 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
InternVideo2: Scaling Video Foundation Models for Multimodal Video Understanding
Mar 22, 2024
We introduce InternVideo2, a new video foundation model (ViFM) that achieves the state-of-the-art performance in action recognition, video-text tasks, and video-centric dialogue. Our approach employs a progressive training paradigm that unifies the different self- or weakly-supervised learning frameworks of masked video token reconstruction, cross-modal contrastive learning, and next token prediction. Different training stages would guide our model to capture different levels of structure and semantic information through different pretext tasks. At the data level, we prioritize the spatiotemporal consistency by semantically segmenting videos and generating video-audio-speech captions. This improves the alignment between video and text. We scale both data and model size for our InternVideo2. Through extensive experiments, we validate our designs and demonstrate the state-of-the-art performance on over 60 video and audio tasks. Notably, our model outperforms others on various video-related captioning, dialogue, and long video understanding benchmarks, highlighting its ability to reason and comprehend long temporal contexts. Code and models are available at https://github.com/OpenGVLab/InternVideo2/.
SICRN: Advancing Speech Enhancement through State Space Model and Inplace Convolution Techniques
Feb 22, 2024Speech enhancement aims to improve speech quality and intelligibility, especially in noisy environments where background noise degrades speech signals. Currently, deep learning methods achieve great success in speech enhancement, e.g. the representative convolutional recurrent neural network (CRN) and its variants. However, CRN typically employs consecutive downsampling and upsampling convolution for frequency modeling, which destroys the inherent structure of the signal over frequency. Additionally, convolutional layers lacks of temporal modelling abilities. To address these issues, we propose an innovative module combing a State space model and Inplace Convolution (SIC), and to replace the conventional convolution in CRN, called SICRN. Specifically, a dual-path multidimensional State space model captures the global frequencies dependency and long-term temporal dependencies. Meanwhile, the 2D-inplace convolution is used to capture the local structure, which abandons the downsampling and upsampling. Systematic evaluations on the public INTERSPEECH 2020 DNS challenge dataset demonstrate SICRN's efficacy. Compared to strong baselines, SICRN achieves performance close to state-of-the-art while having advantages in model parameters, computations, and algorithmic delay. The proposed SICRN shows great promise for improved speech enhancement.
FlowerFormer: Empowering Neural Architecture Encoding using a Flow-aware Graph Transformer
Mar 21, 2024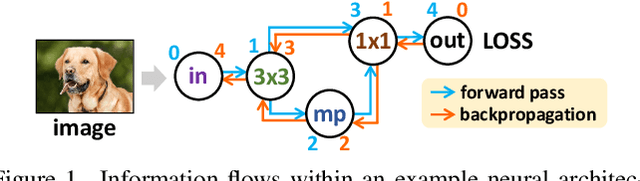
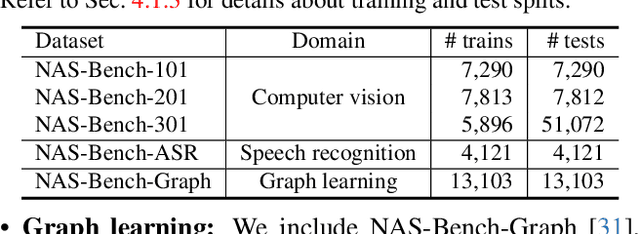
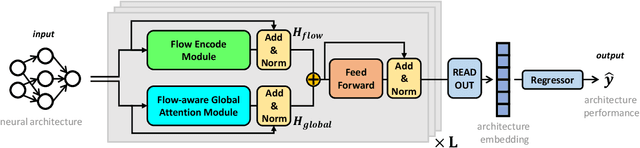
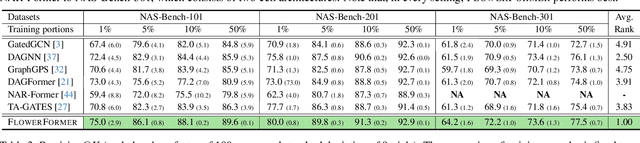
The success of a specific neural network architecture is closely tied to the dataset and task it tackles; there is no one-size-fits-all solution. Thus, considerable efforts have been made to quickly and accurately estimate the performances of neural architectures, without full training or evaluation, for given tasks and datasets. Neural architecture encoding has played a crucial role in the estimation, and graphbased methods, which treat an architecture as a graph, have shown prominent performance. For enhanced representation learning of neural architectures, we introduce FlowerFormer, a powerful graph transformer that incorporates the information flows within a neural architecture. FlowerFormer consists of two key components: (a) bidirectional asynchronous message passing, inspired by the flows; (b) global attention built on flow-based masking. Our extensive experiments demonstrate the superiority of FlowerFormer over existing neural encoding methods, and its effectiveness extends beyond computer vision models to include graph neural networks and auto speech recognition models. Our code is available at http://github.com/y0ngjaenius/CVPR2024_FLOWERFormer.
