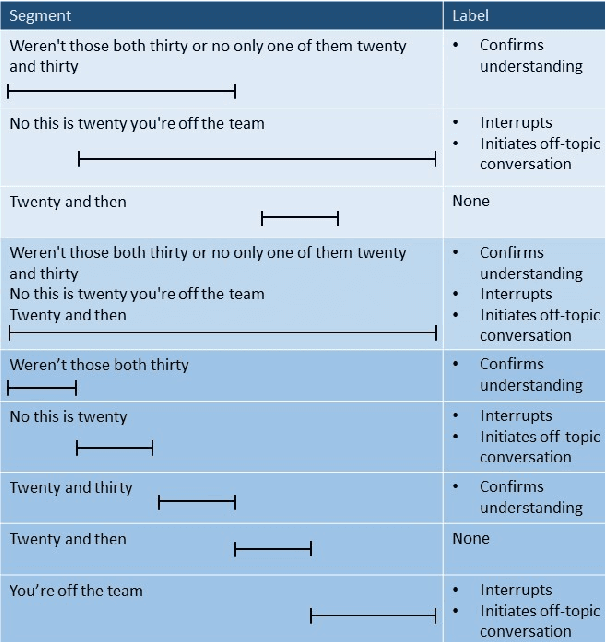
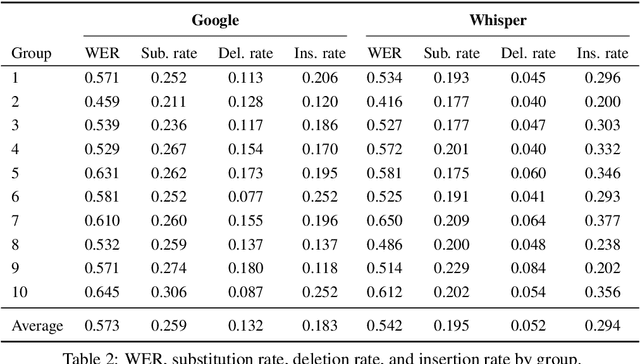
Collaborative problem solving (CPS) in teams is tightly coupled with the creation of shared meaning between participants in a situated, collaborative task. In this work, we assess the quality of different utterance segmentation techniques as an aid in annotating CPS. We (1) manually transcribe utterances in a dataset of triads collaboratively solving a problem involving dialogue and physical object manipulation, (2) annotate collaborative moves according to these gold-standard transcripts, and then (3) apply these annotations to utterances that have been automatically segmented using toolkits from Google and OpenAI's Whisper. We show that the oracle utterances have minimal correspondence to automatically segmented speech, and that automatically segmented speech using different segmentation methods is also inconsistent. We also show that annotating automatically segmented speech has distinct implications compared with annotating oracle utterances--since most annotation schemes are designed for oracle cases, when annotating automatically-segmented utterances, annotators must invoke other information to make arbitrary judgments which other annotators may not replicate. We conclude with a discussion of how future annotation specs can account for these needs.
