 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A Sidecar Separator Can Convert a Single-Talker Speech Recognition System to a Multi-Talker One
Mar 05, 2023
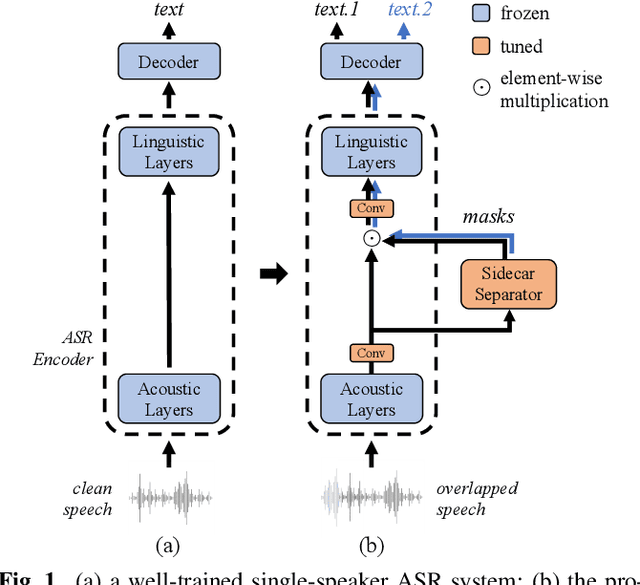
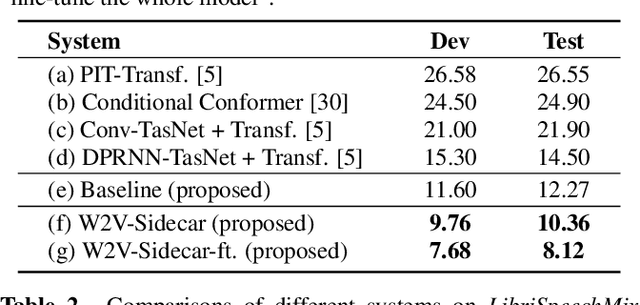
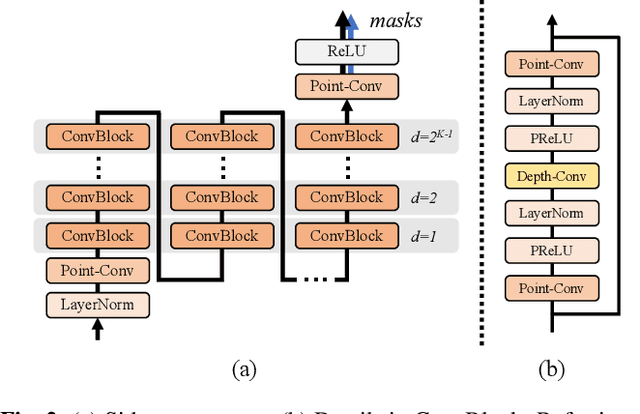
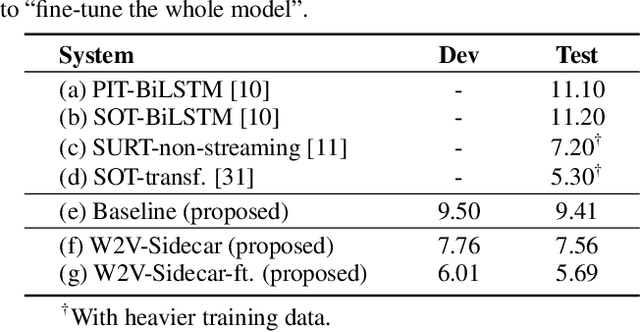
Although automatic speech recognition (ASR) can perform well in common non-overlapping environments, sustaining performance in multi-talker overlapping speech recognition remains challenging. Recent research revealed that ASR model's encoder captures different levels of information with different layers -- the lower layers tend to have more acoustic information, and the upper layers more linguistic. This inspires us to develop a Sidecar separator to empower a well-trained ASR model for multi-talker scenarios by separating the mixed speech embedding between two suitable layers. We experimented with a wav2vec 2.0-based ASR model with a Sidecar mounted. By freezing the parameters of the original model and training only the Sidecar (8.7 M, 8.4% of all parameters), the proposed approach outperforms the previous state-of-the-art by a large margin for the 2-speaker mixed LibriMix dataset, reaching a word error rate (WER) of 10.36%; and obtains comparable results (7.56%) for LibriSpeechMix dataset when limited training.