Dialogue Understandability: Why are we streaming movies with subtitles?
Mar 22, 2024Watching movies and TV shows with subtitles enabled is not simply down to audibility or speech intelligibility. A variety of evolving factors related to technological advances, cinema production and social behaviour challenge our perception and understanding. This study seeks to formalise and give context to these influential factors under a wider and novel term referred to as Dialogue Understandability. We propose a working definition for Dialogue Understandability being a listener's capacity to follow the story without undue cognitive effort or concentration being required that impacts their Quality of Experience (QoE). The paper identifies, describes and categorises the factors that influence Dialogue Understandability mapping them over the QoE framework, a media streaming lifecycle, and the stakeholders involved. We then explore available measurement tools in the literature and link them to the factors they could potentially be used for. The maturity and suitability of these tools is evaluated over a set of pilot experiments. Finally, we reflect on the gaps that still need to be filled, what we can measure and what not, future subjective experiments, and new research trends that could help us to fully characterise Dialogue Understandability.
SynerMix: Synergistic Mixup Solution for Enhanced Intra-Class Cohesion and Inter-Class Separability in Image Classification
Mar 24, 2024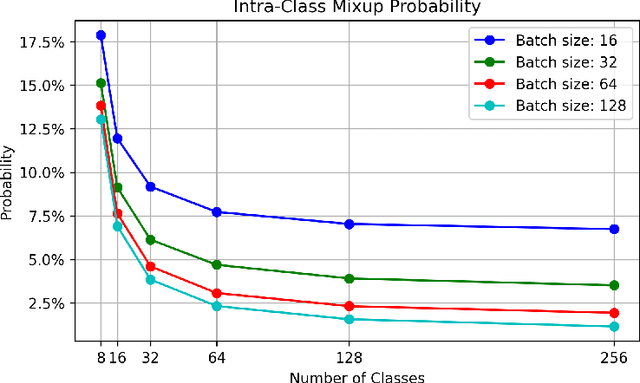

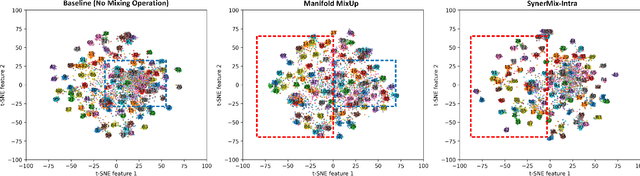
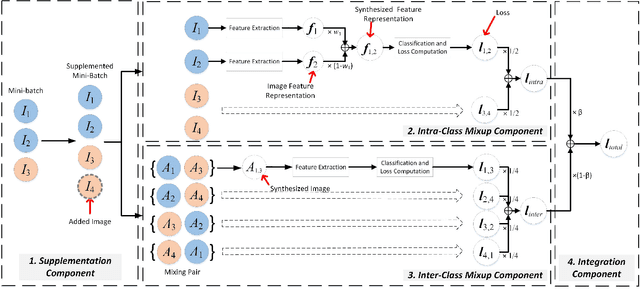
To address the issues of MixUp and its variants (e.g., Manifold MixUp) in image classification tasks-namely, their neglect of mixing within the same class (intra-class mixup) and their inadequacy in enhancing intra-class cohesion through their mixing operations-we propose a novel mixup method named SynerMix-Intra and, building upon this, introduce a synergistic mixup solution named SynerMix. SynerMix-Intra specifically targets intra-class mixup to bolster intra-class cohesion, a feature not addressed by current mixup methods. For each mini-batch, it leverages feature representations of unaugmented original images from each class to generate a synthesized feature representation through random linear interpolation. All synthesized representations are then fed into the classification and loss layers to calculate an average classification loss that significantly enhances intra-class cohesion. Furthermore, SynerMix combines SynerMix-Intra with an existing mixup approach (e.g., MixUp, Manifold MixUp), which primarily focuses on inter-class mixup and has the benefit of enhancing inter-class separability. In doing so, it integrates both inter- and intra-class mixup in a balanced way while concurrently improving intra-class cohesion and inter-class separability. Experimental results on six datasets show that SynerMix achieves a 0.1% to 3.43% higher accuracy than the best of either MixUp or SynerMix-Intra alone, averaging a 1.16% gain. It also surpasses the top-performer of either Manifold MixUp or SynerMix-Intra by 0.12% to 5.16%, with an average gain of 1.11%. Given that SynerMix is model-agnostic, it holds significant potential for application in other domains where mixup methods have shown promise, such as speech and text classification. Our code is publicly available at: https://github.com/wxitxy/synermix.git.