Dialog act guided contextual adapter for personalized speech recognition
Mar 31, 2023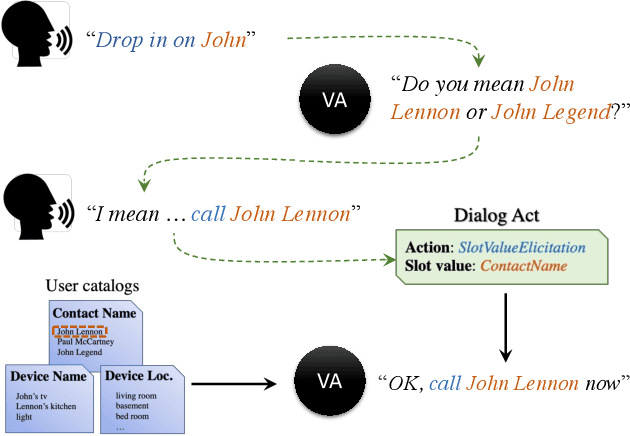
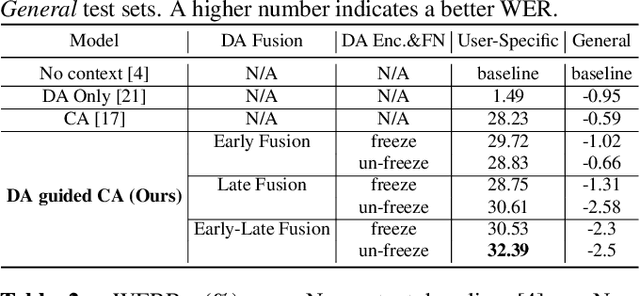
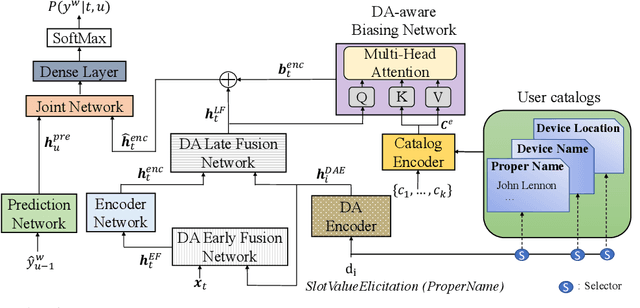

Personalization in multi-turn dialogs has been a long standing challenge for end-to-end automatic speech recognition (E2E ASR) models. Recent work on contextual adapters has tackled rare word recognition using user catalogs. This adaptation, however, does not incorporate an important cue, the dialog act, which is available in a multi-turn dialog scenario. In this work, we propose a dialog act guided contextual adapter network. Specifically, it leverages dialog acts to select the most relevant user catalogs and creates queries based on both -- the audio as well as the semantic relationship between the carrier phrase and user catalogs to better guide the contextual biasing. On industrial voice assistant datasets, our model outperforms both the baselines - dialog act encoder-only model, and the contextual adaptation, leading to the most improvement over the no-context model: 58% average relative word error rate reduction (WERR) in the multi-turn dialog scenario, in comparison to the prior-art contextual adapter, which has achieved 39% WERR over the no-context model.
MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training
Jun 06, 2023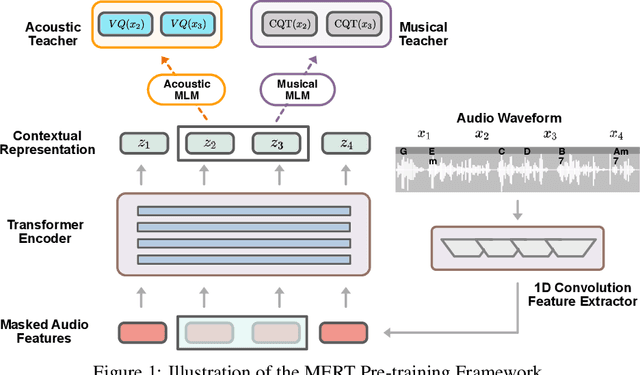
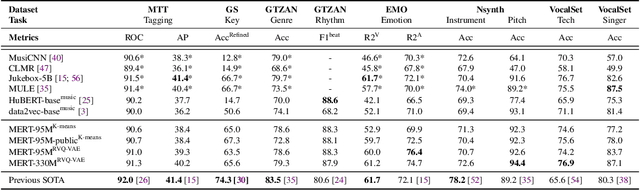
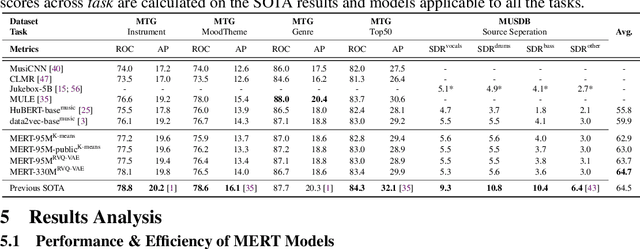
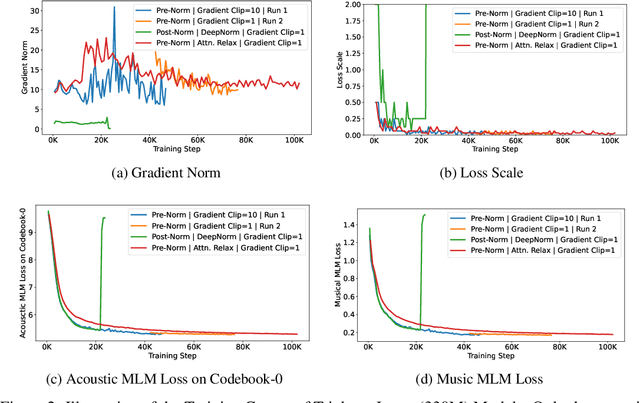