Towards Model-Size Agnostic, Compute-Free, Memorization-based Inference of Deep Learning
Jul 14, 2023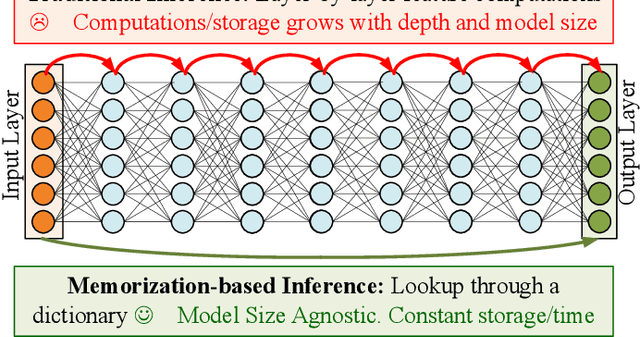
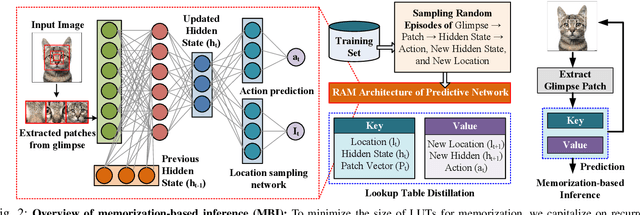
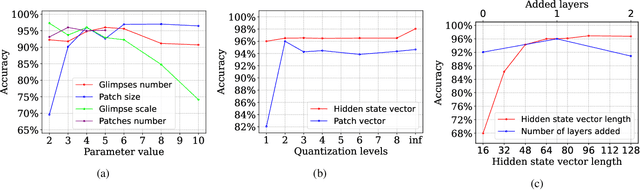
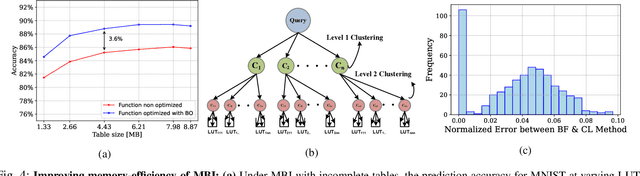
The rapid advancement of deep neural networks has significantly improved various tasks, such as image and speech recognition. However, as the complexity of these models increases, so does the computational cost and the number of parameters, making it difficult to deploy them on resource-constrained devices. This paper proposes a novel memorization-based inference (MBI) that is compute free and only requires lookups. Specifically, our work capitalizes on the inference mechanism of the recurrent attention model (RAM), where only a small window of input domain (glimpse) is processed in a one time step, and the outputs from multiple glimpses are combined through a hidden vector to determine the overall classification output of the problem. By leveraging the low-dimensionality of glimpse, our inference procedure stores key value pairs comprising of glimpse location, patch vector, etc. in a table. The computations are obviated during inference by utilizing the table to read out key-value pairs and performing compute-free inference by memorization. By exploiting Bayesian optimization and clustering, the necessary lookups are reduced, and accuracy is improved. We also present in-memory computing circuits to quickly look up the matching key vector to an input query. Compared to competitive compute-in-memory (CIM) approaches, MBI improves energy efficiency by almost 2.7 times than multilayer perceptions (MLP)-CIM and by almost 83 times than ResNet20-CIM for MNIST character recognition.