What do neural networks listen to? Exploring the crucial bands in Speech Enhancement using Sinc-convolution
Mar 04, 2024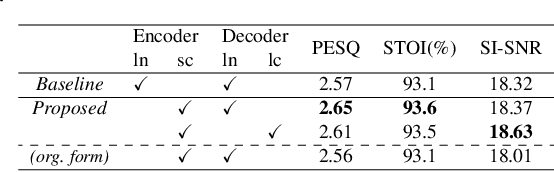
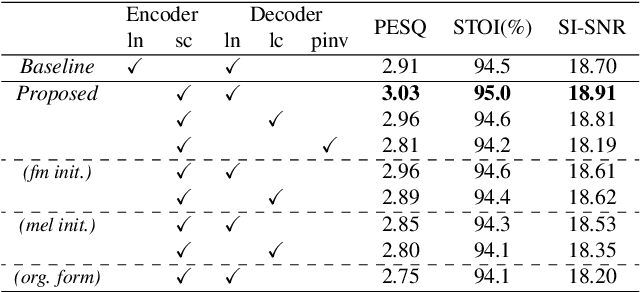
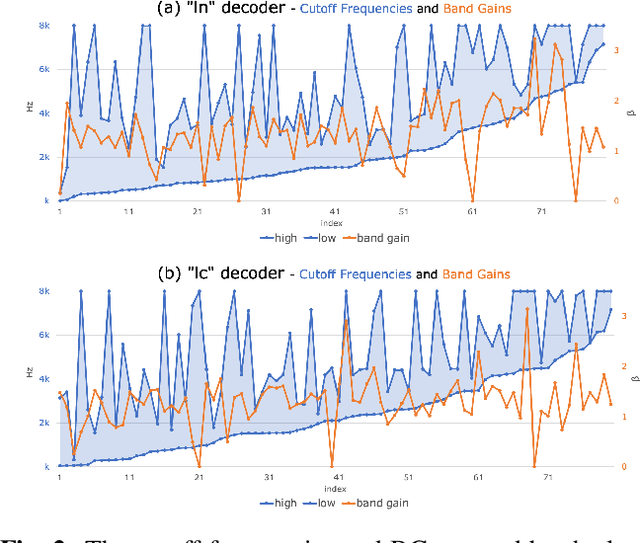
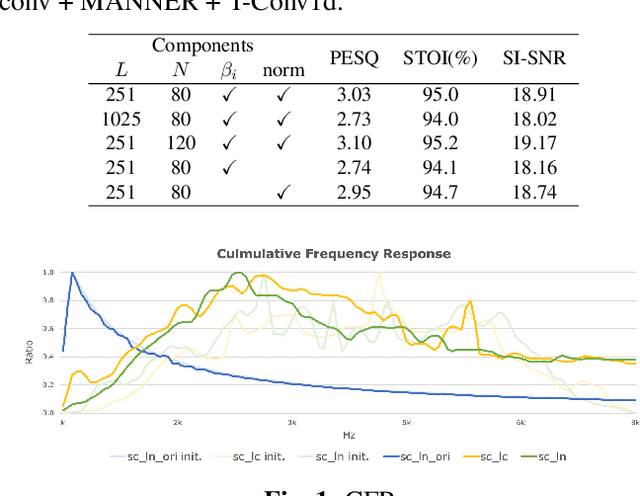
This study introduces a reformed Sinc-convolution (Sincconv) framework tailored for the encoder component of deep networks for speech enhancement (SE). The reformed Sincconv, based on parametrized sinc functions as band-pass filters, offers notable advantages in terms of training efficiency, filter diversity, and interpretability. The reformed Sinc-conv is evaluated in conjunction with various SE models, showcasing its ability to boost SE performance. Furthermore, the reformed Sincconv provides valuable insights into the specific frequency components that are prioritized in an SE scenario. This opens up a new direction of SE research and improving our knowledge of their operating dynamics.