Self-supervised learning (SSL) has recently emerged as a promising paradigm for training generalisable models on large-scale data in the fields of vision, text, and speech. Although SSL has been proven effective in speech and audio, its application to music audio has yet to be thoroughly explored. This is primarily due to the distinctive challenges associated with modelling musical knowledge, particularly its tonal and pitched characteristics of music. To address this research gap, we propose an acoustic Music undERstanding model with large-scale self-supervised Training (MERT), which incorporates teacher models to provide pseudo labels in the masked language modelling (MLM) style acoustic pre-training. In our exploration, we identified a superior combination of teacher models, which outperforms conventional speech and audio approaches in terms of performance. This combination includes an acoustic teacher based on Residual Vector Quantization - Variational AutoEncoder (RVQ-VAE) and a musical teacher based on the Constant-Q Transform (CQT). These teachers effectively guide our student model, a BERT-style transformer encoder, to better model music audio. In addition, we introduce an in-batch noise mixture augmentation to enhance the representation robustness. Furthermore, we explore a wide range of settings to overcome the instability in acoustic language model pre-training, which allows our designed paradigm to scale from 95M to 330M parameters. Experimental results indicate that our model can generalise and perform well on 14 music understanding tasks and attains state-of-the-art (SOTA) overall scores. The code and models are online: https://github.com/yizhilll/MERT.
HiddenSinger: High-Quality Singing Voice Synthesis via Neural Audio Codec and Latent Diffusion Models
Jun 12, 2023
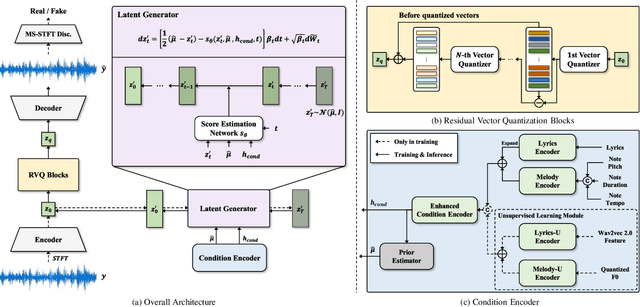
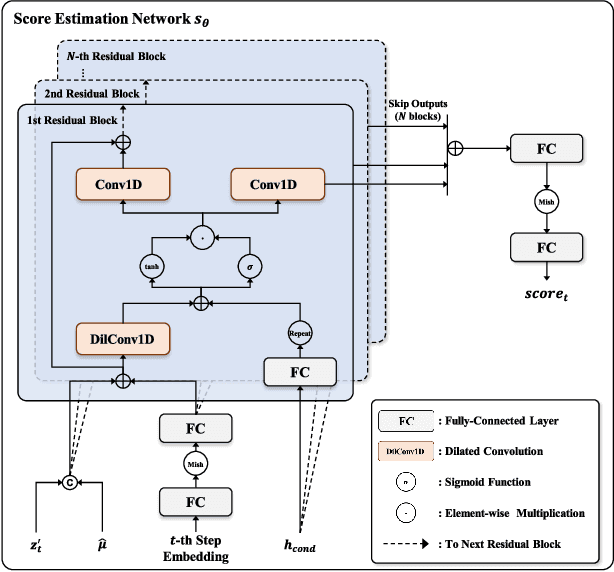