Beyond Universal Transformer: block reusing with adaptor in Transformer for automatic speech recognit
Mar 23, 2023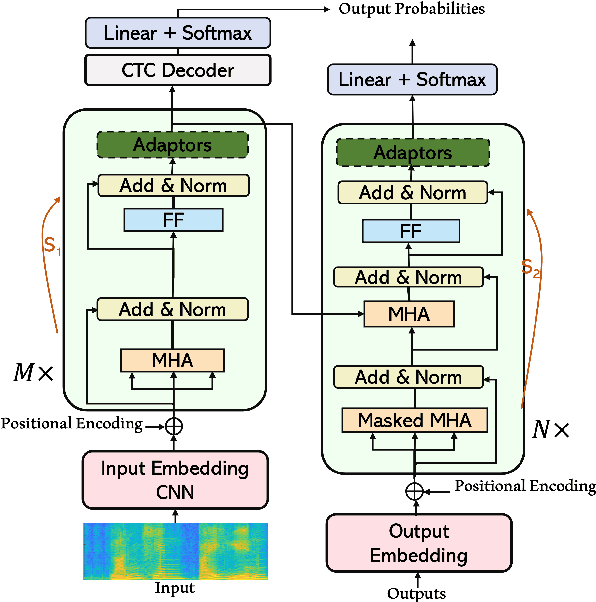
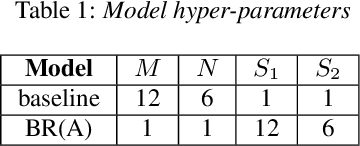
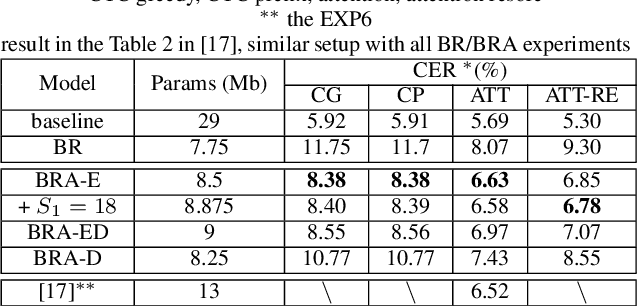
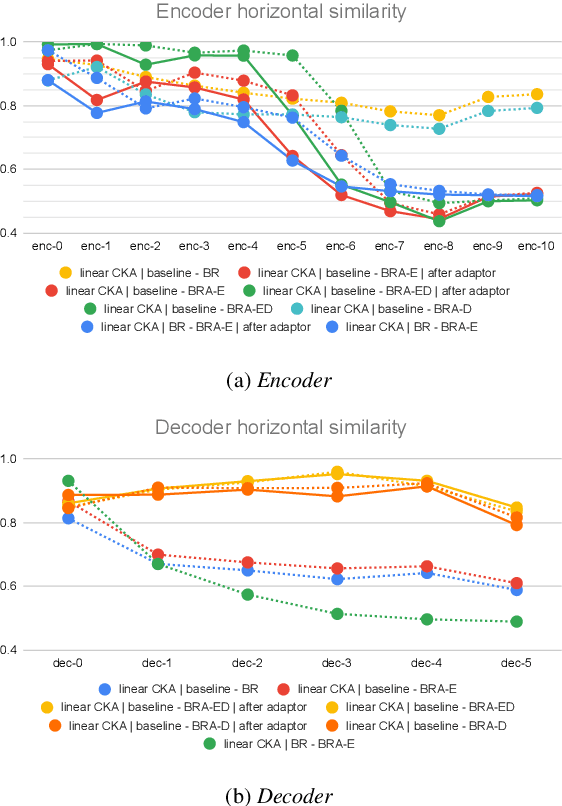
Transformer-based models have recently made significant achievements in the application of end-to-end (E2E) automatic speech recognition (ASR). It is possible to deploy the E2E ASR system on smart devices with the help of Transformer-based models. While these models still have the disadvantage of requiring a large number of model parameters. To overcome the drawback of universal Transformer models for the application of ASR on edge devices, we propose a solution that can reuse the block in Transformer models for the occasion of the small footprint ASR system, which meets the objective of accommodating resource limitations without compromising recognition accuracy. Specifically, we design a novel block-reusing strategy for speech Transformer (BRST) to enhance the effectiveness of parameters and propose an adapter module (ADM) that can produce a compact and adaptable model with only a few additional trainable parameters accompanying each reusing block. We conducted an experiment with the proposed method on the public AISHELL-1 corpus, and the results show that the proposed approach achieves the character error rate (CER) of 9.3%/6.63% with only 7.6M/8.3M parameters without and with the ADM, respectively. In addition, we also make a deeper analysis to show the effect of ADM in the general block-reusing method.