How do Hyenas deal with Human Speech? Speech Recognition and Translation with ConfHyena
Feb 20, 2024The attention mechanism, a cornerstone of state-of-the-art neural models, faces computational hurdles in processing long sequences due to its quadratic complexity. Consequently, research efforts in the last few years focused on finding more efficient alternatives. Among them, Hyena (Poli et al., 2023) stands out for achieving competitive results in both language modeling and image classification, while offering sub-quadratic memory and computational complexity. Building on these promising results, we propose ConfHyena, a Conformer whose encoder self-attentions are replaced with an adaptation of Hyena for speech processing, where the long input sequences cause high computational costs. Through experiments in automatic speech recognition (for English) and translation (from English into 8 target languages), we show that our best ConfHyena model significantly reduces the training time by 27%, at the cost of minimal quality degradation (~1%), which, in most cases, is not statistically significant.
Open Access NAO (OAN): a ROS2-based software framework for HRI applications with the NAO robot
Mar 20, 2024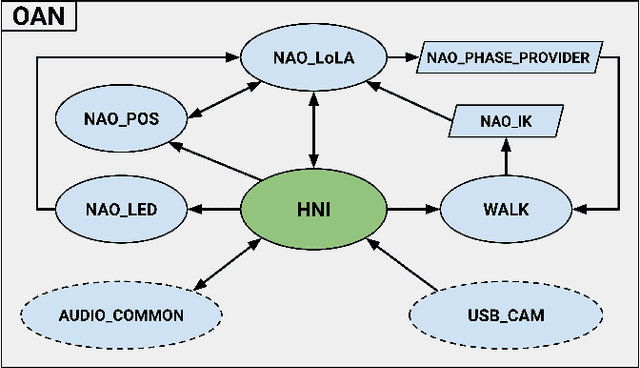


This paper presents a new software framework for HRI experimentation with the sixth version of the common NAO robot produced by the United Robotics Group. Embracing the common demand of researchers for better performance and new features for NAO, the authors took advantage of the ability to run ROS2 onboard on the NAO to develop a framework independent of the APIs provided by the manufacturer. Such a system provides NAO with not only the basic skills of a humanoid robot such as walking and reproducing movements of interest but also features often used in HRI such as: speech recognition/synthesis, face and object detention, and the use of Generative Pre-trained Transformer (GPT) models for conversation. The developed code is therefore configured as a ready-to-use but also highly expandable and improvable tool thanks to the possibilities provided by the ROS community.
AnnoTheia: A Semi-Automatic Annotation Toolkit for Audio-Visual Speech Technologies
Feb 20, 2024More than 7,000 known languages are spoken around the world. However, due to the lack of annotated resources, only a small fraction of them are currently covered by speech technologies. Albeit self-supervised speech representations, recent massive speech corpora collections, as well as the organization of challenges, have alleviated this inequality, most studies are mainly benchmarked on English. This situation is aggravated when tasks involving both acoustic and visual speech modalities are addressed. In order to promote research on low-resource languages for audio-visual speech technologies, we present AnnoTheia, a semi-automatic annotation toolkit that detects when a person speaks on the scene and the corresponding transcription. In addition, to show the complete process of preparing AnnoTheia for a language of interest, we also describe the adaptation of a pre-trained model for active speaker detection to Spanish, using a database not initially conceived for this type of task. The AnnoTheia toolkit, tutorials, and pre-trained models are available on GitHub.
Speech Translation with Speech Foundation Models and Large Language Models: What is There and What is Missing?
Feb 19, 2024The field of natural language processing (NLP) has recently witnessed a transformative shift with the emergence of foundation models, particularly Large Language Models (LLMs) that have revolutionized text-based NLP. This paradigm has extended to other modalities, including speech, where researchers are actively exploring the combination of Speech Foundation Models (SFMs) and LLMs into single, unified models capable of addressing multimodal tasks. Among such tasks, this paper focuses on speech-to-text translation (ST). By examining the published papers on the topic, we propose a unified view of the architectural solutions and training strategies presented so far, highlighting similarities and differences among them. Based on this examination, we not only organize the lessons learned but also show how diverse settings and evaluation approaches hinder the identification of the best-performing solution for each architectural building block and training choice. Lastly, we outline recommendations for future works on the topic aimed at better understanding the strengths and weaknesses of the SFM+LLM solutions for ST.