Recently, denoising diffusion models have demonstrated remarkable performance among generative models in various domains. However, in the speech domain, the application of diffusion models for synthesizing time-varying audio faces limitations in terms of complexity and controllability, as speech synthesis requires very high-dimensional samples with long-term acoustic features. To alleviate the challenges posed by model complexity in singing voice synthesis, we propose HiddenSinger, a high-quality singing voice synthesis system using a neural audio codec and latent diffusion models. To ensure high-fidelity audio, we introduce an audio autoencoder that can encode audio into an audio codec as a compressed representation and reconstruct the high-fidelity audio from the low-dimensional compressed latent vector. Subsequently, we use the latent diffusion models to sample a latent representation from a musical score. In addition, our proposed model is extended to an unsupervised singing voice learning framework, HiddenSinger-U, to train the model using an unlabeled singing voice dataset. Experimental results demonstrate that our model outperforms previous models in terms of audio quality. Furthermore, the HiddenSinger-U can synthesize high-quality singing voices of speakers trained solely on unlabeled data.
Improved Decoding of Attentional Selection in Multi-Talker Environments with Self-Supervised Learned Speech Representation
Feb 11, 2023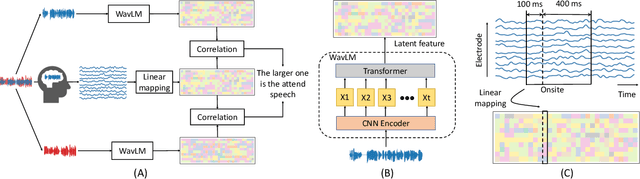
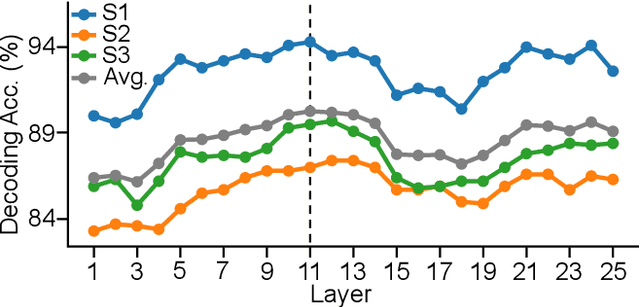
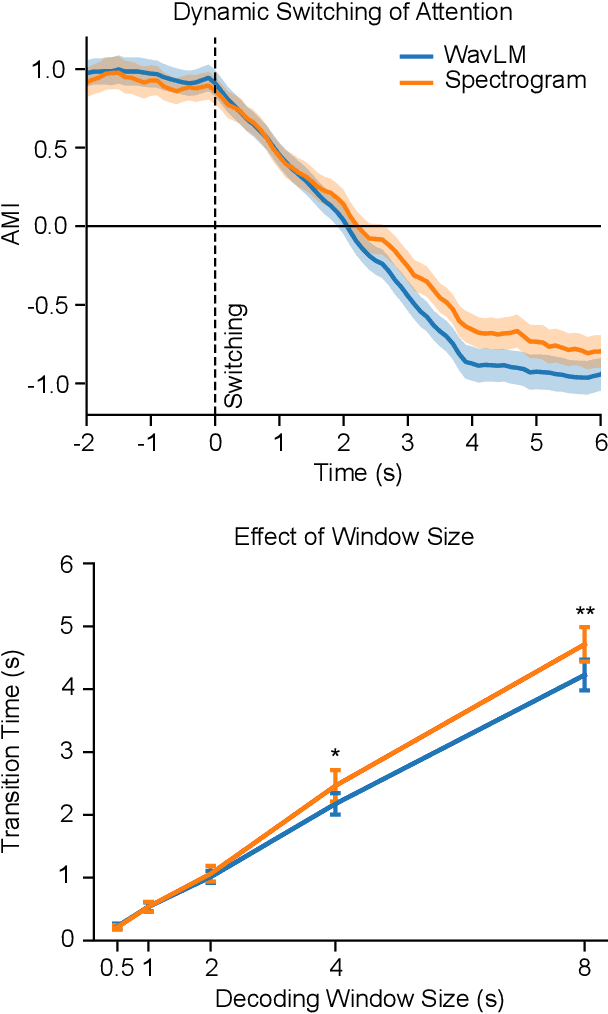