Using Deepfake Technologies for Word Emphasis Detection
May 12, 2023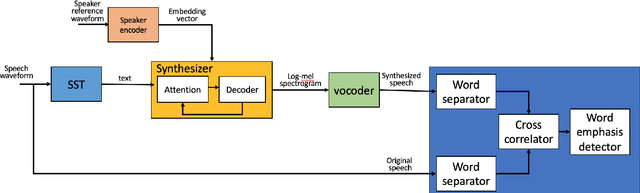
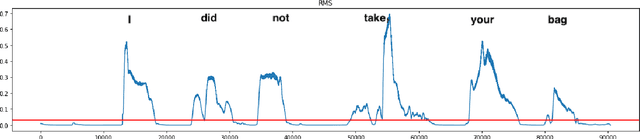
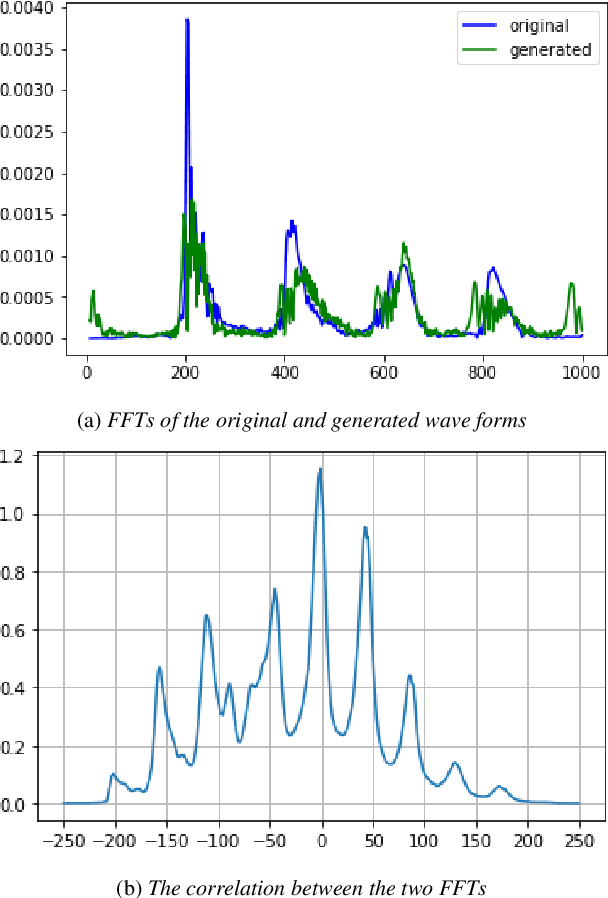
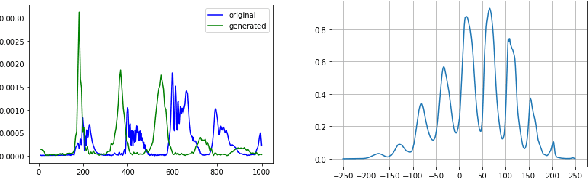
In this work, we consider the task of automated emphasis detection for spoken language. This problem is challenging in that emphasis is affected by the particularities of speech of the subject, for example the subject accent, dialect or voice. To address this task, we propose to utilize deep fake technology to produce an emphasis devoid speech for this speaker. This requires extracting the text of the spoken voice, and then using a voice sample from the same speaker to produce emphasis devoid speech for this task. By comparing the generated speech with the spoken voice, we are able to isolate patterns of emphasis which are relatively easy to detect.
DAE-Talker: High Fidelity Speech-Driven Talking Face Generation with Diffusion Autoencoder
Mar 30, 2023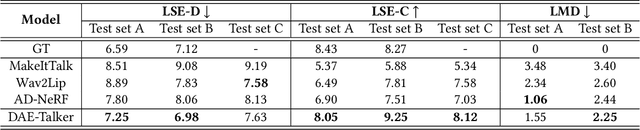
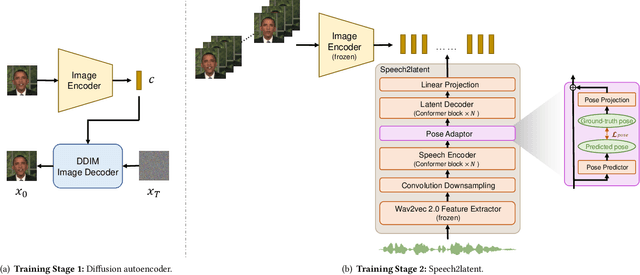

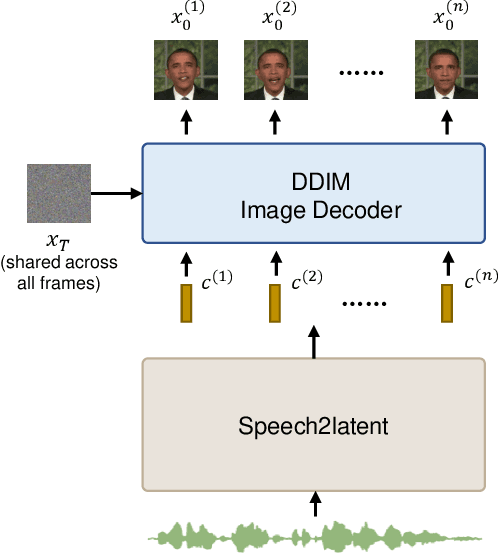
While recent research has made significant progress in speech-driven talking face generation, the quality of the generated video still lags behind that of real recordings. One reason for this is the use of handcrafted intermediate representations like facial landmarks and 3DMM coefficients, which are designed based on human knowledge and are insufficient to precisely describe facial movements. Additionally, these methods require an external pretrained model for extracting these representations, whose performance sets an upper bound on talking face generation. To address these limitations, we propose a novel method called DAE-Talker that leverages data-driven latent representations obtained from a diffusion autoencoder (DAE). DAE contains an image encoder that encodes an image into a latent vector and a DDIM image decoder that reconstructs the image from it. We train our DAE on talking face video frames and then extract their latent representations as the training target for a Conformer-based speech2latent model. This allows DAE-Talker to synthesize full video frames and produce natural head movements that align with the content of speech, rather than relying on a predetermined head pose from a template video. We also introduce pose modelling in speech2latent for pose controllability. Additionally, we propose a novel method for generating continuous video frames with the DDIM image decoder trained on individual frames, eliminating the need for modelling the joint distribution of consecutive frames directly. Our experiments show that DAE-Talker outperforms existing popular methods in lip-sync, video fidelity, and pose naturalness. We also conduct ablation studies to analyze the effectiveness of the proposed techniques and demonstrate the pose controllability of DAE-Talker.
SpeeChain: A Speech Toolkit for Large-Scale Machine Speech Chain
Jan 08, 2023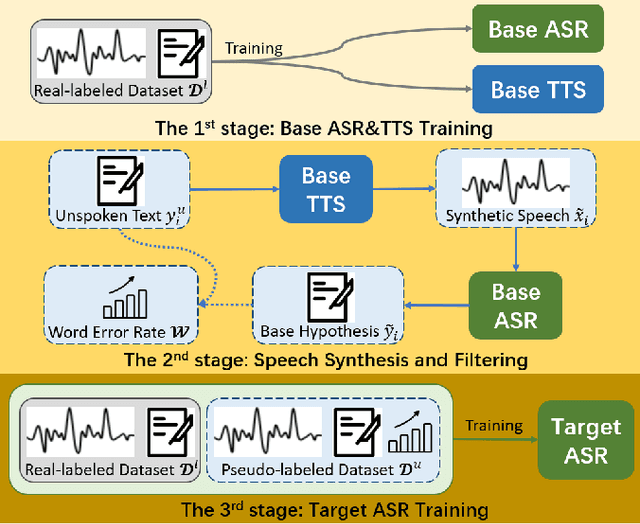
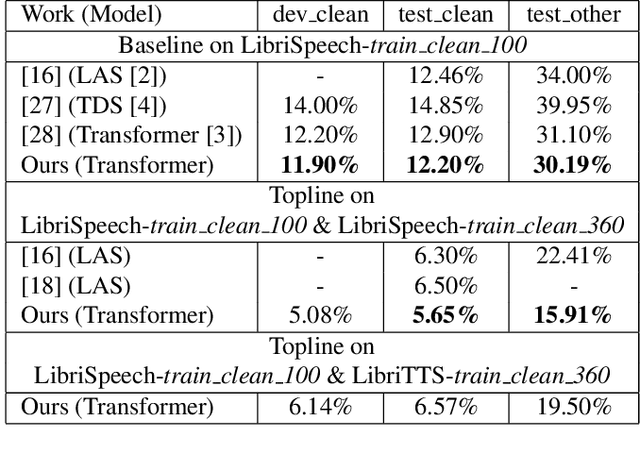
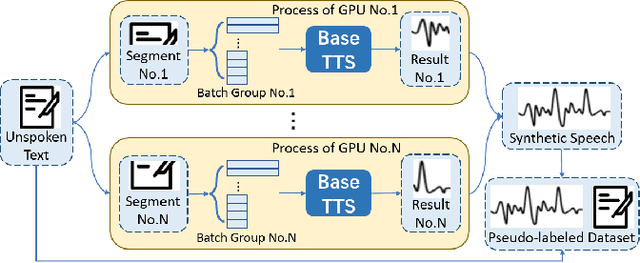
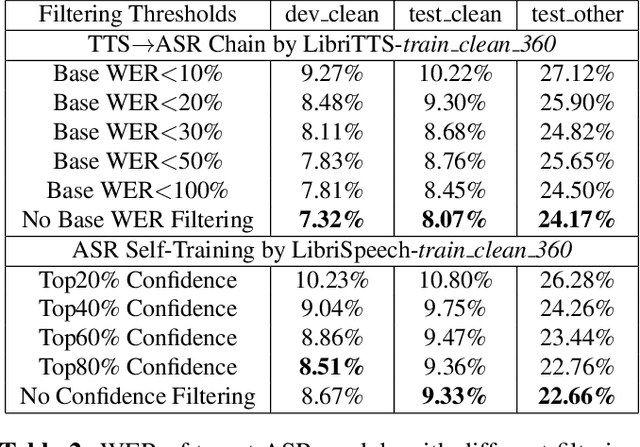