Auditory attention decoding (AAD) is a technique used to identify and amplify the talker that a listener is focused on in a noisy environment. This is done by comparing the listener's brainwaves to a representation of all the sound sources to find the closest match. The representation is typically the waveform or spectrogram of the sounds. The effectiveness of these representations for AAD is uncertain. In this study, we examined the use of self-supervised learned speech representation in improving the accuracy and speed of AAD. We recorded the brain activity of three subjects using invasive electrocorticography (ECoG) as they listened to two conversations and focused on one. We used WavLM to extract a latent representation of each talker and trained a spatiotemporal filter to map brain activity to intermediate representations of speech. During the evaluation, the reconstructed representation is compared to each speaker's representation to determine the target speaker. Our results indicate that speech representation from WavLM provides better decoding accuracy and speed than the speech envelope and spectrogram. Our findings demonstrate the advantages of self-supervised learned speech representation for auditory attention decoding and pave the way for developing brain-controlled hearable technologies.
The NPU-Elevoc Personalized Speech Enhancement System for ICASSP2023 DNS Challenge
Mar 15, 2023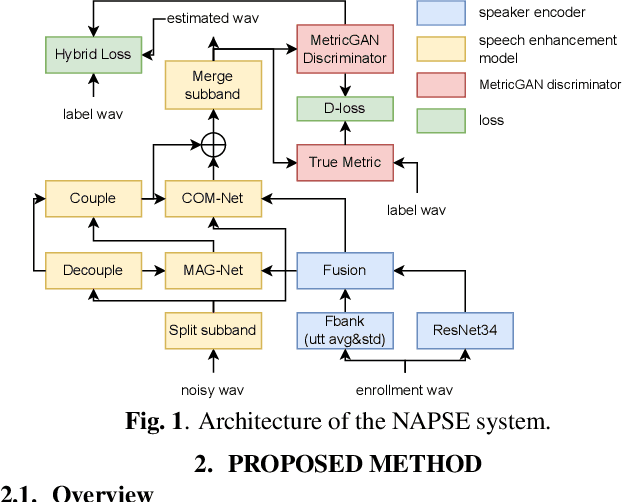
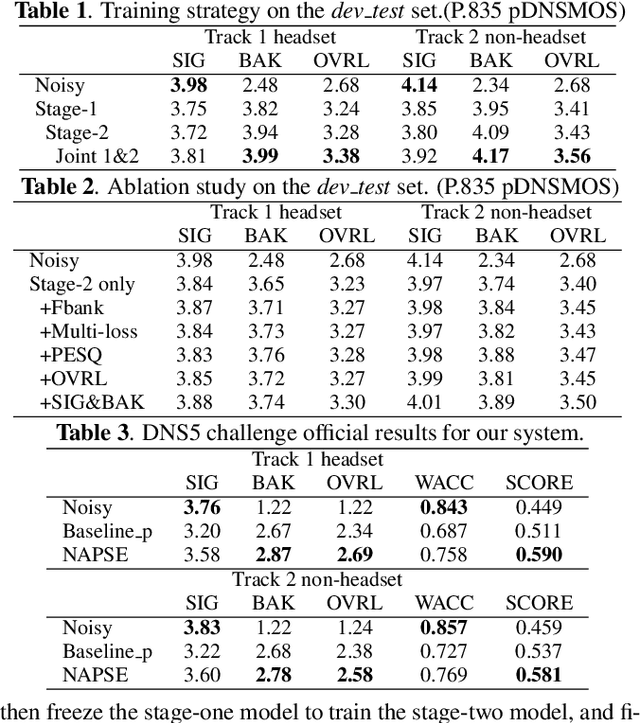
This paper describes our NPU-Elevoc personalized speech enhancement system (NAPSE) for the 5th Deep Noise Suppression Challenge at ICASSP 2023. Based on the superior two-stage model TEA-PSE 2.0, our system particularly explores better strategy for speaker embedding fusion, optimizes the model training pipeline, and leverages adversarial training and multi-scale loss. According to the results, our system is tied for the 1st place in the headset track (track 1) and ranked 2nd in the speakerphone track (track 2).