This paper introduces SpeeChain, an open-source Pytorch-based toolkit designed to develop the machine speech chain for large-scale use. This first release focuses on the TTS-to-ASR chain, a core component of the machine speech chain, that refers to the TTS data augmentation by unspoken text for ASR. To build an efficient pipeline for the large-scale TTS-to-ASR chain, we implement easy-to-use multi-GPU batch-level model inference, multi-dataloader batch generation, and on-the-fly data selection techniques. In this paper, we first explain the overall procedure of the TTS-to-ASR chain and the difficulties of each step. Then, we present a detailed ablation study on different types of unlabeled data, data filtering thresholds, batch composition, and real-synthetic data ratios. Our experimental results on train_clean_460 of LibriSpeech demonstrate that our TTS-to-ASR chain can significantly improve WER in a semi-supervised setting.
Frame-wise and overlap-robust speaker embeddings for meeting diarization
Jun 01, 2023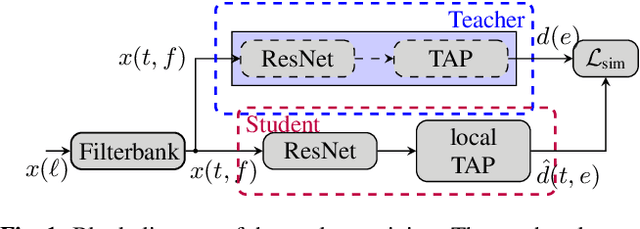
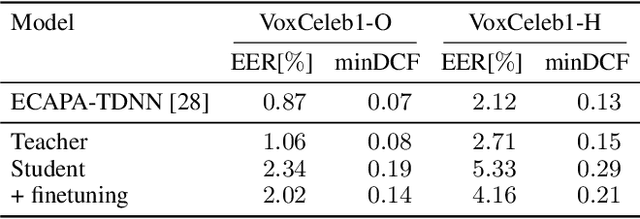
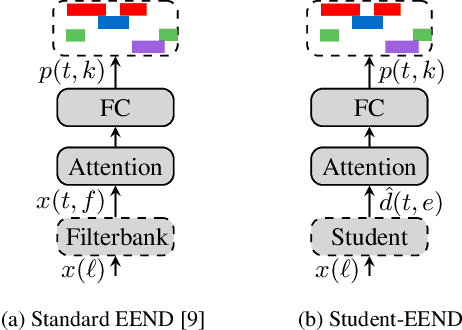
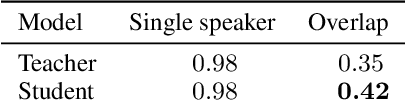
Using a Teacher-Student training approach we developed a speaker embedding extraction system that outputs embeddings at frame rate. Given this high temporal resolution and the fact that the student produces sensible speaker embeddings even for segments with speech overlap, the frame-wise embeddings serve as an appropriate representation of the input speech signal for an end-to-end neural meeting diarization (EEND) system. We show in experiments that this representation helps mitigate a well-known problem of EEND systems: when increasing the number of speakers the diarization performance drop is significantly reduced. We also introduce block-wise processing to be able to diarize arbitrarily long meetings.
BuboGPT: Enabling Visual Grounding in Multi-Modal LLMs
Jul 17, 2023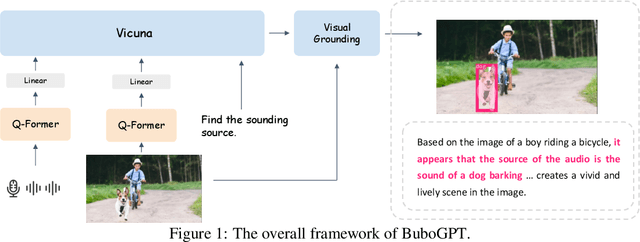

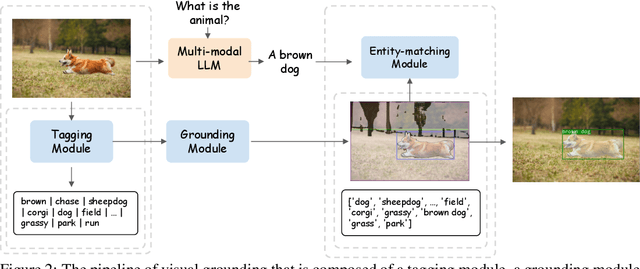
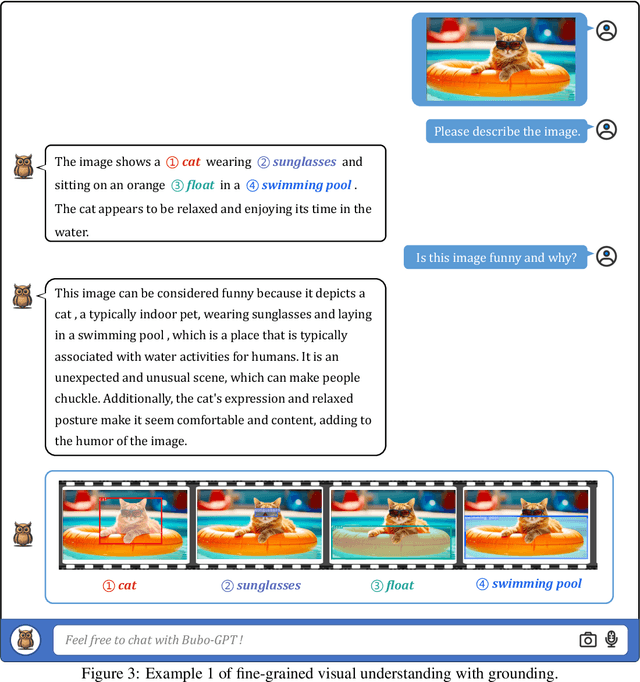
LLMs have demonstrated remarkable abilities at interacting with humans through language, especially with the usage of instruction-following data. Recent advancements in LLMs, such as MiniGPT-4, LLaVA, and X-LLM, further enlarge their abilities by incorporating multi-modal inputs, including image, video, and speech. Despite their effectiveness at generating precise and detailed language understanding of the given modality signal, these LLMs give up the ability to ground specific parts of inputs, thus only constructing a coarse-grained mapping. However, explicit and informative correspondence between text and other modalities will not only improve the user experience but also help to expand the application scenario of multi-modal LLMs. Therefore, we propose BuboGPT, a multi-modal LLM with visual grounding that can perform cross-modal interaction between vision, audio and language, providing fine-grained understanding of visual objects and other given modalities. As a result, BuboGPT is able to point out the specific location of an object in the image, when it is generating response or description for that object. Our contributions are two-fold: 1) An off-the-shelf visual grounding module based on SAM that extracts entities in a sentence and find corresponding masks in the image. 2) A two-stage training scheme and instruction dataset to endow joint text-image-audio understanding. Our experiments show that BuboGPT achieves impressive multi-modality understanding and visual grounding abilities during the interaction with human. It performs consistently well when provided by arbitrary modality combinations (either aligned or unaligned). Our code, model and dataset are available at https://bubo-gpt.github.io .