Multi-level Temporal-channel Speaker Retrieval for Robust Zero-shot Voice Conversion
May 12, 2023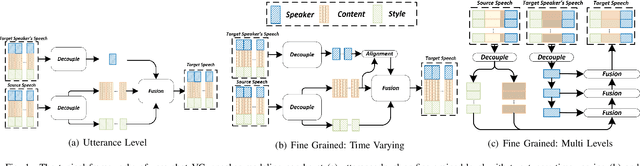
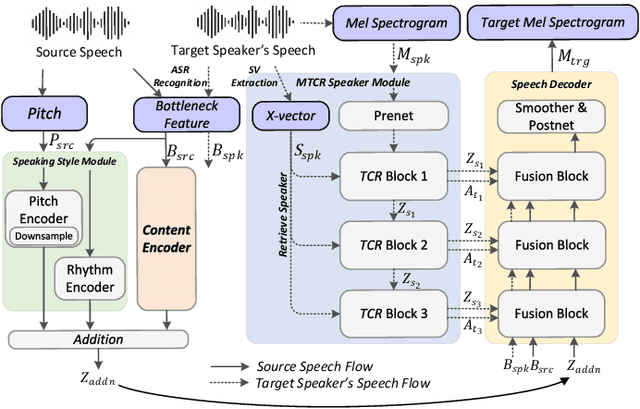
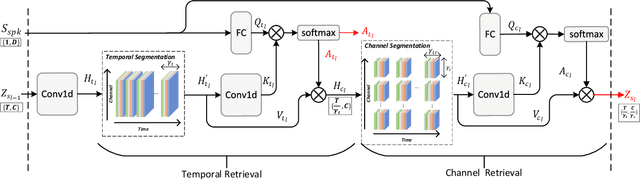
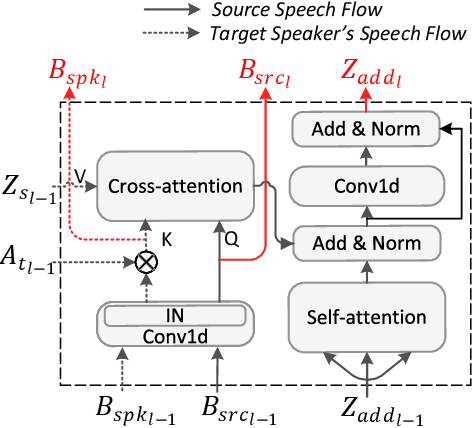
Zero-shot voice conversion (VC) converts source speech into the voice of any desired speaker using only one utterance of the speaker without requiring additional model updates. Typical methods use a speaker representation from a pre-trained speaker verification (SV) model or learn speaker representation during VC training to achieve zero-shot VC. However, existing speaker modeling methods overlook the variation of speaker information richness in temporal and frequency channel dimensions of speech. This insufficient speaker modeling hampers the ability of the VC model to accurately represent unseen speakers who are not in the training dataset. In this study, we present a robust zero-shot VC model with multi-level temporal-channel retrieval, referred to as MTCR-VC. Specifically, to flexibly adapt to the dynamic-variant speaker characteristic in the temporal and channel axis of the speech, we propose a novel fine-grained speaker modeling method, called temporal-channel retrieval (TCR), to find out when and where speaker information appears in speech. It retrieves variable-length speaker representation from both temporal and channel dimensions under the guidance of a pre-trained SV model. Besides, inspired by the hierarchical process of human speech production, the MTCR speaker module stacks several TCR blocks to extract speaker representations from multi-granularity levels. Furthermore, to achieve better speech disentanglement and reconstruction, we introduce a cycle-based training strategy to simulate zero-shot inference recurrently. We adopt perpetual constraints on three aspects, including content, style, and speaker, to drive this process. Experiments demonstrate that MTCR-VC is superior to the previous zero-shot VC methods in modeling speaker timbre while maintaining good speech naturalness.