LyricWhiz: Robust Multilingual Zero-shot Lyrics Transcription by Whispering to ChatGPT
Jul 07, 2023

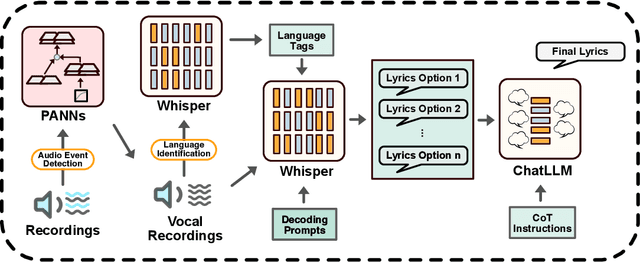
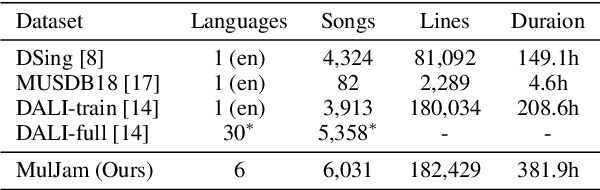
We introduce LyricWhiz, a robust, multilingual, and zero-shot automatic lyrics transcription method achieving state-of-the-art performance on various lyrics transcription datasets, even in challenging genres such as rock and metal. Our novel, training-free approach utilizes Whisper, a weakly supervised robust speech recognition model, and GPT-4, today's most performant chat-based large language model. In the proposed method, Whisper functions as the "ear" by transcribing the audio, while GPT-4 serves as the "brain," acting as an annotator with a strong performance for contextualized output selection and correction. Our experiments show that LyricWhiz significantly reduces Word Error Rate compared to existing methods in English and can effectively transcribe lyrics across multiple languages. Furthermore, we use LyricWhiz to create the first publicly available, large-scale, multilingual lyrics transcription dataset with a CC-BY-NC-SA copyright license, based on MTG-Jamendo, and offer a human-annotated subset for noise level estimation and evaluation. We anticipate that our proposed method and dataset will advance the development of multilingual lyrics transcription, a challenging and emerging task.
Multilingual Contextual Adapters To Improve Custom Word Recognition In Low-resource Languages
Jul 03, 2023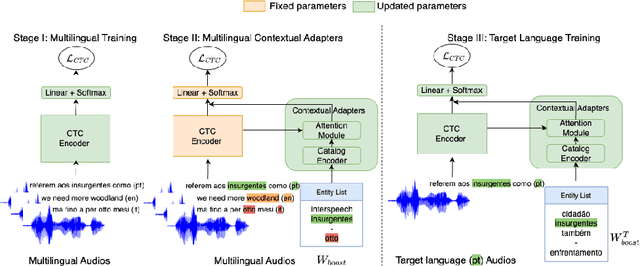
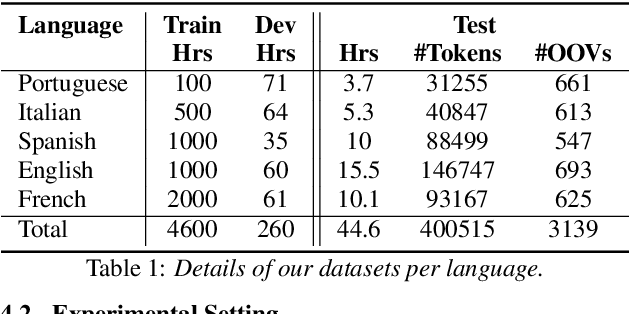
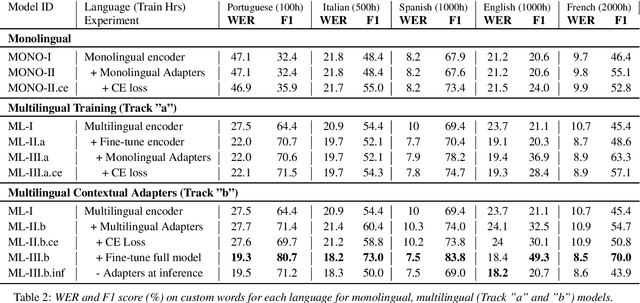
Connectionist Temporal Classification (CTC) models are popular for their balance between speed and performance for Automatic Speech Recognition (ASR). However, these CTC models still struggle in other areas, such as personalization towards custom words. A recent approach explores Contextual Adapters, wherein an attention-based biasing model for CTC is used to improve the recognition of custom entities. While this approach works well with enough data, we showcase that it isn't an effective strategy for low-resource languages. In this work, we propose a supervision loss for smoother training of the Contextual Adapters. Further, we explore a multilingual strategy to improve performance with limited training data. Our method achieves 48% F1 improvement in retrieving unseen custom entities for a low-resource language. Interestingly, as a by-product of training the Contextual Adapters, we see a 5-11% Word Error Rate (WER) reduction in the performance of the base CTC model as well.