SLABERT Talk Pretty One Day: Modeling Second Language Acquisition with BERT
May 31, 2023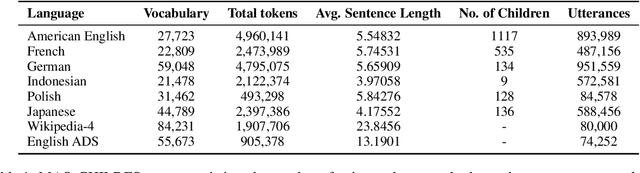
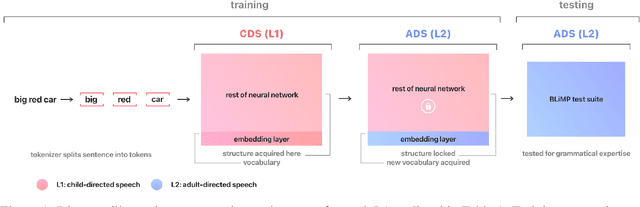
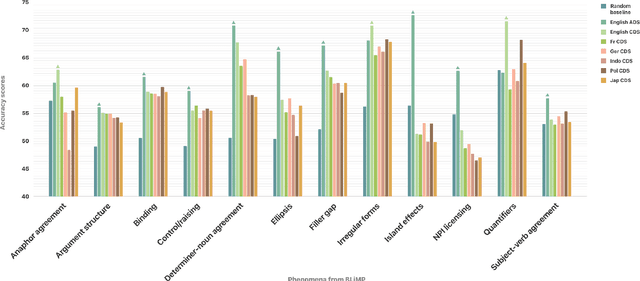
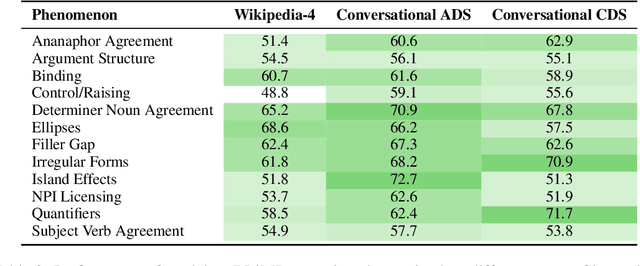
Second language acquisition (SLA) research has extensively studied cross-linguistic transfer, the influence of linguistic structure of a speaker's native language [L1] on the successful acquisition of a foreign language [L2]. Effects of such transfer can be positive (facilitating acquisition) or negative (impeding acquisition). We find that NLP literature has not given enough attention to the phenomenon of negative transfer. To understand patterns of both positive and negative transfer between L1 and L2, we model sequential second language acquisition in LMs. Further, we build a Mutlilingual Age Ordered CHILDES (MAO-CHILDES) -- a dataset consisting of 5 typologically diverse languages, i.e., German, French, Polish, Indonesian, and Japanese -- to understand the degree to which native Child-Directed Speech (CDS) [L1] can help or conflict with English language acquisition [L2]. To examine the impact of native CDS, we use the TILT-based cross lingual transfer learning approach established by Papadimitriou and Jurafsky (2020) and find that, as in human SLA, language family distance predicts more negative transfer. Additionally, we find that conversational speech data shows greater facilitation for language acquisition than scripted speech data. Our findings call for further research using our novel Transformer-based SLA models and we would like to encourage it by releasing our code, data, and models.